كيفية إنشاء واجهة برمجة تطبيقات (API) مخصصة من أي موقع ويب باستخدام Puppeteer

مقدمة: تحويل الويب إلى واجهة برمجة تطبيقات (API)
كثيراً ما نصادف مواقع ويب تتطلب منا تنفيذ سلسلة من الإجراءات المعقدة للحصول على البيانات المطلوبة. في هذه اللحظات، يبرز تساؤل مهم: كيف يمكننا توفير هذه البيانات بصيغة يسهل على تطبيقاتنا استهلاكها ومعالجتها؟ هنا يأتي دور تقنيات استخلاص البيانات (Web Scraping) لتقديم الحل. ويُعد اختيار الأداة المناسبة لهذه المهمة أمراً بالغ الأهمية لضمان الكفاءة والدقة.

واجهة برمجة التطبيقات (API) هي ببساطة طريقة للنظر إلى موقع الويب (المصدر: XKCD Comics)
Puppeteer: أكثر من مجرد مكتبة لاستخلاص البيانات
Puppeteer هي مكتبة Node.js يتم تطويرها وصيانتها بواسطة فريق أدوات مطوري Chrome Devtools في Google. تعمل هذه المكتبة على تشغيل نسخة من متصفح Chromium أو Chrome (الاسم الأكثر شيوعاً) في وضع headless (أي بدون واجهة رسومية مرئية) أو بوضع قابل للتكوين، وتُقدم مجموعة شاملة من واجهات برمجة التطبيقات عالية المستوى.
وفقاً لوثائقها الرسمية، تُستخدم Puppeteer عادةً في العديد من العمليات التي لا تقتصر على ما يلي:
- توليد لقطات شاشة (Screenshots) وملفات PDF.
- الزحف إلى تطبيقات الصفحة الواحدة (
SPA– Single Page Applications) وتوليد محتوى مُسبق العرض (pre-rendered content)، وهو ما يُعرف بـServer Side Rendering. - اختبار إضافات
Chrome. - اختبار الأتمتة لواجهات الويب (
Web Interfaces). - تشخيص مشكلات الأداء من خلال تقنيات مثل التقاط تتبع المخطط الزمني (
timeline trace) لموقع ويب.
في سياق مهمتنا، نحتاج إلى القدرة على الوصول إلى موقع ويب وتعيين بياناته في شكل يمكن لتطبيقنا استهلاكه بسهولة. هل يبدو الأمر بسيطاً؟ التنفيذ ليس معقداً أيضاً. دعونا نبدأ.
بناء الشيفرة خطوة بخطوة: استخلاص البيانات من Amazon
بسبب اهتمامي بمنتجات Amazon، سأستخدم إحدى صفحات قائمة منتجاتهم كمثال. سننفذ حالة الاستخدام هذه على خطوتين رئيسيتين:
- استخلاص البيانات من الصفحة وتعيينها في صيغة
JSONسهلة الاستهلاك. - إضافة لمسة من الأتمتة لتسهيل سير العمل.
يمكنك العثور على الشيفرة الكاملة في هذا المستودع. سنقوم باستخلاص البيانات من الرابط التالي: https://www.amazon.in/s?k=Shirts&ref=nb_sb_noss_2 (قائمة بأكثر القمصان بحثاً كما هو موضح في الصورة) وتحويلها إلى صيغة جاهزة للاستخدام كواجهة API.
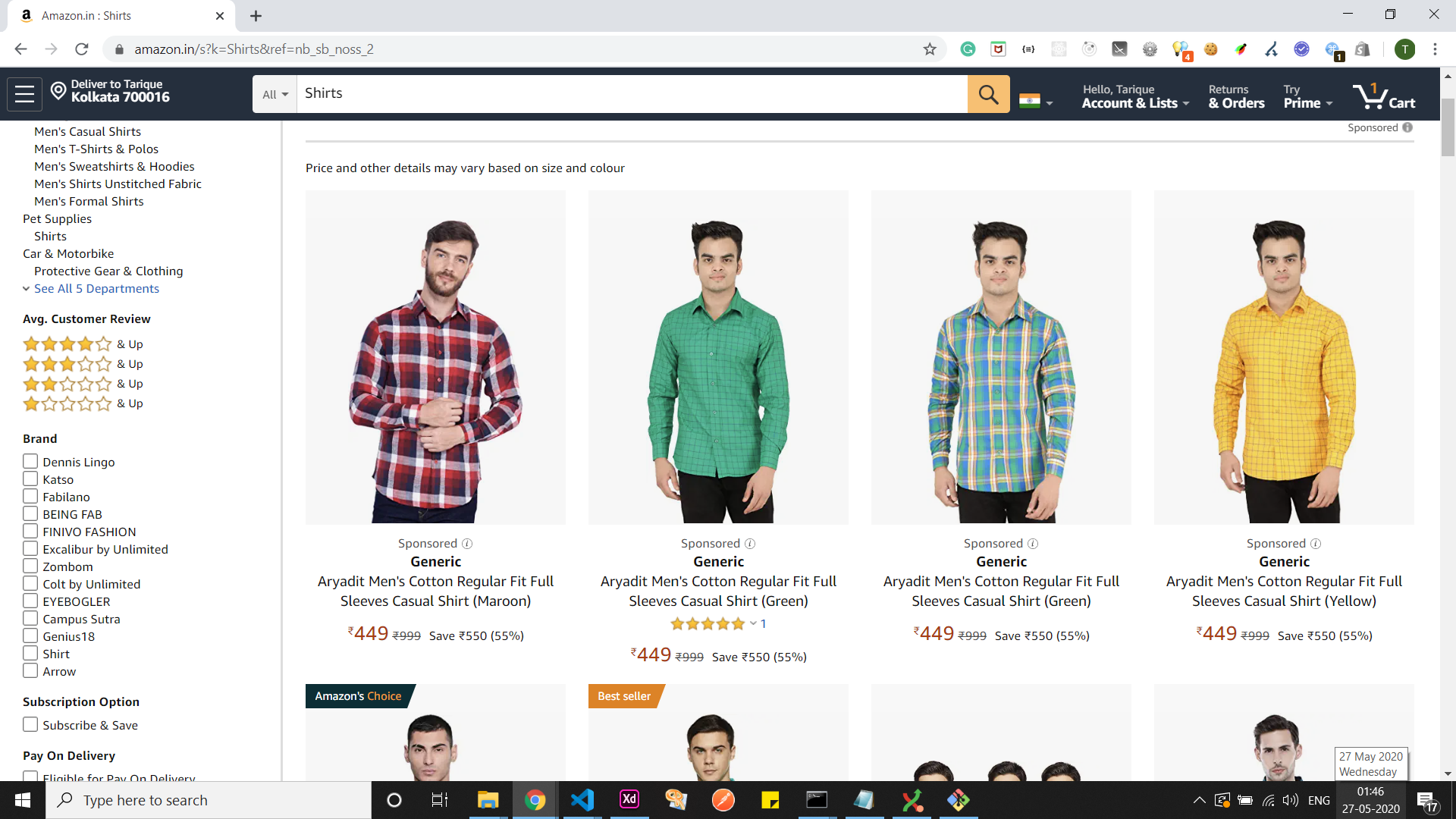
Amazon India – صفحة قائمة القمصان
فهم الفئات الأساسية في Puppeteer: Browser و Page
قبل الشروع في استخدام Puppeteer بشكل مكثف، يجب أن نفهم الفئتين الرئيسيتين اللتين توفرهما:
Browser: تُطلق هذه الفئة نسخة من متصفحChromeعند استخدامنا لـpuppeteer.launchأوpuppeteer.connect. تعمل هذه الفئة كمحاكاة بسيطة للمتصفح.Page: تُشبه هذه الفئة علامة تبويب واحدة في متصفحChrome. توفر مجموعة شاملة من الطرق (methods) التي يمكنك استخدامها مع نسخة صفحة معينة، ويتم استدعاؤها عند استدعاءbrowser.newPage. تماماً كما يمكنك إنشاء علامات تبويب متعددة في المتصفح، يمكنك بالمثل إنشاء نسخ متعددة منPageفي وقت واحد باستخدامPuppeteer.
إعداد Puppeteer والتنقل إلى عنوان URL المستهدف
نبدأ بإعداد Puppeteer باستخدام وحدة npm المتاحة. بعد تثبيت Puppeteer، نقوم بإنشاء نسخة من فئة Browser وفئة Page، ثم ننتقل إلى عنوان URL المستهدف.
const puppeteer = require('puppeteer');
const url = 'https://www.amazon.in/s?k=Shirts&ref=nb_sb_noss_2';
async function fetchProductList(url) {
const browser = await puppeteer.launch({
headless: true, // false: enables one to view the Chrome instance in action
defaultViewport: null, // (optional) useful only in non-headless mode
});
const page = await browser.newPage();
await page.goto(url, { waitUntil: 'networkidle2' });
// ... سيأتي باقي الكود هنا
}
fetchProductList(url);
نستخدم networkidle2 كقيمة لخيار waitUntil أثناء التنقل إلى عنوان URL. يضمن هذا أن حالة تحميل الصفحة تعتبر نهائية عندما لا يكون لديها أكثر من اتصالين قيد التشغيل لمدة 500 مللي ثانية على الأقل.
ملاحظة: لا تحتاج إلى تثبيت Chrome أو نسخة منه على نظامك لكي يعمل Puppeteer. فهو يأتي بالفعل مع نسخة خفيفة منه مدمجة مع المكتبة.
طرق الصفحة (Page Methods) لاستخلاص وتعيين البيانات
لقد تم تحميل DOM بالفعل في نسخة الصفحة التي أنشأناها. سنمضي قدماً ونستفيد من طريقة page.evaluate() للاستعلام عن DOM. قبل أن نبدأ، نحتاج إلى تحديد نقاط البيانات الدقيقة التي نحتاج إلى استخلاصها. في المثال الحالي، سيبدو كل كائن منتج شيئاً من هذا القبيل:
{
brand: 'Brand Name',
product: 'Product Name',
url: 'https://www.amazon.in/url.of.product.com/',
image: 'https://www.amazon.in/image.jpg',
price: '₹599',
}
لقد وضعنا الهيكل الذي نرغب في تحقيقه. حان الوقت لبدء فحص DOM لتحديد المعرفات (identifiers). سنبحث عن المحددات (selectors) التي تظهر في جميع العناصر المراد تعيينها. سنستخدم في الغالب document.querySelector و document.querySelectorAll لتصفح DOM.
// ... استكمال الكود من الدالة fetchProductList
async function fetchProductList(url) {
// ... كود إطلاق المتصفح والصفحة والانتقال إلى URL
await page.waitFor('div[data-cel-widget^="search_result_"]');
const result = await page.evaluate(() => {
// يحسب العدد الإجمالي للمنتجات
let totalSearchResults = Array.from(document.querySelectorAll('div[data-cel-widget^="search_result_"]')).length;
let productsList = [];
for (let i = 1; i < totalSearchResults - 1; i++) {
let product = {
brand: '',
product: '',
};
let onlyProduct = false;
let emptyProductMeta = false;
// تصفح لأسماء العلامة التجارية والمنتج
let productNodes = Array.from(document.querySelectorAll(`div[data-cel-widget="search_result_${i}"] .a-size-base-plus.a-color-base`));
if (productNodes.length === 0) {
// تصفح لأسماء العلامة التجارية والمنتج
// (في حال كانت عملية التصفح السابقة أعادت عناصر فارغة)
productNodes = Array.from(document.querySelectorAll(`div[data-cel-widget="search_result_${i}"] .a-size-medium.a-color-base.a-text-normal`));
productNodes.length > 0 ? onlyProduct = true : emptyProductMeta = true;
}
let productsDetails = productNodes.map(el => el.innerText);
if (!emptyProductMeta) {
product.brand = onlyProduct ? '' : productsDetails[0];
product.product = onlyProduct ? productsDetails[0] : productsDetails[1];
}
// تصفح لصورة المنتج
let rawImage = document.querySelector(`div[data-cel-widget="search_result_${i}"] .s-image`);
product.image = rawImage ? rawImage.src : '';
// تصفح لرابط المنتج
let rawUrl = document.querySelector(`div[data-cel-widget="search_result_${i}"] a[target="_blank"].a-link-normal`);
product.url = rawUrl ? rawUrl.href : '';
// تصفح لسعر المنتج
let rawPrice = document.querySelector(`div[data-cel-widget="search_result_${i}"] span.a-offscreen`);
product.price = rawPrice ? rawPrice.innerText : '';
if (typeof product.product !== 'undefined') {
!product.product.trim() ? null : productsList = productsList.concat(product);
}
}
return productsList;
});
// ... باقي الكود
}
// ... استكمال الكود
بعد فحص DOM، نلاحظ أن كل عنصر مُدرج محاط بعنصر يحمل المحدد div[data-cel-widget^="search_result_"]. يبحث هذا المحدد تحديداً عن جميع وسوم div التي تحتوي على السمة data-cel-widget بقيمة تبدأ بـ search_result_. وبالمثل، نقوم بتعيين المحددات للمعايير التي نحتاجها كما هو موضح أدناه:
- إجمالي العناصر المدرجة:
div[data-cel-widget^="search_result_"] - العلامة التجارية (
brand):div[data-cel-widget="search_result_${i}"] .a-size-base-plus.a-color-base(حيثiيمثل رقم العقدة في إجمالي العناصر المدرجة) - المنتج (
product):div[data-cel-widget="search_result_${i}"] .a-size-base-plus.a-color-baseأوdiv[data-cel-widget="search_result_${i}"] .a-size-medium.a-color-base.a-text-normal(حيثiيمثل رقم العقدة في إجمالي العناصر المدرجة) - الرابط (
url):div[data-cel-widget="search_result_${i}"] a[target="_blank"].a-link-normal(حيثiيمثل رقم العقدة في إجمالي العناصر المدرجة) - الصورة (
image):div[data-cel-widget="search_result_${i}"] .s-image(حيثiيمثل رقم العقدة في إجمالي العناصر المدرجة) - السعر (
price):div[data-cel-widget="search_result_${i}"] span.a-offscreen(حيثiيمثل رقم العقدة في إجمالي العناصر المدرجة)
ملاحظة: ننتظر حتى تصبح العناصر المسماة بالمحدد div[data-cel-widget^="search_result_"] متاحة على الصفحة باستخدام طريقة page.waitFor. بمجرد استدعاء طريقة page.evaluate، يمكننا رؤية البيانات التي نحتاجها مسجلة.

لقد نجح الأمر! بيانات واجهة برمجة التطبيقات (API) جاهزة لخدمة ما نحتاجه.
إضافة الأتمتة لتسهيل سير العمل
حتى الآن، تمكنا من التنقل إلى صفحة، واستخلاص البيانات التي نحتاجها، وتحويلها إلى صيغة جاهزة لواجهة برمجة التطبيقات. يبدو هذا رائعاً. ومع ذلك، لنفكر للحظة في حالة حيث يتعين عليك التنقل من عنوان URL إلى آخر عن طريق تنفيذ بعض الإجراءات – ثم محاولة استخلاص البيانات التي تحتاجها. هل سيجعل ذلك حياتك أكثر تعقيداً؟ ليس على الإطلاق. يمكن لـ Puppeteer تقليد سلوك المستخدم بسهولة. حان الوقت لإضافة بعض الأتمتة إلى حالة الاستخدام الحالية لدينا.
على عكس المثال السابق، سنذهب إلى الصفحة الرئيسية لـ amazon.in ونبحث عن ‘Shirts’. سينقلنا هذا إلى صفحة قائمة المنتجات ويمكننا استخلاص البيانات المطلوبة من DOM. الأمر في غاية السهولة. دعونا نلقي نظرة على الكود.
// ... استكمال الكود
async function fetchProductList(url, searchTerm) {
// ... كود إطلاق المتصفح والصفحة
await page.goto(url, { waitUntil: 'networkidle2' });
await page.waitFor('input[name="field-keywords"]');
await page.evaluate(val => document.querySelector('input[name="field-keywords"]').value = val, searchTerm);
await page.click('div.nav-search-submit.nav-sprite');
// منطق تصفح DOM وتعيين البيانات
// يعيد مصفوفة productsList
// ...
}
fetchProductList('https://amazon.in', 'Shirts');
نلاحظ أننا ننتظر حتى يصبح مربع البحث متاحاً، ثم نضيف searchTerm المُمرر باستخدام page.evaluate. بعد ذلك، ننتقل إلى صفحة قائمة المنتجات عن طريق محاكاة إجراء النقر على ‘زر البحث’ وعرض DOM. تختلف تعقيدات الأتمتة من حالة استخدام إلى أخرى.
ملاحظات هامة و”فخاخ” محتملة عند استخدام Puppeteer
تُعد واجهة برمجة تطبيقات Puppeteer شاملة للغاية، ولكن هناك بعض النقاط الهامة التي واجهتها أثناء العمل بها. تذكر أن ليست كل هذه النقاط مرتبطة مباشرة بـ Puppeteer ولكنها تميل إلى العمل بشكل أفضل معها.
- حظر الروبوتات: تُنشئ
Puppeteerنسخة متصفحChromeكما ذكرنا. ومع ذلك، من المحتمل أن تحظر بعض مواقع الويب الوصول إذا اشتبهت في نشاط روبوت. توجد حزمة تسمىuser-agentsيمكن استخدامها معPuppeteerلتعيين وكيل مستخدم عشوائي (user-agent) للمتصفح.
const puppeteer = require('puppeteer');
const userAgent = require('user-agents');
// ...
const browser = await puppeteer.launch({
headless: true,
defaultViewport: null
});
const page = await browser.newPage();
await page.setUserAgent(userAgent.toString());
// ...
- الجوانب القانونية لاستخلاص البيانات: يقع استخلاص البيانات من موقع ويب في المناطق الرمادية من القبول القانوني. أوصي باستخدامه بحذر والتحقق من القواعد المعمول بها في مكان إقامتك.
defaultViewport: null: صادفناdefaultViewport: nullعند إطلاق نسخةChromeوقد أدرجته كخيار اختياري. هذا لأنه مفيد فقط عندما تشاهد نسخةChromeالتي يتم إطلاقها. يمنع هذا الخيار تأثر عرض وارتفاع موقع الويب عند عرضه.- الأداء:
Puppeteerليس الحل الأمثل عندما يتعلق الأمر بالأداء. سيتعين عليك، كمطور، تحسينه لزيادة كفاءة أدائه من خلال إجراءات مثل تقييد الرسوم المتحركة على الموقع (throttling animations)، والسماح فقط باستدعاءات الشبكة الأساسية (essential network calls)، وما إلى ذلك. - إغلاق الجلسة: تذكر دائماً إنهاء جلسة
Puppeteerبإغلاق نسخةBrowserباستخدامbrowser.close(). (لقد فاتني ذلك في المحاولة الأولى). يساعد هذا في إنهاء جلسة المتصفح الجارية. - سياق
console.log(): لن تعمل بعض عملياتJavaScriptالشائعة مثلconsole.log()ضمن نطاق طرق الصفحة (page methods). السبب هو أن سياق الصفحة (page context) أو سياق المتصفح (browser context) يختلف عن سياقNodeالذي يعمل فيه تطبيقك.
هذه بعض الملاحظات التي لاحظتها. إذا كان لديك المزيد، فلا تتردد في التواصل معي. سأكون سعيداً بالتعلم أكثر.
من موقع ويب إلى واجهة برمجة تطبيقات (API) خاصة بك: تجميع كل شيء
يتم تشغيل التطبيق في وضع غير headless حتى تتمكن من مشاهدة ما يحدث بالضبط. سنقوم بأتمتة التنقل إلى صفحة قائمة المنتجات التي نحصل منها على البيانات.
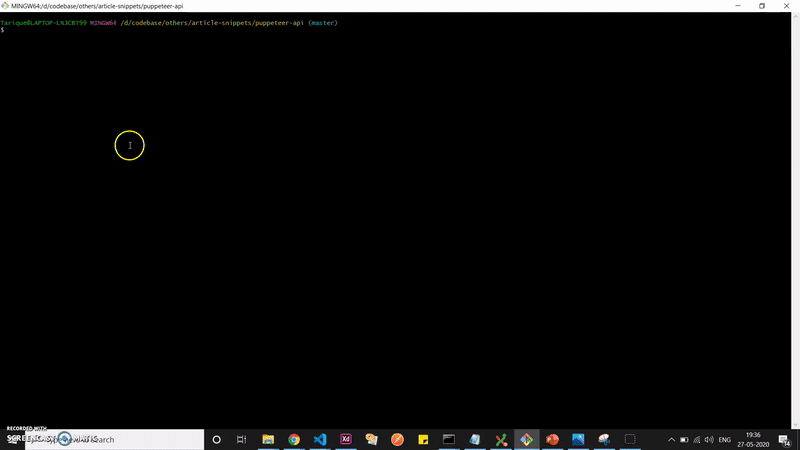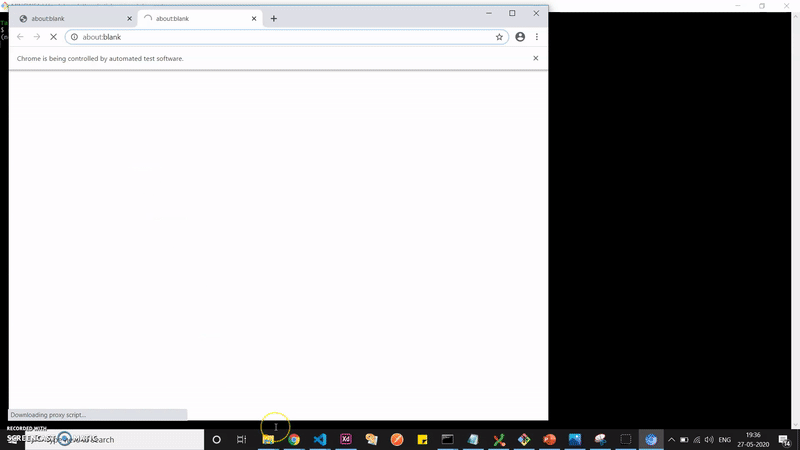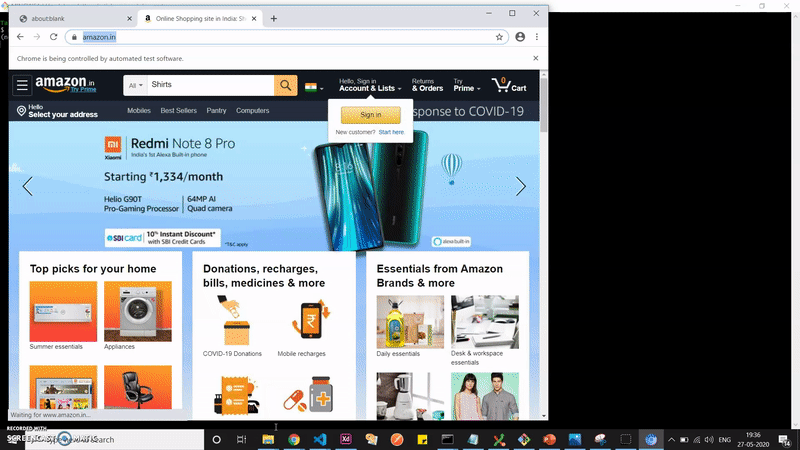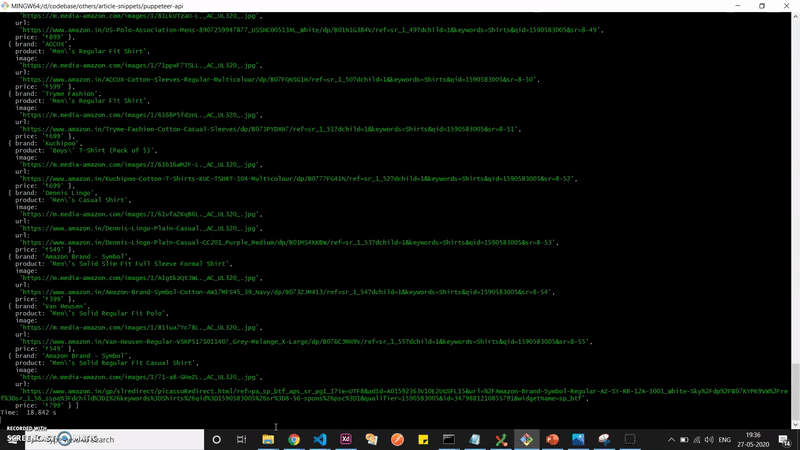
ها أنت ذا. لديك الآن بيانات واجهة برمجة تطبيقات قابلة للاستهلاك خاصة بك من موقع الويب الذي تختاره. كل ما عليك فعله الآن هو ربط هذا بإطار عمل من جانب الخادم (server side framework) مثل express وستكون جاهزاً للانطلاق.
الخلاصة التقنية
تُعد مكتبة Puppeteer أداة قوية ومتعددة الاستخدامات تتجاوز مجرد استخلاص البيانات. قدرتها على التحكم في متصفح Chromium أو Chrome بشكل آلي تفتح آفاقاً واسعة للمطورين لإنشاء حلول مخصصة لأتمتة المهام المعقدة على الويب. من خلال هذه المقالة، رأينا كيف يمكن تحويل أي موقع ويب إلى مصدر بيانات قابل للاستهلاك عبر واجهة برمجة تطبيقات مخصصة، مما يقلل من الجهد اليدوي ويزيد من كفاءة استرجاع المعلومات. ومع ذلك، من الضروري مراعاة الجوانب الأخلاقية والقانونية لاستخلاص البيانات، بالإضافة إلى تحسين الأداء وإدارة موارد المتصفح بفعالية لضمان استمرارية وكفاءة الحلول المبنية على Puppeteer.
الخاتمة
هناك الكثير مما يمكنك فعله باستخدام Puppeteer. هذا مجرد حالة استخدام واحدة. أوصي بأن تقضي بعض الوقت في قراءة الوثائق الرسمية. سأفعل الشيء نفسه. تُستخدم Puppeteer على نطاق واسع في بعض أكبر المنظمات لمهام الأتمتة مثل الاختبار والعرض من جانب الخادم، من بين أمور أخرى. لا يوجد وقت أفضل للبدء مع Puppeteer من الآن.
إذا كانت لديك أي أسئلة أو تعليقات، يمكنك التواصل معي عبر LinkedIn أو Twitter. في هذه الأثناء، استمر في البرمجة.
إذا قرأت هذا القدر، اشكر المؤلف لتظهر له اهتمامك. قل شكراً
تعلم البرمجة مجاناً. ساعد منهج freeCodeCamp مفتوح المصدر أكثر من 40,000 شخص في الحصول على وظائف كمطورين. ابدأ الآن
إعلان