بناء واجهة برمجة تطبيقات لالتقاط لقطات الشاشة باستخدام Terraform و AWS Lambda و API Gateway
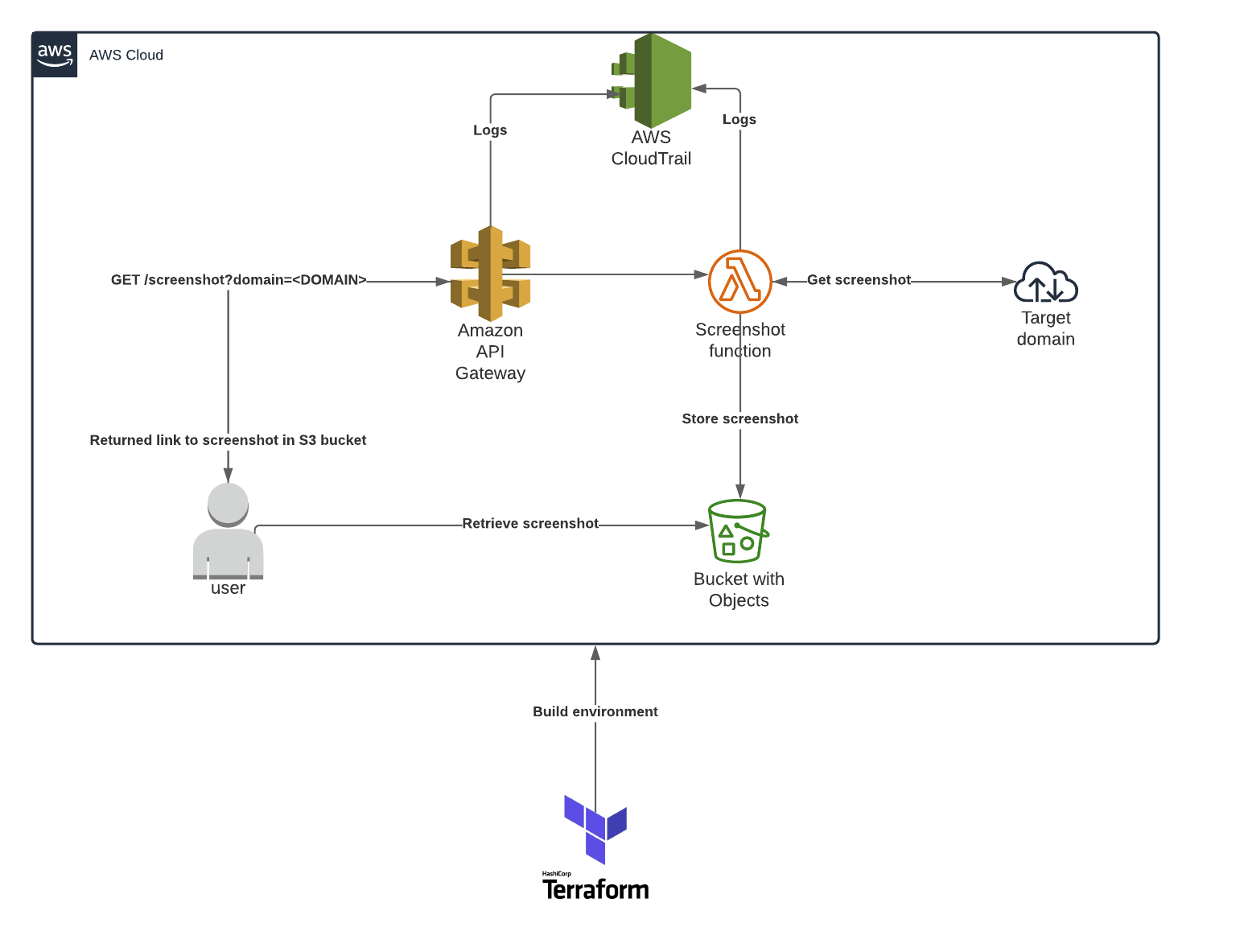
مرحباً بكم في منصة قيد! بصفتي خبيراً في تحسين محركات البحث ومحرر محتوى تقني، يسعدني أن أقدم لكم دليلاً شاملاً حول كيفية بناء واجهة برمجة تطبيقات (API) لالتقاط لقطات الشاشة. في الآونة الأخيرة، تزايدت الحاجة إلى حلول آلية لالتقاط لقطات الشاشة من عناوين URL محددة، سواء لتحليل رسائل البريد الإلكتروني التصيدية (Phishing Emails) أو لأغراض المراقبة والتوثيق. يهدف هذا المقال إلى إرشادكم خطوة بخطوة لإنشاء هذه الواجهة باستخدام مجموعة قوية من خدمات أمازون ويب (AWS) وأداة Terraform لإدارة البنية التحتية كتعليمات برمجية (Infrastructure as Code – IaC). سنستفيد من قدرات AWS Lambda لتشغيل الكود بلا خادم، و AWS API Gateway لإنشاء نقطة نهاية للواجهة، و AWS S3 لتخزين لقطات الشاشة. أما لالتقاط اللقطات الفعلية، فسنعتمد على Selenium و chromedriver مع متصفح Chrome بلا واجهة رسومية (Headless Chrome).
المتطلبات الأساسية
قبل الشروع في العمل، تأكد من توفر المتطلبات التالية:
- حساب
AWSنشط. - تثبيت ثنائي (Binary) أداة
Terraformعلى جهازك. - وجود حزمة تخزين (
S3 bucket) حالية لتخزين حالةTerraform. يمكنكم الاطلاع على المزيد من التفاصيل حول هذا الموضوع في وثائقTerraformالرسمية: Terraform S3 Backend. - مستخدم
AWS IAMومفتاح وصول (Access Key) تم إنشاؤهما بصلاحيات مناسبة (وصول برمجي، مجموعة إدارية) لاستخدامTerraform.
إعداد المشروع
ابدأ بإنشاء دليل جديد لمشروعك وتهيئته باستخدام Terraform كالتالي:
mkdir .\screenshot-service
cd .\screenshot-service
.\terraform initتكوين مزود AWS
أنشئ ملفاً باسم provider.tf في الدليل الجذر لمشروعك. ثم قم بتكوينه بالقيم المناسبة لمفتاح الوصول السري (access_key) والمفتاح السري (secret_key) الخاصين بـ AWS، بالإضافة إلى اسم حزمة S3 الموجودة التي ستُستخدم لتخزين ملف حالة Terraform.
provider "aws" {
region = "us-east-1"
access_key = "ACCESSKEY"
secret_key = "SECRETKEY"
}
terraform {
backend "s3" {
bucket = "EXISTING_BUCKET"
region = "us-east-1"
key = "KEYFORSTATE"
access_key = "ACCESSKEY"
secret_key = "SECRETKEY"
encrypt = "true"
}
}تكوين حزمة S3 لتخزين لقطات الشاشة
سنستخدم حزمة S3 لتخزين جميع لقطات الشاشة التي نلتقطها. لتكوين خدمة S3، أنشئ ملفاً جديداً في الدليل الجذر لمشروعك باسم s3.tf وأضف إليه الكود التالي:
resource "aws_s3_bucket" "screenshot_bucket" {
bucket = "STORAGE_BUCKET_NAME"
force_destroy = true
acl = "public-read"
versioning {
enabled = false
}
}إنشاء طبقة Lambda (Lambda Layer)
لنبدأ بإنشاء طبقة Lambda التي ستحتوي على الثنائيات (binaries) الضرورية. أولاً، من الدليل الجذر للمشروع، أنشئ مجلداً باسم chromedriver_layer:
mkdir .\chromedriver_layer
بعد ذلك، قم بتنزيل الثنائيات الخاصة بـ chromedriver و chromium:
cd .\chromedriver_layer
wget https://chromedriver.storage.googleapis.com/2.41/chromedriver_linux64.zip -OutFile .\chromedriver.zip
wget https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-54/stable-headless-chromium-amazonlinux-2017-03.zip -OutFile .\headless-chromium.zip
Expand-Archive .\headless-chromium.zip
rm *.zipأخيراً، نحتاج إلى ضغط هذه الملفات بشكل مناسب لـ Terraform:
cd ..\
Compress-Archive .\chromedriver_layer -DestinationPath .\chromedriver_layer.zipتكوين دالة Lambda
البنية التحتية لدالة Lambda
أنشئ ملفاً باسم lambda.tf في الدليل الجذر لمشروعك. أولاً، سنقوم بإنشاء دور التنفيذ (execution role) المطلوب لدالتنا:
resource "aws_iam_role" "lambda_exec_role" {
name = "lambda_exec_role"
description = "Execution role for Lambda functions"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
}بعد ذلك، سنضيف بعض السياسات (policies) إلى دور التنفيذ الذي أنشأناه، مما سيمكن دالتنا من الوصول إلى الخدمات المطلوبة:
resource "aws_iam_role_policy" "lambda_logging" {
name = "lambda_logging"
role = aws_iam_role.lambda_exec_role.id
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Resource": "*",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:CreateLogGroup"
]
}
]
}
EOF
}
resource "aws_iam_role_policy" "lambda_s3_access" {
name = "lambda_s3_access"
role = aws_iam_role.lambda_exec_role.id
# TODO: Change resource to be more restrictive
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBuckets",
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObjectAcl"
],
"Resource": ["*"]
}
]
}
EOF
}الآن، ستتمكن دالتنا من الوصول إلى S3 وتسجيل السجلات في CloudWatch. دعونا نحدد دالتنا:
resource "aws_lambda_function" "take_screenshot" {
filename = "./screenshot-service.zip"
function_name = "take_screenshot"
role = aws_iam_role.lambda_exec_role.arn
handler = "screenshot-service.handler"
runtime = "python3.7"
source_code_hash = filebase64sha256("./screenshot-service.zip")
timeout = 600
memory_size = 512
layers = ["${aws_lambda_layer_version.chromedriver_layer.arn}"]
environment {
variables = {
s3_bucket = "${aws_s3_bucket.screenshot_bucket.bucket}"
}
}
}يشير الكود أعلاه إلى أننا نقوم بتحميل حزمة دالة Lambda باستخدام بيئة تشغيل Python 3.7، وأن الدالة التي سيتم استدعاؤها تسمى handler. لقد قمت بتعيين مهلة (timeout) قدرها 600 ثانية، ولكن لا تتردد في تغييرها حسب حاجتك. أيضاً، يمكنكم تجربة قيم مختلفة لـ memory_size – بالنسبة لي، أدت هذه القيمة إلى لقطات شاشة سريعة جداً. كما قمنا بتعيين متغير بيئة (environment variable) باسم s3_bucket سيتم تمريره إلى الدالة، ويحتوي على اسم الحزمة المستخدمة لتخزين لقطة الشاشة.
دالة Lambda نفسها (الكود البرمجي)
أنشئ مجلداً باسم lambda في الدليل الجذر للمشروع، ثم أنشئ ملفاً باسم screenshot-service.py داخل هذا المجلد. أضف الاستيرادات (imports) وتكوين التسجيل (logging configuration) التالي إلى الملف:
#!/usr/bin/env python
# -*- coding utf-8 -*-
import json
import logging
from urllib.parse import urlparse, unquote
# TODO: Can I use urllib3?
from selenium import webdriver
from datetime import datetime
import os
from shutil import copyfile
import boto3
import stat
import urllib.request
import tldextract
# Configure logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)بعد ذلك، سنقوم بإنشاء دالة لنسخ الثنائيات من طبقة Lambda الخاصة بنا وجعلها قابلة للتنفيذ (executable):
def configure_binaries():
"""Copy the binary files from the lambda layer to /tmp and make them executable"""
copyfile("/opt/chromedriver", "/tmp/chromedriver")
copyfile("/opt/headless-chromium", "/tmp/headless-chromium")
os.chmod("/tmp/chromedriver", 755)
os.chmod("/tmp/headless-chromium", 755)الآن، سنقوم بإنشاء الدالة التي ستلتقط لقطة شاشة للمجال المقدم. سنمرر عنوان URL واسم حزمة S3. سنضيف معاملاً اختيارياً يسمح للمستخدم بتعيين عنوان الصورة. يتم التقاط لقطة الشاشة بواسطة Selenium الذي يقوم بأتمتة متصفح Chrome بلا واجهة رسومية الذي قمنا بتنزيله.
def get_screenshot(url, s3_bucket, screenshot_title=None):
configure_binaries()
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument("disable-infobars")
chrome_options.add_argument("enable-automation")
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--window-size=1280x1696')
chrome_options.add_argument('--user-data-dir=/tmp/user-data')
chrome_options.add_argument('--hide-scrollbars')
chrome_options.add_argument('--enable-logging')
chrome_options.add_argument('--log-level=0')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--v=99')
chrome_options.add_argument('--single-process')
chrome_options.add_argument('--data-path=/tmp/data-path')
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_argument('--homedir=/tmp')
chrome_options.add_argument('--disk-cache-dir=/tmp/cache-dir')
chrome_options.add_argument('user-agent=Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36')
chrome_options.binary_location = "/tmp/headless-chromium"
if screenshot_title is None:
ext = tldextract.extract(url)
domain = f"{'' .join(ext[:2])}:{urlparse(url).port}.{ext[2]}"
screenshot_title = f"{domain}_{datetime.utcnow().strftime('%Y%m%d_%H%M%S')}"
logger.debug(f"Screenshot title: {screenshot_title}")
with webdriver.Chrome(chrome_options=chrome_options, executable_path="/tmp/chromedriver", service_log_path="/tmp/selenium.log") as driver:
driver.set_window_size(1024, 768)
logger.info(f"Obtaining screenshot for {url}")
driver.get(url)
driver.save_screenshot(f"/tmp/{screenshot_title}.png")
# TODO: Delete the screenshot after
logger.info(f"Uploading /tmp/{screenshot_title}.png to S3 bucket {s3_bucket}/{screenshot_title}.png")
s3 = boto3.client("s3")
s3.upload_file(f"/tmp/{screenshot_title}.png", s3_bucket, f"{screenshot_title}.png", ExtraArgs={'ContentType': 'image/png', 'ACL': 'public-read'})
return f"https://{s3_bucket}.s3.amazonaws.com/{screenshot_title}.png"أخيراً، دعونا ننشئ دالة المعالج (handler) الخاصة بنا، والتي سيتم استدعاؤها عندما يتلقى API Gateway طلباً صالحاً:
def handler(event, context):
logger.debug("## ENVIRONMENT VARIABLES ##")
logger.debug(os.environ)
logger.debug("## EVENT ##")
logger.debug(event)
bucket_name = os.environ["s3_bucket"]
logger.debug(f"bucket_name: {bucket_name}")
logger.info("Validating url")
if event["httpMethod"] == "GET":
if event["queryStringParameters"]:
try:
url = event["queryStringParameters"]["url"]
except Exception as e:
logger.error(e)
raise e
else:
return {
"statusCode": 400,
"body": json.dumps("No URL provided...")
}
elif event["httpMethod"] == "POST":
if event["body"]:
try:
body = json.loads(event["body"])
url = body["url"]
except Exception as e:
logger.error(e)
raise e
else:
return {
"statusCode": 400,
"body": json.dumps("No URL provided...")
}
else:
return {
"statusCode": 405,
"body": json.dumps(f"Invalid HTTP Method {event['httpMethod']} supplied")
}
logger.info(f"Decoding {url}")
url = unquote(url)
logger.info(f"Parsing {url}")
try:
parsed_url = urlparse(url)
if parsed_url.scheme != "http" and parsed_url.scheme != "https":
logger.info("No valid scheme found, defaulting to http://")
parsed_url = urlparse(f"http://{url}")
if parsed_url.port is None:
if parsed_url.scheme == "http":
parsed_url = urlparse(f"{parsed_url.geturl()}:80")
elif parsed_url.scheme == "https":
parsed_url = urlparse(f"{parsed_url.geturl()}:443")
except Exception as e:
logger.error(e)
raise e
logger.info("Getting screenshot")
try:
screenshot_url = get_screenshot(parsed_url.geturl(), bucket_name) # TODO: Variable!
except Exception as e:
logger.error(e)
raise e
response_body = {
"message": f"Successfully captured screenshot of {parsed_url.geturl()}",
"screenshot_url": screenshot_url
}
return {
"statusCode": 200,
"body": json.dumps(response_body)
}بعد ذلك، نحتاج إلى تثبيت جميع الحزم التي تستخدمها دالة Lambda في دليل lambda، نظراً لأن هذه الحزم لا يتم تثبيتها افتراضياً في AWS. ثم نحتاج إلى إنشاء أرشيف zip (بمجرد إنشائه، سيستمر Terraform في تحديثه إذا أجريت تغييرات على الكود الخاص بك):
cd .\lambda
pip install selenium tldextract -t .\
cd ..\
Compress-Archive .\lambda -DestinationPath .\screenshot-service.zipتكوين AWS API Gateway
أنشئ ملفاً باسم apigw.tf في الدليل الجذر لمشروعك. أولاً، سنقوم بتكوين واجهة REST API:
resource "aws_api_gateway_rest_api" "screenshot_api" {
name = "screenshot_api"
description = "Lambda-powered screenshot API"
depends_on = [
aws_lambda_function.take_screenshot
]
}ستُستخدم هذه الواجهة لتوجيه جميع الطلبات التي يتم إجراؤها لخدمة لقطات الشاشة. نستخدم ميزة depends_on لضمان أن البوابة ومكوناتها ذات الصلة لا يتم إنشاؤها إلا بعد إنشاء دالة Lambda.
بعد ذلك، دعونا ننشئ مورد API Gateway لدالة Lambda:
resource "aws_api_gateway_resource" "screenshot_api_gateway" {
path_part = "screenshot"
parent_id = aws_api_gateway_rest_api.screenshot_api.root_resource_id
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
}لقد حددنا الآن مورداً سيستجيب عند نقطة النهاية /screenshot لخدمة الواجهة البرمجية. بعد ذلك، سننشئ مرحلة (stage) للواجهة. المرحلة هي طريقة أنيقة لتسمية نشر (deployment) الواجهة الخاصة بنا. يمكنك تكوين التخزين المؤقت (caching)، التسجيل (logging)، تقييد الطلبات (request throttling)، والمزيد باستخدام المرحلة.
resource "aws_api_gateway_stage" "prod_stage" {
stage_name = "prod"
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
deployment_id = aws_api_gateway_deployment.api_gateway_deployment_get.id
}بعد ذلك، سننشئ مفتاح API وخطة استخدام (usage plan) مرتبطة بمرحلتنا، بحيث يتمكن فقط المستخدمون الذين يعرفون المفتاح من استخدام هذه الخدمة. (ملاحظة: إذا كنت تريد أن تكون هذه الخدمة متاحة للجمهور، فتخط هذه الخطوة).
resource "aws_api_gateway_usage_plan" "apigw_usage_plan" {
name = "apigw_usage_plan"
api_stages {
api_id = aws_api_gateway_rest_api.screenshot_api.id
stage = aws_api_gateway_stage.prod_stage.stage_name
}
}
resource "aws_api_gateway_usage_plan_key" "apigw_usage_plan_key" {
key_id = aws_api_gateway_api_key.apigw_prod_key.id
key_type = "API_KEY"
usage_plan_id = aws_api_gateway_usage_plan.apigw_usage_plan.id
}
resource "aws_api_gateway_api_key" "apigw_prod_key" {
name = "prod_key"
}دعونا الآن نكوّن الواجهة للاستجابة إما لطلب GET أو POST إذا تم توفير مفتاح API Gateway صالح (اضبط القيمة على false إذا كنت تريد أن تكون الطريقة مفتوحة للجمهور):
resource "aws_api_gateway_method" "take_screenshot_get" {
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
resource_id = aws_api_gateway_resource.screenshot_api_gateway.id
http_method = "GET"
authorization = "NONE"
api_key_required = true
}
resource "aws_api_gateway_method" "take_screenshot_post" {
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
resource_id = aws_api_gateway_resource.screenshot_api_gateway.id
http_method = "POST"
authorization = "NONE"
api_key_required = true
}نحتاج الآن إلى منح API Gateway الإذن لاستدعاء دالة Lambda التي أنشأناها:
resource "aws_lambda_permission" "apigw" {
statement_id = "AllowAPIGatewayInvoke"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.take_screenshot.arn
principal = "apigateway.amazonaws.com"
source_arn = "${aws_api_gateway_rest_api.screenshot_api.execution_arn}/*/*/*"
}رائع، لدينا الآن الصلاحيات المناسبة. دعونا نعد تكاملنا مع دالة Lambda:
resource "aws_api_gateway_integration" "lambda_integration_get" {
depends_on = [
aws_lambda_permission.apigw
]
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
resource_id = aws_api_gateway_method.take_screenshot_get.resource_id
http_method = aws_api_gateway_method.take_screenshot_get.http_method
integration_http_method = "POST" # https://github.com/hashicorp/terraform/issues/9271 Lambda requires POST as the integration type
type = "AWS_PROXY"
uri = aws_lambda_function.take_screenshot.invoke_arn
}
resource "aws_api_gateway_integration" "lambda_integration_post" {
depends_on = [
aws_lambda_permission.apigw
]
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
resource_id = aws_api_gateway_method.take_screenshot_post.resource_id
http_method = aws_api_gateway_method.take_screenshot_post.http_method
integration_http_method = "POST" # https://github.com/hashicorp/terraform/issues/9271 Lambda requires POST as the integration type
type = "AWS_PROXY"
uri = aws_lambda_function.take_screenshot.invoke_arn
}يخبر هذا التكامل API Gateway أي دالة Lambda يجب استدعاؤها عندما تتلقى طلباً عند نقطة النهاية المحددة وطريقة HTTP. لقد أوشكنا على الانتهاء من البوابة، أعدكم بذلك. كخطوة أخيرة، دعونا نتأكد من أن واجهتنا يمكنها إرسال السجلات إلى CloudWatch:
resource "aws_api_gateway_account" "apigw_account" {
cloudwatch_role_arn = aws_iam_role.apigw_cloudwatch.arn
}
resource "aws_iam_role" "apigw_cloudwatch" {
# https://gist.github.com/edonosotti/6e826a70c2712d024b730f61d8b8edfc
name = "api_gateway_cloudwatch_global"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": "apigateway.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
}
resource "aws_iam_role_policy" "apigw_cloudwatch" {
name = "default"
role = aws_iam_role.apigw_cloudwatch.id
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:DescribeLogGroups",
"logs:DescribeLogStreams",
"logs:PutLogEvents",
"logs:GetLogEvents",
"logs:FilterLogEvents"
],
"Resource": "*"
}
]
}
EOF
}لقد منحنا الآن API Gateway الصلاحيات المطلوبة لكتابة السجلات إلى CloudWatch. أخيراً وليس آخراً، نقوم بنشر واجهتنا. نستخدم depends_on لضمان حدوث النشر بعد إنشاء جميع التبعيات.
resource "aws_api_gateway_deployment" "api_gateway_deployment_get" {
depends_on = [aws_api_gateway_integration.lambda_integration_get, aws_api_gateway_method.take_screenshot_get, aws_api_gateway_integration.lambda_integration_post, aws_api_gateway_method.take_screenshot_post]
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
}تجميع حزم Lambda
في ملف main.tf، أضف الكود التالي لتحديد كيفية تجميع ملفات zip الخاصة بدالة Lambda والطبقة (layer):
data "archive_file" "screenshot_service_zip" {
type = "zip"
source_dir = "./lambda"
output_path = "./screenshot-service.zip"
}
data "archive_file" "screenshot_service_layer_zip" {
type = "zip"
source_dir = "./chromedriver_layer"
output_path = "./chromedriver_lambda_layer.zip"
}مخرجات Terraform
أنشئ ملفاً باسم output.tf في الدليل الجذر لمشروعك وأضف إليه الكود التالي لعرض الروابط والمفاتيح الهامة بعد النشر:
output "api_gateway_url" {
value = "${aws_api_gateway_stage.prod_stage.invoke_url}/${aws_api_gateway_resource.screenshot_api_gateway.path_part}"
}
output "api_key" {
value = aws_api_gateway_api_key.apigw_prod_key.value
}الآن، بمجرد تشغيل الأمر .\terraform apply، ستحصل على مخرجات تحتوي على عنوان URL الخاص بالواجهة ومفتاح API المرتبط بها. تهانينا! لديك الآن خدمة لالتقاط لقطات الشاشة تعمل بكامل طاقتها. لعرض الكود الذي استخدمته، لا تتردد في زيارة مستودع GitHub الخاص بي.
الخلاصة التقنية
لقد استعرضنا في هذا الدليل الشامل كيفية بناء واجهة برمجة تطبيقات قوية ومرنة لالتقاط لقطات الشاشة باستخدام مزيج فعال من Terraform وخدمات AWS الرئيسية مثل Lambda و API Gateway و S3. يبرهن هذا الحل على قوة البنية التحتية كتعليمات برمجية (IaC) في أتمتة نشر الموارد السحابية، مما يقلل من الأخطاء البشرية ويسرع عملية التطوير. باستخدام Selenium و Headless Chrome ضمن بيئة Lambda، تمكنا من تحقيق وظيفة التقاط لقطات الشاشة بكفاءة عالية وقابلية للتوسع. هذا النموذج المعماري لا يوفر حلاً عملياً لاحتياجات مثل تحليل رسائل التصيد أو مراقبة مواقع الويب فحسب، بل يمثل أيضاً مثالاً ممتازاً لكيفية دمج التقنيات الحديثة لبناء تطبيقات بلا خادم (Serverless Applications) قوية وفعالة من حيث التكلفة.