أتمتة نشر نماذج تعلّم الآلة باستخدام سجل الحزم في GitLab
مقدمة
في هذا الدليل العملي سنتعرّف على طريقة احترافية لأتمتة نشر نماذج تعلّم الآلة داخل سجل الحزم في GitLab، بحيث تصبح النماذج متاحة للفريق بشكل منظم، قابل للتتبع، وسهل التحديث. ويمكن تطبيق الفكرة نفسها أيضاً على نشر نسخة مجمّعة من الشيفرة البرمجية أو أي ملفات تشغيلية أخرى.
إذا كنت في بداية استخدامك لمنصة GitLab أو لم تتعامل كثيراً مع مفاهيم CI/CD، فهذا المقال مناسب لك. كما أن الإلمام الأساسي بـMachine Learning أو Deep Learning مفيد، لكنه ليس شرطاً لفهم آلية النشر المؤتمت.

سنغطي في هذا المقال المحاور التالية:
- إعداد المشروع على
GitLab - بناء نموذج شبكي عصبي التفافي بسيط
- تنفيذ التعرّف على الصور باستخدام النموذج
- استراتيجية الفروع المناسبة للنشر
- إنشاء خط
CI/CDلرفع الملفات تلقائياً - خاتمة عملية مع توصيات تقنية
لماذا نحتاج إلى أتمتة نشر النماذج؟
خلال عملك كمهندس تعلّم آلة، ستحتاج غالباً إلى مشاركة نموذج تم تدريبه مع مطورين آخرين أو مع فرق داخل المؤسسة. توجد عدة طرق لذلك، لكنها ليست متساوية من حيث التنظيم والاعتمادية.
1. منح الوصول الكامل إلى المستودع
إذا لم تكن لديك مشكلة في إتاحة كامل الشيفرة، فهذا خيار عملي. يمكن لزملائك الرجوع إلى الفرع الرئيسي main أو master لمعرفة أحدث إصدار من النموذج، ثم قراءة ملف README.md لفهم طريقة الاستخدام.
لكن هذا الأسلوب ليس مناسباً دائماً، خاصة إذا كنت لا ترغب في كشف كل تفاصيل المشروع أو إذا كانت هناك أجزاء داخلية لا يجب مشاركتها.
2. مشاركة النموذج يدوياً
يمكنك أيضاً استخراج الملفات المهمة وإرسالها يدوياً إلى الفريق. غير أن هذه الطريقة تصبح مرهقة بسرعة، خصوصاً عند تعدد المستخدمين أو تكرار التحديثات. كما أنها تجعل مسؤولية التأكد من استخدام أحدث نسخة تقع عليك بالكامل.
3. النشر التلقائي عبر CI/CD
الحل الأكثر كفاءة هو جعل خط CI/CD يتولى عملية التغليف والرفع تلقائياً. بهذه الطريقة يصبح النموذج منشوراً بإصدار واضح داخل GitLab Package Registry، ويمكن لأي شخص مخوّل الوصول إليه واستخدامه بسهولة.
في هذا السيناريو سيكون لدينا:
- مستودع الشيفرة، وأدوات
CI/CD، وسجل الحزم كلها علىGitLab. - النموذج المنشور عبارة عن شبكة عصبية مدرّبة باستخدام
PyTorchعلى بياناتMNISTللتعرف على الأرقام. - جميع ملفات التشغيل والتعليمات سترافق النموذج داخل الحزمة نفسها.
تنبيه مهم: هذه الطريقة مناسبة لتوضيح فكرة النشر المؤتمت، لكنها ليست النهج المثالي لنشر نموذج إنتاجي في بيئة حقيقية. عند الانتقال إلى الإنتاج، يُفضّل دراسة أدوات مخصصة مثل TorchScript أو حلول تقديم النماذج Model Serving.
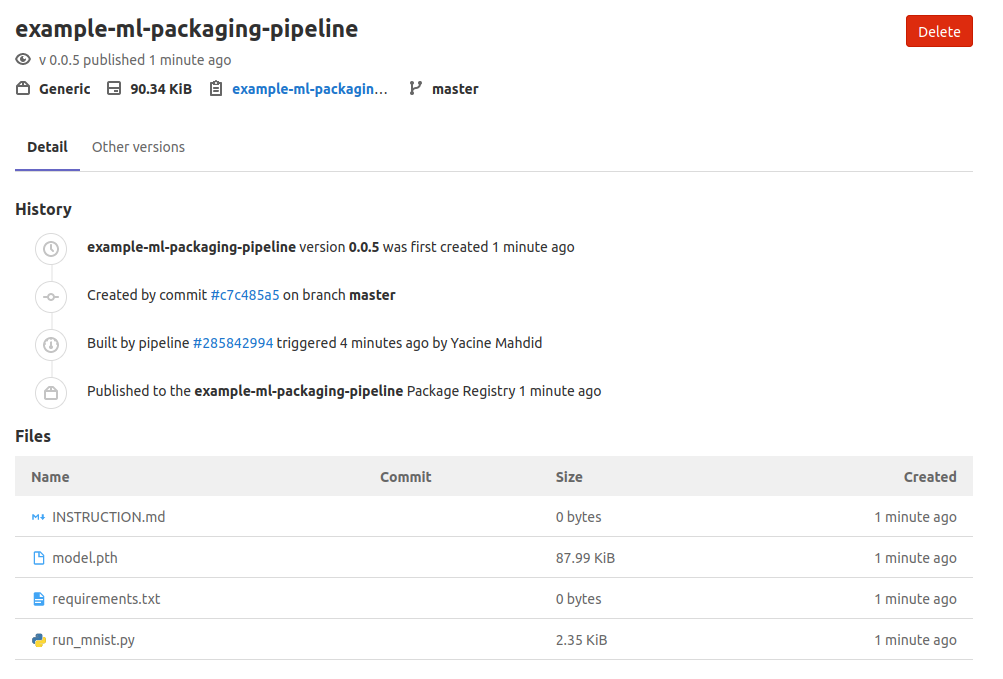
إعداد ملفات المشروع على GitLab
في هذا المثال، سنقوم بتجميع أربعة ملفات رئيسية داخل الحزمة المنشورة:
model.pth: يحتوي على الأوزان المدربة للنموذج.run_mnist.py: سكربتPythonلتشغيل النموذج على صورة واستخراج النتيجة.requirements.txt: قائمة الاعتماديات المطلوبة للتشغيل.INSTRUCTION.md: تعليمات استخدام الحزمة خطوة بخطوة.
بمجرد رفع هذه الملفات إلى سجل الحزم، سيتمكن أي شخص لديه صلاحية الوصول من تنزيل النسخة الصحيحة واستخدامها مباشرة.
بناء نموذج الشبكة العصبية الالتفافية
سنستخدم نموذجاً بسيطاً نسبياً من نوع Convolutional Neural Network للتعرف على الأرقام من بيانات MNIST. الهدف هنا ليس شرح التعلم العميق بالتفصيل، بل توفير مثال عملي يمكن حزمه ونشره لاحقاً.
خصائص النموذج كالتالي:
- طبقتان من الالتفاف
Convolution. - استخدام
Dropoutفي الطبقة الالتفافية الثانية. - تفعيل
ReLUفي الطبقات. - طبقتان كاملتا الاتصال
Fully Connectedللاستدلال النهائي.
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# Define the network
# It's a 2 convolutional layer with dropout at the 2nd and finally 2 fully connected layer
# All layers use relu
class Net ( nn.Module ):
def __init__ ( self ):
super(Net, self).__init__()
self.conv1 = nn.Conv2d( 1 , 10 , kernel_size= 5 )
self.conv2 = nn.Conv2d( 10 , 20 , kernel_size= 5 )
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear( 320 , 50 )
self.fc2 = nn.Linear( 50 , 10 )
def forward ( self, x ):
x = F.relu(F.max_pool2d(self.conv1(x), 2 ))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2 ))
x = x.view( -1 , 320 )
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim= 1 )كيف يعمل هذا النموذج؟
يقوم النموذج باستخراج السمات البصرية من الصورة تدريجياً عبر الطبقات الالتفافية، ثم يحول تلك السمات إلى تمثيل عددي يمكن لطبقات القرار النهائية استخدامه لتحديد الرقم المتوقع. وبما أن بيانات MNIST صغيرة وبسيطة نسبياً، فإن هذا النموذج كافٍ لتقديم أداء جيد في المثال.
دالة التدريب على النموذج
بعد تعريف البنية، نحتاج إلى دالة تدريب تقوم بتحسين الأوزان تدريجياً باستخدام خوارزمية الهبوط التدرجي Gradient Descent. الوظائف الأساسية لهذه المرحلة هي:
- المرور على دفعات البيانات التدريبية.
- حساب قيمة الخطأ
Loss. - اشتقاق التدرجات
Gradients. - تحديث الأوزان باستخدام المحسن
Optimizer. - حفظ النموذج بشكل دوري.
def train ( network, optimizer, train_loader, epoch_id, log_interval= 10 ):
"""Run the training regiment on the training set using train_loader
Args:
network: The instantiated network.
optimizer: The optimizer used to change the weights.
train_loader: the loader for the training set already setup
epoch_id: the current id of the epoch used for cosmetic reason.
log_interval: interval at which we print an output
Returns:
nothing, will save directly at root level the model and the optimizer state
"""
# Set the network in training mode
network.train()
# Iterate over the full training set
for batch_idx, (data, target) in enumerate(train_loader):
# Calculate the gradients for this batch of data
optimizer.zero_grad()
output = network(data)
loss = F.nll_loss(output, target)
loss.backward()
# Optimize the network
optimizer.step()
# Log and save every selected interval
if batch_idx % log_interval == 0 :
print( 'Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}' .format(
epoch_id, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# This will save the state as a pickled object
torch.save(network.state_dict(), './model.pth' )
torch.save(optimizer.state_dict(), './optimizer.pth' )أهمية هذا الجزء لا تقتصر على التدريب فقط، بل تمتد إلى إنتاج ملف model.pth الذي سننشره لاحقاً عبر GitLab Package Registry.
اختبار النموذج بعد التدريب
لا يكفي أن ندرّب النموذج على البيانات نفسها ثم نفترض أنه تعلّم جيداً. يجب اختبار الأداء على مجموعة منفصلة لم يرها النموذج من قبل، حتى نتأكد من قدرته على التعميم وعدم الوقوع في مشكلة Overfitting.
def test ( network, test_loader ):
"""Run the testing regiment on the test set using test_loader
Args:
network: The instantiated and trained network.
test_loader: the loader for the testing set already setup
Returns:
nothing, will only print result
"""
# Variable instantiation
test_loss = 0
correct = 0
# Move the network to evaluate mode instead of training
network.eval()
# setup torch so to not track any gradient
with torch.no_grad():
# Iterate on all the test data and accumulate the loss
for data, target in test_loader:
output = network(data)
test_loss += F.nll_loss(output, target, size_average= False ).item()
pred = output.data.max( 1 , keepdim= True )[ 1 ]
correct += pred.eq(target.data.view_as(pred)).sum()
# Average loss calculation and printing
test_loss /= len(test_loader.dataset)
print( '\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n' .format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))تمنحنا هذه الدالة مؤشراً عملياً عن جودة النموذج بعد كل دورة تدريب Epoch.
نظام التدريب الكامل
الآن يمكننا ربط كل شيء داخل سكربت تدريب واحد. في هذا الجزء نحدد المعاملات الأساسية، ونجهز محمّلات البيانات DataLoader، ثم نبدأ دورة التدريب والاختبار.
# Experimental Parameters that we can tweak
n_epochs = 3
batch_size_train = 64
batch_size_test = 1000
learning_rate = 0.01
momentum = 0.5
# Variable from the dataset that should stay as is
global_mean_mnist = 0.1307
global_std_mnist = 0.3081
# Random Seed for Reproducible Experimentation
random_seed = 42
torch.backends.cudnn.enabled = False
torch.manual_seed(random_seed)
# Data Loader to gather the data and then normalize them
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST( './data/' , train= True , download= True ,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize( (global_mean_mnist,), (global_std_mnist,))
])),
batch_size=batch_size_train, shuffle= True
)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST( './data/' , train= False , download= True ,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize( (global_mean_mnist,), (global_std_mnist,))
])),
batch_size=batch_size_test, shuffle= True
)
# Initialize network and optimizer
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
# Test first to show that the model didn't learn a thing
test(network, test_loader)
# Train on the whole dataset multiple time and test
for epoch_id in range( 1 , n_epochs + 1 ):
train(network, optimizer, train_loader, epoch_id)
test(network, test_loader)من الجيد ملاحظة أن استخدام مجموعة اختبار منفصلة أمر أساسي لتقييم الأداء الحقيقي. أما ملف التدريب الكامل فيمكن وضعه داخل train_mnist.py.
استخدام النموذج للتعرّف على الأرقام من الصور
بعد تدريب النموذج وحفظه في ملف model.pth، يمكننا استخدامه على صور خارجية بصيغة .png لاستخراج الرقم الموجود فيها.
مثلاً قد تكون لدينا الصورة التالية:

أو هذه الصورة:
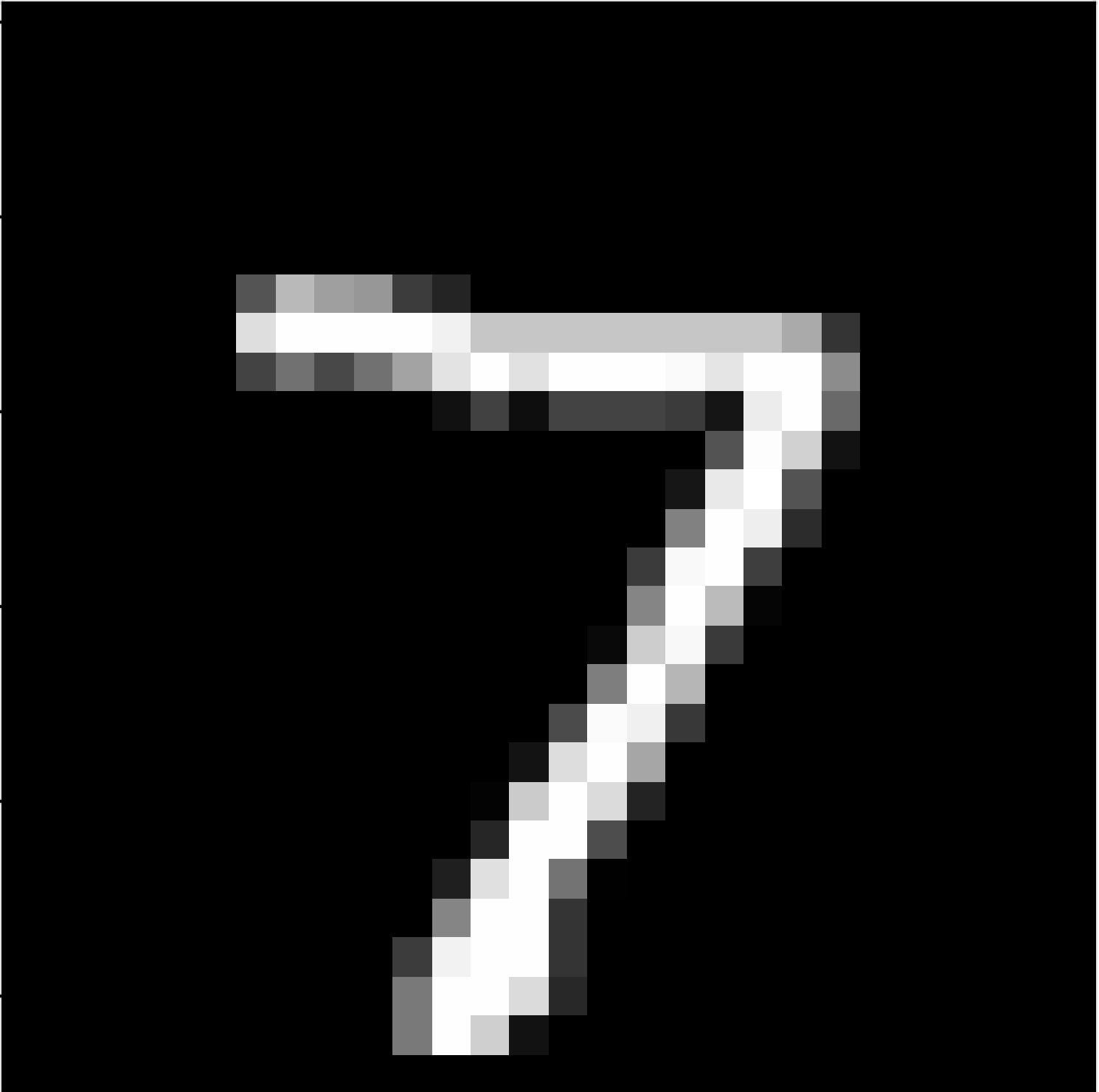
لكي يعمل النموذج بشكل صحيح، يجب تمرير الصور تقريباً عبر نفس خطوات المعالجة المستخدمة أثناء التدريب:
- تحويل الصورة إلى تدرج رمادي
Grayscale. - تغيير الحجم إلى
28×28بكسل. - تطبيع القيم باستخدام متوسط وانحراف بيانات
MNIST.
if __name__ == "__main__" :
# Variable iniatilization
global_mean_mnist = 0.1307
global_std_mnist = 0.3081
# Loading of the network with right weight
result_path = './model.pth'
model = Net()
model.load_state_dict(torch.load(result_path))
model.eval()
# Setup the transform from image to normalized tensors
transform = transforms.Compose([
transforms.Resize(( 28 , 28 )),
transforms.ToTensor(),
transforms.Normalize( (global_mean_mnist,), (global_std_mnist,))
])
# Parse the input from the user which should be a filename with the --image flag
parser = OptionParser()
parser.add_option( "--image" , dest = "input_image_path" , help = "Input Image Path" )
(options, args) = parser.parse_args()
# Get the path to the image to decode
input_image_path = str(options.input_image_path)
# Open the image(s) and do the inference
images=glob.glob(input_image_path)
for image in images:
# Convert the image to grayscale
img = Image.open(image).convert( 'L' )
# Transform the image to a normalized tensor
img_tensor = transform(img).unsqueeze( 0 )
# Make and print the prediction
output = model(img_tensor).data.max( 1 , keepdim= True )[ 1 ][ 0 ][ 0 ]
print( f"Image is a {int(output)} " )من المهم جداً تضمين تعريف الشبكة Net داخل السكربت نفسه أو استيراده بشكل صحيح، لأن تحميل النموذج يعتمد على البنية المطابقة للأوزان المخزنة.
لتشغيل السكربت استخدم الأمر التالي:
python run_mnist.py --image NAME_OF_IMAGE.pngسيقوم البرنامج بطباعة الرقم المتوقع للصورة المحددة.
منهجية الفروع المناسبة للنشر المؤتمت
إذا كنت تعمل منفرداً، فقد يبدو من السهل تنفيذ جميع التعديلات مباشرة على الفرع main أو master. لكن هذا الأسلوب يخلق فوضى مع الوقت، ويجعل تكامل CI/CD أكثر حساسية للأخطاء.
النهج الأكثر تنظيماً هو استخدام فرعين أساسيين:
develop: للتطوير المستمر والتجارب.mainأوmaster: للإصدارات المستقرة الجاهزة للنشر.
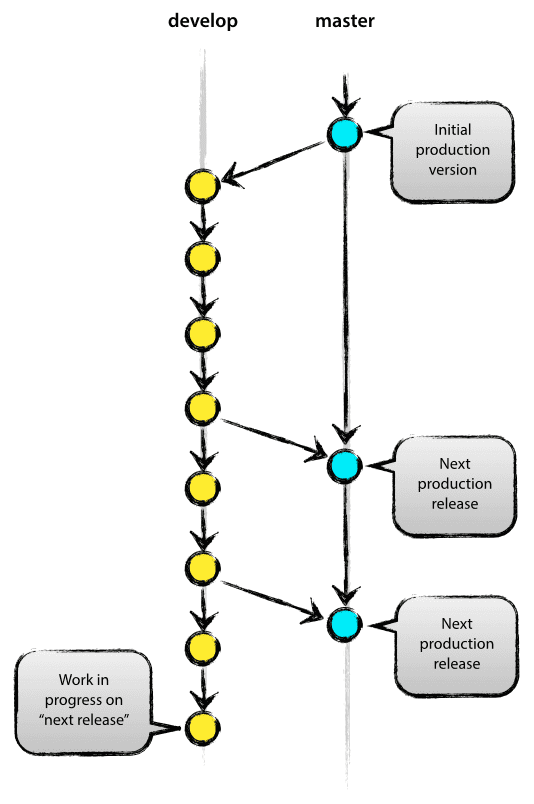
عند الحفاظ على نظافة الفرع الرئيسي، يمكننا ربط عملية النشر التلقائي به فقط. وهكذا تصبح كل عملية دمج إلى main أو master بمثابة إشارة لإطلاق خط النشر ورفع الحزمة الجديدة إلى السجل.
أفضل ممارسة هنا هي استخدام Merge Request قبل الدمج، لأن ذلك يضيف طبقة مراجعة ويقلل من احتمال نشر نموذج غير جاهز.
إنشاء خط CI/CD لرفع النموذج إلى سجل الحزم
يعتمد GitLab على ملف خاص باسم .gitlab-ci.yml لتحديد ما يجب أن يحدث عند كل push إلى المستودع. في مثالنا، سننشئ خطاً بسيطاً جداً مهمته الوحيدة هي رفع ملفات الحزمة إلى GitLab Package Registry.
image: pytorch/pytorch
variables:
VERSION: "0.0.4" # To Change if needs be
stages:
- upload
upload:
stage: upload
only:
- master
script:
- apt-get update
- apt-get install -y curl wget
- 'curl --header "JOB-TOKEN: $CI_JOB_TOKEN" --upload-file ./model.pth "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/example-ml-packaging-pipeline/${VERSION}/model.pth"'
- 'curl --header "JOB-TOKEN: $CI_JOB_TOKEN" --upload-file ./run_mnist.py "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/example-ml-packaging-pipeline/${VERSION}/run_mnist.py"'
- 'curl --header "JOB-TOKEN: $CI_JOB_TOKEN" --upload-file ./requirements.txt "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/example-ml-packaging-pipeline/${VERSION}/requirements.txt"'
- 'curl --header "JOB-TOKEN: $CI_JOB_TOKEN" --upload-file ./INSTRUCTION.md "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/example-ml-packaging-pipeline/${VERSION}/INSTRUCTION.md"'شرح بنية الملف
image: صورة الحاوية المستخدمة لتشغيل المهمة، وهنا استُخدمت بيئةPyTorch.variables: لتعريف متغيرات يمكن إعادة استخدامها مثل رقم الإصدارVERSION.stages: تحدد مراحل خط المعالجة، ولدينا هنا مرحلة واحدة فقط وهيupload.only: تجعل التنفيذ محصوراً عند التحديث على الفرعmaster.script: يضم الأوامر التي ستنفذ فعلياً لرفع الملفات.
كيف يعمل أمر curl في الرفع؟
الهيكل العام للأمر المستخدم هو:
- 'curl --header "JOB-TOKEN: $CI_JOB_TOKEN" --upload-file ./NAME_OF_FILE "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/example-ml-packaging-pipeline/${VERSION}/NAME_OF_FILE"'ويتكون من الأجزاء التالية:
--header: لإرسال ترويسة إضافية مع الطلب.JOB-TOKEN: اسم الترويسة المستخدمة للمصادقة.$CI_JOB_TOKEN: القيمة التي يوفّرهاGitLabتلقائياً أثناء تنفيذ المهمة.--upload-file: يحدد الملف المحلي المراد رفعه.${CI_API_V4_URL}: عنوان واجهةAPIفيGitLab.${CI_PROJECT_ID}: معرّف المشروع الحالي.${VERSION}: رقم الإصدار الذي نريد نشر الملفات ضمنه.
بمجرد دفع تحديث إلى الفرع الرئيسي، سيبدأ الخط تلقائياً ويرفع الملفات إلى السجل بالإصدار المحدد.
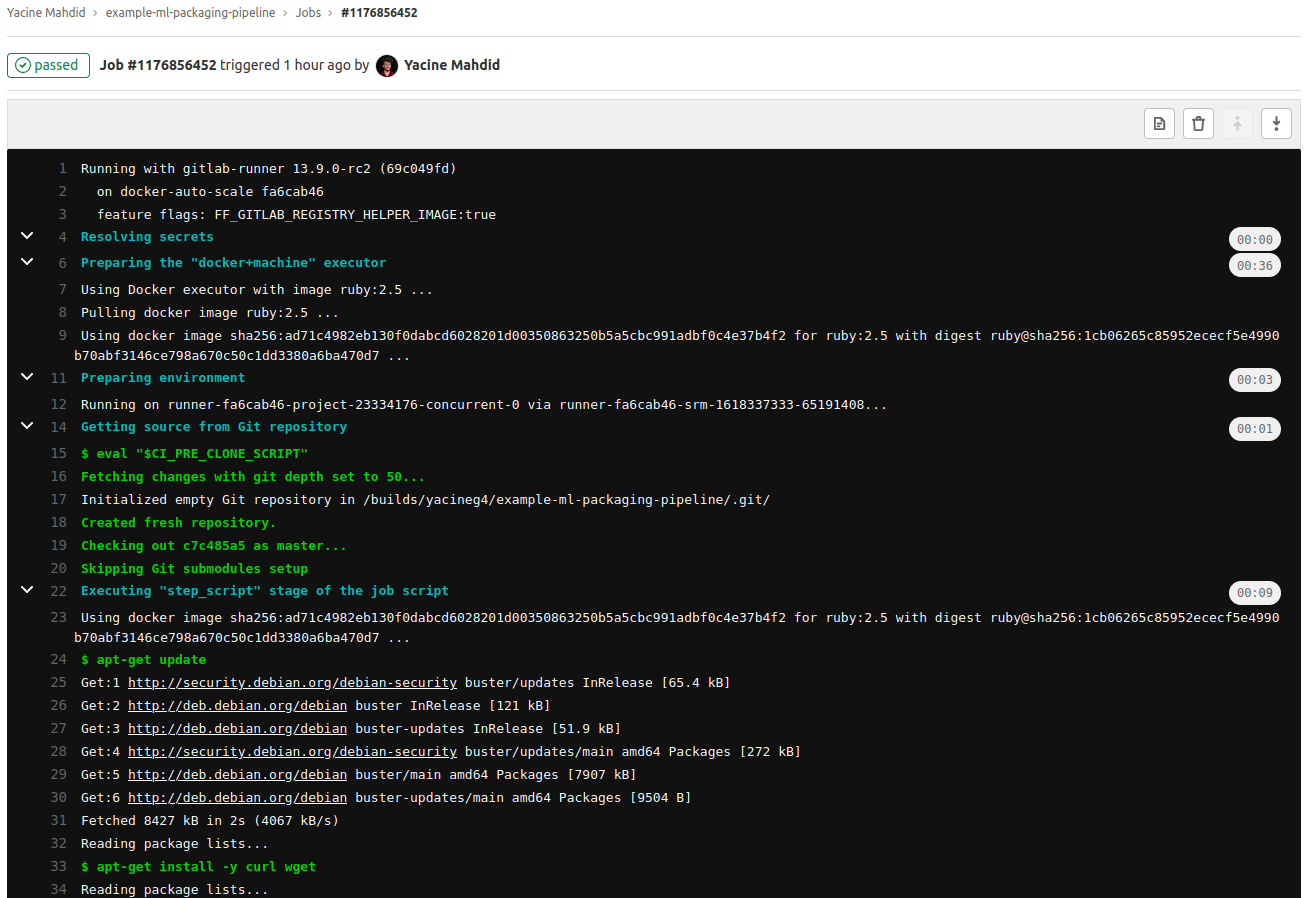
بعد نجاح المهمة، ستصبح الحزمة متاحة داخل قسم الحزم في المشروع، ويمكنك أنت وفريقك الوصول إلى الملفات الصحيحة حسب رقم الإصدار.
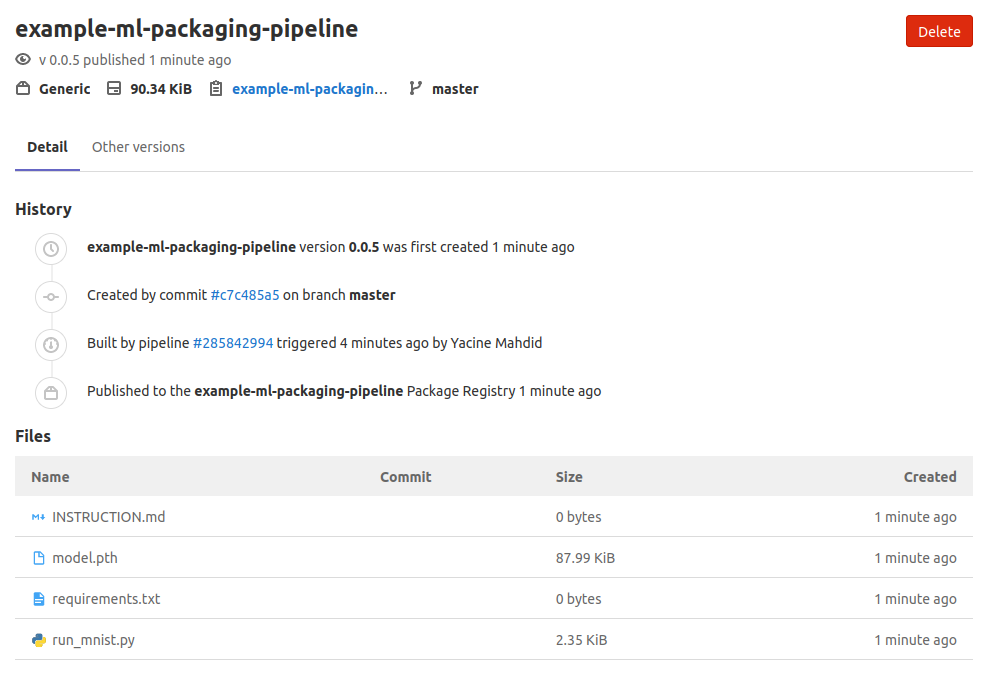
أفضل ممارسات لتحسين الاعتمادية
رغم أن الإعداد السابق بسيط وفعال، إلا أن تحسينه يمنحك عملية نشر أكثر احترافية على المدى الطويل. إليك بعض التوصيات:
- إضافة مرحلة اختبار قبل الرفع للتأكد من أن النموذج والشيفرة يعملان دون أخطاء.
- إضافة فحص لأداء النموذج مثل الدقة أو زمن الاستدلال قبل اعتماد الإصدار.
- إدارة الإصدارات بشكل واضح باستخدام أرقام دلالية مثل
1.0.0. - تجنب رفع ملفات غير ضرورية داخل الحزمة لتقليل الحجم وتسريع التنزيل.
- إرفاق ملف تعليمات واضح يشرح التثبيت والتشغيل ومتطلبات البيئة.
متى تكون هذه الطريقة مفيدة فعلاً؟
هذا النهج مناسب جداً في الحالات التالية:
- عند مشاركة النماذج داخلياً بين أعضاء الفريق.
- عند الحاجة إلى تتبع الإصدارات السابقة من النموذج.
- عند الرغبة في فصل النموذج المنشور عن بقية الشيفرة الخاصة.
- عند بناء سير عمل منظم يربط التدريب والتعبئة والنشر في منصة واحدة.
كما أن استخدام Package Registry يمنحك نقطة توزيع مركزية بدلاً من تبادل الملفات يدوياً عبر البريد أو المحادثات الداخلية.
الخاتمة
تعلمت في هذا المقال كيفية تجهيز نموذج تعلّم آلة، حفظ ملفاته الضرورية، ثم أتمتة نشره إلى GitLab Package Registry باستخدام خط CI/CD بسيط وواضح. هذه الآلية تقلل التدخل اليدوي، وتحسن اتساق الإصدارات، وتسهل على الفريق استهلاك النماذج المحدثة.
ويمكنك تطوير هذا الأسلوب لاحقاً عبر:
- إضافة مراحل اختبار متعددة قبل النشر.
- إرسال إشعارات تلقائية عند إصدار نسخة جديدة.
- الاعتماد على نماذج أكثر كفاءة مثل
TorchScript. - ربط عملية النشر بخط تدريب مؤتمت بالكامل.
الخلاصة التقنية
من الناحية التقنية، يُعد استخدام GitLab Package Registry مع CI/CD وسيلة عملية لإدارة توزيع نماذج تعلّم الآلة داخل الفرق، خاصة عندما تكون الحاجة الأساسية هي الحوكمة، وضبط الإصدارات، وسهولة الوصول. هذا الحل لا يغني عن منصات تقديم النماذج الإنتاجية، لكنه ممتاز كطبقة تنظيم ونشر داخلية، ويمنح فرق التطوير مساراً واضحاً وقابلاً للتوسع مع نمو المشروع.