دليل المبتدئين إلى هندسة السمات واختيارها في تعلم الآلة
مقدمة: لماذا تُعد البيانات الخام غير كافية؟
يُقال كثيراً إن البيانات هي نفط العصر الحديث، لكن النفط لا يُستخدم بصورته الخام فور استخراجه، بل يمر بمراحل من التنقية والمعالجة حتى يصبح صالحاً للاستخدام. والأمر نفسه ينطبق على البيانات؛ فلا يمكن الاعتماد عليها مباشرة قبل تنظيفها وتحويلها وإعدادها بالشكل المناسب للنماذج التحليلية وخوارزميات Machine Learning.

تكمن الصعوبة الأساسية، خصوصاً لدى المبتدئين في مجالي Machine Learning وData Science، في أن البيانات تأتي من مصادر متعددة وبأنواع مختلفة. لذلك لا توجد طريقة واحدة تصلح لجميع الحالات عند التنظيف أو التحضير. كل نوع من البيانات يحتاج إلى أسلوب مناسب يراعي طبيعته وبنيته والغرض النهائي من استخدامه.

عندما تتقن التعامل مع البيانات، يصبح بإمكانك استخراج رؤى تحليلية ذات قيمة، أو بناء نماذج أكثر كفاءة للتنبؤ والتصنيف. وفي هذا الدليل ستتعرّف إلى الأساسيات التي تحتاجها للبدء بطريقة صحيحة.
ما الذي ستتعلمه في هذا المقال؟
- مفهوم هندسة السمات
Feature Engineeringوأهميتها. - مفهوم اختيار السمات
Feature Selection. - طرق معالجة القيم المفقودة داخل مجموعة البيانات.
- أساليب التعامل مع السمات العددية المستمرة.
- طرق تحويل السمات الفئوية إلى صيغ مناسبة للنماذج.
- أشهر تقنيات اختيار السمات المؤثرة في الأداء.
ما هي هندسة السمات؟
تشير Feature Engineering إلى عملية اختيار المتغيرات وتحويلها أو إنشاء تمثيلات أفضل لها داخل مجموعة البيانات عند بناء نموذج تنبؤي باستخدام تعلم الآلة. بعبارة أبسط، هي المرحلة التي تجعل البيانات الخام أكثر قابلية للفهم من قبل الخوارزميات.
قبل تدريب أي نموذج، تحتاج غالباً إلى استخراج السمات المناسبة من البيانات الأولية. إذا أُهملت هذه الخطوة، فغالباً ستنخفض جودة النتائج، وقد يصبح اكتشاف الأنماط المفيدة أكثر صعوبة.
أهداف هندسة السمات
- تهيئة بيانات الإدخال لتصبح متوافقة مع متطلبات خوارزميات تعلم الآلة.
- تحسين أداء النماذج من حيث الدقة والاستقرار والقدرة على التعميم.
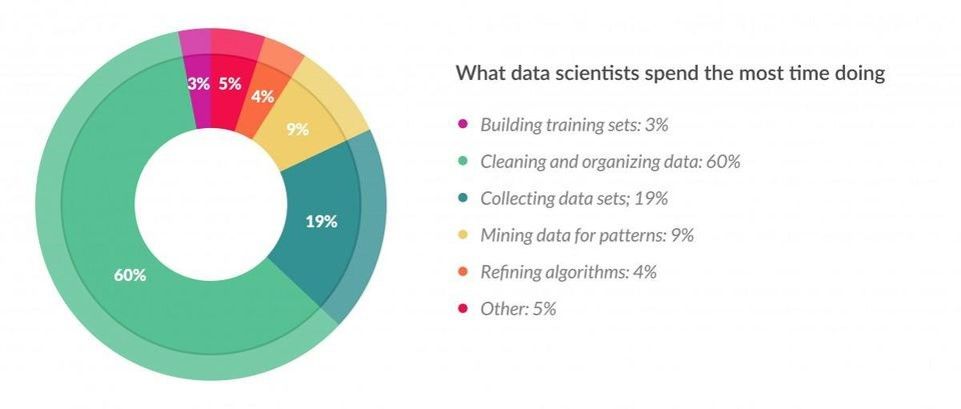
تشير دراسات مهنية عديدة إلى أن جزءاً كبيراً من وقت المختصين في البيانات يُستهلك في تنظيف البيانات وتنظيمها. وهذا يفسّر لماذا تُعد مهارات Feature Engineering وFeature Selection من أهم المهارات العملية في هذا المجال.
كيفية التعامل مع القيم المفقودة
تُعد القيم المفقودة من أكثر مشكلات البيانات شيوعاً، وهي قد تتسبب في أخطاء أثناء التدريب أو في تراجع ملحوظ في أداء بعض الخوارزميات التي لا تتعامل تلقائياً مع الفراغات.
من أمثلة القيم المفقودة التي قد تجدها في البيانات: N/A، null، NaN، none، أو حتى خانات فارغة.
1) حذف المتغيرات ذات الفقد المرتفع
تعتمد هذه الطريقة على حذف الأعمدة التي تحتوي على نسبة مرتفعة جداً من القيم المفقودة، خصوصاً إذا كان العمود قليل الأهمية. وغالباً يكون الحذف منطقياً عندما تتجاوز القيم المفقودة نسبة كبيرة من السجلات.
# import packages
import numpy as np
import pandas as pd
# read dataset
data = pd.read_csv('path/to/data')
#set threshold
threshold = 0.7
# dropping columns with missing value rate higher than threshold
data = data[data.columns[data.isnull().mean() < threshold]]في هذا المثال، تم تحديد العتبة بالقيمة 0.7، ما يعني حذف أي عمود تتجاوز فيه نسبة القيم المفقودة 70%. ومن الأفضل اختيار هذه القيمة بناءً على حجم البيانات وأهمية العمود في التحليل.
2) التعويض بالمتوسط أو الوسيط
تُستخدم هذه الطريقة عادة مع السمات الرقمية. ويتم فيها استبدال القيم المفقودة بمتوسط العمود أو وسيطه. وغالباً يُعد median خياراً جيداً عند وجود قيم شاذة.
# filling missing values with medians of the columns
data = data.fillna(data.median())هذا الأسلوب بسيط وفعّال، لكنه ليس مثالياً في كل الحالات، لأنه قد يقلل من التباين الطبيعي داخل البيانات إذا استُخدم بشكل مفرط.
3) التعويض بالقيمة الأكثر تكراراً
يُعد هذا الخيار مناسباً غالباً للبيانات الفئوية، إذ يتم ملء القيم المفقودة بالقيمة الأكثر ظهوراً داخل العمود.
# filling missing values with the most common value
data['column_name'].fillna(data['column_name'].value_counts().idxmax(), inplace=True)في هذا المثال، تُستخدم الدالة value_counts() لحساب تكرار كل قيمة، ثم تُستخدم idxmax() لاختيار القيمة الأكثر شيوعاً.
كيفية التعامل مع السمات المستمرة
السمات المستمرة هي السمات التي تأخذ نطاقاً واسعاً من القيم العددية، مثل العمر والراتب والسعر والطول. وتحتاج هذه السمات غالباً إلى توحيد أو تحجيم قبل تدريب النموذج.
تكمن المشكلة في أن اختلاف النطاقات بين الأعمدة قد يؤثر في أداء بعض الخوارزميات. على سبيل المثال، إذا كان لدينا عمود age وعمود salary، فستكون قيم الراتب أكبر بكثير من قيم العمر، ما قد يجعل النموذج يمنح وزناً غير متوازن لبعض السمات.

1) التطبيع بطريقة الحد الأدنى والحد الأقصى
تعتمد طريقة Min-Max Normalization على طرح الحد الأدنى من كل قيمة ثم القسمة على المدى الكامل للعمود. والنتيجة النهائية تكون عادة ضمن النطاق بين 0 و1.
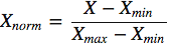
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# 4 samples/observations and 2 variables/features
data = np.array([[4, 6], [11, 34], [10, 17], [1, 5]])
# create scaler method
scaler = MinMaxScaler(feature_range=(0, 1))
# fit and transform the data
scaled_data = scaler.fit_transform(data)
print(scaled_data)
# [[0.3 0.03448276]
# [1. 1. ]
# [0.9 0.4137931 ]
# [0. 0. ]]هذا التحويل مفيد عندما تريد توحيد النطاقات العددية، وخاصة في النماذج التي تتأثر مباشرة بمقياس القيم.
2) التقييس
يهدف Standardization إلى جعل متوسط كل سمة يساوي 0 والانحراف المعياري يساوي 1. وهذا يساعد في جعل السمات على مستوى متقارب من حيث الحجم الإحصائي.

from sklearn.preprocessing import StandardScaler
import numpy as np
# 4 samples/observations and 2 variables/features
data = np.array([[4, 1], [11, 1], [10, 4], [1, 11]])
# create scaler method
scaler = StandardScaler()
# fit and transform the data
scaled_data = scaler.fit_transform(data)
print(scaled_data)
# [[-0.60192927 -0.79558708]
# [ 1.08347268 -0.79558708]
# [ 0.84270097 -0.06119901]
# [-1.32424438 1.65237317]]يمكن التحقق من أن متوسط كل عمود أصبح صفراً تقريباً:
print(scaled_data.mean(axis=0))
# [0. 0.]كما يمكن التحقق من أن الانحراف المعياري أصبح مساوياً تقريباً لـ 1:
print(scaled_data.std(axis=0))
# [1. 1.]كيفية التعامل مع السمات الفئوية
السمات الفئوية هي التي تمثل مجموعات أو تصنيفات، مثل الجنس أو الدولة أو المستوى التعليمي. وبما أن كثيراً من مكتبات تعلم الآلة لا تتعامل مباشرة مع النصوص، فيلزم تحويل هذه القيم إلى تمثيل عددي مناسب.
1) الترميز التصنيفي
تعتمد طريقة Label Encoding على تحويل كل قيمة فئوية إلى رقم. وهي مفيدة في بعض السيناريوهات، لكن يجب استخدامها بحذر لأن الأرقام الناتجة قد توحي بترتيب غير موجود فعلياً بين الفئات.
# import packages
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# intialise data of lists.
data = {
'Gender': ['male', 'female', 'female', 'male', 'male'],
'Country': ['Tanzania', 'Kenya', 'Tanzania', 'Tanzania', 'Kenya']
}
# Create DataFrame
data = pd.DataFrame(data)
# create label encoder object
le = LabelEncoder()
data['Gender'] = le.fit_transform(data['Gender'])
data['Country'] = le.fit_transform(data['Country'])
print(data)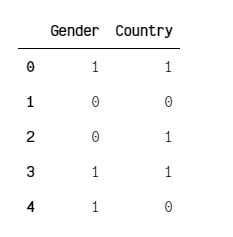
2) الترميز الثنائي الشائع
تُعد طريقة One-Hot Encoding من أكثر الطرق استخداماً في تمثيل المتغيرات الفئوية. وتقوم على إنشاء أعمدة جديدة تمثل كل فئة، بحيث تأخذ القيم 0 أو 1.

# import packages
import numpy as np
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
# define example
data = np.array(['cold', 'cold', 'warm', 'cold', 'hot', 'hot', 'warm', 'cold', 'warm', 'hot'])
# integer encode
label_encoder = LabelEncoder()
# fit and transform the data
integer_encoded = label_encoder.fit_transform(data)
print(integer_encoded)
# one-hot encode
onehot_encoder = OneHotEncoder(sparse=False)
# reshape the data
integer_encoded = integer_encoded.reshape(len(integer_encoded), 1)
# fit and transform the data
onehot_encoded = onehot_encoder.fit_transform(integer_encoded)
print(onehot_encoded)مخرجات LabelEncoder تكون كالتالي:
[0 0 2 0 1 1 2 0 2 1]أما مخرجات OneHotEncoder فتكون كالتالي:
[[1. 0. 0.]
[1. 0. 0.]
[0. 0. 1.]
[1. 0. 0.]
[0. 1. 0.]
[0. 1. 0.]
[0. 0. 1.]
[1. 0. 0.]
[0. 0. 1.]
[0. 1. 0.]]ما هو اختيار السمات؟
يشير Feature Selection إلى عملية اختيار السمات الأكثر تأثيراً في متغير الهدف، سواء تم ذلك يدوياً أو آلياً. والغاية هي تقليل الضوضاء وتحسين جودة النموذج من خلال التركيز على المعلومات الأكثر فائدة.

وجود سمات غير مهمة أو زائدة قد يؤدي إلى انخفاض الدقة وتعقيد النموذج وارتفاع احتمال Overfitting.
لماذا نستخدم اختيار السمات؟
- تسريع عملية تدريب النموذج.
- تقليل التعقيد وتحسين سهولة التفسير.
- رفع الدقة عند اختيار مجموعة مناسبة من السمات.
- تقليل خطر فرط التخصيص
Overfitting.
أشهر طرق اختيار السمات
1) الاختيار الأحادي
تعتمد هذه الطريقة على اختبارات إحصائية لقياس قوة العلاقة بين كل سمة مستقلة ومتغير الهدف. من أشهر هذه الاختبارات اختبار chi-squared للبيانات المناسبة له.
توفر مكتبة Scikit-learn الصنف SelectKBest لاختيار أفضل عدد محدد من السمات.
# Load packages
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
# Load iris data
iris_dataset = load_iris()
# Create features and target
X = iris_dataset.data
y = iris_dataset.target
# Convert to categorical data by converting data to integers
X = X.astype(int)
# Two features with highest chi-squared statistics are selected
chi2_features = SelectKBest(chi2, k=2)
X_kbest_features = chi2_features.fit_transform(X, y)
# Reduced features
print('Original feature number:', X.shape[1])
print('Reduced feature number:', X_kbest_features.shape[1])
# Original feature number: 4
# Reduced feature number: 2يُظهر المثال أن الاختبار الإحصائي ساعد في تقليص عدد السمات من 4 إلى 2 فقط، مع الاحتفاظ بالأكثر ارتباطاً بمتغير الهدف.
2) أهمية السمات
تعطي طريقة Feature Importance درجة لكل سمة بحسب تأثيرها في التنبؤ. وكلما ارتفعت الدرجة، زادت أهمية السمة بالنسبة للمخرجات.
تتوفر هذه الإمكانية في كثير من النماذج الشجرية، مثل Random Forest وExtra Trees.
# Load libraries
from sklearn.datasets import load_iris
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import ExtraTreesClassifier
# Load iris data
iris_dataset = load_iris()
# Create features and target
X = iris_dataset.data
y = iris_dataset.target
# Convert to categorical data by converting data to integers
X = X.astype(int)
# Building the model
extra_tree_forest = ExtraTreesClassifier(
n_estimators=5,
criterion='entropy',
max_features=2
)
# Training the model
extra_tree_forest.fit(X, y)
# Computing the importance of each feature
feature_importance = extra_tree_forest.feature_importances_
# Normalizing the individual importances
feature_importance_normalized = np.std(
[tree.feature_importances_ for tree in extra_tree_forest.estimators_],
axis=0
)
# Plotting a Bar Graph to compare the models
plt.bar(iris_dataset.feature_names, feature_importance_normalized)
plt.xlabel('Feature Labels')
plt.ylabel('Feature Importances')
plt.title('Comparison of different Feature Importances')
plt.show()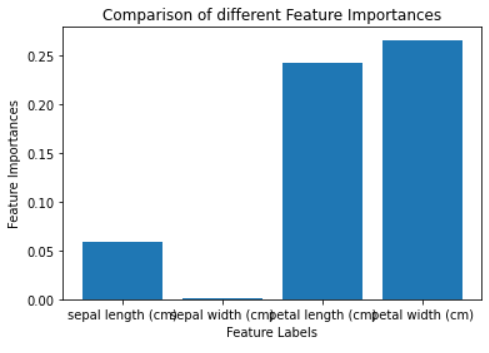
في هذا النوع من التحليل، يمكنك بسهولة ملاحظة السمات الأقوى تأثيراً، ثم التركيز عليها عند بناء النموذج لتحسين الأداء وتبسيط المعالجة.
3) خريطة الارتباط الحرارية
يكشف الارتباط Correlation عن العلاقة بين السمات بعضها مع بعض، أو بينها وبين متغير الهدف. وقد تكون العلاقة موجبة أو سالبة.
إذا كانت سمتان مترابطتين بشدة، فغالباً تحملان معلومات متشابهة، وقد يكون من الأفضل حذف إحداهما لتقليل التكرار.
# Load libraries
from sklearn.datasets import load_boston
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# load boston data
boston_dataset = load_boston()
# create a dataframe for boston data
boston = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names)
# ploting the heatmap for correlation
ax = sns.heatmap(boston.corr().round(2), annot=True)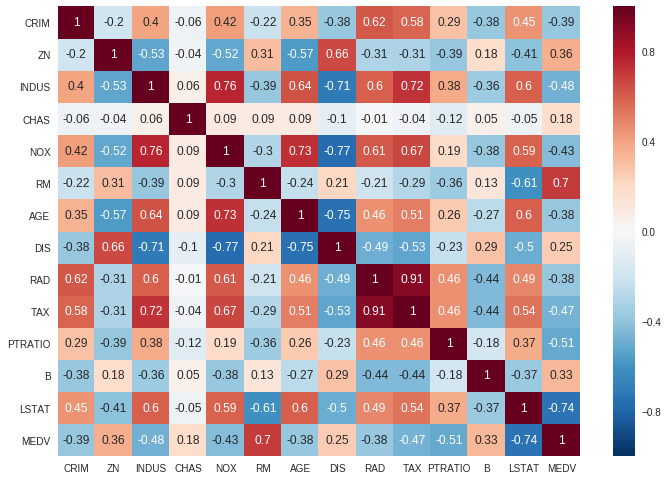
تتراوح قيمة معامل الارتباط بين -1 و1. وعندما تقترب القيمة من 1، فهذا يعني وجود ارتباط موجب قوي، وعندما تقترب من -1، فهذا يشير إلى ارتباط سالب قوي.
أفضل ممارسات عملية للمبتدئين
- ابدأ دائماً بفحص القيم المفقودة قبل أي خطوة أخرى.
- اختر أسلوب التحجيم المناسب بناءً على طبيعة النموذج.
- لا تستخدم
Label Encodingعشوائياً مع جميع المتغيرات الفئوية. - اختبر أكثر من طريقة في اختيار السمات وقارن النتائج.
- لا تُفرط في حذف الأعمدة قبل فهم قيمتها التحليلية.
- قسّم البيانات إلى تدريب واختبار قبل تنفيذ بعض التحويلات الحساسة لتجنب تسرب البيانات
Data Leakage.
خاتمة
الأساليب المذكورة في هذا الدليل تساعدك على تجهيز معظم مجموعات البيانات المنظمة Structured Data للاستخدام في مشاريع تعلم الآلة. لكن إذا كنت تتعامل مع بيانات غير منظمة مثل الصور أو النصوص أو الصوت، فستحتاج إلى تقنيات أخرى متخصصة في المعالجة المسبقة.
النجاح في بناء نموذج جيد لا يعتمد فقط على اختيار الخوارزمية، بل يعتمد بدرجة كبيرة على جودة إعداد البيانات والسمات المستخدمة. وكلما كانت السمات أنظف وأكثر تعبيراً عن المشكلة، تحسنت فرص الوصول إلى نموذج قوي وموثوق.
الخلاصة التقنية
من الناحية العملية، تمثل Feature Engineering وFeature Selection العمود الفقري لأي مشروع ناجح في Machine Learning. فمعالجة القيم المفقودة، وتوحيد السمات المستمرة، وتحويل السمات الفئوية، ثم اختيار الأكثر تأثيراً، كلها خطوات تصنع الفارق الحقيقي بين نموذج متوسط وآخر فعّال. إذا أردت تحسين الأداء بسرعة وبشكل منهجي، فابدأ دائماً من جودة السمات قبل التفكير في تعقيد النموذج.