كيفية بناء شبكة عصبية من الصفر باستخدام بايتورش (PyTorch)

في هذا المقال، سنغوص في أعماق الشبكات العصبية لنتعلم كيفية بنائها من الألف إلى الياء. أكثر ما يثير حماسي في مجال التعلم العميق هو القدرة على التلاعب بالتعليمات البرمجية لبناء شيء من الصفر. ورغم أن هذه المهمة ليست سهلة، فإن تعليمها للآخرين أصعب. لقد استلهمت هذه المدونة بشكل كبير من تجربتي في دورة Fast.ai. دون مزيد من التأخير، دعونا نبدأ رحلتنا المذهلة لكشف الغموض عن الشبكات العصبية.
كيف تعمل الشبكات العصبية؟
لنبدأ بفهم كيفية عمل الشبكات العصبية على مستوى عالٍ. تأخذ الشبكة العصبية مجموعة بيانات وتُخرج تنبؤًا. الأمر بهذه البساطة.
دعوني أقدم لكم مثالاً. لنفترض أن أحد أصدقائك (الذي ليس من كبار مشجعي كرة القدم) يشير إلى صورة قديمة للاعب كرة قدم مشهور – لنقل ليونيل ميسي – ويسألك عنه. ستتمكن من التعرف على اللاعب في ثانية واحدة. والسبب هو أنك رأيت صوره آلاف المرات من قبل. لذا يمكنك التعرف عليه حتى لو كانت الصورة قديمة أو التُقطت في إضاءة خافتة. ولكن ماذا لو عرضت عليك صورة للاعب بيسبول مشهور (ولم ترَ لعبة بيسبول واحدة من قبل)؟ لن تتمكن من التعرف على هذا اللاعب. في هذه الحالة، حتى لو كانت الصورة واضحة ومشرقة، فلن تعرف من هو.
هذا هو نفس المبدأ المستخدم للشبكات العصبية. إذا كان هدفنا هو بناء شبكة عصبية للتعرف على القطط والكلاب، فإننا ببساطة نعرض على الشبكة العصبية مجموعة من صور الكلاب والقطط. وبشكل أكثر تحديدًا، نعرض على الشبكة العصبية صور الكلاب ثم نخبرها أن هذه كلاب. ثم نعرض عليها صور القطط، ونحددها على أنها قطط. بمجرد تدريب شبكتنا العصبية باستخدام صور القطط والكلاب، يمكنها بسهولة تصنيف ما إذا كانت الصورة تحتوي على قطة أو كلب. باختصار، يمكنها التعرف على القطة من الكلب. ولكن إذا عرضت على شبكتنا العصبية صورة لحصان أو نسر، فلن تتعرف عليها أبدًا على أنها حصان أو نسر. هذا لأنها لم ترَ صورة لحصان أو نسر من قبل لأننا لم نعرض عليها تلك الحيوانات.
إذا كنت ترغب في تحسين قدرة الشبكة العصبية، فكل ما عليك فعله هو عرض صور لجميع الحيوانات التي تريد أن تصنفها الشبكة العصبية. حتى الآن، كل ما تعرفه هو القطط والكلاب ولا شيء آخر. تعتمد مجموعة البيانات التي نستخدمها لتدريبنا بشكل كبير على المشكلة المطروحة. إذا كنت ترغب في تصنيف ما إذا كانت التغريدة تحمل شعورًا إيجابيًا أو سلبيًا، فمن المحتمل أنك سترغب في مجموعة بيانات تحتوي على الكثير من التغريدات مع تسمياتها المقابلة على أنها إيجابية أو سلبية. الآن بعد أن أصبح لديك نظرة عامة عالية المستوى على مجموعات البيانات وكيف تتعلم الشبكة العصبية من تلك البيانات، دعنا نتعمق أكثر في كيفية عمل الشبكات العصبية.
فهم الشبكات العصبية
سنقوم ببناء شبكة عصبية لتصنيف الأرقام ثلاثة وسبعة من صورة. ولكن قبل أن نبني شبكتنا العصبية، نحتاج إلى التعمق أكثر لفهم كيفية عملها. كل صورة نمررها إلى شبكتنا العصبية هي مجرد مجموعة من الأرقام. أي أن كل صورة من صورنا بحجم 28x28 بكسل، مما يعني أنها تحتوي على 28 صفًا و 28 عمودًا، تمامًا مثل المصفوفة. نحن نرى كل رقم كصورة كاملة، ولكن بالنسبة للشبكة العصبية، إنها مجرد مجموعة من الأرقام تتراوح من 0 إلى 255. إليك تمثيل بكسل للرقم خمسة:

كما ترى أعلاه، لدينا 28 صفًا و 28 عمودًا (يبدأ الفهرس من 0 وينتهي عند 27) تمامًا مثل المصفوفة. لا ترى الشبكات العصبية سوى هذه المصفوفات ذات الحجم 28x28. لإظهار المزيد من التفاصيل، عرضت الظل جنبًا إلى جنب مع قيم البكسل. إذا نظرت عن كثب إلى الصورة، يمكنك أن ترى أن قيم البكسل القريبة من 255 تكون أغمق بينما القيم القريبة من 0 تكون أفتح في الظل. في PyTorch، لا نستخدم مصطلح “مصفوفة” (matrix). بدلاً من ذلك، نستخدم مصطلح “موتر” (tensor). يتم تمثيل كل رقم في PyTorch كموتر. لذا، من الآن فصاعدًا، سنستخدم مصطلح tensor بدلاً من matrix.
تصور الشبكة العصبية
يمكن أن تحتوي الشبكة العصبية على أي عدد من الخلايا العصبية (neurons) والطبقات (layers). هكذا تبدو الشبكة العصبية:
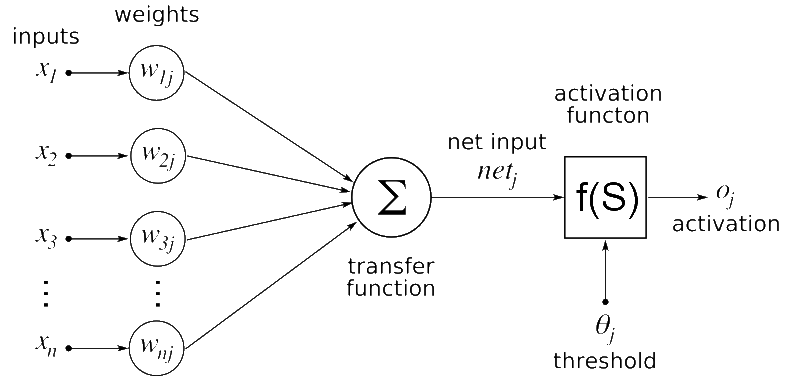
لا تدع الحروف اليونانية في الصورة تربكك. سأشرحها لك: لنأخذ حالة التنبؤ بما إذا كان المريض سيعيش أم لا بناءً على مجموعة بيانات تحتوي على اسم المريض، درجة الحرارة، ضغط الدم، حالة القلب، الراتب الشهري، والعمر. في مجموعة بياناتنا، فقط درجة الحرارة، ضغط الدم، حالة القلب، والعمر لها أهمية كبيرة للتنبؤ بما إذا كان المريض سيعيش أم لا. لذا سنخصص قيمة وزن (weight) أعلى لهذه القيم لإظهار أهمية أكبر. لكن ميزات مثل اسم المريض والراتب الشهري ليس لها تأثير يذكر أو لا تأثير على معدل بقاء المريض. لذا نخصص قيم وزن أصغر لهذه الميزات لإظهار أهمية أقل.
في الشكل أعلاه، تمثل x1, x2, x3...xn الميزات في مجموعة بياناتنا والتي قد تكون قيم بكسل في حالة بيانات الصور أو ميزات مثل ضغط الدم أو حالة القلب كما في المثال أعلاه. تُضرب قيم الميزات بقيم الأوزان المقابلة المشار إليها باسم w1j, w2j, w3j...wnj. تُجمع القيم المضروبة معًا وتُمرر إلى الطبقة التالية. تُتعلم قيم الأوزان المثلى أثناء تدريب الشبكة العصبية. تُحدّث قيم الأوزان باستمرار بطريقة تزيد من عدد التنبؤات الصحيحة. وظيفة التنشيط (activation function) ليست سوى دالة sigmoid في حالتنا. أي قيمة نمررها إلى sigmoid تُحوّل إلى قيمة تتراوح بين 0 و 1. نحن ببساطة نضع دالة sigmoid فوق تنبؤ شبكتنا العصبية للحصول على قيمة بين 0 و 1. ستفهم أهمية طبقة sigmoid بمجرد أن نبدأ في بناء نموذج شبكتنا العصبية. هناك العديد من دوال التنشيط الأخرى الأبسط في التعلم من sigmoid. هذه هي معادلة دالة sigmoid:
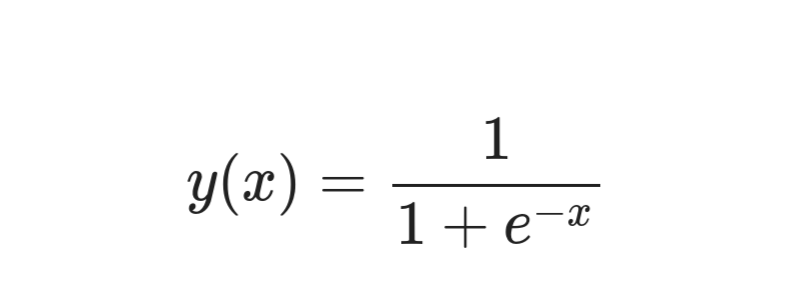
تسمى العقد ذات الشكل الدائري في الرسم البياني “الخلايا العصبية” (neurons). في كل طبقة من طبقات الشبكة العصبية، تُضرب الأوزان (weights) ببيانات الإدخال. يمكننا زيادة عمق الشبكة العصبية بزيادة عدد الطبقات. ويمكننا تحسين سعة الطبقة بزيادة عدد الخلايا العصبية فيها.
فهم مجموعة بياناتنا
أول شيء نحتاجه لتدريب شبكتنا العصبية هو مجموعة البيانات (data set). بما أن هدف شبكتنا العصبية هو تصنيف ما إذا كانت الصورة تحتوي على الرقم ثلاثة أو سبعة، فنحن بحاجة إلى تدريب شبكتنا العصبية باستخدام صور للأرقام ثلاثة وسبعة. لذا، دعنا نبني مجموعة بياناتنا. لحسن الحظ، لا يتعين علينا إنشاء مجموعة البيانات من الصفر. مجموعتنا البيانات موجودة بالفعل في PyTorch. كل ما علينا فعله هو تنزيلها وإجراء بعض العمليات الأساسية عليها. نحتاج إلى تنزيل مجموعة بيانات تسمى MNIST (معهد المعايير والتكنولوجيا الوطني المعدل) من مكتبة torchvision في PyTorch. الآن دعنا نتعمق أكثر في مجموعة بياناتنا.
ما هي مجموعة بيانات MNIST؟
تحتوي مجموعة بيانات MNIST على أرقام مكتوبة بخط اليد من صفر إلى تسعة مع تسمياتها المقابلة كما هو موضح أدناه:

لذا، ما نفعله هو ببساطة تغذية الشبكة العصبية بصور الأرقام وتسمياتها المقابلة التي تخبر الشبكة العصبية أن هذا الرقم هو ثلاثة أو سبعة.
كيفية إعداد مجموعة بياناتنا
تحتوي مجموعة بيانات MNIST التي تم تنزيلها على صور وتسمياتها المقابلة. سنقوم بكتابة التعليمات البرمجية لاستخراج الصور التي تحمل تسمية الرقم ثلاثة أو سبعة فقط. وبالتالي، نحصل على مجموعة بيانات مكونة من الأرقام ثلاثة وسبعة. أولاً، دعنا نستورد جميع المكتبات الضرورية.
import torch
from torchvision import datasets
import matplotlib.pyplot as pltنستورد مكتبة PyTorch لبناء شبكتنا العصبية ومكتبة torchvision لتنزيل مجموعة بيانات MNIST، كما ناقشنا سابقًا. تُستخدم مكتبة Matplotlib لعرض الصور من مجموعة بياناتنا. الآن، دعنا نُعدّ مجموعة بياناتنا.
mnist = datasets.MNIST( './data' , download= True )
threes = mnist.data[(mnist.targets == 3 )]/ 255.0
sevens = mnist.data[(mnist.targets == 7 )]/ 255.0
len(threes), len(sevens)كما تعلمنا أعلاه، يتم تمثيل كل شيء في PyTorch كموترات (tensors). لذا فإن مجموعة بياناتنا أيضًا في شكل موترات. نقوم بتنزيل مجموعة البيانات في السطر الأول. ثم نستخرج فقط الصور التي تكون قيمة الهدف (target) لها مساوية لـ 3 أو 7 ونقوم بتطبيعها (normalize) بقسمتها على 255 وتخزينها بشكل منفصل. يمكننا التحقق مما إذا كان الفهرسة (indexing) قد تمت بشكل صحيح عن طريق تشغيل التعليمات البرمجية في السطر الأخير التي تُعطي عدد الصور في موترات threes و sevens. الآن دعنا نتحقق مما إذا كنا قد أعددنا مجموعة بياناتنا بشكل صحيح.
def show_image ( img ):
plt.imshow(img)
plt.xticks([])
plt.yticks([])
plt.show()
show_image(threes[ 3 ])
show_image(sevens[ 8 ])باستخدام مكتبة Matplotlib، ننشئ دالة لعرض الصور. دعنا نجري فحصًا سريعًا للتأكد من صحة البيانات (sanity check) عن طريق طباعة شكل موتراتنا (tensors).
print(threes.shape, sevens.shape)إذا سار كل شيء على ما يرام، ستحصل على حجم موترات threes و sevens كـ ([6131, 28, 28]) و ([6265, 28, 28]) على التوالي. هذا يعني أن لدينا 6131 صورة بحجم 28x28 للرقم ثلاثة و 6265 صورة بحجم 28x28 للرقم سبعة. لقد أنشأنا موترين يحتويان على صور للأرقام ثلاثة وسبعة. الآن نحتاج إلى دمجها في مجموعة بيانات واحدة لتغذية شبكتنا العصبية.
combined_data = torch.cat([threes, sevens])
combined_data.shapeسنقوم بدمج الموترين (tensors) باستخدام PyTorch والتحقق من شكل مجموعة البيانات المدمجة. الآن سنقوم بتسطيح الصور في مجموعة البيانات.
flat_imgs = combined_data.view(( -1 , 28 * 28 ))
flat_imgs.shapeسنقوم بتسطيح الصور بطريقة تجعل كل صورة بحجم 28x28 تصبح صفًا واحدًا يحتوي على 784 عمودًا (28x28=784). وبالتالي يتحول الشكل إلى ([12396, 784]). نحتاج إلى إنشاء تسميات (labels) تتوافق مع الصور في مجموعة البيانات المدمجة.
target = torch.tensor([ 1 ]*len(threes)+[ 2 ]*len(sevens))
target.shapeنُعيّن التسمية 1 للصور التي تحتوي على الرقم ثلاثة، والتسمية 2 للصور التي تحتوي على الرقم سبعة. (ملاحظة: في الممارسات الشائعة لتصنيف الفئتين، غالبًا ما تستخدم التسمية 0 للفئة الثانية، ولكن هنا تم استخدام 2.)
كيفية تدريب شبكتك العصبية
لتدريب شبكتك العصبية، اتبع هذه الخطوات.
الخطوة 1: بناء النموذج
أدناه يمكنك رؤية أبسط معادلة توضح كيفية عمل الشبكات العصبية: y = Wx + b. هنا، يشير المصطلح 'y' إلى تنبؤنا، أي الرقم ثلاثة أو سبعة. ويشير 'W' إلى قيم الأوزان (weights) الخاصة بنا، ويشير 'x' إلى صورة الإدخال (input image) الخاصة بنا، و 'b' هو الانحياز (bias) (الذي يساعد، جنبًا إلى جنب مع الأوزان، في إجراء التنبؤات). باختصار، نضرب كل قيمة بكسل بقيم الأوزان ونضيفها إلى قيمة الانحياز. تحدد قيم الأوزان والانحياز أهمية كل قيمة بكسل أثناء إجراء التنبؤات.
نحن نصنف الرقمين ثلاثة وسبعة، لذا لدينا فئتان فقط للتنبؤ بهما. لذلك، يمكننا التنبؤ بـ 1 إذا كانت الصورة ثلاثة و 0 إذا كانت الصورة سبعة. قد يكون التنبؤ الذي نحصل عليه من هذه الخطوة أي رقم حقيقي، ولكننا نحتاج إلى جعل نموذجنا (الشبكة العصبية) يتنبأ بقيمة بين 0 و 1. يتيح لنا هذا إنشاء عتبة (threshold) قدرها 0.5. أي، إذا كانت القيمة المتوقعة أقل من 0.5، فهي سبعة. وإلا فهي ثلاثة. نستخدم دالة sigmoid للحصول على قيمة بين 0 و 1. سننشئ دالة لـ sigmoid باستخدام نفس المعادلة الموضحة سابقًا. ثم نمرر القيم من الشبكة العصبية إلى sigmoid. سنقوم بإنشاء شبكة عصبية ذات طبقة واحدة. لا يمكننا إنشاء الكثير من الحلقات لضرب كل قيمة وزن بكل بكسل في الصورة، لأن ذلك مكلف للغاية. لذلك يمكننا استخدام “خدعة سحرية” لإجراء عملية الضرب بأكملها دفعة واحدة باستخدام ضرب المصفوفات (matrix multiplication).
def sigmoid ( x ):
return 1 /( 1 +torch.exp(-x))
def simple_nn ( data, weights, bias ):
return sigmoid((data@weights) + bias)الخطوة 2: تحديد دالة الخسارة (Loss Function)
الآن، نحتاج إلى دالة خسارة (loss function) لحساب مدى اختلاف قيمتنا المتوقعة عن القيمة الحقيقية (ground truth). على سبيل المثال، إذا كانت القيمة المتوقعة 0.3 ولكن القيمة الحقيقية هي 1، فإن خسارتنا عالية جدًا. لذلك سيحاول نموذجنا تقليل هذه الخسارة عن طريق تحديث الأوزان (weights) والانحياز (bias) بحيث تصبح تنبؤاتنا قريبة من القيمة الحقيقية. سنستخدم متوسط الخطأ التربيعي (mean squared error) للتحقق من قيمة الخسارة. يحسب متوسط الخطأ التربيعي متوسط مربع الفرق بين القيمة المتوقعة والقيمة الحقيقية.
def error ( pred, target ):
return ((pred-target)** 2 ).mean()الخطوة 3: تهيئة قيم الأوزان
نحن ببساطة نهيئ الأوزان (weights) والانحياز (bias) بشكل عشوائي. لاحقًا، سنرى كيف تُحدّث هذه القيم للحصول على أفضل التنبؤات.
w = torch.randn((flat_imgs.shape[ 1 ], 1 ), requires_grad= True )
b = torch.randn(( 1 , 1 ), requires_grad= True )يجب أن يكون شكل قيم الأوزان (weights) على النحو التالي: (عدد الخلايا العصبية في الطبقة السابقة، عدد الخلايا العصبية في الطبقة التالية). نستخدم طريقة تسمى “الانحدار التدرجي” (gradient descent) لتحديث أوزاننا وانحيازاتنا (bias) لتحقيق أقصى عدد من التنبؤات الصحيحة. هدفنا هو تحسين أو تقليل خسارتنا، لذا فإن أفضل طريقة هي حساب التدرجات (gradients). نحتاج إلى أخذ المشتقة لكل وزن وانحياز بالنسبة لدالة الخسارة. ثم يجب علينا طرح هذه القيمة من أوزاننا وانحيازاتنا. بهذه الطريقة، تُحدّث قيم أوزاننا وانحيازاتنا بطريقة تجعل نموذجنا يقدم تنبؤًا جيدًا. تحديث معلمة لتحسين دالة ليس شيئًا جديدًا – يمكنك تحسين أي دالة عشوائية باستخدام التدرجات. لقد قمنا بتعيين معلمة خاصة (تسمى requires_grad) إلى true لحساب تدرج الأوزان والانحياز.
الخطوة 4: تحديث الأوزان
إذا لم يقترب تنبؤنا من القيمة الحقيقية (ground truth)، فهذا يعني أننا قمنا بتنبؤ غير صحيح. وهذا يعني أن أوزاننا (weights) ليست صحيحة. لذلك نحتاج إلى تحديث أوزاننا حتى نحصل على تنبؤات جيدة. لهذا الغرض، نضع جميع الخطوات المذكورة أعلاه داخل حلقة تكرارية (for loop) ونسمح لها بالتكرار أي عدد من المرات نرغب فيه. في كل تكرار، تُحسب الخسارة (loss) وتُحدّث الأوزان والانحيازات (biases) للحصول على تنبؤ أفضل في التكرار التالي. وهكذا يصبح نموذجنا أفضل بعد كل تكرار من خلال إيجاد قيمة الوزن المثلى المناسبة لمهمتنا الحالية. تتطلب كل مهمة مجموعة مختلفة من قيم الأوزان، لذا لا يمكننا أن نتوقع أن شبكتنا العصبية المدربة لتصنيف الحيوانات ستؤدي أداءً جيدًا في تصنيف الآلات الموسيقية. هكذا يبدو تدريب نموذجنا:
for i in range( 2000 ):
pred = simple_nn(flat_imgs, w, b)
loss = error(pred, target.unsqueeze( 1 ))
loss.backward()
w.data -= 0.001 *w.grad.data
b.data -= 0.001 *b.grad.data
w.grad.zero_()
b.grad.zero_()
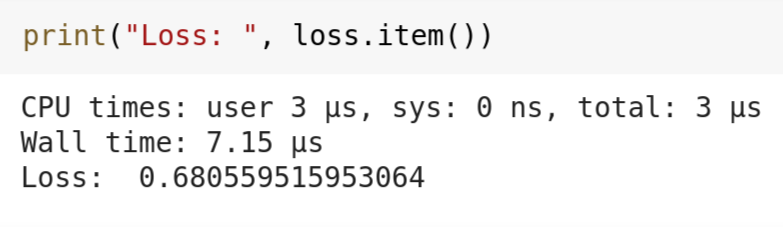
print( "Loss: " , loss.item())سنقوم بحساب التنبؤات وتخزينها في المتغير 'pred' عن طريق استدعاء الدالة التي أنشأناها سابقًا. ثم نحسب خسارة متوسط الخطأ التربيعي (mean squared error loss). بعد ذلك، سنحسب جميع التدرجات (gradients) لأوزاننا (weights) وانحيازاتنا (bias) ونُحدّث القيمة باستخدام تلك التدرجات. لقد ضربنا التدرجات بـ 0.001، وهذا ما يسمى معدل التعلم (learning rate). تحدد هذه القيمة المعدل الذي سيتعلم به نموذجنا؛ إذا كان منخفضًا جدًا، فسيتعلم النموذج ببطء، أو بعبارة أخرى، ستنخفض الخسارة ببطء. إذا كان معدل التعلم مرتفعًا جدًا، فلن يكون نموذجنا مستقرًا، وسيقفز بين نطاق واسع من قيم الخسارة. هذا يعني أنه سيفشل في التقارب (converge). نقوم بالخطوات المذكورة أعلاه 2000 مرة، وفي كل مرة يحاول نموذجنا تقليل الخسارة عن طريق تحديث قيم الأوزان والانحياز. يجب علينا تصفير التدرجات في نهاية كل حلقة أو حقبة (epoch) حتى لا يكون هناك تراكم للتدرجات غير المرغوب فيها في الذاكرة مما سيؤثر على تعلم نموذجنا. نظرًا لأن نموذجنا صغير جدًا، فإنه لا يستغرق وقتًا طويلاً للتدريب لـ 2000 حقبة أو تكرار. بعد 2000 حقبة، أعطت شبكتنا العصبية قيمة خسارة قدرها 0.6805، وهو ليس سيئًا بالنسبة لنموذج صغير كهذا.
الخلاصة التقنية
لقد نجحنا في بناء شبكة عصبية بسيطة من الصفر باستخدام PyTorch لتصنيف الأرقام. على الرغم من أن النموذج أساسي، إلا أنه يوضح المبادئ الجوهرية لعمل الشبكات العصبية، من معالجة البيانات الأولية إلى تحديث الأوزان عبر الانحدار التدرجي. يمكن تحسين أداء هذا النموذج بشكل كبير من خلال إضافة المزيد من الطبقات (layers)، وزيادة الخلايا العصبية (neurons)، أو استخدام دوال تنشيط وخسارة أكثر تعقيدًا. تكمن القوة الحقيقية للتعلم العميق في فهم هذه المكونات الأساسية وكيفية تفاعلها لتحقيق نتائج دقيقة.
هناك مجال كبير للتحسين في النموذج الذي أنشأناه للتو. هذا مجرد نموذج بسيط، ويمكنك التجربة عليه بزيادة عدد الطبقات (layers)، أو عدد الخلايا العصبية (neurons) في كل طبقة، أو زيادة عدد الحقبات (epochs). باختصار، التعلم الآلي (machine learning) هو سحر كبير باستخدام الرياضيات. تعلم دائمًا المفاهيم الأساسية – قد تكون مملة، ولكن في النهاية ستفهم أن تلك المفاهيم الرياضية “المملة” هي التي خلقت هذه التقنيات المتطورة مثل deepfakes. يمكنك الحصول على التعليمات البرمجية الكاملة على GitHub أو اللعب بالتعليمات البرمجية في Google Colab.