بناء خط أنابيب تحليلات البيانات القابل للتوسع: دليل شامل لمنصات الحوسبة السحابية
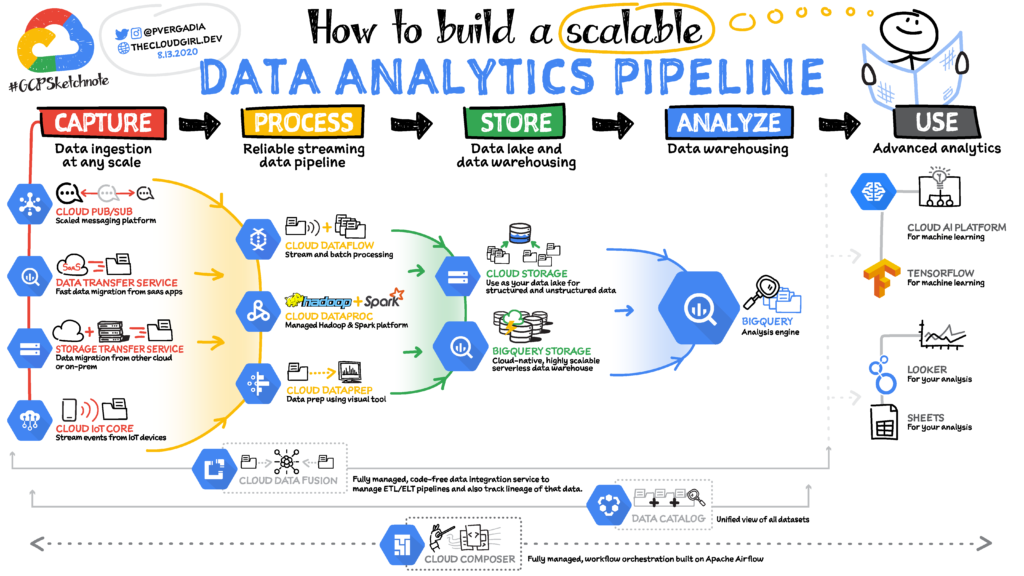
مقدمة: أهمية تحليلات البيانات في عالم اليوم
في عصرنا الرقمي، تُعد البيانات بمثابة النفط الجديد، فكل تطبيق رقمي يُنتج كميات هائلة منها. لكن السؤال الأهم الذي يسعى علماء البيانات للإجابة عليه هو: ما الذي تعنيه هذه البيانات حقًا؟ لا شك أن هذه المعلومات تُشكل أثمن سلعة لأي عمل تجاري، لكن الأهم من ذلك هو القدرة على فهمها، استخلاص الرؤى منها، وتحويلها إلى قرارات استراتيجية.
مع تزايد حجم البيانات باستمرار، يجب أن تكون خطوط أنابيب تحليلات البيانات (Data Analytics Pipelines) قابلة للتوسع لتتكيف مع معدل التغيير السريع. ولهذا السبب، يُعد اختيار إعداد خط الأنابيب في البيئة السحابية خيارًا منطقيًا للغاية، حيث توفر السحابة مرونة وقابلية للتوسع حسب الطلب. في هذا المقال، سنُزيل الغموض عن كيفية بناء خط أنابيب لمعالجة البيانات قابل للتوسع والتكيف، مع التركيز على أمثلة من Google Cloud، مع التأكيد على أن هذه المفاهيم قابلة للتطبيق في أي بيئة سحابية أخرى أو حتى في البنية التحتية المحلية (on-premise).
الخطوات الخمس الأساسية لبناء خط أنابيب تحليلات البيانات
يتألف خط أنابيب تحليلات البيانات الفعال من خمس مراحل رئيسية تعمل بشكل متكامل لضمان تدفق البيانات بسلاسة وتحويلها إلى معلومات قيمة:

- استيعاب البيانات (
Ingestion): جمع البيانات من مصادرها المختلفة. - معالجة وإثراء البيانات (
Processing & Enrichment): تحويل البيانات الخام وتنقيتها لتصبح جاهزة للاستخدام. - تخزين البيانات (
Storage): حفظ البيانات في مستودعات مناسبة للتحليل أو الأرشفة. - تحليل البيانات (
Analysis): تطبيق الأدوات والتقنيات لاستخلاص الرؤى. - استخدام وتصور البيانات (
Usage & Visualization): عرض النتائج وتطبيق النماذج لاتخاذ القرارات.
دعونا نتعمق في كل خطوة من هذه الخطوات بالتفصيل.
1. كيفية استيعاب البيانات وجمعها
اعتمادًا على مصدر بياناتك، لديك خيارات متعددة لاستيعابها في خط الأنابيب الخاص بك:
- أدوات ترحيل البيانات: استخدم أدوات ترحيل البيانات لنقلها من الأنظمة المحلية (
on-premises) أو من بيئة سحابية إلى أخرى. توفرGoogle CloudخدمةStorage Transfer Serviceلهذا الغرض. - واجهات برمجة التطبيقات (
APIs): لاستيعاب البيانات من خدماتSaaSالتابعة لجهات خارجية، يمكنك استخدام واجهات برمجة التطبيقات وإرسال البيانات مباشرة إلى مستودع البيانات. فيGoogle Cloud BigQuery، يوفر مستودع البيانات عديم الخادم (serverless) خدمةData Transfer Serviceالتي تتيح لك جلب البيانات من تطبيقاتSaaSمثلYouTubeوGoogle AdsوAmazon S3وTeradataوRedshiftوغيرها. - تدفق البيانات في الوقت الفعلي (
Real-time Streaming): يمكنك بث البيانات في الوقت الفعلي من تطبيقاتك باستخدام خدمةPub/Sub. تقوم بتكوين مصدر بيانات لدفع رسائل الأحداث إلىPub/Sub، ومن ثم يلتقط المشترك (subscriber) الرسالة ويتخذ الإجراء المناسب بناءً عليها. - أجهزة إنترنت الأشياء (
IoT Devices): إذا كانت لديك أجهزة إنترنت الأشياء، فيمكنها بث البيانات في الوقت الفعلي باستخدامCloud IoT Coreالذي يدعم بروتوكولMQTTلأجهزةIoT. يمكنك أيضًا إرسال بيانات إنترنت الأشياء إلىPub/Sub.
2. كيفية معالجة وإثراء البيانات
بمجرد استيعاب البيانات، تحتاج إلى معالجتها أو إثرائها لجعلها مفيدة للأنظمة النهائية (downstream systems). هناك ثلاث أدوات رئيسية تساعدك على تحقيق ذلك في Google Cloud:
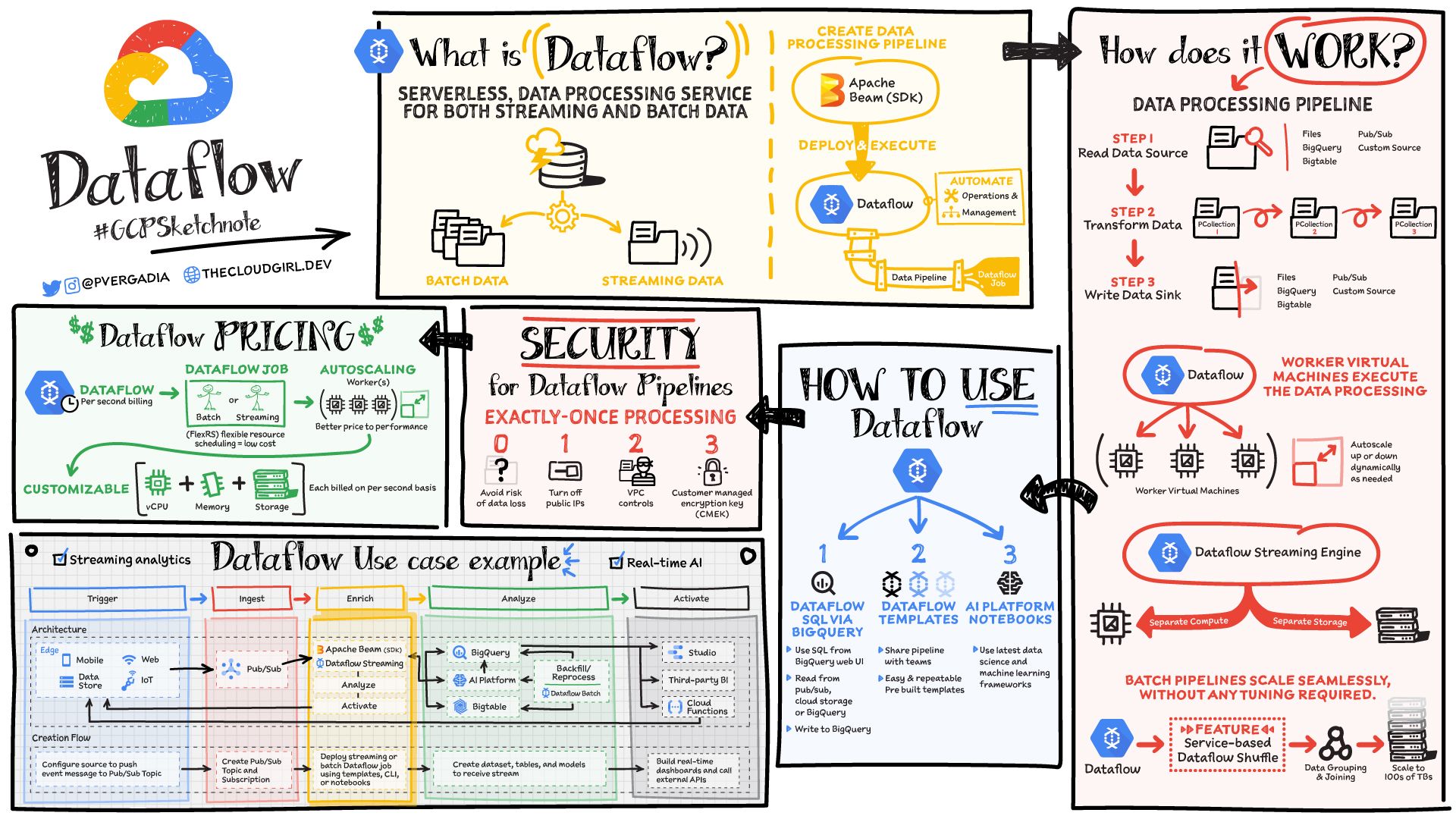
Dataproc: هو في الأساس خدمةHadoopمُدارة. إذا كنت تستخدم نظامHadoopالبيئي، فأنت تعلم أن إعداده قد يكون معقدًا، ويستغرق ساعات أو حتى أيامًا. يمكن لـDataprocتشغيل مجموعة (cluster) في 90 ثانية فقط، مما يتيح لك البدء في تحليل البيانات بسرعة.Dataprep: أداة ذكية بواجهة مستخدم رسومية (GUI) تساعد محللي البيانات على معالجة البيانات بسرعة دون الحاجة إلى كتابة أي تعليمات برمجية.Dataflow: خدمة معالجة بيانات عديمة الخادم (serverless) لتدفق البيانات والدفعات (batch data). تستند إلى حزمة تطوير البرامج مفتوحة المصدرApache Beam SDK، مما يجعل خطوط الأنابيب الخاصة بك قابلة للنقل. تفصل الخدمة التخزين عن الحوسبة، مما يسمح لها بالتوسع بسلاسة.
لمزيد من التفاصيل، يُرجى الرجوع إلى المخطط أدناه:
3. كيفية تخزين البيانات
بمجرد معالجة البيانات، يجب عليك تخزينها في بحيرة بيانات (data lake) أو مستودع بيانات (data warehouse) إما للأرشفة طويلة الأجل أو لإعداد التقارير والتحليل. هناك أداتان رئيسيتان تساعدانك على تحقيق ذلك في Google Cloud:
Google Cloud Storage: هو مخزن كائنات (object store) للصور ومقاطع الفيديو والملفات وما إلى ذلك، ويأتي في أربعة أنواع رئيسية:Standard Storage: مناسب للبيانات “الساخنة” التي يتم الوصول إليها بشكل متكرر، بما في ذلك مواقع الويب ومقاطع الفيديو المتدفقة وتطبيقات الجوال.Nearline Storage: تكلفة منخفضة. جيد للبيانات التي يمكن تخزينها لمدة 30 يومًا على الأقل، بما في ذلك النسخ الاحتياطي للبيانات ومحتوى الوسائط المتعددة طويل الذيل (long-tail multimedia content).Coldline Storage: تكلفة منخفضة جدًا. جيد للبيانات التي يمكن تخزينها لمدة 90 يومًا على الأقل، بما في ذلك التعافي من الكوارث (disaster recovery).Archive Storage: أقل تكلفة. جيد للبيانات التي يمكن تخزينها لمدة 365 يومًا على الأقل، بما في ذلك الأرشيفات التنظيمية (regulatory archives).
BigQuery: هو مستودع بيانات عديم الخادم (serverless data warehouse) يتوسع بسلاسة ليناسب بيتابايت من البيانات دون الحاجة إلى إدارة أو صيانة أي خادم. يمكنك تخزين البيانات والاستعلام عنها فيBigQueryباستخدام لغةSQL. بعد ذلك، يمكنك بسهولة مشاركة البيانات والاستعلامات مع الآخرين في فريقك. كما يضم مئات من مجموعات البيانات العامة المجانية التي يمكنك استخدامها في تحليلاتك. ويوفر موصلات مدمجة لخدمات أخرى بحيث يمكن استيعاب البيانات بسهولة فيه واستخراجها منه للتصور أو لمزيد من المعالجة/التحليل.
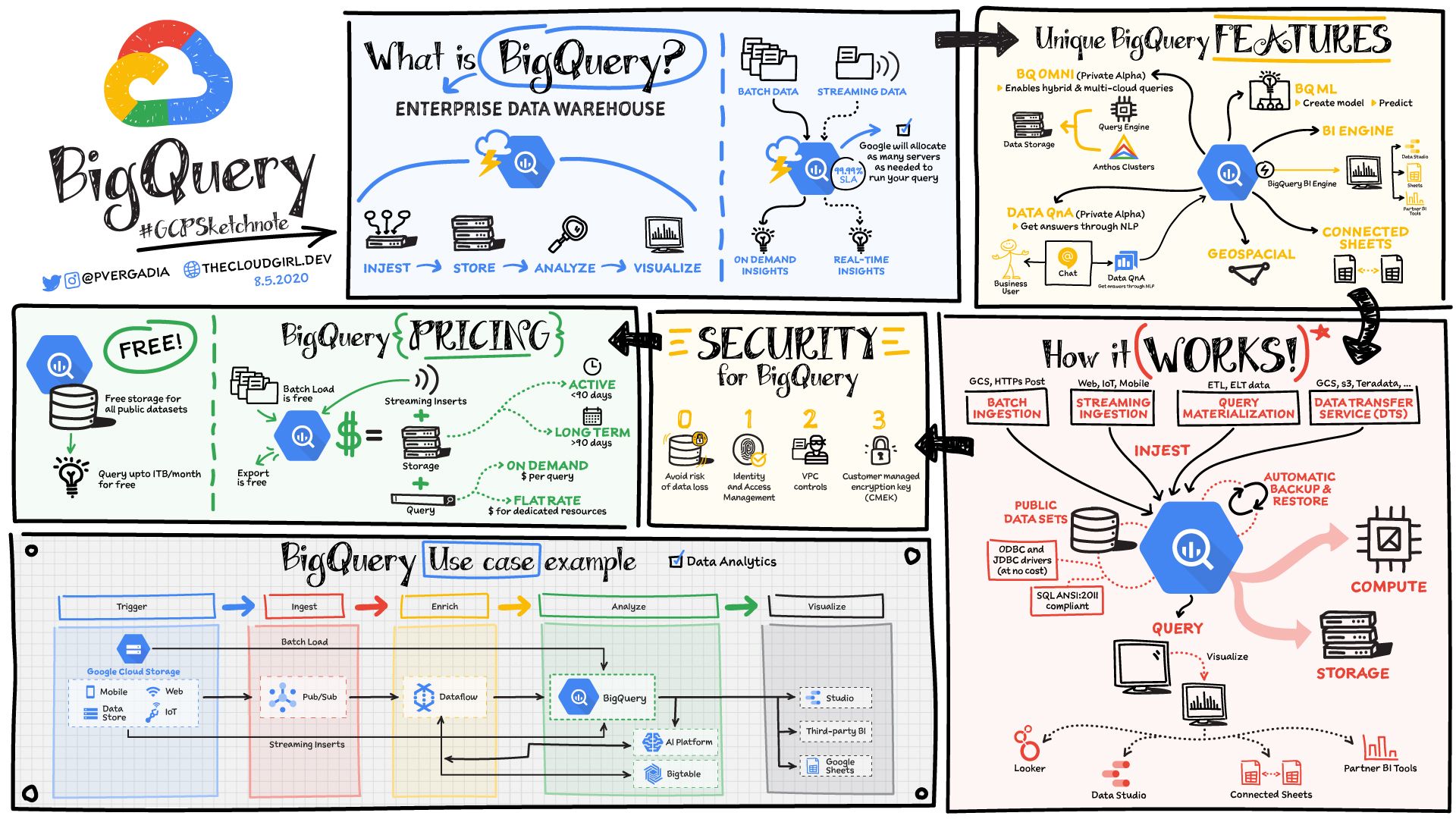
4. كيفية تحليل البيانات
بمجرد معالجة البيانات وتخزينها في بحيرة بيانات أو مستودع بيانات، تصبح جاهزة للتحليل:
- إذا كنت تستخدم
BigQueryلتخزين البيانات، فيمكنك تحليل تلك البيانات مباشرة فيBigQueryباستخدام لغةSQL. - إذا كنت تستخدم
Google Cloud Storage، فيمكنك بسهولة نقل البيانات إلىBigQuery. - يوفر
BigQueryأيضًا ميزات التعلم الآلي (Machine Learning) معBigQueryML. لذا يمكنك إنشاء النماذج والتنبؤ مباشرة من واجهة مستخدمBigQueryباستخدام لغةSQLالتي قد تكون أكثر دراية لك.
5. كيفية استخدام وتصور البيانات
استخدام البيانات
بمجرد أن تكون البيانات في مستودع البيانات، يمكنك استخدامها للحصول على رؤى وإجراء تنبؤات باستخدام التعلم الآلي. لمزيد من المعالجة والتنبؤات، يمكنك استخدام إطار عمل TensorFlow ومنصة AI Platform اعتمادًا على احتياجاتك.
TensorFlow: منصة تعلم آلي مفتوحة المصدر شاملة، تحتوي على أدوات ومكتبات وموارد مجتمعية.AI Platform: تُسهل على المطورين وعلماء البيانات ومهندسي البيانات تبسيط سير عمل التعلم الآلي الخاص بهم. تتضمن أدوات لكل مرحلة من مراحل دورة حياة التعلم الآلي بدءًا من التحضير (Preparation) مرورًا بالبناء (Build) والتحقق (Validation) وصولاً إلى النشر (Deployment).
تصور البيانات
هناك العديد من الأدوات المختلفة لتصور البيانات، ومعظمها يحتوي على موصل (connector) لـ BigQuery لإنشاء الرسوم البيانية بسهولة في الأداة التي تختارها. توفر Google Cloud بعض الأدوات التي قد تجدها مفيدة:
Data Studio: مجاني ويتصل ليس فقط بـBigQueryولكن أيضًا بالعديد من الخدمات الأخرى لتصور البيانات بسهولة. إذا كنت قد استخدمتGoogle Drive، فإن مشاركة الرسوم البيانية ولوحات المعلومات (dashboards) تشبه تمامًا ذلك – سهلة للغاية.Looker: منصة مؤسسية لذكاء الأعمال (Business Intelligence)، وتطبيقات البيانات، والتحليلات المضمنة (embedded analytics).
الخلاصة التقنية
إن بناء خط أنابيب لتحليلات البيانات هو عملية معقدة تتطلب تخطيطًا دقيقًا واختيارًا حكيمًا للأدوات. المفتاح هنا هو التركيز على قابلية التوسع والمرونة، خاصة مع النمو المستمر لحجم البيانات. توفر المنصات السحابية مثل Google Cloud مجموعة شاملة من الخدمات التي تغطي كل مرحلة من مراحل خط الأنابيب، من استيعاب البيانات الخام إلى استخلاص رؤى قابلة للتنفيذ وتصورها. إن تبني حلول عديمة الخادم (serverless) مثل BigQuery و Dataflow يمكن أن يقلل بشكل كبير من أعباء الإدارة ويسمح للفرق بالتركيز على القيمة الحقيقية للبيانات بدلاً من البنية التحتية. بغض النظر عن الأدوات المختارة، يجب أن يكون الهدف النهائي هو بناء نظام قوي يمكنه التكيف مع المتطلبات المستقبلية وتقديم رؤى دقيقة وفي الوقت المناسب لدعم اتخاذ القرار.