15 إطار عمل للتعلم الآلي مفتوح المصدر وغير المعروف يستحق الاكتشاف في 2020

يُعد التعلم الآلي (Machine Learning - ML) من أسرع التقنيات نموًا وتطورًا في عصرنا الحالي. يشهد تطبيق التعلم الآلي في مختلف مجالات الحوسبة انتشارًا واسعًا وسريعًا، ولا يقتصر هذا النمو على توافر الأجهزة القوية وبتكلفة معقولة فحسب، بل يمتد ليشمل التزايد المستمر في أُطر عمل التعلم الآلي مفتوحة المصدر والمجانية. هذه الأُطر تُمكّن المطورين من تنفيذ حلول التعلم الآلي بسهولة وفعالية.
تُتيح هذه المجموعة الواسعة من أُطر عمل التعلم الآلي مفتوحة المصدر لعلماء البيانات ومهندسي التعلم الآلي بناء أنظمة قوية، وتطبيقها، وصيانتها، بالإضافة إلى إطلاق مشاريع جديدة ومبتكرة ذات تأثير كبير. عند اختيار إطار عمل أو مكتبة للتعلم الآلي لمعالجة حالة استخدام معينة، من الضروري إجراء تقييم شامل لتحديد الأنسب لاحتياجاتك. تتضمن العوامل الأساسية لهذا التقييم:
- سهولة الاستخدام.
- الدعم المجتمعي الواسع.
- سرعات التشغيل والأداء.
- درجة الانفتاح والمرونة.
لمن هذا المقال؟ يستهدف هذا المقال كل من يرغب في تطبيق المعرفة النظرية للتعلم الآلي عمليًا، وكذلك المهتمين باستكشاف أُطر عمل مفتوحة المصدر جديدة ومحتملة لمشاريعهم المستقبلية في مجال التعلم الآلي. فيما يلي قائمة بأُطر العمل والمكتبات مفتوحة المصدر وغير المعروفة نسبيًا، والتي يمكن للشركات والأفراد الاستفادة منها لبناء أنظمة تعلم آلي متطورة.
1. Blocks
Blocks هو إطار عمل يسهل عليك بناء نماذج الشبكات العصبية بالاعتماد على مكتبة Theano. يدعم الإطار حاليًا ويوفر إمكانية إنشاء عمليات Theano مُحددة بمعاملات تُسمى “bricks“، بالإضافة إلى مطابقة الأنماط لاختيار المتغيرات وbricks في النماذج الكبيرة، وتوفير خوارزميات لتحسين نموذجك، وحفظ واستئناف عمليات التدريب. يمكنك أيضًا التعرف على Fuel، وهو محرك معالجة البيانات الذي طُوّر بشكل أساسي لـ Blocks.
- لغة البرمجة:
Python - رابط
GitHub:https://github.com/mila-iqia/blocks
2. Analytics Zoo

يوفر Analytics Zoo منصة موحدة لتحليل البيانات والذكاء الاصطناعي، تجمع بسلاسة بين برامج TensorFlow وKeras وPyTorch وSpark وFlink وRay في مسار عمل متكامل. يمكن لهذه المنصة التوسع بشفافية من جهاز حاسوب محمول إلى مجموعات خوادم كبيرة لمعالجة البيانات الضخمة في بيئات الإنتاج.
متى يجب عليك استخدام Analytics Zoo لتطوير حلول الذكاء الاصطناعي الخاصة بك؟
- إذا كنت ترغب في بناء نماذج ذكاء اصطناعي أولية (
prototype) بسهولة. - عندما تكون قابلية التوسع (
scaling) أمرًا بالغ الأهمية بالنسبة لك. - عندما ترغب في إضافة عمليات أتمتة إلى مسار التعلم الآلي الخاص بك، مثل هندسة الميزات (
feature engineering) واختيار النموذج (model selection).
يتم صيانة هذا المشروع بواسطة Intel-analytics.
- لغة البرمجة:
Python - رابط
GitHub:https://github.com/intel-analytics/analytics-zoo
3. Ml5.js

يهدف Ml5.js إلى جعل التعلم الآلي متاحًا لجمهور واسع يشمل الفنانين، المبرمجين المبدعين، والطلاب. توفر المكتبة وصولاً إلى خوارزميات ونماذج التعلم الآلي مباشرة في المتصفح، معتمدة على TensorFlow.js. استلهمت ml5.js من Processing وp5.js. يتم تطوير وصيانة هذا المشروع مفتوح المصدر بواسطة برنامج الاتصالات التفاعلية/الفنون الإعلامية التفاعلية بجامعة نيويورك، وبواسطة فنانين ومصممين وطلاب وتقنيين ومطورين من جميع أنحاء العالم. ملاحظة: هذا المشروع لا يزال قيد التطوير حاليًا.
- لغة البرمجة:
Javascript - رابط
GitHub:https://github.com/ml5js/ml5-library
4. AdaNet

AdaNet هو إطار عمل خفيف الوزن يعتمد على TensorFlow، مصمم للتعلم التلقائي لنماذج عالية الجودة بأقل قدر من تدخل الخبراء. يعتمد AdaNet على الجهود الحديثة في مجال التعلم الآلي التلقائي (AutoML) ليكون سريعًا ومرنًا مع توفير ضمانات للتعلم. الأهم من ذلك، يوفر AdaNet إطار عمل عامًا ليس فقط لتعلم بنية الشبكة العصبية، بل أيضًا لتعلم تجميع النماذج (ensemble) للحصول على نماذج أفضل.
يوفر AdaNet واجهة برمجة تطبيقات (API) مألوفة تشبه Keras للتدريب، التقييم، ونشر نماذجك في بيئات الإنتاج.
- لغة البرمجة:
Python - رابط
GitHub:https://github.com/tensorflow/adanet
5. Mljar
إذا كنت تبحث عن منصة لإنشاء نماذج أولية وخدمة نشر، فإن Mljar هو الخيار الأمثل لك. يميل Mljar إلى البحث في خوارزميات مختلفة وإجراء ضبط للمعاملات الفائقة (hyper-parameters tuning) للعثور على أفضل نموذج. كما يوفر نتائج سريعة عن طريق تشغيل جميع العمليات الحسابية في السحابة، وفي النهاية يقوم بإنشاء نماذج مجمعة (ensemble models). بعد ذلك، يقوم بإنشاء تقارير بتنسيق Markdown من تدريب AutoML.
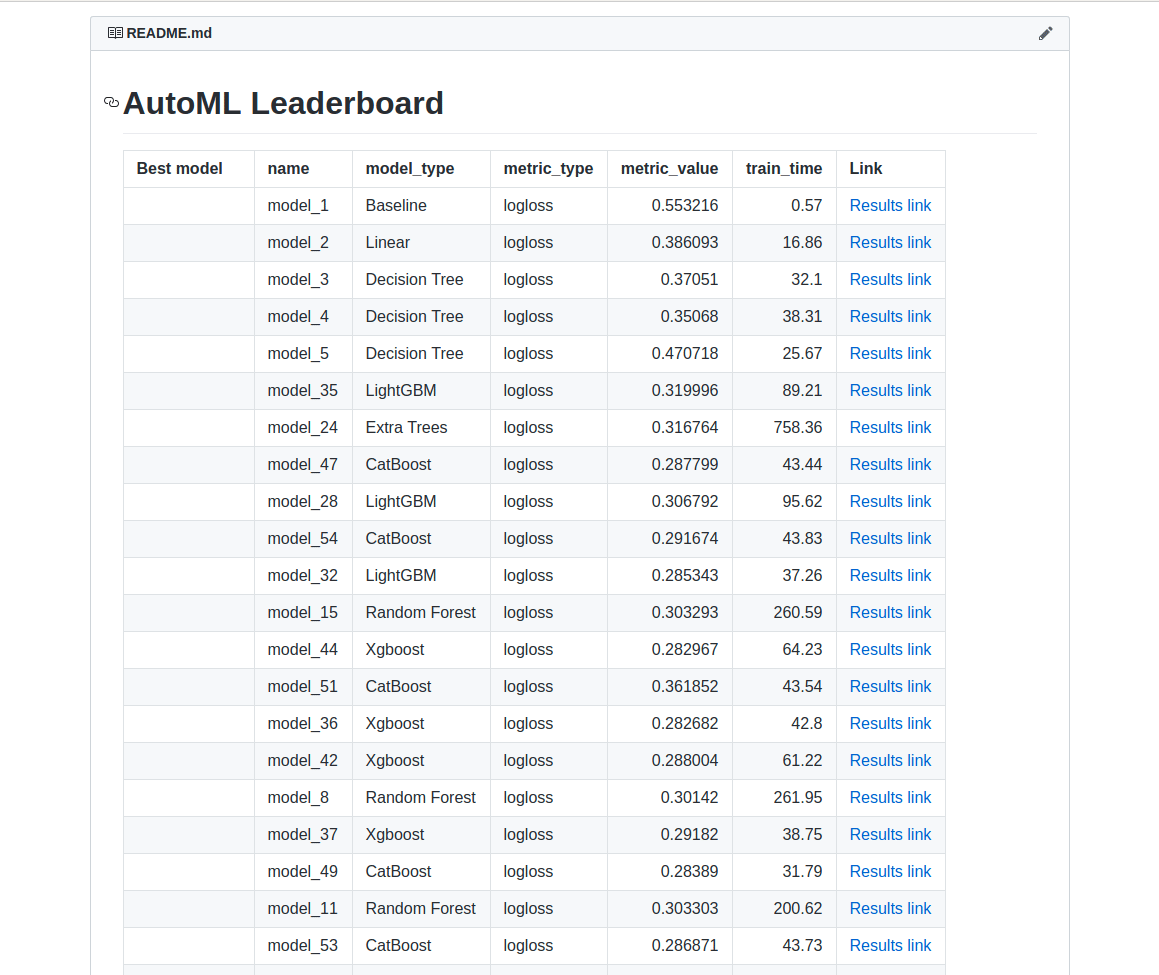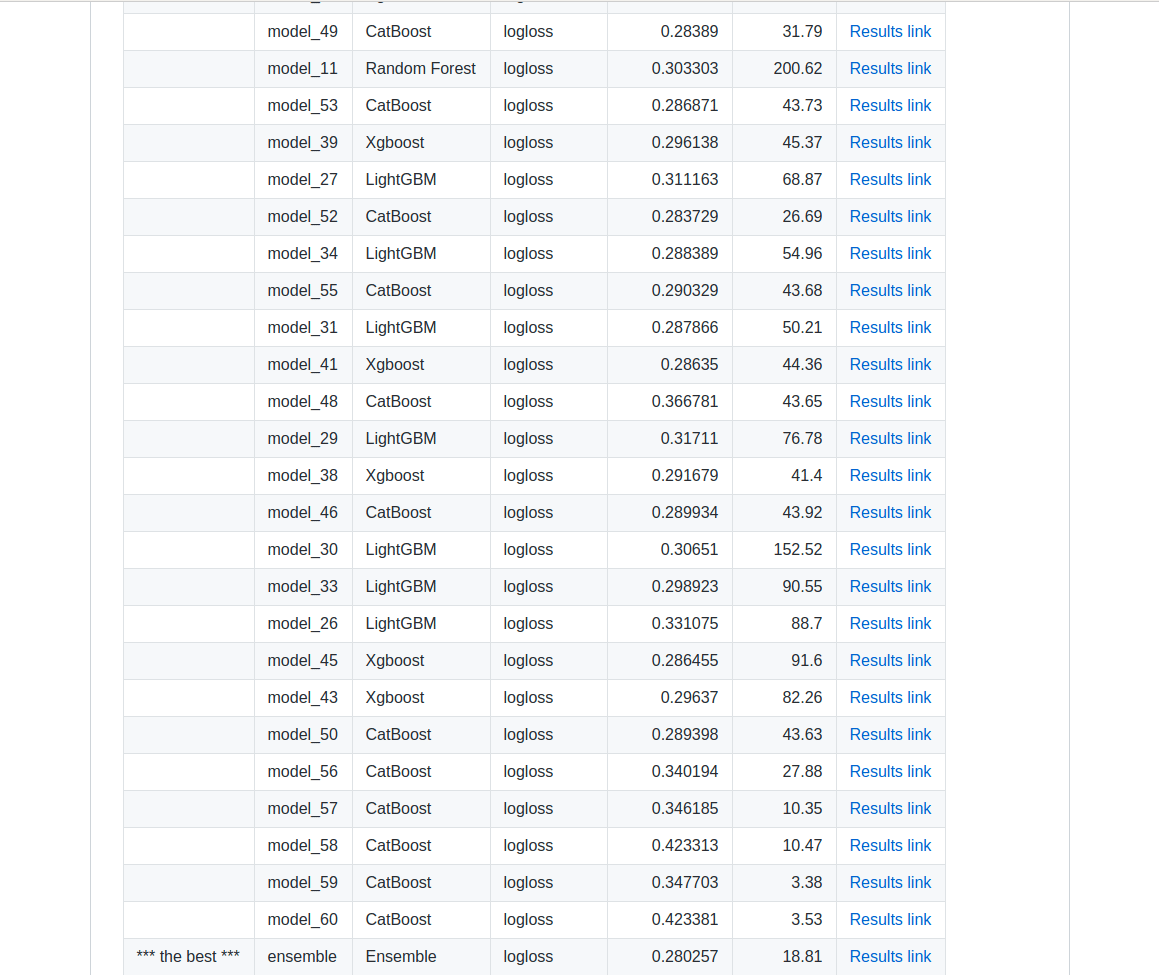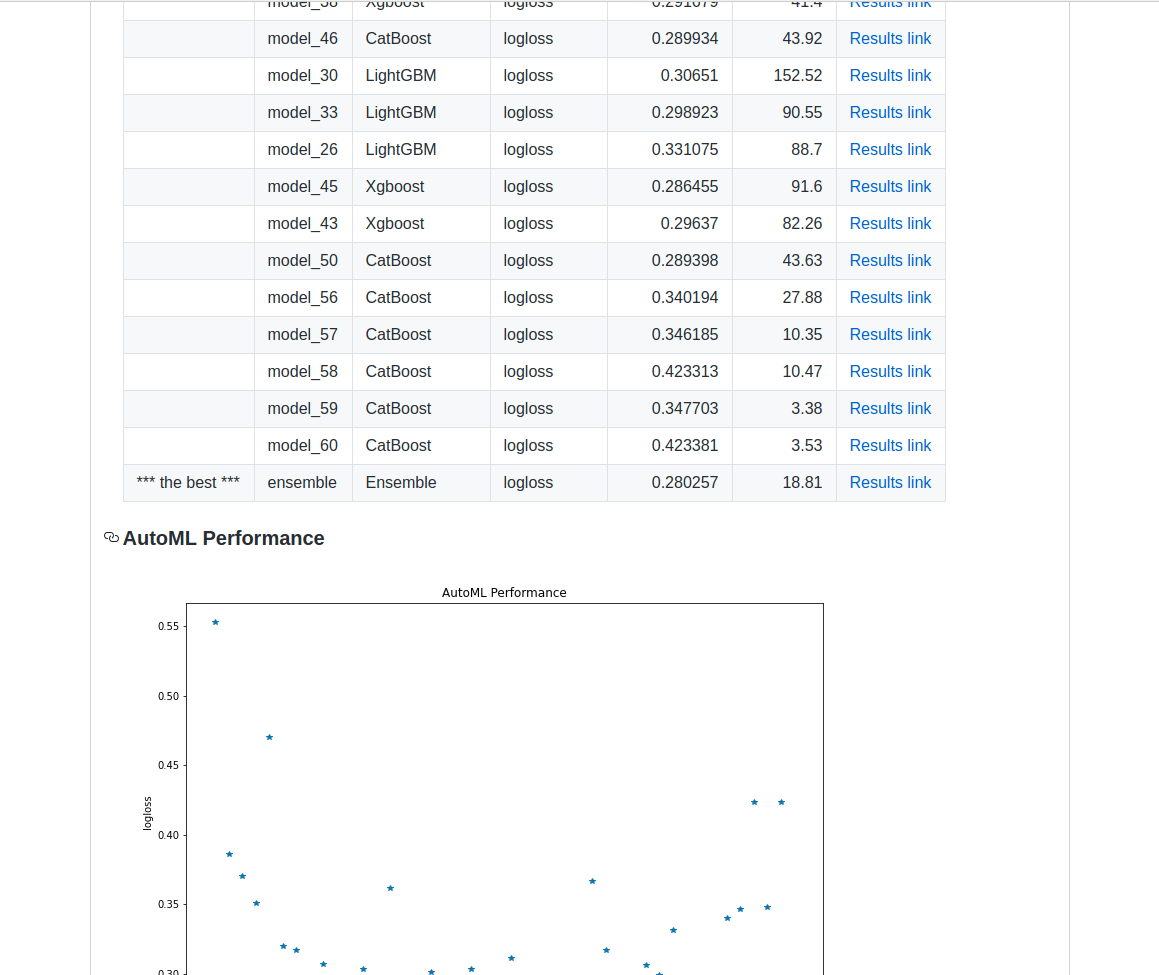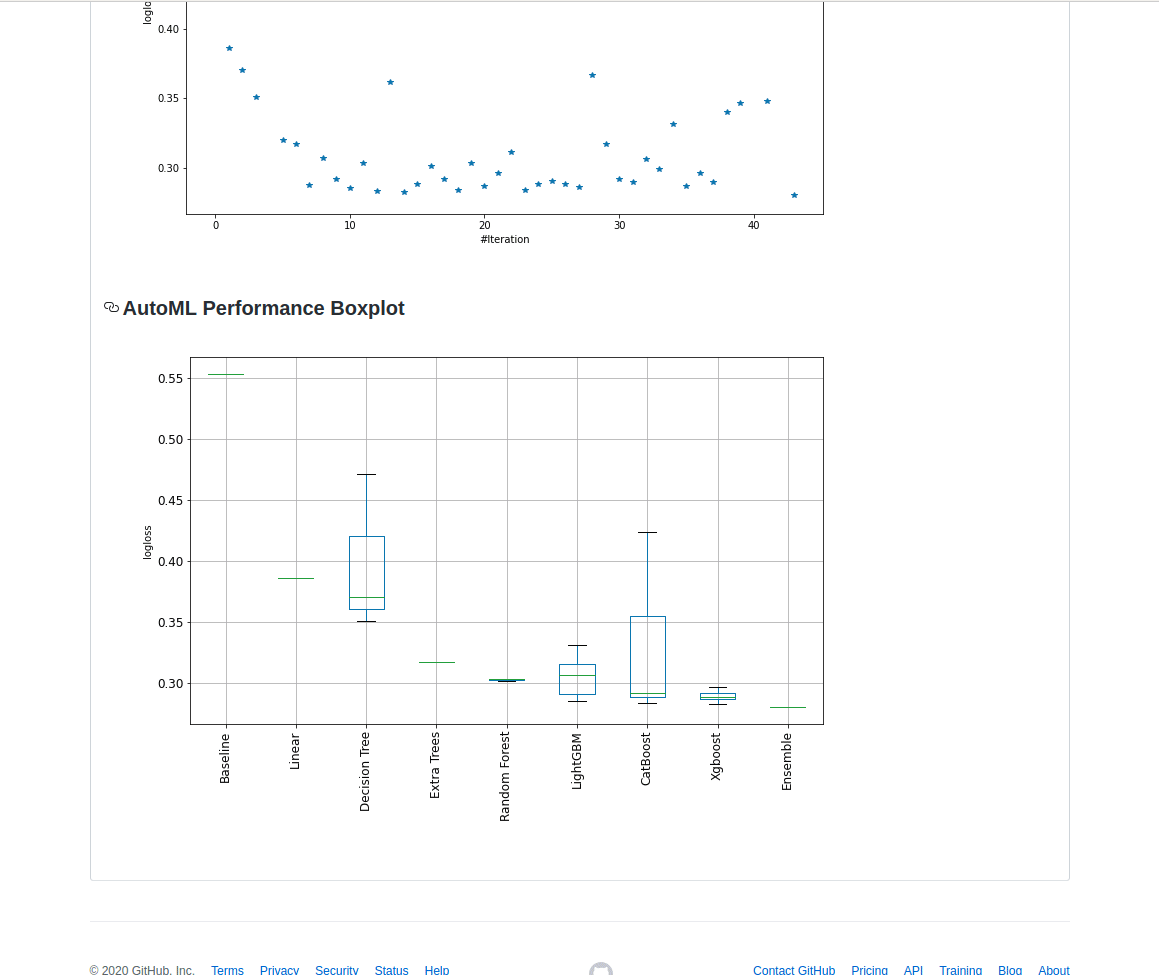
يمكن لـ Mljar تدريب نماذج التعلم الآلي لـ:
- التصنيف الثنائي (
binary classification). - التصنيف متعدد الفئات (
multi-class classification). - الانحدار (
regression).
يوفر Mljar نوعين من الواجهات:
- غلاف
Pythonفوق واجهة برمجة تطبيقاتMljar API. - تشغيل نماذج التعلم الآلي في متصفح الويب الخاص بك.
- لغة البرمجة:
Python - رابط
GitHub:https://github.com/mljar/mljar-supervised
6. ConvNetJS

التعلم العميق في Javascript. تدريب الشبكات العصبية التلافيفية (Convolutional Neural Networks) أو الشبكات العادية مباشرة في متصفحك. على غرار Tensorflow.js، تُعد ConvNetJS مكتبة JavaScript تدعم تدريب نماذج التعلم العميق المختلفة في متصفح الويب الخاص بك. لا تحتاج إلى وحدات معالجة رسوميات (GPUs) أو برامج ثقيلة أخرى.
تدعم ConvNetJS ما يلي:
- وحدات الشبكات العصبية (
Neural Network modules). - تدريب الشبكات التلافيفية للصور (
Convolutional Networks for images). - دوال التكلفة للانحدار والتصنيف (
Regression and Classification cost functions). - وحدة التعلم المعزز (
Reinforcement Learning module)، استنادًا إلى تعلمDeep Q Learning.
ملاحظة: لا يتم صيانة هذا المشروع بنشاط.
- لغة البرمجة:
Javascript - رابط
GitHub:https://github.com/karpathy/convnetjs
7. NNI (Neural Network Intelligence)
![]()
NNI (Neural Network Intelligence) هي مجموعة أدوات خفيفة الوزن لكنها قوية لمساعدة المستخدمين على أتمتة هندسة الميزات (Feature Engineering)، البحث عن بنية الشبكة العصبية (Neural Architecture Search)، ضبط المعاملات الفائقة (Hyperparameter Tuning)، وضغط النماذج (Model Compression). تدير الأداة تجارب التعلم الآلي التلقائي (AutoML)، وتوزع وتشغل مهام التجارب الناتجة عن خوارزميات الضبط للبحث عن أفضل بنية عصبية و/أو معاملات فائقة في بيئات تدريب مختلفة مثل الأجهزة المحلية (Local Machine)، الخوادم البعيدة (Remote Servers)، OpenPAI، Kubeflow، وخيارات السحابة الأخرى.
متى يجب أن تفكر في استخدام NNI:
- إذا كنت ترغب في تجربة خوارزميات
AutoMLمختلفة. - إذا كنت ترغب في تشغيل مهام تجريبية لـ
AutoMLفي بيئات متعددة. - إذا كنت ترغب في دعم
AutoMLفي منصتك الخاصة.
ملاحظة: هذا المشروع مفتوح المصدر من Microsoft.
- لغة البرمجة:
Python - رابط
GitHub:https://github.com/Microsoft/nni
8. Datumbox

إطار عمل Datumbox Machine Learning Framework هو إطار عمل مفتوح المصدر مكتوب بلغة Java، يتيح التطوير السريع لتطبيقات التعلم الآلي والإحصائية. يركز الإطار بشكل أساسي على تضمين عدد كبير من خوارزميات التعلم الآلي والأساليب الإحصائية، وقدرته على التعامل مع مجموعات البيانات الكبيرة.
يوفر Datumbox عددًا من النماذج المدربة مسبقًا لمهام مختلفة مثل الكشف عن الرسائل غير المرغوب فيها (Spam Detection)، تحليل المشاعر (Sentiment Analysis)، الكشف عن اللغة (Language Detection)، تصنيف المواضيع (Topic Classification) وما إلى ذلك.
- لغة البرمجة:
Java - رابط
GitHub:https://github.com/datumbox/datumbox-framework
9. XAI (An eXplainability toolbox for ML)
XAI هي مكتبة تعلم آلي صُممت مع وضع قابلية تفسير الذكاء الاصطناعي (AI explainability) في صميمها. تحتوي XAI على أدوات متنوعة تُمكّن من تحليل وتقييم البيانات والنماذج. يتم صيانة مكتبة XAI بواسطة معهد الذكاء الاصطناعي والأخلاقيات (The Institute for Ethical AI & ML)، وقد طُوّرت بناءً على المبادئ الثمانية للتعلم الآلي المسؤول (Responsible Machine Learning).
تتضمن المبادئ الثمانية للتعلم الآلي المسؤول ما يلي:
- التعزيز البشري (
Human augmentation). - تقييم التحيز (
Bias Evaluation). - قابلية التفسير بالتبرير (
Explainability by Justification). - العمليات القابلة للتكرار (
Reproducible operations). - استراتيجية الإزاحة (
Displacement strategy). - الدقة العملية (
Practical accuracy). - الثقة بالخصوصية (
Trust by privacy). - الوعي بمخاطر البيانات (
Data risk awareness).
لمعرفة المزيد حول XAI، يمكنك مشاهدة هذا الحديث في مؤتمر Tensorflow London، والذي يقدم رؤى حول تعريفات ومبادئ هذه المكتبة. XAI حاليًا في مرحلة تطوير مبكرة، والإصدار الحالي هو 0.05 (Alpha).
- لغة البرمجة:
Python - رابط
GitHub:https://github.com/EthicalML/xai
10. Plato

Plato هو إطار عمل مرن لتطوير أي وكلاء ذكاء اصطناعي للمحادثة (conversational AI agents) في بيئات مختلفة. صُمم Plato لكل من المستخدمين ذوي الخلفية المحدودة في الذكاء الاصطناعي للمحادثة والباحثين المتمرسين في هذا المجال. يوفر تصميمًا نظيفًا ومفهومًا، ويتكامل مع أُطر التعلم العميق والتحسين البايزي (Bayesian optimization frameworks) الموجودة، ويقلل من الحاجة إلى كتابة التعليمات البرمجية. يدعم التفاعلات عبر النصوص والكلام وأفعال الحوار (dialogue acts). لمعرفة كيفية عمل نظام حوار أبحاث Plato، يمكنك قراءة المقال المخصص لذلك. ملاحظة: Plato هو مشروع مفتوح المصدر من Uber.
- لغة البرمجة:
Python - رابط
GitHub:https://github.com/uber-research/plato-research-dialogue-system
11. DeepDetect

DeepDetect هو خادم وواجهة برمجة تطبيقات (API) للتعلم الآلي مكتوب بلغة C++. يسهل العمل مع أحدث تقنيات التعلم الآلي ودمجها في التطبيقات الحالية. يدعم DeepDetect التعلم العميق الخاضع للإشراف وغير الخاضع للإشراف للصور والنصوص والسلاسل الزمنية والبيانات الأخرى، مع التركيز على البساطة وسهولة الاستخدام والاختبار والاتصال بالتطبيقات الحالية. يدعم التصنيف (classification)، الكشف عن الكائنات (object detection)، التجزئة (segmentation)، الانحدار (regression)، والمشفرات التلقائية (autoencoders).
يعتمد DeepDetect على مكتبات التعلم الآلي الخارجية مثل:
- مكتبة تعزيز التدرج (
Gradient boosting library)XGBoost. - مكتبات التعلم العميق (
Caffe،Tensorflow،Caffe2،Torch،NCNN، وDlib). - التجميع (
clustering) باستخدامT-SNE. - البحث عن التشابه (
similarity search) باستخدامAnnoyوFAISS.
تم تصميم DeepDetect وتنفيذه ودعمه بواسطة Jolibrain بمساعدة مساهمين مختلفين آخرين.
- لغة البرمجة:
C++ - رابط
GitHub:https://github.com/jolibrain/deepdetect
12. Streamlit
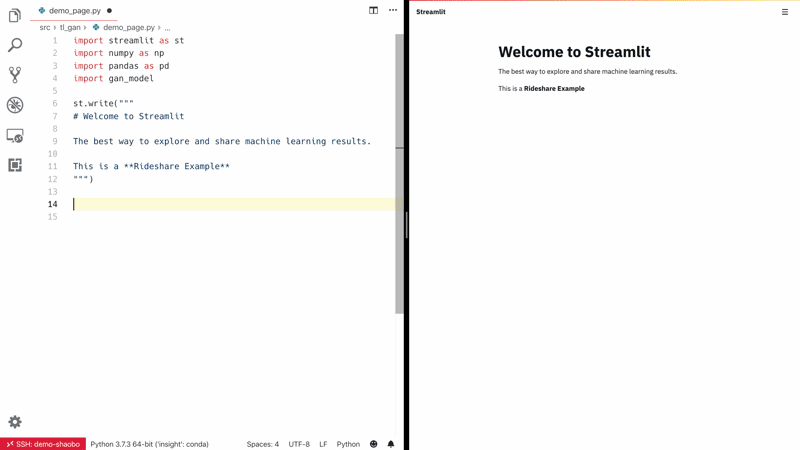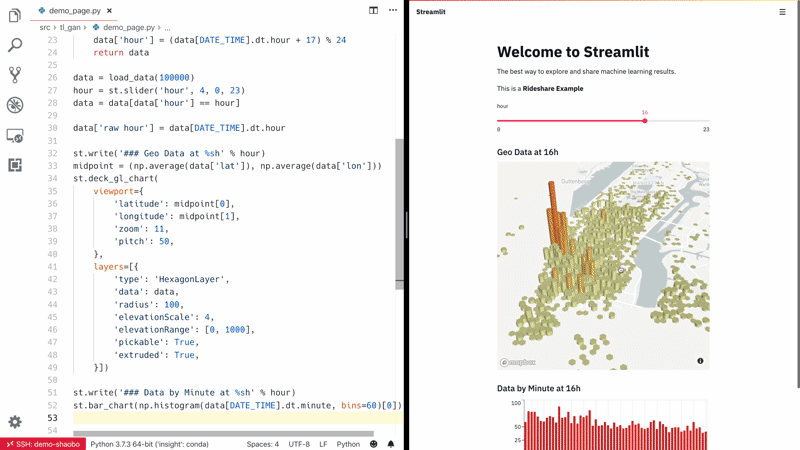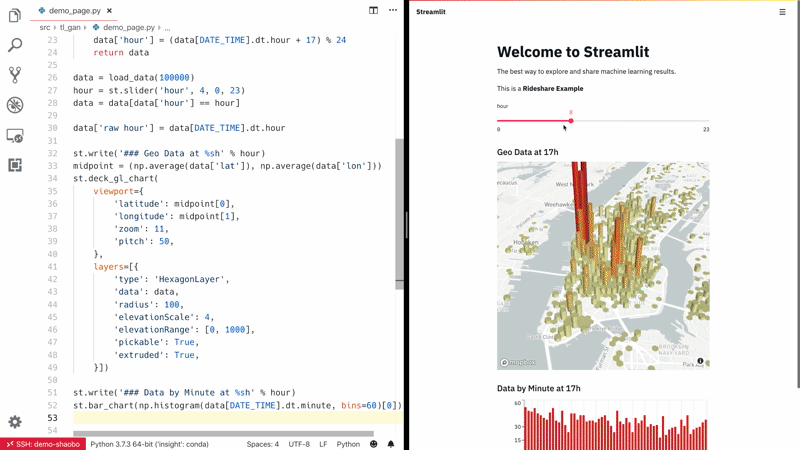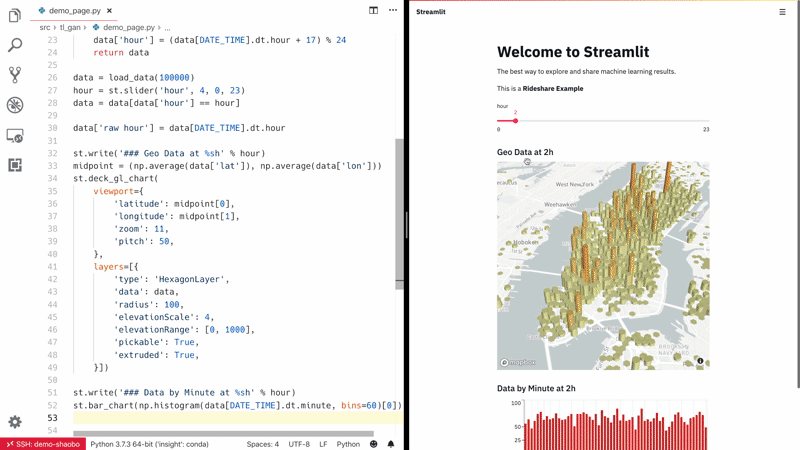
Streamlit — أسرع طريقة لبناء أدوات تعلم آلي مخصصة. Streamlit هي أداة رائعة تتيح لعلماء البيانات ومهندسي التعلم الآلي والمطورين بناء تطبيقات ويب تفاعلية للغاية لمشاريع التعلم الآلي الخاصة بهم بسرعة. لا يتطلب Streamlit أي معرفة بتطوير الويب؛ إذا كنت تعرف Python، فأنت جاهز للانطلاق! كما يدعم إعادة التحميل السريع (hot-reloading)، مما يعني أن تطبيقك يتحدث مباشرة أثناء تحرير وحفظ ملفاتك.
شاهد Streamlit وهو يعمل:
- لغة البرمجة:
Javascript & Python - رابط
GitHub:https://github.com/streamlit/streamlit
13. Dopamine

Dopamine هو إطار عمل بحثي للنماذج الأولية السريعة لخوارزميات التعلم المعزز (reinforcement learning algorithms). يهدف إلى تلبية الحاجة إلى قاعدة تعليمات برمجية صغيرة وسهلة الفهم، يمكن للمستخدمين من خلالها تجربة أفكار جريئة بحرية (بحث تأملي).
تتضمن مبادئ تصميم Dopamine ما يلي:
- سهولة التجريب (
Easy experimentation). - تطوير مرن (
Flexible development). - مدمج وموثوق (
Compact and reliable). - قابلية التكرار (
Reproducible).
في العام الماضي (2019)، حول Dopamine تعريفات شبكاته لاستخدام tf.keras.Model، وتمت إزالة الشبكات السابقة المعتمدة على tf.contrib.slim. لمعرفة كيفية استخدام Dopamine، يمكنك الاطلاع على دفاتر ملاحظات Colaboratory. ملاحظة: Dopamine هو مشروع مفتوح المصدر من Google.
- لغة البرمجة:
Python - رابط
GitHub:https://github.com/google/dopamine
14. TuriCreate

TuriCreate هي مجموعة أدوات مفتوحة المصدر لإنشاء نماذج Core ML مخصصة. باستخدام TuriCreate، يمكنك إنجاز مهام تعلم آلي مختلفة مثل تصنيف الصور (Image classification)، تصنيف الأصوات (Sound classification)، الكشف عن الكائنات (Object Detection)، نقل الأنماط (Style Transfer)، تصنيف الأنشطة (Activity classification)، أنظمة التوصية بالصور المتشابهة (Image similarity recommender)، تصنيف النصوص (text classification)، والتجميع (clustering). يتميز الإطار بكونه سهل الاستخدام، مرن، ومرئي. يعمل على مجموعات بيانات كبيرة وجاهز للنشر. يمكن استخدام النماذج المدربة على الفور في تطبيقات iOS وmacOS وtvOS وwatchOS دون أي تحويل إضافي. اطلع على محادثات TuriCreate في مؤتمري WWDC 2019 وWWDC 2018 لمعرفة المزيد. ملاحظة: TuriCreate هو مشروع مفتوح المصدر من Apple.
- لغة البرمجة:
Python - رابط
GitHub:https://github.com/apple/turicreate
15. Flair
![]()
Flair هو إطار عمل بسيط لمعالجة اللغة الطبيعية (Natural Language Processing - NLP)، تم تطويره وإتاحته كمصدر مفتوح بواسطة جامعة هومبولت في برلين. يُعد Flair جزءًا رسميًا من نظام PyTorch البيئي ويُستخدم في مئات المشاريع الصناعية والأكاديمية. يتيح لك Flair تطبيق أحدث نماذج معالجة اللغة الطبيعية على نصوصك، مثل التعرف على الكيانات المسماة (Named Entity Recognition - NER)، ووسم أجزاء الكلام (Part-of-Speech Tagging - PoS)، وإزالة الغموض الدلالي (sense disambiguation)، والتصنيف (classification).
يتفوق Flair على أفضل الأساليب السابقة في مجموعة من مهام معالجة اللغة الطبيعية:
- التعرف على الكيانات المسماة (
Named Entity Recognition). - وسم أجزاء الكلام (
Part of Speech Tagging). - التجزئة (
Chunking).
راجع هذا الجدول الذي يوضح أداء Flair:
| المهمة | أفضل طريقة سابقة (F1 Score) |
Flair (F1 Score) |
|---|---|---|
Named Entity Recognition |
92.8 | 93.09 |
Part of Speech Tagging |
97.3 | 97.43 |
Chunking |
95.1 | 95.29 |
ملاحظة: درجة F1 هي مقياس تقييم يُستخدم بشكل أساسي لمهام التصنيف، وتأخذ في الاعتبار توزيع الفئات الموجودة. تعرف على كيفية إجراء تصنيف النصوص باستخدام تضمينات Flair Embeddings في المقال المخصص لذلك.
- لغة البرمجة:
Python - رابط
GitHub:https://github.com/flairNLP/flair
الخلاصة
قبل الشروع في بناء أي تطبيق للتعلم الآلي، يواجه المطورون تحديًا في اختيار إطار العمل المناسب من بين الخيارات العديدة المتاحة. تُعد عملية التقييم الدقيق لعدة أُطر عمل أمرًا بالغ الأهمية قبل اتخاذ القرار النهائي. الأُطر مفتوحة المصدر المذكورة أعلاه توفر إمكانيات كبيرة لمساعدة أي شخص في بناء نماذج تعلم آلي بكفاءة وسهولة.
إذا كنت تتساءل عن أُطر عمل التعلم الآلي الأكثر شيوعًا، فإليك قائمة بتلك التي يستخدمها معظم علماء البيانات ومهندسي التعلم الآلي بانتظام:
TensorFlowPyTorchFastaiKerasscikit-learnMicrosoft Cognitive ToolkitTheanoCaffe2DL4JMxNetH2OAccord.NETApache Spark
الخلاصة التقنية
يُظهر هذا الاستعراض الشامل لأُطر عمل التعلم الآلي مفتوحة المصدر أن المشهد التقني في هذا المجال يتسم بالديناميكية والتنوع. بينما تهيمن أُطر مثل TensorFlow وPyTorch على الساحة، فإن وجود بدائل أقل شهرة مثل Blocks، Analytics Zoo، وXAI يقدم حلولًا متخصصة تلبي احتياجات محددة، سواء كان ذلك في سهولة الاستخدام للمبتدئين (مثل Ml5.js)، أو الأتمتة المتقدمة (مثل NNI)، أو حتى التركيز على قابلية التفسير (XAI). إن اختيار الإطار الأمثل لا يعتمد فقط على الشعبية، بل على مدى توافقه مع متطلبات المشروع، لغة البرمجة المفضلة، الدعم المجتمعي، وقابلية التوسع. هذه الأُطر تُمثل جسرًا حيويًا بين النظرية والتطبيق، مما يفتح آفاقًا واسعة للابتكار في مجال الذكاء الاصطناعي.