بناء وتدريب نماذج تعلم الآلة K-Nearest Neighbors و K-Means Clustering في بايثون
يُعد حل مشكلات التصنيف (Classification Problems) أحد أبرز تطبيقات تعلم الآلة (Machine Learning) وأكثرها شيوعًا. تُعرف مشكلات التصنيف بأنها سيناريوهات تمتلك فيها مجموعة بيانات (Data Set)، وترغب في تصنيف الملاحظات (Observations) من تلك المجموعة إلى فئة محددة. من الأمثلة الشهيرة على ذلك مرشحات البريد العشوائي (Spam Filters) لمزودي خدمة البريد الإلكتروني. يستخدم Gmail تقنيات تعلم الآلة المُشرف عليها (Supervised Machine Learning) لوضع رسائل البريد الإلكتروني تلقائيًا في مجلد البريد العشوائي بناءً على محتواها، سطر الموضوع، وميزات أخرى.
هناك نموذجان من نماذج تعلم الآلة يؤديان جزءًا كبيرًا من العمل الشاق عندما يتعلق الأمر بمشكلات التصنيف والتجميع:
K-Nearest Neighbors(الجيران الأقرباء)K-Means Clustering(التجميع بالمتوسطات)
سيعلمك هذا الدليل كيفية برمجة خوارزميات K-Nearest Neighbors و K-Means Clustering في لغة بايثون (Python)، مع التركيز على الخطوات العملية والتطبيقات الواقعية.
نماذج K-Nearest Neighbors (الجيران الأقرباء)
تُعد خوارزمية K-Nearest Neighbors (اختصارًا KNN) أحد نماذج تعلم الآلة الأكثر شعبية على مستوى العالم لحل مشكلات التصنيف. تعتمد هذه الخوارزمية على مبدأ بسيط: تُصنف نقطة بيانات جديدة بناءً على أغلبية الفئات بين أقرب K من جيرانها في مجموعة البيانات. من التمارين الشائعة للطلاب الذين يستكشفون تعلم الآلة هو تطبيق خوارزمية KNN على مجموعة بيانات لا تكون فيها الفئات معروفة مسبقًا، مما يحاكي سيناريوهات العالم الحقيقي حيث تحتاج إلى إجراء تنبؤات باستخدام تعلم الآلة على بيانات سرية أو غير مصنفة.
في هذا الدليل، ستتعلم كيفية كتابة أول خوارزمية K-Nearest Neighbors لتعلم الآلة في بايثون. سنعمل مع مجموعة بيانات مجهولة (anonymous data set) مشابهة للحالة المذكورة أعلاه.
مجموعة البيانات التي ستحتاجها في هذا الدليل
للبدء، ستحتاج إلى الحصول على مجموعة البيانات التي سنستخدمها في هذا الدليل. عادةً ما يتم توفير هذه البيانات من قبل المؤلف أو يمكن العثور عليها في مستودعات البيانات الشائعة. بعد تنزيل الملف، انقل مجموعة البيانات إلى الدليل الذي ستعمل فيه. بعد ذلك، افتح بيئة Jupyter Notebook، ويمكننا البدء في كتابة كود بايثون!
المكتبات الأساسية التي ستحتاجها
لكتابة خوارزمية K-Nearest Neighbors، سنستفيد من العديد من مكتبات بايثون مفتوحة المصدر، بما في ذلك NumPy لمعالجة المصفوفات، و pandas لإدارة البيانات، و scikit-learn التي توفر أدوات قوية لتعلم الآلة. ابدأ نص بايثون البرمجي الخاص بك بكتابة عبارات الاستيراد التالية:
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline استيراد مجموعة البيانات إلى نص بايثون البرمجي
خطوتنا التالية هي استيراد ملف classified_data.csv إلى نص بايثون البرمجي. تُسهّل مكتبة pandas عملية استيراد البيانات إلى كائن DataFrame. نظرًا لأن مجموعة البيانات مخزنة في ملف csv، سنستخدم الدالة read_csv() للقيام بذلك:
raw_data = pd.read_csv( 'classified_data.csv' ) طباعة كائن DataFrame هذا داخل Jupyter Notebook سيعطيك فكرة عن شكل البيانات:
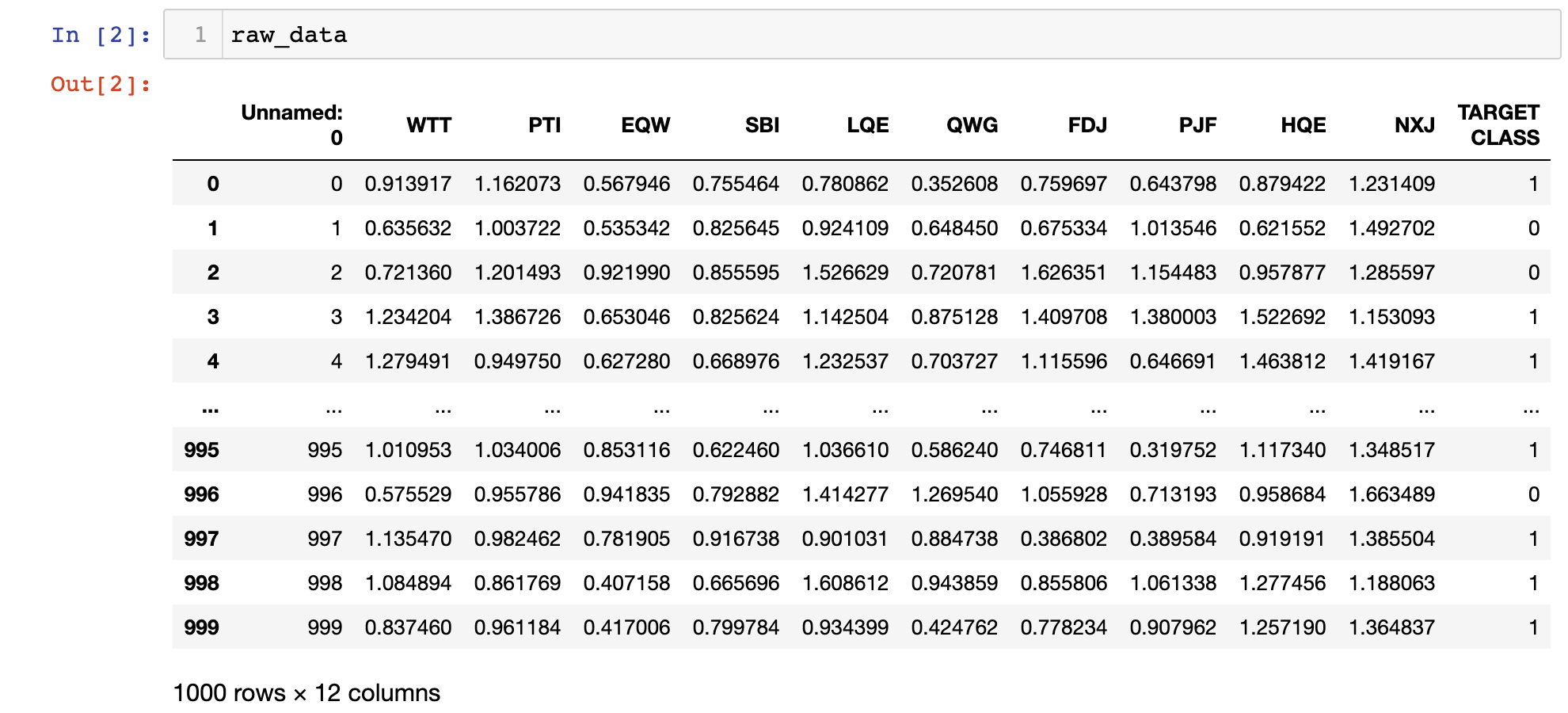
ستلاحظ أن كائن DataFrame يبدأ بعمود غير مسمى تتساوى قيمه مع فهرس DataFrame. يمكننا إصلاح ذلك بإجراء تعديل طفيف على الأمر الذي استورد مجموعة البيانات إلى نص بايثون البرمجي، وذلك بتحديد العمود الصفري كفهرس:
raw_data = pd.read_csv( 'classified_data.csv' , index_col = 0 ) بعد ذلك، دعنا نلقي نظرة على الميزات الفعلية المتضمنة في مجموعة البيانات هذه. يمكنك طباعة قائمة بأسماء أعمدة مجموعة البيانات باستخدام العبارة التالية:
print(raw_data.columns) هذا يُرجع:
Index([ 'WTT' , 'PTI' , 'EQW' , 'SBI' , 'LQE' , 'QWG' , 'FDJ' , 'PJF' , 'HQE' , 'NXJ' , 'TARGET CLASS' ], dtype= 'object' ) نظرًا لأن هذه مجموعة بيانات مصنفة (classified data set)، فليس لدينا فكرة عما يعنيه أي من هذه الأعمدة. في الوقت الحالي، يكفي أن ندرك أن كل عمود ذو طبيعة رقمية، وبالتالي فهو مناسب تمامًا للنمذجة باستخدام تقنيات تعلم الآلة.
توحيد قياس مجموعة البيانات (Standardizing the Data Set)
نظرًا لأن خوارزمية K-Nearest Neighbors تُجري تنبؤات حول نقطة بيانات باستخدام الملاحظات الأقرب إليها، فإن مقياس الميزات داخل مجموعة البيانات مهم جدًا. إذا كانت الميزات ذات مقاييس مختلفة بشكل كبير، فقد تهيمن الميزات ذات القيم الأكبر على حساب الميزات الأخرى. لهذا السبب، يقوم ممارسو تعلم الآلة عادةً بـ توحيد قياس (standardize) مجموعة البيانات، مما يعني تعديل كل قيمة x بحيث تكون على نفس المقياس تقريبًا (عادةً بمتوسط صفر وانحراف معياري واحد).
لحسن الحظ، تتضمن مكتبة scikit-learn بعض الوظائف الممتازة للقيام بذلك بأقل جهد. للبدء، سنحتاج إلى استيراد الفئة StandardScaler من مكتبة scikit-learn. أضف الأمر التالي إلى نص بايثون البرمجي للقيام بذلك:
from sklearn.preprocessing import StandardScaler تتصرف هذه الدالة بشكل مشابه جدًا لفئتي LinearRegression و LogisticRegression التي قد نكون استخدمناها سابقًا. سنحتاج إلى إنشاء كائن (instance) من هذه الفئة ثم تدريب هذا الكائن على مجموعة البيانات الخاصة بنا. أولاً، دعنا ننشئ كائنًا من الفئة StandardScaler باسم scaler باستخدام العبارة التالية:
scaler = StandardScaler() يمكننا الآن تدريب هذا الكائن على مجموعة البيانات الخاصة بنا باستخدام الدالة fit()، مع استبعاد عمود 'TARGET CLASS' لأنه يمثل المتغير الهدف الذي نحاول التنبؤ به وليس ميزة:
scaler.fit(raw_data.drop( 'TARGET CLASS' , axis= 1 )) الآن يمكننا استخدام الدالة transform() لتوحيد قياس جميع الميزات في مجموعة البيانات بحيث تكون على نفس المقياس تقريبًا. سنقوم بتعيين هذه الميزات المُقاسة (scaled features) للمتغير المسمى scaled_features:
scaled_features = scaler.transform(raw_data.drop( 'TARGET CLASS' , axis= 1 )) هذا في الواقع ينشئ مصفوفة NumPy لجميع الميزات في مجموعة البيانات، ونحن نريدها أن تكون كائن pandas DataFrame بدلاً من ذلك لتسهيل التعامل معها. لحسن الحظ، هذا إصلاح سهل. سنقوم ببساطة بتغليف المتغير scaled_features داخل الدالة pd.DataFrame() وتعيين DataFrame هذا لمتغير جديد يسمى scaled_data مع وسيط مناسب لتحديد أسماء الأعمدة الأصلية:
scaled_data = pd.DataFrame(scaled_features, columns = raw_data.drop( 'TARGET CLASS' , axis= 1 ).columns) الآن بعد أن استوردنا مجموعة البيانات الخاصة بنا ووحدنا قياس ميزاتها، نحن جاهزون لتقسيم مجموعة البيانات إلى بيانات تدريب وبيانات اختبار.
تقسيم مجموعة البيانات إلى بيانات تدريب واختبار
سنستخدم الدالة train_test_split() من مكتبة scikit-learn جنبًا إلى جنب مع تفكيك القوائم (list unpacking) لإنشاء بيانات تدريب وبيانات اختبار من مجموعة البيانات المصنفة لدينا. أولاً، ستحتاج إلى استيراد الدالة train_test_split() من وحدة model_selection في scikit-learn باستخدام العبارة التالية:
from sklearn.model_selection import train_test_split بعد ذلك، سنحتاج إلى تحديد قيم x (الميزات) وقيم y (الهدف) التي سيتم تمريرها إلى دالة train_test_split() هذه. ستكون قيم x هي كائن DataFrame المسمى scaled_data الذي أنشأناه سابقًا. وستكون قيم y هي العمود 'TARGET CLASS' من كائن DataFrame الأصلي raw_data. يمكنك إنشاء هذه المتغيرات باستخدام العبارات التالية:
x = scaled_data y = raw_data[ 'TARGET CLASS' ] بعد ذلك، ستحتاج إلى تشغيل دالة train_test_split() باستخدام هذين الوسيطين وحجم اختبار (test_size) معقول. سنستخدم test_size بنسبة 30%، مما يعني أن 30% من البيانات ستُستخدم للاختبار و 70% للتدريب. إليك المعلمات للدالة:
x_training_data, x_test_data, y_training_data, y_test_data = train_test_split(x, y, test_size = 0.3 ) الآن بعد أن تم تقسيم مجموعة البيانات الخاصة بنا إلى بيانات تدريب وبيانات اختبار، نحن جاهزون لبدء تدريب نموذجنا!
تدريب نموذج K-Nearest Neighbors
دعنا نبدأ باستيراد الفئة KNeighborsClassifier من مكتبة scikit-learn، وهي الفئة التي تُستخدم لبناء نموذج KNN:
from sklearn.neighbors import KNeighborsClassifier بعد ذلك، دعنا ننشئ كائنًا من الفئة KNeighborsClassifier ونعينه لمتغير يسمى model. تتطلب هذه الفئة معلمة تسمى n_neighbors، والتي تساوي قيمة K لخوارزمية K-Nearest Neighbors التي تقوم ببنائها. للبدء، دعنا نحدد n_neighbors = 1، مما يعني أن النموذج سيعتمد على أقرب جار واحد فقط للتصنيف:
model = KNeighborsClassifier(n_neighbors = 1 ) يمكننا الآن تدريب نموذج K-Nearest Neighbors الخاص بنا باستخدام الدالة fit() والمتغيرين x_training_data و y_training_data:
model.fit(x_training_data, y_training_data) الآن دعنا نُجري بعض التنبؤات باستخدام خوارزمية K-Nearest Neighbors المدربة حديثًا!
إجراء التنبؤات باستخدام خوارزمية K-Nearest Neighbors
يمكننا إجراء التنبؤات باستخدام خوارزمية K-Nearest Neighbors بنفس الطريقة التي فعلناها مع نماذج الانحدار الخطي والانحدار اللوجستي سابقًا في هذه الدورة: باستخدام الدالة predict() وتمرير المتغير x_test_data الذي يحتوي على بيانات الاختبار. بشكل أكثر تحديدًا، إليك كيفية إجراء التنبؤات وتعيينها لمتغير يسمى predictions:
predictions = model.predict(x_test_data) دعنا نستكشف مدى دقة تنبؤاتنا في القسم التالي من هذا الدليل.
قياس دقة النموذج
لقد رأينا في أدلة سابقة أن مكتبة scikit-learn تأتي مع دوال مدمجة تُسهّل قياس أداء نماذج تصنيف تعلم الآلة. دعنا نستورد اثنتين من هذه الدوال (classification_report() و confusion_matrix()) إلى تقريرنا الآن:
from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix دعنا نعمل على كل واحدة من هذه الدوال على حدة، بدءًا من classification_report() الذي يوفر تقريرًا شاملاً عن دقة النموذج، الاستدعاء (recall)، ودرجة F1 (f1-score). يمكنك إنشاء التقرير باستخدام العبارة التالية:
print(classification_report(y_test_data, predictions)) هذا يُنشئ تقريرًا يوضح أداء النموذج لكل فئة:
precision recall f1-score support 0 0.94 0.85 0.89 150 1 0.86 0.95 0.90 150 accuracy 0.90 300 macro avg 0.90 0.90 0.90 300 weighted avg 0.90 0.90 0.90 300 وبالمثل، يمكنك إنشاء مصفوفة الارتباك (confusion matrix) باستخدام العبارة التالية، والتي توضح عدد التنبؤات الصحيحة والخاطئة لكل فئة:
print(confusion_matrix(y_test_data, predictions)) هذا يُنشئ:
[[ 141 12 ] [ 18 129 ]] بالنظر إلى مقاييس الأداء هذه، يبدو أن نموذجنا يؤدي بشكل جيد بالفعل. ومع ذلك، لا يزال بالإمكان تحسينه. في القسم التالي، سنرى كيف يمكننا تحسين أداء نموذج K-Nearest Neighbors الخاص بنا عن طريق اختيار قيمة أفضل لـ K.
اختيار قيمة K المثلى باستخدام طريقة الكوع (Elbow Method)
في هذا القسم، سنستخدم طريقة الكوع (Elbow Method) لاختيار قيمة مثالية لـ K لخوارزمية K-Nearest Neighbors الخاصة بنا. تتضمن طريقة الكوع التكرار عبر قيم K مختلفة وحساب معدل الخطأ لكل قيمة، ثم اختيار القيمة التي تحقق أدنى معدل خطأ عند تطبيقها على بيانات الاختبار لدينا.
للبدء، دعنا ننشئ قائمة فارغة تسمى error_rates. سنقوم بالتكرار عبر قيم K مختلفة وإلحاق معدلات الخطأ المقابلة لها بهذه القائمة.
error_rates = [] بعد ذلك، نحتاج إلى إنشاء حلقة بايثون (Python loop) تتكرر عبر قيم K المختلفة التي نرغب في اختبارها وتنفذ الوظائف التالية مع كل تكرار:
- تُنشئ كائنًا جديدًا من الفئة
KNeighborsClassifierمن مكتبةscikit-learn. - تُدرب النموذج الجديد باستخدام بيانات التدريب لدينا.
- تُجري تنبؤات على بيانات الاختبار لدينا.
- تحسب متوسط الفرق لكل تنبؤ غير صحيح (كلما كانت هذه القيمة أقل، كان نموذجنا أكثر دقة).
إليك الكود للقيام بذلك لقيم K بين 1 و 100:
for i in np.arange( 1 , 101 ): new_model = KNeighborsClassifier(n_neighbors = i) new_model.fit(x_training_data, y_training_data) new_predictions = new_model.predict(x_test_data) error_rates.append(np.mean(new_predictions != y_test_data)) دعنا نُصوّر كيف يتغير معدل الخطأ لدينا مع قيم K المختلفة باستخدام تصور سريع من مكتبة matplotlib:
plt.plot(error_rates) 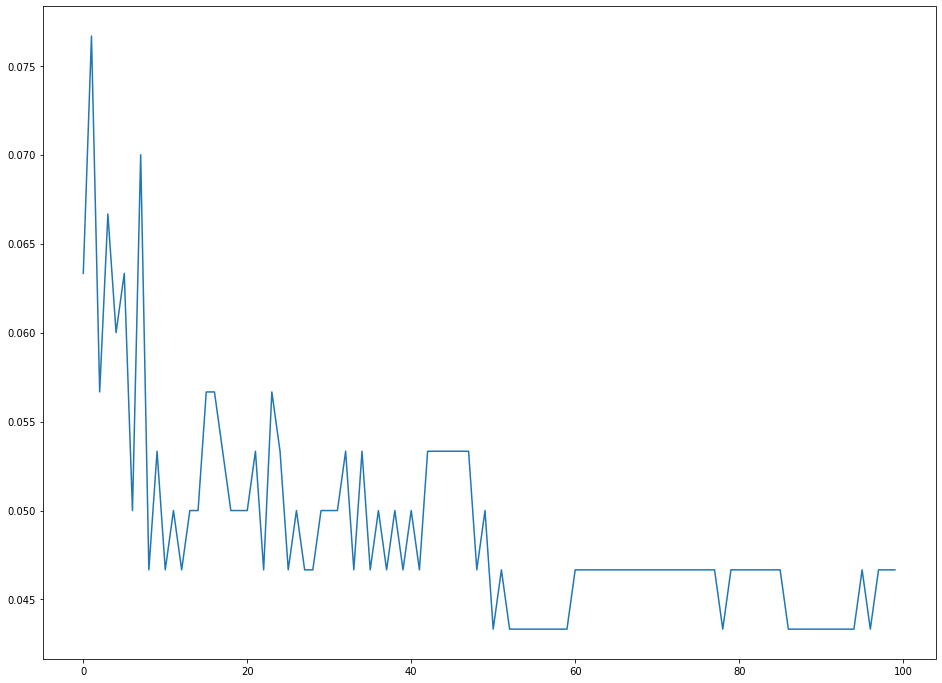
كما ترى، تميل معدلات الخطأ لدينا إلى أن تكون في أدنى مستوياتها مع قيمة K تبلغ حوالي 50. هذا يعني أن 50 هو خيار مناسب لـ K يوازن بين البساطة والقوة التنبؤية.
الكود الكامل لنموذج K-Nearest Neighbors
يمكنك الاطلاع على الكود الكامل لهذا الدليل في مستودع GitHub الخاص بالمشروع، أو يمكنك الرجوع إليه أدناه:
#Common imports import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline #Import the data set raw_data = pd.read_csv( 'classified_data.csv' , index_col = 0 ) #Import standardization functions from scikit-learn from sklearn.preprocessing import StandardScaler #Standardize the data set scaler = StandardScaler() scaler.fit(raw_data.drop( 'TARGET CLASS' , axis= 1 )) scaled_features = scaler.transform(raw_data.drop( 'TARGET CLASS' , axis= 1 )) scaled_data = pd.DataFrame(scaled_features, columns = raw_data.drop( 'TARGET CLASS' , axis= 1 ).columns) #Split the data set into training data and test data from sklearn.model_selection import train_test_split x = scaled_data y = raw_data[ 'TARGET CLASS' ] x_training_data, x_test_data, y_training_data, y_test_data = train_test_split(x, y, test_size = 0.3 ) #Train the model and make predictions from sklearn.neighbors import KNeighborsClassifier model = KNeighborsClassifier(n_neighbors = 1 ) model.fit(x_training_data, y_training_data) predictions = model.predict(x_test_data) #Performance measurement from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix print(classification_report(y_test_data, predictions)) print(confusion_matrix(y_test_data, predictions)) #Selecting an optimal K value error_rates = [] for i in np.arange( 1 , 101 ): new_model = KNeighborsClassifier(n_neighbors = i) new_model.fit(x_training_data, y_training_data) new_predictions = new_model.predict(x_test_data) error_rates.append(np.mean(new_predictions != y_test_data)) plt.figure(figsize=( 16 , 12 )) plt.plot(error_rates) نماذج K-Means Clustering (التجميع بالمتوسطات)
تُعد خوارزمية K-Means Clustering (التجميع بالمتوسطات) عادةً أول نموذج تعلم آلة غير مُشرف عليه (Unsupervised Machine Learning) يتعلمه الطلاب. على عكس التعلم المُشرف عليه، لا تتطلب نماذج التعلم غير المُشرف عليها بيانات مصنفة مسبقًا. تسمح هذه الخوارزمية لممارسي تعلم الآلة بإنشاء مجموعات (clusters) من نقاط البيانات داخل مجموعة بيانات ذات خصائص كمية متشابهة. إنها مفيدة لحل مشكلات مثل إنشاء شرائح العملاء (customer segments) أو تحديد المناطق في المدينة ذات معدلات الجريمة المرتفعة، حيث لا تكون الفئات المستهدفة معروفة مسبقًا.
في هذا القسم، ستتعلم كيفية بناء أول خوارزمية K-Means Clustering في بايثون.
مجموعة البيانات التي سنستخدمها في هذا الدليل
في هذا الدليل، سنستخدم مجموعة بيانات تم إنشاؤها بشكل اصطناعي باستخدام مكتبة scikit-learn. دعنا نستورد دالة make_blobs() من مكتبة scikit-learn لإنشاء هذه البيانات الاصطناعية. افتح Jupyter Notebook وابدأ نص بايثون البرمجي الخاص بك بالعبارة التالية:
from sklearn.datasets import make_blobs الآن دعنا نستخدم دالة make_blobs() لإنشاء بعض البيانات الاصطناعية! بشكل أكثر تحديدًا، إليك كيفية إنشاء مجموعة بيانات تحتوي على 200 عينة (n_samples)، ولها ميزتان (n_features)، و 4 مراكز تجميع (centers). سيتم تعيين الانحراف المعياري داخل كل تجميع إلى 1.8 (cluster_std).
raw_data = make_blobs(n_samples = 200 , n_features = 2 , centers = 4 , cluster_std = 1.8 ) إذا قمت بطباعة كائن raw_data هذا، ستلاحظ أنه في الواقع كائن tuple في بايثون. العنصر الأول من هذا الـ tuple هو مصفوفة NumPy تحتوي على 200 ملاحظة. تحتوي كل ملاحظة على ميزتين (تمامًا كما حددنا باستخدام دالة make_blobs()!). العنصر الثاني هو مصفوفة NumPy أخرى تحتوي على التسمية الحقيقية للتجميع الذي تنتمي إليه كل نقطة بيانات، وهو ما سنستخدمه للمقارنة لاحقًا.
الآن بعد أن تم إنشاء بياناتنا، يمكننا الانتقال إلى استيراد مكتبات مفتوحة المصدر مهمة أخرى إلى نص بايثون البرمجي.
الاستيرادات التي سنستخدمها في هذا الدليل
سيستخدم هذا الدليل عددًا من مكتبات بايثون مفتوحة المصدر الشائعة، بما في ذلك pandas و NumPy و matplotlib. دعنا نتابع نص بايثون البرمجي بإضافة الاستيرادات التالية:
import pandas as pd import numpy as np import seaborn import matplotlib.pyplot as plt %matplotlib inline المجموعة الأولى من الاستيرادات في كتلة الكود هذه مخصصة لمعالجة مجموعات البيانات الكبيرة (pandas و NumPy). والمجموعة الثانية (seaborn و matplotlib.pyplot) مخصصة لإنشاء تصورات البيانات. دعنا ننتقل إلى تصور مجموعة البيانات الخاصة بنا بعد ذلك.
تصور مجموعة البيانات
في دالة make_blobs() الخاصة بنا، حددنا أن تحتوي مجموعة البيانات على 4 مراكز تجميع. أفضل طريقة للتحقق من معالجة ذلك بشكل صحيح هي بإنشاء بعض تصورات البيانات السريعة. للبدء، دعنا نستخدم الأمر التالي لرسم جميع الصفوف في العمود الأول من مجموعة البيانات الخاصة بنا مقابل جميع الصفوف في العمود الثاني من مجموعة البيانات الخاصة بنا:
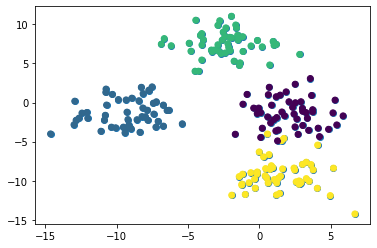
plt.scatter(raw_data[ 0 ][:, 0 ], raw_data[ 0 ][:, 1 ]) 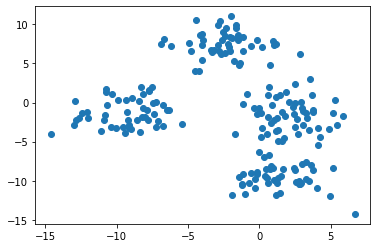
ملاحظة: ستظهر مجموعة البيانات الخاصة بك بشكل مختلف عن مجموعتي لأن هذه البيانات مُولّدة عشوائيًا. يبدو أن هذه الصورة تشير إلى أن مجموعة البيانات لدينا تحتوي على ثلاثة تجميعات فقط. هذا لأن تجميعين قريبين جدًا من بعضهما البعض.
لإصلاح هذا الالتباس، نحتاج إلى الإشارة إلى العنصر الثاني من كائن raw_data الـ tuple، وهو مصفوفة NumPy تحتوي على التجميع الذي تنتمي إليه كل ملاحظة. إذا قمنا بتلوين مجموعة البيانات الخاصة بنا باستخدام تجميع كل ملاحظة، ستصبح التجميعات الفريدة واضحة بسرعة. إليك الكود للقيام بذلك:
plt.scatter(raw_data[ 0 ][:, 0 ], raw_data[ 0 ][:, 1 ], c=raw_data[ 1 ]) 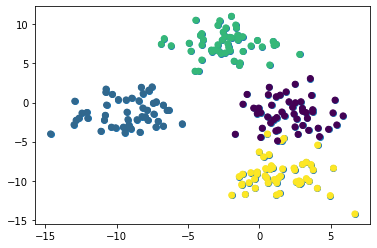
يمكننا الآن أن نرى بوضوح أن مجموعة البيانات لدينا تحتوي على أربعة تجميعات فريدة. دعنا ننتقل إلى بناء نموذج K-Means Clustering الخاص بنا في بايثون!
بناء وتدريب نموذج K-Means Clustering
الخطوة الأولى لبناء خوارزمية K-Means Clustering الخاصة بنا هي استيرادها من مكتبة scikit-learn. للقيام بذلك، أضف الأمر التالي إلى نص بايثون البرمجي:
from sklearn.cluster import KMeans بعد ذلك، دعنا ننشئ كائنًا من هذه الفئة KMeans بمعلمة n_clusters=4 (لأننا نعرف أن هناك 4 تجميعات في بياناتنا الاصطناعية) ونعينها للمتغير model:
model = KMeans(n_clusters= 4 ) الآن دعنا ندرب نموذجنا باستدعاء الدالة fit() عليه وتمرير العنصر الأول من كائن raw_data الـ tuple الخاص بنا (وهو مصفوفة البيانات الفعلية):
model.fit(raw_data[ 0 ]) في القسم التالي، سنستكشف كيفية إجراء التنبؤات باستخدام نموذج K-Means Clustering هذا. قبل المتابعة، أردت الإشارة إلى اختلاف مهم قد تكون لاحظته بين عملية بناء خوارزمية K-Means Clustering (وهي خوارزمية تعلم آلة غير مُشرف عليها) وخوارزميات تعلم الآلة المُشرف عليها التي عملنا بها حتى الآن في هذه الدورة. وهو أننا لم نضطر إلى تقسيم مجموعة البيانات إلى بيانات تدريب وبيانات اختبار. هذا اختلاف جوهري – وفي الواقع، لا تحتاج أبدًا إلى إجراء تقسيم التدريب/الاختبار على مجموعة بيانات عند بناء نماذج تعلم الآلة غير المُشرف عليها، لأن الهدف هو اكتشاف الأنماط وليس التنبؤ بفئة معروفة.
إجراء التنبؤات باستخدام نموذج K-Means Clustering
يستخدم ممارسو تعلم الآلة عمومًا خوارزميات K-Means Clustering لإجراء نوعين من التنبؤات:
- تحديد أي تجميع تنتمي إليه كل نقطة بيانات.
- تحديد أين يقع مركز كل تجميع.
من السهل إنشاء هذه التنبؤات الآن بعد تدريب نموذجنا. أولاً، دعنا نتنبأ بأي تجميع تنتمي إليه كل نقطة بيانات. للقيام بذلك، قم بالوصول إلى الخاصية labels_ من كائن model الخاص بنا باستخدام عامل النقطة (dot operator)، هكذا:
model.labels_ هذا يُنشئ مصفوفة NumPy مع تنبؤات لكل نقطة بيانات تبدو هكذا (قد تختلف الأرقام الدقيقة):
array([ 3 , 2 , 7 , 0 , 5 , 1 , 7 , 7 , 6 , 1 , 2 , 4 , 6 , 7 , 6 , 4 , 4 , 3 , 3 , 6 , 0 , 0 , 6 , 4 , 5 , 6 , 0 , 2 , 6 , 5 , 4 , 3 , 4 , 2 , 6 , 6 , 6 , 5 , 6 , 2 , 1 , 1 , 3 , 4 , 3 , 5 , 7 , 1 , 7 , 5 , 3 , 6 , 0 , 3 , 5 , 5 , 7 , 1 , 3 , 1 , 5 , 7 , 7 , 0 , 5 , 7 , 3 , 4 , 0 , 5 , 6 , 5 , 1 , 4 , 6 , 4 , 5 , 6 , 7 , 2 , 2 , 0 , 4 , 1 , 1 , 1 , 6 , 3 , 3 , 7 , 3 , 6 , 7 , 7 , 0 , 3 , 4 , 3 , 4 , 0 , 3 , 5 , 0 , 3 , 6 , 4 , 3 , 3 , 4 , 6 , 1 , 3 , 0 , 5 , 4 , 2 , 7 , 0 , 2 , 6 , 4 , 2 , 1 , 4 , 7 , 0 , 3 , 2 , 6 , 7 , 5 , 7 , 5 , 4 , 1 , 7 , 2 , 4 , 7 , 7 , 4 , 6 , 6 , 3 , 7 , 6 , 4 , 5 , 5 , 5 , 7 , 0 , 1 , 1 , 0 , 0 , 2 , 5 , 0 , 3 , 2 , 5 , 1 , 5 , 6 , 5 , 1 , 3 , 5 , 1 , 2 , 0 , 4 , 5 , 6 , 3 , 4 , 4 , 5 , 6 , 4 , 4 , 2 , 1 , 7 , 4 , 6 , 6 , 0 , 6 , 3 , 5 , 0 , 5 , 2 , 4 , 6 , 0 , 1 , 0 ], dtype=int32) لمعرفة مكان مركز كل تجميع، قم بالوصول إلى الخاصية cluster_centers_ باستخدام عامل النقطة هكذا:
model.cluster_centers_ هذا يُنشئ مصفوفة NumPy ثنائية الأبعاد تحتوي على إحداثيات مركز كل تجميع. ستبدو هكذا (قد تختلف الأرقام الدقيقة):
array([[ -8.06473328 , -0.42044783 ], [ 0.15944397 , -9.4873621 ], [ 1.49194628 , 0.21216413 ], [ -10.97238157 , -2.49017206 ], [ 3.54673215 , -9.7433692 ], [ -3.41262049 , 7.80784834 ], [ 2.53980034 , -2.96376999 ], [ -0.4195847 , 6.92561289 ]]) سنقوم بتقييم دقة هذه التنبؤات في القسم التالي.
تصور دقة النموذج
آخر شيء سنفعله في هذا الدليل هو تصور دقة نموذجنا. يمكنك استخدام الكود التالي للقيام بذلك، حيث سنُنشئ رسمين بيانيين جنبًا إلى جنب لمقارنة التجميعات المتوقعة مع التجميعات الأصلية:
f, (ax1, ax2) = plt.subplots( 1 , 2 , sharey= True ,figsize=( 10 , 6 )) ax1.set_title( 'Our Model' ) ax1.scatter(raw_data[ 0 ][:, 0 ], raw_data[ 0 ][:, 1 ],c=model.labels_) ax2.set_title( 'Original Data' ) ax2.scatter(raw_data[ 0 ][:, 0 ], raw_data[ 0 ][:, 1 ],c=raw_data[ 1 ]) 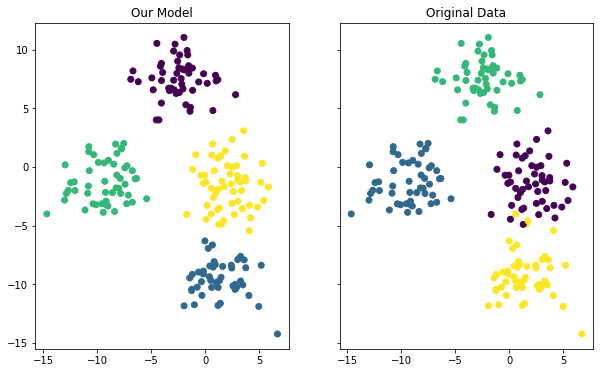
على الرغم من اختلاف الألوان بين الرسمين البيانيين (بسبب تعيين الألوان العشوائي)، يمكنك أن ترى أن نموذجنا قام بعمل جيد إلى حد ما في التنبؤ بالتجميعات داخل مجموعة البيانات الخاصة بنا. يمكنك أيضًا أن ترى أن النموذج لم يكن مثاليًا تمامًا – إذا نظرت إلى نقاط البيانات على طول حافة التجميع، يمكنك أن ترى أنه أحيانًا ما يصنف ملاحظة خاطئة من مجموعة البيانات لدينا.
هناك شيء أخير يجب ذكره حول قياس تنبؤات نموذجنا. في هذا المثال، عرفنا أي تجميع تنتمي إليه كل ملاحظة لأننا في الواقع أنشأنا مجموعة البيانات هذه بأنفسنا. هذا أمر غير معتاد للغاية في التطبيقات الواقعية. غالبًا ما يتم تطبيق K-Means Clustering عندما لا تكون التجميعات معروفة مسبقًا. بدلاً من ذلك، يستخدم ممارسو تعلم الآلة K-Means Clustering للعثور على أنماط لا يعرفونها بالفعل داخل مجموعة البيانات، مما يجعلها أداة قوية للاستكشاف وتحليل البيانات.
الكود الكامل لنموذج K-Means Clustering
يمكنك الاطلاع على الكود الكامل لهذا الدليل في مستودع GitHub الخاص بالمشروع، أو يمكنك الرجوع إليه أدناه:
#Create artificial data set from sklearn.datasets import make_blobs raw_data = make_blobs(n_samples = 200 , n_features = 2 , centers = 4 , cluster_std = 1.8 ) #Data imports import pandas as pd import numpy as np #Visualization imports import seaborn import matplotlib.pyplot as plt %matplotlib inline #Visualize the data plt.scatter(raw_data[ 0 ][:, 0 ], raw_data[ 0 ][:, 1 ]) plt.scatter(raw_data[ 0 ][:, 0 ], raw_data[ 0 ][:, 1 ], c=raw_data[ 1 ]) #Build and train the model from sklearn.cluster import KMeans model = KMeans(n_clusters= 4 ) model.fit(raw_data[ 0 ]) #See the predictions model.labels_ model.cluster_centers_ #PLot the predictions against the original data set f, (ax1, ax2) = plt.subplots( 1 , 2 , sharey= True ,figsize=( 10 , 6 )) ax1.set_title( 'Our Model' ) ax1.scatter(raw_data[ 0 ][:, 0 ], raw_data[ 0 ][:, 1 ],c=model.labels_) ax2.set_title( 'Original Data' ) ax2.scatter(raw_data[ 0 ][:, 0 ], raw_data[ 0 ][:, 1 ],c=raw_data[ 1 ]) الخلاصة التقنية
لقد استعرض هذا الدليل بشكل شامل كيفية بناء وتدريب نموذجين أساسيين في تعلم الآلة باستخدام بايثون وهما K-Nearest Neighbors و K-Means Clustering. من خلال KNN، تعلمنا كيفية التعامل مع مشكلات التصنيف المُشرف عليها، بدءًا من استيراد البيانات وتوحيد قياسها، مرورًا بتقسيمها إلى مجموعات تدريب واختبار، وصولاً إلى تدريب النموذج وتقييم أدائه وتحسينه باستخدام طريقة الكوع لاختيار قيمة K المثلى.
على الجانب الآخر، قدم K-Means Clustering مقدمة ممتازة للتعلم غير المُشرف عليه، حيث اكتشفنا كيفية تجميع نقاط البيانات المتشابهة دون الحاجة إلى تسميات مسبقة. لقد رأينا كيف يمكن إنشاء بيانات اصطناعية، تصورها، ثم بناء وتدريب نموذج K-Means لاستخراج التجميعات ومراكزها. الفارق الجوهري بين النموذجين يكمن في طبيعة البيانات التي يتعاملان معها؛ KNN يتطلب بيانات مصنفة (مُشرف عليه)، بينما K-Means يعمل على بيانات غير مصنفة (غير مُشرف عليه)، مما يجعله أداة قيمة لاكتشاف الأنماط الخفية.
يُعد إتقان هذين النموذجين خطوة حاسمة لأي مبتدئ في مجال تعلم الآلة، حيث يوفران أساسًا قويًا لفهم مفاهيم التصنيف والتجميع، وهما من الركائز الأساسية في العديد من التطبيقات العملية.