أفضل 10 مجموعات بيانات للغات الأفريقية لمشاريع علم البيانات
مقدمة: لماذا تُعد مجموعات بيانات اللغات الأفريقية مهمة؟
تضم أفريقيا أكثر من 2000 لغة، ومع ذلك ما تزال هذه اللغات ضعيفة التمثيل في منظومة Natural Language Processing أو معالجة اللغات الطبيعية. وتُعد ندرة مجموعات البيانات الجيدة واحدة من أبرز العقبات التي تحد من تطوير حلول تقنية قادرة على معالجة تحديات اجتماعية واقتصادية حقيقية.
في هذا الدليل، ستجد قائمة مختارة من أفضل مجموعات بيانات اللغات الأفريقية التي يمكن توظيفها في مشاريع علم البيانات ومهام NLP المختلفة، مثل text classification، وnamed entity recognition، وmachine translation، وsentiment analysis، وspeech recognition، وtopic modeling.

مجموعات بيانات تصنيف النصوص
تُستخدم مجموعات بيانات Text Classification في تدريب النماذج على تصنيف المحتوى النصي إلى فئات محددة مسبقاً. وتفيد هذه المهمة في تنظيم الأخبار، وتصنيف الشكاوى، وفرز الرسائل، وتحسين تجربة البحث داخل المنصات الرقمية.
1. مجموعة بيانات أخبار السواحيلية
تضم هذه المجموعة أكثر من 31 ألف مقال إخباري باللغة السواحيلية، موزعة على عدة فئات مثل الأخبار المحلية، والدولية، والأعمال، والصحة، والرياضة، والترفيه.
تُعد السواحيلية من أكثر اللغات انتشاراً في أفريقيا، إذ يتحدث بها ما بين 100 و150 مليون شخص في شرق القارة. وقد جُمعت هذه البيانات من منصات إخبارية متعددة من داخل تنزانيا وخارجها، ما يمنحها قيمة جيدة لبناء نماذج تصنيف متعددة الفئات.
يمكن الاستفادة من هذه المجموعة في إنشاء نموذج يفرز الأخبار تلقائياً بحسب نوعها، وهو أمر مفيد جداً للمواقع الإخبارية التي ترغب في تحسين تنظيم المحتوى وتسهيل وصول القراء إلى الموضوعات التي تهمهم.
يمكن تحميل المجموعة عبر مكتبة datasets في بايثون كما يلي:
from datasets import load_dataset
dataset = load_dataset("swahili_news")ملاحظة تقنية: تحتوي هذه المجموعة على عدم توازن في توزيع الفئات، إذ إن بعض الأقسام تضم عدداً أقل من المقالات، مثل:
- الأخبار الدولية:
6.2% - الأخبار الصحية:
4.9% - أخبار الأعمال:
4.3%
2. مجموعة بيانات أخبار لغة تشيتشيوا
تتكون هذه المجموعة من مقالات إخبارية بلغة Chichewa، وهي لغة من لغات البانتو تُستخدم على نطاق واسع في مناطق من جنوب وشرق أفريقيا، خاصة في مالاوي وزامبيا حيث تُعد لغة رسمية.
تتضمن المجموعة 3,482 مقالاً، وتحتوي على أكثر من 930,000 كلمة، وما يزيد على 48,000 جملة. كما جرى تصنيف المقالات إلى 19 فئة، من بينها التعليم، والقانون والنظام، والسياسة، والثقافة، والفنون، والزراعة، والاقتصاد، والحياة البرية.
تُعد هذه المجموعة مناسبة لتجارب التصنيف الإخباري، وتحليل المحتوى المحلي، وتطوير حلول ذكية موجهة للأسواق الأفريقية الناشئة.
مجموعات بيانات التعرف على الكيانات المسماة
تُستخدم مجموعات بيانات Named Entity Recognition أو NER لاستخراج الكيانات المهمة من النصوص غير المنظمة، مثل أسماء الأشخاص، والمنظمات، والمواقع، والتواريخ، والأزمنة.
ويُعد هذا المجال أساسياً في العديد من التطبيقات، مثل المدققات الإملائية الذكية، والمساعدات الحوارية، وأنظمة الفهرسة، وأدوات الترجمة والتوطين.
3. مجموعات بيانات MasakhaNER
يُعد مشروع Masakhane من أبرز المبادرات المجتمعية الأفريقية في مجال معالجة اللغات الطبيعية، إذ يقوده باحثون ومطورون أفارقة بهدف تعزيز البحث العلمي وبناء موارد لغوية عالية الجودة للغات القارة.
وقد نجح المشروع في إنتاج واحدة من أولى مجموعات البيانات العامة واسعة النطاق وعالية الجودة لمهمة NER في عشر لغات أفريقية، وهي:
- الأمهرية
- الهوسا
- الإيغبو
- الكينيارواندا
- اللوغندية
- اللوو
- البيجين النيجيري
- السواحيلية
- الولوف
- اليوروبا
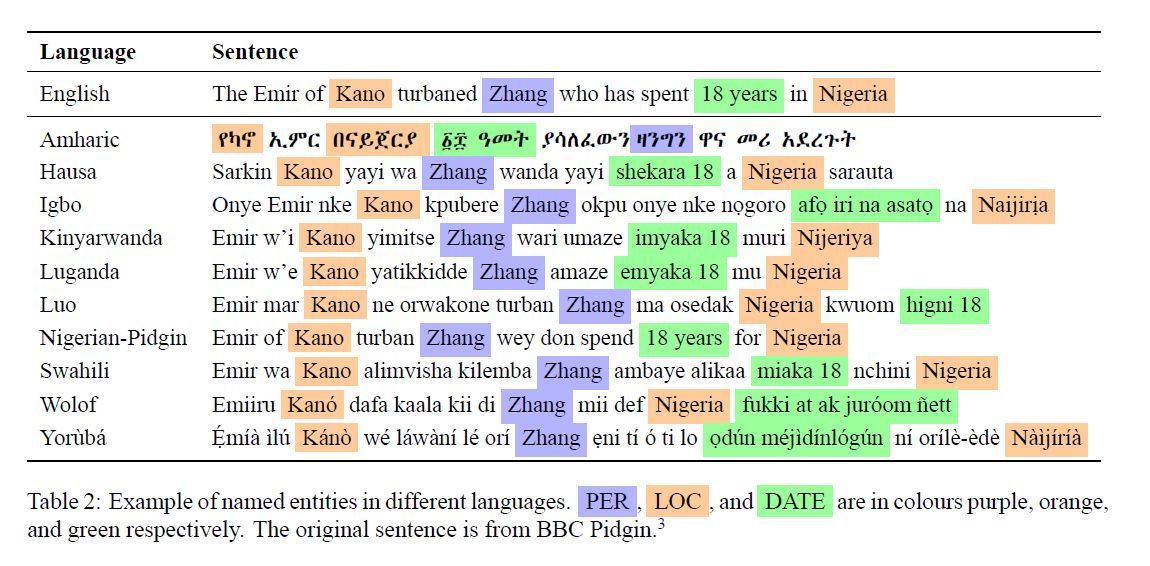
تكمن أهمية هذه المجموعة في أنها تفتح الباب أمام تطوير تطبيقات أكثر دقة في استخراج المعلومات من النصوص الأفريقية، خاصة في البيئات التي تعاني شحاً في الموارد اللغوية.
مجموعات بيانات الترجمة الآلية
تُعنى Machine Translation بترجمة النصوص أو الكلام من لغة مصدر إلى لغة هدف بصورة آلية. وتُستخدم هذه التقنية في ترجمة الوثائق، والتعليمات، والبريد الداخلي، والمحتوى الرقمي، ما يجعلها عنصراً مهماً في تسريع الوصول إلى المعلومات.
4. مجموعة بيانات الترجمة من الفرنسية إلى Ewe ومن الفرنسية إلى Fongbe
هذه المجموعة عبارة عن parallel corpus مخصص للترجمة الآلية من الفرنسية إلى لغتي Ewe وFongbe، وهما من لغات Niger-Congo.
تُستخدم لغة Fongbe في بنين ويتحدث بها نحو 4.1 مليون شخص، بينما تنتشر لغة Ewe في توغو وجنوب شرق غانا ويبلغ عدد المتحدثين بها قرابة 4.5 مليون شخص.
تتضمن المجموعة نحو 23,000 جملة متوازية بين الفرنسية وEwe، وحوالي 53,000 جملة متوازية بين الفرنسية وFongbe. وقد جُمعت البيانات من المدونات، والحكايات، والصحف، والمحادثات اليومية، وصفحات الويب، مع إعدادها لتدريب نماذج الترجمة العصبية.
5. مجموعة بيانات الترجمة من اليوروبا إلى الإنجليزية
تتكون هذه المجموعة من جمل متوازية للترجمة بين لغة Yorùbá واللغة الإنجليزية. وتُعد اليوروبا من لغات Niger-Congo، وتنتشر أساساً في غرب أفريقيا، ولا سيما في جنوب غرب نيجيريا.
يُقدَّر عدد المتحدثين باليوروبا بما بين 45 و55 مليون شخص. وتحتوي المجموعة على 10,054 جملة متوازية مأخوذة من مجالات متنوعة، مثل الأخبار، والأمثال اليوروبية، ونصوص الأفلام، والترجمات المحلية، والكتب.
هذا التنوع في مصادر البيانات يجعل المجموعة مفيدة لبناء نماذج ترجمة أكثر قدرة على التعامل مع السياقات الواقعية.
6. مجموعة بيانات الترجمة من الإنجليزية إلى اللوغندية
تستهدف هذه المجموعة الترجمة الآلية من الإنجليزية إلى لغة Luganda، وهي إحدى لغات البانتو الرئيسية في أوغندا.
يتحدث بهذه اللغة أكثر من 8.5 مليون شخص من شعب الباغاندا، إلى جانب مستخدمين كثيرين في العاصمة كمبالا. وتضم المجموعة 15,022 جملة متوازية بين الإنجليزية واللوغندية.
وقد أُعدت هذه البيانات بواسطة فريق بحثي من مختبر AI and Data Science Research Lab في جامعة Makerere، بالتعاون مع معلمين وطلاب ومستقلين يتقنون اللغة اللوغندية، ما يعزز من موثوقية المحتوى اللغوي.
مجموعات بيانات تحليل المشاعر
تُستخدم مجموعات بيانات Sentiment Analysis في تفسير مشاعر النصوص وتصنيفها إلى إيجابية أو سلبية أو محايدة. وتُعد هذه المهمة مهمة في مراقبة وسائل التواصل الاجتماعي، وتحليل آراء العملاء، وقياس الانطباع عن العلامات التجارية، ودعم أبحاث السوق.
7. مجموعة بيانات Tunizi
تُعتبر Tunizi أول مجموعة بيانات لتحليل المشاعر خاصة بـTunisian Arabizi، وهو أسلوب كتابة للهجة التونسية يعتمد على الحروف اللاتينية والأرقام بدلاً من الحروف العربية.
جمعت منصة iCompass تعليقات من شبكات التواصل الاجتماعي تعبّر عن آراء تجاه موضوعات شائعة، ثم استخرجت نحو 100,000 تعليق باستخدام واجهات برمجة عامة للبث المباشر.
بعد ذلك، جرى توصيف التعليقات يدوياً وفق ثلاث درجات رئيسية:
- إيجابي:
1 - سلبي:
-1 - محايد:
0
ومن الجوانب المهمة في هذه المجموعة أن المشاركين في عملية التوصيف كانوا متنوعين من حيث الجنس والعمر والخلفية الاجتماعية، وهو ما يساعد في تقليل التحيز وتحسين جودة البيانات.
يمكن تحميل هذه المجموعة عبر مكتبة datasets كما يلي:
from datasets import load_dataset
dataset = load_dataset("tunizi")مجموعات بيانات التعرف على الكلام
يشير Speech Recognition أو Automatic Speech Recognition إلى التقنية التي تحلل الكلام البشري وتحوّله إلى مخرجات نصية، غالباً بشكل شبه فوري. ويُعرف هذا المجال أيضاً باسم speech-to-text.
ومن المهم التمييز بينه وبين voice recognition، فالأخير يركز على التعرف على هوية المتحدث، بينما يهتم التعرف على الكلام بفهم المحتوى المنطوق نفسه.
8. مجموعة بيانات التعرف على الكلام بلغة الولوف
لغة Wolof مستخدمة في السنغال وغامبيا وموريتانيا، ويتحدث بها أكثر من 10 ملايين شخص. وفي السنغال وحدها، يتخذها نحو 40% من السكان لغة أم.
تحتوي مجموعة ASR الخاصة بهذه اللغة على 6,683 ملفاً صوتياً مرفقاً بتفريغات نصية، وقد طورها فريق من الباحثين في شركة Baamtu Datamation في السنغال.
تصلح هذه البيانات لبناء نماذج أولية للتفريغ الصوتي، أو لتحسين أدوات النفاذ الرقمي للمحتوى الصوتي المحلي.
9. مجموعة بيانات التعرف على الكلام بلغة الكينيارواندا
تُعد Kinyarwanda لغة من لغات البانتو، كما أنها لغة رسمية في رواندا. ويتحدث بها ما لا يقل عن 12 مليون شخص في رواندا وشرق جمهورية الكونغو الديمقراطية وجنوب أوغندا.
أُنشئت هذه المجموعة بمشاركة 895 متحدثاً من أعمار وأجناس مختلفة عبر منصة Common Voice. وتضم ما مجموعه 1,183 ساعة من المقاطع الصوتية الموثقة، بينما يصل حجمها الحالي إلى نحو 40GB.
ويمثل هذا الحجم فرصة ممتازة لتدريب نماذج أكثر قوة في التعرف على الكلام للهجات وسياقات استخدام متعددة.
مجموعات بيانات نمذجة الموضوعات
تعتمد Topic Modeling على أساليب تعلم غير خاضعة للإشراف لاستخراج الموضوعات الرئيسة من مجموعة كبيرة من الوثائق النصية. وهي مفيدة في اكتشاف الأنماط العامة داخل المحتوى دون الحاجة إلى بيانات معنونة مسبقاً.
10. مجموعة بيانات أخبار جنوب أفريقيا
تتكون هذه المجموعة من عناوين أخبار جُمعت من صفحات SABC4 على Facebook. وتُعد SABC هيئة البث العامة في جنوب أفريقيا.
تشمل البيانات عناوين قصيرة بلغتي Setswana وSepedi. ويتحدث بلغة Setswana نحو 8.2 مليون شخص في جنوب القارة، بينما تُستخدم Sepedi بصورة رئيسية في المناطق الشمالية من جنوب أفريقيا ويصل عدد متحدثيها إلى 4.7 مليون شخص.
وبما أن هذه المجموعة غير معنونة، فهي مناسبة لبناء نماذج topic model تقوم بتجميع الأخبار إلى محاور مثل الرياضة، والسياسة، والثقافة، والترفيه.
كيف تختار مجموعة البيانات المناسبة لمشروعك؟
قبل تنزيل أي مجموعة بيانات، من الأفضل تقييمها وفق مجموعة من المعايير العملية:
- حجم البيانات ومدى كفايته لتدريب النموذج.
- جودة التوصيف أو
annotationإن كانت البيانات معنونة. - تنوع المصادر والسياقات اللغوية.
- درجة التوازن بين الفئات.
- إمكانية استخدام البيانات قانونياً وفق الرخصة المتاحة.
- مدى ملاءمتها للهجة أو اللغة المستهدفة في مشروعك.
كما يُستحسن إجراء معالجة أولية مناسبة، مثل تنظيف النصوص، وإزالة التكرار، وتوحيد الترميز، ومراجعة جودة الأمثلة قبل البدء في التدريب.
مصادر إضافية للبحث عن بيانات لغوية أفريقية
إذا لم تجد المجموعة المناسبة لاحتياجك الحالي، فهناك مصادر مهمة يمكن الرجوع إليها لاكتشاف المزيد من الموارد المفتوحة:
ZenodoلمواردAfrican Natural Language Processing (AfricaNLP)Githubالخاص بمبادرةMasakhane
البحث في هذه المصادر قد يساعدك في الوصول إلى بيانات أحدث أو أكثر تخصصاً، خاصة في اللغات منخفضة الموارد.
الخلاصة التقنية
تمثل مجموعات بيانات اللغات الأفريقية فرصة كبيرة للباحثين والمطورين لبناء حلول أكثر شمولاً وعدالة في مجال الذكاء الاصطناعي اللغوي. وعلى الرغم من أن كثيراً من هذه الموارد ما يزال محدوداً مقارنة باللغات العالمية الكبرى، فإن قيمتها التقنية عالية جداً، خصوصاً في المشاريع التي تستهدف الترجمة، والتصنيف، والتعرف على الكيانات، وتحليل المشاعر، ومعالجة الصوت. من الناحية العملية، أفضل نهج هو اختيار مجموعة بيانات مرتبطة بمشكلة واقعية، ثم تحسينها بالمعالجة المسبقة والتقييم الدقيق للحصول على نموذج مفيد فعلاً للمستخدم النهائي.