إنشاء وإدارة قواعد بيانات SQL باستخدام بايثون: دليل شامل للمحللين والمهندسين

مقدمة: قوة الدمج بين بايثون و SQL
يُعد كل من بايثون (Python) ولغة الاستعلام الهيكلية (SQL) من أهم اللغات التي لا غنى عنها لمحللي البيانات وعلماء البيانات. في هذا المقال الشامل، سنأخذك في رحلة تفصيلية لتتعلم كل ما تحتاج معرفته لربط بايثون بقواعد بيانات SQL. ستكتشف كيف يمكنك سحب البيانات من قواعد البيانات العلائقية مباشرة إلى مسارات تعلم الآلة (machine learning pipelines) الخاصة بك، أو تخزين البيانات من تطبيقات بايثون في قاعدة بيانات خاصة بك، أو أي حالة استخدام أخرى قد تخطر ببالك.
معًا، سنتناول المحاور التالية:
- لماذا يجب أن تتعلم استخدام بايثون و
SQLمعًا؟ - كيفية إعداد بيئة بايثون وخادم
MySQL. - الاتصال بخادم
MySQLمن بايثون. - إنشاء قاعدة بيانات جديدة.
- إنشاء الجداول والعلاقات بينها.
- تعبئة الجداول بالبيانات.
- قراءة واسترجاع البيانات.
- تحديث السجلات الموجودة.
- حذف السجلات.
- إنشاء سجلات من قوائم بايثون.
- إنشاء دوال قابلة لإعادة الاستخدام لتسهيل هذه العمليات مستقبلًا.
هذا قدر كبير من المعلومات المفيدة والمثيرة للاهتمام. لنبدأ!
ملاحظة سريعة قبل البدء: يتوفر دفتر Jupyter Notebook الذي يحتوي على جميع الأكواد المستخدمة في هذا الدليل في مستودع GitHub هذا. نوصي بشدة بتطبيق الأكواد خطوة بخطوة.
لماذا بايثون مع SQL؟
لمحللي البيانات وعلماء البيانات، توفر بايثون العديد من المزايا الفريدة. مجموعة واسعة من المكتبات مفتوحة المصدر تجعلها أداة مفيدة بشكل لا يصدق لأي محلل بيانات. لدينا مكتبات مثل pandas و NumPy و Vaex لتحليل البيانات، و Matplotlib و seaborn و Bokeh للتصور البياني، و TensorFlow و scikit-learn و PyTorch لتطبيقات تعلم الآلة (بالإضافة إلى العديد والعديد غيرها). بفضل منحنى التعلم السهل نسبيًا وتعدد استخداماتها، فلا عجب أن بايثون هي واحدة من أسرع لغات البرمجة نموًا في العالم.
لذا، إذا كنا نستخدم بايثون لتحليل البيانات، فمن الجدير بالذكر أن نتساءل: من أين تأتي كل هذه البيانات؟ بينما توجد مجموعة هائلة من مصادر مجموعات البيانات، ففي كثير من الحالات – خاصة في الشركات الكبيرة – سيتم تخزين البيانات في قاعدة بيانات علائقية (relational database). قواعد البيانات العلائقية هي طريقة فعالة للغاية وقوية وشائعة الاستخدام لإنشاء وقراءة وتحديث وحذف جميع أنواع البيانات.
تستخدم أنظمة إدارة قواعد البيانات العلائقية (RDBMSs) الأكثر استخدامًا – مثل Oracle و MySQL و Microsoft SQL Server و PostgreSQL و IBM DB2 – جميعها لغة الاستعلام الهيكلية (SQL) للوصول إلى البيانات وإجراء التغييرات عليها. تجدر الإشارة إلى أن كل نظام RDBMS يستخدم نكهة مختلفة قليلاً من SQL، لذا فإن كود SQL المكتوب لأحدها عادةً لن يعمل في الآخر دون تعديلات (عادةً ما تكون طفيفة جدًا). لكن المفاهيم والهياكل والعمليات متطابقة إلى حد كبير. هذا يعني بالنسبة لمحلل البيانات العامل، أن الفهم القوي للغة SQL أمر بالغ الأهمية. إن معرفة كيفية استخدام بايثون و SQL معًا سيمنحك ميزة أكبر عندما يتعلق الأمر بالعمل مع بياناتك. سيخصص بقية هذا المقال لإظهار كيفية تحقيق ذلك بالضبط.
البدء: المتطلبات والتثبيت
للتطبيق العملي مع هذا الدليل، ستحتاج إلى إعداد بيئة بايثون الخاصة بك. نوصي باستخدام Anaconda، ولكن هناك العديد من الطرق للقيام بذلك. يمكنك ببساطة البحث عن "كيفية تثبيت بايثون" إذا كنت بحاجة إلى مزيد من المساعدة. يمكنك أيضًا استخدام Binder للتطبيق العملي مع دفتر Jupyter Notebook المرتبط.
سنستخدم MySQL Community Server لأنه مجاني وشائع الاستخدام في الصناعة. إذا كنت تستخدم نظام التشغيل Windows، فسيساعدك هذا الدليل في الإعداد. إليك أدلة لمستخدمي Mac و Linux أيضًا (على الرغم من أنها قد تختلف باختلاف توزيعة Linux).
بمجرد إعداد هذه المكونات، سنحتاج إلى جعلها تتواصل مع بعضها البعض. لذلك، نحتاج إلى تثبيت مكتبة MySQL Connector Python. للقيام بذلك، اتبع التعليمات، أو ببساطة استخدم pip:
pip install mysql-connector-python
سنستخدم أيضًا مكتبة pandas، لذا تأكد من تثبيتها أيضًا:
pip install pandas
استيراد المكتبات الأساسية
كما هو الحال مع كل مشروع في بايثون، فإن أول ما نرغب في فعله هو استيراد مكتباتنا. من أفضل الممارسات استيراد جميع المكتبات التي سنستخدمها في بداية المشروع، حتى يعرف الأشخاص الذين يقرأون أو يراجعون الكود الخاص بنا تقريبًا ما سيأتي، ولا توجد مفاجآت. لهذا الدليل، سنستخدم مكتبتين فقط: MySQL Connector و pandas.
import mysql.connector
from mysql.connector import Error
import pandas as pd
نقوم باستيراد دالة Error بشكل منفصل حتى نتمكن من الوصول إليها بسهولة لاستخدامها في دوالنا.
الاتصال بخادم MySQL
في هذه المرحلة، يجب أن يكون لدينا خادم MySQL Community Server مُعدًا على نظامنا. الآن نحتاج إلى كتابة بعض الأكواد في بايثون تسمح لنا بإنشاء اتصال بهذا الخادم.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connection
إنشاء دالة قابلة لإعادة الاستخدام لهذا النوع من الأكواد هو أفضل الممارسات، حتى نتمكن من استخدامها مرارًا وتكرارًا بأقل جهد. بمجرد كتابتها مرة واحدة، يمكنك إعادة استخدامها في جميع مشاريعك المستقبلية أيضًا، لذا فإن "أنت المستقبل" ستكون ممتنًا!
دعنا نراجع هذا الكود سطرًا بسطر لفهم ما يحدث هنا:
- السطر الأول هو تسمية الدالة (
create_server_connection) وتسمية الوسائط التي ستتلقاها الدالة (host_name،user_name، وuser_password). - السطر التالي (ضمن كتلة
try) يحاول إنشاء اتصال بالخادم باستخدام الدالةmysql.connector.connect()مع التفاصيل المحددة من قبل المستخدم في الوسائط. - إذا نجح هذا، تطبع الدالة رسالة نجاح صغيرة.
- الجزء
exceptمن الكتلة يطبع الخطأ الذي يعيده خادمMySQL، في الظرف المؤسف لوجود خطأ. - أخيرًا، إذا كان الاتصال ناجحًا، تعيد الدالة كائن اتصال (
connection object).
نستخدم هذا عمليًا عن طريق تعيين مخرجات الدالة لمتغير، والذي يصبح بعد ذلك كائن الاتصال الخاص بنا. يمكننا بعد ذلك تطبيق طرق أخرى (مثل cursor) عليه وإنشاء كائنات مفيدة أخرى.
connection = create_server_connection("localhost", "root", pw)
يجب أن ينتج عن هذا رسالة نجاح:

رائع!
إنشاء قاعدة بيانات جديدة
الآن بعد أن أنشأنا اتصالًا، خطوتنا التالية هي إنشاء قاعدة بيانات جديدة على خادمنا. في هذا الدليل، سنقوم بذلك مرة واحدة فقط، ولكن مرة أخرى، سنكتب هذا كدالة قابلة لإعادة الاستخدام بحيث يكون لدينا دالة مفيدة يمكننا إعادة استخدامها لمشاريع مستقبلية.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")
تأخذ هذه الدالة وسيطتين: connection (كائن الاتصال الخاص بنا) و query (استعلام SQL سنكتبه في الخطوة التالية). تقوم بتنفيذ الاستعلام في الخادم عبر الاتصال. نستخدم طريقة cursor على كائن الاتصال الخاص بنا لإنشاء كائن مؤشر (cursor object). يستخدم MySQL Connector نموذج برمجة كائنية التوجه (object-oriented programming paradigm)، لذا هناك الكثير من الكائنات التي ترث خصائص من كائنات أصلية. يحتوي كائن المؤشر هذا على طرق مثل execute و executemany (التي سنستخدمها في هذا الدليل) بالإضافة إلى العديد من الطرق المفيدة الأخرى. إذا كان ذلك يساعد، يمكننا التفكير في كائن المؤشر على أنه يوفر لنا الوصول إلى المؤشر الوامض في نافذة طرفية لخادم MySQL.

هذا هو المؤشر الذي نتحدث عنه.
بعد ذلك، نحدد استعلامًا لإنشاء قاعدة البيانات ونستدعي الدالة:

جميع استعلامات SQL المستخدمة في هذا الدليل مبينة بالتفصيل في سلسلة دروس Introduction to SQL، ويمكن العثور على الكود الكامل في دفتر Jupyter Notebook المرتبط في مستودع GitHub هذا. لذا، لن نقدم شروحات لما يفعله كود SQL في هذا الدليل. ومع ذلك، هذا ربما أبسط استعلام SQL ممكن. إذا كنت تستطيع قراءة اللغة الإنجليزية، فمن المحتمل أن تتمكن من فهم ما يفعله!
تشغيل دالة create_database بالوسائط المذكورة أعلاه يؤدي إلى إنشاء قاعدة بيانات تسمى 'school' في خادمنا. لماذا تسمى قاعدة بياناتنا 'school'؟ ربما حان الوقت الآن للنظر بمزيد من التفصيل في ما سنقوم بتنفيذه بالضبط في هذا الدليل.
تصميم قاعدة بياناتنا: مثال مدرسة اللغات
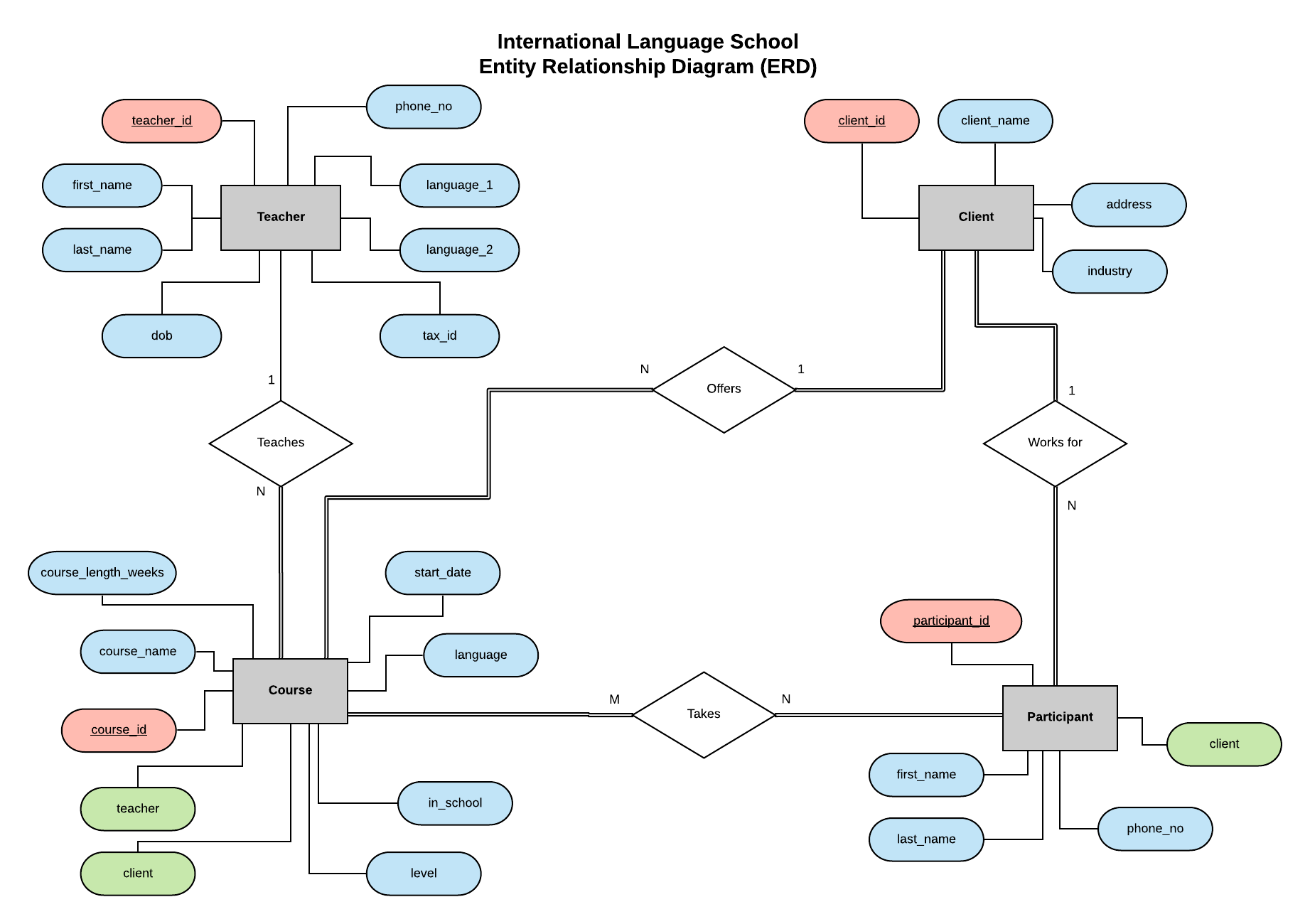
مخطط علاقة الكيانات (ERD) لقاعدة بياناتنا.
باتباع المثال في السلسلة السابقة، سنقوم بتطبيق قاعدة بيانات لمدرسة اللغات الدولية (International Language School) – وهي مدرسة تدريب لغات خيالية تقدم دروسًا لغوية احترافية للعملاء من الشركات. يحدد مخطط علاقة الكيانات (ERD) هذا كياناتنا (Teacher، Client، Course، و Participant) ويعرف العلاقات بينها. يمكن العثور على جميع المعلومات المتعلقة بما هو ERD وما يجب مراعاته عند إنشائه وتصميم قاعدة بيانات في هذا المقال.
يحتوي مستودع GitHub هذا على كود SQL الخام، ومتطلبات قاعدة البيانات، والبيانات التي ستدخل في قاعدة البيانات، ولكنك سترى كل ذلك ونحن نتقدم في هذا الدليل أيضًا.
الاتصال بقاعدة البيانات المحددة
الآن بعد أن أنشأنا قاعدة بيانات في خادم MySQL، يمكننا تعديل دالة create_server_connection للاتصال مباشرة بقاعدة البيانات هذه. لاحظ أنه من الممكن – بل من الشائع، في الواقع – أن يكون لديك قواعد بيانات متعددة على خادم MySQL واحد، لذا نرغب دائمًا في الاتصال تلقائيًا بقاعدة البيانات التي نهتم بها. يمكننا القيام بذلك على النحو التالي:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connection
هذه هي نفس الدالة تمامًا، ولكننا الآن نأخذ وسيطة إضافية – اسم قاعدة البيانات (db_name) – ونمررها كوسيطة إلى الدالة connect().
إنشاء دالة لتنفيذ الاستعلامات
الدالة الأخيرة التي سننشئها (في الوقت الحالي) هي دالة حيوية للغاية – دالة لتنفيذ الاستعلامات. ستأخذ هذه الدالة استعلامات SQL الخاصة بنا، المخزنة في بايثون كسلاسل نصية (strings)، وتمررها إلى طريقة cursor.execute() لتنفيذها على الخادم.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")
هذه الدالة هي نفسها تمامًا مثل دالة create_database التي أنشأناها سابقًا، باستثناء أنها تستخدم طريقة connection.commit() للتأكد من تنفيذ الأوامر المفصلة في استعلامات SQL الخاصة بنا. ستكون هذه هي دالتنا الأساسية، والتي سنستخدمها (إلى جانب create_db_connection) لإنشاء الجداول، وإنشاء العلاقات بين تلك الجداول، وتعبئة الجداول بالبيانات، وتحديث وحذف السجلات في قاعدة بياناتنا. إذا كنت خبيرًا في SQL، فستسمح لك هذه الدالة بتنفيذ جميع الأوامر والاستعلامات المعقدة التي قد تكون لديك، مباشرة من سكربت بايثون. يمكن أن تكون هذه أداة قوية جدًا لإدارة بياناتك.
إنشاء الجداول
الآن نحن جاهزون لبدء تشغيل أوامر SQL في خادمنا وبدء بناء قاعدة بياناتنا. أول شيء نرغب في فعله هو إنشاء الجداول اللازمة. لنبدأ بجدول Teacher:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined query
أولاً، نقوم بتعيين أمر SQL الخاص بنا (المشروح بالتفصيل هنا) لمتغير باسم مناسب. في هذه الحالة، نستخدم تدوين الاقتباس الثلاثي في بايثون لسلاسل النص متعددة الأسطر لتخزين استعلام SQL الخاص بنا، ثم نمرره إلى دالة execute_query لتنفيذه.
لاحظ أن هذا التنسيق متعدد الأسطر هو فقط لفائدة البشر الذين يقرأون الكود الخاص بنا. لا يهتم SQL ولا بايثون إذا تم توزيع أمر SQL بهذه الطريقة. طالما أن بناء الجملة صحيح، ستقبل اللغتان ذلك. ومع ذلك، لفائدة البشر الذين سيقرأون الكود الخاص بك (حتى لو كان ذلك هو "أنت المستقبل" فقط!)، من المفيد جدًا القيام بذلك لجعل الكود أكثر قابلية للقراءة والفهم.
الأمر نفسه ينطبق على استخدام الأحرف الكبيرة (CAPITALISATION) للمشغلين في SQL. هذه اتفاقية مستخدمة على نطاق واسع ويوصى بها بشدة، ولكن البرنامج الفعلي الذي يقوم بتشغيل الكود غير حساس لحالة الأحرف وسيتعامل مع 'CREATE TABLE teacher' و 'create table teacher' كأوامر متطابقة.

تشغيل هذا الكود يمنحنا رسائل النجاح. يمكننا أيضًا التحقق من ذلك في عميل سطر أوامر MySQL Server:

ممتاز! الآن لننشئ الجداول المتبقية.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)
ينشئ هذا الجداول الأربعة الضرورية لكياناتنا الأربعة. الآن نريد تحديد العلاقات بينها وإنشاء جدول آخر للتعامل مع العلاقة متعددة إلى متعدد (many-to-many relationship) بين جدولي participant و course (انظر هنا لمزيد من التفاصيل). نقوم بذلك بنفس الطريقة تمامًا:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)
الآن تم إنشاء جداولنا، جنبًا إلى جنب مع القيود المناسبة، والمفتاح الأساسي (primary key)، وعلاقات المفتاح الأجنبي (foreign key relations).
تعبئة الجداول بالبيانات
الخطوة التالية هي إضافة بعض السجلات إلى الجداول. مرة أخرى، نستخدم execute_query لتغذية أوامر SQL الموجودة لدينا إلى الخادم. لنبدأ مرة أخرى بجدول Teacher.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)
هل هذا يعمل؟ يمكننا التحقق مرة أخرى في عميل سطر أوامر MySQL الخاص بنا:

يبدو جيدًا! الآن لنعبئ الجداول المتبقية.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)
مذهل! لقد أنشأنا الآن قاعدة بيانات كاملة مع العلاقات والقيود والسجلات في MySQL، باستخدام أوامر بايثون فقط. لقد مررنا بهذه الخطوات خطوة بخطوة للحفاظ على سهولة الفهم. ولكن في هذه المرحلة، يمكنك أن ترى أنه يمكن كتابة كل هذا بسهولة شديدة في سكربت بايثون واحد وتنفيذه بأمر واحد في الطرفية. إنها قدرة قوية.
قراءة واسترجاع البيانات
الآن لدينا قاعدة بيانات وظيفية للعمل معها. كمحلل بيانات، من المحتمل أن تتعامل مع قواعد بيانات موجودة في المؤسسات التي تعمل بها. سيكون من المفيد جدًا معرفة كيفية سحب البيانات من قواعد البيانات هذه لتغذيتها بعد ذلك في مسار بيانات بايثون الخاص بك. هذا ما سنعمل عليه بعد ذلك.
للقيام بذلك، سنحتاج إلى دالة أخرى، تستخدم هذه المرة cursor.fetchall() بدلاً من cursor.commit(). باستخدام هذه الدالة، نقوم بقراءة البيانات من قاعدة البيانات ولن نجري أي تغييرات.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")
مرة أخرى، سنقوم بتنفيذ هذا بطريقة مشابهة جدًا لدالة execute_query. دعنا نجربها باستعلام بسيط لنرى كيف تعمل.
q1 = """
SELECT * FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)

بالضبط ما نتوقعه. تعمل الدالة أيضًا مع استعلامات أكثر تعقيدًا، مثل هذا الاستعلام الذي يتضمن عملية ربط (JOIN) بين جدولي course و client.
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)

جيد جداً. بالنسبة لمسارات عملنا وتحليل البيانات في بايثون، قد نرغب في الحصول على هذه النتائج بتنسيقات مختلفة لجعلها أكثر فائدة أو جاهزة للتلاعب بها. دعنا نمر على بعض الأمثلة لنرى كيف يمكننا القيام بذلك.
تنسيق المخرجات إلى قائمة (List)
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)

تنسيق المخرجات إلى قائمة من القوائم (List of Lists)
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)

تنسيق المخرجات إلى إطار بيانات Pandas (Pandas DataFrame)
لمحللي البيانات الذين يستخدمون بايثون، مكتبة pandas هي صديقنا القديم الجميل والموثوق به. من السهل جدًا تحويل المخرجات من قاعدة بياناتنا إلى إطار بيانات (DataFrame)، ومن هناك، الاحتمالات لا حصر لها!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)

نأمل أن ترى الإمكانيات تتكشف أمامك هنا. ببضعة أسطر من الكود، يمكننا بسهولة استخراج جميع البيانات التي يمكننا التعامل معها من قواعد البيانات العلائقية التي تعيش فيها، وسحبها إلى مسارات تحليل البيانات الحديثة الخاصة بنا. هذا أمر مفيد حقًا.
تحديث السجلات
عندما نقوم بصيانة قاعدة بيانات، سنحتاج أحيانًا إلى إجراء تغييرات على السجلات الموجودة. في هذا القسم، سننظر في كيفية القيام بذلك. لنفترض أن مدرسة اللغات الدولية (ILS) تم إخطارها بأن أحد عملائها الحاليين، اتحاد الأعمال الكبيرة (Big Business Federation)، ينتقل إلى مكاتب جديدة في 23 Fingiertweg, 14534 Berlin. في هذه الحالة، سيحتاج مسؤول قاعدة البيانات (وهو نحن!) إلى إجراء بعض التغييرات. لحسن الحظ، يمكننا القيام بذلك باستخدام دالة execute_query جنبًا إلى جنب مع عبارة SQL UPDATE.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)
لاحظ أن عبارة WHERE مهمة جدًا هنا. إذا قمنا بتشغيل هذا الاستعلام بدون عبارة WHERE، فسيتم تحديث جميع العناوين لجميع السجلات في جدول Client الخاص بنا إلى 23 Fingiertweg. وهذا ليس ما نبحث عنه على الإطلاق.
لاحظ أيضًا أننا استخدمنا "WHERE client_id = 101" في استعلام UPDATE. كان من الممكن أيضًا استخدام "WHERE client_name = 'Big Business Federation'" أو "WHERE address = '123 Falschungstraße, 10999 Berlin'" أو حتى "WHERE address LIKE '%Falschung%'". المهم هو أن عبارة WHERE تسمح لنا بتحديد السجل (أو السجلات) التي نريد تحديثها بشكل فريد.
حذف السجلات
من الممكن أيضًا استخدام دالة execute_query لحذف السجلات، باستخدام الأمر DELETE. عند استخدام SQL مع قواعد البيانات العلائقية، نحتاج إلى توخي الحذر عند استخدام عامل DELETE. هذا ليس نظام Windows، لا يوجد تحذير منبثق "هل أنت متأكد من أنك تريد حذف هذا؟"، ولا توجد سلة مهملات. بمجرد حذف شيء ما، فإنه يختفي حقًا.
مع ذلك، نحتاج حقًا إلى حذف الأشياء أحيانًا. لذا دعنا نلقي نظرة على ذلك عن طريق حذف دورة تدريبية من جدول Course الخاص بنا. أولاً، دعنا نتذكر الدورات التدريبية التي لدينا.
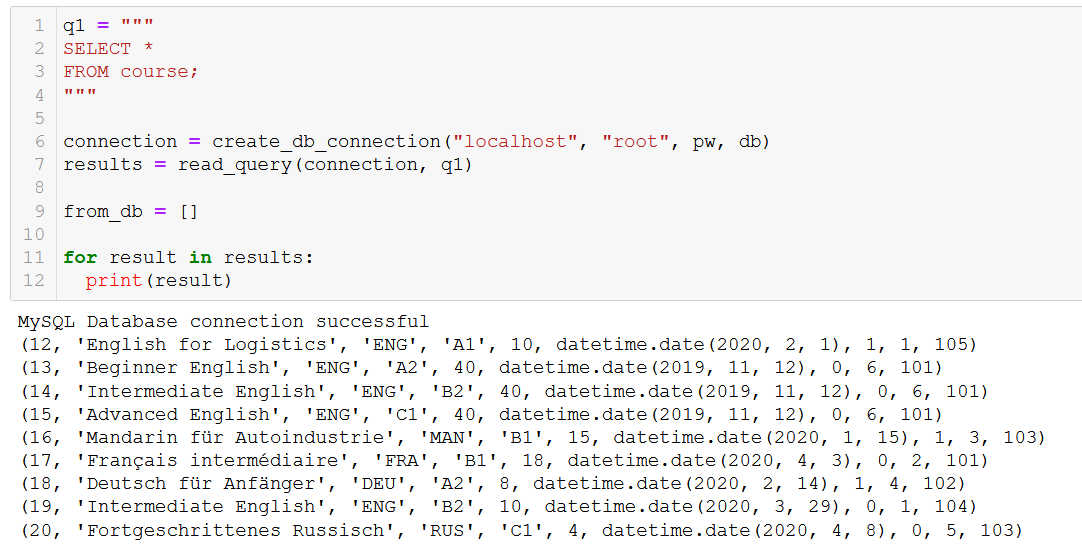
لنقل أن الدورة 20، "Fortgeschrittenes Russisch" (وهي "الروسية المتقدمة" بالنسبة لنا)، توشك على الانتهاء، لذا نحتاج إلى إزالتها من قاعدة بياناتنا. في هذه المرحلة، لن تتفاجأ على الإطلاق بكيفية القيام بذلك – احفظ أمر SQL كسلسلة نصية، ثم قم بتغذيته إلى دالة execute_query الأساسية لدينا.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)
دعنا نتحقق للتأكد من أن ذلك كان له التأثير المقصود:
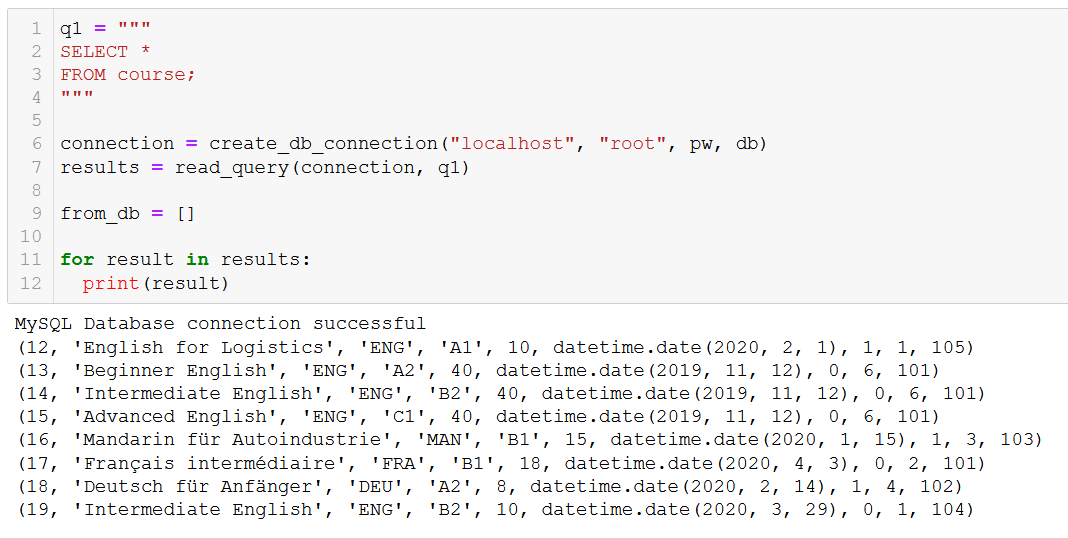
لقد اختفت "الروسية المتقدمة"، كما توقعنا. هذا يعمل أيضًا مع حذف أعمدة كاملة باستخدام أوامر DROP COLUMN وجداول كاملة باستخدام أوامر DROP TABLE، لكننا لن نغطيها في هذا الدليل. ومع ذلك، لا تتردد في تجربتها – لا يهم إذا حذفت عمودًا أو جدولًا من قاعدة بيانات لمدرسة خيالية، وهي فكرة جيدة أن تصبح مرتاحًا لهذه الأوامر قبل الانتقال إلى بيئة إنتاجية.
عمليات CRUD الأساسية
في هذه المرحلة، أصبحنا الآن قادرين على إكمال العمليات الأربع الرئيسية لتخزين البيانات المستمر. لقد تعلمنا كيفية:
- الإنشاء (
Create): قواعد بيانات وجداول وسجلات جديدة بالكامل. - القراءة (
Read): استخراج البيانات من قاعدة بيانات، وتخزين تلك البيانات بتنسيقات متعددة. - التحديث (
Update): إجراء تغييرات على السجلات الموجودة في قاعدة البيانات. - الحذف (
Delete): إزالة السجلات التي لم تعد هناك حاجة إليها.
هذه أمور مفيدة بشكل رائع أن تكون قادرًا على القيام بها. قبل أن ننهي الأمور هنا، لدينا مهارة أخرى مفيدة جدًا لنتعلمها.
إنشاء سجلات من قوائم بايثون
لقد رأينا عند تعبئة جداولنا أنه يمكننا استخدام أمر SQL INSERT في دالة execute_query لإدراج سجلات في قاعدة بياناتنا. نظرًا لأننا نستخدم بايثون للتلاعب بقاعدة بيانات SQL الخاصة بنا، فسيكون من المفيد أن نكون قادرين على أخذ بنية بيانات بايثون (مثل قائمة list) وإدراجها مباشرة في قاعدة بياناتنا. يمكن أن يكون هذا مفيدًا عندما نريد تخزين سجلات نشاط المستخدم على تطبيق وسائط اجتماعية كتبناه في بايثون، أو إدخال من المستخدمين في ويكي قمنا ببنائه، على سبيل المثال. هناك العديد من الاستخدامات الممكنة لهذا بقدر ما يمكنك التفكير فيه.
هذه الطريقة أيضًا أكثر أمانًا إذا كانت قاعدة بياناتنا مفتوحة لمستخدمينا في أي وقت، حيث تساعد في منع هجمات حقن SQL (SQL Injection attacks)، والتي يمكن أن تلحق الضرر بقاعدة بياناتنا بأكملها أو حتى تدمرها.
للقيام بذلك، سنكتب دالة تستخدم طريقة executemany()، بدلاً من طريقة execute() الأبسط التي كنا نستخدمها حتى الآن.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")
الآن بعد أن أصبح لدينا الدالة، نحتاج إلى تعريف أمر SQL (المتغير 'sql') وقائمة تحتوي على القيم التي نرغب في إدخالها في قاعدة البيانات (المتغير 'val'). يجب تخزين القيم كقائمة من الصفوف (list of tuples)، وهي طريقة شائعة إلى حد ما لتخزين البيانات في بايثون. لإضافة مدرسين جديدين إلى قاعدة البيانات، يمكننا كتابة بعض الأكواد مثل هذا:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]
لاحظ هنا أننا في كود 'sql' نستخدم '%s' كعنصر نائب لقيمتنا. التشابه مع العنصر النائب '%s' لسلسلة نصية في بايثون هو مجرد مصادفة (وبصراحة، مربك للغاية)، نريد استخدام '%s' لجميع أنواع البيانات (سلاسل نصية، أعداد صحيحة، تواريخ، إلخ) مع موصل MySQL Python Connector. يمكنك رؤية عدد من الأسئلة على Stackoverflow حيث ارتبك شخص ما وحاول استخدام عناصر نائبة '%d' للأعداد الصحيحة لأنه اعتاد على القيام بذلك في بايثون. هذا لن يعمل هنا – نحتاج إلى استخدام '%s' لكل عمود نريد إضافة قيمة إليه.
تأخذ دالة executemany بعد ذلك كل صف (tuple) في قائمة 'val' الخاصة بنا وتدرج القيمة ذات الصلة لهذا العمود بدلاً من العنصر النائب وتنفذ أمر SQL لكل صف موجود في القائمة. يمكن إجراء ذلك لصفوف متعددة من البيانات، طالما أنها منسقة بشكل صحيح. في مثالنا، سنضيف مدرسين جديدين فقط، لأغراض توضيحية، ولكن من حيث المبدأ يمكننا إضافة أي عدد نرغب فيه.
دعنا نمضي قدمًا وننفذ هذا الاستعلام ونضيف المعلمين إلى قاعدة بياناتنا.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)

أهلاً بكم في مدرسة اللغات الدولية، هانك وسو! هذه دالة أخرى مفيدة للغاية، تسمح لنا بأخذ البيانات التي تم إنشاؤها في سكربتات وتطبيقات بايثون الخاصة بنا، وإدخالها مباشرة في قاعدة بياناتنا.
الخاتمة
لقد غطينا الكثير من الجوانب في هذا الدليل. تعلمنا كيفية استخدام بايثون وموصل MySQL Connector لإنشاء قاعدة بيانات جديدة بالكامل في خادم MySQL، وإنشاء جداول داخل تلك القاعدة، وتحديد العلاقات بين تلك الجداول، وتعبئتها بالبيانات. لقد غطينا كيفية إنشاء وقراءة وتحديث وحذف البيانات في قاعدة بياناتنا.
لقد نظرنا في كيفية استخراج البيانات من قواعد البيانات الموجودة وتحميلها في إطارات بيانات Pandas DataFrames، لتكون جاهزة للتحليل والمزيد من العمل بالاستفادة من جميع الإمكانيات التي توفرها حزمة PyData stack. وبالاتجاه الآخر، تعلمنا أيضًا كيفية أخذ البيانات التي تم إنشاؤها بواسطة سكربتات وتطبيقات بايثون الخاصة بنا، وكتابتها في قاعدة بيانات حيث يمكن تخزينها بأمان لاسترجاعها والتلاعب بها لاحقًا.
نأمل أن يكون هذا الدليل قد ساعدك على رؤية كيف يمكننا استخدام بايثون و SQL معًا لتتمكن من التلاعب بالبيانات بشكل أكثر فعالية!
الخلاصة التقنية
يُبرز هذا المقال ببراعة التكامل القوي بين بايثون و SQL كأدوات لا غنى عنها في عالم تحليل البيانات وهندستها. من خلال استخدام مكتبة mysql.connector، تمكنا من بناء جسر فعال بين بيئة بايثون المرنة وقواعد بيانات MySQL القوية. إن القدرة على أتمتة عمليات CRUD (الإنشاء، القراءة، التحديث، الحذف) مباشرة من بايثون، بالإضافة إلى تحويل البيانات المسترجعة إلى هياكل بيانات بايثون مألوفة مثل Pandas DataFrames، تفتح آفاقًا واسعة للمطورين ومحللي البيانات. هذا التكامل لا يقتصر على الكفاءة التشغيلية فحسب، بل يعزز أيضًا الأمان من خلال استخدام طرق مثل executemany() التي تساعد في الحماية من ثغرات حقن SQL. يعد هذا الدليل مرجعًا ممتازًا لأي شخص يسعى لإتقان إدارة البيانات العلائقية باستخدام لغة بايثون.