دليل مرئي لآلية عمل Git الداخلية: الكائنات، الفروع، وإنشاء مستودع من الصفر

مقدمة إلى عالم Git الخفي: ما يحدث تحت الغطاء
يستخدم الكثير منا أداة Git بشكل يومي لإدارة مشاريعنا البرمجية. لكن كم منا يدرك حقًا ما يدور خلف الكواليس عند تنفيذ الأوامر المألوفة؟ على سبيل المثال، ماذا يحدث بالضبط عند استخدام git commit؟ ما الذي يتم تخزينه بين عمليات الالتزام؟ هل هو مجرد فرق (diff) بين الالتزام الحالي والسابق؟ إذا كان الأمر كذلك، فكيف يتم ترميز هذا الفرق؟ أم يتم تخزين لقطة كاملة للمستودع في كل مرة؟ وماذا يحدث حقًا عندما نستخدم git init؟
قد لا يعرف العديد من مستخدمي Git إجابات هذه الأسئلة. ولكن هل يهم ذلك حقًا؟ كمتخصصين، يجب أن نسعى جاهدين لفهم الأدوات التي نستخدمها، خاصة إذا كنا نعتمد عليها باستمرار مثل Git. الأهم من ذلك، لقد وجدت أن فهم كيفية عمل Git فعليًا مفيد في العديد من السيناريوهات، سواء كان ذلك لحل تعارضات الدمج (merge conflicts)، أو إجراء عملية إعادة قاعدة (rebase) معقدة، أو حتى عندما تسير الأمور بشكل خاطئ قليلًا.
ستستفيد من هذا المقال إذا كنت تتمتع بخبرة كافية مع Git وتشعر بالراحة عند استخدام أوامر مثل git pull، git push، git add، أو git commit. ومع ذلك، سنبدأ بنظرة عامة للتأكد من أننا على دراية بآليات Git، وتحديدًا المصطلحات المستخدمة في هذا المقال.
ماذا تتوقع من هذا الدليل؟
سنكتسب فهمًا نادرًا لما يحدث تحت غطاء ما نفعله يوميًا تقريبًا. سنبدأ بتغطية الكائنات الأساسية في Git: blobs، trees، وcommits. ثم سنناقش بإيجاز الفروع وكيفية تنفيذها. سنتعمق في دليل العمل (working directory)، ومنطقة التخزين المؤقت (staging area)، والمستودع (repository). وسنتأكد من فهمنا لكيفية ارتباط هذه المصطلحات بأوامر Git التي نعرفها ونستخدمها لإنشاء مستودع جديد.
بعد ذلك، سنقوم بإنشاء مستودع من الصفر – دون استخدام أوامر git init، git add، أو git commit. سيتيح لنا ذلك تعميق فهمنا لما يحدث تحت الغطاء عند العمل مع Git. سنقوم أيضًا بإنشاء فروع جديدة، والتبديل بينها، وإنشاء التزامات إضافية – كل ذلك دون استخدام git branch أو git checkout. بحلول نهاية هذا المقال، ستشعر أنك تدرك تمامًا جوهر Git.
كائنات Git الأساسية: Blob، Tree، و Commit
من المفيد جدًا التفكير في Git كنظام يحافظ على نظام ملفات، وتحديدًا – لقطات (snapshots) لهذا النظام عبر الزمن. يبدأ نظام الملفات بدليل جذري (في أنظمة UNIX، /)، والذي يحتوي عادةً على أدلة أخرى (على سبيل المثال، /usr أو /bin). تحتوي هذه الأدلة على أدلة أخرى، و/أو ملفات (على سبيل المثال، /usr/1.txt).
Blob: محتوى الملفات الخام
في Git، يتم تخزين محتويات الملفات في كائنات تسمى blobs (اختصار لـ binary large objects). الفرق بين blobs والملفات هو أن الملفات تحتوي أيضًا على بيانات وصفية (meta-data). على سبيل المثال، يتذكر الملف متى تم إنشاؤه، لذلك إذا نقلت هذا الملف إلى دليل آخر، يظل وقت إنشائه كما هو. أما blobs، فهي مجرد محتويات – تدفقات بيانات ثنائية. لا يسجل blob تاريخ إنشائه، اسمه، أو أي شيء سوى محتوياته. يتم تعريف كل blob في Git بواسطة تجزئة SHA-1 الخاصة به. تتكون تجزئات SHA-1 من 20 بايت، وعادة ما يتم تمثيلها بـ 40 حرفًا في شكل سداسي عشري. في هذا المقال، سنعرض أحيانًا الأحرف الأولى فقط من هذه التجزئة.

Tree: تمثيل الأدلة
في Git، ما يعادل الدليل هو tree (شجرة). tree هي في الأساس قائمة دليل، تشير إلى blobs وكذلك إلى trees أخرى. يتم تعريف trees بواسطة تجزئات SHA-1 الخاصة بها أيضًا. تتم الإشارة إلى هذه الكائنات، سواء كانت blobs أو trees أخرى، عبر تجزئة SHA-1 للكائنات.

لاحظ أن الـ tree CAFE7 يشير إلى الـ blob F92A0 باسم pic.png. في tree آخر، قد يحمل نفس الـ blob اسمًا آخر.

الرسم البياني أعلاه يعادل نظام ملفات بدليل جذري يحتوي على ملف واحد في /test.js، ودليل باسم /docs يحتوي على ملفين: /docs/pic.png و /docs/1.txt.
Commit: لقطة زمنية للمستودع
حان الوقت الآن لالتقاط لقطة لنظام الملفات هذا – وتخزين جميع الملفات التي كانت موجودة في ذلك الوقت، جنبًا إلى جنب مع محتوياتها. في Git، اللقطة هي commit (التزام). يتضمن كائن الـ commit مؤشرًا إلى الـ tree الرئيسي (الدليل الجذري)، بالإضافة إلى بيانات وصفية أخرى مثل الملتزم (committer)، رسالة الالتزام (commit message)، ووقت الالتزام (commit time). في معظم الحالات، يحتوي الـ commit أيضًا على التزام أب واحد أو أكثر – اللقطة (اللقطات) السابقة. بالطبع، يتم تعريف كائنات الـ commit أيضًا بواسطة تجزئات SHA-1 الخاصة بها. هذه هي التجزئات التي اعتدنا رؤيتها عند استخدام git log.

كل commit يحتفظ باللقطة الكاملة، وليس مجرد فروقات (diffs) عن الـ commit(s) السابق. كيف يمكن لذلك أن يعمل؟ ألا يعني ذلك أننا يجب أن نخزن الكثير من البيانات في كل commit؟
دعنا نفحص ما يحدث إذا غيرنا محتويات ملف. لنفترض أننا قمنا بتعديل 1.txt، وأضفنا علامة تعجب – أي أننا غيرنا المحتوى من HELLO WORLD إلى HELLO WORLD!. حسنًا، هذا التغيير يعني أن لدينا blob جديدًا، بتجزئة SHA-1 جديدة. هذا منطقي، حيث أن sha1("HELLO WORLD") يختلف عن sha1("HELLO WORLD!").

بما أن لدينا تجزئة جديدة، فيجب أن تتغير قائمة الـ tree أيضًا. ففي النهاية، لم يعد الـ tree الخاص بنا يشير إلى الـ blob 73D8A، بل يشير إلى الـ blob 62E7A بدلاً من ذلك. ومع تغيير محتويات الـ tree، فإننا نغير تجزئته أيضًا.

والآن، بما أن تجزئة هذا الـ tree مختلفة، نحتاج أيضًا إلى تغيير الـ tree الأب – حيث لم يعد الأخير يشير إلى الـ tree CAFE7، بل إلى الـ tree 24601. وبالتالي، سيكون للـ tree الأب أيضًا تجزئة جديدة.

نحن على وشك إنشاء كائن commit جديد، ويبدو أننا سنخزن الكثير من البيانات – نظام الملفات بأكمله، مرة أخرى! ولكن هل هذا ضروري حقًا؟ في الواقع، بعض الكائنات، وتحديداً كائنات blob، لم تتغير منذ الـ commit السابق – ظل الـ blob F92A0 سليمًا، وكذلك الـ blob F00D1. إذن هذه هي الحيلة – طالما أن الكائن لا يتغير، فإننا لا نخزنه مرة أخرى. في هذه الحالة، لا نحتاج إلى تخزين الـ blob F92A0 والـ blob F00D1 مرة أخرى. نحن فقط نشير إليهما بقيم التجزئة الخاصة بهما. يمكننا بعد ذلك إنشاء كائن الـ commit الخاص بنا.
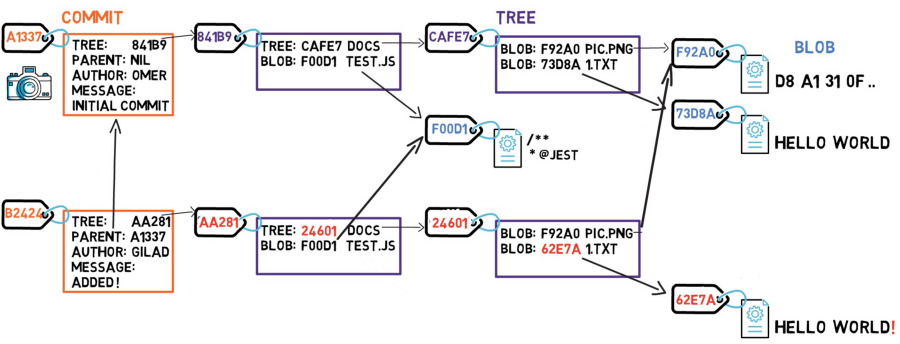
بما أن هذا الـ commit ليس الـ commit الأول، فله أب – الـ commit A1337. لتلخيص ما سبق، قدمنا ثلاثة كائنات Git:
blob: محتويات ملف.tree: قائمة دليل (منblobsوtrees).commit: لقطة لدليل العمل.
دعونا نتأمل تجزئات هذه الكائنات قليلاً. لنفترض أنني كتبت السلسلة النصية git is awesome! وأنشأت منها blob. لقد فعلت أنت الشيء نفسه على نظامك. هل سنحصل على نفس التجزئة؟ الإجابة هي – نعم. بما أن الـ blobs تتكون من نفس البيانات، فسيكون لها نفس قيم SHA-1.
ماذا لو أنشأت tree يشير إلى الـ blob الخاص بـ git is awesome!، وأعطيته اسمًا محددًا وبيانات وصفية، وفعلت أنت الشيء نفسه تمامًا على نظامك. هل سنحصل على نفس التجزئة؟ مرة أخرى، نعم. بما أن كائنات الـ trees هي نفسها، فسيكون لها نفس التجزئة.
ماذا لو أنشأت commit لهذا الـ tree برسالة الالتزام Hello، وفعلت أنت الشيء نفسه على نظامك. هل سنحصل على نفس التجزئة؟ في هذه الحالة، الإجابة هي – لا. على الرغم من أن كائنات الـ commit الخاصة بنا تشير إلى نفس الـ tree، إلا أنها تحتوي على تفاصيل التزام مختلفة – الوقت، الملتزم، إلخ.
الفروع في Git: آلية العمل والتطبيق
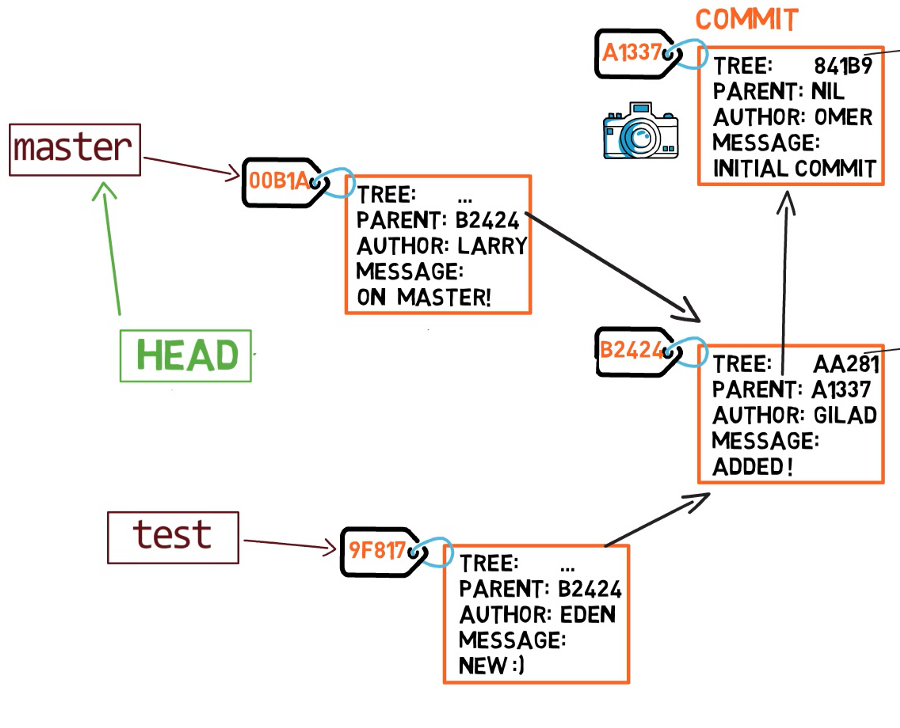
الفرع (branch) هو مجرد مرجع مسمى إلى commit. يمكننا دائمًا الإشارة إلى commit بواسطة تجزئة SHA-1 الخاصة به، لكن البشر يفضلون عادةً أشكالًا أخرى لتسمية الكائنات. الفرع هو إحدى طرق الإشارة إلى commit، ولكنه في الحقيقة ليس أكثر من ذلك.
في معظم المستودعات، يتم خط التطوير الرئيسي في فرع يسمى master (أو main). هذا مجرد اسم، ويتم إنشاؤه عندما نستخدم git init، مما يجعله شائع الاستخدام. ومع ذلك، فهو ليس مميزًا بأي حال من الأحوال، ويمكننا استخدام أي اسم آخر نرغب فيه. عادةً، يشير الفرع إلى أحدث commit في خط التطوير الذي نعمل عليه حاليًا.
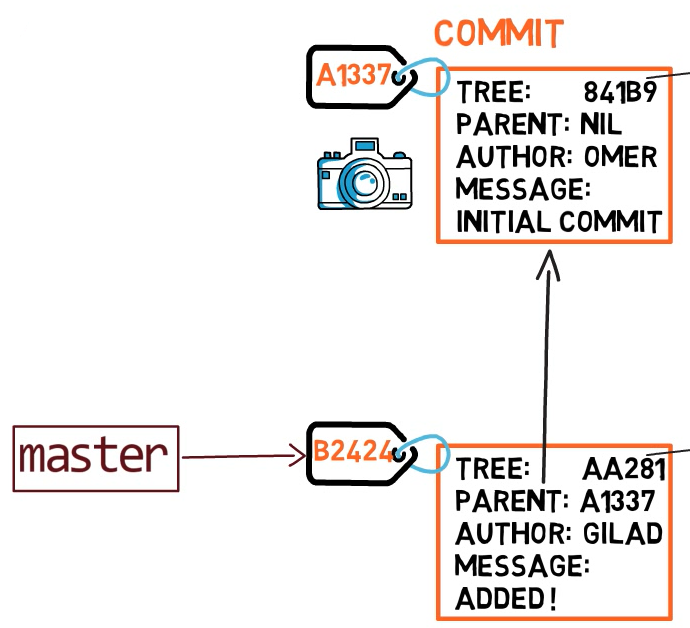
إنشاء الفروع والتبديل بينها
لإنشاء فرع آخر، نستخدم عادةً الأمر git branch. بفعل ذلك، فإننا في الواقع ننشئ مؤشرًا آخر. لذا إذا أنشأنا فرعًا يسمى test، باستخدام git branch test، فإننا في الواقع ننشئ مؤشرًا آخر يشير إلى نفس الـ commit الذي يشير إليه الفرع الذي نحن عليه حاليًا.
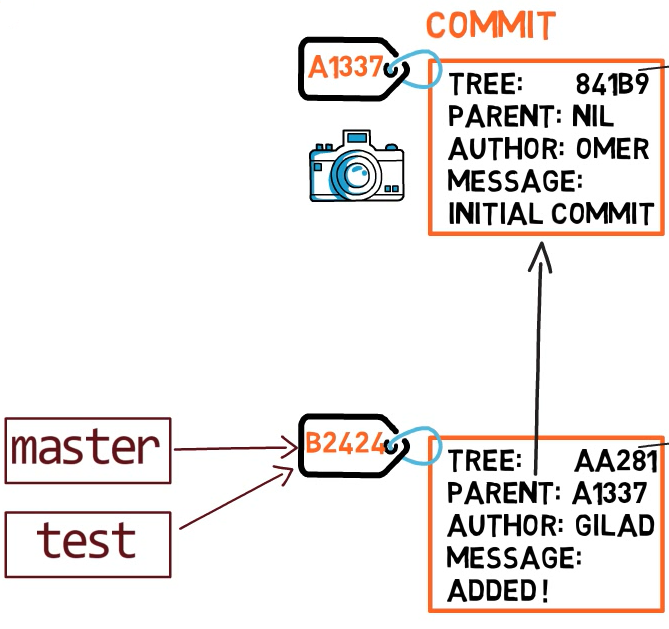
كيف يعرف Git الفرع الذي نحن عليه حاليًا؟ يحتفظ بمؤشر خاص يسمى HEAD. عادةً، يشير HEAD إلى فرع، والذي بدوره يشير إلى commit. في بعض الحالات، يمكن أن يشير HEAD أيضًا إلى commit مباشرةً، لكننا لن نركز على ذلك.

للتبديل إلى الفرع النشط ليكون test، يمكننا استخدام الأمر git checkout test. الآن يمكننا بالفعل تخمين ما يفعله هذا الأمر في الواقع – إنه يغير ببساطة HEAD ليشير إلى test.

يمكننا أيضًا استخدام git checkout -b test قبل إنشاء فرع test، وهو ما يعادل تشغيل git branch test لإنشاء الفرع، ثم git checkout test لنقل HEAD ليشير إلى الفرع الجديد.
ماذا يحدث إذا أجرينا بعض التغييرات وأنشأنا commit جديدًا باستخدام git commit؟ إلى أي فرع سيتم إضافة الـ commit الجديد؟ الإجابة هي فرع test، لأنه الفرع النشط (بما أن HEAD يشير إليه). بعد ذلك، سينتقل مؤشر test إلى الـ commit المضاف حديثًا. لاحظ أن HEAD لا يزال يشير إلى test.
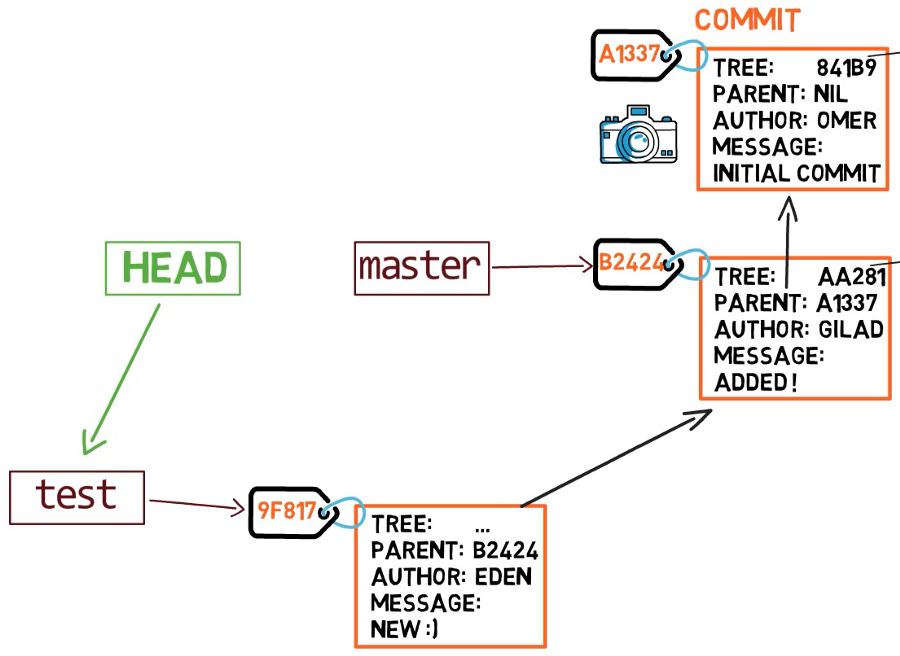
في كل مرة نستخدم فيها git commit، ينتقل مؤشر الفرع إلى الـ commit الذي تم إنشاؤه حديثًا. لذا إذا عدنا إلى master باستخدام git checkout master، فإننا ننقل HEAD ليشير إلى master مرة أخرى.

الآن، إذا أنشأنا commit آخر، فسيتم إضافته إلى فرع master (وسيكون أبوه هو الـ commit B2424).
تسجيل التغييرات في Git: دليل العمل ومنطقة التخزين المؤقت والمستودع
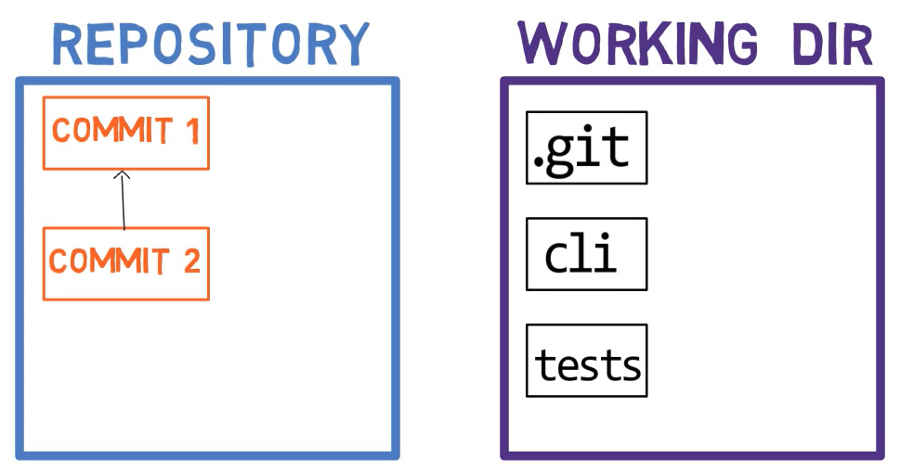
عادةً، عندما نعمل على الشيفرة المصدرية الخاصة بنا، فإننا نعمل من دليل عمل (working directory). دليل العمل (أو working tree) هو أي دليل في نظام الملفات الخاص بنا مرتبط به مستودع. يحتوي على المجلدات والملفات الخاصة بمشروعنا، وأيضًا دليل يسمى .git سنتحدث عنه لاحقًا.
بعد إجراء بعض التغييرات، نرغب في تسجيلها في مستودعنا (repository). المستودع (باختصار: repo) هو مجموعة من الالتزامات (commits)، كل منها أرشيف لما كان يبدو عليه working tree للمشروع في تاريخ سابق، سواء على جهازنا أو جهاز شخص آخر. يتضمن المستودع أيضًا أشياء أخرى غير ملفات الشيفرة الخاصة بنا، مثل HEAD، والفروع، وما إلى ذلك.
منطقة التخزين المؤقت (Staging Area) أو الفهرس (Index)
على عكس الأدوات المماثلة الأخرى التي قد تكون استخدمتها، لا يقوم Git بـ commit التغييرات من working tree مباشرة إلى repository. بدلاً من ذلك، يتم تسجيل التغييرات أولاً في شيء يسمى index، أو staging area. يشير كلا المصطلحين إلى نفس الشيء، ويستخدمان غالبًا في وثائق Git. سنستخدم هذه المصطلحات بالتبادل في هذا المقال.
عندما نقوم بـ checkout لفرع، يقوم Git بملء الـ index بجميع محتويات الملفات التي تم checkout لها آخر مرة في working directory الخاص بنا وكيف كانت تبدو عند checkout الأصلي. عندما نستخدم git commit، يتم إنشاء الـ commit بناءً على حالة الـ index. يتيح لنا استخدام الـ index إعداد كل commit بعناية. على سبيل المثال، قد يكون لدينا ملفان بهما تغييرات منذ آخر commit في working directory الخاص بنا. قد نضيف أحدهما فقط إلى الـ index (باستخدام git add)، ثم نستخدم git commit لتسجيل هذا التغيير فقط.

يمكن أن تكون الملفات في working directory الخاص بنا في إحدى حالتين: tracked (متعقبة) أو untracked (غير متعقبة). الملفات المتعقبة هي الملفات التي يعرفها Git. إما أنها كانت في اللقطة الأخيرة (commit)، أو أنها الآن في مرحلة التخزين المؤقت (staged) (أي أنها في staging area). الملفات غير المتعقبة هي كل شيء آخر – أي ملفات في working directory الخاص بنا لم تكن في لقطتنا الأخيرة (commit) وليست في staging area.
إنشاء مستودع Git بالطريقة التقليدية
دعنا نتأكد من أننا نفهم كيف ترتبط المصطلحات التي قدمناها بعملية إنشاء مستودع. هذه مجرد نظرة عامة سريعة وعالية المستوى، قبل أن نتعمق أكثر في هذه العملية.
ملاحظة: معظم المقالات التي تحتوي على أوامر shell تعرض أوامر UNIX. سأقدم أوامر لكل من Windows و UNIX، مع لقطات شاشة من Windows، من أجل التنوع. عندما تكون الأوامر متطابقة تمامًا، سأقدمها مرة واحدة فقط.
تهيئة المستودع وإضافة الملفات
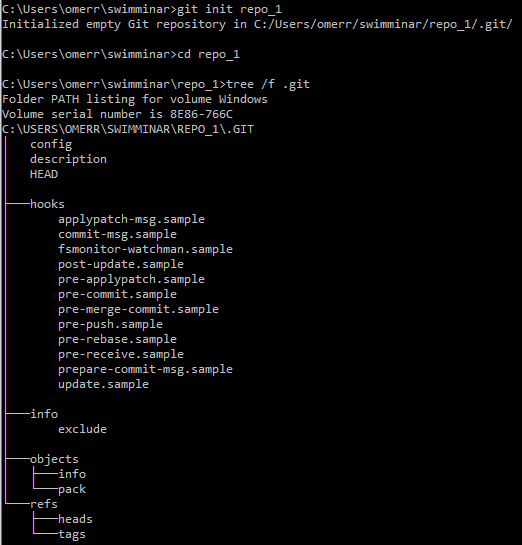
سنقوم بتهيئة مستودع جديد باستخدام git init repo_1، ثم نغير دليلنا إلى دليل المستودع باستخدام cd repo_1. باستخدام tree /f .git يمكننا أن نرى أن تشغيل git init أدى إلى عدد لا بأس به من الأدلة الفرعية داخل .git. (العلامة /f تتضمن الملفات في مخرجات tree).
لنقم بإنشاء ملف داخل دليل repo_1:

على نظام Linux:
$ echo "Initial content" > new_file.txt
هذا الملف موجود ضمن working directory الخاص بنا. ومع ذلك، بما أننا لم نضفه إلى staging area، فهو حاليًا untracked. دعنا نتحقق باستخدام git status:

يمكننا الآن إضافة هذا الملف إلى staging area باستخدام git add new_file.txt. يمكننا التحقق من أنه تم تخزينه مؤقتًا عن طريق تشغيل git status:
$ git add new_file.txt
يمكننا الآن إنشاء commit باستخدام git commit:
$ git commit -m "First commit"
هل تغير شيء داخل دليل .git؟ دعنا نشغل tree /f .git للتحقق:

على ما يبدو، تغير الكثير. حان الوقت للتعمق أكثر في بنية .git وفهم ما يحدث تحت الغطاء عندما نشغل git init، git add، أو git commit.
الغوص العميق: بناء مستودع Git من الصفر
حتى الآن، غطينا بعض أساسيات Git، والآن نحن مستعدون للتعمق حقًا. من أجل فهم عميق لكيفية عمل Git، سنقوم بإنشاء مستودع، ولكن هذه المرة – سنبنيه من الصفر. لن نستخدم أوامر git init، git add، أو git commit مما سيمكننا من الحصول على فهم عملي أفضل للعملية.
إعداد بنية مجلد .git
لنقم بإنشاء دليل جديد، ونشغل git status بداخله:

حسنًا، يبدو أن Git غير راضٍ لأننا لا نملك مجلد .git. الشيء الطبيعي الذي يجب فعله هو ببساطة إنشاء هذا الدليل:
mkdir .git
على ما يبدو، إنشاء دليل .git ليس كافيًا. نحتاج إلى إضافة بعض المحتوى إلى هذا الدليل. يحتوي مستودع Git على مكونين رئيسيين:
- مجموعة من الكائنات –
blobs،trees، وcommits. - نظام لتسمية تلك الكائنات – يسمى المراجع (
references).
قد يحتوي المستودع أيضًا على أشياء أخرى، مثل خطاطيف Git (git hooks)، ولكن على الأقل – يجب أن يتضمن الكائنات والمراجع. لنقم بإنشاء دليل للكائنات في .git\objects ودليل للمراجع (باختصار: refs) في .git\refs (على أنظمة UNIX – .git/objects و .git/refs، على التوالي).
mkdir .git\objects
mkdir .git\refs
أحد أنواع المراجع هو الفروع (branches). داخليًا، يسمي Git الفروع بـ heads. لذا سنقوم بإنشاء دليل لها – .git\refs\heads.
mkdir .git\refs\heads
هذا لا يزال لا يغير git status الخاص بنا:

كيف يعرف Git من أين يبدأ عند البحث عن commit في المستودع؟ كما أوضحت سابقًا، يبحث عن HEAD، الذي يشير إلى الفرع النشط الحالي (أو commit، في بعض الحالات). لذا، نحتاج إلى إنشاء HEAD، وهو مجرد ملف موجود في .git\HEAD. يمكننا تطبيق ما يلي:
على Windows:
> echo ref: refs/heads/master > .git\HEADعلى UNIX:
$ echo "ref: refs/heads/master" > .git/HEAD⭐ لذا نحن نعرف الآن كيف يتم تنفيذ HEAD – إنه ببساطة ملف، ومحتوياته تصف ما يشير إليه. بعد الأمر أعلاه، يبدو أن git status يغير رأيه:

لاحظ أن Git يعتقد أننا على فرع يسمى master، على الرغم من أننا لم ننشئ هذا الفرع. كما ذكرنا سابقًا، master هو مجرد اسم. يمكننا أيضًا أن نجعل Git يعتقد أننا على فرع يسمى banana إذا أردنا:
> echo ref: refs/heads/banana > .git\HEAD
🍌 سنعود إلى master لبقية هذا المقال، فقط للالتزام بالاتفاقية العادية. الآن بعد أن أصبح دليل .git جاهزًا، هل يمكننا العمل على إنشاء commit (مرة أخرى، دون استخدام git add أو git commit)؟
أوامر Git: الفروقات بين “Plumbing” و “Porcelain”
في هذه المرحلة، سيكون من المفيد التمييز بين نوعين من أوامر Git: plumbing و porcelain. يأتي تطبيق المصطلحين بشكل غريب من الحمامات (نعم، هذه – 🚽)، المصنوعة تقليديًا من البورسلين، والبنية التحتية للسباكة (plumbing) (الأنابيب والمصارف). يمكننا القول إن طبقة porcelain توفر واجهة سهلة الاستخدام لـ plumbing. معظم الناس يتعاملون فقط مع porcelain. ومع ذلك، عندما تسوء الأمور (بشكل فظيع)، ويرغب شخص ما في فهم السبب، فسيتعين عليه أن يشمر عن سواعده للتحقق من plumbing. (ملاحظة: هذه المصطلحات ليست لي، بل تستخدم على نطاق واسع في Git).
Git يستخدم هذه المصطلحات كتشبيه للفصل بين الأوامر منخفضة المستوى التي لا يحتاج المستخدمون عادةً إلى استخدامها مباشرةً (“أوامر plumbing“) عن الأوامر عالية المستوى الأكثر سهولة في الاستخدام (“أوامر porcelain“). حتى الآن، تعاملنا مع أوامر porcelain – git init، git add، أو git commit. بعد ذلك، ننتقل إلى أوامر plumbing.
إنشاء كائنات Git باستخدام أوامر “Plumbing”
لنبدأ بإنشاء كائن وكتابته في قاعدة بيانات الكائنات الخاصة بـ Git، والتي توجد داخل .git\objects. سنجد قيمة تجزئة SHA-1 لـ blob باستخدام أول أمر plumbing لدينا، git hash-object، بالطريقة التالية:
على Windows:
> echo git is awesome | git hash-object --stdin -wعلى UNIX:
$ echo "git is awesome" | git hash-object --stdin -wباستخدام --stdin، فإننا نوجه git hash-object لأخذ مدخلاته من المدخل القياسي. سيوفر لنا هذا قيمة التجزئة ذات الصلة. لكي نكتب هذا الـ blob بالفعل في قاعدة بيانات كائنات Git، يمكننا ببساطة إضافة المفتاح -w لـ git hash-object. ثم، يمكننا التحقق من محتويات مجلد .git، ونرى أنها قد تغيرت.

يمكننا الآن أن نرى أن تجزئة الـ blob الخاص بنا هي – 54f6...36. يمكننا أيضًا أن نرى أنه تم إنشاء دليل تحت .git\objects، دليل باسم 54، وداخله ملف باسم f6...36. لذا فإن Git يأخذ بالفعل أول حرفين من تجزئة SHA-1 ويستخدمهما كاسم للدليل. تستخدم الأحرف المتبقية كاسم للملف الذي يحتوي بالفعل على الـ blob. لماذا هذا؟
تخيل مستودعًا كبيرًا جدًا، يحتوي على 300,000 كائن (blobs، trees، و commits) في قاعدة بياناته. قد يستغرق البحث عن تجزئة داخل تلك القائمة التي تضم 300,000 تجزئة بعض الوقت. وبالتالي، يقوم Git ببساطة بتقسيم هذه المشكلة على 256. للبحث عن التجزئة أعلاه، سيبحث Git أولاً عن الدليل المسمى 54 داخل الدليل .git\objects، والذي قد يحتوي على ما يصل إلى 256 دليلًا (00 إلى FF). ثم سيبحث في هذا الدليل، ويضيق نطاق البحث كلما تقدم.
العودة إلى عملية إنشاء commit. لقد أنشأنا الآن كائنًا. ما هو نوع هذا الكائن؟ يمكننا استخدام أمر plumbing آخر، git cat-file -t (-t تعني “type”)، للتحقق من ذلك:
$ git cat-file -t 54f6...36
ليس من المستغرب، هذا الكائن هو blob. يمكننا أيضًا استخدام git cat-file -p (-p تعني “pretty-print”) لرؤية محتوياته:
$ git cat-file -p 54f6...36
تحدث عملية إنشاء blob هذه عادةً عندما نضيف شيئًا إلى staging area – أي عندما نستخدم git add. تذكر أن Git ينشئ blob للملف بأكمله الذي يتم تخزينه مؤقتًا. حتى إذا تم تعديل حرف واحد أو إضافته (كما أضفنا ! في مثالنا السابق)، فإن الملف يحتوي على blob جديد بتجزئة جديدة.
هل سيكون هناك أي تغيير في git status؟

على ما يبدو، لا. إضافة كائن blob إلى قاعدة بيانات Git الداخلية لا يغير الحالة، حيث لا يعرف Git أي ملفات متعقبة أو غير متعقبة في هذه المرحلة. نحتاج إلى تعقب هذا الملف – إضافته إلى staging area. للقيام بذلك، يمكننا استخدام أمر plumbing git update-index، على النحو التالي:
$ git update-index --add --cacheinfo 100644 <blob-hash> my_file.txtملاحظة: (cacheinfo هو وضع ملف 16 بت كما يخزنه Git، باتباع تخطيط أنواع وأوضاع POSIX. هذا ليس ضمن نطاق هذا المقال).
سيؤدي تشغيل الأمر أعلاه إلى تغيير في محتويات .git:

هل يمكنك ملاحظة التغيير؟ تم إنشاء ملف جديد باسم index. هذا هو – الـ index الشهير (أو staging area)، هو في الأساس ملف موجود داخل .git\index. الآن بعد أن تم إضافة الـ blob الخاص بنا إلى الـ index، نتوقع أن يبدو git status مختلفًا، هكذا:

هذا مثير للاهتمام! حدث شيئان هنا. أولاً، يمكننا أن نرى أن new_file.txt يظهر باللون الأخضر، في منطقة Changes to be committed. هذا لأن الـ index يحتوي الآن على new_file.txt، في انتظار الالتزام. ثانيًا، يمكننا أن نرى أن new_file.txt يظهر باللون الأحمر – لأن Git يعتقد أن الملف my_file.txt قد تم حذفه، وحقيقة أن الملف قد تم حذفه ليست في مرحلة التخزين المؤقت. يحدث هذا لأننا أضفنا الـ blob بمحتويات git is awesome إلى قاعدة بيانات الكائنات، وأخبرنا الـ index أن الملف my_file.txt يحتوي على محتويات هذا الـ blob، لكننا لم نقم بإنشاء هذا الملف فعليًا.
يمكننا حل هذا بسهولة عن طريق أخذ محتويات الـ blob، وكتابتها في نظام الملفات الخاص بنا، إلى ملف يسمى my_file.txt:
$ git cat-file -p <blob-hash> > my_file.txt
نتيجة لذلك، لن يظهر باللون الأحمر بواسطة git status:
حان الوقت الآن لإنشاء كائن commit من staging area الخاص بنا. كما هو موضح أعلاه، يحتوي كائن الـ commit على مرجع إلى tree، لذلك نحتاج إلى إنشاء tree. يمكننا القيام بذلك باستخدام الأمر git write-tree، الذي يسجل محتويات الـ index في كائن tree. بالطبع، يمكننا استخدام git cat-file -t لنرى أنه بالفعل tree:
$ git write-tree
$ git cat-file -t <tree-hash>
ويمكننا استخدام git cat-file -p لرؤية محتوياته:
$ git cat-file -p <tree-hash>
رائع، لقد أنشأنا tree، والآن نحتاج إلى إنشاء كائن commit يشير إلى هذا الـ tree. للقيام بذلك، يمكننا استخدام git commit-tree <tree-hash> -m <commit message>:
$ git commit-tree <tree-hash> -m "Initial commit from scratch"
يجب أن تشعر الآن بالراحة مع الأوامر المستخدمة للتحقق من نوع الكائن الذي تم إنشاؤه، وطباعة محتوياته:
$ git cat-file -t <commit-hash>
$ git cat-file -p <commit-hash>
لاحظ أن هذا الـ commit ليس له أب، لأنه الـ commit الأول. عندما نضيف commit آخر، سيتعين علينا الإعلان عن أبيه – سنفعل ذلك لاحقًا. التجزئة الأخيرة التي حصلنا عليها – 80e...8f – هي تجزئة commit. نحن في الواقع معتادون جدًا على استخدام هذه التجزئات – ننظر إليها طوال الوقت. لاحظ أن هذا الـ commit يمتلك كائن tree، بتجزئته الخاصة، والتي نادرًا ما نحددها صراحةً.
هل سيتغير شيء في git status؟

لا 😕. لماذا هذا؟ حسنًا، لكي يعرف Git أن ملفنا قد تم الالتزام به، يحتاج Git إلى معرفة أحدث commit. كيف يفعل Git ذلك؟ يذهب إلى HEAD:


يشير HEAD إلى master، ولكن ما هو master؟ لم نقم بإنشائه بعد حقًا. كما أوضحنا سابقًا في هذا المقال، الفرع هو ببساطة مرجع مسمى إلى commit. وفي هذه الحالة، نرغب في أن يشير master إلى الـ commit الذي يحمل التجزئة 80e8ed4fb0bfc3e7ba88ec417ecf2f6e6324998f. يمكننا تحقيق ذلك ببساطة عن طريق إنشاء ملف في \refs\heads\master، بمحتويات هذه التجزئة، على النحو التالي:
على Windows:
> echo 80e8ed4fb0bfc3e7ba88ec417ecf2f6e6324998f > .git\refs\heads\masterعلى UNIX:
$ echo "80e8ed4fb0bfc3e7ba88ec417ecf2f6e6324998f" > .git/refs/heads/master
⭐ باختصار، الفرع هو مجرد ملف داخل .git\refs\heads، يحتوي على تجزئة الـ commit الذي يشير إليه. الآن، أخيرًا، يبدو أن git status و git log يقدران جهودنا:

لقد نجحنا في إنشاء commit دون استخدام أوامر porcelain! كم هذا رائع! 🎉
العمل مع الفروع في Git: نظرة من الداخل
تمامًا كما أنشأنا مستودعًا و commit دون استخدام git init، git add، أو git commit، الآن سنقوم بإنشاء فروع والتبديل بينها دون استخدام أوامر porcelain (git branch أو git checkout). من المفهوم تمامًا إذا كنت متحمسًا، أنا أيضًا 🙂 لنبدأ:
حتى الآن لدينا فرع واحد فقط، اسمه master. لإنشاء فرع آخر باسم test (ما يعادل git branch test)، سنحتاج ببساطة إلى إنشاء ملف باسم test داخل .git\refs\heads، وسيكون محتوى هذا الملف هو نفس تجزئة الـ commit الذي يشير إليه master.
> copy .git\refs\heads\master .git\refs\heads\test
إذا استخدمنا git log، يمكننا أن نرى أن هذا هو الحال بالفعل – يشير كل من master و test إلى هذا الـ commit:

دعنا ننتقل أيضًا إلى فرعنا الذي تم إنشاؤه حديثًا (ما يعادل git checkout test). لذلك، يجب أن نغير HEAD ليشير إلى فرعنا الجديد:
> echo ref: refs/heads/test > .git\HEAD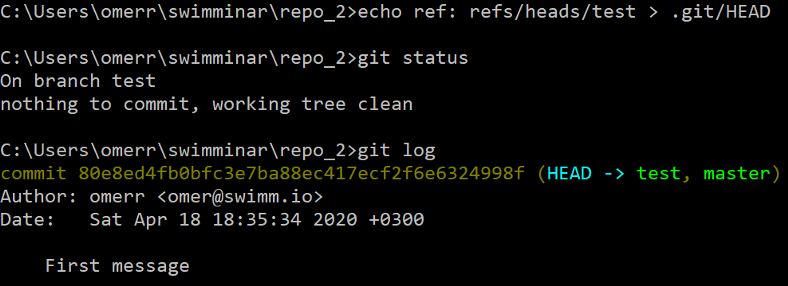
كما نرى، يؤكد كل من git status و git log أن HEAD يشير الآن إلى test، وهو بالتالي الفرع النشط. يمكننا الآن استخدام الأوامر التي استخدمناها بالفعل لإنشاء ملف آخر وإضافته إلى الـ index:
> echo Testing > test.txt
> git hash-object -w test.txt
> git update-index --add --cacheinfo 100644 <new-blob-hash> test.txt
باستخدام الأوامر أعلاه، أنشأنا ملفًا باسم test.txt، بمحتوى Testing، وأنشأنا blob مطابقًا، وأضفناه إلى الـ index. أنشأنا أيضًا tree يمثل الـ index. حان الوقت الآن لإنشاء commit يشير إلى هذا الـ tree. هذه المرة، يجب علينا أيضًا تحديد أب هذا الـ commit – والذي سيكون الـ commit السابق. نحدد الأب باستخدام المفتاح -p لـ git commit-tree:
$ git write-tree
$ git commit-tree <new-tree-hash> -p <parent-commit-hash> -m "Second commit on test branch"
لقد أنشأنا للتو commit، مع tree بالإضافة إلى أب، كما نرى:
$ git cat-file -p <new-commit-hash>
هل سيعرض لنا git log الـ commit الجديد؟

كما نرى، لا يعرض git log أي شيء جديد. لماذا هذا؟ 🤔 تذكر أن git log يتتبع الفروع للعثور على الالتزامات ذات الصلة لعرضها. يعرض لنا الآن test والـ commit الذي يشير إليه، ويعرض أيضًا master الذي يشير إلى نفس الـ commit. هذا صحيح – نحتاج إلى تغيير test ليشير إلى الـ commit الجديد الخاص بنا. يمكننا القيام بذلك ببساطة عن طريق تغيير محتويات .git\refs\heads\test:
على Windows:
> echo <new-commit-hash> > .git\refs\heads\testعلى UNIX:
$ echo "<new-commit-hash>" > .git/refs/heads/test
لقد نجح الأمر! 🎉🥂 يتوجه git log إلى HEAD، الذي يخبره بالذهاب إلى الفرع test، الذي يشير إلى الـ commit 465...5e، والذي يرتبط بدوره بـ commit الأب 80e...8f. لا تتردد في الإعجاب بهذا الجمال، لقد فهمت Git.
الخلاصة التقنية
لقد قدم هذا المقال نظرة معمقة على آليات Git الداخلية. بدأنا بتغطية الكائنات الأساسية: blobs التي تحمل محتويات الملفات، trees التي تمثل قوائم الأدلة وتشير إلى blobs و trees فرعية، و commits التي تمثل لقطات لدليل العمل مع بيانات وصفية ومراجع للالتزامات السابقة. تعلمنا أن Git يعتمد على تجزئات SHA-1 لتعريف هذه الكائنات، وكيف يستفيد من عدم تكرار تخزين الكائنات غير المتغيرة لتحسين الكفاءة.
ثم انتقلنا إلى الفروع، موضحين أنها ليست سوى مراجع مسمّاة إلى commits، وكيف يدير HEAD الفرع النشط. استكشفنا العلاقة بين دليل العمل (working directory)، ومنطقة التخزين المؤقت (staging area أو index)، والمستودع (repository)، وكيف تتفاعل هذه المكونات مع أوامر Git التقليدية مثل git init و git add و git commit.
كان الجزء الأكثر إثارة هو الغوص العميق في Git، حيث توقفنا عن استخدام أوامر porcelain (عالية المستوى) وتحولنا إلى أوامر plumbing (منخفضة المستوى). من خلال استخدام أوامر مثل git hash-object، git update-index، git write-tree، و git commit-tree، قمنا ببناء مستودع Git من الصفر، خطوة بخطوة. هذا النهج العملي كشف عن البنية الداخلية لـ .git، وكيف يتم تخزين الكائنات والمراجع، وكيف يتم تحديث مؤشرات الفروع.
إن فهم هذه الآليات الداخلية لا يقتصر على الفضول التقني فحسب، بل يمنح المطورين قدرة أكبر على استكشاف الأخطاء وإصلاحها، وحل تعارضات الدمج المعقدة، وتنفيذ عمليات Git المتقدمة بثقة وفعالية. نأمل أن يكون هذا المقال قد عمّق فهمك لما يحدث تحت الغطاء عند العمل مع Git.