9 خوارزميات تعلم آلة أساسية: شرح مبسط ومفاهيم جوهرية

Machine Learning) يُحدث تحولاً جذرياً في عالمنا اليوم. تستخدمه جوجل لاقتراح نتائج البحث للمستخدمين، وتعتمد عليه نتفليكس للتوصية بالأفلام التي قد تعجبك، بينما يستفيد منه فيسبوك لاقتراح أشخاص قد تعرفهم. لم يكن تعلم الآلة بهذه الأهمية من قبل.
في الوقت نفسه، قد يكون فهم تعلم الآلة أمراً صعباً نظراً لكثرة المصطلحات المتخصصة (jargon) وتزايد عدد خوارزمياته باستمرار. يهدف هذا المقال إلى تعريفك بالمفاهيم الأساسية في مجال تعلم الآلة، وسنتناول بالتحديد المبادئ الكامنة وراء أهم 9 خوارزميات لتعلم الآلة المستخدمة حالياً.
أنظمة التوصية (Recommendation Systems)
ما هي أنظمة التوصية؟
تُستخدم أنظمة التوصية للعثور على إدخالات متشابهة ضمن مجموعة بيانات. ربما يكون المثال الأكثر شيوعاً في العالم الحقيقي لأنظمة التوصية موجوداً في نتفليكس (Netflix)، حيث توصي خدمة بث الفيديو الخاصة بها بأفلام وعروض تلفزيونية مقترحة بناءً على المحتوى الذي شاهدته بالفعل. مثال آخر هو ميزة “أشخاص قد تعرفهم” (People You May Know) في فيسبوك (Facebook)، والتي تقترح أصدقاء محتملين لك بناءً على قائمة أصدقائك الحالية. إن أنظمة التوصية المطورة والمنشورة بالكامل معقدة للغاية وتتطلب موارد حاسوبية مكثفة.
أنظمة التوصية والجبر الخطي (Linear Algebra)
تتطلب أنظمة التوصية المتكاملة خلفية عميقة في الجبر الخطي (Linear Algebra) لبنائها من الصفر. لهذا السبب، قد تكون هناك مفاهيم في هذا القسم لا تفهمها إذا لم تدرس الجبر الخطي من قبل. لا تقلق، فمكتبة بايثون (Python) الشهيرة scikit-learn تجعل بناء أنظمة التوصية سهلاً للغاية، لذا لا تحتاج إلى معرفة عميقة بالجبر الخطي لبناء أنظمة توصية عملية وواقعية.
كيف تعمل أنظمة التوصية؟
يوجد نوعان رئيسيان من أنظمة التوصية:
- أنظمة التوصية القائمة على المحتوى (
Content-based recommendation systems) - أنظمة التوصية بالترشيح التعاوني (
Collaborative filtering recommendation systems)
تقدم أنظمة التوصية القائمة على المحتوى توصيات بناءً على تشابه العناصر التي استخدمتها بالفعل. إنها تتصرف تماماً كما تتوقع أن يتصرف نظام التوصية.
أما أنظمة التوصية بالترشيح التعاوني، فتنتج توصيات بناءً على معرفة تفاعلات المستخدم مع العناصر. بعبارة أخرى، تستخدم “حكمة الجماهير” (wisdom of the crowds)، ومن هنا جاء مصطلح “التعاوني” (collaborative) في اسمها. في العالم الحقيقي، تعد أنظمة الترشيح التعاوني أكثر شيوعاً بكثير من الأنظمة القائمة على المحتوى، ويرجع ذلك أساساً إلى أنها عادةً ما تعطي نتائج أفضل. يجد بعض الممارسين أيضاً أن أنظمة الترشيح التعاوني أسهل في الفهم.
تتميز أنظمة الترشيح التعاوني أيضاً بميزة فريدة تفتقر إليها الأنظمة القائمة على المحتوى، وهي قدرتها على تعلم الميزات (features) تلقائياً. هذا يعني أنها يمكن أن تبدأ في تحديد أوجه التشابه بين العناصر بناءً على سمات لم تخبرها حتى بأخذها في الاعتبار.
يوجد فئتان فرعيتان ضمن الترشيح التعاوني:
- الترشيح التعاوني القائم على الذاكرة (
Memory-based collaborative filtering) - الترشيح التعاوني القائم على النموذج (
Model-based collaborative filtering)
لا تحتاج إلى معرفة الاختلافات بين هذين النوعين من أنظمة الترشيح التعاوني لتكون ناجحاً في تعلم الآلة. يكفي أن تدرك وجود أنواع متعددة.
ملخص القسم
فيما يلي ملخص موجز لما ناقشناه حول أنظمة التوصية في هذا الشرح:
- أمثلة على أنظمة التوصية في العالم الحقيقي.
- الأنواع المختلفة لأنظمة التوصية، وكيف أن أنظمة الترشيح التعاوني أكثر استخداماً من الأنظمة القائمة على المحتوى.
- العلاقة بين أنظمة التوصية والجبر الخطي.
الانحدار الخطي (Linear Regression)
يُستخدم الانحدار الخطي (Linear Regression) للتنبؤ بقيم y بناءً على قيم مجموعة أخرى من x.
تاريخ الانحدار الخطي
ابتكر فرانسيس غالتون (Francis Galton) الانحدار الخطي في القرن التاسع عشر. كان غالتون عالماً يدرس العلاقة بين الآباء والأبناء، وبشكل أكثر تحديداً، كان يبحث في العلاقة بين أطوال الآباء وأطوال أبنائهم. كان اكتشاف غالتون الأول هو أن الأبناء يميلون إلى أن يكونوا بنفس طول آبائهم تقريباً، وهذا ليس مستغرباً.
لاحقاً، اكتشف غالتون شيئاً أكثر إثارة للاهتمام: كان طول الابن يميل إلى أن يكون أقرب إلى متوسط الطول الإجمالي لجميع الأشخاص منه إلى طول والده. أطلق غالتون على هذه الظاهرة اسم “الانحدار” (regression). على وجه التحديد، قال: “يميل طول ابن الأب إلى الانحدار (أو الانجراف نحو) متوسط الطول”. أدى هذا إلى ظهور مجال كامل في الإحصاء وتعلم الآلة يُعرف باسم الانحدار (regression).
الرياضيات وراء الانحدار الخطي
عند إنشاء نموذج انحدار، كل ما نحاول فعله هو رسم خط يكون أقرب ما يمكن إلى كل نقطة في مجموعة البيانات. المثال النموذجي لذلك هو “طريقة المربعات الصغرى” (least squares method) للانحدار الخطي، والتي تحسب فقط مدى قرب الخط في الاتجاه الرأسي (أعلى وأسفل). إليك مثال للمساعدة في توضيح ذلك:
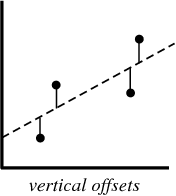
عند إنشاء نموذج انحدار، يكون الناتج النهائي معادلة يمكنك استخدامها للتنبؤ بقيمة y لقيمة x، دون معرفة قيمة y مسبقاً.
الانحدار اللوجستي (Logistic Regression)
يشبه الانحدار اللوجستي (Logistic Regression) الانحدار الخطي، باستثناء أنه بدلاً من حساب قيمة رقمية لـ y، فإنه يقدر الفئة التي تنتمي إليها نقطة البيانات.
ما هو الانحدار اللوجستي؟
الانحدار اللوجستي هو نموذج تعلم آلة (machine learning model) يُستخدم لحل مشكلات التصنيف (classification problems). إليك بعض الأمثلة على مشكلات تصنيف تعلم الآلة:
- رسائل البريد الإلكتروني العشوائية (
Spam emails): هل هي رسالة مزعجة أم لا؟ - مطالبات تأمين السيارات: هل هي شطب كامل أم إصلاح؟
- تشخيص الأمراض.
تحتوي كل مشكلة من مشكلات التصنيف هذه على فئتين بالضبط، مما يجعلها أمثلة على مشكلات التصنيف الثنائي (binary classification problems). الانحدار اللوجستي مناسب تماماً لحل مشكلات التصنيف الثنائي؛ ما علينا سوى تعيين قيم 0 و 1 للفئات المختلفة على التوالي.
لماذا نحتاج إلى الانحدار اللوجستي؟
لأنك لا تستطيع استخدام نموذج الانحدار الخطي لإجراء تنبؤات التصنيف الثنائي. لن يؤدي ذلك إلى ملاءمة جيدة، نظراً لأنك تحاول ملاءمة خط مستقيم عبر مجموعة بيانات بقيمتين محتملتين فقط. قد تساعدك هذه الصورة على فهم سبب عدم ملاءمة نماذج الانحدار الخطي لمشكلات التصنيف الثنائي:
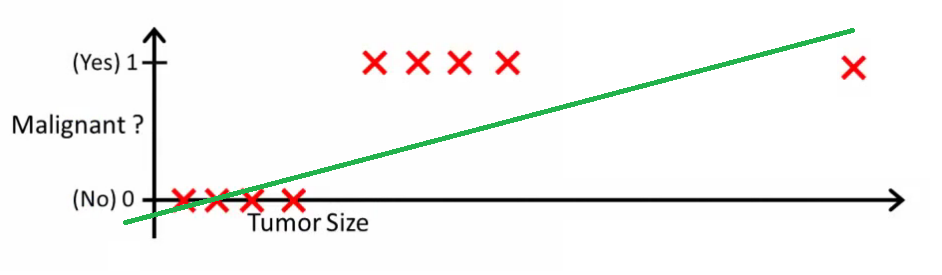
في هذه الصورة، يمثل المحور y احتمال أن يكون الورم خبيثاً. على العكس من ذلك، تمثل القيمة 1-y احتمال ألا يكون الورم خبيثاً. كما ترى، يقوم نموذج الانحدار الخطي بعمل ضعيف في التنبؤ بهذا الاحتمال لمعظم الملاحظات في مجموعة البيانات. لهذا السبب، تعد نماذج الانحدار اللوجستي مفيدة؛ فهي تتميز بانحناء في خط أفضل ملاءمة لها، مما يجعلها أكثر ملاءمة للتنبؤ بالبيانات الفئوية. إليك مثال يقارن نموذج الانحدار الخطي بنموذج الانحدار اللوجستي باستخدام نفس بيانات التدريب:
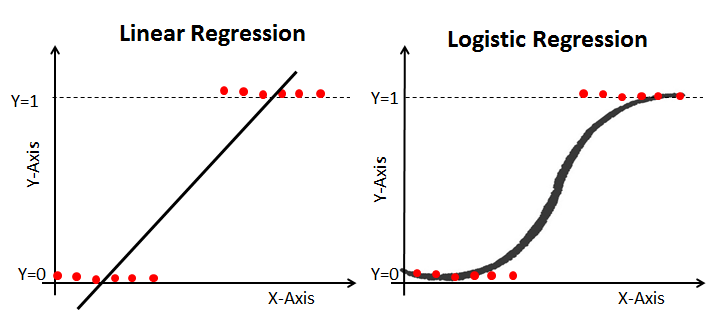
دالة سيغمويد (Sigmoid Function)
السبب وراء انحناء نموذج الانحدار اللوجستي في منحناه هو أنه لا يتم حسابه باستخدام معادلة خطية. بدلاً من ذلك، يتم بناء نماذج الانحدار اللوجستي باستخدام دالة سيغمويد (Sigmoid Function)، والتي تسمى أيضاً الدالة اللوجستية (Logistic Function) بسبب استخدامها في الانحدار اللوجستي.
لن تضطر إلى حفظ دالة سيغمويد لتكون ناجحاً في تعلم الآلة، ومع ذلك، فإن امتلاك بعض الفهم لمظهرها مفيد. المعادلة موضحة أدناه:
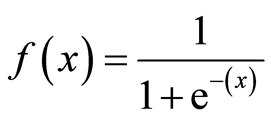
الخاصية الرئيسية لدالة سيغمويد التي تستحق الفهم هي: بغض النظر عن القيمة التي تمررها إليها، فإنها ستولد دائماً مخرجاً يتراوح بين 0 و 1.
استخدام نماذج الانحدار اللوجستي لإجراء التنبؤات
لاستخدام نموذج الانحدار اللوجستي لإجراء التنبؤات، تحتاج عموماً إلى تحديد “نقطة قطع” (cutoff point). عادةً ما تكون نقطة القطع هذه 0.5. دعنا نستخدم مثال تشخيص السرطان من صورتنا السابقة لرؤية هذا المبدأ عملياً. إذا كان نموذج الانحدار اللوجستي ينتج قيمة أقل من 0.5، فسيتم تصنيف نقطة البيانات على أنها ورم غير خبيث. وبالمثل، إذا كانت دالة سيغمويد تنتج قيمة أعلى من 0.5، فسيتم تصنيف الورم على أنه خبيث.
استخدام مصفوفة الارتباك (Confusion Matrix) لقياس أداء الانحدار اللوجستي
يمكن استخدام مصفوفة الارتباك (confusion matrix) كأداة لمقارنة الإيجابيات الحقيقية (true positives)، والسلبيات الحقيقية (true negatives)، والإيجابيات الخاطئة (false positives)، والسلبيات الخاطئة (false negatives) في تعلم الآلة. تعد مصفوفات الارتباك مفيدة بشكل خاص عند استخدامها لقياس أداء نماذج الانحدار اللوجستي. إليك مثال على كيفية استخدامنا لمصفوفة الارتباك:
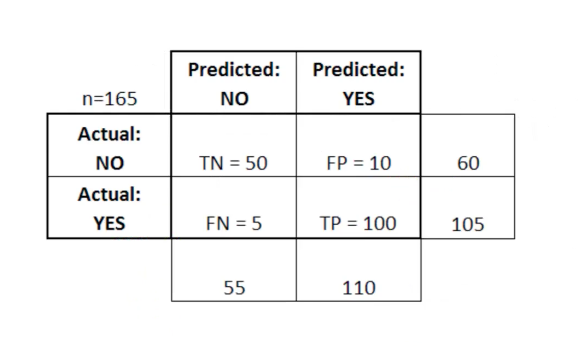
في هذا الرسم البياني، يرمز TN إلى “السلبي الحقيقي” (True Negative) ويرمز FN إلى “السلبي الخاطئ” (False Negative). يرمز FP إلى “الإيجابي الخاطئ” (False Positive) ويرمز TP إلى “الإيجابي الحقيقي” (True Positive).
تعد مصفوفة الارتباك مفيدة لتقييم ما إذا كان نموذجك ضعيفاً بشكل خاص في ربع معين من مصفوفة الارتباك. على سبيل المثال، قد يحتوي على عدد مرتفع بشكل غير طبيعي من الإيجابيات الخاطئة. يمكن أن يكون مفيداً أيضاً في تطبيقات معينة، للتأكد من أن نموذجك يعمل بشكل جيد في منطقة خطرة بشكل خاص من مصفوفة الارتباك. في مثال السرطان هذا، على سبيل المثال، سترغب في التأكد تماماً من أن نموذجك لا يحتوي على معدل مرتفع جداً من السلبيات الخاطئة، حيث يشير هذا إلى أن شخصاً ما لديه ورم خبيث صنفته بشكل غير صحيح على أنه غير خبيث.
ملخص القسم
في هذا القسم، تعرفت على نماذج تعلم الآلة للانحدار اللوجستي. إليك ملخص موجز لما تعلمته حول الانحدار اللوجستي:
- أنواع مشكلات التصنيف المناسبة للحل باستخدام نماذج الانحدار اللوجستي.
- أن الدالة اللوجستية (تسمى أيضاً دالة سيغمويد) تنتج دائماً قيمة تتراوح بين
0و1. - كيفية استخدام نقاط القطع لإجراء التنبؤات باستخدام نموذج تعلم الآلة للانحدار اللوجستي.
- لماذا تعد مصفوفات الارتباك مفيدة لقياس أداء نماذج الانحدار اللوجستي.
خوارزمية الجيران الأقرب (K-Nearest Neighbors – K-NN)
يمكن لخوارزمية الجيران الأقرب (K-Nearest Neighbors)، أو K-NN اختصاراً، أن تساعدك في حل مشكلات التصنيف التي تحتوي على أكثر من فئتين.
ما هي خوارزمية الجيران الأقرب؟
خوارزمية الجيران الأقرب هي خوارزمية تصنيف (classification algorithm) تستند إلى مبدأ بسيط. في الواقع، المبدأ بسيط جداً لدرجة أنه يُفهم بشكل أفضل من خلال مثال. تخيل أن لديك بيانات عن طول ووزن لاعبي كرة القدم وكرة السلة. يمكن استخدام خوارزمية K-NN للتنبؤ بما إذا كان رياضي جديد هو لاعب كرة قدم أو لاعب كرة سلة.
للقيام بذلك، تحدد خوارزمية K-NN نقاط البيانات K الأقرب للملاحظة الجديدة. توضح الصورة التالية هذا المفهوم، بقيمة K تساوي 3:
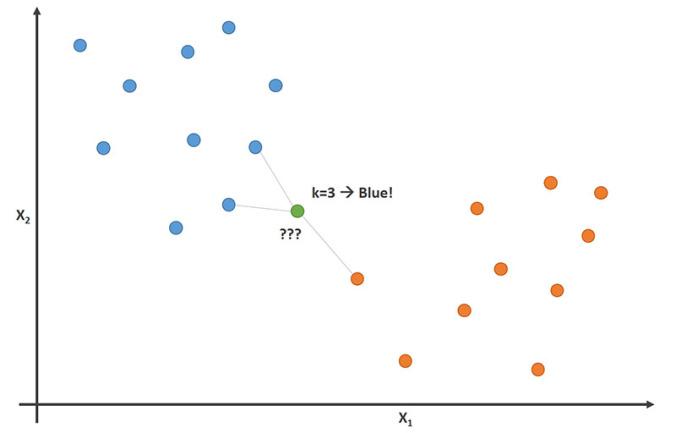
في هذه الصورة، تم تصنيف لاعبي كرة القدم كنقاط بيانات زرقاء، ولاعبي كرة السلة كنقاط برتقالية. نقطة البيانات التي نحاول تصنيفها مصنفة باللون الأخضر. نظراً لأن غالبية (2 من 3) نقاط البيانات الأقرب للنقطة الجديدة هي لاعبو كرة قدم زرقاء، فإن خوارزمية K-NN ستتنبأ بأن نقطة البيانات الجديدة هي أيضاً لاعب كرة قدم.
خطوات بناء خوارزمية الجيران الأقرب
الخطوات العامة لبناء خوارزمية K-NN هي:
- تخزين جميع البيانات.
- حساب المسافة الإقليدية (
Euclidean distance) من نقطة البيانات الجديدةxإلى جميع النقاط الأخرى في مجموعة البيانات. - فرز النقاط في مجموعة البيانات بترتيب المسافة المتزايدة من
x. - التنبؤ باستخدام نفس الفئة التي تنتمي إليها غالبية نقاط البيانات
Kالأقرب إلىx.
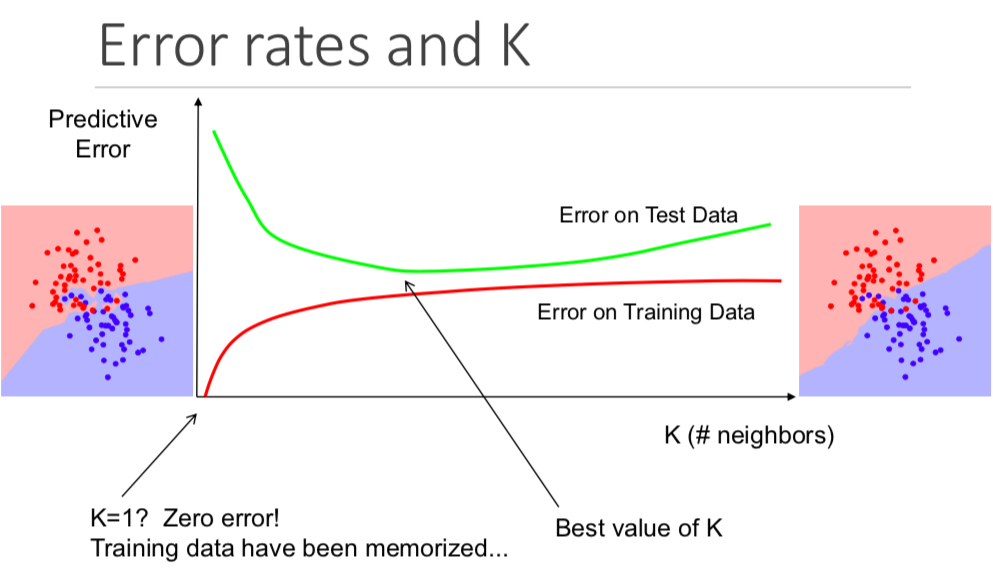
أهمية قيمة K في خوارزمية الجيران الأقرب
على الرغم من أنه قد لا يكون واضحاً من البداية، فإن تغيير قيمة K في خوارزمية K-NN سيغير الفئة التي يتم تعيين نقطة جديدة إليها. بشكل أكثر تحديداً، ستؤدي قيمة K المنخفضة جداً إلى تنبؤ نموذجك ببيانات التدريب الخاصة بك بشكل مثالي وتنبؤه ببيانات الاختبار بشكل سيء. وبالمثل، فإن قيمة K المرتفعة جداً ستجعل نموذجك معقداً بشكل غير ضروري. يوضح التصور التالي هذا بشكل ممتاز:
إيجابيات وسلبيات خوارزمية الجيران الأقرب
لإنهاء هذا التقديم لخوارزمية K-NN، أود أن أناقش بإيجاز بعض الإيجابيات والسلبيات لاستخدام هذا النموذج. إليك بعض المزايا الرئيسية لخوارزمية K-NN:
- الخوارزمية بسيطة وسهلة الفهم.
- من السهل تدريب النموذج على بيانات تدريب جديدة.
- تعمل مع أي عدد من الفئات في مشكلة التصنيف.
- من السهل إضافة المزيد من البيانات إلى مجموعة البيانات.
- يقبل النموذج معلمتين فقط:
Kومقياس المسافة الذي ترغب في استخدامه (عادةً المسافة الإقليديةEuclidean distance).
وبالمثل، إليك بعض العيوب الرئيسية للخوارزمية:
- هناك تكلفة حسابية عالية لإجراء التنبؤات، حيث تحتاج إلى فرز مجموعة البيانات بأكملها.
- لا تعمل بشكل جيد مع الميزات الفئوية (
categorical features).
ملخص القسم
إليك ملخص موجز لما تعلمته للتو حول خوارزمية K-NN:
- مثال على مشكلة تصنيف (لاعبي كرة القدم مقابل لاعبي كرة السلة) يمكن لخوارزمية
K-NNحلها. - كيف تستخدم خوارزمية
K-NNالمسافة الإقليدية لنقاط البيانات المجاورة للتنبؤ بالفئة التي تنتمي إليها نقطة بيانات جديدة. - لماذا تعد قيمة
Kمهمة لإجراء التنبؤات. - إيجابيات وسلبيات استخدام خوارزمية
K-NN.
أشجار القرار (Decision Trees) والغابات العشوائية (Random Forests)
تُعد أشجار القرار (Decision Trees) والغابات العشوائية (Random Forests) أمثلة على “أساليب الشجرة” (tree methods). وبشكل أكثر تحديداً، أشجار القرار هي نماذج تعلم آلة تُستخدم لإجراء التنبؤات من خلال المرور بكل ميزة (feature) في مجموعة البيانات، واحدة تلو الأخرى. أما الغابات العشوائية فهي تجمعات (ensembles) من أشجار القرار التي تستخدم ترتيبات عشوائية للميزات في مجموعات البيانات.
ما هي أساليب الشجرة؟
قبل أن نتعمق في الأسس النظرية لأساليب الشجرة في تعلم الآلة، من المفيد أن نبدأ بمثال. تخيل أنك تلعب كرة السلة كل يوم اثنين، وتدعو صديقاً لك دائماً للمجيء واللعب معك. أحياناً يأتي الصديق، وأحياناً لا يأتي. يعتمد قرار الحضور أو عدم الحضور على عوامل متعددة، مثل الطقس ودرجة الحرارة والرياح والإرهاق. تبدأ في ملاحظة هذه الميزات وتتبعها جنباً إلى جنب مع قرار صديقك باللعب أو عدم اللعب. يمكنك استخدام هذه البيانات للتنبؤ بما إذا كان صديقك سيحضر للعب كرة السلة أم لا. إحدى التقنيات التي يمكنك استخدامها هي شجرة القرار. إليك كيف ستبدو شجرة القرار هذه:
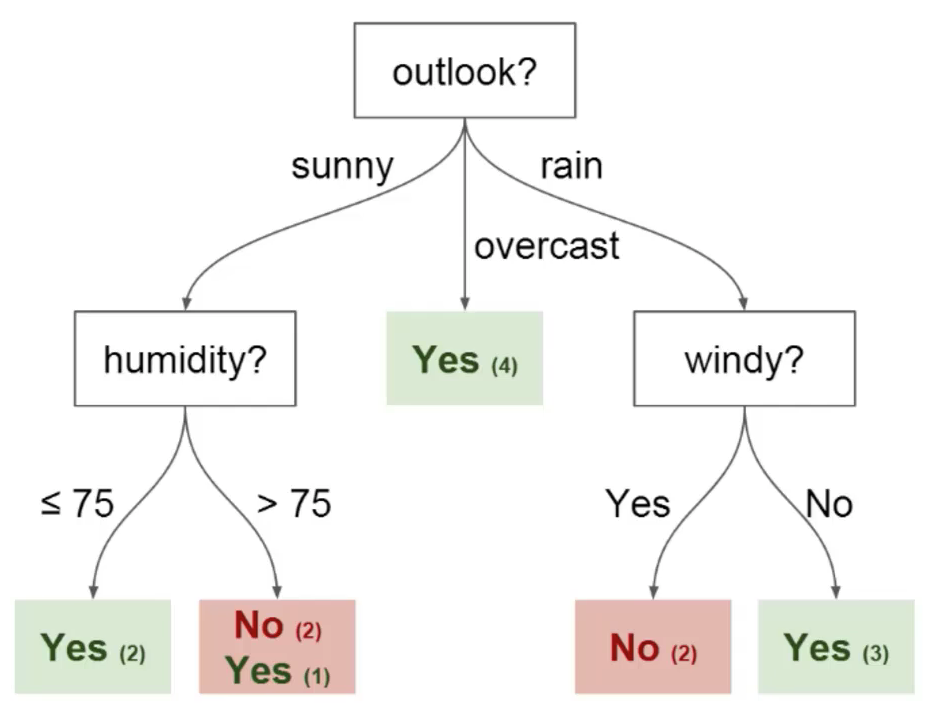
تحتوي كل شجرة قرار على نوعين من العناصر:
- العُقد (
Nodes): المواقع التي تتفرع فيها الشجرة وفقاً لقيمة سمة معينة. - الحواف (
Edges): نتيجة التفرع إلى العقدة التالية.
يمكنك أن ترى في الصورة أعلاه أن هناك عُقداً لـ outlook و humidity و windy. وهناك حافة لكل قيمة محتملة لكل من هذه السمات. إليك مصطلحان آخران لشجرة القرار يجب أن تفهمهما قبل المتابعة:
- الجذر (
Root): العقدة التي تقوم بالانقسام الأول. - الأوراق (
Leaves): العقد الطرفية التي تتنبأ بالنتيجة النهائية.
لديك الآن فهم أساسي لماهية أشجار القرار. سنتعلم كيفية بناء أشجار القرار من الصفر في القسم التالي.
كيفية بناء أشجار القرار من الصفر
بناء أشجار القرار أصعب مما تتخيل. هذا لأن تحديد الميزات التي ستقسم بياناتك عليها (وهو موضوع ينتمي إلى مجالات الإنتروبيا (Entropy) ومكاسب المعلومات (Information Gain)) يمثل مشكلة معقدة رياضياً. لمعالجة هذا، يستخدم ممارسو تعلم الآلة عادةً العديد من أشجار القرار باستخدام عينة عشوائية من الميزات المختارة كتقسيم. بعبارة أخرى، يتم اختيار عينة عشوائية جديدة من الميزات لكل شجرة فردية عند كل تقسيم. تسمى هذه التقنية “الغابات العشوائية” (random forests).
بشكل عام، يختار الممارسون عادةً حجم العينة العشوائية للميزات (المشار إليها بـ m) ليكون الجذر التربيعي لعدد الميزات الكلي في مجموعة البيانات (المشار إليها بـ p). باختصار، m هو الجذر التربيعي لـ p، ثم يتم اختيار ميزة معينة عشوائياً من m. إذا لم يكن هذا منطقياً تماماً الآن، فلا تقلق، سيصبح الأمر أكثر وضوحاً عندما تقوم ببناء أول نموذج غابة عشوائية لك.
فوائد استخدام الغابات العشوائية
تخيل أنك تعمل مع مجموعة بيانات تحتوي على ميزة قوية جداً. بعبارة أخرى، تحتوي مجموعة البيانات على ميزة واحدة أكثر تنبؤاً بالنتيجة النهائية من الميزات الأخرى في مجموعة البيانات. إذا كنت تبني أشجار القرار يدوياً، فمن المنطقي استخدام هذه الميزة كتقسيم علوي لشجرة القرار. هذا يعني أنك ستحصل على أشجار متعددة تكون تنبؤاتها مترابطة للغاية. نريد تجنب هذا لأن أخذ متوسط المتغيرات المترابطة للغاية لا يقلل التباين بشكل كبير.
من خلال اختيار الميزات عشوائياً لكل شجرة في الغابة العشوائية، تصبح الأشجار غير مترابطة، ويتم تقليل تباين النموذج الناتج. هذا “فك الارتباط” (decorrelation) هو الميزة الرئيسية لاستخدام الغابات العشوائية على أشجار القرار المصنوعة يدوياً.
ملخص القسم
إليك ملخص موجز لما تعلمته حول أشجار القرار والغابات العشوائية في هذا المقال:
- مثال على مشكلة يمكن التنبؤ بها باستخدام أشجار القرار.
- عناصر شجرة القرار: العُقد (
nodes)، الحواف (edges)، الجذور (roots)، والأوراق (leaves). - كيف يسمح لنا أخذ عينات عشوائية من ميزات شجرة القرار ببناء غابة عشوائية.
- لماذا يمكن أن يكون استخدام الغابات العشوائية لفك ارتباط المتغيرات مفيداً لتقليل تباين نموذجك النهائي.
آلات المتجهات الداعمة (Support Vector Machines – SVM)
آلات المتجهات الداعمة (Support Vector Machines)، أو SVM اختصاراً، هي خوارزميات تصنيف (classification algorithms) (على الرغم من أنه، من الناحية الفنية، يمكن استخدامها أيضاً لحل مشكلات الانحدار regression problems) التي تقسم مجموعة البيانات إلى فئات بناءً على قطع أوسع فجوة بين الفئات. سيتضح هذا المفهوم بشكل أكبر من خلال الرسوم التوضيحية بعد قليل.
ما هي آلات المتجهات الداعمة؟
آلات المتجهات الداعمة – أو SVMs باختصار – هي نماذج تعلم آلة خاضعة للإشراف (supervised machine learning models) مع خوارزميات تعلم مرتبطة تحلل البيانات وتتعرف على الأنماط. يمكن استخدام آلات المتجهات الداعمة لكل من مشكلات التصنيف ومشكلات الانحدار. في هذا المقال، سنركز تحديداً على استخدام آلات المتجهات الداعمة لحل مشكلات التصنيف.
كيف تعمل آلات المتجهات الداعمة؟
دعنا نتعمق في كيفية عمل آلات المتجهات الداعمة بالفعل. بالنظر إلى مجموعة من أمثلة التدريب – كل منها معلمة للانتماء إلى إحدى فئتين – تقوم خوارزمية تدريب آلة المتجهات الداعمة ببناء نموذج. يخصص هذا النموذج أمثلة جديدة لإحدى الفئتين. هذا يجعل آلة المتجهات الداعمة مصنفاً خطياً ثنائياً غير احتمالي (non-probabilistic binary linear classifier).
تستخدم SVM الهندسة لإجراء تنبؤات فئوية. بشكل أكثر تحديداً، يقوم نموذج SVM بتعيين نقاط البيانات كنقاط في الفضاء ويقسم الفئات المنفصلة بحيث يتم تقسيمها بواسطة فجوة مفتوحة واسعة قدر الإمكان. يتم التنبؤ بانتماء نقاط البيانات الجديدة إلى فئة بناءً على أي جانب من الفجوة تنتمي إليه. إليك مثال توضيحي يمكن أن يساعدك على فهم الحدس وراء آلات المتجهات الداعمة:

كما ترى، إذا سقطت نقطة بيانات جديدة على الجانب الأيسر من الخط الأخضر، فسيتم تصنيفها بالفئة الحمراء. وبالمثل، إذا سقطت نقطة بيانات جديدة على الجانب الأيمن من الخط الأخضر، فسيتم تصنيفها على أنها تنتمي إلى الفئة الزرقاء. يسمى هذا الخط الأخضر “المستوى الفائق” (hyperplane)، وهو مصطلح مهم لخوارزميات آلة المتجهات الداعمة. دعنا نلقي نظرة على تمثيل مرئي مختلف لآلة المتجهات الداعمة:

في هذا الرسم البياني، تم تصنيف المستوى الفائق على أنه “المستوى الفائق الأمثل” (optimal hyperplane). تحدد نظرية آلة المتجهات الداعمة المستوى الفائق الأمثل على أنه الذي يزيد الهامش (margin) بين أقرب نقاط البيانات من كل فئة إلى أقصى حد. كما ترى، يلامس خط الهامش بالفعل ثلاث نقاط بيانات – اثنتين من الفئة الحمراء وواحدة من الفئة الزرقاء. تسمى نقاط البيانات هذه التي تلامس خطوط الهامش “المتجهات الداعمة” (support vectors)، ومن هنا جاء اسم آلات المتجهات الداعمة.
ملخص القسم
إليك ملخص موجز لما تعلمته للتو حول آلات المتجهات الداعمة:
- أن آلات المتجهات الداعمة هي مثال على خوارزمية تعلم آلة خاضعة للإشراف.
- أنه يمكن استخدام آلات المتجهات الداعمة لحل كل من مشكلات التصنيف والانحدار.
- كيف تصنف آلات المتجهات الداعمة نقاط البيانات باستخدام مستوى فائق يزيد الهامش بين الفئات في مجموعة البيانات إلى أقصى حد.
- أن نقاط البيانات التي تلامس خطوط الهامش في آلة المتجهات الداعمة تسمى “المتجهات الداعمة”. ومن نقاط البيانات هذه تستمد آلات المتجهات الداعمة اسمها.
تجميع K-Means (K-Means Clustering)
تجميع K-Means هو خوارزمية تعلم آلة تسمح لك بتحديد شرائح من البيانات المتشابهة داخل مجموعة بيانات.
ما هو تجميع K-Means؟
تجميع K-Means هو خوارزمية تعلم آلة غير خاضعة للإشراف (unsupervised machine learning algorithm). هذا يعني أنها تستقبل بيانات غير معلمة (unlabelled data) وستحاول تجميع مجموعات متشابهة من الملاحظات معاً داخل بياناتك. تعد خوارزميات تجميع K-Means مفيدة للغاية لحل مشكلات العالم الحقيقي. إليك بعض حالات الاستخدام لهذا النموذج من تعلم الآلة:
- تجزئة العملاء لفرق التسويق.
- تصنيف المستندات.
- تحسين مسار التسليم للشركات مثل أمازون (
Amazon) ويو بي إس (UPS) أو فيديكس (FedEx). - تحديد مراكز الجريمة داخل المدينة والتفاعل معها.
- تحليلات الرياضات الاحترافية.
- التنبؤ بالجريمة الإلكترونية ومنعها.
الهدف الأساسي لخوارزمية تجميع K-Means هو تقسيم مجموعة البيانات إلى مجموعات متميزة بحيث تكون الملاحظات داخل كل مجموعة متشابهة مع بعضها البعض. إليك تمثيل مرئي لما يبدو عليه هذا عملياً:
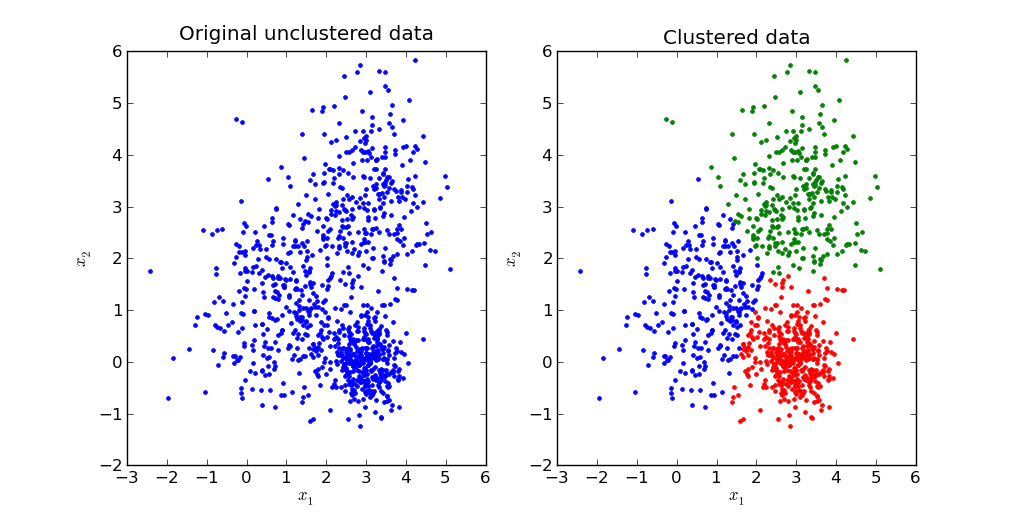
سنستكشف الرياضيات الكامنة وراء تجميع K-Means في القسم التالي من هذا الشرح.
كيف تعمل خوارزميات تجميع K-Means؟
الخطوة الأولى في تشغيل خوارزمية تجميع K-Means هي تحديد عدد المجموعات (clusters) التي ترغب في تقسيم بياناتك إليها. هذا العدد من المجموعات هو قيمة K المشار إليها في اسم الخوارزمية. يعد اختيار قيمة K ضمن خوارزمية تجميع K-Means خياراً مهماً. سنتحدث أكثر عن كيفية اختيار قيمة K مناسبة لاحقاً في هذا المقال.
بعد ذلك، يجب عليك تعيين كل نقطة في مجموعة البيانات الخاصة بك عشوائياً إلى مجموعة عشوائية. يعطي هذا تعييننا الأولي الذي تقوم بعد ذلك بتشغيل التكرار التالي عليه حتى تتوقف المجموعات عن التغيير:
- حساب مركز كل مجموعة (
centroid) عن طريق أخذ متوسط متجه النقاط داخل تلك المجموعة. - إعادة تعيين كل نقطة بيانات إلى المجموعة التي تحتوي على أقرب مركز.
إليك رسم متحرك لكيفية عمل هذا عملياً لخوارزمية تجميع K-Means بقيمة K تساوي 3. يمكنك رؤية مركز كل مجموعة ممثلاً بحرف + أسود.
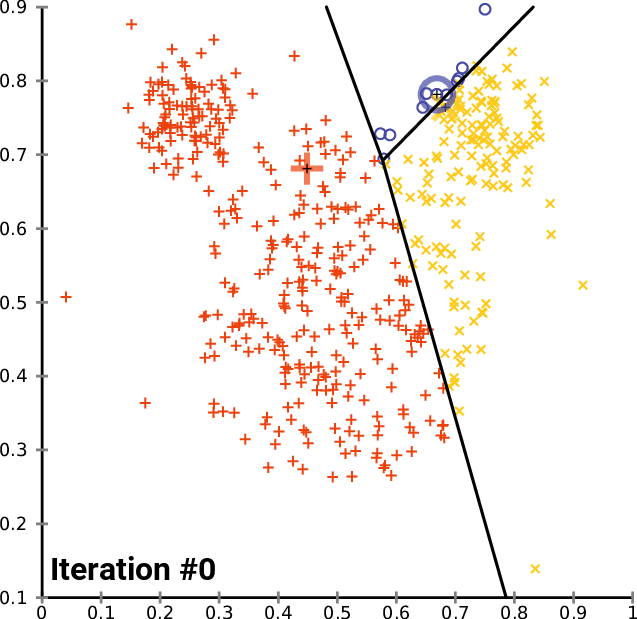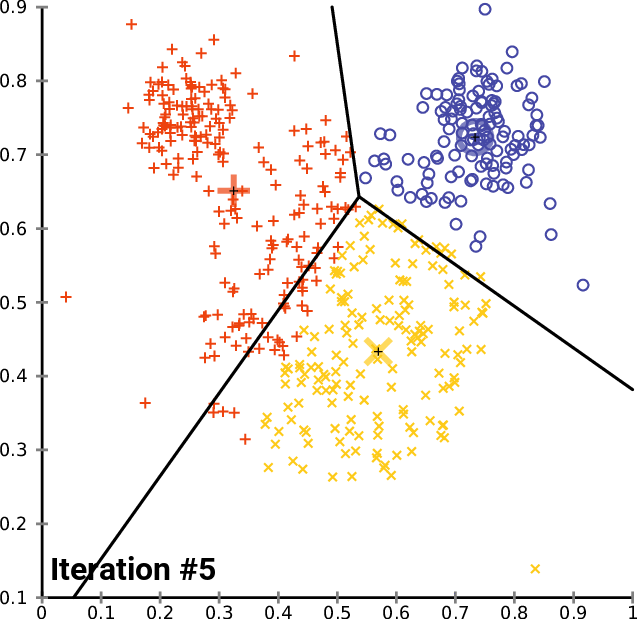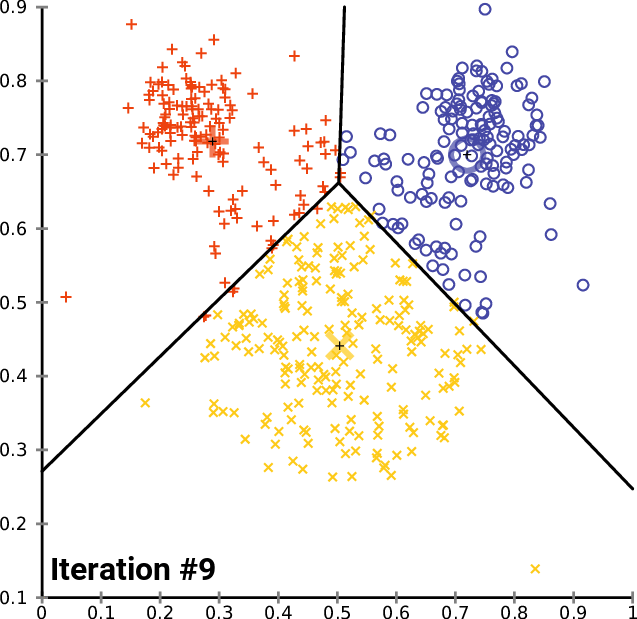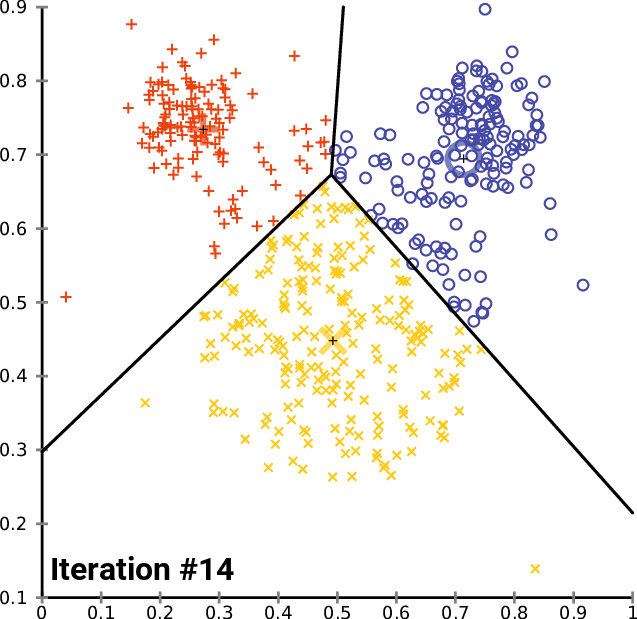
كما ترى، يستمر هذا التكرار حتى تتوقف المجموعات عن التغيير – مما يعني أنه لم تعد نقاط البيانات تُعيّن إلى مجموعات جديدة.
اختيار قيمة K المناسبة لخوارزميات تجميع K-Means
يعد اختيار قيمة K مناسبة لخوارزمية تجميع K-Means أمراً صعباً للغاية في الواقع. لا توجد إجابة “صحيحة” لاختيار أفضل قيمة K. إحدى الطرق التي يستخدمها ممارسو تعلم الآلة غالباً تسمى “طريقة الكوع” (elbow method).
لاستخدام طريقة الكوع، أول شيء تحتاج إلى القيام به هو حساب مجموع الأخطاء المربعة (sum of squared errors - SSE) لخوارزمية تجميع K-Means الخاصة بك لمجموعة من قيم K. يتم تعريف SSE في خوارزمية تجميع K-Means على أنها مجموع المسافة المربعة بين كل نقطة بيانات في مجموعة ومركز تلك المجموعة. كمثال على هذه الخطوة، قد تحسب SSE لقيم K التالية: 2، 4، 6، 8، و 10.
بعد ذلك، ستحتاج إلى إنشاء رسم بياني لـ SSE مقابل قيم K المختلفة هذه. سترى أن الخطأ يتناقص مع زيادة قيمة K. هذا منطقي – فكلما زاد عدد الفئات التي تنشئها داخل مجموعة البيانات، زاد احتمال أن تكون كل نقطة بيانات قريبة من مركز مجموعتها المحددة.
مع ذلك، فإن الفكرة وراء طريقة الكوع هي اختيار قيمة K التي يتباطأ عندها معدل انخفاض SSE فجأة. ينتج عن هذا الانخفاض المفاجئ “كوعاً” (elbow) في الرسم البياني. كمثال، إليك رسم بياني لـ SSE مقابل K. في هذه الحالة، ستقترح طريقة الكوع استخدام قيمة K تبلغ حوالي 6.
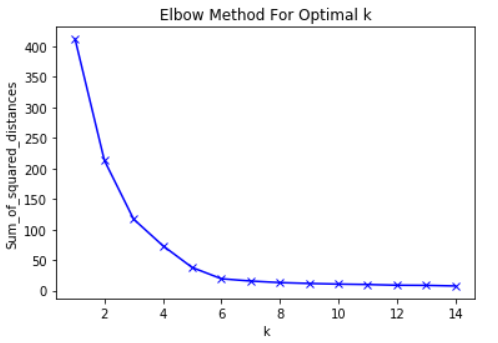
الأهم من ذلك، أن 6 هو مجرد تقدير لقيمة جيدة لـ K لاستخدامها. لا توجد أبداً قيمة K “مثلى” في خوارزمية تجميع K-Means. كما هو الحال مع العديد من الأشياء في مجال تعلم الآلة، هذا قرار يعتمد بشكل كبير على الموقف.
ملخص القسم
إليك ملخص موجز لما تعلمته في هذا المقال:
- أمثلة على مشكلات تعلم الآلة غير الخاضعة للإشراف التي تستطيع خوارزمية تجميع
K-Meansحلها. - المبادئ الأساسية لماهية خوارزمية تجميع
K-Means. - كيف تعمل خوارزمية تجميع
K-Means. - كيفية استخدام طريقة الكوع لتحديد قيمة
Kمناسبة في نموذج تجميعK-Means.
تحليل المكونات الرئيسية (Principal Component Analysis – PCA)
يُستخدم تحليل المكونات الرئيسية (Principal Component Analysis)، أو PCA اختصاراً، لتحويل مجموعة بيانات ذات ميزات متعددة إلى مجموعة بيانات محولة ذات ميزات أقل، حيث تكون كل ميزة جديدة عبارة عن تركيبة خطية (linear combination) من الميزات الموجودة مسبقاً. تهدف مجموعة البيانات المحولة هذه إلى شرح معظم تباين (variance) مجموعة البيانات الأصلية بتبسيط أكبر بكثير.
ما هو تحليل المكونات الرئيسية؟
تحليل المكونات الرئيسية هو تقنية تعلم آلة تُستخدم لدراسة العلاقات المتبادلة بين مجموعات المتغيرات. بعبارة أخرى، يدرس تحليل المكونات الرئيسية مجموعات المتغيرات لتحديد الهيكل الأساسي لتلك المتغيرات. يُطلق على تحليل المكونات الرئيسية أحياناً اسم “تحليل العوامل” (factor analysis).
بناءً على هذا الوصف، قد تعتقد أن تحليل المكونات الرئيسية يشبه إلى حد كبير الانحدار الخطي (linear regression). لكن هذا ليس هو الحال؛ في الواقع، هاتان التقنيتان لهما بعض الاختلافات المهمة.
الاختلافات بين الانحدار الخطي وتحليل المكونات الرئيسية
يحدد الانحدار الخطي خطاً أفضل ملاءمة عبر مجموعة بيانات. بينما يحدد تحليل المكونات الرئيسية عدة خطوط متعامدة (orthogonal) لأفضل ملاءمة لمجموعة البيانات. إذا لم تكن على دراية بمصطلح “متعامد” (orthogonal)، فهذا يعني ببساطة أن الخطوط تكون بزوايا قائمة (90 درجة) لبعضها البعض – مثل الشمال والشرق والجنوب والغرب على الخريطة. دعنا نأخذ مثالاً لمساعدتك على فهم هذا بشكل أفضل:
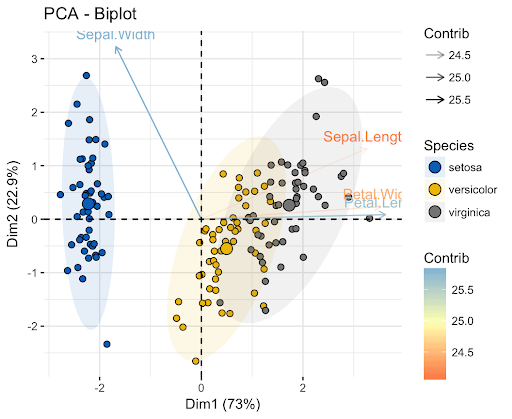
ألقِ نظرة على تسميات المحاور في هذه الصورة. في هذه الصورة، يفسر المكون الرئيسي للمحور x حوالي 73% من التباين في مجموعة البيانات. ويفسر المكون الرئيسي للمحور y حوالي 23% من التباين في مجموعة البيانات. هذا يعني أن 4% من التباين في مجموعة البيانات يظل غير مفسر. يمكنك تقليل هذا العدد بشكل أكبر عن طريق إضافة المزيد من المكونات الرئيسية إلى تحليلك.
ملخص القسم
إليك ملخص موجز لما تعلمته حول تحليل المكونات الرئيسية في هذا الشرح:
- أن تحليل المكونات الرئيسية يحاول العثور على عوامل متعامدة تحدد التباين في مجموعة البيانات.
- الاختلافات بين تحليل المكونات الرئيسية والانحدار الخطي.
- كيف تبدو المكونات الرئيسية المتعامدة عند تصورها داخل مجموعة بيانات.
- أن إضافة المزيد من المكونات الرئيسية يمكن أن يساعدك على شرح المزيد من التباين في مجموعة البيانات.
الخلاصة التقنية
لقد استعرضنا في هذا المقال تسع خوارزميات أساسية في عالم تعلم الآلة، بدءاً من أنظمة التوصية التي تحاكي التفكير البشري في اقتراح المحتوى، مروراً بخوارزميات الانحدار الخطي واللوجستي التي تُعد اللبنات الأساسية للتنبؤ والتصنيف. كما تعمقنا في فهم K-Nearest Neighbors لتصنيف البيانات المتعددة الفئات، وأشجار القرار والغابات العشوائية التي تقدم رؤى قوية من خلال نماذجها الشجرية. لم نغفل أيضاً آلات المتجهات الداعمة (SVM) بقدرتها الفائقة على الفصل بين الفئات، وتجميع K-Means لتحديد الأنماط المخفية في البيانات غير المصنفة، وأخيراً تحليل المكونات الرئيسية (PCA) لتبسيط البيانات المعقدة مع الحفاظ على جوهرها.
إن إتقان هذه الخوارزميات لا يفتح الأبواب أمام فهم أعمق للذكاء الاصطناعي فحسب، بل يمنح المطورين والباحثين القدرة على بناء حلول مبتكرة لمشكلات العالم الحقيقي، من تخصيص تجارب المستخدم إلى تحسين العمليات المعقدة. يظل الاختيار الأمثل للخوارزمية يعتمد على طبيعة المشكلة والبيانات المتاحة، مما يؤكد على أهمية الفهم النظري والعملي لكل منها.