ما هي الشبكة العصبية الالتفافية؟ دليل مبسط للمبتدئين في تعلم الآلة والتعلم العميق
مقدمة: لماذا تُعد الشبكات العصبية الالتفافية مهمة؟
توجد أنواع عديدة من الشبكات العصبية المستخدمة في مشاريع Machine Learning، مثل الشبكات المتكررة RNN، والشبكات الأمامية Feedforward Neural Networks، والشبكات المعيارية Modular Neural Networks. ومن بين أكثر الأنواع شيوعاً وفعالية في معالجة الصور والبيانات المهيكلة على شكل شبكات تأتي الشبكات العصبية الالتفافية Convolutional Neural Networks أو اختصاراً CNN.
قبل فهم آلية عمل CNN، من المهم أولاً تكوين صورة واضحة عن معنى الشبكة العصبية التقليدية، لأن الشبكات الالتفافية ما هي إلا تطور متخصص ومصمم للتعامل بكفاءة أعلى مع أنواع محددة من البيانات، خصوصاً الصور.
ما هي الشبكة العصبية؟
عندما يتحدث المختصون عن مجال Deep Learning، فهم غالباً يشيرون إلى الشبكات العصبية. وقد استُلهم هذا المفهوم من طريقة عمل الدماغ البشري، حيث توجد وحدات مترابطة تشبه الخلايا العصبية، وتتعاون فيما بينها لمعالجة المعلومات واتخاذ القرارات.
تتكون الشبكة العصبية من طبقات متعددة:
- طبقة إدخال
Input Layerتستقبل البيانات الأولية. - طبقات مخفية
Hidden Layersتنفذ عمليات المعالجة والتحويل. - طبقة إخراج
Output Layerتنتج التنبؤ أو التصنيف النهائي.
كل عقدة Node داخل الشبكة تستقبل مدخلات مرتبطة بأوزان Weights. هذه الأوزان تحدد مدى تأثير كل قيمة على النتيجة النهائية. وخلال التدريب، يتم تعديل هذه الأوزان تدريجياً لتحسين دقة النموذج.
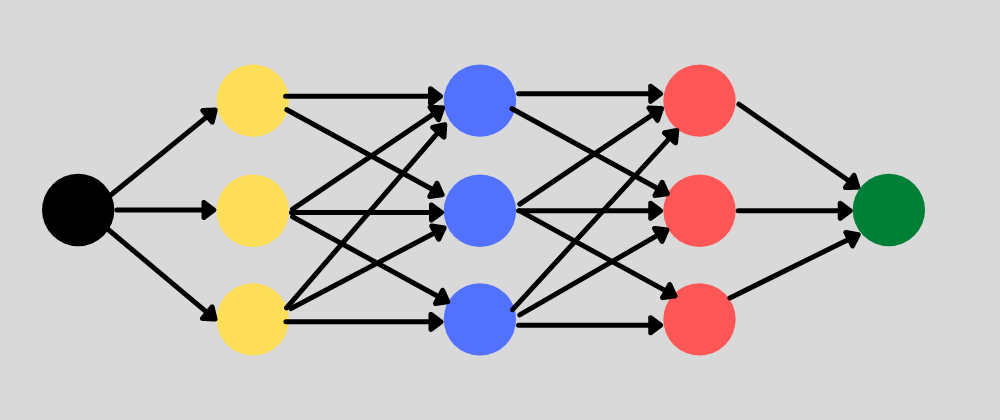
تمر بيانات التدريب من طبقة الإدخال إلى الطبقات المخفية، حيث تُعاد صياغتها رياضياً في كل مرحلة اعتماداً على الأوزان ودوال التنشيط. وفي النهاية، تصل القيم إلى طبقة الإخراج التي تقدم النتيجة المتوقعة.
لكن تدريب الشبكات العصبية التقليدية قد يكون عملية دقيقة وتحتاج إلى موازنة بين عدد السمات المستخدمة، وعمق النموذج، وحجم البيانات، لتجنب ضعف التعميم أو الوقوع في فرط التخصيص Overfitting.
ما الذي يميز الشبكة العصبية الالتفافية CNN؟
الشبكة العصبية الالتفافية هي نوع متخصص من الشبكات العصبية متعددة الطبقات، صُمم للتعامل مع البيانات التي تأتي في صورة بنية شبكية Grid-like Data، مثل الصور. وتمتاز هذه الشبكات بقدرتها على استخراج السمات المهمة تلقائياً، دون الحاجة إلى قدر كبير من المعالجة المسبقة.
في خوارزميات معالجة الصور التقليدية، كان المهندس يحدد المرشحات Filters يدوياً اعتماداً على الخبرة والتجربة. أما في CNN، فإن النموذج نفسه يتعلم أثناء التدريب ما هي السمات أو الأنماط الأكثر أهمية، مثل الحواف والزوايا والأشكال.
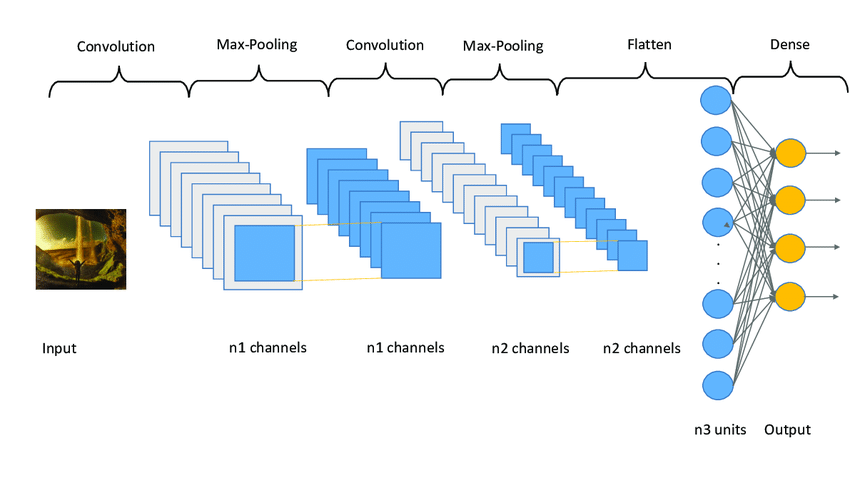
هذه الميزة توفر وقتاً كبيراً، وتقلل الحاجة إلى التجريب اليدوي، خصوصاً عند التعامل مع صور عالية الدقة تحتوي على آلاف أو ملايين البكسلات.
الهدف الأساسي من CNN هو تحويل البيانات إلى تمثيلات أسهل للمعالجة، مع الحفاظ على السمات الجوهرية التي تساعد في فهم محتوى البيانات. ولهذا السبب، تُعد هذه الشبكات مناسبة جداً للتعامل مع مجموعات البيانات الضخمة.
الفرق الرياضي الأساسي بين CNN والشبكات التقليدية
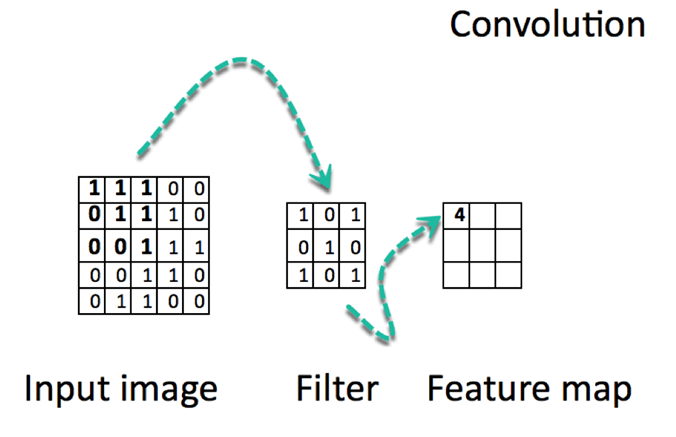
أحد أهم الفروق أن CNN تعتمد على عملية الالتفاف Convolution بدلاً من الاكتفاء بعمليات الضرب المصفوفي التقليدية في جميع الطبقات. والالتفاف هو عملية رياضية تجمع بين دالتين لإنتاج دالة جديدة تعبّر عن الخصائص المهمة في البيانات.
عملياً، تقوم الشبكة بتطبيق مرشحات Filters على بيانات الإدخال. والأهم من ذلك أن هذه المرشحات لا تبقى ثابتة، بل تتطور أثناء التدريب، مما يمنح النموذج قدرة عالية على تحسين نفسه تدريجياً واكتشاف الأنماط الأكثر فائدة.
هذا ما يجعل CNN قوية في تطبيقات معقدة مثل:
- التعرف على الوجوه.
- تصنيف الصور.
- تحليل المشاهد في المركبات ذاتية القيادة.
- التشخيص الطبي المعتمد على الصور.
ومع ذلك، فإن نجاح هذه الشبكات يعتمد بدرجة كبيرة على توفر بيانات كافية ونظيفة ومصنفة بشكل صحيح. فكلما زادت جودة البيانات وكميتها، تحسن أداء النموذج ودقته. ولهذا غالباً ما تكون مشاريع CNN مكلفة من حيث جمع البيانات وتجهيزها.
كيف تعمل الشبكات العصبية الالتفافية؟
تعتمد CNN على طبقات من العصبونات الاصطناعية Artificial Neurons أو العقد Nodes. كل عقدة تنفذ عملية حسابية تعتمد على مجموع المدخلات الموزونة، ثم تنتج خريطة تنشيط Activation Map توضّح السمات المكتشفة.
عند تمرير صورة إلى الشبكة، تبدأ الطبقات الأولى عادةً باكتشاف السمات البسيطة مثل:
- الحواف.
- الفواصل بين الألوان.
- الاتجاهات الأساسية.
بعد ذلك، تمر هذه التمثيلات إلى طبقات أعمق تبدأ في التقاط سمات أكثر تعقيداً، مثل:
- الزوايا.
- التجمعات اللونية.
- الأشكال الجزئية.
- مكونات العناصر الظاهرة في الصورة.
ومع استمرار الانتقال بين الطبقات، تصبح السمات أكثر تجريداً ودلالة، إلى أن تتمكن الشبكة من بناء فهم كافٍ للصورة وإصدار التنبؤ النهائي.
ما المقصود بـ Max Pooling؟
أثناء معالجة البيانات، تستخدم CNN غالباً عملية تُعرف باسم Max Pooling. وتتمثل وظيفتها في تقليل حجم البيانات المارة بين الطبقات، مع الاحتفاظ بأكثر السمات أهمية فقط.
فوائد Max Pooling تشمل:
- تقليل التعقيد الحسابي.
- تسريع التدريب.
- خفض استهلاك الذاكرة.
- الاحتفاظ بالسمات الأهم في خريطة التنشيط.
وفي الطبقة الأخيرة، تأتي طبقة التصنيف Classification Layer التي تحدد الفئة النهائية اعتماداً على خرائط التنشيط المستخرجة. فإذا مررت إلى الشبكة صورة لرقم مكتوب بخط اليد، فإن هذه الطبقة تُرجع الرقم الأقرب لما فهمته الشبكة من الصورة.
ولهذا تُستخدم CNN في أنظمة متقدمة مثل السيارات ذاتية القيادة، حيث تساعد على التمييز بين الإنسان والمركبة والعوائق الأخرى.
كيف يتم تدريب نموذج CNN؟
يُشبه تدريب CNN تدريب كثير من نماذج تعلم الآلة الأخرى. تبدأ العملية بتقسيم البيانات إلى:
- بيانات تدريب
Training Data. - بيانات اختبار
Test Data.
بعد ذلك، تُحدَّث الأوزان تدريجياً بناءً على مدى دقة التوقعات مقارنةً بالقيم الصحيحة. والهدف هو تقليل الخطأ وتحسين التعميم. لكن ينبغي الانتباه إلى مشكلة Overfitting، حيث يبالغ النموذج في حفظ بيانات التدريب على حساب قدرته على التعامل مع بيانات جديدة.
أنواع الشبكات العصبية الالتفافية
يمكن استخدام أكثر من نوع من CNN بحسب طبيعة المشكلة والبيانات:
1D CNN
في هذا النوع، تتحرك النواة Kernel في اتجاه واحد فقط. ويُستخدم غالباً مع البيانات الزمنية Time-Series Data أو الإشارات المتسلسلة.
2D CNN
هذا هو النوع الأكثر شيوعاً، حيث تتحرك النواة في اتجاهين. ويُستخدم بكثرة في تصنيف الصور، وتحليل المشاهد، ومعالجة الصور الرقمية.
3D CNN
في هذا النوع، تتحرك النواة في ثلاثة اتجاهات، مما يجعله مناسباً للصور ثلاثية الأبعاد مثل صور الأشعة المقطعية CT Scans وصور الرنين المغناطيسي MRI.
وعملياً، يبقى 2D CNN الأكثر انتشاراً لأنه يرتبط مباشرةً بمعظم تطبيقات الصور الشائعة.
أهم استخدامات الشبكات العصبية الالتفافية
تدخل CNN في عدد كبير من التطبيقات الحديثة، ومن أبرزها:
- التعرف على الصور مع حاجة أقل إلى المعالجة المسبقة.
- تمييز الكتابة اليدوية بدقة عالية.
- تطبيقات الرؤية الحاسوبية
Computer Vision. - قراءة الأرقام في الشيكات داخل الأنظمة البنكية.
- قراءة الرموز البريدية على المظاريف في الخدمات البريدية.
- التعرف على العناصر في أنظمة القيادة الذاتية.
- تحليل الصور الطبية والمساعدة في التشخيص.
مثال عملي على CNN باستخدام لغة Python
لفهم الفكرة بشكل أوضح، يمكن تطبيق شبكة عصبية التفافية على مجموعة بيانات MNIST الشهيرة، وهي مجموعة تحتوي على صور لأرقام مكتوبة بخط اليد. سنقوم بتعريف النموذج، ثم تقسيم البيانات إلى تدريب واختبار، ثم تدريب النموذج وقياس دقته.
from keras import layers
from keras import models
from keras.datasets import mnist
from keras.utils import to_categorical
# Define the CNN model
model = models.Sequential()
model.add(layers.Conv2D(32, (5, 5), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (5, 5), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(10, activation='softmax'))
model.summary()
# Split the data into training and test sets
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# Use the training data to train the model
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
model.fit(train_images, train_labels, batch_size=100, epochs=5, verbose=1)
# Test the model's accuracy with the test data
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)شرح سريع لما يحدث في هذا المثال
- يتم إنشاء نموذج تسلسلي باستخدام
Sequential. - تُضاف طبقات
Conv2Dلاستخراج السمات من الصور. - تُستخدم طبقات
MaxPooling2Dلتقليل الأبعاد والتركيز على السمات المهمة. - تُسطَّح المخرجات عبر
Flatten()تمهيداً لتمريرها إلى طبقة التصنيف. - تقوم طبقة
Denseالنهائية بإخراج احتمالات الأرقام من0إلى9باستخدامsoftmax. - بعد ذلك، يتم تدريب النموذج ثم تقييمه على بيانات الاختبار.
لماذا تحقق CNN نتائج قوية في معالجة الصور؟
تكمن قوة CNN في أنها لا تتعامل مع الصورة كمجموعة أرقام عشوائية، بل تحاول فهم البنية المكانية بين البكسلات. فهي تتعلم أنماطاً محلية صغيرة أولاً، ثم تبني منها فهماً أكبر وأكثر تعقيداً مع تقدم الطبقات.
ومن أهم مزاياها:
- تقليل الحاجة إلى هندسة السمات اليدوية.
- القدرة على اكتشاف الأنماط المعقدة تلقائياً.
- فعالية عالية في التعامل مع الصور والبيانات البصرية.
- مرونة في التوسع لتطبيقات متقدمة جداً.
كما أن عدد الطبقات المخفية المطلوب لا يكون دائماً كبيراً مثل بعض الأنواع الأخرى من الشبكات، لأن عمليات الالتفاف نفسها تنفذ جزءاً مهماً من مهمة اكتشاف السمات.
الخلاصة التقنية
الشبكات العصبية الالتفافية CNN تمثل حجر أساس في تطبيقات الرؤية الحاسوبية الحديثة. قوتها الحقيقية لا تكمن فقط في دقتها، بل في قدرتها على تعلم السمات تلقائياً من البيانات الخام، خصوصاً الصور. وإذا توفرت بيانات نظيفة ومصنفة جيداً، فإن هذه الشبكات قادرة على تقديم نتائج ممتازة في مهام تبدأ من التعرف على الأرقام المكتوبة بخط اليد وتصل إلى الأنظمة الطبية والقيادة الذاتية. ومن الناحية التقنية، تعد CNN خياراً عملياً وفعالاً لكل مشروع يعتمد على فهم الأنماط البصرية واستخراج المعنى منها بأقل تدخل يدوي ممكن.