بناء وتدريب نماذج الانحدار الخطي واللوجستي للتعلم الآلي في بايثون

يُعد الانحدار الخطي (Linear Regression) والانحدار اللوجستي (Logistic Regression) من أكثر نماذج التعلم الآلي (Machine Learning) شيوعًا واستخدامًا في الوقت الحالي. في هذا الدليل الشامل، سنتعمق في كيفية إنشاء وتدريب واختبار نماذج الانحدار الخطي واللوجستي باستخدام لغة بايثون ومكتبة scikit-learn القوية، مع التركيز على التطبيق العملي والشرح المفصل.
القسم الأول: الانحدار الخطي (Linear Regression)
يهدف الانحدار الخطي إلى نمذجة العلاقة بين متغير تابع (dependent variable) ومتغير مستقل واحد أو أكثر (independent variables) عن طريق ملاءمة معادلة خطية للبيانات المرصودة. لنبدأ ببناء نموذجنا الأول.
مجموعة البيانات المستخدمة في هذا الدليل
نظرًا لأننا في بداية رحلتنا لتعلم الانحدار الخطي في التعلم الآلي، سنعمل مع مجموعات بيانات تم إنشاؤها بشكل اصطناعي. يتيح لنا هذا التركيز على مفاهيم التعلم الآلي الأساسية وتجنب قضاء وقت غير ضروري في تنظيف البيانات أو معالجتها. سنعمل بشكل خاص مع مجموعة بيانات تحتوي على معلومات عن المنازل، وسنحاول التنبؤ بأسعار المساكن.
المكتبات الأساسية التي سنستخدمها
قبل بناء النموذج، نحتاج أولاً إلى استيراد المكتبات اللازمة:
pandas: تُعد هذه المكتبة الأكثر شيوعًا في بايثون للتعامل مع البيانات الجدولية. من الشائع استيرادpandasتحت الاسم المستعارpd.NumPy: مكتبة شهيرة للحوسبة العددية، تُعرف بهيكل بيانات مصفوفةNumPy arrayوطرائقها المفيدة مثلreshapeوarangeوappend. من الشائع استيرادها تحت الاسم المستعارnp.matplotlib: مكتبة بايثون الأكثر استخدامًا لتصور البيانات. تُستورد عادةً تحت الاسم المستعارplt.seaborn: مكتبة أخرى لتصور البيانات في بايثون، تجعل إنشاء تصورات جميلة باستخدامmatplotlibأسهل.
إليك جميع عمليات الاستيراد المطلوبة:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as snsتضمن عبارة %matplotlib inline أن يتم تضمين جميع تصورات matplotlib مباشرة في دفتر ملاحظات Jupyter Notebook الخاص بنا، مما يسهل الوصول إليها وتفسيرها.
استيراد مجموعة البيانات
كما ذكرنا، سنستخدم مجموعة بيانات معلومات عن المساكن. تم رفع مجموعة البيانات هذه إلى موقع الويب الخاص بي كملف .csv على الرابط التالي:
https://nickmccullum.com/files/Housing_Data.csvلاستيراد مجموعة البيانات إلى دفتر ملاحظات Jupyter Notebook الخاص بك، يجب عليك أولاً تنزيل الملف عن طريق نسخ هذا الرابط ولصقه في متصفحك. ثم، انقل الملف إلى نفس الدليل الذي يوجد به دفتر ملاحظات Jupyter Notebook. بمجرد الانتهاء من ذلك، ستقوم عبارة بايثون التالية باستيراد مجموعة بيانات الإسكان:
raw_data = pd.read_csv('Housing_Data.csv')تحتوي مجموعة البيانات هذه على عدد من الميزات، بما في ذلك:
- متوسط الدخل في منطقة المنزل.
- متوسط العدد الإجمالي للغرف في المنطقة.
- السعر الذي بيع به المنزل.
- عنوان المنزل.
تم إنشاء هذه البيانات عشوائيًا، لذا قد تلاحظ بعض الفروق الدقيقة التي قد لا تكون منطقية عادةً (مثل عدد كبير من المنازل العشرية بعد رقم يجب أن يكون عددًا صحيحًا).
فهم مجموعة البيانات
بعد استيراد مجموعة البيانات تحت المتغير raw_data، يمكنك استخدام طريقة info() للحصول على بعض المعلومات عالية المستوى حول مجموعة البيانات. على وجه التحديد، تشغيل raw_data.info() يعطي:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5000 entries, 0 to 4999
Data columns (total 7 columns):
Avg. Area Income 5000 non-null float64
Avg. Area House Age 5000 non-null float64
Avg. Area Number of Rooms 5000 non-null float64
Avg. Area Number of Bedrooms 5000 non-null float64
Area Population 5000 non-null float64
Price 5000 non-null float64
Address 5000 non-null object
dtypes: float64(6), object(1)
memory usage: 273.6+ KBطريقة أخرى مفيدة يمكنك من خلالها التعرف على مجموعة البيانات هذه هي عن طريق إنشاء مخطط زوجي (pairplot). يمكنك استخدام طريقة pairplot من مكتبة seaborn لهذا الغرض، وتمرير DataFrame بأكمله كمعامل. إليك العبارة الكاملة لذلك:
sns.pairplot(raw_data)إليك المخطط الزوجي الذي تم إنشاؤه:

الآن، لنبدأ ببناء نموذج الانحدار الخطي الخاص بنا.
بناء نموذج الانحدار الخطي للتعلم الآلي
أول شيء نحتاج إلى القيام به هو تقسيم بياناتنا إلى مصفوفة x (التي تحتوي على البيانات التي سنستخدمها لإجراء التنبؤات) ومصفوفة y (التي تحتوي على البيانات التي نحاول التنبؤ بها). أولاً، يجب أن نقرر الأعمدة التي سيتم تضمينها. يمكنك إنشاء قائمة بأعمدة DataFrame باستخدام raw_data.columns، والتي تنتج:
Index(['Avg. Area Income', 'Avg. Area House Age', 'Avg. Area Number of Rooms',
'Avg. Area Number of Bedrooms', 'Area Population', 'Price', 'Address'],
dtype='object')سنستخدم جميع هذه المتغيرات في مصفوفة x باستثناء Price (لأنه المتغير الذي نحاول التنبؤ به) و Address (لأنه يحتوي على نص فقط). لنقم بإنشاء مصفوفة x الخاصة بنا وتعيينها لمتغير يسمى x.
x = raw_data[['Avg. Area Income', 'Avg. Area House Age', 'Avg. Area Number of Rooms',
'Avg. Area Number of Bedrooms', 'Area Population']]بعد ذلك، لنقم بإنشاء مصفوفة y الخاصة بنا وتعيينها لمتغير يسمى y.
y = raw_data['Price']لقد قسمنا بنجاح مجموعة بياناتنا إلى مصفوفة x (وهي قيم الإدخال لنموذجنا) ومصفوفة y (وهي قيم الإخراج لنموذجنا). سنتعلم كيفية تقسيم مجموعة بياناتنا بشكل أكبر إلى بيانات تدريب وبيانات اختبار في القسم التالي.
تقسيم مجموعة البيانات إلى بيانات تدريب واختبار
تُسهل مكتبة scikit-learn تقسيم مجموعة بياناتنا إلى بيانات تدريب وبيانات اختبار. للقيام بذلك، سنحتاج إلى استيراد الدالة train_test_split من الوحدة النمطية model_selection في scikit-learn. إليك الكود الكامل لذلك:
from sklearn.model_selection import train_test_splitتقبل دالة train_test_split ثلاثة وسائط:
- مصفوفة
xالخاصة بنا. - مصفوفة
yالخاصة بنا. - الحجم المطلوب لبيانات الاختبار الخاصة بنا (
test_size).
باستخدام هذه المعلمات، ستقوم دالة train_test_split بتقسيم بياناتنا! إليك الكود للقيام بذلك إذا أردنا أن تكون بيانات الاختبار لدينا 30% من مجموعة البيانات بأكملها:
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3)تُرجع دالة train_test_split قائمة بايثون بطول 4، حيث كل عنصر في القائمة هو x_train و x_test و y_train و y_test على التوالي. ثم نستخدم تفكيك القائمة لتعيين القيم الصحيحة لأسماء المتغيرات الصحيحة. الآن بعد أن قسمنا مجموعة بياناتنا بشكل صحيح، حان الوقت لبناء وتدريب نموذج الانحدار الخطي للتعلم الآلي الخاص بنا.
بناء وتدريب النموذج
أول شيء نحتاج إلى القيام به هو استيراد المقدر LinearRegression من scikit-learn. إليك عبارة بايثون لذلك:
from sklearn.linear_model import LinearRegressionبعد ذلك، نحتاج إلى إنشاء مثيل لكائن بايثون LinearRegression. سنقوم بتعيين هذا لمتغير يسمى model. إليك الكود لذلك:
model = LinearRegression()يمكننا استخدام طريقة fit من scikit-learn لتدريب هذا النموذج على بيانات التدريب الخاصة بنا.
model.fit(x_train, y_train)لقد تم تدريب نموذجنا الآن. يمكنك فحص كل معامل من معاملات النموذج باستخدام العبارة التالية:
print(model.coef_)الناتج هو:
[ 2.16176350e+01 1.65221120e+05 1.21405377e+05 1.31871878e+03 1.52251955e+01 ]وبالمثل، إليك كيفية رؤية نقطة التقاطع (intercept) لمعادلة الانحدار:
print(model.intercept_)الناتج هو:
-2641372.6673013503طريقة أفضل لعرض المعاملات هي وضعها في DataFrame. يمكن القيام بذلك باستخدام العبارة التالية:
pd.DataFrame(model.coef_, x.columns, columns = ['Coeff'])الناتج في هذه الحالة أسهل بكثير في التفسير:
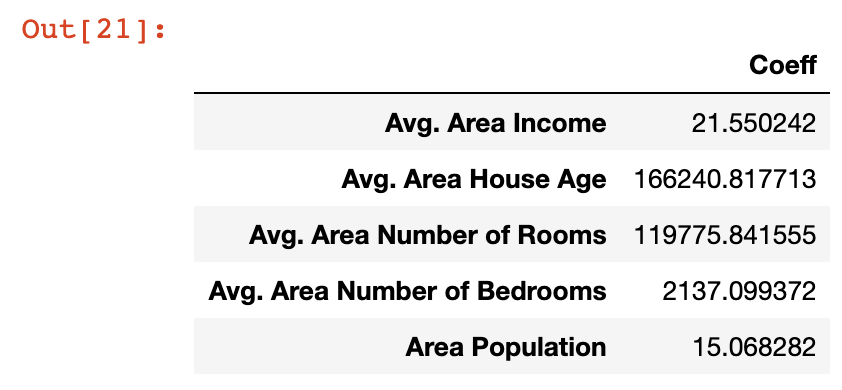
لنأخذ لحظة لفهم ما تعنيه هذه المعاملات. دعنا ننظر إلى متغير Area Population على وجه التحديد، والذي له معامل يبلغ حوالي 15. هذا يعني أنه إذا حافظت على جميع المتغيرات الأخرى ثابتة، فإن زيادة وحدة واحدة في Area Population ستؤدي إلى زيادة 15 وحدة في المتغير المتنبأ به – في هذه الحالة، Price. بعبارة أخرى، المعاملات الكبيرة لمتغير معين تعني أن هذا المتغير له تأثير كبير على قيمة المتغير الذي تحاول التنبؤ به. وبالمثل، القيم الصغيرة لها تأثير صغير.
الآن بعد أن أنشأنا أول نموذج انحدار خطي للتعلم الآلي، حان الوقت لاستخدام النموذج لإجراء تنبؤات من مجموعة بيانات الاختبار الخاصة بنا.
إجراء التنبؤات باستخدام نموذجنا
تُسهل مكتبة scikit-learn إجراء التنبؤات من نموذج التعلم الآلي. ما عليك سوى استدعاء طريقة predict على متغير model الذي أنشأناه سابقًا. نظرًا لأن متغير predict مصمم لإجراء التنبؤات، فإنه يقبل فقط معلمة مصفوفة x. سيقوم بإنشاء قيم y لك! إليك الكود الذي ستحتاجه لإنشاء تنبؤات من نموذجنا باستخدام طريقة predict:
predictions = model.predict(x_test)يحتوي المتغير predictions على القيم المتوقعة للميزات المخزنة في x_test. نظرًا لأننا استخدمنا طريقة train_test_split لتخزين القيم الحقيقية في y_test، فإن ما نريد القيام به بعد ذلك هو مقارنة قيم مصفوفة predictions بقيم y_test. طريقة سهلة للقيام بذلك هي رسم المصفوفتين باستخدام مخطط مبعثر (scatterplot). من السهل بناء مخططات matplotlib scatterplots باستخدام طريقة plt.scatter. إليك الكود لذلك:
plt.scatter(y_test, predictions)إليك المخطط المبعثر الذي ينشئه هذا الكود:
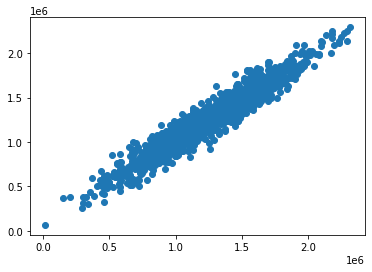
كما ترى، فإن قيمنا المتوقعة قريبة جدًا من القيم الفعلية للملاحظات في مجموعة البيانات. يشير الخط القطري المستقيم تمامًا في هذا المخطط المبعثر إلى أن نموذجنا تنبأ تمامًا بقيم مصفوفة y.
طريقة أخرى لتقييم أداء نموذجنا بصريًا هي رسم residuals (البواقي)، وهي الفرق بين قيم مصفوفة y الفعلية وقيم مصفوفة y المتوقعة. طريقة سهلة للقيام بذلك هي باستخدام العبارة التالية:
plt.hist(y_test - predictions)إليك التصور الذي ينشئه هذا الكود:
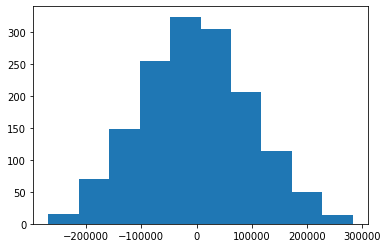
هذا مخطط بياني للبواقي من نموذج التعلم الآلي الخاص بنا. قد تلاحظ أن البواقي من نموذج التعلم الآلي الخاص بنا تبدو موزعة بشكل طبيعي. هذه علامة جيدة جدًا! تشير إلى أننا اخترنا نوع نموذج مناسب (في هذه الحالة، الانحدار الخطي) لإجراء تنبؤات من مجموعة بياناتنا.
اختبار أداء النموذج
هناك ثلاثة مقاييس أداء رئيسية تُستخدم لنماذج الانحدار في التعلم الآلي:
- متوسط الخطأ المطلق (
Mean Absolute Error - MAE) - متوسط الخطأ التربيعي (
Mean Squared Error - MSE) - الجذر التربيعي لمتوسط الخطأ التربيعي (
Root Mean Squared Error - RMSE)
سنرى الآن كيفية حساب كل من هذه المقاييس للنموذج الذي بنيناه في هذا الدليل. قبل المتابعة، قم بتشغيل عبارة الاستيراد التالية داخل دفتر ملاحظات Jupyter Notebook الخاص بك:
from sklearn import metricsمتوسط الخطأ المطلق (MAE)
يمكنك حساب متوسط الخطأ المطلق في بايثون باستخدام العبارة التالية:
metrics.mean_absolute_error(y_test, predictions)متوسط الخطأ التربيعي (MSE)
وبالمثل، يمكنك حساب متوسط الخطأ التربيعي في بايثون باستخدام العبارة التالية:
metrics.mean_squared_error(y_test, predictions)الجذر التربيعي لمتوسط الخطأ التربيعي (RMSE)
على عكس متوسط الخطأ المطلق ومتوسط الخطأ التربيعي، لا تحتوي مكتبة scikit-learn في الواقع على طريقة مدمجة لحساب الجذر التربيعي لمتوسط الخطأ التربيعي. لحسن الحظ، لا تحتاج إلى ذلك حقًا. نظرًا لأن الجذر التربيعي لمتوسط الخطأ التربيعي هو ببساطة الجذر التربيعي لمتوسط الخطأ التربيعي، يمكنك استخدام طريقة sqrt من NumPy لحسابه بسهولة:
np.sqrt(metrics.mean_squared_error(y_test, predictions))الكود الكامل للقسم الأول (الانحدار الخطي)
إليك الكود الكامل لنموذج الانحدار الخطي في بايثون:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
raw_data = pd.read_csv('Housing_Data.csv')
x = raw_data[['Avg. Area Income', 'Avg. Area House Age', 'Avg. Area Number of Rooms',
'Avg. Area Number of Bedrooms', 'Area Population']]
y = raw_data['Price']
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3)
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_train, y_train)
print(model.coef_)
print(model.intercept_)
pd.DataFrame(model.coef_, x.columns, columns = ['Coeff'])
predictions = model.predict(x_test)
plt.scatter(y_test, predictions)
plt.hist(y_test - predictions)
from sklearn import metrics
metrics.mean_absolute_error(y_test, predictions)
metrics.mean_squared_error(y_test, predictions)
np.sqrt(metrics.mean_squared_error(y_test, predictions))القسم الثاني: الانحدار اللوجستي (Logistic Regression)
بينما يُستخدم الانحدار الخطي للتنبؤ بقيم مستمرة، يُستخدم الانحدار اللوجستي لمشاكل التصنيف (classification problems)، حيث يكون المتغير التابع ثنائيًا (مثل نعم/لا، 0/1). إذا كنت قد قمت بالبرمجة مع هذا الدليل حتى الآن وبنيت نموذج الانحدار الخطي الخاص بك بالفعل، فستحتاج إلى فتح دفتر ملاحظات Jupyter Notebook جديد (بدون أي كود فيه) قبل المتابعة.
مجموعة البيانات المستخدمة في هذا القسم
تُعد مجموعة بيانات تايتانيك (Titanic data set) مجموعة بيانات مشهورة جدًا تحتوي على خصائص حول الركاب على متن سفينة تايتانيك. تُستخدم غالبًا كمجموعة بيانات تمهيدية لمشاكل الانحدار اللوجستي. في هذا الدليل، سنستخدم مجموعة بيانات تايتانيك جنبًا إلى جنب مع نموذج انحدار لوجستي في بايثون للتنبؤ بما إذا كان الراكب قد نجا من حادث تحطم تايتانيك أم لا.
مجموعة بيانات تايتانيك الأصلية متاحة للجمهور على موقع Kaggle.com، وهو موقع يستضيف مجموعات البيانات ومسابقات علوم البيانات. لتسهيل الأمور عليك كطالب في هذه الدورة، سنستخدم نسخة شبه نظيفة من مجموعة بيانات تايتانيك، مما سيوفر عليك الوقت في تنظيف البيانات ومعالجتها. يمكنك تنزيل ملف البيانات بالنقر على الرابط المتاح.
بمجرد تنزيل هذا الملف، افتح دفتر ملاحظات Jupyter Notebook في نفس دليل العمل، ويمكننا البدء في بناء نموذج الانحدار اللوجستي الخاص بنا.
عمليات الاستيراد المطلوبة
كما كان من قبل، سنستخدم العديد من مكتبات البرامج مفتوحة المصدر في هذا الدليل. إليك عمليات الاستيراد التي ستحتاج إلى تشغيلها للمتابعة أثناء قيامي ببرمجة نموذج الانحدار اللوجستي في بايثون:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as snsبعد ذلك، سنحتاج إلى استيراد مجموعة بيانات تايتانيك إلى برنامج بايثون الخاص بنا.
استيراد مجموعة البيانات إلى برنامج بايثون الخاص بنا
سنستخدم طريقة read_csv من pandas لاستيراد ملفات csv الخاصة بنا إلى pandas DataFrames تسمى titanic_data. إليك الكود للقيام بذلك:
titanic_data = pd.read_csv('titanic_train.csv')بعد ذلك، دعنا نستكشف البيانات المضمنة بالفعل في مجموعة بيانات تايتانيك. هناك طريقتان رئيسيتان للقيام بذلك (باستخدام DataFrame الخاص بـ titanic_data على وجه التحديد):
- ستقوم طريقة
titanic_data.head(5)بطباعة أول 5 صفوف منDataFrame. يمكنك استبدال5بأي رقم تريده. - يمكنك أيضًا طباعة
titanic_data.columns، والذي سيعرض لك أسماء الأعمدة.
تشغيل الأمر الثاني (titanic_data.columns) يولد الناتج التالي:
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')هذه هي أسماء الأعمدة في DataFrame. إليك شروحات موجزة لكل نقطة بيانات:
PassengerId: معرف رقمي لكل راكب على متن تايتانيك.Survived: معرف ثنائي يشير إلى ما إذا كان الراكب قد نجا من حادث تحطم تايتانيك أم لا. سيحتوي هذا المتغير على قيمة1إذا نجا و0إذا لم ينجُ.Pclass: درجة الراكب. يمكن أن يحمل قيمة1أو2أو3، اعتمادًا على مكان الراكب في السفينة.Name: اسم الراكب.Sex: ذكر أو أنثى.Age: عمر الراكب (بالسنوات).SibSp: عدد الأشقاء والأزواج على متن السفينة.Parch: عدد الآباء والأطفال على متن السفينة.Ticket: رقم تذكرة الراكب.Fare: المبلغ الذي دفعه الراكب مقابل تذكرته على متن تايتانيك.Cabin: رقم كابينة الراكب.Embarked: الميناء الذي صعد منه الراكب (C = Cherbourg،Q = Queenstown،S = Southampton).
بعد ذلك، سنتعلم المزيد عن مجموعة بياناتنا باستخدام بعض تقنيات تحليل البيانات الاستكشافية الأساسية.
فهم مجموعة البيانات من خلال تحليل البيانات الاستكشافية (EDA)
انتشار كل فئة تصنيفية
عند استخدام تقنيات التعلم الآلي لنمذجة مشاكل التصنيف، من الجيد دائمًا أن يكون لديك فكرة عن النسبة بين الفئات. لهذه المشكلة المحددة، من المفيد معرفة عدد الناجين مقابل غير الناجين الموجودين في بيانات التدريب لدينا. طريقة سهلة لتصور ذلك هي استخدام مخطط countplot من seaborn. في هذا المثال، يمكنك إنشاء مخطط seaborn المناسب باستخدام كود بايثون التالي:
sns.countplot(x='Survived', data=titanic_data)هذا يولد المخطط التالي:
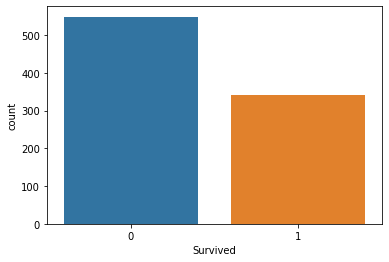
كما ترى، لدينا عدد أكبر بكثير من حالات غير الناجين مقارنة بالناجين.
معدلات البقاء على قيد الحياة بين الجنسين
من المفيد أيضًا مقارنة معدلات البقاء على قيد الحياة بالنسبة لبعض ميزات البيانات الأخرى. على سبيل المثال، يمكننا مقارنة معدلات البقاء على قيد الحياة بين قيم Male و Female لـ Sex باستخدام كود بايثون التالي:
sns.countplot(x='Survived', hue='Sex', data=titanic_data)هذا يولد المخطط التالي:
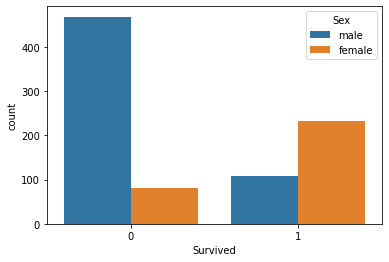
كما ترى، كان الركاب ذوو الجنس Male أكثر عرضة بكثير لعدم النجاة من الركاب ذوي الجنس Female.
معدلات البقاء على قيد الحياة بين فئات الركاب
يمكننا إجراء تحليل مماثل باستخدام متغير Pclass لمعرفة أي فئة ركاب كانت الأكثر (والأقل) احتمالًا أن يكون لديها ركاب ناجون. إليك الكود للقيام بذلك:
sns.countplot(x='Survived', hue='Pclass', data=titanic_data)هذا يولد المخطط التالي:
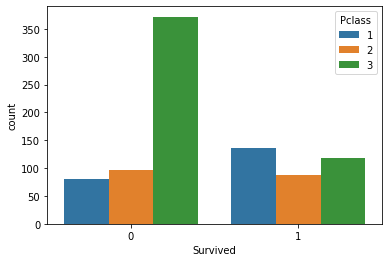
الملاحظة الأكثر وضوحًا من هذا المخطط هي أن الركاب ذوي قيمة Pclass البالغة 3 – والتي تشير إلى الدرجة الثالثة، وهي الأرخص والأقل فخامة – كانوا أكثر عرضة للوفاة عند تحطم تايتانيك.
توزيع أعمار ركاب تايتانيك
تحليل آخر مفيد يمكننا إجراؤه هو التحقيق في توزيع أعمار ركاب تايتانيك. المخطط البياني (histogram) أداة ممتازة لذلك. يمكنك إنشاء مخطط بياني لمتغير Age باستخدام الكود التالي:
plt.hist(titanic_data['Age'].dropna())لاحظ أن طريقة dropna() ضرورية لأن مجموعة البيانات تحتوي على عدة قيم فارغة (nulls). إليك المخطط البياني الذي ينشئه هذا الكود:
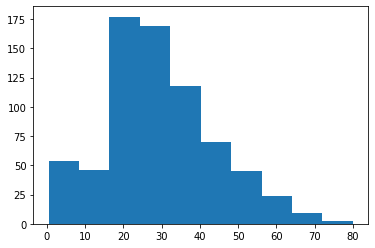
كما ترى، هناك تركيز لركاب تايتانيك تتراوح أعمارهم بين 20 و 40 عامًا.
توزيع أسعار تذاكر ركاب تايتانيك
آخر تقنية تحليل بيانات استكشافية سنستخدمها هي التحقيق في توزيع أسعار الأجرة ضمن مجموعة بيانات تايتانيك. يمكنك القيام بذلك باستخدام الكود التالي:
plt.hist(titanic_data['Fare'])هذا يولد المخطط التالي:
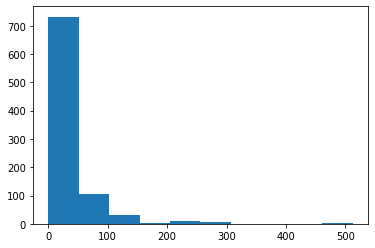
كما ترى، هناك ثلاث مجموعات متميزة من أسعار Fare ضمن مجموعة بيانات تايتانيك. هذا منطقي لأن هناك أيضًا ثلاث قيم فريدة لمتغير Pclass. تتوافق مجموعات Fare المختلفة مع فئات Pclass المختلفة. نظرًا لأن مجموعة بيانات تايتانيك هي مجموعة بيانات من العالم الحقيقي، فإنها تحتوي على بعض البيانات المفقودة. سنتعلم كيفية التعامل مع البيانات المفقودة في القسم التالي.
إزالة البيانات الفارغة من مجموعة البيانات
للبدء، دعنا نفحص أين تحتوي مجموعة بياناتنا على بيانات مفقودة. للقيام بذلك، قم بتشغيل الأمر التالي:
titanic_data.isnull()سيؤدي هذا إلى إنشاء DataFrame من القيم المنطقية (boolean values) حيث تحتوي الخلية على True إذا كانت قيمة فارغة و False بخلاف ذلك. إليك صورة لما يبدو عليه هذا:
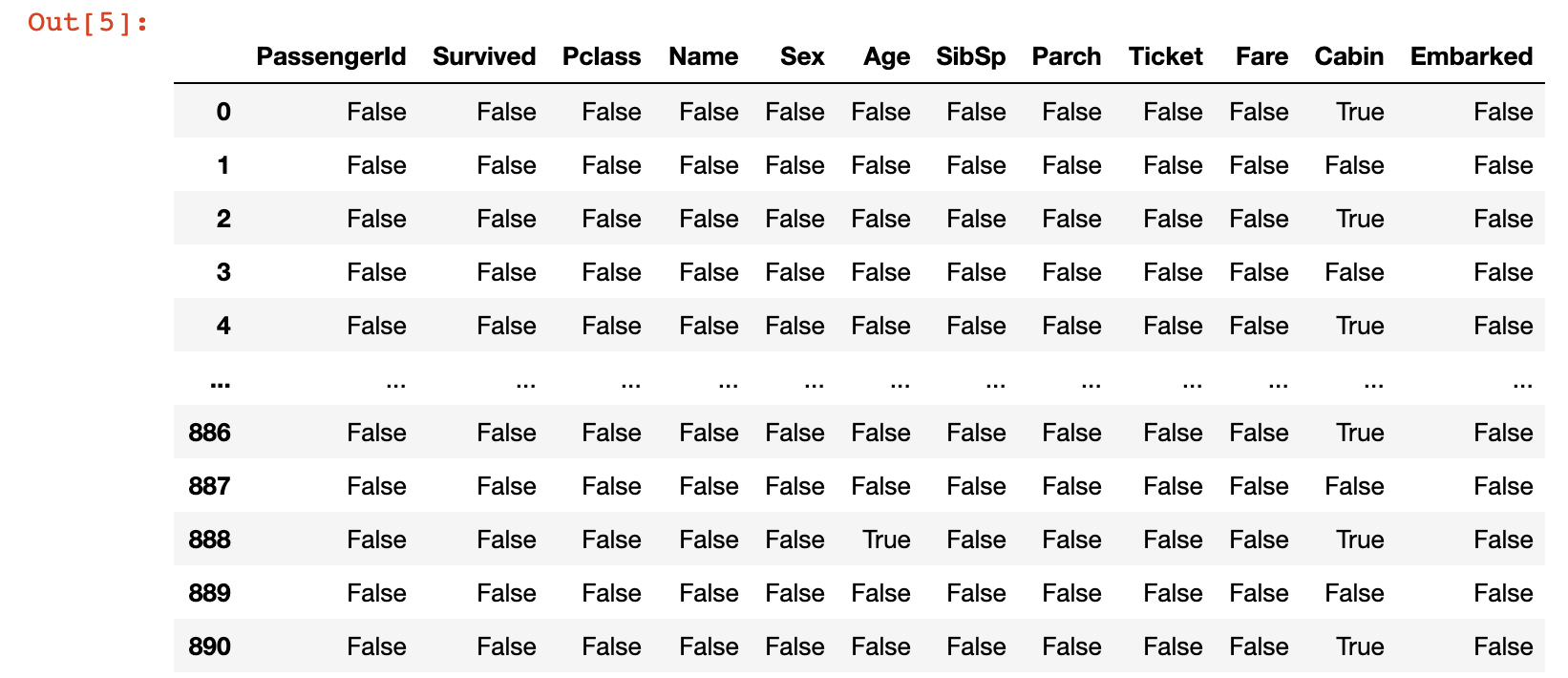
طريقة أكثر فائدة بكثير لتقييم البيانات المفقودة في مجموعة البيانات هذه هي عن طريق إنشاء تصور سريع. للقيام بذلك، يمكننا استخدام مكتبة seaborn لتصور البيانات. إليك أمر سريع يمكنك استخدامه لإنشاء heatmap باستخدام مكتبة seaborn:
sns.heatmap(titanic_data.isnull(), cbar=False)إليك التصور الذي ينشئه هذا:

في هذا التصور، تشير الخطوط البيضاء إلى قيم مفقودة في مجموعة البيانات. يمكنك أن ترى أن عمودي Age و Cabin يحتويان على غالبية البيانات المفقودة في مجموعة بيانات تايتانيك. يحتوي عمود Age على كمية صغيرة بما يكفي من البيانات المفقودة بحيث يمكننا ملء البيانات المفقودة باستخدام شكل من أشكال الرياضيات. من ناحية أخرى، تفتقد بيانات Cabin ما يكفي من البيانات لدرجة أننا يمكننا إزالتها بالكامل من نموذجنا.
تُسمى عملية ملء البيانات المفقودة بمتوسط البيانات من بقية مجموعة البيانات imputation (الاستيفاء). سنستخدم الآن imputation لملء البيانات المفقودة من عمود Age. أبسط شكل من أشكال imputation هو ملء بيانات Age المفقودة بمتوسط قيمة Age عبر مجموعة البيانات بأكملها. ومع ذلك، هناك طرق أفضل. سنقوم بملء قيم Age المفقودة بمتوسط قيمة Age لفئة الركاب Pclass المحددة التي ينتمي إليها الراكب.
لفهم سبب فائدة ذلك، ضع في اعتبارك مخطط الصندوق (boxplot) التالي:
sns.boxplot(titanic_data['Pclass'], titanic_data['Age']) 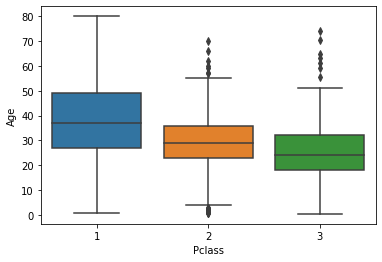
كما ترى، يميل الركاب ذوو قيمة Pclass البالغة 1 (فئة الركاب الأكثر تكلفة) إلى أن يكونوا الأكبر سنًا، بينما يميل الركاب ذوو قيمة Pclass البالغة 3 (الأرخص) إلى أن يكونوا الأصغر سنًا. هذا منطقي جدًا، لذلك سنستخدم متوسط قيمة Age ضمن بيانات Pclass المختلفة لـ imputate البيانات المفقودة في عمود Age الخاص بنا.
أسهل طريقة لإجراء imputation على مجموعة بيانات مثل مجموعة بيانات تايتانيك هي بناء دالة مخصصة. للبدء، سنحتاج إلى تحديد متوسط قيمة Age لكل قيمة Pclass.
#Pclass value 1
titanic_data[titanic_data['Pclass'] == 1]['Age'].mean()
#Pclass value 2
titanic_data[titanic_data['Pclass'] == 2]['Age'].mean()
#Pclass 3
titanic_data[titanic_data['Pclass'] == 3]['Age'].mean()إليك الدالة النهائية التي سنستخدمها لـ imputate متغيرات Age المفقودة لدينا:
def impute_missing_age(columns):
age = columns[0]
passenger_class = columns[1]
if pd.isnull(age):
if (passenger_class == 1):
return titanic_data[titanic_data['Pclass'] == 1]['Age'].mean()
elif(passenger_class == 2):
return titanic_data[titanic_data['Pclass'] == 2]['Age'].mean()
elif(passenger_class == 3):
return titanic_data[titanic_data['Pclass'] == 3]['Age'].mean()
else:
return ageالآن بعد اكتمال دالة الاستيفاء هذه، نحتاج إلى تطبيقها على كل صف في DataFrame الخاص بـ titanic_data. تُعد طريقة apply في بايثون أداة ممتازة لذلك:
titanic_data['Age'] = titanic_data[['Age', 'Pclass']].apply(impute_missing_age, axis = 1)الآن بعد أن قمنا بإجراء imputation على كل صف للتعامل مع بيانات Age المفقودة لدينا، دعنا نفحص مخطط الصندوق الأصلي لدينا مرة أخرى:
sns.heatmap(titanic_data.isnull(), cbar=False)ستلاحظ أنه لم يعد هناك أي بيانات مفقودة في عمود Age في pandas DataFrame الخاص بنا! قد تتساءل لماذا قضينا الكثير من الوقت في التعامل مع البيانات المفقودة في عمود Age على وجه التحديد. ذلك لأنه بالنظر إلى تأثير Age على البقاء على قيد الحياة في معظم الكوارث والأمراض، فمن المحتمل أن يكون متغيرًا ذا قيمة تنبؤية عالية ضمن مجموعة بياناتنا.
الآن بعد أن أصبح لدينا فهم لهيكل مجموعة البيانات هذه وقمنا بإزالة بياناتها المفقودة، دعنا نبدأ ببناء نموذج الانحدار اللوجستي للتعلم الآلي الخاص بنا.
بناء نموذج الانحدار اللوجستي
حان الوقت الآن لإزالة نموذج الانحدار اللوجستي.
إزالة الأعمدة التي تحتوي على الكثير من البيانات المفقودة
أولاً، دعنا نزيل عمود Cabin. كما ذكرنا، فإن الانتشار الكبير للبيانات المفقودة في هذا العمود يعني أنه من غير الحكمة إجراء impute للبيانات المفقودة، لذلك سنقوم بإزالتها بالكامل باستخدام الكود التالي:
titanic_data.drop('Cabin', axis=1, inplace = True)بعد ذلك، دعنا نزيل أي أعمدة إضافية تحتوي على بيانات مفقودة باستخدام طريقة dropna() من pandas:
titanic_data.dropna(inplace = True)التعامل مع البيانات الفئوية باستخدام المتغيرات الوهمية (Dummy Variables)
المهمة التالية التي نحتاج إلى التعامل معها هي التعامل مع الميزات الفئوية (categorical features). على وجه التحديد، نحتاج إلى إيجاد طريقة للعمل رقميًا مع الملاحظات التي ليست رقمية بطبيعتها. مثال رائع على ذلك هو عمود Sex، الذي يحتوي على قيمتين: Male و Female. وبالمثل، يحتوي عمود Embarked على حرف واحد يشير إلى المدينة التي غادر منها الراكب. لحل هذه المشكلة، سنقوم بإنشاء dummy variables (متغيرات وهمية). هذه المتغيرات تعين قيمة رقمية لكل فئة من ميزة غير رقمية.
لحسن الحظ، تحتوي pandas على طريقة مدمجة تسمى get_dummies() تجعل إنشاء المتغيرات الوهمية أمرًا سهلاً. ومع ذلك، فإن طريقة get_dummies لديها مشكلة واحدة – ستنشئ عمودًا جديدًا لكل قيمة في عمود DataFrame. دعنا نأخذ مثالًا للمساعدة في فهم هذا بشكل أفضل. إذا استدعينا طريقة get_dummies() على عمود Sex، نحصل على الناتج التالي:
pd.get_dummies(titanic_data['Sex']) 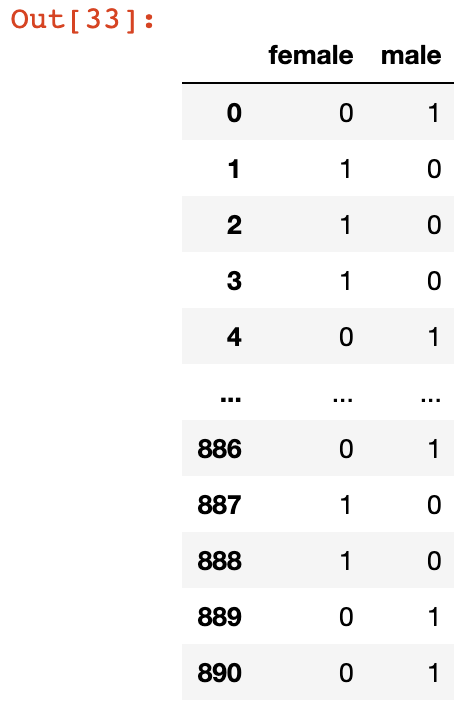
كما ترى، هذا ينشئ عمودين جديدين: female و male. سيكون هذان العمودان متنبئين مثاليين لبعضهما البعض، حيث تشير قيمة 0 في عمود female إلى قيمة 1 في عمود male، والعكس صحيح. يُسمى هذا multicollinearity (التعدد الخطي)، ويقلل بشكل كبير من القوة التنبؤية لخوارزميتك. لإزالة هذا، يمكننا إضافة الوسيطة drop_first = True إلى طريقة get_dummies على النحو التالي:
pd.get_dummies(titanic_data['Sex'], drop_first = True)الآن، دعنا ننشئ أعمدة متغيرات وهمية لأعمدة Sex و Embarked، ونعينها لمتغيرات تسمى sex_data و embarked_data.
sex_data = pd.get_dummies(titanic_data['Sex'], drop_first = True)
embarked_data = pd.get_dummies(titanic_data['Embarked'], drop_first = True)هناك شيء واحد مهم يجب ملاحظته حول متغير embarked_data. يحتوي على عمودين: Q و S، ولكن نظرًا لأننا أزلنا بالفعل عمودًا آخر (عمود C)، فلا يوجد أي من العمودين المتبقيين متنبئًا مثاليًا لبعضهما البعض، وبالتالي لا يوجد multicollinearity في مجموعة البيانات الجديدة المعدلة.
إضافة المتغيرات الوهمية إلى pandas DataFrame
بعد ذلك، نحتاج إلى إضافة أعمدة sex_data و embarked_data إلى DataFrame. يمكنك دمج أعمدة البيانات هذه في pandas DataFrame الحالي باستخدام الكود التالي:
titanic_data = pd.concat([titanic_data, sex_data, embarked_data], axis = 1)الآن إذا قمت بتشغيل الأمر print(titanic_data.columns)، فسيقوم دفتر ملاحظات Jupyter Notebook الخاص بك بإنشاء الناتج التالي:
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Embarked', 'male', 'Q', 'S'],
dtype='object')يشير وجود أعمدة male و Q و S إلى أن بياناتنا تم دمجها بنجاح.
إزالة الأعمدة غير الضرورية من مجموعة البيانات
هذا يعني أنه يمكننا الآن إسقاط أعمدة Sex و Embarked الأصلية من DataFrame. هناك أيضًا أعمدة أخرى (مثل Name و PassengerId و Ticket) ليست تنبؤية بمعدلات البقاء على قيد الحياة في حادث تحطم تايتانيك، لذلك سنقوم بإزالتها أيضًا. يتعامل الكود التالي مع هذا الأمر لنا:
titanic_data.drop(['Name', 'Ticket', 'Sex', 'Embarked'], axis = 1, inplace = True)إذا قمت بطباعة titanic_data.columns الآن، فسيقوم دفتر ملاحظات Jupyter Notebook الخاص بك بإنشاء الناتج التالي:
Index(['Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Fare', 'male', 'Q', 'S'], dtype='object')يظهر DataFrame الآن بالشكل التالي:

كما ترى، كل حقل في مجموعة البيانات هذه أصبح الآن رقميًا، مما يجعله مرشحًا ممتازًا لخوارزمية الانحدار اللوجستي للتعلم الآلي.
إنشاء بيانات التدريب وبيانات الاختبار
بعد ذلك، حان الوقت لتقسيم titanic_data إلى بيانات تدريب وبيانات اختبار. كما كان من قبل، سنستخدم وظائف مدمجة من scikit-learn للقيام بذلك. أولاً، نحتاج إلى تقسيم بياناتنا إلى قيم x (البيانات التي سنستخدمها لإجراء التنبؤات) وقيم y (البيانات التي نحاول التنبؤ بها). يتعامل الكود التالي مع هذا:
y_data = titanic_data['Survived']
x_data = titanic_data.drop('Survived', axis = 1)بعد ذلك، نحتاج إلى استيراد دالة train_test_split من scikit-learn. ينفذ الكود التالي هذا الاستيراد:
from sklearn.model_selection import train_test_splitأخيرًا، يمكننا استخدام دالة train_test_split جنبًا إلى جنب مع تفكيك القائمة لإنشاء بيانات التدريب وبيانات الاختبار لدينا:
x_training_data, x_test_data, y_training_data, y_test_data = train_test_split(x_data, y_data, test_size = 0.3)لاحظ أنه في هذه الحالة، تمثل بيانات الاختبار 30% من مجموعة البيانات الأصلية كما هو محدد بالمعامل test_size = 0.3. لقد أنشأنا الآن بيانات التدريب وبيانات الاختبار لنموذج الانحدار اللوجستي الخاص بنا. سنقوم بتدريب نموذجنا في القسم التالي من هذا الدليل.
تدريب نموذج الانحدار اللوجستي
لتدريب نموذجنا، سنحتاج أولاً إلى استيراد النموذج المناسب من scikit-learn باستخدام الأمر التالي:
from sklearn.linear_model import LogisticRegressionبعد ذلك، نحتاج إلى إنشاء نموذجنا عن طريق إنشاء مثيل لكائن LogisticRegression:
model = LogisticRegression()لتدريب النموذج، نحتاج إلى استدعاء طريقة fit على كائن LogisticRegression الذي أنشأناه للتو وتمرير متغيرات x_training_data و y_training_data الخاصة بنا، على النحو التالي:
model.fit(x_training_data, y_training_data)لقد تم تدريب نموذجنا الآن. سنبدأ في إجراء التنبؤات باستخدام هذا النموذج في القسم التالي من هذا الدليل.
إجراء التنبؤات باستخدام نموذج الانحدار اللوجستي الخاص بنا
دعنا ننشئ مجموعة من التنبؤات على بيانات الاختبار الخاصة بنا باستخدام نموذج الانحدار اللوجستي model الذي أنشأناه للتو. سنقوم بتخزين هذه التنبؤات في متغير يسمى predictions:
predictions = model.predict(x_test_data)لقد تم إجراء تنبؤاتنا. دعنا نفحص دقة نموذجنا بعد ذلك.
قياس أداء نموذج الانحدار اللوجستي للتعلم الآلي
تحتوي scikit-learn على وحدة نمطية مدمجة ممتازة تسمى classification_report تجعل قياس أداء نموذج التعلم الآلي للتصنيف أمرًا سهلاً. سنستخدم هذه الوحدة النمطية لقياس أداء النموذج الذي أنشأناه للتو. أولاً، دعنا نستورد الوحدة النمطية:
from sklearn.metrics import classification_reportبعد ذلك، دعنا نستخدم الوحدة النمطية لحساب مقاييس الأداء لوحدة الانحدار اللوجستي للتعلم الآلي الخاصة بنا:
print(classification_report(y_test_data, predictions))إليك الناتج لهذا الأمر:
precision recall f1-score support
0 0.83 0.87 0.85 169
1 0.75 0.68 0.72 98
accuracy 0.80 267
macro avg 0.79 0.78 0.78 267
weighted avg 0.80 0.80 0.80 267إذا كنت مهتمًا برؤية مصفوفة الارتباك (confusion matrix) الخام وحساب مقاييس الأداء يدويًا، يمكنك القيام بذلك باستخدام الكود التالي:
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test_data, predictions))هذا يولد الناتج التالي:
[[145 22]
[ 30 70]]الكود الكامل للقسم الثاني (الانحدار اللوجستي)
يمكنك عرض الكود الكامل لهذا الدليل في مستودع GitHub هذا. كما هو ملصق أدناه للرجوع إليه:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
#Import the data set
titanic_data = pd.read_csv('titanic_train.csv')
#Exploratory data analysis
sns.heatmap(titanic_data.isnull(), cbar=False)
sns.countplot(x='Survived', data=titanic_data)
sns.countplot(x='Survived', hue='Sex', data=titanic_data)
sns.countplot(x='Survived', hue='Pclass', data=titanic_data)
plt.hist(titanic_data['Age'].dropna())
plt.hist(titanic_data['Fare'])
sns.boxplot(x='Pclass', y='Age', data=titanic_data)
#Imputation function
def impute_missing_age(columns):
age = columns[0]
passenger_class = columns[1]
if pd.isnull(age):
if (passenger_class == 1):
return titanic_data[titanic_data['Pclass'] == 1]['Age'].mean()
elif(passenger_class == 2):
return titanic_data[titanic_data['Pclass'] == 2]['Age'].mean()
elif(passenger_class == 3):
return titanic_data[titanic_data['Pclass'] == 3]['Age'].mean()
else:
return age
# Impute the missing Age data
titanic_data['Age'] = titanic_data[['Age', 'Pclass']].apply(impute_missing_age, axis = 1)
# Reinvestigate missing data
sns.heatmap(titanic_data.isnull(), cbar=False)
# Drop null data
titanic_data.drop('Cabin', axis=1, inplace = True)
titanic_data.dropna(inplace = True)
# Create dummy variables for Sex and Embarked columns
sex_data = pd.get_dummies(titanic_data['Sex'], drop_first = True)
embarked_data = pd.get_dummies(titanic_data['Embarked'], drop_first = True)
# Add dummy variables to the DataFrame and drop non-numeric data
titanic_data = pd.concat([titanic_data, sex_data, embarked_data], axis = 1)
titanic_data.drop(['Name', 'PassengerId', 'Ticket', 'Sex', 'Embarked'], axis = 1, inplace = True)
# Print the finalized data set
print(titanic_data.head())
# Split the data set into x and y data
y_data = titanic_data['Survived']
x_data = titanic_data.drop('Survived', axis = 1)
# Split the data set into training data and test data
from sklearn.model_selection import train_test_split
x_training_data, x_test_data, y_training_data, y_test_data = train_test_split(x_data, y_data, test_size = 0.3)
# Create the model
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
# Train the model and create predictions
model.fit(x_training_data, y_training_data)
predictions = model.predict(x_test_data)
# Calculate performance metrics
from sklearn.metrics import classification_report
print(classification_report(y_test_data, predictions))
# Generate a confusion matrix
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test_data, predictions))الخلاصة التقنية
في هذا الدليل الشامل، استكشفنا بعمق كيفية بناء وتدريب نماذج التعلم الآلي الأساسية: الانحدار الخطي والانحدار اللوجستي، باستخدام لغة بايثون ومكتبة scikit-learn. بدأنا بالانحدار الخطي، حيث تعلمنا كيفية التعامل مع البيانات الرقمية المستمرة للتنبؤ بالأسعار، مرورًا بخطوات استيراد البيانات، تحليلها استكشافيًا، تقسيمها، تدريب النموذج، وتقييم أدائه باستخدام مقاييس مثل MAE و MSE و RMSE. ثم انتقلنا إلى الانحدار اللوجستي، وهو نموذج حيوي لمشاكل التصنيف، حيث طبقناه على مجموعة بيانات تايتانيك للتنبؤ بالنجاة. غطينا تقنيات معالجة البيانات المفقودة باستخدام الاستيفاء (imputation) وإنشاء المتغيرات الوهمية (dummy variables) للبيانات الفئوية، وهي خطوات حاسمة في إعداد البيانات. اختتمنا بتدريب نموذج الانحدار اللوجستي وتقييم فعاليته باستخدام classification_report و confusion_matrix. هذا الدليل يمثل أساسًا متينًا لأي شخص يرغب في فهم وتطبيق هذه النماذج القوية في مشاريع التعلم الآلي الواقعية، مؤكدًا على أهمية كل خطوة من إعداد البيانات إلى التقييم النهائي للنموذج.