الشبكات العصبية العميقة: دليل شامل للمبتدئين في التعلم العميق

مقدمة إلى عالم الشبكات العصبية العميقة
يُعد التعلم الآلي، وبخاصة التعلم العميق، من التقنيات التحويلية التي تعيد تشكيل عالمنا اليوم. بعد فترة طويلة عُرفت بـ "شتاء الذكاء الاصطناعي" امتدت لثلاثين عامًا، تضافرت قوة الحوسبة وتوافر مجموعات البيانات الضخمة أخيرًا مع خوارزميات الذكاء الاصطناعي التي اقتُرحت في النصف الثاني من القرن العشرين. هذا التطور مكن نماذج التعلم العميق من تحقيق تنبؤات فعالة وحل مشكلات واقعية معقدة.
أصبح من الضروري أكثر من أي وقت مضى لعلماء البيانات ومهندسي البرمجيات أن يمتلكوا فهمًا رفيع المستوى لكيفية عمل نماذج التعلم العميق. يهدف هذا المقال إلى شرح تاريخ ومفاهيم الشبكات العصبية العميقة بأسلوب واضح ومبسط.
الرحلة التاريخية للتعلم العميق
تأسس مفهوم التعلم العميق على يد جيفري هينتون في الثمانينيات، ويُعتبر على نطاق واسع الأب المؤسس لهذا المجال. عمل هينتون في جوجل منذ مارس 2013 بعد استحواذ الشركة على شركته DNNresearch Inc.. كان إسهام هينتون الرئيسي في مجال التعلم العميق هو مقارنة تقنيات التعلم الآلي بالدماغ البشري.
بشكل أكثر تحديدًا، ابتكر مفهوم "الشبكة العصبية"، وهي خوارزمية للتعلم العميق مُصممة بهيكل مشابه لتنظيم الخلايا العصبية في الدماغ. اتبع هينتون هذا النهج لأن الدماغ البشري يُعد بلا شك أقوى محرك حاسوبي معروف حتى الآن. أُطلق على الهيكل الذي ابتكره هينتون اسم الشبكة العصبية الاصطناعية (أو artificial neural net اختصارًا).
إليك وصف موجز لكيفية عملها:
- تتكون الشبكات العصبية الاصطناعية من طبقات من العقد (
nodes). - صُممت كل عقدة لتتصرف بشكل مشابه للخلية العصبية في الدماغ.
- تُسمى الطبقة الأولى من الشبكة العصبية
input layer(طبقة الإدخال)، تليهاhidden layers(الطبقات المخفية)، ثم أخيرًاoutput layer(طبقة الإخراج). - تُجري كل عقدة في الشبكة العصبية نوعًا من الحساب، والذي يُمرر إلى عقد أخرى أعمق في الشبكة.
إليك تصور مبسط يوضح كيفية عمل ذلك:
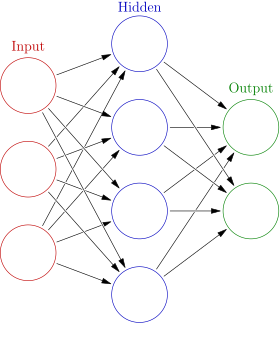
مثّلت الشبكات العصبية خطوة هائلة إلى الأمام في مجال التعلم العميق. ومع ذلك، استغرق الأمر عقودًا حتى يكتسب التعلم الآلي (وبخاصة التعلم العميق) مكانة بارزة. سنستكشف السبب في القسم التالي.
لماذا لم ينجح التعلم العميق فورًا؟
إذا كان التعلم العميق قد صُمم في الأصل منذ عقود، فلماذا بدأ يكتسب زخمًا اليوم فقط؟ يرجع ذلك إلى أن أي نموذج تعلم عميق ناضج يتطلب وفرة من موردين أساسيين:
- البيانات (
Data) - قوة الحوسبة (
Computing power)
في وقت الميلاد المفاهيمي للتعلم العميق، لم يكن الباحثون يمتلكون ما يكفي من البيانات أو قوة الحوسبة لبناء وتدريب نماذج تعلم عميق ذات مغزى. لقد تغير هذا بمرور الوقت، مما أدى إلى بروز التعلم العميق اليوم.
فهم الخلايا العصبية في التعلم العميق
تُعد الخلايا العصبية (neurons) مكونًا حاسمًا في أي نموذج تعلم عميق. في الواقع، يمكن القول إنه لا يمكنك فهم التعلم العميق بشكل كامل دون معرفة عميقة بكيفية عمل الخلايا العصبية. سيعرفك هذا القسم على مفهوم الخلايا العصبية في التعلم العميق. سنتحدث عن أصل خلايا التعلم العميق العصبية، وكيف استُلهمت من بيولوجيا الدماغ البشري، ولماذا تُعد الخلايا العصبية مهمة جدًا في نماذج التعلم العميق اليوم.
ما هي الخلية العصبية في علم الأحياء؟
استُلهمت الخلايا العصبية في التعلم العميق من الخلايا العصبية في الدماغ البشري. إليك مخططًا لتشريح الخلية العصبية الدماغية:
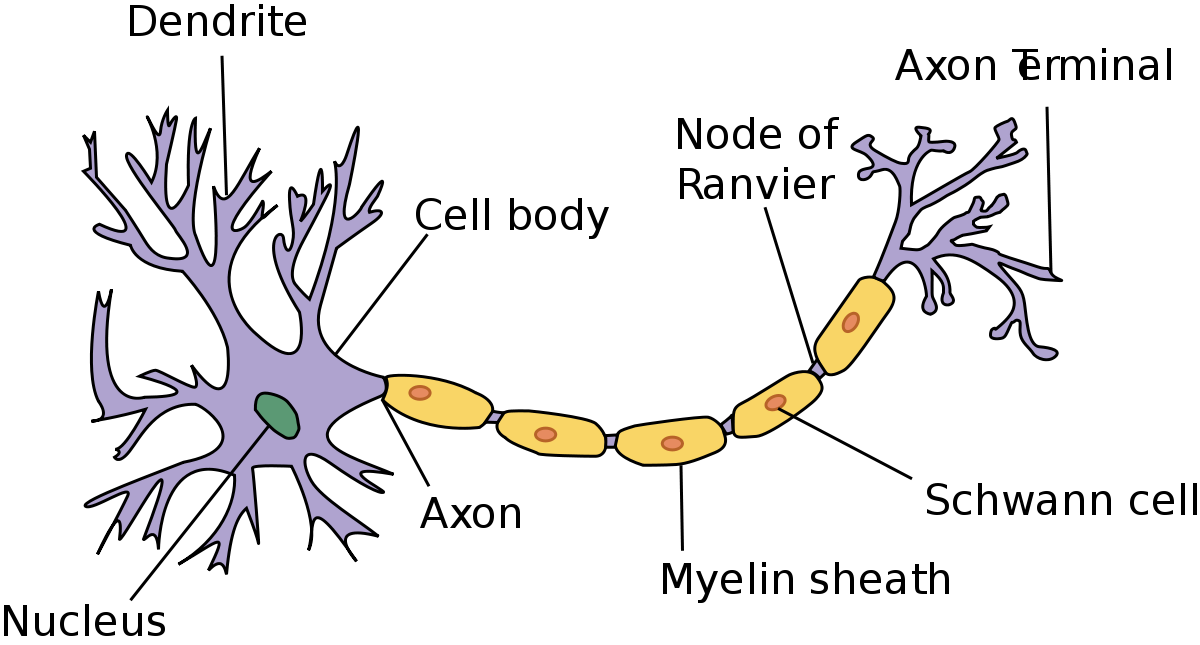
كما ترى، تتمتع الخلايا العصبية بهيكل مثير للاهتمام. تعمل مجموعات من الخلايا العصبية معًا داخل الدماغ البشري لأداء الوظائف التي نحتاجها في حياتنا اليومية. كان السؤال الذي طرحه جيفري هينتون خلال بحثه الرائد في الشبكات العصبية هو ما إذا كان بإمكاننا بناء خوارزميات حاسوبية تتصرف بشكل مشابه للخلايا العصبية في الدماغ. كان الأمل هو أنه من خلال محاكاة بنية الدماغ، قد نتمكن من التقاط بعض من قدراته.
لتحقيق ذلك، درس الباحثون طريقة تصرف الخلايا العصبية في الدماغ. كانت إحدى الملاحظات المهمة هي أن الخلية العصبية بحد ذاتها عديمة الفائدة. بدلاً من ذلك، تحتاج إلى شبكات من الخلايا العصبية لتوليد أي وظائف ذات مغزى. هذا لأن الخلايا العصبية تعمل عن طريق استقبال وإرسال الإشارات. وبشكل أكثر تحديدًا، تستقبل dendrites (الزوائد الشجرية) للخلية العصبية الإشارات وتمرر تلك الإشارات عبر axon (المحور العصبي). تتصل dendrites لخلية عصبية واحدة بـ axon لخلية عصبية أخرى. تُسمى هذه الاتصالات synapses (المشابك العصبية)، وهو مفهوم تم تعميمه على مجال التعلم العميق.
ما هي الخلية العصبية في التعلم العميق؟
الخلايا العصبية في نماذج التعلم العميق هي عقد (nodes) يتدفق من خلالها البيانات والحسابات. تعمل الخلايا العصبية على النحو التالي:
- تستقبل إشارة إدخال واحدة أو أكثر. يمكن أن تأتي إشارات الإدخال هذه إما من مجموعة البيانات الخام أو من خلايا عصبية موضوعة في طبقة سابقة من الشبكة العصبية.
- تُجري بعض الحسابات.
- تُرسل بعض إشارات الإخراج إلى خلايا عصبية أعمق في الشبكة العصبية عبر
synapse(مشابك عصبية).
إليك مخطط لوظيفة الخلية العصبية في شبكة عصبية للتعلم العميق:
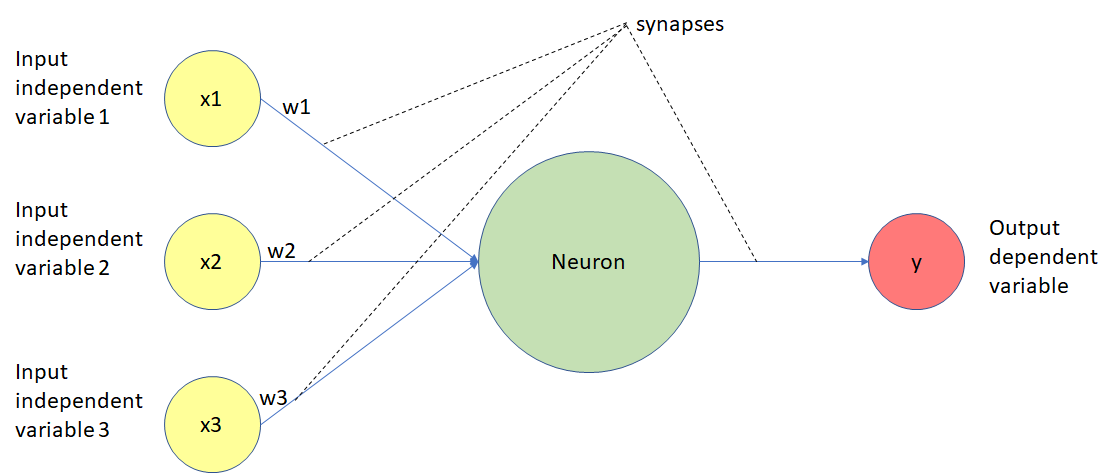
دعنا نستعرض هذا المخطط خطوة بخطوة. كما ترى، الخلايا العصبية في نموذج التعلم العميق قادرة على امتلاك مشابك تتصل بأكثر من خلية عصبية واحدة في الطبقة السابقة. لكل مشبك weight (وزن) مرتبط به، والذي يؤثر على أهمية الخلية العصبية السابقة في الشبكة العصبية الكلية. تُعد الأوزان موضوعًا مهمًا جدًا في مجال التعلم العميق لأن تعديل أوزان النموذج هو الطريقة الأساسية التي يتم من خلالها تدريب نماذج التعلم العميق. سترى هذا عمليًا لاحقًا عندما نبني أولى شبكاتنا العصبية من الصفر.
بمجرد أن تستقبل الخلية العصبية مدخلاتها من الخلايا العصبية في الطبقة السابقة للنموذج، فإنها تجمع كل إشارة مضروبة في وزنها المقابل وتمررها إلى دالة تنشيط (activation function)، على هذا النحو:
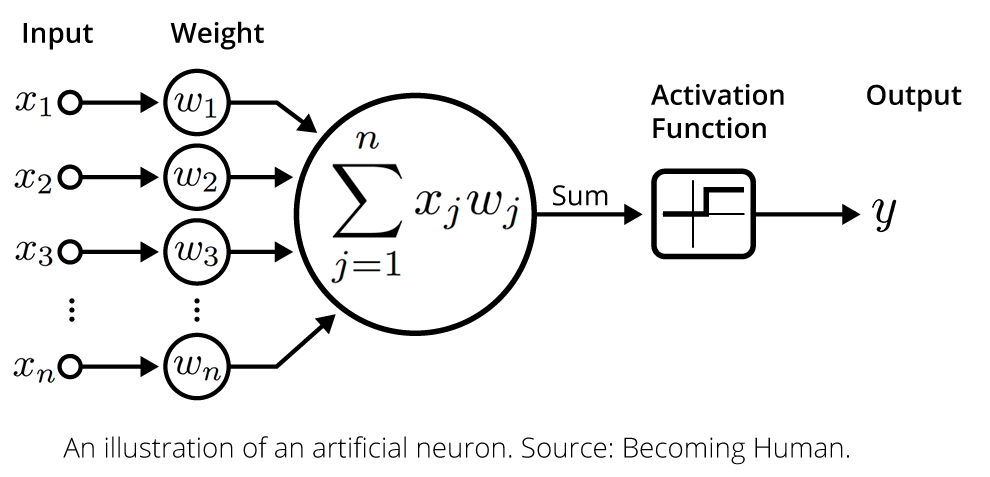
تحسب دالة التنشيط قيمة الإخراج للخلية العصبية. ثم تُمرر قيمة الإخراج هذه إلى الطبقة التالية من الشبكة العصبية عبر مشبك آخر. هذا بمثابة نظرة عامة واسعة على خلايا التعلم العميق العصبية. لا تقلق إذا كان الأمر كثيرًا لاستيعابه – سنتعلم المزيد عن الخلايا العصبية في بقية هذا البرنامج التعليمي. في الوقت الحالي، يكفي أن يكون لديك فهم رفيع المستوى لكيفية هيكلتها في نموذج التعلم العميق.
وظائف التنشيط في التعلم العميق
تُعد وظائف التنشيط (Activation functions) مفهومًا أساسيًا لفهمه في التعلم العميق. إنها ما يسمح للخلايا العصبية في الشبكة العصبية بالتواصل مع بعضها البعض عبر مشابكها. في هذا القسم، ستتعلم فهم أهمية ووظيفة وظائف التنشيط في التعلم العميق.
ما هي وظائف التنشيط في التعلم العميق؟
في القسم الأخير، تعلمنا أن الخلايا العصبية تستقبل إشارات إدخال من الطبقة السابقة للشبكة العصبية. يُغذى مجموع مرجح لهذه الإشارات في دالة التنشيط للخلية العصبية، ثم يُمرر إخراج دالة التنشيط إلى الطبقة التالية من الشبكة. هناك أربعة أنواع رئيسية من وظائف التنشيط التي سنناقشها في هذا البرنامج التعليمي:
- وظائف العتبة (
Threshold functions) - وظائف السيجمويد (
Sigmoid functions) - وظائف المصحح، أو
ReLUs(Rectifier functions) - وظائف الظل الزائدي (
Hyperbolic Tangent functions)
دعنا نعمل من خلال وظائف التنشيط هذه واحدة تلو الأخرى.
وظائف العتبة (Threshold Functions)
تحسب وظائف العتبة إشارة إخراج مختلفة اعتمادًا على ما إذا كانت مدخلاتها تقع فوق أو تحت عتبة معينة. تذكر أن قيمة الإدخال لدالة التنشيط هي المجموع المرجح لقيم الإدخال من الطبقة السابقة في الشبكة العصبية. رياضيًا، إليك التعريف الرسمي لدالة عتبة التعلم العميق:
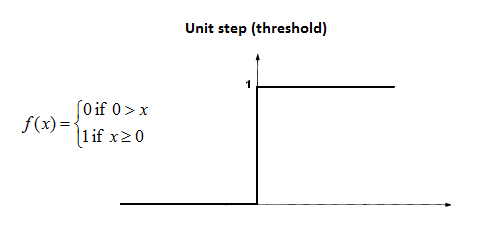
كما تشير الصورة أعلاه، تُسمى دالة العتبة أحيانًا أيضًا unit step function (دالة الخطوة الوحدوية). تتشابه وظائف العتبة مع المتغيرات المنطقية (boolean variables) في برمجة الكمبيوتر. قيمتها المحسوبة هي إما 1 (مشابهة لـ True) أو 0 (مكافئة لـ False).
دالة السيجمويد (The Sigmoid Function)
تشتهر دالة السيجمويد (sigmoid function) بين مجتمع علوم البيانات بسبب استخدامها في الانحدار اللوجستي (logistic regression)، وهي إحدى تقنيات التعلم الآلي الأساسية المستخدمة لحل مشكلات التصنيف. يمكن لدالة السيجمويد قبول أي قيمة، ولكنها تحسب دائمًا قيمة تتراوح بين 0 و 1. إليك التعريف الرياضي لدالة السيجمويد:
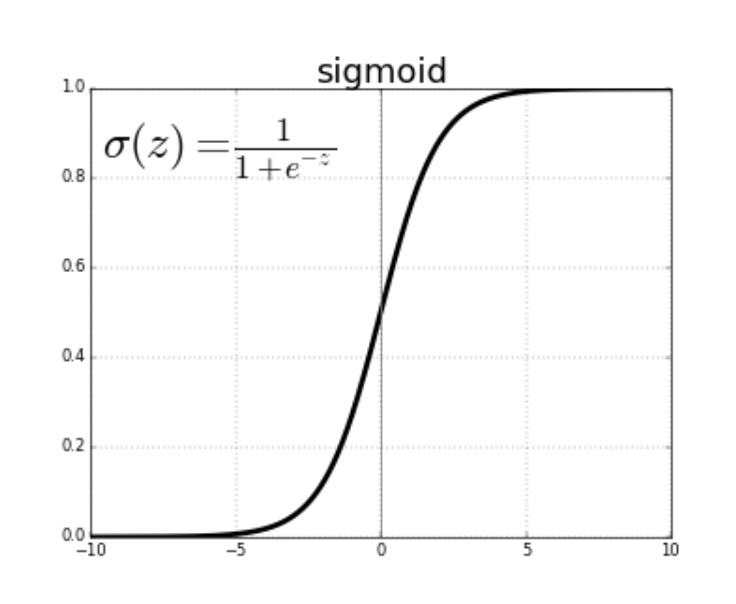
إحدى فوائد دالة السيجمويد على دالة العتبة هي أن منحناها سلس. هذا يعني أنه من الممكن حساب المشتقات عند أي نقطة على طول المنحنى، وهو أمر بالغ الأهمية في عملية التدريب.
دالة المصحح (The Rectifier Function)
لا تتمتع دالة المصحح (rectifier function) بنفس خاصية السلاسة مثل دالة السيجمويد من القسم الأخير. ومع ذلك، لا تزال تحظى بشعبية كبيرة في مجال التعلم العميق. تُعرف دالة المصحح على النحو التالي:
- إذا كانت قيمة الإدخال أقل من
0، فإن الدالة تُخرج0. - وإلا، فإن الدالة تُخرج قيمة إدخالها.
إليك هذا المفهوم مشروحًا رياضيًا:
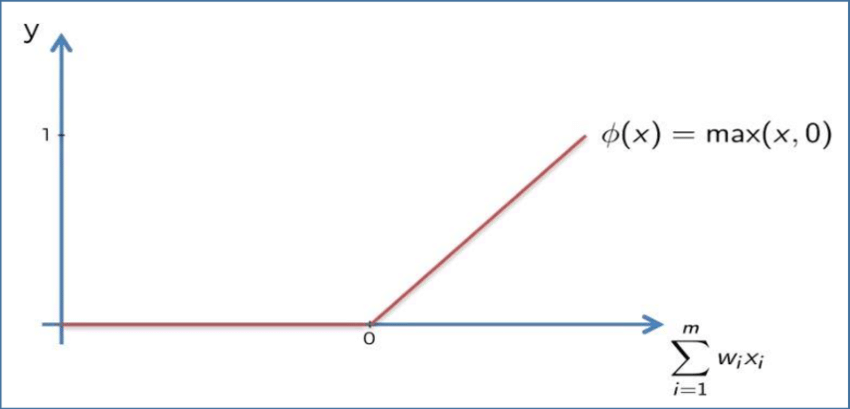
غالبًا ما تُسمى وظائف المصحح Rectified Linear Unit activation functions، أو ReLUs اختصارًا. وهي تُعد الخيار الافتراضي في العديد من الشبكات العصبية الحديثة نظرًا لكفاءتها الحسابية.
دالة الظل الزائدي (The Hyperbolic Tangent Function)
دالة الظل الزائدي (hyperbolic tangent function) هي دالة التنشيط الوحيدة المدرجة في هذا البرنامج التعليمي التي تعتمد على هوية مثلثية. تعريفها الرياضي أدناه:
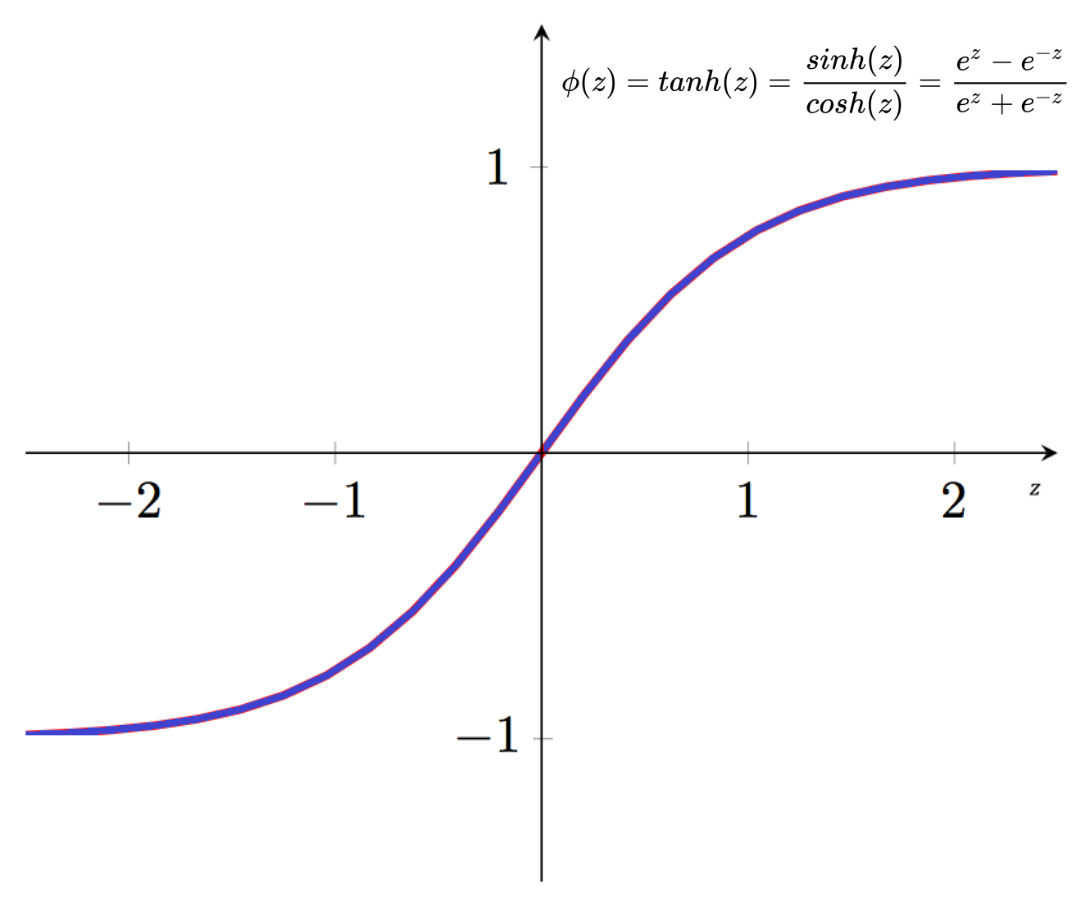
تتشابه دالة الظل الزائدي في مظهرها مع دالة السيجمويد، لكن قيم إخراجها كلها مُزاحة إلى الأسفل، مما يجعل نطاقها يتراوح بين -1 و 1.
كيف تعمل الشبكات العصبية حقًا؟
حتى الآن في هذا البرنامج التعليمي، ناقشنا اثنين من اللبنات الأساسية لبناء الشبكات العصبية:
- الخلايا العصبية (
Neurons) - وظائف التنشيط (
Activation functions)
ومع ذلك، ربما لا تزال مرتبكًا بعض الشيء بشأن كيفية عمل الشبكات العصبية حقًا. سيجمع هذا البرنامج التعليمي القطع التي ناقشناها بالفعل حتى تتمكن من فهم كيفية عمل الشبكات العصبية عمليًا.
المثال الذي سنستخدمه في هذا البرنامج التعليمي
سيتناول هذا البرنامج التعليمي مثالًا واقعيًا خطوة بخطوة حتى تتمكن من فهم كيفية قيام الشبكات العصبية بإجراء التنبؤات. وبشكل أكثر تحديدًا، سنتعامل مع تقييمات العقارات. ربما تعلم بالفعل أن هناك عددًا كبيرًا من العوامل التي تؤثر على أسعار المنازل، بما في ذلك الاقتصاد، وأسعار الفائدة، وعدد غرف النوم/الحمامات، وموقعها. الأبعاد العالية لمجموعة البيانات هذه تجعلها مرشحًا مثيرًا للاهتمام لبناء وتدريب شبكة عصبية عليها. ملاحظة حول هذا القسم هي أن الشبكة العصبية التي سنستخدمها لإجراء التنبؤات قد تم تدريبها بالفعل. سنستكشف عملية تدريب شبكة عصبية جديدة في القسم التالي من هذا البرنامج التعليمي.
المعلمات في مجموعة بياناتنا
دعنا نبدأ بمناقشة المعلمات في مجموعة بياناتنا. وبشكل أكثر تحديدًا، دعنا نتخيل أن مجموعة البيانات تحتوي على المعلمات التالية:
- المساحة بالقدم المربع (
Square footage) - عدد غرف النوم (
Bedrooms) - المسافة إلى مركز المدينة (
Distance to city center) - عمر المنزل (
House age)
ستشكل هذه المعلمات الأربع طبقة الإدخال للشبكة العصبية الاصطناعية. لاحظ أنه في الواقع، من المحتمل أن يكون هناك العديد من المعلمات التي يمكنك استخدامها لتدريب شبكة عصبية للتنبؤ بأسعار المساكن. لقد قيدنا هذا العدد بأربعة للحفاظ على المثال بسيطًا بشكل معقول.
الشكل الأساسي للشبكة العصبية
في أبسط أشكالها، تحتوي الشبكة العصبية على طبقتين فقط – طبقة الإدخال (input layer) وطبقة الإخراج (output layer). طبقة الإخراج هي المكون الذي يقوم فعليًا بإجراء التنبؤات. على سبيل المثال، إذا كنت ترغب في إجراء تنبؤات باستخدام نموذج مجموع مرجح بسيط (يُسمى أيضًا الانحدار الخطي)، فستأخذ شبكتك العصبية الشكل التالي:
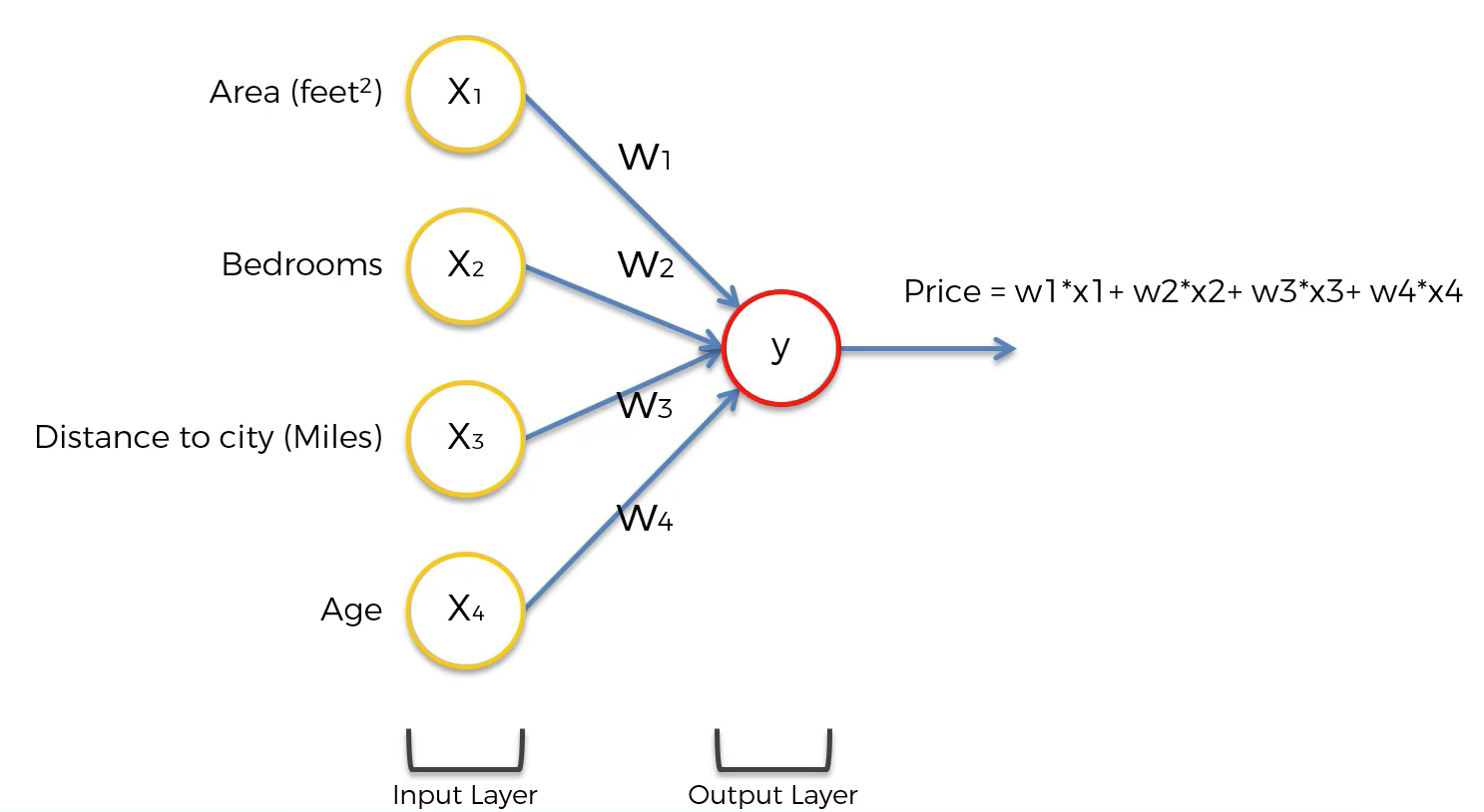
بينما هذا المخطط مجرد بعض الشيء، فإن النقطة المهمة هي أن معظم الشبكات العصبية يمكن تصورها بهذه الطريقة:
- طبقة إدخال (
An input layer) - ربما بعض الطبقات المخفية (
Possibly some hidden layers) - طبقة إخراج (
An output layer)
إن الطبقة المخفية من الخلايا العصبية هي التي تجعل الشبكات العصبية قوية جدًا في حساب التنبؤات. لكل خلية عصبية في طبقة مخفية، تُجري حسابات باستخدام بعض (أو كل) الخلايا العصبية في الطبقة الأخيرة من الشبكة العصبية. ثم تُستخدم هذه القيم في الطبقة التالية من الشبكة العصبية.
الغرض من الخلايا العصبية في الطبقة المخفية للشبكة العصبية
ربما تتساءل – ما الذي تعنيه بالضبط كل خلية عصبية في الطبقة المخفية؟ بعبارة أخرى، كيف يجب على ممارسي التعلم الآلي تفسير هذه القيم؟ بشكل عام، تُنشط الخلايا العصبية في الطبقات الوسطى من الشبكة العصبية (مما يعني أن دالة التنشيط الخاصة بها تُرجع 1) لقيمة إدخال تفي بخصائص فرعية معينة. بالنسبة لنموذج التنبؤ بأسعار المساكن لدينا، قد يكون أحد الأمثلة هو المنازل المكونة من 5 غرف نوم بمسافات قصيرة إلى مركز المدينة. في معظم الحالات الأخرى، ليس من السهل وصف الخصائص التي ستؤدي إلى تنشيط خلية عصبية في طبقة مخفية.
كيف تحدد الخلايا العصبية قيم مدخلاتها
في وقت سابق من هذا البرنامج التعليمي، كتبت "لكل خلية عصبية في طبقة مخفية، تُجري حسابات باستخدام بعض (أو كل) الخلايا العصبية في الطبقة الأخيرة من الشبكة العصبية." يوضح هذا نقطة مهمة – وهي أن كل خلية عصبية في الشبكة العصبية لا تحتاج إلى استخدام كل خلية عصبية في الطبقة السابقة. تُسمى العملية التي تحدد من خلالها الخلايا العصبية قيم الإدخال التي ستستخدمها من الطبقة السابقة للشبكة العصبية تدريب النموذج (training the model). سنتعلم المزيد عن تدريب الشبكات العصبية في القسم التالي من هذه الدورة.
تصور عملية التنبؤ للشبكة العصبية
عند تصور شبكة عصبية، نرسم عادةً خطوطًا من الطبقة السابقة إلى الطبقة الحالية عندما يكون للخلية العصبية السابقة وزن أعلى من 0 في صيغة المجموع المرجح للخلية العصبية الحالية. ستساعد الصورة التالية في تصور ذلك:
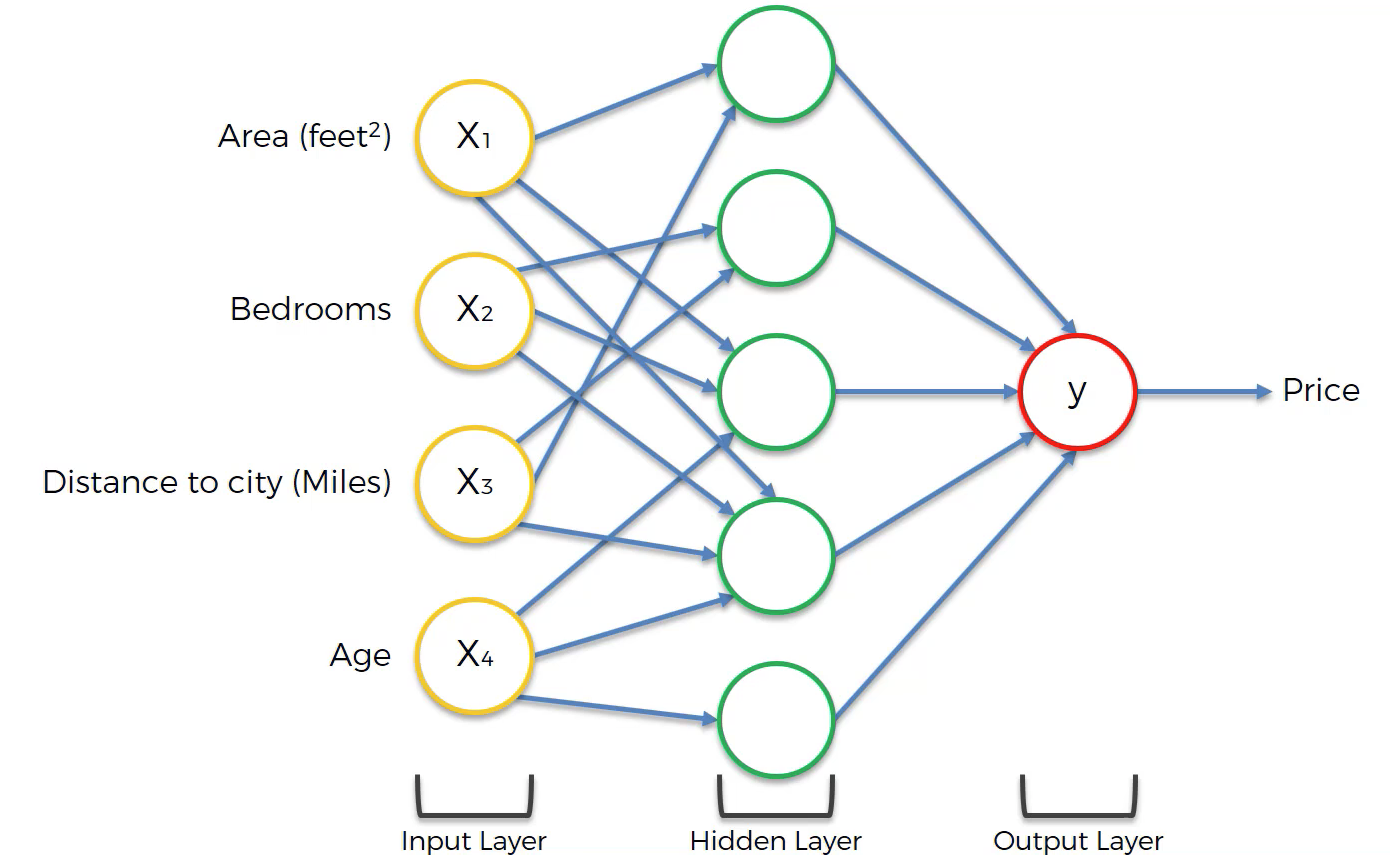
كما ترى، لا يوجد مشبك بين كل زوج من الخلايا العصبية. على سبيل المثال، x4 يغذي ثلاث فقط من أصل خمس خلايا عصبية في الطبقة المخفية. يوضح هذا نقطة مهمة عند بناء الشبكات العصبية – وهي أنه لا يجب استخدام كل خلية عصبية في طبقة سابقة في الطبقة التالية من الشبكة العصبية.
كيف يتم تدريب الشبكات العصبية
حتى الآن تعلمت ما يلي عن الشبكات العصبية:
- أنها تتكون من خلايا عصبية.
- أن كل خلية عصبية تستخدم دالة تنشيط مطبقة على المجموع المرجح للمخرجات من الطبقة السابقة للشبكة العصبية.
- نظرة عامة واسعة بدون أكواد على كيفية قيام الشبكات العصبية بإجراء التنبؤات.
لم نغط بعد جزءًا مهمًا جدًا من عملية هندسة الشبكات العصبية: كيفية تدريب الشبكات العصبية. الآن ستتعلم كيفية تدريب الشبكات العصبية. سنناقش مجموعات البيانات والخوارزميات والمبادئ العامة المستخدمة في تدريب الشبكات العصبية الحديثة التي تحل مشكلات العالم الحقيقي.
البرمجة الصلبة مقابل البرمجة المرنة (Hard-Coding vs. Soft-Coding)
هناك طريقتان رئيسيتان يمكنك من خلالهما تطوير تطبيقات الكمبيوتر. قبل الخوض في كيفية تدريب الشبكات العصبية، من المهم التأكد من أن لديك فهمًا للاختلاف بين البرامج الحاسوبية المبرمجة صلبًا (hard-coding) والبرامج المبرمجة مرنًا (soft-coding).
- البرمجة الصلبة (
Hard-coding): تعني أنك تحدد صراحة متغيرات الإدخال ومتغيرات الإخراج المطلوبة. بعبارة أخرى، لا تترك البرمجة الصلبة مجالًا للكمبيوتر لتفسير المشكلة التي تحاول حلها. - البرمجة المرنة (
Soft-coding): هي العكس تمامًا. إنها تترك مجالًا للبرنامج لفهم ما يحدث في مجموعة البيانات. تسمح البرمجة المرنة للكمبيوتر بتطوير أساليب حل المشكلات الخاصة به.
مثال محدد مفيد هنا. إليك مثالان لكيفية تحديد القطط ضمن مجموعة بيانات باستخدام تقنيات البرمجة المرنة والصلبة.
- البرمجة الصلبة: تستخدم معلمات محددة للتنبؤ بما إذا كان الحيوان قطة. وبشكل أكثر تحديدًا، قد تقول إنه إذا كان وزن الحيوان وطوله يقعان ضمن نطاقات معينة، فهو قطة.
- البرمجة المرنة: توفر مجموعة بيانات تحتوي على حيوانات مصنفة بنوعها وخصائص حول تلك الحيوانات. ثم تقوم ببناء برنامج كمبيوتر للتنبؤ بما إذا كان الحيوان قطة أم لا بناءً على الخصائص في مجموعة البيانات.
كما قد تتخيل، يندرج تدريب الشبكات العصبية ضمن فئة البرمجة المرنة (soft-coding). ضع هذا في اعتبارك أثناء متابعة هذه الدورة.
تدريب شبكة عصبية باستخدام دالة التكلفة (Cost Function)
تُدرب الشبكات العصبية باستخدام دالة التكلفة (cost function)، وهي معادلة تُستخدم لقياس الخطأ الموجود في تنبؤ الشبكة. صيغة دالة تكلفة التعلم العميق (وهناك العديد منها – هذا مجرد مثال واحد) هي أدناه:
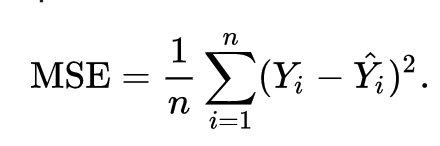
ملاحظة: تُسمى دالة التكلفة هذه متوسط الخطأ التربيعي (mean squared error)، ولهذا السبب يوجد MSE على الجانب الأيسر من علامة التساوي. بينما يوجد الكثير من الرياضيات في هذه المعادلة، يمكن تلخيصها على النحو التالي:
خذ الفرق بين قيمة الإخراج المتوقعة للملاحظة وقيمة الإخراج الفعلية لتلك الملاحظة. ربع هذا الفرق واقسمه على 2.للتأكيد، لاحظ أن هذا مجرد مثال واحد لدالة تكلفة يمكن استخدامها في التعلم الآلي (على الرغم من أنها بالتأكيد الخيار الأكثر شيوعًا). يُعد اختيار دالة التكلفة موضوعًا معقدًا ومثيرًا للاهتمام بحد ذاته، ويقع خارج نطاق هذا البرنامج التعليمي.
كما ذكرنا، الهدف من الشبكة العصبية الاصطناعية هو تقليل قيمة دالة التكلفة. تُقلل دالة التكلفة عندما تكون القيمة المتوقعة لخوارزميتك أقرب ما يمكن إلى القيمة الفعلية. بعبارة أخرى، الهدف من الشبكة العصبية هو تقليل الخطأ الذي ترتكبه في تنبؤاتها!
تعديل الشبكة العصبية
بعد إنشاء شبكة عصبية أولية وإدخال دالة التكلفة الخاصة بها، تُجرى تغييرات على الشبكة العصبية لمعرفة ما إذا كانت تقلل من قيمة دالة التكلفة. وبشكل أكثر تحديدًا، المكون الفعلي للشبكة العصبية الذي يتم تعديله هو أوزان كل خلية عصبية عند مشبكها الذي يتواصل مع الطبقة التالية من الشبكة.
تُسمى الآلية التي تُعدل بها الأوزان لتحريك الشبكة العصبية إلى أوزان ذات خطأ أقل انحدار التدرج (gradient descent). في الوقت الحالي، يكفي أن تفهم أن عملية تدريب الشبكات العصبية تبدو كالتالي:
- تُعين أوزان أولية لقيم الإدخال لكل خلية عصبية.
- تُحسب التنبؤات باستخدام هذه القيم الأولية.
- تُغذى التنبؤات في دالة تكلفة لقياس خطأ الشبكة العصبية.
- تُغير خوارزمية انحدار التدرج الأوزان لقيم إدخال كل خلية عصبية.
- تُستمر هذه العملية حتى تتوقف الأوزان عن التغيير (أو حتى ينخفض مقدار تغييرها في كل تكرار إلى ما دون عتبة محددة).
قد يبدو هذا مجردًا للغاية – وهذا أمر طبيعي! لا تُفهم هذه المفاهيم عادةً بشكل كامل إلا عندما تبدأ في تدريب أولى نماذج التعلم الآلي الخاصة بك.
الخلاصة التقنية
في هذا المقال، استكشفنا بعمق عالم الشبكات العصبية العميقة، من جذورها التاريخية التي وضعها جيفري هينتون إلى آليات عملها المعقدة. لقد رأينا كيف أن الحاجة إلى قوة حوسبة هائلة ومجموعات بيانات ضخمة كانت العقبة الرئيسية التي أخرت انتشار التعلم العميق، وكيف أن توفرها اليوم قد أطلق العنان لإمكاناته الهائلة. فهمنا أن الخلايا العصبية الاصطناعية، المستوحاة من الدماغ البشري، تعمل كوحدات معالجة أساسية، تستقبل المدخلات، تُجري حسابات مرجحة، وتُمرر المخرجات عبر وظائف تنشيط متنوعة مثل Sigmoid و ReLU. الأوزان ودالة التكلفة، جنبًا إلى جنب مع خوارزمية انحدار التدرج، هي جوهر عملية التدريب التي تسمح لهذه الشبكات بالتعلم من البيانات وتحسين دقة تنبؤاتها بشكل مستمر. هذا الفهم الشامل يضع الأساس لأي مهندس أو عالم بيانات طموح يرغب في الغوص في بناء وتطبيق نماذج التعلم العميق لحل تحديات العالم الحقيقي.