كيفية إنشاء جداول بيانات إكسل محدثة تلقائياً لبيانات سوق الأسهم باستخدام بايثون، AWS، و IEX Cloud

يواجه العديد من مطوري بايثون في القطاع المالي مهمة إنشاء مستندات إكسل لتحليلها من قبل مستخدمين غير تقنيين. قد تبدو هذه المهمة بسيطة، لكنها في الواقع أكثر تعقيداً مما تبدو عليه. فمن الحصول على البيانات وتنسيق جدول البيانات وصولاً إلى نشر المستند النهائي في موقع مركزي، تتضمن العملية العديد من الخطوات.
في هذا الدليل الشامل، سأوضح لك كيفية إنشاء جداول بيانات إكسل باستخدام بايثون تتميز بالآتي:
- تستخدم بيانات سوق الأسهم من
IEX Cloud. - يتم نشرها في
S3 bucketمركزي، مما يتيح لأي شخص لديه الرابط الصحيح الوصول إليها. - تُحدّث تلقائياً يومياً باستخدام أداة سطر الأوامر
cron.
الخطوة 1: إنشاء حساب في IEX Cloud
تُعد IEX Cloud شركة تابعة لمزود البيانات الخاص ببورصة IEX. إذا لم تكن على دراية بـ IEX، فهي اختصار لـ “The Investor’s Exchange” (بورصة المستثمرين). أسسها براد كاتسوياما بهدف بناء بورصة أسهم أفضل تتجنب السلوكيات غير الودية للمستثمرين مثل التداول المسبق (front-running) والتداول عالي التردد (high-frequency trading). وقد تم توثيق إنجازات كاتسوياما بشكل مشهور في كتاب مايكل لويس الأكثر مبيعاً Flash Boys.
لقد بحثت في العديد من مزودي البيانات المالية، ووجدت أن IEX Cloud يقدم أفضل مزيج من:
- بيانات عالية الجودة.
- أسعار معقولة.
فيما يلي نظرة على أسعارهم:
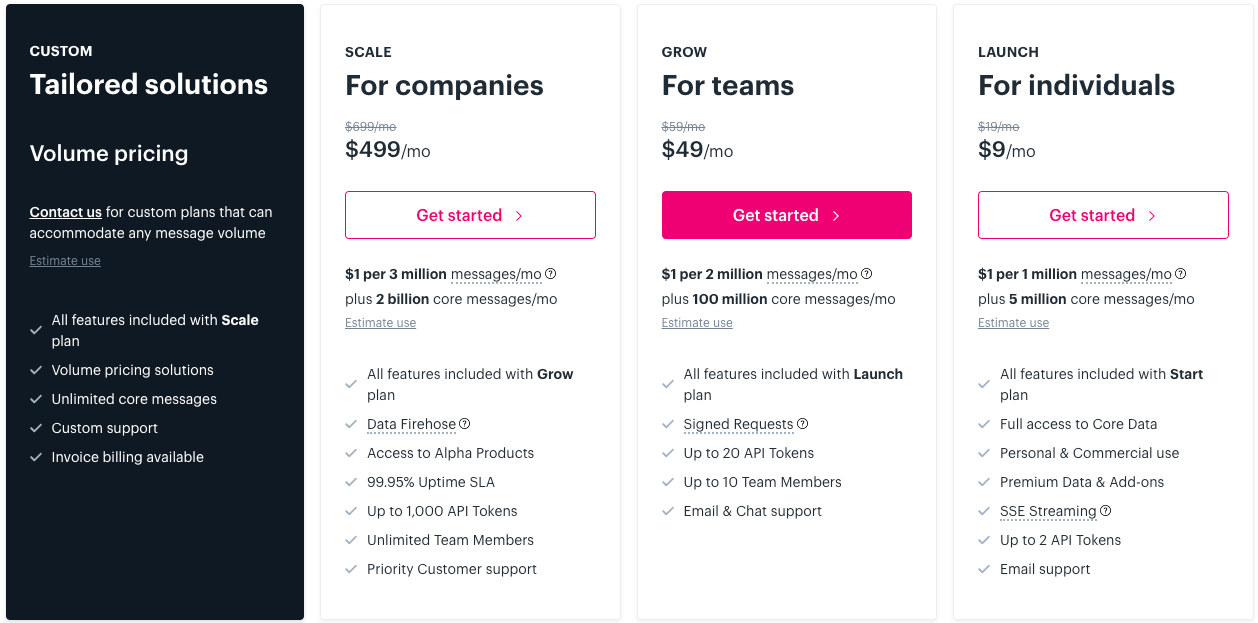
تُعد خطة Launch التي تبلغ تكلفتها 9 دولارات شهرياً كافية للعديد من حالات الاستخدام. ولكن، هناك تحذير مهم عند استخدام IEX Cloud (وأي مزود بيانات آخر يعتمد على الدفع حسب الاستخدام): من الضروري جداً تعيين ميزانيات الاستخدام منذ البداية. هذه الميزانيات تمنعك من الوصول إلى حسابك بمجرد تجاوز تكلفة محددة بالدولار لذلك الشهر.
عندما بدأت استخدام IEX Cloud لأول مرة، قمت عن طريق الخطأ بإنشاء حلقة لا نهائية بعد ظهر يوم جمعة تحتوي على استدعاء API إلى IEX Cloud. تُسعّر هذه الاستدعاءات على أساس التكلفة لكل استدعاء، مما أدى إلى تلقي بريد إلكتروني مخيف من IEX:

يُعد هذا دليلاً على تركيز IEX على العملاء، حيث وافقوا على إعادة تعيين استخدامي بشرط أن أقوم بتعيين ميزانيات استخدام للمستقبل. أحسنت يا IEX!
كما هو الحال مع معظم اشتراكات API، فإن الفائدة الرئيسية من إنشاء حساب IEX Cloud هي الحصول على مفتاح API. لأسباب واضحة، لن أشارك مفتاح API في هذه المقالة. ومع ذلك، لا يزال بإمكانك متابعة هذا الدليل باستخدام مفتاح API الخاص بك طالما قمت بتعيينه لاسم المتغير التالي:
IEX_API_Keyسترى المتغير الفارغ IEX_API_Key في كتل التعليمات البرمجية الخاصة بي طوال بقية هذا الدليل.
الخطوة 2: كتابة نص بايثون البرمجي
الآن بعد أن أصبح لديك وصول إلى مفتاح API الذي ستحتاجه لجمع البيانات المالية، حان الوقت لكتابة نص بايثون البرمجي الخاص بك. سيكون هذا القسم الأطول في هذا الدليل، وهو أيضاً الأكثر مرونة – سنقوم بإنشاء نص بايثون يلبي معايير محددة مسبقاً، ولكن يمكنك تعديل هذا القسم لإنشاء أي جدول بيانات تريده حقاً!
للبدء، دعنا نحدد أهدافنا. سنكتب نص بايثون برمجياً يقوم بإنشاء ملف إكسل لبيانات سوق الأسهم بالخصائص التالية:
- سيتضمن أكبر 10 أسهم في الولايات المتحدة.
- سيحتوي على أربعة أعمدة: رمز السهم (
stock ticker)، اسم الشركة (company name)، سعر السهم (share price)، وعائد الأرباح (dividend yield). - سيتم تنسيقه بحيث يكون لون خلفية الرأس
#135485والنص أبيض، بينما تكون خلفية جسم جدول البيانات#DADADAولون الخط أسود (الافتراضي).
دعنا نبدأ باستيراد أول حزمة لدينا. نظراً لأن جداول البيانات هي في الأساس هياكل بيانات تحتوي على صفوف وأعمدة، فإن مكتبة pandas – بما في ذلك كائن DataFrame المدمج فيها – هي المرشح المثالي لمعالجة البيانات في هذا الدليل. سنبدأ باستيراد pandas تحت الاسم المستعار pd هكذا:
import pandas as pdبعد ذلك، سنحدد مفتاح API الخاص بنا من IEX Cloud. كما ذكرت سابقاً، لن أقوم بتضمين مفتاح API الخاص بي، لذا سيتعين عليك الحصول على مفتاح API الخاص بك من حساب IEX الخاص بك وتضمينه هنا:
IEX_API_Key = ''خطوتنا التالية هي تحديد أكبر عشر شركات في الولايات المتحدة. يمكنك الإجابة على هذا السؤال ببحث سريع في جوجل. للاختصار، قمت بتضمين الشركات (أو بالأحرى، رموز أسهمها) في قائمة بايثون التالية:
tickers = [ 'MSFT' , 'AAPL' , 'AMZN' , 'GOOG' , 'FB' , 'BRK.B' , 'JNJ' , 'WMT' , 'V' , 'PG' ]بعد ذلك، حان الوقت لمعرفة كيفية استدعاء IEX Cloud API لسحب المقاييس التي نحتاجها لكل شركة. تُرجع IEX Cloud API كائنات JSON استجابة لطلبات HTTP. نظراً لأننا نعمل مع أكثر من رمز سهم واحد في هذا الدليل، فسنستخدم وظيفة استدعاء API الدفعية (batch API call) من IEX Cloud، والتي تتيح لك طلب البيانات لأكثر من رمز سهم واحد في المرة الواحدة. لاستخدام استدعاءات API الدفعية فائدتان:
- تقلل من عدد طلبات
HTTPالتي تحتاج إلى إجرائها، مما يجعل التعليمات البرمجية الخاصة بك أكثر كفاءة. - يكون تسعير استدعاءات
APIالدفعية أفضل قليلاً لدى معظم مزودي البيانات.
فيما يلي مثال على شكل طلب HTTP، مع بعض الكلمات النائبة حيث سنحتاج إلى تخصيص الطلب:
https://cloud.iexapis.com/stable/stock/market/batch?symbols=TICKERS&types=ENDPOINTS&range=RANGE&token=IEX_API_Keyفي هذا الرابط، سنستبدل هذه المتغيرات بالقيم التالية:
- سيتم استبدال
TICKERSبسلسلة نصية تحتوي على كل من رموز الأسهم الخاصة بنا مفصولة بفاصلة. - سيتم استبدال
ENDPOINTSبسلسلة نصية تحتوي على كل من نقاط نهايةIEX Cloudالتي نريد الوصول إليها، مفصولة بفاصلة. - سيتم استبدال
RANGEبـ1y. تحتوي نقاط النهاية هذه على بيانات نقطة زمنية وليست بيانات سلسلة زمنية، لذا يمكن أن يكون هذا النطاق أي شيء تريده.
دعنا نضع هذا الرابط في متغير يسمى HTTP_request لكي نقوم بتعديله لاحقاً:
HTTP_request = 'https://cloud.iexapis.com/stable/stock/market/batch?symbols=TICKERS&types=ENDPOINTS&range=RANGE&token=IEX_API_Key'دعنا نعمل على كل من هذه المتغيرات واحداً تلو الآخر لتحديد الرابط الدقيق الذي نحتاج إلى الوصول إليه. بالنسبة لمتغير TICKERS، يمكننا إنشاء متغير بايثون حقيقي (وليس مجرد كلمة نائبة) باستخدام حلقة for بسيطة:
#Create an empty string called `ticker_string` that we'll add tickers and commas to ticker_string = '' #Loop through every element of `tickers` and add them and a comma to ticker_string for ticker in tickers: ticker_string += ticker ticker_string += ',' #Drop the last comma from `ticker_string` ticker_string = ticker_string[: -1 ]الآن يمكننا دمج متغير ticker_string الخاص بنا في متغير HTTP_request الذي أنشأناه سابقاً باستخدام f-string:
HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types=ENDPOINTS&range=RANGE&token=IEX_API_Key'بعد ذلك، نحتاج إلى تحديد نقاط نهاية IEX Cloud التي نحتاج إلى استدعائها. يكشف تحقيق سريع في وثائق IEX Cloud أننا نحتاج فقط إلى نقطتي النهاية price و stats لإنشاء جدول البيانات الخاص بنا. وبالتالي، يمكننا استبدال الكلمة النائبة ENDPOINTS من طلب HTTP الأصلي بمتغير endpoints التالي:
endpoints = 'price,stats'كما فعلنا مع متغير ticker_string الخاص بنا، دعنا نستبدل متغير endpoints في متغير HTTP_request:
HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range=RANGE&token=IEX_API_Key'آخر عنصر نائب نحتاج إلى استبداله هو RANGE. لن نستبدله بمتغير. بدلاً من ذلك، يمكننا ترميز 1y مباشرة في مسار الرابط هكذا:
https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range=1y&token=IEX_API_Keyلقد أنجزنا الكثير حتى الآن، لذا دعنا نلخص قاعدة التعليمات البرمجية الخاصة بنا:
import pandas as pd IEX_API_Key = '' #Specify the stock tickers that will be included in our spreadsheet tickers = [ 'MSFT' , 'AAPL' , 'AMZN' , 'GOOG' , 'FB' , 'BRK.B' , 'JNJ' , 'WMT' , 'V' , 'PG' ] #Create an empty string called `ticker_string` that we'll add tickers and commas to ticker_string = '' #Loop through every element of `tickers` and add them and a comma to ticker_string for ticker in tickers: ticker_string += ticker ticker_string += ',' #Drop the last comma from `ticker_string` ticker_string = ticker_string[: -1 ] #Create the endpoint strings endpoints = 'price,stats' #Interpolate the endpoint strings into the HTTP_request string HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range=1y&token={IEX_API_Key}'لقد حان الوقت الآن لاستدعاء API وحفظ بياناتها في هيكل بيانات داخل تطبيق بايثون الخاص بنا. يمكننا قراءة كائنات JSON باستخدام دالة read_json من مكتبة pandas. في حالتنا، سنحفظ بيانات JSON في DataFrame من pandas يسمى raw_data، هكذا:
raw_data = pd.read_json(HTTP_request)دعنا نأخذ لحظة الآن للتأكد من أن البيانات قد تم استيرادها بتنسيق جيد لتطبيقنا. إذا كنت تعمل على هذا الدليل في Jupyter Notebook، يمكنك ببساطة كتابة اسم متغير pandas DataFrame في السطر الأخير من خلية التعليمات البرمجية، وسيقوم Jupyter بعرض صورة للبيانات بشكل جميل، هكذا:

كما ترى، يحتوي pandas DataFrame على عمود لكل رمز سهم وصفين: أحدهما لنقطة نهاية stats والآخر لنقطة نهاية price. سنحتاج إلى تحليل هذا DataFrame للحصول على المقاييس الأربعة التي نريدها. دعنا نعمل على المقاييس واحداً تلو الآخر في الخطوات أدناه.
المقياس 1: رمز السهم (Stock Ticker)
هذه الخطوة مباشرة جداً لأن رموز الأسهم موجودة في أعمدة pandas DataFrame. يمكننا الوصول إليها من خلال السمة columns الخاصة بـ pandas DataFrame هكذا:
raw_data.columnsللوصول إلى المقاييس الأخرى في raw_data، سننشئ حلقة for تمر عبر كل رمز سهم في raw_data.columns. في كل تكرار للحلقة، سنضيف البيانات إلى كائن pandas DataFrame جديد يسمى output_data. أولاً، سنحتاج إلى إنشاء output_data، والذي يجب أن يكون pandas DataFrame فارغاً بأربعة أعمدة. إليك كيفية القيام بذلك:
output_data = pd.DataFrame(pd.np.empty(( 0 , 4 )))ينشئ هذا pandas DataFrame فارغاً بـ 0 صف و 4 أعمدة. الآن بعد إنشاء هذا الكائن، إليك كيفية هيكلة حلقة for هذه:
for ticker in raw_data.columns: #Parse the company's name - not completed yet company_name = '' #Parse the company's stock price - not completed yet stock_price = 0 #Parse the company's dividend yield - not completed yet dividend_yield = 0 new_column = pd.Series([ticker, company_name, stock_price, dividend_yield]) output_data = output_data.append(new_column, ignore_index = True )بعد ذلك، دعنا نحدد كيفية تحليل متغير company_name من كائن raw_data.
المقياس 2: اسم الشركة (Company Name)
متغير company_name هو أول متغير سنحتاج إلى تحليله من كائن raw_data. كتذكير سريع، إليك كيف يبدو raw_data:

يتم الاحتفاظ بمتغير company_name ضمن نقطة نهاية stats تحت مفتاح القاموس companyName. لتحليل نقطة البيانات هذه من raw_data، يمكننا استخدام هذه الفهارس:
raw_data[ticker][ 'stats' ][ 'companyName' ]بما في ذلك هذا في حلقة for الخاصة بنا من قبل يعطينا هذا:
output_data = pd.DataFrame(pd.np.empty(( 0 , 4 ))) for ticker in raw_data.columns: #Parse the company's name - not completed yet company_name = raw_data[ticker][ 'stats' ][ 'companyName' ] #Parse the company's stock price - not completed yet stock_price = 0 #Parse the company's dividend yield - not completed yet dividend_yield = 0 new_column = pd.Series([ticker, company_name, stock_price, dividend_yield]) output_data = output_data.append(new_column, ignore_index = True )دعنا ننتقل إلى تحليل stock_price.
المقياس 3: سعر السهم (Stock Price)
يحتوي متغير stock_price ضمن نقطة نهاية price، والتي تُرجع قيمة واحدة فقط. هذا يعني أننا لا نحتاج إلى ربط الفهارس معاً كما فعلنا مع company_name. إليك كيفية تحليل stock_price من raw_data:
raw_data[ticker][ 'price' ]بما في ذلك هذا في حلقة for الخاصة بنا يعطينا:
output_data = pd.DataFrame(pd.np.empty(( 0 , 4 ))) for ticker in raw_data.columns: #Parse the company's name - not completed yet company_name = raw_data[ticker][ 'stats' ][ 'companyName' ] #Parse the company's stock price - not completed yet stock_price = raw_data[ticker][ 'price' ] #Parse the company's dividend yield - not completed yet dividend_yield = 0 new_column = pd.Series([ticker, company_name, stock_price, dividend_yield]) output_data = output_data.append(new_column, ignore_index = True )آخر مقياس نحتاج إلى تحليله هو dividend_yield.
المقياس 4: عائد الأرباح (Dividend Yield)
مثل company_name، يحتوي dividend_yield على نقطة نهاية stats. يتم الاحتفاظ به تحت مفتاح القاموس dividendYield. إليك كيفية تحليله من raw_data:
raw_data[ticker][ 'stats' ][ 'dividendYield' ]إضافة هذا إلى حلقة for الخاصة بنا يعطينا:
output_data = pd.DataFrame(pd.np.empty(( 0 , 4 ))) for ticker in raw_data.columns: #Parse the company's name - not completed yet company_name = raw_data[ticker][ 'stats' ][ 'companyName' ] #Parse the company's stock price - not completed yet stock_price = raw_data[ticker][ 'price' ] #Parse the company's dividend yield - not completed yet dividend_yield = raw_data[ticker][ 'stats' ][ 'dividendYield' ] new_column = pd.Series([ticker, company_name, stock_price, dividend_yield]) output_data = output_data.append(new_column, ignore_index = True )دعنا نطبع كائن output_data الخاص بنا لنرى كيف تبدو البيانات:
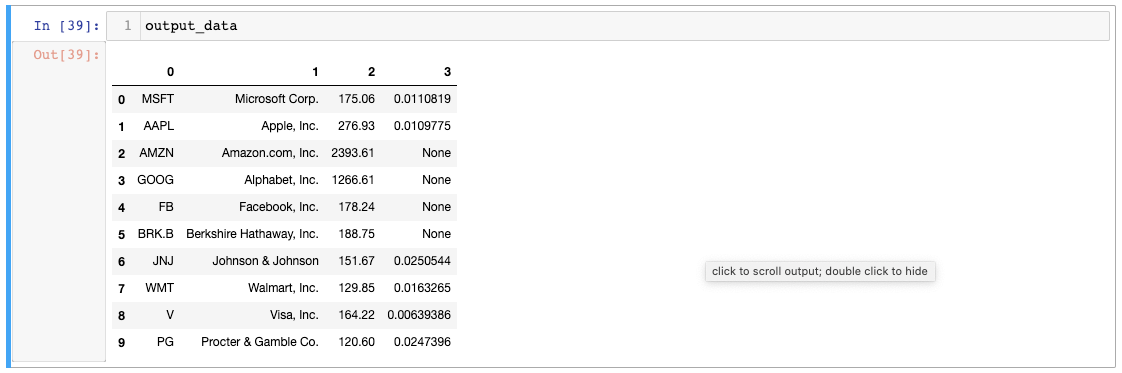
حتى الآن كل شيء جيد! الخطوتان التاليتان هما تسمية أعمدة pandas DataFrame وتغيير فهرسها.
كيفية تسمية أعمدة Pandas DataFrame
يمكننا تحديث أسماء أعمدة كائن output_data الخاص بنا عن طريق إنشاء قائمة بأسماء الأعمدة وتعيينها لسمة output_data.columns، هكذا:
output_data.columns = [ 'Ticker' , 'Company Name' , 'Stock Price' , 'Dividend Yield' ]دعنا نطبع كائن output_data الخاص بنا لنرى كيف تبدو البيانات:
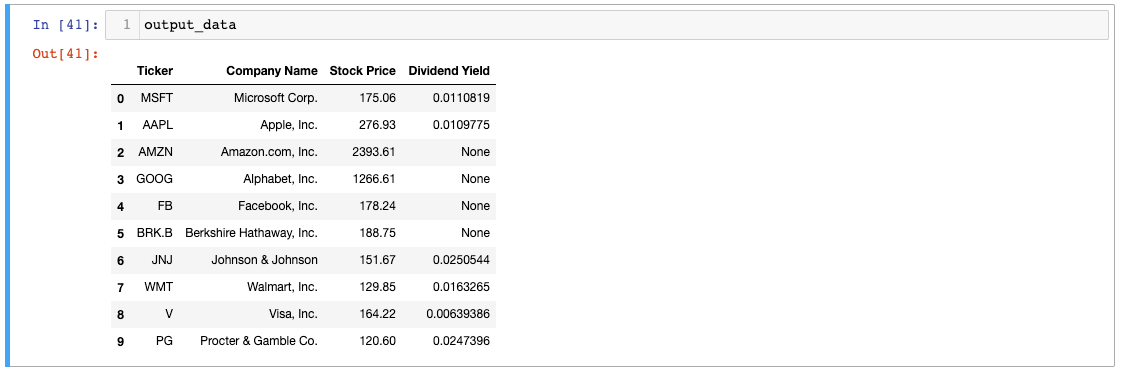
أفضل بكثير! دعنا نغير فهرس output_data بعد ذلك.
كيفية تغيير فهرس Pandas DataFrame
فهرس pandas DataFrame هو عمود خاص يشبه إلى حد ما المفتاح الأساسي لجدول قاعدة بيانات SQL. في كائن output_data الخاص بنا، نريد تعيين عمود Ticker كفهرس لـ DataFrame. إليك كيفية القيام بذلك باستخدام دالة set_index:
output_data.set_index( 'Ticker' , inplace= True )دعنا نطبع كائن output_data الخاص بنا لنرى كيف تبدو البيانات:
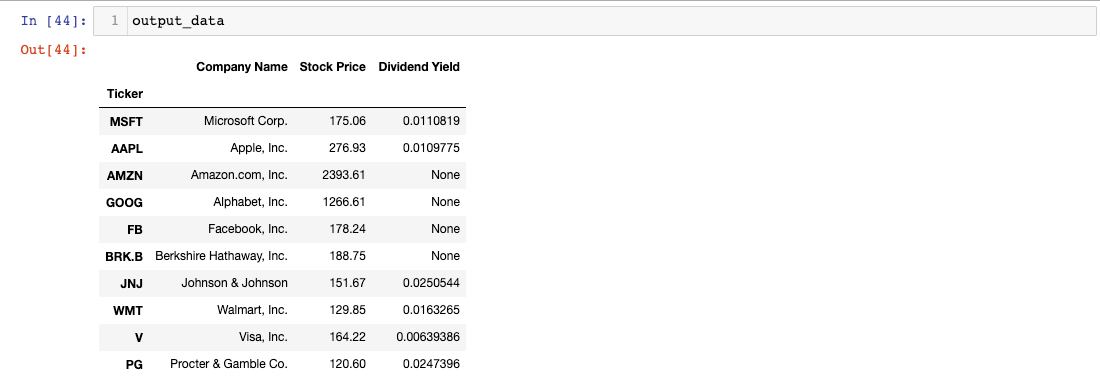
تحسن تدريجي آخر! بعد ذلك، دعنا نتعامل مع البيانات المفقودة في output_data.
كيفية التعامل مع البيانات المفقودة في Pandas DataFrames
إذا نظرت عن كثب إلى output_data، ستلاحظ وجود عدة قيم None في عمود Dividend Yield:
تشير قيم None هذه ببساطة إلى أن الشركة في هذا الصف لا تدفع أرباحاً حالياً. في حين أن None هي إحدى طرق تمثيل سهم لا يدفع أرباحاً، إلا أنه من الشائع إظهار Dividend Yield بقيمة 0. لحسن الحظ، فإن إصلاح هذا الأمر بسيط جداً. تتضمن مكتبة pandas دالة fillna ممتازة تتيح لنا استبدال القيم المفقودة في pandas DataFrame. إليك كيفية استخدام دالة fillna لاستبدال قيم None في عمود Dividend Yield بـ 0:
output_data[ 'Dividend Yield' ].fillna( 0 ,inplace= True )يبدو كائن output_data أنظف بكثير الآن:
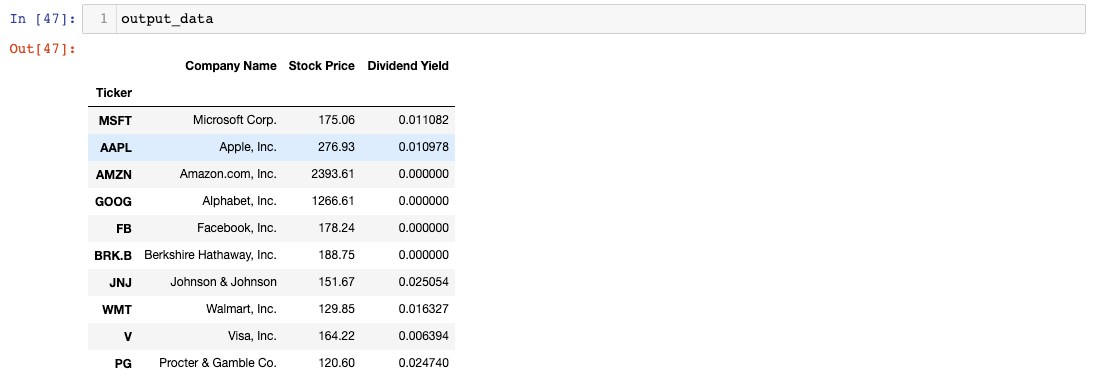
نحن الآن جاهزون لتصدير DataFrame الخاص بنا إلى مستند إكسل! كتذكير سريع، إليك نص بايثون البرمجي الخاص بنا حتى الآن:
import pandas as pd IEX_API_Key = '' #Specify the stock tickers that will be included in our spreadsheet tickers = [ 'MSFT' , 'AAPL' , 'AMZN' , 'GOOG' , 'FB' , 'BRK.B' , 'JNJ' , 'WMT' , 'V' , 'PG' ] #Create an empty string called `ticker_string` that we'll add tickers and commas to ticker_string = '' #Loop through every element of `tickers` and add them and a comma to ticker_string for ticker in tickers: ticker_string += ticker ticker_string += ',' #Drop the last comma from `ticker_string` ticker_string = ticker_string[: -1 ] #Create the endpoint strings endpoints = 'price,stats' #Interpolate the endpoint strings into the HTTP_request string HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range=1y&token={IEX_API_Key}' #Create an empty pandas DataFrame to append our parsed values into during our for loop output_data = pd.DataFrame(pd.np.empty(( 0 , 4 ))) for ticker in raw_data.columns: #Parse the company's name company_name = raw_data[ticker][ 'stats' ][ 'companyName' ] #Parse the company's stock price stock_price = raw_data[ticker][ 'price' ] #Parse the company's dividend yield dividend_yield = raw_data[ticker][ 'stats' ][ 'dividendYield' ] new_column = pd.Series([ticker, company_name, stock_price, dividend_yield]) output_data = output_data.append(new_column, ignore_index = True ) #Change the column names of output_data output_data.columns = [ 'Ticker' , 'Company Name' , 'Stock Price' , 'Dividend Yield' ] #Change the index of output_data output_data.set_index( 'Ticker' , inplace= True ) #Replace the missing values of the 'Dividend Yield' column with 0 output_data[ 'Dividend Yield' ].fillna( 0 ,inplace= True ) #Print the DataFrame output_dataكيفية تصدير مستند إكسل منسق من Pandas DataFrame باستخدام XlsxWriter
هناك طرق متعددة لتصدير ملف xlsx من pandas DataFrame. أسهل طريقة هي استخدام الدالة المدمجة to_excel. على سبيل المثال، إليك كيفية تصدير output_data إلى ملف إكسل:
output_data.to_excel( 'my_excel_document.xlsx')المشكلة في هذا النهج هي أن ملف إكسل لا يحتوي على أي تنسيق على الإطلاق. يبدو الإخراج هكذا:
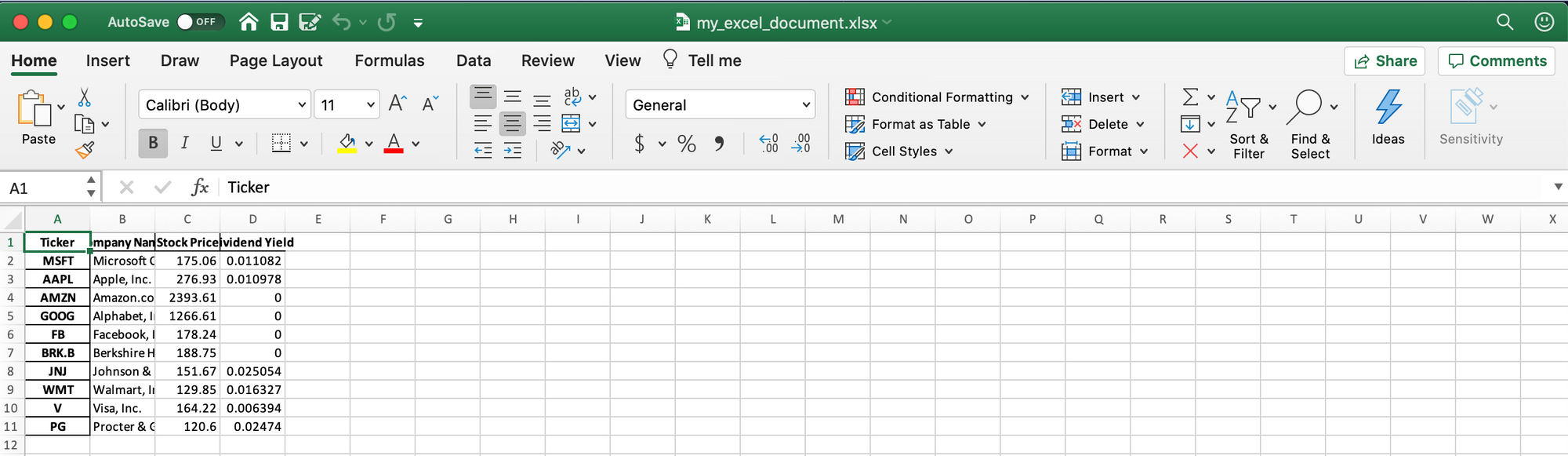
يصعب تفسير هذا المستند بسبب نقص التنسيق. ما هو الحل؟ يمكننا استخدام حزمة بايثون XlsxWriter لإنشاء ملفات إكسل منسقة بشكل جيد. للبدء، سنضيف الاستيراد التالي إلى بداية نص بايثون البرمجي الخاص بنا:
import xlsxwriterبعد ذلك، نحتاج إلى إنشاء ملف إكسل الفعلي الخاص بنا. تحتوي حزمة XlsxWriter في الواقع على صفحة وثائق مخصصة لكيفية العمل مع pandas DataFrames، وهي متاحة هنا. خطوتنا الأولى هي استدعاء دالة pd.ExcelWriter وتمرير الاسم المطلوب لملف xlsx الخاص بنا كأول وسيطة و engine='xlsxwriter' كوسيطة ثانية. سنقوم بتعيين هذا لمتغير يسمى writer:
writer = pd.ExcelWriter( 'stock_market_data.xlsx' , engine= 'xlsxwriter' )من هناك، نحتاج إلى استدعاء دالة to_excel على pandas DataFrame الخاص بنا. هذه المرة، بدلاً من تمرير اسم الملف الذي نحاول تصديره، سنمرر كائن writer الذي أنشأناه للتو:
output_data.to_excel(writer, sheet_name= 'Sheet1' )أخيراً، سنقوم باستدعاء دالة save على كائن writer الخاص بنا، والذي يحفظ ملف xlsx في دليل العمل الحالي الخاص بنا. عند الانتهاء من كل هذا، إليك قسم نص بايثون البرمجي الخاص بنا الذي يحفظ output_data في ملف إكسل.
writer = pd.ExcelWriter( 'stock_market_data.xlsx' , engine= 'xlsxwriter' ) output_data.to_excel(writer, sheet_name= 'Sheet1' ) writer.save()يجب أن تكون جميع تعليمات التنسيق التي سنقوم بتضمينها في ملف xlsx الخاص بنا محتواة بين إنشاء كائن ExcelWriter وبيان writer.save().
كيفية تنسيق ملف xlsx تم إنشاؤه باستخدام بايثون
من الصعب فعلاً أكثر مما تتخيل تنسيق ملف إكسل باستخدام بايثون. ويرجع ذلك جزئياً إلى بعض قيود حزمة XlsxWriter. تنص وثائقها على ما يلي: ‘تقدم XlsxWriter و Pandas دعماً محدوداً جداً لتنسيق بيانات الإخراج من DataFrame بخلاف التنسيق الافتراضي مثل خلايا الرأس والفهرس وأي خلايا تحتوي على تواريخ أو أوقات. بالإضافة إلى ذلك، لا يمكن تنسيق أي خلايا تم تطبيق تنسيق افتراضي عليها بالفعل. إذا كنت تتطلب تنسيقاً متحكماً جداً لإخراج DataFrame، فربما يكون من الأفضل استخدام XlsxWriter مباشرة مع البيانات الخام المأخوذة من Pandas. ومع ذلك، تتوفر بعض خيارات التنسيق.’
في تجربتي، فإن الطريقة الأكثر مرونة لتنسيق الخلايا في ملف xlsx الذي تم إنشاؤه بواسطة XlsxWriter هي استخدام التنسيق الشرطي (conditional formatting) الذي يطبق التنسيق فقط عندما لا تكون الخلية مساوية لـ None. هذا له ثلاث مزايا:
- يوفر مرونة أكبر في التنسيق من خيارات التنسيق العادية المتاحة في
XlsxWriter. - لا تحتاج إلى المرور يدوياً عبر كل نقطة بيانات واستيرادها إلى كائن
writerواحدة تلو الأخرى. - يتيح لك رؤية متى وصلت قيم
Noneإلى ملفاتxlsxالنهائية بسهولة، حيث ستفتقر إلى التنسيق المطلوب.
لتطبيق التنسيق باستخدام التنسيق الشرطي، نحتاج أولاً إلى إنشاء بعض قوالب الأنماط. على وجه التحديد، سنحتاج إلى أربعة قوالب:
- قالب
header_templateواحد سيتم تطبيقه على أسماء الأعمدة في الجزء العلوي من جدول البيانات. - قالب
string_templateواحد سيتم تطبيقه على عموديTickerوCompany Name. - قالب
dollar_templateواحد سيتم تطبيقه على عمودStock Price. - قالب
percent_templateواحد سيتم تطبيقه على عمودDividend Yield.
يجب إضافة كل من قوالب التنسيق هذه إلى كائن writer في قواميس تشبه صيغة CSS. إليك ما أعنيه:
header_template = writer.book.add_format( { 'font_color' : '#ffffff' , 'bg_color' : '#135485' , 'border' : 1 } ) string_template = writer.book.add_format( { 'bg_color' : '#DADADA' , 'border' : 1 } ) dollar_template = writer.book.add_format( { 'num_format' : '$0.00' , 'bg_color' : '#DADADA' , 'border' : 1 } ) percent_template = writer.book.add_format( { 'num_format' : '0.0%' , 'bg_color' : '#DADADA' , 'border' : 1 } )لتطبيق هذه التنسيقات على خلايا محددة في ملف xlsx الخاص بنا، نحتاج إلى استدعاء دالة conditional_format الخاصة بالحزمة على writer.sheets['Stock Market Data']. إليك مثال:
writer.sheets[ 'Stock Market Data' ].conditional_format( 'A2:B11' , { 'type' : 'cell' , 'criteria' : '<>' , 'value' : '"None"' , 'format' : string_template } )إذا قمنا بتعميم هذا التنسيق على التنسيقات الثلاثة الأخرى التي نطبقها، فإليك ما يصبح عليه قسم التنسيق في نص بايثون البرمجي الخاص بنا:
writer = pd.ExcelWriter( 'stock_market_data.xlsx' , engine= 'xlsxwriter' ) output_data.to_excel(writer, sheet_name= 'Stock Market Data' ) header_template = writer.book.add_format( { 'font_color' : '#ffffff' , 'bg_color' : '#135485' , 'border' : 1 } ) string_template = writer.book.add_format( { 'bg_color' : '#DADADA' , 'border' : 1 } ) dollar_template = writer.book.add_format( { 'num_format' : '$0.00' , 'bg_color' : '#DADADA' , 'border' : 1 } ) percent_template = writer.book.add_format( { 'num_format' : '0.0%' , 'bg_color' : '#DADADA' , 'border' : 1 } ) #Format the header of the spreadsheet writer.sheets[ 'Stock Market Data' ].conditional_format( 'A1:D1' , { 'type' : 'cell' , 'criteria' : '<>' , 'value' : '"None"' , 'format' : header_template } ) #Format the 'Ticker' and 'Company Name' columns writer.sheets[ 'Stock Market Data' ].conditional_format( 'A2:B11' , { 'type' : 'cell' , 'criteria' : '<>' , 'value' : '"None"' , 'format' : string_template } ) #Format the 'Stock Price' column writer.sheets[ 'Stock Market Data' ].conditional_format( 'C2:C11' , { 'type' : 'cell' , 'criteria' : '<>' , 'value' : '"None"' , 'format' : dollar_template } ) #Format the 'Dividend Yield' column writer.sheets[ 'Stock Market Data' ].conditional_format( 'D2:D11' , { 'type' : 'cell' , 'criteria' : '<>' , 'value' : '"None"' , 'format' : percent_template } ) writer.save()دعنا نلقي نظرة على مستند إكسل الخاص بنا لنرى كيف يبدو:
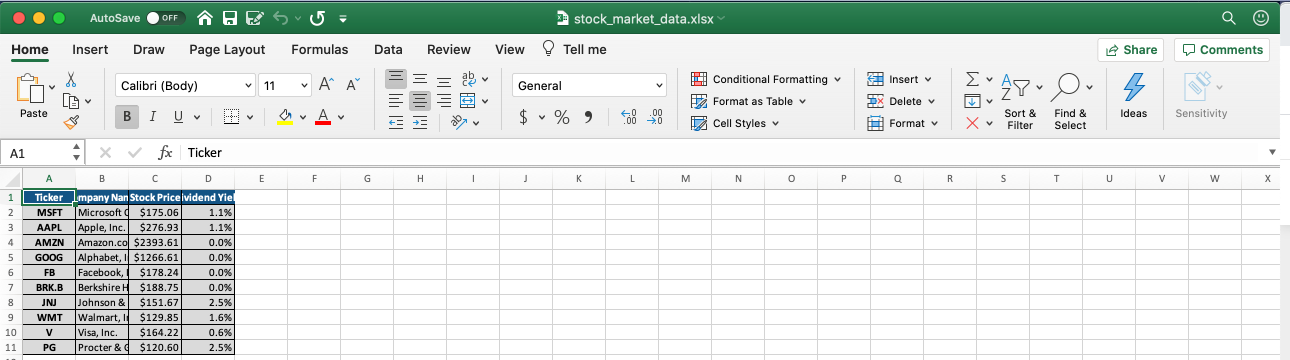
حتى الآن كل شيء جيد! التحسين التدريجي الأخير الذي يمكننا إجراؤه على هذا المستند هو جعل أعمدته أوسع قليلاً. يمكننا تحديد عرض الأعمدة عن طريق استدعاء دالة set_column على writer.sheets['Stock Market Data']. إليك ما سنضيفه إلى نص بايثون البرمجي الخاص بنا للقيام بذلك:
#Specify all column widths writer.sheets[ 'Stock Market Data' ].set_column( 'B:B' , 32 ) writer.sheets[ 'Stock Market Data' ].set_column( 'C:C' , 18 ) writer.sheets[ 'Stock Market Data' ].set_column( 'D:D' , 20 )إليك النسخة النهائية من جدول البيانات:
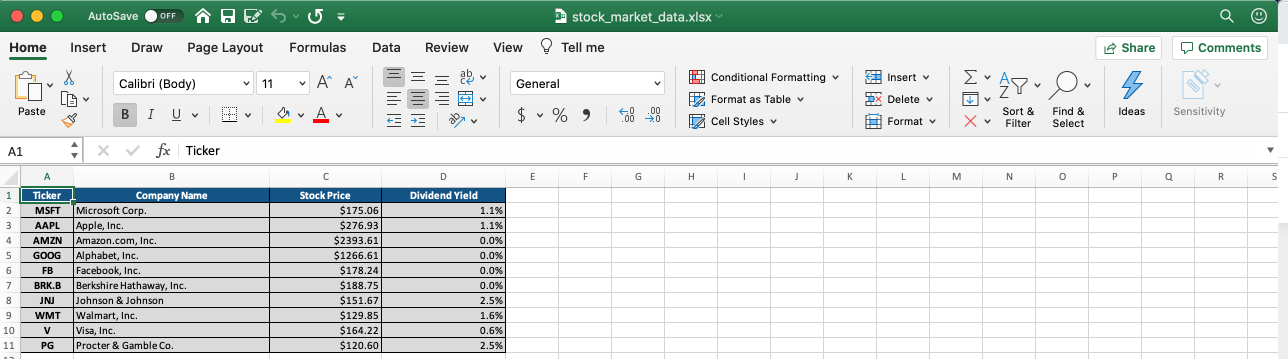
وهكذا! نحن جاهزون للانطلاق! يمكنك الوصول إلى النسخة النهائية من نص بايثون البرمجي هذا على GitHub هنا. الملف يسمى stock_market_data.py.
الخطوة 3: إعداد جهاز افتراضي AWS EC2 لتشغيل نص بايثون البرمجي الخاص بك
نص بايثون البرمجي الخاص بك جاهز للتشغيل. ومع ذلك، لا نريد ببساطة تشغيله على جهازنا المحلي بشكل مخصص. بدلاً من ذلك، سنقوم بإعداد جهاز افتراضي باستخدام خدمة Elastic Compute Cloud (EC2) من Amazon Web Services. ستحتاج إلى إنشاء حساب AWS أولاً إذا لم يكن لديك واحد بالفعل. للقيام بذلك، انتقل إلى هذا الرابط وانقر على “Create an AWS Account” في الزاوية العلوية اليمنى:
سيقوم تطبيق الويب الخاص بـ AWS بإرشادك خلال خطوات إنشاء حساب. بمجرد إنشاء حسابك، ستحتاج إلى إنشاء EC2 instance. هذا ببساطة هو خادم افتراضي لتشغيل التعليمات البرمجية على بنية AWS التحتية. تأتي EC2 instances بأنظمة تشغيل وأحجام مختلفة، تتراوح من خوادم صغيرة جداً مؤهلة للطبقة المجانية من AWS إلى خوادم كبيرة جداً قادرة على تشغيل تطبيقات معقدة. سنستخدم أصغر خادم من AWS لتشغيل نص بايثون البرمجي الذي كتبناه في هذه المقالة.
للبدء، انتقل إلى EC2 داخل وحدة تحكم إدارة AWS. بمجرد وصولك إلى EC2، انقر على Launch Instance:
سيأخذك هذا إلى شاشة تحتوي على جميع أنواع المثيلات المتاحة داخل AWS EC2. أي جهاز مؤهل للطبقة المجانية من AWS سيكون كافياً. لقد اخترت Amazon Linux 2 AMI (HVM):

انقر على Select للمتابعة. في الصفحة التالية، ستطلب منك AWS تحديد مواصفات جهازك. تتضمن الحقول التي يمكنك تحديدها:
FamilyTypevCPUsMemoryInstance Storage (GB)EBS-OptimizedNetwork PerformanceIPv6 Support
لغرض هذا الدليل، نريد ببساطة تحديد الجهاز الوحيد المؤهل للطبقة المجانية. يتميز هذا الجهاز بملصق أخضر صغير يبدو هكذا:

بمجرد تحديد جهاز مؤهل للطبقة المجانية، انقر على Review and Launch في أسفل الشاشة للمتابعة. ستعرض الشاشة التالية تفاصيل المثيل الجديد الخاص بك للمراجعة. راجع مواصفات الجهاز بسرعة، ثم انقر على Launch في الزاوية السفلية اليمنى.
سيؤدي النقر على زر Launch إلى ظهور نافذة منبثقة تطلب منك Select an existing key pair or create a new key pair. يتكون زوج المفاتيح من مفتاح عام تحتفظ به AWS ومفتاح خاص يجب عليك تنزيله وتخزينه في ملف .pem. يجب أن يكون لديك وصول إلى ملف .pem هذا للوصول إلى EC2 instance الخاص بك (عادةً عبر SSH). لديك أيضاً خيار المتابعة بدون زوج مفاتيح، ولكن هذا لا يُنصح به لأسباب أمنية.
بمجرد تحديد أو إنشاء زوج مفاتيح لـ EC2 instance هذا والنقر على زر الاختيار لـ I acknowledge that I have access to the selected private key file (data-feeds.pem), and that without this file, I won't be able to log into my instance، يمكنك النقر على Launch Instances للمتابعة. سيبدأ مثيلك الآن في التشغيل. قد يستغرق الأمر بعض الوقت حتى يتم تشغيل هذه المثيلات، ولكن بمجرد أن يصبح جاهزاً، ستظهر حالة Instance State الخاصة به كـ running في لوحة تحكم EC2 الخاصة بك.
بعد ذلك، ستحتاج إلى دفع نص بايثون البرمجي الخاص بك إلى EC2 instance الخاص بك. إليك بيان أمر عام يسمح لك بنقل ملف إلى EC2 instance:
scp -i path/to/.pem_file path/to/file username@host_address.amazonaws.com:/path_to_copyقم بتشغيل هذا البيان مع الاستبدالات الضرورية لنقل stock_market_data.py إلى EC2 instance. محاولة تشغيل stock_market_data.py في هذه المرحلة ستؤدي في الواقع إلى خطأ لأن EC2 instance لا يأتي مع حزم بايثون الضرورية. لإصلاح ذلك، يمكنك إما تصدير ملف requirements.txt واستيراد الحزم المناسبة باستخدام pip، أو يمكنك ببساطة تشغيل ما يلي:
sudo yum install python3-pip pip3 install pandas pip3 install xlsxwriterبمجرد الانتهاء من ذلك، يمكنك الاتصال بـ EC2 instance عبر SSH وتشغيل نص بايثون البرمجي من سطر الأوامر بالبيان التالي:
python3 stock_market_data.pyالخطوة 4: إنشاء AWS S3 Bucket للاحتفاظ بنص بايثون البرمجي النهائي
مع العمل الذي أكملناه حتى الآن، يمكن تنفيذ نص بايثون البرمجي الخاص بنا داخل EC2 instance. المشكلة في هذا هي أن ملف xlsx سيتم حفظه على الخادم الافتراضي لـ AWS. لا يمكن لأي شخص الوصول إليه سوانا في هذا الخادم، مما يحد من فائدته. لإصلاح ذلك، سنقوم بإنشاء bucket عام على AWS S3 حيث يمكننا حفظ ملف xlsx. سيتمكن أي شخص لديه الرابط الصحيح من تنزيل هذا الملف بمجرد إجراء هذا التغيير.
للبدء، انتقل إلى AWS S3 من داخل وحدة تحكم إدارة AWS. انقر على Create bucket في الجزء العلوي الأيمن:

في الشاشة التالية، ستحتاج إلى اختيار اسم لـ bucket الخاص بك ومنطقة AWS لاستضافة bucket فيها. يجب أن يكون اسم bucket فريداً ولا يمكن أن يحتوي على مسافات أو أحرف كبيرة. لا تهم المنطقة كثيراً لغرض هذا الدليل، لذلك سأستخدم المنطقة الافتراضية US East (Ohio) us-east-2. ستحتاج إلى تغيير إعدادات الوصول العام (Public Access) في القسم التالي لتتناسب مع هذا التكوين:
انقر على Create bucket لإنشاء bucket الخاص بك واختتام هذه الخطوة من هذا الدليل!
الخطوة 5: تعديل نص بايثون البرمجي لدفع ملف xlsx إلى AWS S3
AWS S3 bucket الخاص بنا جاهز الآن للاحتفاظ بمستند xlsx النهائي. سنقوم الآن بإجراء تغيير صغير على ملف stock_market_data.py الخاص بنا لدفع المستند النهائي إلى S3 bucket الخاص بنا. سنحتاج إلى استخدام حزمة boto3 للقيام بذلك. boto3 هو AWS Software Development Kit (SDK) لـ بايثون، مما يسمح لمطوري بايثون بكتابة برامج تتصل بخدمات AWS.
للبدء، ستحتاج إلى تثبيت boto3 على جهازك الافتراضي EC2. قم بتشغيل بيان سطر الأوامر التالي للقيام بذلك:
pip3 install boto3ستحتاج أيضاً إلى استيراد المكتبة إلى stock_market_data.py عن طريق إضافة البيان التالي إلى أعلى نص بايثون البرمجي.
import boto3سنحتاج إلى إضافة بضعة أسطر من التعليمات البرمجية إلى نهاية stock_market_data.py لدفع المستند النهائي إلى AWS S3.
s3 = boto3.resource( 's3' ) s3.meta.client.upload_file( 'stock_market_data.xlsx' , 'my-S3-bucket' , 'stock_market_data.xlsx' , ExtraArgs={ 'ACL' : 'public-read' })السطر الأول من هذه التعليمات البرمجية، s3 = boto3.resource('s3')، يسمح لنص بايثون البرمجي الخاص بنا بالاتصال بخدمات Amazon Web Services. السطر الثاني من التعليمات البرمجية يستدعي دالة من boto3 تقوم بالفعل بتحميل ملفنا إلى S3. تأخذ أربع وسيطات:
stock_market_data.xlsx– اسم الملف على جهازنا المحلي.my-S3-bucket– اسمS3 bucketالذي نقوم بتحميل ملفنا إليه.stock_market_data.xlsx– الاسم المطلوب للملف داخلS3 bucket. في معظم الحالات، سيكون له نفس قيمة الوسيطة الأولى التي تم تمريرها إلى هذه الدالة.ExtraArgs={'ACL':'public-read'}– هذه وسيطة اختيارية تخبرAWSبجعل الملف الذي تم تحميله قابلاً للقراءة علناً.
الخطوة 6: جدولة نص بايثون البرمجي للتشغيل بشكل دوري باستخدام Cron
حتى الآن، أكملنا ما يلي:
- بناء نص
بايثونالبرمجي الخاص بنا. - إنشاء
EC2 instanceونشر التعليمات البرمجية الخاصة بنا هناك. - إنشاء
S3 bucketحيث يمكننا دفع مستندxlsxالنهائي. - تعديل نص
بايثونالبرمجي الأصلي لتحميل ملفstock_market_data.xlsxالنهائي إلىAWS S3 bucket.
الخطوة الوحيدة المتبقية هي جدولة نص بايثون البرمجي للتشغيل بشكل دوري. يمكننا القيام بذلك باستخدام أداة سطر الأوامر تسمى cron. للبدء، سنحتاج إلى إنشاء cron expression يخبر الأداة متى يجب تشغيل التعليمات البرمجية. موقع crontab guru هو مورد ممتاز لذلك. إليك كيفية استخدام crontab guru للحصول على cron expression الذي يعني كل يوم عند الظهر:
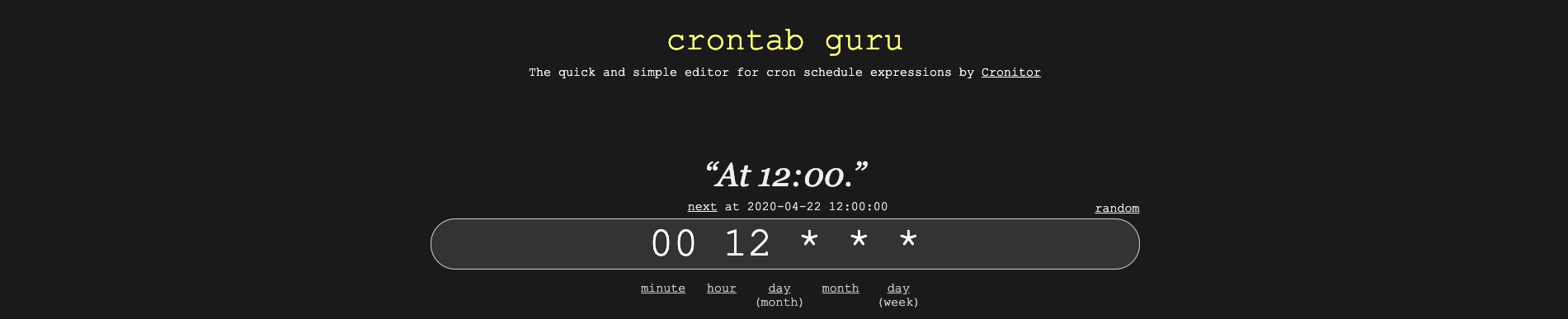
الآن نحتاج إلى توجيه cron daemon في EC2 instance لتشغيل stock_market_data.py في هذا الوقت كل يوم. للقيام بذلك، سنقوم أولاً بإنشاء ملف جديد في EC2 instance الخاص بنا يسمى stock_market_data.cron. افتح هذا الملف واكتب cron expression الخاص بنا متبوعاً بالبيان الذي يجب تنفيذه في سطر الأوامر في الوقت المحدد. بيان سطر الأوامر الخاص بنا هو python3 stock_market_data.py، لذا إليك ما يجب أن يحتويه stock_market_data.cron:
00 12 * * * python3 stock_market_data.pyإذا قمت بتشغيل أمر ls في EC2 instance الخاص بك، يجب أن ترى الآن ملفين:
stock_market_data.py stock_market_data.cronالخطوة الأخيرة في هذا الدليل هي تحميل stock_market_data.cron إلى crontab. يمكنك اعتبار crontab ملفاً يحتوي على أوامر وتعليمات لـ cron daemon لتنفيذها. بعبارة أخرى، يحتوي crontab على دفعات من cron jobs.
أولاً، دعنا نرى ما هو موجود في crontab الخاص بنا. يجب أن يكون فارغاً لأننا لم نضع أي شيء فيه! يمكنك عرض محتويات crontab الخاص بك بالأمر التالي:
crontab -lلتحميل stock_market_data.cron إلى crontab، قم بتشغيل البيان التالي في سطر الأوامر:
crontab stock_market_data.cronالآن عندما تقوم بتشغيل crontab -l، يجب أن ترى:
00 12 * * * python3 stock_market_data.pyسيتم الآن تشغيل نص stock_market_data.py الخاص بنا عند الظهر كل يوم على جهاز AWS EC2 الافتراضي الخاص بنا!
الخلاصة التقنية
لقد قدم هذا المقال دليلاً عملياً ومتكاملاً لإنشاء نظام آلي لتحديث جداول بيانات إكسل لبيانات سوق الأسهم، مستفيداً من قوة بايثون، ومرونة AWS، وموثوقية IEX Cloud. يكمن الابتكار هنا في دمج هذه التقنيات لتقديم حل فعال يتجاوز مجرد استخراج البيانات إلى تقديمها في شكل منسق ومتاح للمستخدمين غير التقنيين بشكل دوري. إن استخدام pandas و XlsxWriter في بايثون يتيح معالجة البيانات وتصديرها بتنسيقات احترافية، بينما توفر AWS EC2 بيئة مستقرة لتشغيل النصوص البرمجية و AWS S3 منصة تخزين سحابية آمنة ومتاحة عالمياً. تُعد جدولة المهام باستخدام cron هي اللبنة الأخيرة التي تحول هذا الحل إلى نظام مستقل يعمل تلقائياً، مما يقلل من التدخل اليدوي ويضمن تحديث البيانات في الوقت المناسب. هذا النهج يمثل نموذجاً قوياً لأتمتة المهام المالية وتحسين كفاءة سير العمل في المؤسسات.