كيف تبني نماذج تعلم آلي أفضل: ممارسات عملية لتحسين الأداء وتقليل الأخطاء
مقدمة: لماذا لا يكفي بناء النموذج وحده؟
بناء نماذج تعلم آلي قوية لا يعتمد فقط على اختيار خوارزمية مناسبة، بل يرتبط أيضاً بجودة التجربة، ودقة ضبط الإعدادات، وسلامة التنفيذ، وكفاءة التدريب. عند العمل على الشبكات العصبية العميقة، ستجد أن الوصول إلى نموذج جيد يتطلب سلسلة من القرارات الدقيقة، مثل اختيار معدل التعلم، وعدد الطبقات، وحجم كل طبقة، وآلية إيقاف التدريب، وأساليب الحد من فرط التخصيص.
في هذا المقال ستتعرف على مجموعة من الإرشادات العملية التي تساعدك على تطوير نماذج أفضل بصورة منهجية، مع أمثلة واضحة باستخدام TensorFlow. الهدف هنا ليس تقديم وصفات سحرية، بل عرض أدوات وأساليب مثبتة تساعدك على بناء نموذج أكثر استقراراً وكفاءة.

ضبط المعاملات الفائقة بطريقة أكثر ذكاءً
من أكثر التحديات إزعاجاً في تدريب الشبكات العصبية التعامل مع العدد الكبير من Hyperparameters. وتشمل هذه الإعدادات مثلاً learning rate، وعدد الطبقات، وعدد الوحدات المخفية، واختيارات المحسنات مثل RMSprop وAdam، إلى جانب إعدادات إضافية مثل جداول تغيير معدل التعلم.
إذا تعاملت مع هذه القيم بعشوائية غير منظمة، فستستهلك وقتاً كبيراً دون نتائج واضحة. لذلك من المهم اعتماد أسلوب منظم في البحث عن أفضل التوليفات.
لماذا يُعد Random Search خياراً عملياً؟
بدلاً من تجربة جميع الاحتمالات بطريقة شبكية صارمة، يمكن استخدام Random Search لاختيار نقاط عشوائية من فضاء البحث. هذه الفكرة تبدو بسيطة، لكنها فعالة جداً في كثير من الحالات، خصوصاً عندما يكون لبعض المعاملات تأثير أكبر من غيرها.
على سبيل المثال، إذا كنت تريد تجربة معاملين يتراوحان بين 1 و5، فليس من الضروري اختبار كل التركيبات الممكنة. قد يكون اختيار عدد مناسب من النقاط العشوائية أكثر كفاءة ويوفر نتائج أفضل في وقت أقل.

مثال عملي باستخدام TensorFlow وKerasTuner
import kerastuner as kt
import tensorflow as tf
def model_builder(hp):
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
# Tune the number of units in the first Dense layer
# Choose an optimal value between 32-512
hp_units = hp.Int('units', min_value=32, max_value=512, step=32)
model.add(tf.keras.layers.Dense(units=hp_units, activation='relu'))
model.add(tf.keras.layers.Dense(10))
# Tune the learning rate for the optimizer
# Choose an optimal value from 0.01, 0.001, or 0.0001
hp_learning_rate = hp.Choice('learning_rate', values=[1e-2, 1e-3, 1e-4])
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=hp_learning_rate),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
return model
tuner = kt.RandomSearch(
model_builder,
objective='val_accuracy',
max_trials=10,
directory='random_search_starter',
project_name='intro_to_kt'
)
tuner.search(img_train, label_train, epochs=10, validation_data=(img_test, label_test))
# Which was the best model?
best_model = tuner.get_best_models(1)[0]
# What were the best hyperparameters?
best_hyperparameters = tuner.get_best_hyperparameters(1)[0]في هذا المثال، يتم البحث عن أفضل عدد وحدات في أول طبقة Dense ضمن المجال من 32 إلى 512، مع خطوة مقدارها 32. كما يتم اختبار ثلاثة احتمالات فقط لمعدل التعلم باستخدام hp.Choice().
hp_units = hp.Int('units', min_value=32, max_value=512, step=32)
model.add(tf.keras.layers.Dense(units=hp_units, activation='relu'))hp_learning_rate = hp.Choice('learning_rate', values=[1e-2, 1e-3, 1e-4])
optimizer = tf.keras.optimizers.Adam(learning_rate=hp_learning_rate)بعد ذلك، يحدد RandomSearch أن الهدف هو تعظيم قيمة val_accuracy، أي اختيار النموذج الذي يحقق أفضل دقة على بيانات التحقق.
tuner = kt.RandomSearch(
model_builder,
objective='val_accuracy',
max_trials=10,
directory='random_search_starter',
project_name='intro_to_kt'
)
tuner.search(img_train, label_train, epochs=10, validation_data=(img_test, label_test))ويمكن بعد انتهاء البحث استخراج أفضل نموذج وأفضل إعدادات:
# Which was the best model?
best_model = tuner.get_best_models(1)[0]
# What were the best hyperparameters?
best_hyperparameters = tuner.get_best_hyperparameters(1)[0]لكن من المهم ملاحظة أن استخدام get_best_models() يُعد اختصاراً عملياً فقط. للحصول على أفضل أداء فعلي، من الأفضل إعادة تدريب النموذج من البداية باستخدام أفضل hyperparameters على كامل البيانات المتاحة.
تسريع التدريب باستخدام Mixed Precision Training
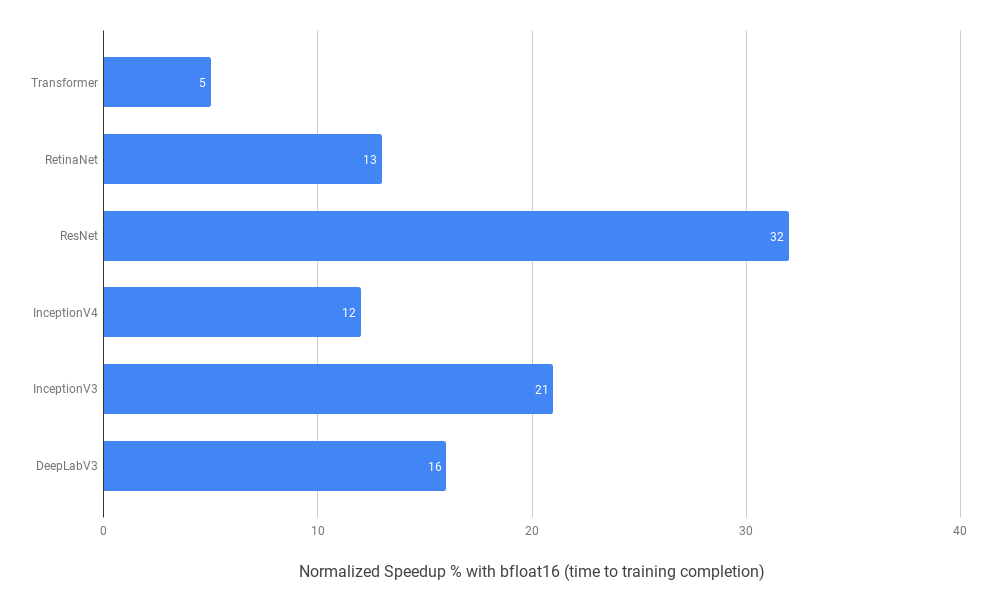
كلما كبر حجم الشبكة العصبية، زادت عادة قدرتها على تمثيل الأنماط المعقدة، لكن ذلك يرفع أيضاً متطلبات الذاكرة والحوسبة. هنا تبرز فائدة Mixed Precision Training، وهي تقنية تعتمد على استخدام أعداد عشرية منخفضة الدقة مثل float16 في أجزاء كبيرة من التدريب، مع الحفاظ على دقة أعلى في المواضع الحساسة.
الفائدة الأساسية من هذا الأسلوب هي تسريع التدريب وتقليل استهلاك الذاكرة، مع تأثير محدود جداً أو شبه معدوم على الأداء النهائي للنموذج، خاصة عند تدريب النماذج الكبيرة جداً.
متى يكون هذا الأسلوب مناسباً؟
- عند التعامل مع نماذج ضخمة تحتوي على عدد هائل من المعاملات.
- عند استخدام عتاد حديث مثل بطاقات
NVIDIA GPUالحديثة أوCloud TPU. - عندما يكون عنق الزجاجة مرتبطاً بسرعة التدريب واستهلاك الذاكرة.
غالباً لن تظهر الفائدة القصوى مع النماذج الصغيرة، لذلك لا يُنصح باعتباره خطوة افتراضية لكل مشروع.
مثال تطبيقي باستخدام TensorFlow
import tensorflow as tf
policy = tf.keras.mixed_precision.Policy('mixed_float16')
tf.keras.mixed_precision.set_global_policy(policy)
inputs = keras.Input(shape=(784,))
x = tf.keras.layers.Dense(4096, activation='relu')(inputs)
x = tf.keras.layers.Dense(4096, activation='relu')(x)
x = layers.Dense(10)(x)
outputs = layers.Activation('softmax', dtype='float32')(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(...)
model.fit(...)في هذا المثال يتم أولاً تعيين سياسة البيانات إلى mixed_float16، ما يجعل الطبقات تستخدم float16 تلقائياً. لكن طبقة الإخراج تُجبر على استخدام float32 لتجنب المشكلات الرقمية المحتملة. وهذه ممارسة موصى بها خصوصاً في طبقات الإخراج النهائية.
ومن مزايا هذا الأسلوب أيضاً أنك تستطيع غالباً زيادة حجم batch size لأن استخدام float16 يخفف الضغط على الذاكرة.
استخدام Gradient Check لاكتشاف أخطاء Backpropagation
عند بناء شبكة عصبية مخصصة يدوياً، فإن تنفيذ backpropagation يعد من أكثر الأجزاء عرضة للأخطاء. المشكلة أن النموذج قد يتعلم شيئاً يبدو مقبولاً ظاهرياً، رغم وجود خلل رياضي داخلي، ما يجعل اكتشاف الخطأ صعباً.
هنا يفيد أسلوب Gradient Check، والذي يعتمد على تقريب التدرجات عددياً، ثم مقارنة هذه القيم مع التدرجات التي حسبتها خوارزمية backpropagation. إذا كانت القيمتان متقاربتين جداً، فهذه إشارة جيدة إلى أن التنفيذ صحيح.
الفكرة الأساسية هي حساب متجه تقريبي للتدرجات يشار إليه عادة باسم dθ[approx].
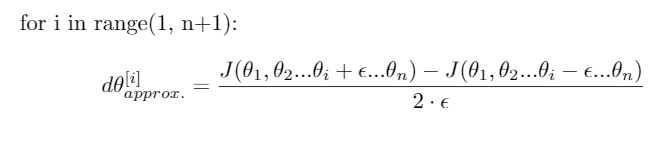
بعد ذلك تتم مقارنة dθ[approx] مع dθ الناتج عن backpropagation، وغالباً ما تستخدم المسافة الإقليدية بين المتجهين كمؤشر تشخيصي.

هذا الأسلوب مهم خصوصاً في الحالات التالية:
- عند تنفيذ شبكة عصبية من الصفر.
- عند كتابة دوال خسارة مخصصة.
- عند تطوير طبقات أو عمليات رياضية جديدة غير جاهزة.
تخزين مجموعات البيانات مؤقتاً لتحسين سرعة التدريب
تخزين البيانات مؤقتاً أو ما يعرف بـ Caching من الأفكار البسيطة والفعالة التي لا تُستخدم بالقدر الكافي. الفكرة هي تحميل البيانات أو معالجتها مرة واحدة، ثم حفظها في الذاكرة أو في ملف وسيط، حتى لا تضطر لإعادة تنفيذ العمليات المكلفة مع كل epoch.
هذا يعني أن أول دورة تدريب قد تستغرق وقتاً أطول قليلاً، لأن النظام سيقرأ الملفات ويعالج البيانات ثم يخزنها. لكن الدورات اللاحقة تصبح أسرع بوضوح، لأن البيانات تصبح جاهزة للاستخدام المباشر.
تشمل الفوائد العملية لهذه الخطوة:
- تقليل عمليات فتح الملفات المتكررة.
- خفض زمن القراءة من القرص.
- تخفيف الضغط على المعالج أثناء التدريب.
- رفع كفاءة خط أنابيب البيانات.

كيف تعالج فرط التخصيص Overfitting؟
فرط التخصيص من أشهر المشكلات التي تواجه مطوري النماذج، ويحدث عندما يتعلم النموذج تفاصيل وضجيج بيانات التدريب بدرجة تجعله ضعيف التعميم على بيانات جديدة. وفي المقابل، يحدث Underfitting عندما يكون النموذج بسيطاً أكثر من اللازم ولا يلتقط العلاقات المهمة في البيانات.
أفضل حل نظري لفرط التخصيص هو الحصول على بيانات أكثر. وإذا لم يكن ذلك ممكناً، يمكن اللجوء إلى زيادة البيانات أو تعديل بنية النموذج أو تطبيق تقنيات تنظيمية على الأوزان.
أولاً: تعديل بنية النموذج
أحياناً يكون النموذج أكبر من اللازم مقارنة بحجم البيانات أو تعقيد المهمة. في هذه الحالة يمكن:
- تقليل عدد الطبقات أو الوحدات.
- استخدام
Random Searchللعثور على بنية أكثر ملاءمة. - تطبيق
Pruningلإزالة العقد أو الاتصالات الأقل أهمية.
ثانياً: تعديل أوزان الشبكة بطرق تنظيمية
هناك عدة تقنيات فعالة تساعد على ضبط سلوك الأوزان وتقليل الميل إلى فرط التخصيص.
تنظيم الأوزان باستخدام L1 وL2
الفكرة هنا أن النماذج الأبسط تميل إلى التعميم بصورة أفضل. لذلك نضيف إلى دالة الخسارة عقوبة على الأوزان الكبيرة. هذه العقوبة تحد من التعقيد الزائد وتدفع الأوزان إلى قيم أصغر.
L1: يضيف عقوبة تتناسب مع القيمة المطلقة للأوزان.L2: يضيف عقوبة تتناسب مع مربع قيمة الأوزان.
عملياً، يدفع L1 بعض الأوزان إلى الصفر تماماً، بينما يميل L2 إلى تقليصها دون تصفير كامل في العادة. ولهذا يُستخدم L2 كثيراً في التطبيقات العملية.
import tensorflow as tf
tf.keras.layers.Dense(
3,
kernel_regularizer=tf.keras.regularizers.L2(0.1)
)في هذا المثال تتم إضافة حد عقابي إلى الخسارة على صورة 0.1 × weight_coefficient_value²، ما يجعل الأوزان الكبيرة أكثر كلفة أثناء التعلم.
استخدام Dropout
Dropout من أول الخيارات العملية التي تُستخدم عند ظهور مؤشرات فرط التخصيص. وتعتمد الفكرة على تعطيل نسبة عشوائية من مخرجات الطبقة أثناء التدريب، بحيث لا تعتمد الوحدات على بعضها بصورة مبالغ فيها.
هذه التقنية تساعد على بناء تمثيلات أكثر عمومية، وتقلل من ظاهرة التكيف المشترك بين العقد.
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), padding='same', activation='relu', input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(128, (3, 3), padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])كما ترى، يمكن ببساطة استخدام الطبقة tf.keras.layers.Dropout وتمرير النسبة المراد تجاهلها، مثل 0.2 أي 20% من المخرجات خلال التدريب.
الإيقاف المبكر باستخدام Early Stopping
Early Stopping من أكثر الوسائل العملية فعالية وبساطة. تقوم الفكرة على مراقبة أداء النموذج على مجموعة التحقق أثناء التدريب، ثم إيقاف التدريب تلقائياً عندما يتوقف التحسن.
بدلاً من الاستمرار في التدريب حتى يبدأ النموذج بحفظ بيانات التدريب، يتم إنهاء العملية عند النقطة المناسبة، ما يساعد على تقليل فرط التخصيص وتوفير الوقت والموارد.
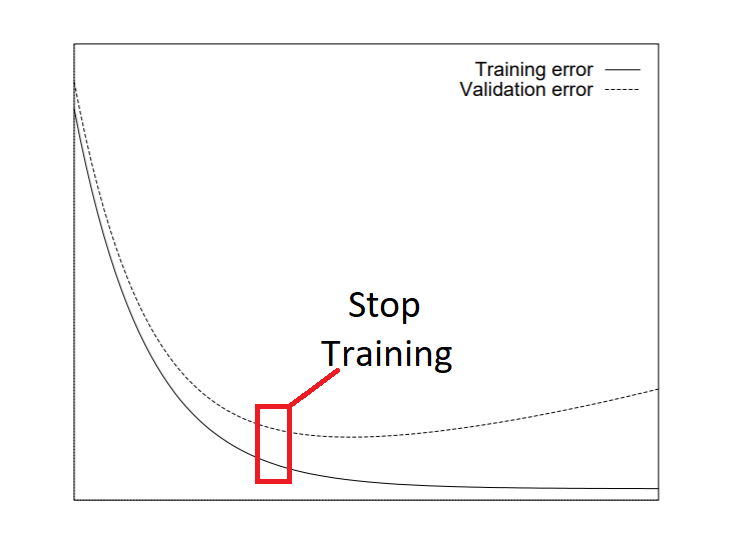
ويُنظر إلى هذه التقنية على أنها من أجمل وسائل التنظيم لأنها بسيطة وسريعة ولا تتطلب تعديلات معقدة على بنية النموذج.
import tensorflow as tf
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=3)
model = tf.keras.models.Sequential([...])
model.compile(...)
model.fit(..., callbacks=[callback])في هذا المثال تتم مراقبة قيمة loss، وإذا لم يحدث تحسن ملحوظ لمدة 3 دورات تدريبية متتالية، يتوقف التدريب تلقائياً. ويمكن استخدام هذا الأسلوب سواء مع نماذج Sequential أو Functional API أو النماذج المبنية بالوراثة.
ملخص عملي لأفضل الأساليب المذكورة
| الأسلوب | الفائدة الأساسية | متى يُستخدم؟ |
|---|---|---|
Random Search |
تحسين ضبط المعاملات الفائقة بكفاءة | عند وجود مساحة بحث كبيرة |
Mixed Precision Training |
تسريع التدريب وتقليل استهلاك الذاكرة | مع النماذج الكبيرة والعتاد الحديث |
Gradient Check |
التحقق من صحة التدرجات | عند تنفيذ backpropagation يدوياً |
Caching |
تسريع تغذية البيانات أثناء التدريب | عند تكرار القراءة والمعالجة لكل epoch |
L2 Regularization |
تقليل تعقيد الأوزان | عند ظهور فرط تخصيص |
Dropout |
تحسين التعميم ومنع الاعتماد الزائد بين العقد | في النماذج المعرضة لفرط التخصيص |
Early Stopping |
إيقاف التدريب عند توقف التحسن | عند مراقبة أداء التحقق باستمرار |
الخلاصة التقنية
تحسين نموذج تعلم الآلة لا يتحقق غالباً عبر تعديل واحد فقط، بل من خلال منظومة متكاملة تشمل ضبط hyperparameters، وتسريع التدريب، ومراقبة صحة التدرجات، وتحسين خط إدخال البيانات، وتقليل فرط التخصيص بوسائل مدروسة. من الناحية العملية، إذا أردت أكبر أثر بأقل تعقيد، فابدأ بـ Random Search، ثم فعّل Early Stopping وDropout، واهتم بتسريع البيانات عبر Caching. أما إذا كنت تعمل على نماذج ضخمة، فإن Mixed Precision Training قد يمنحك قفزة واضحة في الأداء. القيمة الحقيقية لا تأتي من استخدام كل التقنيات دفعة واحدة، بل من اختيار التقنية المناسبة للمشكلة المناسبة.