دليل شامل لمنصة Google Cloud Platform: من المبتدئ إلى المحترف

هل تمتلك المعرفة والمهارات اللازمة لتصميم منصة لتحليل بيانات ألعاب الهاتف المحمول، قادرة على جمع وتخزين وتحليل كميات ضخمة من البيانات المجمعة والبيانات في الوقت الفعلي؟ بعد قراءة هذا المقال، ستكون قادرًا على ذلك. يهدف هذا الدليل إلى نقلك من نقطة الصفر إلى مستوى الاحتراف في استخدام Google Cloud Platform (GCP) في مقال واحد فقط. سأوضح لك كيفية:
- البدء بحساب GCP مجاني.
- تقليل التكاليف في بنيتك التحتية على GCP.
- تنظيم مواردك بفعالية.
- أتمتة إنشاء مواردك وتكوينها.
- إدارة العمليات: مثل التسجيل (logging)، المراقبة (monitoring)، التتبع (tracing)، وغيرها.
- تخزين بياناتك بأمان.
- نشر تطبيقاتك وخدماتك.
- إنشاء شبكات في GCP وربطها بشبكاتك المحلية (on-premise).
- العمل مع البيانات الضخمة (Big Data)، الذكاء الاصطناعي (AI)، وتعلم الآلة (Machine Learning).
- تأمين مواردك.
بعد شرح جميع هذه المواضيع، سأشارك معك حلاً لنظام تحليل بيانات الألعاب الذي وصفته. إذا واجهت صعوبة في فهم بعض الأجزاء، يمكنك العودة إلى الأقسام ذات الصلة. وإذا لم يكن ذلك كافيًا، يمكنك زيارة الروابط إلى الوثائق الرسمية التي سأقدمها. هل أنت مستعد للتحدي؟
لقد اخترت لك بعض الأسئلة من امتحانات شهادات GCP Professional Certification القديمة. ستختبر هذه الأسئلة مدى فهمك للمفاهيم المشروحة في هذا المقال. أوصي بمحاولة حل تحديات التصميم والأسئلة بنفسك، والرجوع إلى الدليل عند الضرورة. بمجرد حصولك على إجابة، قارنها بالحل المقترح. حاول أن تتجاوز ما تقرأه واسأل نفسك ماذا سيحدث إذا تغير متطلب معين، مثل:
- البيانات المجمعة (Batch data) مقابل بيانات التدفق (streaming data).
- حل إقليمي (Regional solution) مقابل حل عالمي (global solution).
- عدد قليل من المستخدمين مقابل حجم هائل من المستخدمين.
- وقت الاستجابة (Latency) ليس مشكلة مقابل التطبيقات في الوقت الفعلي (real-time applications).
وأي سيناريوهات أخرى يمكنك التفكير فيها. في نهاية المطاف، لا يتم الدفع لك فقط مقابل ما تعرفه، بل مقابل عملية تفكيرك والقرارات التي تتخذها. ولهذا السبب، من الأهمية بمكان أن تمارس هذه المهارة. في نهاية المقال، سأقدم المزيد من الموارد والخطوات التالية إذا كنت ترغب في مواصلة التعلم عن GCP.
البدء المجاني مع Google Cloud Platform
تقدم GCP حاليًا فترة تجريبية مجانية لمدة 3 أشهر مع رصيد مجاني بقيمة 300 دولار أمريكي. يمكنك استخدام هذا الرصيد للبدء، وتجربة GCP، وإجراء التجارب لتحديد ما إذا كان الخيار المناسب لك. لن يتم محاسبتك في نهاية الفترة التجريبية. ستتلقى إشعارًا وستتوقف خدماتك عن العمل ما لم تقرر ترقية خطتك. أوصي بشدة باستخدام هذه الفترة التجريبية للممارسة. للتعلم، يجب عليك تجربة الأشياء بنفسك، ومواجهة المشاكل، وتجربة الفشل، وإصلاح الأخطاء. لا يهم مدى جودة هذا الدليل (أو الوثائق الرسمية)، إذا لم تجرب الأشياء بنفسك.
لماذا ترحّل خدماتك إلى Google Cloud Platform؟
يوفر استهلاك الموارد من GCP، مثل التخزين أو قوة الحوسبة، الفوائد التالية:
- لا حاجة لإنفاق مبالغ كبيرة مقدمًا على الأجهزة.
- لا حاجة لترقية أجهزتك وترحيل بياناتك وخدماتك كل بضع سنوات.
- القدرة على التوسع للتكيف مع الطلب، مع الدفع فقط مقابل الموارد التي تستهلكها.
- إنشاء نماذج أولية بسرعة، حيث يمكن توفير الموارد بسرعة كبيرة.
- تأمين وإدارة واجهات برمجة التطبيقات (APIs) الخاصة بك.
- ليست مجرد بنية تحتية: تتوفر خدمات تحليل البيانات وتعلم الآلة في GCP.
تجعل GCP من السهل التجربة واستخدام الموارد التي تحتاجها بطريقة اقتصادية.
تحسين أداء الأجهزة الافتراضية (VMs) لخفض التكاليف في GCP
بشكل عام، سيتم محاسبتك فقط على الوقت الذي تعمل فيه الأجهزة الافتراضية (instances) الخاصة بك. لن تفرض Google رسومًا على الأجهزة المتوقفة. ومع ذلك، إذا كانت تستهلك موارد مثل الأقراص أو عناوين IP المحجوزة، فقد تتحمل رسومًا. إليك بعض الطرق التي يمكنك من خلالها تحسين تكلفة تشغيل تطبيقاتك في GCP.
أنواع الأجهزة المخصصة (Custom Machine Types)
توفر GCP عائلات مختلفة من الأجهزة بكميات محددة مسبقًا من ذاكرة الوصول العشوائي (RAM) ووحدات المعالجة المركزية (CPUs):
- متعددة الأغراض (General-purpose): توفر أفضل نسبة سعر إلى أداء لمجموعة متنوعة من أعباء العمل.
- مُحسّنة للذاكرة (Memory-optimized): مثالية لأعباء العمل التي تتطلب ذاكرة مكثفة. توفر ذاكرة أكبر لكل نواة مقارنة بأنواع الأجهزة الأخرى.
- مُحسّنة للحوسبة (Compute-optimized): توفر أعلى أداء لكل نواة ومُحسّنة لأعباء العمل التي تتطلب حوسبة مكثفة.
- النواة المشتركة (Shared-core): تشارك هذه الأنواع من الأجهزة نواة فيزيائية. يمكن أن تكون هذه طريقة فعالة من حيث التكلفة لتشغيل التطبيقات الصغيرة.
بالإضافة إلى ذلك، يمكنك إنشاء جهاز مخصص خاص بك بكمية ذاكرة الوصول العشوائي ووحدات المعالجة المركزية التي تحتاجها.
الأجهزة الافتراضية القابلة للإيقاف المؤقت (Preemptible VMs)
يمكنك استخدام الأجهزة الافتراضية القابلة للإيقاف المؤقت لتوفير ما يصل إلى 80% من تكاليفك. إنها مثالية للتطبيقات المتسامحة مع الأخطاء وغير الحرجة. يمكنك حفظ تقدم عملك في قرص ثابت (persistent disk) باستخدام نص إيقاف التشغيل (shut-down script) للمتابعة من حيث توقفت. قد توقف Google أجهزتك في أي وقت (مع تحذير مدته 30 ثانية) وستوقفها دائمًا بعد 24 ساعة. لتقليل فرص إيقاف أجهزتك الافتراضية، توصي Google بما يلي:
- استخدام العديد من الأجهزة الافتراضية الصغيرة.
- تشغيل مهامك خلال أوقات الذروة المنخفضة.
ملاحظة: تنطبق نصوص بدء التشغيل (start-up scripts) وإيقاف التشغيل أيضًا على الأجهزة الافتراضية غير القابلة للإيقاف المؤقت. يمكنك استخدامها للتحكم في سلوك جهازك عند بدء التشغيل أو الإيقاف. على سبيل المثال، لتثبيت البرامج، أو تنزيل البيانات، أو نسخ السجلات احتياطيًا. هناك خياران لتعريف هذه النصوص:
- عند إنشاء جهازك في Google Console، يوجد حقل للصق التعليمات البرمجية الخاصة بك.
- استخدام عنوان URL لخادم البيانات الوصفية (metadata server) لتوجيه جهازك إلى نص برمجي مخزن في Google Cloud Storage. هذا الأخير مفضل لأنه أسهل في إنشاء العديد من الأجهزة وإدارة النص البرمجي.
خصومات الاستخدام المستمر (Sustained Use Discounts)
كلما طالت مدة استخدامك لأجهزتك الافتراضية (وCloud SQL instances)، زاد الخصم – حتى 30%. تقوم Google بذلك تلقائيًا نيابة عنك.
خصومات الاستخدام الملتزم (Committed Use Discounts)
يمكنك الحصول على خصم يصل إلى 57% إذا التزمت بكمية معينة من موارد وحدة المعالجة المركزية (CPU) وذاكرة الوصول العشوائي (RAM) لمدة تتراوح من 1 إلى 3 سنوات. لتقدير تكاليفك، استخدم Price Calculator. يساعد هذا في منع أي مفاجآت في فواتيرك وإنشاء تنبيهات للميزانية (budget alerts).
إدارة الموارد في Google Cloud Platform
في هذا القسم، سأشرح لك كيفية إدارة موارد Google Cloud والإشراف عليها.
التسلسل الهرمي للموارد (Resource Hierarchy)
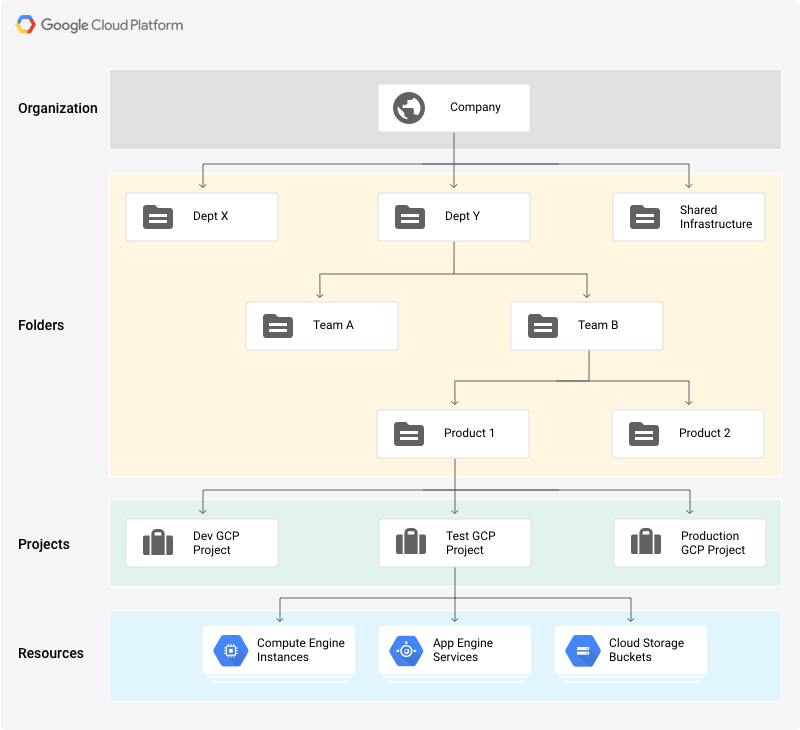
هناك أربعة أنواع من الموارد التي يمكن إدارتها من خلال Resource Manager:
- مورد المنظمة (The organization resource): هو العقدة الجذر في التسلسل الهرمي للموارد. يمثل منظمة، على سبيل المثال، شركة.
- مورد المشاريع (The projects resource): على سبيل المثال، لفصل المشاريع لبيئات الإنتاج والتطوير. إنها مطلوبة لإنشاء الموارد.
- مورد المجلدات (The folder resource): توفر مستوى إضافيًا من عزل المشروع. على سبيل المثال، إنشاء مجلد لكل قسم في شركة.
- الموارد (Resources): الأجهزة الافتراضية، مثيلات قواعد البيانات، موازنات التحميل، وما إلى ذلك.
هناك حصص (quotas) تحد من العدد الأقصى للموارد التي يمكنك إنشاؤها لمنع الارتفاعات غير المتوقعة في الفواتير. ومع ذلك، يمكن زيادة معظم الحصص عن طريق فتح تذكرة دعم.
تتبع الموارد في GCP تسلسلاً هرميًا عبر علاقة الأب/الابن، على غرار نظام الملفات التقليدي، حيث:
- يتم توريث الأذونات كلما نزلنا في التسلسل الهرمي. على سبيل المثال، الأذونات الممنوحة على مستوى المنظمة ستنتشر إلى جميع المجلدات والمشاريع.
- تتجاوز سياسات الأب الأكثر تساهلاً دائمًا سياسات الابن الأكثر تقييدًا.
يساعدك هذا التنظيم الهرمي على إدارة الجوانب المشتركة لمواردك، مثل التحكم في الوصول وإعدادات التكوين. يمكنك إنشاء حسابات مشرفين فائقين (super admin accounts) لديهم حق الوصول إلى كل مورد في مؤسستك. نظرًا لأنها قوية جدًا، تأكد من اتباع أفضل ممارسات Google.
التصنيفات (Labels)
التصنيفات (Labels) هي أزواج من المفاتيح والقيم (key-value pairs) يمكنك استخدامها لتنظيم مواردك في GCP. بمجرد إرفاق تصنيف بمورد (على سبيل المثال، بجهاز افتراضي)، يمكنك التصفية بناءً على هذا التصنيف. هذا مفيد أيضًا لتقسيم فواتيرك حسب التصنيفات. بعض حالات الاستخدام الشائعة:
- البيئات: prod، test، وما إلى ذلك.
- مالكو الفريق أو المنتج.
- المكونات: backend، frontend، وما إلى ذلك.
- حالة المورد: active، archive، وما إلى ذلك.
التصنيفات (Labels) مقابل علامات الشبكة (Network Tags)
يبدو أن هذين المفهومين المتشابهين يسببان بعض الارتباك. لقد لخصت الاختلافات في هذا الجدول:
| التصنيفات (Labels) | علامات الشبكة (Network tags) |
|---|---|
| تُطبق على أي مورد في GCP | تُطبق فقط على موارد VPC |
| تنظم الموارد فقط | تؤثر على كيفية عمل الموارد (مثل: من خلال تطبيق قواعد جدار الحماية) |
إدارة الهوية والوصول السحابية (Cloud IAM)
ببساطة، تتحكم Cloud IAM في من يمكنه فعل ماذا على أي مورد. يمكن أن يكون المورد جهازًا افتراضيًا، أو مثيل قاعدة بيانات، أو مستخدمًا، وما إلى ذلك. من المهم ملاحظة أن الأذونات لا تُسند مباشرة إلى المستخدمين. بدلاً من ذلك، يتم تجميعها في أدوار (roles)، والتي تُسند إلى أعضاء (members). والسياسة (policy) هي مجموعة من ربط واحد أو أكثر من الأعضاء بدور معين.

الهويات (Identities)
في مشروع GCP، يتم تمثيل الهويات بواسطة حسابات Google، التي تُنشأ خارج GCP، وتُعرف بواسطة عنوان بريد إلكتروني (ليس بالضرورة @gmail.com). هناك أنواع مختلفة:
- حسابات Google: لتمثيل الأشخاص: المهندسين، المسؤولين، وما إلى ذلك.
- حسابات الخدمة (Service accounts): تُستخدم لتحديد المستخدمين غير البشريين: التطبيقات، الخدمات، الأجهزة الافتراضية، وغيرها. يتم تعريف عملية المصادقة بواسطة مفاتيح الحساب (account keys)، والتي يمكن إدارتها بواسطة Google أو بواسطة المستخدمين (فقط لحسابات الخدمة التي أنشأها المستخدم).
- مجموعات Google (Google Groups): هي مجموعة من حسابات Google وحسابات الخدمة.
- نطاق G Suite: هو نوع الحساب الذي يمكنك استخدامه لتحديد المنظمات. إذا كانت مؤسستك تستخدم بالفعل Active Directory، فيمكن مزامنته مع Cloud IAM باستخدام Cloud Identity.
allAuthenticatedUsers: لتمثيل أي مستخدم مصادق عليه في GCP.allUsers: لتمثيل أي شخص، سواء كان مصادقًا عليه أم لا.
فيما يتعلق بحسابات الخدمة، تتضمن بعض أفضل ممارسات Google ما يلي:
- عدم استخدام حساب الخدمة الافتراضي.
- تطبيق مبدأ الحد الأدنى من الامتيازات (Principle of Least Privilege). على سبيل المثال:
- تقييد من يمكنه العمل كحساب خدمة.
- منح الحد الأدنى فقط من الأذونات التي يحتاجها الحساب.
- إنشاء حسابات خدمة لكل خدمة، مع الأذونات التي تحتاجها فقط.
الأدوار (Roles)
الدور (role) هو مجموعة من الأذونات. هناك ثلاثة أنواع من الأدوار:
- الأدوار البدائية (Primitive): أدوار GCP الأصلية التي تنطبق على المشروع بأكمله. هناك ثلاثة أدوار متداخلة: Viewer (عارض)، Editor (محرر)، و Owner (مالك). يحتوي Editor على Viewer، ويحتوي Owner على Editor.
- الأدوار المحددة مسبقًا (Predefined): توفر الوصول إلى خدمات محددة، على سبيل المثال، storage.admin.
- الأدوار المخصصة (Custom): تتيح لك إنشاء أدوارك الخاصة، ودمج الأذونات المحددة التي تحتاجها.
عند تعيين الأدوار، اتبع مبدأ الحد الأدنى من الامتيازات أيضًا. بشكل عام، فضل الأدوار المحددة مسبقًا على الأدوار البدائية.
مدير النشر السحابي (Cloud Deployment Manager)
يقوم Cloud Deployment Manager بأتمتة المهام المتكررة مثل توفير الموارد وتكوينها ونشرها لأي عدد من الأجهزة. إنها خدمة Infrastructure as Code من Google، مماثلة لـ Terraform – على الرغم من أنه يمكنك نشر موارد GCP فقط. تُستخدم بواسطة GCP Marketplace لإنشاء عمليات نشر مهيأة مسبقًا.
يمكنك تعريف تكوينك في ملفات YAML، مع سرد الموارد (التي يتم إنشاؤها عبر استدعاءات API) التي تريد إنشاءها وخصائصها. تُعرف الموارد باسمها (VM-1, disk-1)، ونوعها (compute.v1.disk, compute.v1.instance)، وخصائصها (zone:europe-west4, boot:false). لزيادة الأداء، يتم نشر الموارد بالتوازي. لذلك تحتاج إلى تحديد أي تبعيات باستخدام المراجع (references). على سبيل المثال، لا تنشئ جهازًا افتراضيًا VM-1 حتى يتم إنشاء القرص الثابت disk-1. في المقابل، سيكتشف Terraform التبعيات بنفسه.
يمكنك تقسيم ملفات التكوين الخاصة بك إلى وحدات باستخدام القوالب (templates) بحيث يمكن تحديثها ومشاركتها بشكل مستقل. يمكن تعريف القوالب في Python أو Jinja2. سيتم تضمين محتويات قوالبك في ملف التكوين الذي يشير إليها. سينشئ Deployment Manager بيانًا (manifest) يحتوي على التكوين الأصلي الخاص بك، وأي قوالب قمت باستيرادها، والقائمة الموسعة لجميع الموارد التي تريد إنشاءها.
عمليات السحابة (Cloud Operations) – Stackdriver سابقًا
توفر Cloud Operations مجموعة من الأدوات للمراقبة والتسجيل وتصحيح الأخطاء والإبلاغ عن الأخطاء والتوصيف والتتبع للموارد في GCP (وAWS وحتى في البنية التحتية المحلية).
تسجيل السحابة (Cloud Logging)
يُعد Cloud Logging حل GCP المركزي لإدارة السجلات في الوقت الفعلي. لكل مشروع من مشاريعك، يتيح لك تخزين بيانات التسجيل والبحث فيها وتحليلها ومراقبتها والتنبيه بشأنها:
- بشكل افتراضي، سيتم تخزين البيانات لفترة زمنية معينة. تختلف فترة الاحتفاظ بالبيانات حسب نوع السجل. لا يمكنك استرداد السجلات بعد انتهاء فترة الاحتفاظ هذه.
- يمكن تصدير السجلات لأغراض مختلفة. للقيام بذلك، يمكنك إنشاء مستقبل (sink)، والذي يتكون من مرشح (filter) (لتحديد ما تريد تسجيله) ووجهة (destination): Google Cloud Storage (GCS) للاحتفاظ طويل الأمد، BigQuery للتحليلات، أو Pub/Sub لتدفقها إلى تطبيقات أخرى.
- يمكنك إنشاء مقاييس تستند إلى السجلات (log-based metrics) في Cloud Monitoring وحتى تلقي تنبيهات عندما يحدث خطأ ما.
السجلات هي مجموعة مسماة من إدخالات السجل (log entries). تسجل إدخالات السجل الحالة أو الأحداث وتتضمن اسم سجلها، على سبيل المثال، compute.googleapis.com/activity. هناك نوعان رئيسيان من السجلات:
- سجلات المستخدم (User Logs): يتم إنشاؤها بواسطة تطبيقاتك وخدماتك. تُكتب إلى Cloud Logging باستخدام Cloud Logging API، أو مكتبات العميل (client libraries)، أو وكلاء التسجيل (logging agents) المثبتين على أجهزتك الافتراضية. تقوم بتدفق السجلات من تطبيقات الطرف الثالث الشائعة مثل MySQL، MongoDB، أو Tomcat.
- سجلات الأمان (Security logs): تنقسم إلى:
- سجلات التدقيق (Audit logs): للتغييرات الإدارية، أحداث النظام، والوصول إلى البيانات لمواردك. على سبيل المثال، من أنشأ مثيل قاعدة بيانات معين أو لتسجيل ترحيل مباشر (live migration). يجب تمكين سجلات الوصول إلى البيانات صراحة وقد تتحمل رسومًا إضافية. أما البقية فيتم تمكينها افتراضيًا، ولا يمكن تعطيلها، وهي مجانية.
- سجلات شفافية الوصول (Access Transparency logs): للإجراءات التي يتخذها موظفو Google عند وصولهم إلى مواردك، على سبيل المثال للتحقيق في مشكلة أبلغت عنها لفريق الدعم.
سجلات تدفق الشبكة الافتراضية الخاصة (VPC Flow Logs)
إنها خاصة بشبكات VPC (التي سأقدمها لاحقًا). تسجل سجلات تدفق VPC عينة من تدفقات الشبكة المرسلة من وإلى مثيلات الأجهزة الافتراضية، والتي يمكن الوصول إليها لاحقًا في Cloud Logging. يمكن استخدامها لمراقبة أداء الشبكة، والاستخدام، والتحقيقات الجنائية، وتحليل الأمان في الوقت الفعلي، وتحسين النفقات.
ملاحظة: قد ترغب في تسجيل بيانات الفواتير الخاصة بك للتحليل. في هذه الحالة، لا تنشئ مستقبلًا (sink). يمكنك تصدير تقاريرك مباشرة إلى BigQuery.
مراقبة السحابة (Cloud Monitoring)
تتيح لك Cloud Monitoring مراقبة أداء تطبيقاتك وبنيتك التحتية، وتصورها في لوحات المعلومات (dashboards)، وإنشاء فحوصات وقت التشغيل (uptime checks) لاكتشاف الموارد المعطلة وتنبيهك بناءً على هذه الفحوصات حتى تتمكن من إصلاح المشاكل في بيئتك. يمكنك مراقبة الموارد في GCP وAWS وحتى في البنية التحتية المحلية. يوصى بإنشاء مشروع منفصل لـ Cloud Monitoring حيث يمكنه تتبع الموارد عبر مشاريع متعددة. كما يوصى بتثبيت وكيل مراقبة (monitoring agent) في أجهزتك الافتراضية لإرسال مقاييس التطبيق (بما في ذلك العديد من تطبيقات الطرف الثالث) إلى Cloud Monitoring. وإلا، سيعرض Cloud Monitoring فقط مقاييس وحدة المعالجة المركزية (CPU)، وحركة القرص، وحركة الشبكة، ووقت التشغيل.
التنبيهات (Alerts)
لتلقي التنبيهات، يجب عليك الإعلان عن سياسة تنبيه (alerting policy). تحدد سياسة التنبيه الشروط التي بموجبها تعتبر الخدمة غير صحية. عند استيفاء الشروط، سيتم إنشاء حادث جديد وإرسال إشعارات (عبر البريد الإلكتروني، Slack، الرسائل القصيرة، PagerDuty، إلخ). تنتمي السياسة إلى مساحة عمل فردية (workspace)، والتي يمكن أن تحتوي على 500 سياسة كحد أقصى.
التتبع (Trace)
يساعد Trace في العثور على نقاط الاختناق (bottlenecks) في خدماتك. يمكنك استخدام هذه الخدمة لمعرفة المدة التي يستغرقها معالجة طلب ما، وأي خدمة مصغرة (microservice) تستغرق أطول وقت للاستجابة، وأين يجب التركيز لتقليل زمن الاستجابة الإجمالي، وما إلى ذلك. يتم تمكينه افتراضيًا للتطبيقات التي تعمل على Google App Engine (GAE) – البيئة القياسية (Standard environment) – ولكن يمكن استخدامه للتطبيقات التي تعمل على GCE، GKE، و Google App Engine Flexible.
الإبلاغ عن الأخطاء (Error Reporting)
سيقوم Error Reporting بتجميع وعرض الأخطاء التي تحدث في الخدمات المكتوبة بلغات Go، Java، Node.js، PHP، Python، Ruby، أو .NET، والتي تعمل على GCE، GKE، GAP، Cloud Functions، أو Cloud Run.
التصحيح (Debug)
يتيح لك Debug فحص حالة التطبيق دون إيقاف خدمتك. وهو مدعوم حاليًا لـ Java، Go، Node.js، و Python. يتم دمجه تلقائيًا مع GAE ولكن يمكن استخدامه على GCE، GKE، و Cloud Run.
التوصيف (Profile)
أداة توصيف (Profiler) تجمع باستمرار معلومات استخدام وحدة المعالجة المركزية (CPU usage) وتخصيص الذاكرة (memory-allocation) من تطبيقاتك. لاستخدامها، تحتاج إلى تثبيت وكيل توصيف (profiling agent).
كيفية تخزين البيانات في Google Cloud Platform
في هذا القسم، سأغطي كلاً من Google Cloud Storage (لأي نوع من البيانات، بما في ذلك الملفات والصور والفيديو وما إلى ذلك)، وخدمات قواعد البيانات المختلفة المتاحة في GCP، وكيفية تحديد خيار التخزين الأنسب لك.
تخزين Google السحابي (Google Cloud Storage – GCS)
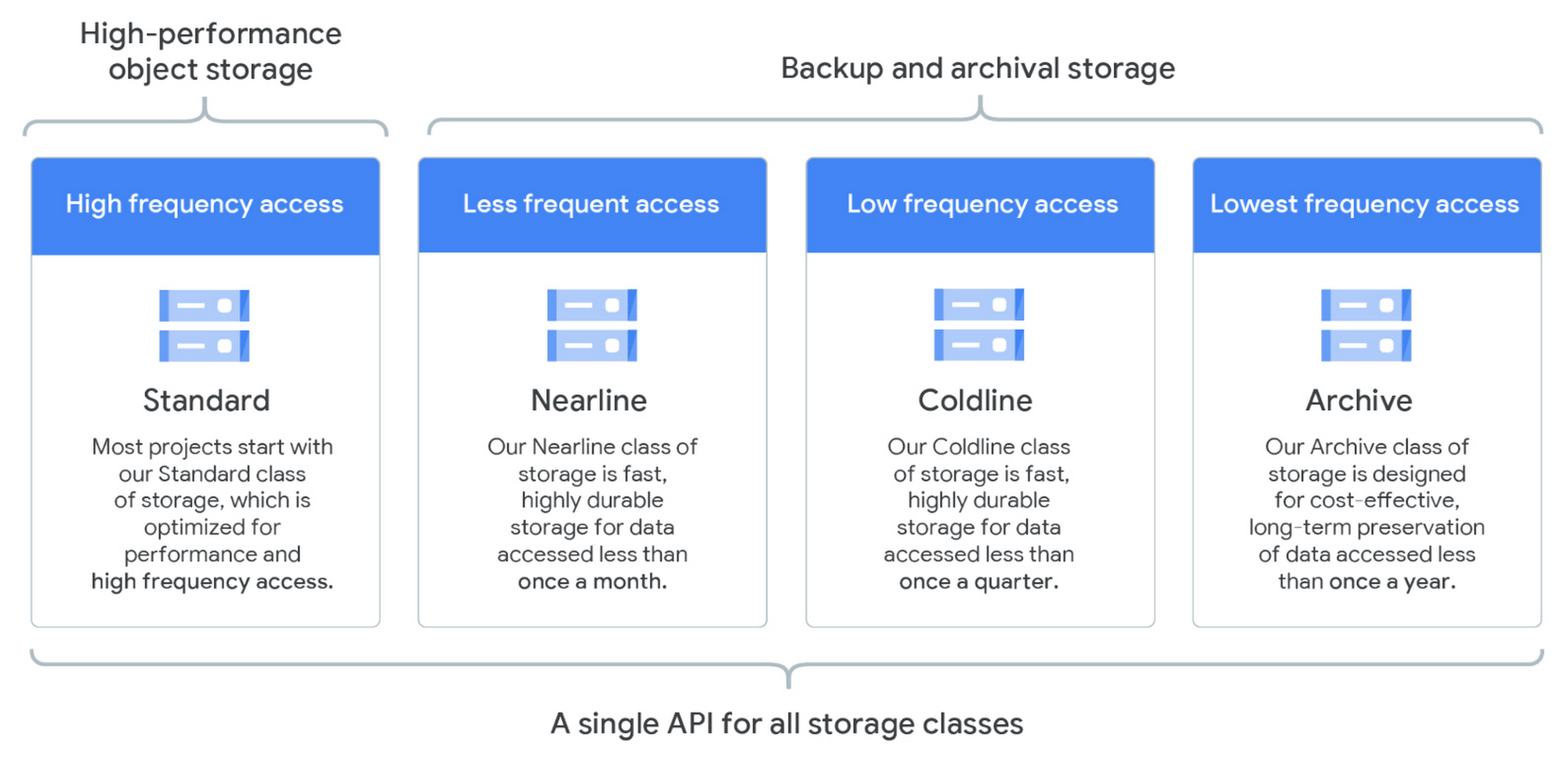
يُعد GCS خدمة تخزين Google للبيانات غير المهيكلة (unstructured data): الصور، مقاطع الفيديو، الملفات، النصوص البرمجية، النسخ الاحتياطية لقواعد البيانات، وما إلى ذلك. تُوضع الكائنات (Objects) في حاويات (buckets)، والتي ترث منها الأذونات وفئات التخزين (storage classes). توفر فئات التخزين اتفاقيات مستوى خدمة (SLAs) مختلفة لتخزين بياناتك لتقليل التكاليف لحالة استخدامك. يمكن تغيير فئة تخزين الحاوية (مع بعض القيود)، ولكنها ستؤثر فقط على الكائنات الجديدة المضافة إلى الحاوية. بالإضافة إلى وحدة تحكم Google، يمكنك التفاعل مع GCS من سطر الأوامر الخاص بك، باستخدام gsutil. يمكنك تحديد:
- التحديثات متعددة الخيوط (Multithreaded updates) عندما تحتاج إلى تحميل عدد كبير من الملفات الصغيرة. يبدو الأمر كـ
gsutil -m cp files gs://my-bucket. - التحديثات المتوازية (Parallel updates) عندما تحتاج إلى تحميل ملفات كبيرة. لمزيد من التفاصيل والقيود، زر هذا الرابط.
خيار آخر لتحميل الملفات إلى GCS هو Storage Transfer Service (STS)، وهي خدمة تستورد البيانات إلى حاوية GCS من:
- حاوية AWS S3.
- مورد يمكن الوصول إليه عبر HTTP(S).
- حاوية Google Cloud Storage أخرى.
إذا كنت بحاجة إلى تحميل كميات هائلة من البيانات (من مئات التيرابايت إلى بيتابايت واحد)، ففكر في Data Transfer Appliance: اشحن بياناتك إلى منشأة Google. بمجرد تحميل البيانات إلى GCS، تقوم عملية إعادة ترطيب البيانات (data rehydration) بإعادة تكوين الملفات بحيث يمكن الوصول إليها مرة أخرى.
إدارة دورة حياة الكائنات (Object Lifecycle Management)
يمكنك تعريف قواعد تحدد ما سيحدث لكائن (هل سيتم أرشفته أو حذفه) عند استيفاء شرط معين. على سبيل المثال، يمكنك تعريف سياسة لتغيير فئة تخزين كائن تلقائيًا من Standard إلى Nearline بعد 30 يومًا وحذفه بعد 180 يومًا. هذه هي الطريقة التي يمكن بها تعريف القاعدة:
{
"lifecycle" :{
"rule" :[
{
"action" :{
"type" : "Delete"
},
"condition" :{
"age" : 30 ,
"isLive" : true
}
},
{
"action" :{
"type" : "Delete"
},
"condition" :{
"numNewerVersions" : 2
}
},
{
"action" :{
"type" : "Delete"
},
"condition" :{
"age" : 180 ,
"isLive" : false
}
}
]
}
}سيتم تطبيقها عبر gsutils أو استدعاء REST API. يمكن أيضًا إنشاء القواعد من خلال Google Console.
الأذونات في GCS
بالإضافة إلى أدوار IAM، يمكنك استخدام قوائم التحكم في الوصول (Access Control Lists – ACLs) لإدارة الوصول إلى الموارد في حاوية. استخدم أدوار IAM عندما يكون ذلك ممكنًا، ولكن تذكر أن ACLs تمنح الوصول إلى الحاويات والكائنات الفردية، بينما أدوار IAM هي أذونات على مستوى المشروع أو الحاوية. تعمل كلتا الطريقتين جنبًا إلى جنب. لمنح وصول مؤقت للمستخدمين خارج GCP، استخدم عناوين URL الموقعة (Signed URLs).
قفل الحاوية (Bucket Lock)
تسمح لك أقفال الحاويات بفرض فترة احتفاظ دنيا للكائنات في حاوية. قد تحتاج إلى ذلك لأسباب تدقيق أو قانونية. بمجرد قفل الحاوية، لا يمكن فتحها. لإزالتها، تحتاج أولاً إلى إزالة جميع الكائنات في الحاوية، وهو ما لا يمكنك فعله إلا بعد أن تصل جميعها إلى فترة الاحتفاظ المحددة بواسطة سياسة الاحتفاظ. عندها فقط، يمكنك حذف الحاوية. يمكنك تضمين سياسة الاحتفاظ عند إنشاء الحاوية أو إضافة سياسة احتفاظ إلى حاوية موجودة (تنطبق بأثر رجعي على الكائنات الموجودة في الحاوية أيضًا). حقيقة ممتعة: أقصى فترة احتفاظ هي 100 عام.
قواعد البيانات العلائقية المُدارة في GCP
يُعد Cloud SQL و Cloud Spanner خدمتين لقواعد البيانات المُدارة المتاحتين في GCP. إذا كنت لا ترغب في التعامل مع كل العمل الضروري للحفاظ على قاعدة بيانات متصلة بالإنترنت، فهما خيار رائع. يمكنك دائمًا تشغيل جهاز افتراضي وإدارة قاعدة البيانات الخاصة بك.
Cloud SQL
يوفر Cloud SQL الوصول إلى مثيل قاعدة بيانات MySQL أو PostgreSQL مُدار في GCP. يقتصر كل مثيل على منطقة واحدة ولديه سعة قصوى تبلغ 30 تيرابايت (TB). ستتولى Google عملية التثبيت، والنسخ الاحتياطية، والتوسع، والمراقبة، وتجاوز الفشل (failover)، ونسخ القراءة المتماثلة (read replicas). لأسباب تتعلق بالتوافر، يجب تعريف النسخ المتماثلة في نفس المنطقة ولكن في منطقة مختلفة عن المثيلات الأساسية. يمكن استيراد البيانات بسهولة (عبر تحميل البيانات أولاً إلى Google Cloud Storage ثم إلى المثيل) وتصديرها باستخدام تفريغات SQL أو تنسيقات ملفات CSV. يمكن ضغط البيانات لتقليل التكاليف (يمكنك استيراد ملفات .gz مباشرة). لعمليات الترحيل من نوع “رفع ونقل” (lift and shift)، يعد هذا خيارًا رائعًا. إذا كنت بحاجة إلى توافر عالمي أو سعة أكبر، ففكر في استخدام Cloud Spanner.
Cloud Spanner
يتوفر Cloud Spanner عالميًا ويمكنه التوسع (أفقيًا) بشكل جيد للغاية. هاتان الميزتان تجعلانه قادرًا على دعم حالات استخدام مختلفة عن Cloud SQL وأكثر تكلفة أيضًا. Cloud Spanner ليس خيارًا لعمليات الترحيل من نوع “رفع ونقل”.
قواعد البيانات NoSQL المُدارة في GCP
وبالمثل، توفر GCP قاعدتي بيانات NoSQL مُدارتين، Bigtable و Datastore، بالإضافة إلى خدمة قاعدة بيانات في الذاكرة، Memorystore.
Datastore
يُعد Datastore قاعدة بيانات مستندات (document database) لا تتطلب عمليات تشغيل، وقابلة للتوسع بدرجة عالية، ومثالية لتطبيقات الويب والهاتف المحمول: حالات الألعاب، كتالوجات المنتجات، المخزون في الوقت الفعلي، وما إلى ذلك. إنه رائع لـ:
- ملفات تعريف المستخدمين – تطبيقات الهاتف المحمول.
- حالات حفظ الألعاب.
بشكل افتراضي، يحتوي Datastore على فهرس مدمج (built-in index) يحسن الأداء في الاستعلامات البسيطة. يمكنك إنشاء فهارس خاصة بك، تسمى الفهارس المركبة (composite indexes)، المعرفة بتنسيق YAML. إذا كنت بحاجة إلى إنتاجية قصوى (عدد هائل من عمليات القراءة/الكتابة في الثانية)، استخدم Bigtable بدلاً من ذلك.
Bigtable
يُعد Bigtable قاعدة بيانات NoSQL مثالية لأعباء العمل التحليلية حيث يمكنك توقع حجم كبير جدًا من عمليات الكتابة، وعمليات القراءة في غضون أجزاء من الثانية، والقدرة على تخزين تيرابايت إلى بيتابايت من المعلومات. إنه رائع لـ:
- التحليل المالي.
- بيانات إنترنت الأشياء (IoT data).
- بيانات التسويق.
يتطلب Bigtable إنشاء وتكوين العقد (nodes) الخاصة بك (على عكس Datastore أو BigQuery المُدارتين بالكامل). يمكنك إضافة أو إزالة العقد من مجموعتك (cluster) دون توقف. أبسط طريقة للتفاعل مع Bigtable هي أداة سطر الأوامر cbt. سيعتمد أداء Bigtable على تصميم مخطط قاعدة البيانات (database schema) الخاص بك. يمكنك تعريف مفتاح واحد فقط لكل صف ويجب الاحتفاظ بجميع المعلومات المرتبطة بكيان في نفس الصف. فكر في الأمر كجدول تجزئة (hash table). الجداول متفرقة (sparse): إذا لم تكن هناك معلومات مرتبطة بعمود، فلا توجد مساحة مطلوبة. لجعل عمليات القراءة أكثر كفاءة، حاول تخزين الكيانات ذات الصلة في صفوف متجاورة. نظرًا لأن هذا الموضوع يستحق مقالًا خاصًا به، أوصي بقراءة الوثائق.
Memorystore
يوفر إصدارًا مُدارًا من Redis و Memcache (قواعد بيانات في الذاكرة)، مما يؤدي إلى أداء سريع جدًا. المثيلات إقليمية، مثل Cloud SQL، ولديها سعة تصل إلى 300 جيجابايت.
كيف تختار قاعدة البيانات المناسبة؟
تحب Google أشجار القرارات. ستساعدك هذه الشجرة في اختيار قاعدة البيانات المناسبة لمشاريعك. بالنسبة للبيانات غير المهيكلة، ضع في اعتبارك GCS أو قم بمعالجتها باستخدام Dataflow (سيتم مناقشته لاحقًا).

كيف تعمل الشبكات في Google Cloud Platform؟
الشبكة الافتراضية الخاصة (Virtual Private Cloud – VPC)
يمكنك استخدام نفس البنية التحتية للشبكة التي تستخدمها Google لتشغيل خدماتها: YouTube، Search، Maps، Gmail، Drive، وما إلى ذلك. تنقسم بنية Google التحتية إلى:
- المناطق (Regions): مناطق جغرافية مستقلة، تبعد عن بعضها البعض 100 ميل على الأقل، حيث تستضيف Google مراكز البيانات. تتكون من 3 مناطق أو أكثر. على سبيل المثال، us-central1.
- المناطق (Zones): مراكز بيانات فردية متعددة داخل منطقة. على سبيل المثال، us-central1-a.
- نقاط تواجد الحافة (Edge Points of Presence): نقاط اتصال بين شبكة Google وبقية الإنترنت.
تم تصميم بنية GCP التحتية بطريقة تجعل جميع حركة المرور بين المناطق تنتقل عبر شبكة خاصة عالمية، مما يؤدي إلى أمان وأداء أفضل. فوق هذه البنية التحتية، يمكنك بناء شبكات لمواردك، وهي Virtual Private Clouds. إنها شبكات معرفة بالبرمجيات (software-defined networks)، حيث تنطبق جميع مفاهيم الشبكة التقليدية:
- الشبكات الفرعية (Subnets): أقسام منطقية لشبكة معرفة باستخدام تدوين CIDR. تنتمي إلى منطقة واحدة فقط ولكن يمكن أن تمتد عبر مناطق متعددة. إذا كان لديك شبكات فرعية متعددة (بما في ذلك شبكاتك المحلية إذا كانت متصلة بـ GCP)، فتأكد من أن نطاقات CIDR لا تتداخل.
- عناوين IP: يمكن أن تكون داخلية (للاتصال الخاص داخل GCP) أو خارجية (للتواصل مع بقية الإنترنت). بالنسبة لعناوين IP الخارجية، يمكنك استخدام عنوان IP مؤقت (ephemeral IP) أو الدفع مقابل عنوان IP ثابت (static IP). بشكل عام، تحتاج إلى عنوان IP خارجي للاتصال بخدمات GCP. ومع ذلك، في بعض الحالات، يمكنك تكوين وصول خاص للمثيلات التي تحتوي فقط على عنوان IP داخلي.
- قواعد جدار الحماية (Firewall rules): للسماح أو رفض حركة المرور إلى أجهزتك الافتراضية، سواء الواردة (ingress) أو الصادرة (egress). بشكل افتراضي، يتم رفض جميع حركة المرور الواردة ويُسمح بجميع حركة المرور الصادرة. تُعرف قواعد جدار الحماية على مستوى VPC ولكنها تنطبق على المثيلات الفردية أو مجموعات المثيلات باستخدام علامات الشبكة (network tags) أو نطاقات IP.
مشكلة شائعة: إذا كنت تعلم أن أجهزتك الافتراضية تعمل بشكل صحيح ولكن لا يمكنك الوصول إليها عبر HTTP(S) أو لا يمكنك الاتصال بها عبر SSH، فراجع قواعد جدار الحماية الخاصة بك.
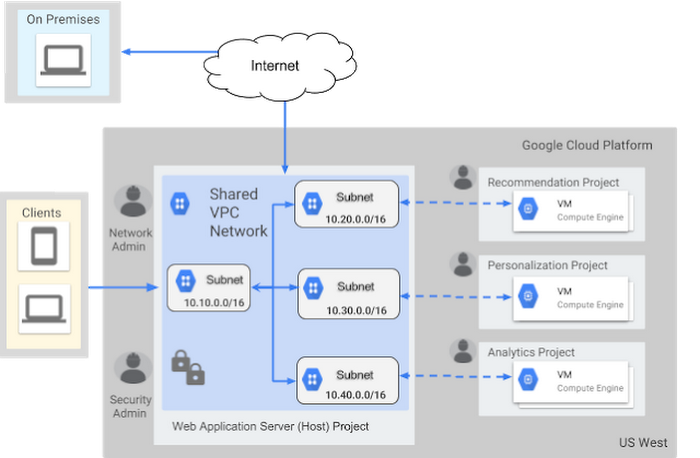
يمكنك إنشاء شبكات هجينة تربط بنيتك التحتية المحلية بشبكة VPC الخاصة بك. عند إنشاء مشروع، سيتم إنشاء شبكة افتراضية مع شبكات فرعية في كل منطقة (وضع تلقائي – auto mode). يمكنك حذف هذه الشبكة، ولكنك تحتاج إلى إنشاء شبكة واحدة على الأقل لتتمكن من إنشاء أجهزة افتراضية. يمكنك أيضًا إنشاء شبكاتك المخصصة (custom networks)، حيث لا يتم إنشاء شبكات فرعية افتراضيًا ولديك تحكم كامل في إنشاء الشبكات الفرعية (وضع مخصص – custom mode).
الهدف الرئيسي لـ VPC هو فصل موارد الشبكة. مشروع GCP هو طريقة لتنظيم الموارد وإدارة الأذونات. يحتاج مستخدمو المشروع A إلى أذونات للوصول إلى الموارد في المشروع B. يمكن لجميع المستخدمين الوصول إلى أي VPC معرف في أي مشروع ينتمون إليه. ضمن نفس VPC، تحتاج الموارد في الشبكة الفرعية 1 إلى منح حق الوصول إلى الموارد في الشبكة الفرعية 2.
فيما يتعلق بأدوار IAM، هناك تمييز بين من يمكنه إنشاء موارد الشبكة (Network admin، لإنشاء الشبكات الفرعية، والأجهزة الافتراضية، وما إلى ذلك) ومن هو المسؤول عن أمان الموارد (Security Admin، لإنشاء قواعد جدار الحماية، وشهادات SSL، وما إلى ذلك). يجمع دور Compute Instance Admin بين كلا الدورين. كالعادة، هناك حصص وقيود على ما يمكنك فعله في VPC، من بينها:
- الحد الأقصى لعدد VPC في المشروع.
- الحد الأقصى لعدد الأجهزة الافتراضية لكل VPC.
- لا يوجد بث (broadcast) أو بث متعدد (multicast).
- لا يمكن لشبكات VPC استخدام IPv6 للتواصل داخليًا، على الرغم من أن موازنات التحميل العالمية تدعم حركة مرور IPv6.
مشاركة الموارد بين شبكات VPC متعددة
Shared VPC
تُعد Shared VPCs طريقة لمشاركة الموارد بين مشاريع مختلفة داخل نفس المنظمة. يتيح لك هذا التحكم في الفواتير وإدارة الوصول إلى الموارد في مشاريع مختلفة، باتباع مبدأ الحد الأدنى من الامتيازات. وإلا، سيتعين عليك وضع جميع الموارد في مشروع واحد. لتصميم Shared VPC، تندرج المشاريع تحت ثلاث فئات:
- المشروع المضيف (Host project): هو المشروع الذي يستضيف الموارد المشتركة. يمكن أن يكون هناك مشروع مضيف واحد فقط.
- مشروع الخدمة (Service project): المشاريع التي يمكنها الوصول إلى الموارد في المشروع المضيف. لا يمكن أن يكون المشروع مضيفًا وخدمة في نفس الوقت.
- المشروع المستقل (Standalone project): أي مشروع لا يستخدم Shared VPC.
ستتمكن فقط من التواصل بين الموارد التي تم إنشاؤها بعد تحديد مشاريعك المضيفة والخدمية. لن تكون أي موارد موجودة قبل ذلك جزءًا من Shared VPC.
VPC Network Peering
يمكن استخدام Shared VPCs عندما تنتمي جميع المشاريع إلى نفس المنظمة. ومع ذلك، إذا:
- كنت بحاجة إلى اتصال خاص عبر شبكات VPC.
- كانت شبكات VPC في مشاريع قد تنتمي إلى منظمات مختلفة.
- كنت ترغب في تحكم لامركزي، أي لا حاجة لتحديد مشاريع مضيفة، ومشاريع خادمة، وما إلى ذلك.
- كنت ترغب في إعادة استخدام الموارد الموجودة.
فإن VPC Network Peering هو الحل الصحيح. في القسم التالي، سأناقش كيفية ربط شبكة VPC الخاصة بك بالشبكات خارج GCP.
ربط البنية التحتية المحلية بشبكات GCP
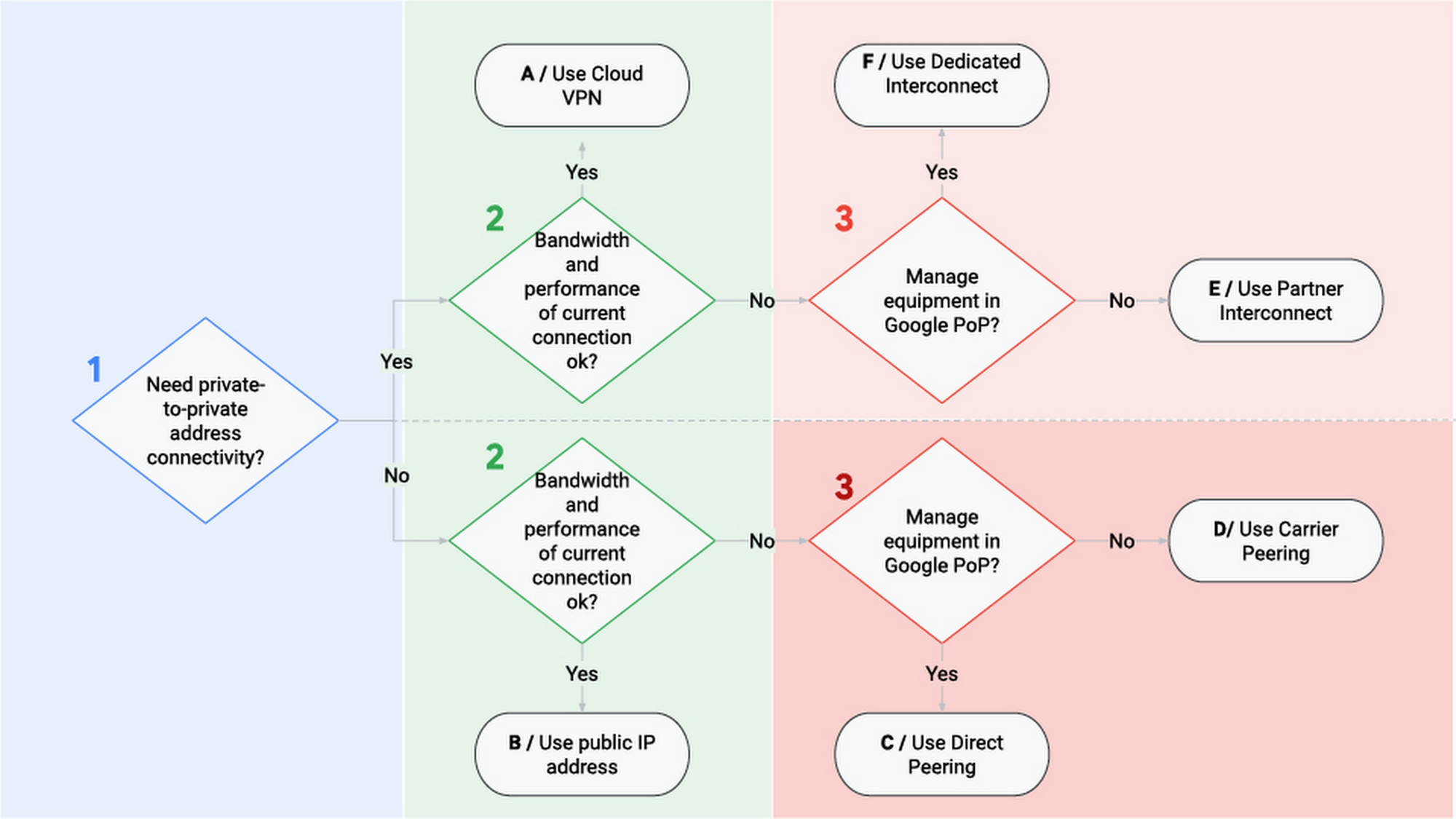
هناك ثلاثة خيارات لربط بنيتك التحتية المحلية بـ GCP:
- Cloud VPN
- Cloud Interconnect
- Cloud Peering
لكل منها قدرات وحالات استخدام وأسعار مختلفة سأصفها في الأقسام التالية.
Cloud VPN
مع Cloud VPN، تنتقل حركة المرور الخاصة بك عبر الإنترنت العام عبر نفق مشفر (encrypted tunnel). يبلغ الحد الأقصى لسعة كل نفق 3 جيجابت في الثانية، ويمكنك استخدام 8 أنفاق كحد أقصى للحصول على أداء أفضل. هاتان الخاصيتان تجعلان VPN الخيار الأقل تكلفة. يمكنك تعريف نوعين من المسارات بين شبكة VPC الخاصة بك وشبكاتك المحلية:
- المسارات الثابتة (Static routes): يجب عليك تعريفها وتحديثها يدويًا، على سبيل المثال عند إضافة شبكة فرعية جديدة. هذا ليس الخيار المفضل.
- المسارات الديناميكية (Dynamic routes): يتم التعامل مع المسارات تلقائيًا (تعريفها وتحديثها) لك باستخدام Cloud Router. هذا هو الخيار المفضل عندما يكون BGP متاحًا.
يتم تشفير وفك تشفير حركة المرور الخاصة بك بواسطة بوابات VPN Gateways (في GCP، هي موارد إقليمية). للحصول على اتصال أكثر قوة، فكر في استخدام بوابات وأنفاق VPN متعددة. في حالة الفشل، يضمن هذا التكرار استمرار تدفق حركة المرور.
Cloud Interconnect
مع Cloud VPN، تنتقل حركة المرور عبر الإنترنت العام. مع Cloud Interconnect، يوجد اتصال مادي مباشر بين شبكتك المحلية وشبكة VPC الخاصة بك. سيكون هذا الخيار أكثر تكلفة ولكنه سيوفر أفضل أداء. هناك نوعان من interconnect متاحان، اعتمادًا على كيفية رغبتك في تحقيق اتصالك بـ GCP:
- الربط المخصص (Dedicated interconnect): يوجد “كابل مباشر” يربط بنيتك التحتية بـ GCP. هذا هو الخيار الأسرع، بسعة تتراوح من 10 إلى 200 جيجابت في الثانية. ومع ذلك، فهو غير متاح في كل مكان: في وقت كتابة هذا المقال، يتوفر فقط في 62 موقعًا في العالم.
- ربط الشريك (Partner interconnect): تتصل من خلال مزود خدمة. هذا الخيار متاح جغرافيًا بشكل أكبر، ولكنه ليس بنفس سرعة الربط المخصص: من 50 ميجابت في الثانية إلى 10 جيجابت في الثانية.
Cloud Peering
لا تُعد Cloud Peering خدمة من GCP، ولكن يمكنك استخدامها لربط شبكتك بشبكة Google والوصول إلى خدمات مثل Youtube أو Drive أو خدمات GCP. حالة استخدام شائعة هي عندما تحتاج إلى الاتصال بـ Google ولكن لا ترغب في القيام بذلك عبر الإنترنت العام.
خدمات الشبكات الأخرى
موازنات التحميل (Load Balancers – LB)
في GCP، موازنات التحميل هي أجزاء من البرامج توزع طلبات المستخدمين بين مجموعة من المثيلات. قد يكون لموازن التحميل عدة خدمات خلفية (backends) مرتبطة به، مع قواعد لتحديد الخدمة الخلفية المناسبة لطلب معين. هناك أنواع مختلفة من موازنات التحميل. تختلف في نوع حركة المرور (HTTP مقابل TCP/UDP – الطبقة 7 أو الطبقة 4)، وما إذا كانت تتعامل مع حركة المرور الخارجية أو الداخلية، وما إذا كان نطاقها إقليميًا أو عالميًا:
- HTTP(s): موازن تحميل عالمي (Global LB) يتعامل مع طلبات HTTP(s)، ويوزع حركة المرور على مناطق متعددة بناءً على موقع المستخدم (إلى أقرب منطقة بها مثيلات متاحة) أو خرائط URL (يمكن تكوين موازن التحميل لإعادة توجيه الطلبات إلى URL/news إلى خدمة خلفية وإلى URL/videos إلى خدمة مختلفة). يمكنه استقبال حركة مرور IPv4 و IPv6 (ولكن هذا الأخير يتم إنهاؤه على مستوى موازن التحميل ويتم توكيله كـ IPv4 إلى الخدمات الخلفية) ولديه دعم أصلي لـ WebSockets.
- SSL Proxy LB: موازن تحميل عالمي يتعامل مع حركة مرور TCP المشفرة، ويدير شهادات SSL نيابة عنك.
- TCP Proxy LB: موازن تحميل عالمي يتعامل مع حركة مرور TCP غير المشفرة. مثل SSL Proxy LB، بشكل افتراضي، لن يحافظ على عنوان IP للعميل، ولكن يمكن تغيير ذلك.
- Network Load Balancer: موازن تحميل إقليمي (Regional LB) يتعامل مع حركة مرور TCP/UDP الخارجية، بناءً على عنوان IP والمنفذ.
- Internal Load Balancer: مثل Network LB، ولكن لحركة المرور الداخلية.
لمن يفضلون التعلم المرئي:

Cloud DNS
يُعد Cloud DNS مضيف نظام أسماء النطاقات (DNS) المُدار من Google، لكل من حركة المرور الداخلية والخارجية (العامة). سيقوم بربط عناوين URL مثل https://www.freecodecamp.org/ بعنوان IP. إنها الخدمة الوحيدة في GCP التي تتمتع باتفاقية مستوى خدمة بنسبة 100% – فهي متاحة 100% من الوقت.
Google Cloud CDN
يُعد Cloud CDN شبكة توصيل المحتوى (Content Delivery Network) من Google. إذا كان لديك بيانات لا تتغير كثيرًا (صور، مقاطع فيديو، CSS، إلخ)، فمن المنطقي تخزينها مؤقتًا بالقرب من المستخدمين. يوفر Cloud CDN 90 نقطة تواجد حافة (Edges Point of Presence – POP) لتخزين البيانات مؤقتًا بالقرب من المستخدمين النهائيين. بعد الطلب الأول، يمكن تخزين البيانات الثابتة في نقطة تواجد حافة، والتي عادة ما تكون أقرب بكثير إلى المستخدم من خوادمك الرئيسية. وبالتالي، في الطلبات اللاحقة، يمكنك استرداد البيانات بشكل أسرع من نقطة التواجد وتقليل الحمل على خوادمك الخلفية (backend servers).
أين يمكنك تشغيل تطبيقاتك في Google Cloud Platform؟
سأقدم 4 أماكن يمكن أن يعمل فيها الكود الخاص بك في GCP:
- Google Compute Engine
- Google Kubernetes Engine
- App Engine
- Cloud Functions

ملاحظة: هناك خيار خامس: Firebase هي منصة Google المتنقلة التي تساعدك على تطوير التطبيقات بسرعة.
محرك الحوسبة (Compute Engine – GCE)
يتيح لك Compute Engine تشغيل أجهزة افتراضية في GCP. سيكون هذا القسم أطول نظرًا لأن GCE يوفر البنية التحتية التي يعمل عليها GKE و GAE. في المقدمة، تحدثت عن الأنواع المختلفة من الأجهزة الافتراضية التي يمكنك إنشاؤها في GCE. الآن، سأغطي مكان تخزين البيانات، وكيفية نسخها احتياطيًا، وكيفية إنشاء مثيلات بجميع البيانات والتكوين الذي تحتاجه.
تخزين بيانات الأجهزة الافتراضية: الأقراص
يمكن تخزين بياناتك في الأقراص الثابتة (Persistent disks)، أو أقراص Local SSDs، أو في Cloud Storage.
الأقراص الثابتة (Persistent Disk)
توفر الأقراص الثابتة تخزينًا كتليًا (block storage) دائمًا وموثوقًا. إنها ليست محلية للجهاز. بدلاً من ذلك، يتم توصيلها بالشبكة، مما له إيجابياته وسلبياته:
- يمكن تغيير حجم الأقراص، أو إرفاقها، أو فصلها عن جهاز افتراضي حتى لو كان المثيل قيد الاستخدام.
- تتمتع بموثوقية عالية.
- يمكن للأقراص أن تبقى بعد حذف المثيل.
- إذا كنت بحاجة إلى مساحة أكبر، ما عليك سوى إرفاق المزيد من الأقراص.
- ستوفر الأقراص الأكبر حجمًا أداءً أعلى.
- كونها متصلة بالشبكة، فإنها أقل أداءً من الخيارات المحلية.
تتوفر أيضًا أقراص SSD persistent disks لأعباء العمل الأكثر تطلبًا. سيحتاج كل مثيل إلى قرص تمهيد واحد (boot disk) ويجب أن يكون من هذا النوع.
أقراص Local SSD
تُرفق أقراص Local SSDs بجهاز افتراضي لتوفير تخزين مؤقت عالي الأداء (ephemeral storage). اعتبارًا من الآن، يمكنك إرفاق ما يصل إلى ثمانية أقراص Local SSDs بسعة 375 جيجابايت لكل منها بنفس المثيل. ومع ذلك، ستفقد هذه البيانات إذا تم إيقاف الجهاز الافتراضي. لا يمكن إرفاق أقراص Local SSDs بجهاز إلا عند إنشائه، ولكن يمكنك إرفاق كل من أقراص Local SSDs والأقراص الثابتة بنفس الجهاز. كلا النوعين من الأقراص هما موارد مناطقية (zonal resources).
Cloud Storage
لقد غطينا GCS على نطاق واسع في قسم سابق. GCS ليس نظام ملفات، ولكن يمكنك استخدام GCS-Fuse لتركيب حاويات GCS كنظم ملفات في أنظمة Linux أو macOS. يمكنك أيضًا السماح للتطبيقات بتنزيل وتحميل البيانات إلى GCS باستخدام دلالات نظام الملفات القياسية.
النسخ الاحتياطي لبيانات الأجهزة الافتراضية: اللقطات (Snapshots)
اللقطات (Snapshots) هي نسخ احتياطية لأقراصك. لتقليل المساحة، يتم إنشاؤها بشكل تدريجي:
- النسخ الاحتياطي 1 يحتوي على جميع محتويات القرص الخاص بك.
- النسخ الاحتياطي 2 يحتوي فقط على البيانات التي تغيرت منذ النسخ الاحتياطي 1.
- النسخ الاحتياطي 3 يحتوي فقط على البيانات التي تغيرت منذ النسخ الاحتياطي 2، وهكذا.
هذا يكفي لاستعادة حالة القرص الخاص بك. على الرغم من أنه يمكن التقاط اللقطات دون إيقاف المثيل، إلا أن أفضل الممارسات هي تقليل نشاطه على الأقل، والتوقف عن كتابة البيانات إلى القرص، ومسح المخازن المؤقتة (flush buffers). يساعدك هذا على التأكد من حصولك على تمثيل دقيق لمحتوى القرص.
الصور (Images)
تشير الصور (Images) إلى صور نظام التشغيل (operating system images) اللازمة لإنشاء أقراص تمهيد (boot disks) لمثيلاتك. هناك نوعان من الصور:
- الصور العامة (Public images): يتم توفيرها وصيانتها بواسطة Google، ومجتمعات المصادر المفتوحة، وموردي الطرف الثالث. جاهزة للاستخدام بمجرد إنشاء مشروعك. متاحة لأي شخص.
- الصور المخصصة (Custom images): صور قمت بإنشائها. ترتبط بالمشروع الذي أنشأتها فيه ولكن يمكنك مشاركتها مع مشاريع أخرى. يمكنك إنشاء صور من أقراص ثابتة وصور أخرى، سواء من نفس المشروع أو مشاركة من مشروع آخر.
يمكن تجميع الصور ذات الصلة في عائلات صور (image families) لتبسيط إدارة إصدارات الصور المختلفة. بالنسبة للصور المستندة إلى Linux، يمكنك مشاركتها أيضًا عن طريق تصديرها إلى Cloud Storage كملف tar.gz.
قد تسأل نفسك ما هو الفرق بين الصورة واللقطة. بشكل أساسي، غرضهما. تُستخدم اللقطات كنسخ احتياطية تدريجية لقرص بينما تُنشأ الصور لتشغيل أجهزة افتراضية جديدة وتكوين قوالب المثيلات (instance templates).
ملاحظة حول الصور مقابل نصوص بدء التشغيل (startup scripts): للإعدادات البسيطة، تعد نصوص بدء التشغيل خيارًا أيضًا. يمكن استخدامها لاختبار التغييرات بسرعة، ولكن ستستغرق الأجهزة الافتراضية وقتًا أطول لتكون جاهزة مقارنة باستخدام صورة تم تثبيت جميع البرامج المطلوبة فيها وتكوينها، وما إلى ذلك.
مجموعات الأجهزة الافتراضية (Instance Groups)
تتيح لك مجموعات المثيلات التعامل مع مجموعة من المثيلات كوحدة واحدة، وتأتي بنوعين:
- مجموعة مثيلات غير مُدارة (Unmanaged instance group): تتكون من مجموعة غير متجانسة من المثيلات التي تتطلب إعدادات تكوين فردية.
- مجموعة مثيلات مُدارة (Managed instance group – MIG): هذا هو الخيار المفضل عندما يكون ذلك ممكنًا. تبدو جميع الأجهزة متشابهة، مما يسهل تكوينها، وإنشاءها في مناطق متعددة (توافر عالٍ)، واستبدالها إذا أصبحت غير صحية (شفاء تلقائي – auto-healing)، وموازنة حركة المرور بينها، وإنشاء مثيلات جديدة إذا زادت حركة المرور (توسع أفقي – horizontal scaling).
لإنشاء MIGs، تحتاج إلى تعريف قالب مثيل (instance template)، وتحديد نوع جهازك، والمنطقة، وصورة نظام التشغيل، ونصوص بدء التشغيل وإيقاف التشغيل، وما إلى ذلك. قوالب المثيلات غير قابلة للتغيير. لتحديث MIG، تحتاج إلى إنشاء قالب جديد واستخدام Managed Instance Group Updated لنشر الإصدار الجديد على كل جهاز في المجموعة. يمكن استخدام هذه الوظيفة لإنشاء اختبارات الكناري (canary tests)، ونشر تغييراتك على جزء صغير من أجهزتك أولاً. زر هذا الرابط لمعرفة المزيد حول توصيات Google لضمان أن التطبيق المنشور عبر مجموعة مثيلات مُدارة يمكنه التعامل مع الحمل حتى لو فشلت منطقة بأكملها.
أفضل ممارسات الأمان لـ GCE
لزيادة أمان بنيتك التحتية في GCE، ألقِ نظرة على:
- Shielded VMs: منع الوصول إلى المثيلات من الإنترنت العام.
- الصور الموثوقة (Trusted images): للتأكد من أن المستخدمين يمكنهم فقط إنشاء أقراص من الصور في مشاريع محددة.
محرك التطبيقات (App Engine)
يُعد App Engine خيارًا رائعًا عندما تريد التركيز على الكود والسماح لـ Google بالتعامل مع بنيتك التحتية. ما عليك سوى اختيار المنطقة التي سيتم نشر تطبيقك فيها (لا يمكن تغيير ذلك بمجرد تعيينه). من بين حالات الاستخدام الرئيسية له المواقع الإلكترونية، وتطبيقات الهاتف المحمول، والخدمات الخلفية للألعاب. يمكنك تحديث إصدار تطبيقك الذي يعمل بسهولة عبر سطر الأوامر أو Google Console. أيضًا، إذا كنت بحاجة إلى نشر تحديث محفوف بالمخاطر لتطبيقك، فيمكنك تقسيم حركة المرور بين الإصدار القديم والإصدار المحفوف بالمخاطر لنشر الكناري (canary deployment). بمجرد أن تكون راضيًا عن النتائج، يمكنك توجيه كل حركة المرور إلى الإصدار الجديد. هناك بيئتان لـ App Engine:
- القياسية (Standard): يمكن لهذا الإصدار التوسع بسرعة صعودًا أو هبوطًا (حتى إلى صفر مثيل) للتكيف مع الطلب. حاليًا، يتم دعم عدد قليل فقط من لغات البرمجة (Go، Java، PHP، و Python) وليس لديك وصول إلى VPC (بما في ذلك اتصالات VPN). يمكن تقليص حجمه إلى صفر مثيل.
- المرنة (Flexible): يعمل الكود الخاص بك في حاويات Docker في GCE، وبالتالي فهو أكثر مرونة من البيئة القياسية. ومع ذلك، فإن إنشاء مثيلات جديدة أبطأ ولا يمكن تقليص حجمه إلى صفر مثيل. إنه مناسب لحركة المرور الأكثر اتساقًا.
بغض النظر عن البيئة، لا توجد تكاليف مقدمة وتدفع فقط مقابل ما تستخدمه (يتم الفوترة في الثانية). Memcache مدمج في App Engine، مما يمنحك إمكانية الاختيار بين ذاكرة تخزين مؤقت مشتركة (افتراضي، خيار مجاني) أو ذاكرة تخزين مؤقت مخصصة لأداء أفضل. زر هذا الرابط لمعرفة المزيد حول أفضل الممارسات التي يجب عليك اتباعها لزيادة أداء تطبيقك إلى أقصى حد.
محرك Google Kubernetes (GKE)
يُعد Kubernetes نظامًا مفتوح المصدر لتنسيق الحاويات (container orchestration system)، تم تطويره بواسطة Google. Kubernetes موضوع واسع جدًا بحد ذاته ولن أغطيه هنا. تحتاج فقط إلى معرفة أن GKE يسهل تشغيل وإدارة مجموعات Kubernetes الخاصة بك على GCP. توفر Google أيضًا Container Registry لتخزين صور الحاويات الخاصة بك – فكر في الأمر كـ Docker Hub الخاص بك.
ملاحظة: يمكنك استخدام Cloud Build لتشغيل عمليات البناء الخاصة بك في GCP، ومن بين أمور أخرى، إنتاج صور Docker وتخزينها في Container Registry. يمكن لـ Cloud Build استيراد الكود الخاص بك من Google Cloud Storage، Cloud Source Repository، GitHub، أو Bitbucket.
وظائف السحابة (Cloud Functions)
وظائف السحابة (Cloud Functions) هي ما يعادل وظائف Lambda في AWS. وظائف السحابة لا خادم لها (serverless). تتيح لك التركيز على الكود وعدم القلق بشأن البنية التحتية التي سيعمل عليها. مع Cloud Functions، من السهل الاستجابة للأحداث مثل التحميلات إلى حاوية GCS أو الرسائل في موضوع Pub/Sub. يتم محاسبتك فقط على الوقت الذي تعمل فيه وظيفتك استجابة لحدث ما.
العمل مع البيانات الضخمة (Big Data) في Google Cloud Platform
بيج كويري (BigQuery)

يُعد BigQuery مستودع بيانات Google بدون خادم (serverless data warehousing) ويوفر إمكانيات تحليلية لقواعد البيانات بحجم البيتابايت. يقوم BigQuery تلقائيًا بعمل نسخ احتياطية لجداولك، ولكن يمكنك دائمًا تصديرها إلى GCS لتكون في الجانب الآمن – مع تحمل تكاليف إضافية. يمكن استيعاب البيانات على دفعات (batches) (على سبيل المثال، من حاوية GCS) أو من تدفق (stream) بتنسيقات متعددة: CSV، JSON، Parquet، أو Avro (الأكثر أداءً). أيضًا، يمكنك استعلام البيانات الموجودة في مصادر خارجية، تسمى المصادر الموحدة (federated sources)، على سبيل المثال، حاويات GCS.
يمكنك التفاعل مع بياناتك في BigQuery باستخدام SQL عبر Google Console، سطر الأوامر (تشغيل أوامر مثل bq query 'SELECT field FROM ....)، REST API، أو الكود باستخدام مكتبات العميل (client libraries). تتيح لك وظائف معرفة من قبل المستخدم (User-Defined Functions) دمج استعلامات SQL مع وظائف JavaScript لإنشاء عمليات معقدة.
يُعد BigQuery مخزن بيانات عموديًا (columnar data store): تُخزن السجلات في أعمدة. الجداول هي مجموعات من الأعمدة ومجموعات البيانات (datasets) هي مجموعات من الجداول. المهام (Jobs) هي إجراءات لتحميل أو تصدير أو استعلام أو نسخ البيانات التي يقوم BigQuery بتشغيلها نيابة عنك. طرق العرض (Views) هي جداول افتراضية معرفة بواسطة استعلام SQL وهي مفيدة لمشاركة البيانات مع الآخرين عندما تريد التحكم بدقة في ما يمكنهم الوصول إليه. مفهومان مهمان يتعلقان بالجداول هما:
- الجداول المقسمة (Partitioned tables): للحد من كمية البيانات التي تحتاج إلى استعلامها، يمكن تقسيم الجداول إلى أقسام. يمكن القيام بذلك بناءً على وقت الاستيعاب أو تضمين عمود طابع زمني أو تاريخ أو نطاق عدد صحيح. بهذه الطريقة، من السهل الاستعلام عن فترات معينة دون استعلام الجدول بالكامل. لتقليل التكاليف، يمكنك تحديد فترة انتهاء صلاحية يتم بعدها حذف القسم.
- الجداول المجمعة (Clustered tables): يتم تجميع البيانات حسب العمود (على سبيل المثال، order_id). عندما تستعلم جدولك، سيتم قراءة الصفوف المرتبطة بهذا العمود فقط. سيقوم BigQuery بإجراء هذا التجميع تلقائيًا بناءً على عمود واحد أو أكثر.
باستخدام أدوار IAM، يمكنك التحكم في الوصول على مستوى المشروع، أو مجموعة البيانات، أو طريقة العرض، ولكن ليس على مستوى الجدول. الأدوار معقدة لـ BigQuery، لذا أوصي بالتحقق من الوثائق. على سبيل المثال، يسمح دور jobUser فقط بتشغيل المهام بينما يسمح دور user role بتشغيل المهام وإنشاء مجموعات البيانات (ولكن ليس الجداول). تعتمد تكاليفك على مقدار البيانات التي تخزنها وتدفقها إلى BigQuery ومقدار البيانات التي تستعلمها. لتقليل التكاليف، يقوم BigQuery تلقائيًا بتخزين الاستعلامات السابقة مؤقتًا (لكل مستخدم). يمكن تعطيل هذا السلوك. عندما لا تقوم بتحرير البيانات لمدة 90 يومًا، فإنها تنتقل تلقائيًا إلى فئة تخزين أرخص. تدفع مقابل ما تستخدمه، ولكن من الممكن اختيار سعر ثابت (فقط إذا كنت بحاجة إلى أكثر من 2000 فتحة مخصصة افتراضيًا). تحقق من هذه الروابط لمعرفة كيفية تحسين أدائك وتكاليفك.
بب/سب السحابي (Cloud Pub/Sub)
يُعد Pub/Sub خدمة قائمة انتظار الرسائل المُدارة بالكامل من Google، مما يتيح لك فصل الناشرين (publishers) (إضافة رسائل إلى قائمة الانتظار) والمشتركين (subscribers) (استهلاك الرسائل من قائمة الانتظار). على الرغم من أنه مشابه لـ Kafka، إلا أن Pub/Sub ليس بديلاً مباشرًا. يمكن دمجهما في نفس خط الأنابيب (pipeline) (يتم نشر Kafka محليًا أو حتى في GKE). توجد مكونات إضافية مفتوحة المصدر لربط Kafka بـ GCP، مثل Kafka Connect. يضمن Pub/Sub تسليم كل رسالة مرة واحدة على الأقل ولكنه لا يضمن معالجة الرسائل بالترتيب. عادة ما يتم ربطه بـ Dataflow لمعالجة البيانات، والتأكد من معالجة الرسائل بالترتيب، وما إلى ذلك. يدعم Pub/Sub كلا وضعي الدفع (push) والسحب (pull):
- الدفع (Push): تُرسل الرسائل إلى المشتركين، مما يؤدي إلى زمن استجابة أقل.
- السحب (Pull): يسحب المشتركون الرسائل من المواضيع، وهو مناسب بشكل أفضل لحجم كبير من الرسائل.
مقارنة بين Cloud Pub/Sub و Cloud Tasks
يُعد Cloud Tasks خدمة أخرى مُدارة بالكامل لتنفيذ المهام بشكل غير متزامن وإدارة الرسائل بين الخدمات. ومع ذلك، هناك اختلافات بين Cloud Tasks و Pub/Sub:
- في Pub/Sub، يتم فصل الناشرين والمشتركين. لا يعرف الناشرون شيئًا عن مشتركيهم. عندما ينشرون رسالة، فإنهم يتسببون ضمنيًا في رد فعل واحد أو أكثر من المشتركين على حدث النشر.
- في Cloud Tasks، يظل الناشر متحكمًا في التنفيذ. بالإضافة إلى ذلك، يوفر Cloud Tasks ميزات أخرى غير متوفرة لـ Pub/Sub مثل جدولة أوقات تسليم محددة، وضوابط معدل التسليم، وإعادة المحاولة القابلة للتكوين، والوصول إلى المهام الفردية في قائمة الانتظار وإدارتها، وإلغاء تكرار إنشاء المهام/الرسائل. لمزيد من التفاصيل، تحقق من هذا الرابط.
تدفق البيانات السحابي (Cloud Dataflow)
يُعد Cloud Dataflow خدمة Google المُدارة لمعالجة بيانات التدفق والدفعات (stream and batch data processing)، بناءً على Apache Beam. يمكنك تعريف خطوط أنابيب (pipelines) ستحول بياناتك، على سبيل المثال قبل استيعابها في خدمة أخرى مثل BigQuery، BigTable، أو Cloud ML. يمكن لنفس خط الأنابيب معالجة بيانات التدفق والدفعات. نمط شائع هو تدفق البيانات إلى Pub/Sub، على سبيل المثال من أجهزة إنترنت الأشياء (IoT devices)، ومعالجتها في Dataflow، وتخزينها للتحليل في BigQuery. لكن Pub/Sub لا يضمن أن الترتيب الذي تُدفع به الرسائل إلى المواضيع سيكون هو الترتيب الذي تُستهلك به الرسائل. ومع ذلك، يمكن القيام بذلك باستخدام Dataflow.
معالجة البيانات السحابية (Cloud Dataproc)
يُعد Cloud Dataproc نظام Hadoop و Spark المُدار من Google. يتيح لك إنشاء وإدارة مجموعاتك بسهولة وإيقاف تشغيلها عندما لا تستخدمها، لتقليل التكاليف. يمكن استخدام Dataproc فقط لمعالجة بيانات الدفعات، بينما يمكن لـ Dataflow التعامل أيضًا مع بيانات التدفق. توصي Google باستخدام Dataproc لترحيل “رفع واستفادة” (lift and leverage migration) لمجموعات Hadoop المحلية الخاصة بك إلى السحابة:
- تقليل التكاليف عن طريق إيقاف تشغيل مجموعتك عندما لا تستخدمها.
- الاستفادة من البنية التحتية لـ Google.
- استخدام بعض الأجهزة الافتراضية القابلة للإيقاف المؤقت لتقليل التكاليف.
- إضافة أقراص ثابتة أكبر (SSD) لتحسين الأداء.
- يمكن لـ BigQuery أن يحل محل Hive ويمكن لـ BigTable أن يحل محل HBase.
- يحل Cloud Storage محل HDFS. ما عليك سوى تحميل بياناتك إلى GCS وتغيير البادئات hdfs:// إلى gs://.
وإلا، يجب عليك اختيار Cloud Dataflow.
إعداد البيانات (Dataprep)
يوفر Cloud Dataprep واجهة قائمة على الويب لتنظيف وإعداد بياناتك قبل المعالجة. تتضمن تنسيقات الإدخال والإخراج، من بين أمور أخرى، CSV، JSON، و Avro. بعد تعريف التحويلات، سيتم تشغيل مهمة Dataflow. يمكن تصدير البيانات المحولة إلى GCS، BigQuery، إلخ.

مُلحّن السحابة (Cloud Composer)
يُعد Cloud Composer خدمة Apache Airflow المُدارة بالكامل من Google لإنشاء وجدولة ومراقبة وإدارة سير العمل (workflows). يتعامل مع جميع البنية التحتية نيابة عنك حتى تتمكن من التركيز على دمج الخدمات التي وصفتها أعلاه لإنشاء سير العمل الخاص بك. تحت الغطاء، سيتم إنشاء مجموعة GKE مع Airflow فيها وسيتم استخدام GCS لتخزين الملفات.
الذكاء الاصطناعي وتعلم الآلة في Google Cloud Platform
تغطية أساسيات تعلم الآلة ستستغرق مقالًا آخر. لذا هنا، أفترض أنك على دراية بها وسأوضح لك كيفية تدريب ونشر نماذجك في GCP. سنلقي نظرة أيضًا على واجهات برمجة التطبيقات (APIs) المتاحة للاستفادة من قدرات تعلم الآلة من Google في خدماتك، حتى لو لم تكن خبيرًا في هذا المجال.

منصة الذكاء الاصطناعي (AI Platform)
توفر لك AI Platform منصة مُدارة بالكامل لاستخدام مكتبات تعلم الآلة مثل Tensorflow. ما عليك سوى التركيز على نموذجك وستتولى Google جميع البنية التحتية اللازمة لتدريبه. بعد تدريب نموذجك، يمكنك استخدامه للحصول على تنبؤات عبر الإنترنت وعلى دفعات (online and batch predictions).
التعلم الآلي التلقائي السحابي (Cloud AutoML)
تتيح لك Google استخدام بياناتك لتدريب نماذجها. يمكنك الاستفادة من النماذج لبناء تطبيقات تعتمد على معالجة اللغة الطبيعية (على سبيل المثال، تطبيقات تصنيف المستندات أو تحليل المشاعر)، ومعالجة الكلام، والترجمة الآلية، أو معالجة الفيديو (تصنيف الفيديو أو اكتشاف الكائنات).
استكشاف وتصور البيانات في Google Cloud Platform
استوديو البيانات السحابي (Cloud Data Studio)
يتيح لك Data Studio إنشاء تصورات ولوحات معلومات بناءً على البيانات الموجودة في خدمات Google (YouTube Analytics، Sheets، AdWords، تحميل محلي)، و Google Cloud Platform (BigQuery، Cloud SQL، GCS، Spanner)، والعديد من خدمات الطرف الثالث، مع تخزين تقاريرك في Google Drive. لا يُعد Data Studio جزءًا من GCP، بل من G-Suite، وبالتالي لا تتم إدارة أذوناته باستخدام IAM. لا توجد تكاليف إضافية لاستخدام Data Studio، بخلاف تخزين البيانات، والاستعلامات في BigQuery، وما إلى ذلك. يمكن استخدام التخزين المؤقت (Caching) لتحسين الأداء وتقليل التكاليف.
مختبر البيانات السحابي (Cloud Datalab)
يتيح لك Datalab استكشاف وتحليل وتصور البيانات في BigQuery، ML Engine، Compute Engine، Cloud Storage، و Stackdriver. يعتمد على دفاتر ملاحظات Jupyter notebooks ويدعم كود Python، SQL، و Javascript. يمكن مشاركة دفاتر ملاحظاتك عبر Cloud Source Repository. Cloud Datalab نفسه مجاني، ولكنه سينشئ جهازًا افتراضيًا في GCE سيتم محاسبتك عليه.
الأمان في Google Cloud Platform
التشفير في Google Cloud Platform
تقوم Google Cloud بتشفير البيانات سواء أثناء السكون (at rest) (البيانات المخزنة على القرص) أو أثناء النقل (in transit) (البيانات التي تنتقل في الشبكة)، باستخدام خوارزمية AES المطبقة عبر Boring SSL. يمكنك إدارة مفاتيح التشفير بنفسك (سواء بتخزينها في GCP أو محليًا) أو السماح لـ Google بالتعامل معها.
التشفير أثناء السكون (Encryption at Rest)
تقوم GCP بتشفير البيانات المخزنة أثناء السكون بشكل افتراضي. سيتم تقسيم بياناتك إلى أجزاء (chunks). يتم توزيع كل جزء عبر أجهزة مختلفة وتشفيره بمفتاح فريد، يسمى مفتاح تشفير البيانات (data encryption key – DEK). يتم إنشاء المفاتيح وإدارتها بواسطة Google ولكن يمكنك أيضًا إدارة المفاتيح بنفسك، كما سنرى لاحقًا في هذا الدليل.
التشفير أثناء النقل (Encryption in Transit)
لإضافة طبقة أمان إضافية، يتم تشفير جميع الاتصالات بين خدمتين من خدمات GCP أو من بنيتك التحتية إلى GCP على طبقة شبكة واحدة أو أكثر. لن يتم اختراق بياناتك إذا تم اعتراض رسائلك.
خدمة إدارة المفاتيح السحابية (Cloud Key Management Service – KMS)
كما ذكرت سابقًا، يمكنك السماح لـ Google بإدارة المفاتيح لك أو يمكنك إدارتها بنفسك. Google KMS هي الخدمة التي تتيح لك إدارة مفاتيح التشفير الخاصة بك. يمكنك إنشاء وتدوير وتدمير مفاتيح التشفير المتماثلة. يتم تسجيل جميع الأنشطة المتعلقة بالمفاتيح في السجلات. تُشار إلى هذه المفاتيح باسم مفاتيح التشفير المدارة من قبل العميل (customer-managed encryption keys). في GCS، تُستخدم لتشفير:
- بيانات الكائن.
- مجموع التحقق CRC32C للكائن.
- تجزئة MD5 للكائن.
وتستخدم Google مفاتيح من جانب الخادم للتعامل مع بقية البيانات الوصفية (metadata)، بما في ذلك اسم الكائن. يتم أيضًا تشفير مفاتيح DEKs المستخدمة لتشفير بياناتك باستخدام مفاتيح تشفير المفاتيح (key encryption keys – KEKs)، في عملية تسمى تشفير المغلف (envelope encryption). بشكل افتراضي، يتم تدوير مفاتيح KEKs كل 90 يومًا. من المهم ملاحظة أن KMS لا تخزن الأسرار. KMS هو مستودع مركزي لمفاتيح KEKs. فقط المفاتيح التي تحتاجها GCP لتشفير الأسرار المخزنة في مكان آخر، على سبيل المثال في إدارة الأسرار (Secrets management).
ملاحظة: بالنسبة لـ GCE و GCS، لديك إمكانية الاحتفاظ بمفاتيحك محليًا والسماح لـ Google باستردادها لتشفير وفك تشفير بياناتك. تُعرف هذه المفاتيح باسم مفاتيح التشفير التي يوفرها العميل (customer-supplied keys).
الوكيل المدرك للهوية (Identity-Aware Proxy – IAP)
يتيح لك Identity-Aware Proxy التحكم في الوصول إلى تطبيقات GCP عبر HTTPs دون تثبيت أي برنامج VPN أو إضافة كود إضافي في تطبيقك للتعامل مع تسجيل الدخول. تطبيقاتك مرئية للإنترنت العام، ولكن يمكن الوصول إليها فقط للمستخدمين المصرح لهم، مما يطبق نموذج أمان الوصول بدون ثقة (zero-trust security access model). علاوة على ذلك، باستخدام إعادة توجيه TCP، يمكنك منع خدمات مثل SSH من التعرض للإنترنت العام.
درع السحابة (Cloud Armor)
يحمي Cloud Armor بنيتك التحتية من هجمات الحرمان من الخدمة الموزعة (distributed denial of service – DDoS). يمكنك تعريف قواعد (على سبيل المثال، لإدراج عناوين IP أو نطاقات CIDR معينة في القائمة البيضاء أو رفضها) لإنشاء سياسات أمان، والتي يتم فرضها على مستوى نقطة التواجد (Point of Presence) (أقرب إلى مصدر الهجوم). يمنحك Cloud Armor خيار معاينة تأثيرات سياساتك قبل تفعيلها.
منع فقدان البيانات السحابي (Cloud Data Loss Prevention – DLP)
يُعد Data Loss Prevention خدمة مُدارة بالكامل مصممة لمساعدتك على اكتشاف وتصنيف وحماية البيانات الحساسة، مثل:
- معلومات التعريف الشخصية (Personable Identifiable Information – PII): الاسم، رقم الضمان الاجتماعي، رقم رخصة القيادة، رقم الحساب المصرفي، رقم جواز السفر، عنوان البريد الإلكتروني، وما إلى ذلك.
- الأسرار (Secrets).
- بيانات الاعتماد (Credentials).
تُدمج DLP مع GCS، BigQuery، و Datastore. أيضًا، يمكن أن يكون مصدر البيانات خارج GCP. يمكنك تحديد نوع البيانات التي تهتم بها، والتي تسمى نوع المعلومات (info type)، أو تعريف أنواعك الخاصة (بناءً على قواميس الكلمات والعبارات أو بناءً على تعبيرات regex)، أو السماح لـ Google باستخدام الافتراضي الذي قد يستغرق وقتًا طويلاً لكميات كبيرة من البيانات. لكل نتيجة، ستُرجع DLP احتمالية مطابقة هذه القطعة من البيانات لنوع معلومات معين: LIKELIHOOD_UNSPECIFIED، VERY_UNLIKELY، UNLIKELY، POSSIBLE، LIKELY، VERY_LIKELY. بعد اكتشاف جزء من PII، يمكن لـ DLP تحويله بحيث لا يمكن ربطه مرة أخرى بالمستخدم. تستخدم DLP تقنيات متعددة لإلغاء تحديد هوية بياناتك الحساسة مثل الترميز (tokenization)، والتجميع (bucketing)، وتحويل التاريخ (date shifting). يمكن لـ DLP اكتشاف وإخفاء البيانات الحساسة في الصور أيضًا.
التحكم في خدمة VPC (VPC Service Control)
يساعد VPC Service Control في منع تسرب البيانات (data exfiltration). يتيح لك تحديد محيط حول الموارد التي تريد حمايتها. يمكنك تحديد الخدمات والشبكات التي يمكن من خلالها الوصول إلى هذه الموارد.
ماسح أمان الويب السحابي (Cloud Web Security Scanner)
يقوم Cloud Web Security Scanner بمسح التطبيقات التي تعمل في Compute Engine، GKE، و App Engine بحثًا عن الثغرات الأمنية الشائعة مثل كلمات المرور في نص واضح، ورؤوس غير صالحة، ومكتبات قديمة، وهجمات البرمجة عبر المواقع (cross-site scripting attacks). إنه يحاكي مستخدمًا حقيقيًا يحاول النقر على أزرارك، وإدخال نص في حقول النص الخاصة بك، وما إلى ذلك. إنه جزء من Cloud Security Command Center.
موارد إضافية لـ Google Cloud Platform
إذا كنت مهتمًا بمعرفة المزيد عن GCP، أوصي بالتحقق من امتحانات الممارسة المجانية للشهادات المختلفة. سواء كنت تستعد لشهادة GCP أم لا، يمكنك استخدامها للعثور على فجوات في معرفتك:
- Professional Cloud Developer
- Professional Cloud Data Engineer
- Professional Cloud Network Engineer
- Professional Cloud Security Engineer
- Professional Cloud DevOps Engineer
- Professional Cloud Machine Learning Engineer
- Professional Cloud Architect
ملاحظة: تستند بعض الأسئلة إلى دراسات حالة. سيتم توفير روابط لدراسات الحالة في الامتحانات حتى يكون لديك السياق الكامل لفهم السؤال والإجابة عليه بشكل صحيح.
اختبر معلوماتك
لقد استخلصت 10 أسئلة من بعض الامتحانات المذكورة أعلاه. بعضها مباشر جدًا. يتطلب البعض الآخر تفكيرًا عميقًا وتحديد أفضل حل عندما يكون هناك أكثر من خيار واحد ممكن.
السؤال 1:
يقوم عميلك بنقل تطبيقات شركته إلى Google Cloud. يريد فريق الأمان رؤية تفصيلية لجميع الموارد في المنظمة. أنت تستخدم Resource Manager لتعيين نفسك كـ Organization Administrator. ما هي أدوار Cloud Identity and Access Management (Cloud IAM) التي يجب أن تمنحها لفريق الأمان مع اتباع الممارسات الموصى بها من Google؟
- أ. Organization viewer, Project owner
- ب. Organization viewer, Project viewer
- ج. Organization administrator, Project browser
- د. Project owner, Network administrator
السؤال 2:
تريد شركتك تجربة السحابة بمخاطر منخفضة. إنهم يريدون أرشفة حوالي 100 تيرابايت من بيانات سجلاتهم إلى السحابة واختبار ميزات التحليلات بدون خادم المتاحة لهم هناك، مع الاحتفاظ بهذه البيانات كنسخة احتياطية طويلة الأجل للتعافي من الكوارث. ما هي الخطوتان اللتان يجب عليهما اتخاذهما؟ (اختر اثنتين)
- أ. تحميل السجلات إلى BigQuery.
- ب. تحميل السجلات إلى Cloud SQL.
- ج. استيراد السجلات إلى Cloud Logging.
- د. إدراج السجلات في Cloud Bigtable.
- هـ. تحميل ملفات السجلات إلى Cloud Storage.
السؤال 3:
تريد شركتك تتبع ما إذا كان شخص ما حاضرًا في غرفة اجتماعات محجوزة لاجتماع مجدول. هناك 1000 غرفة اجتماعات عبر 5 مكاتب في 3 قارات. كل غرفة مجهزة بمستشعر حركة يبلغ عن حالته كل ثانية. تريد دعم احتياجات استيعاب البيانات لشبكة المستشعرات هذه. يجب أن تأخذ البنية التحتية المستقبلة في الاعتبار احتمال أن تكون الأجهزة ذات اتصال غير متسق. ما هو الحل الذي يجب عليك تصميمه؟
- أ. جعل كل جهاز ينشئ اتصالًا ثابتًا بمثيل Compute Engine ويكتب الرسائل إلى تطبيق مخصص.
- ب. جعل الأجهزة تستعلم عن الاتصال بـ Cloud SQL وتدرج أحدث الرسائل على فترات منتظمة في جدول خاص بالجهاز.
- ج. جعل الأجهزة تستعلم عن الاتصال بـ Cloud Pub/Sub وتنشر أحدث الرسائل على فترات منتظمة في موضوع مشترك لجميع الأجهزة.
- د. جعل الأجهزة تنشئ اتصالًا ثابتًا بتطبيق App Engine أمامه Cloud Endpoints، الذي يستوعب الرسائل ويكتبها إلى Cloud Datastore.
السؤال 4:
لتقليل التكاليف، طلب مدير الهندسة من جميع المطورين نقل موارد بنيتهم التحتية للتطوير من الأجهزة الافتراضية المحلية (on-premises VMs) إلى Google Cloud. تمر هذه الموارد بأحداث بدء/إيقاف متعددة خلال اليوم وتتطلب استمرار الحالة. طُلب منك تصميم عملية تشغيل بيئة تطوير في Google Cloud مع توفير رؤية التكلفة لقسم المالية. ما هي الخطوتان اللتان يجب عليك اتخاذهما؟ (اختر اثنتين)
- أ. استخدام الأقراص الثابتة لتخزين الحالة. بدء وإيقاف الجهاز الافتراضي حسب الحاجة.
- ب. استخدام العلامة –auto-delete على جميع الأقراص الثابتة قبل إيقاف الجهاز الافتراضي.
- ج. تطبيق تسمية استخدام CPU للجهاز الافتراضي وتضمينها في تصدير فواتير BigQuery.
- د. استخدام تصدير فواتير BigQuery والتسميات لربط التكلفة بالمجموعات.
- هـ. تخزين جميع الحالات في Local SSD، وأخذ لقطة للأقراص الثابتة وإنهاء الجهاز الافتراضي.
السؤال 5:
طلب فريق إدارة قواعد البيانات مساعدتك في تحسين أداء خادم قاعدة البيانات الجديد الذي يعمل على Compute Engine. تُستخدم قاعدة البيانات لاستيراد وتطبيع إحصائيات أداء الشركة. تم بناؤها باستخدام MySQL الذي يعمل على Debian Linux. لديهم جهاز افتراضي n1-standard-8 مع 80 جيجابايت من قرص SSD zonal persistent disk لا يمكنهم إعادة تشغيله حتى حدث الصيانة التالي. ما الذي يجب عليهم تغييره للحصول على أداء أفضل من هذا النظام في أقرب وقت ممكن وبطريقة فعالة من حيث التكلفة؟
- أ. زيادة ذاكرة الجهاز الافتراضي إلى 64 جيجابايت.
- ب. إنشاء جهاز افتراضي جديد يعمل بنظام PostgreSQL.
- ج. تغيير حجم قرص SSD persistent disk ديناميكيًا إلى 500 جيجابايت.
- د. ترحيل مستودع مقاييس الأداء الخاص بهم إلى BigQuery.
السؤال 6:
لدى مؤسستك تطبيق ويب من 3 طبقات منتشر في نفس Google Cloud Virtual Private Cloud (VPC). تتوسع كل طبقة (الويب، API، وقاعدة البيانات) بشكل مستقل عن الأخرى. يجب أن تتدفق حركة مرور الشبكة من طبقة الويب إلى طبقة API، ثم إلى طبقة قاعدة البيانات. يجب ألا تتدفق حركة المرور بين طبقة الويب وطبقة قاعدة البيانات. كيف يجب عليك تكوين الشبكة بأقل عدد من الخطوات؟
- أ. إضافة كل طبقة إلى شبكة فرعية مختلفة.
- ب. إعداد جدران حماية قائمة على البرامج على الأجهزة الافتراضية الفردية.
- ج. إضافة علامات إلى كل طبقة وإعداد مسارات للسماح بتدفق حركة المرور المطلوبة.
- د. إضافة علامات إلى كل طبقة وإعداد قواعد جدار حماية للسماح بتدفق حركة المرور المطلوبة.
السؤال 7:
أنت تقوم بتطوير تطبيق على Google Cloud سيقوم بتسمية المعالم الشهيرة في صور المستخدمين. أنت تحت ضغط تنافسي لتطوير نموذج تنبؤي بسرعة. تحتاج إلى إبقاء تكاليف الخدمة منخفضة. ماذا يجب أن تفعل؟
- أ. بناء تطبيق يستدعي Cloud Vision API. فحص قيم MID التي تم إنشاؤها لتوفير تسميات الصور.
- ب. بناء تطبيق يستدعي Cloud Vision API. تمرير مواقع صور العميل كسلاسل مشفرة بـ base64.
- ج. بناء وتدريب نموذج تصنيف باستخدام TensorFlow. نشر النموذج باستخدام AI Platform Prediction. تمرير مواقع صور العميل كسلاسل مشفرة بـ base64.
- د. بناء وتدريب نموذج تصنيف باستخدام TensorFlow. نشر النموذج باستخدام AI Platform Prediction. فحص قيم MID التي تم إنشاؤها لتوفير تسميات الصور.
السؤال 8:
لقد قمت بإعداد مجموعة مثيلات مُدارة ذاتية التوسع لخدمة حركة مرور الويب لإطلاق قادم. بعد تكوين مجموعة المثيلات كخدمة خلفية لموازن تحميل HTTP(S)، لاحظت أن مثيلات الأجهزة الافتراضية يتم إنهاؤها وإعادة تشغيلها كل دقيقة. لا تحتوي المثيلات على عنوان IP عام. لقد تحققت من أن استجابة الويب المناسبة تأتي من كل مثيل باستخدام أمر curl. تريد التأكد من أن الخدمة الخلفية مُكونة بشكل صحيح. ماذا يجب أن تفعل؟
- أ. التأكد من وجود قاعدة جدار حماية للسماح لحركة المرور المصدر على HTTP/HTTPS بالوصول إلى موازن التحميل.
- ب. تعيين IP عام لكل مثيل وتكوين قاعدة جدار حماية للسماح لموازن التحميل بالوصول إلى IP العام للمثيل.
- ج. التأكد من وجود قاعدة جدار حماية للسماح لفحوصات سلامة موازن التحميل بالوصول إلى المثيلات في مجموعة المثيلات.
- د. إنشاء علامة على كل مثيل باسم موازن التحميل. تكوين قاعدة جدار حماية باسم موازن التحميل كمصدر وعلامة المثيل كوجهة.
السؤال 9:
لقد أنشأت مهمة تعمل يوميًا لاستيراد بيانات حساسة للغاية من موقع محلي إلى Cloud Storage. لقد قمت أيضًا بإعداد إدراج بيانات تدفق إلى Cloud Storage عبر عقدة Kafka تعمل على مثيل Compute Engine. تحتاج إلى تشفير البيانات أثناء السكون وتوفير مفتاح التشفير الخاص بك. يجب ألا يتم تخزين مفتاحك في Google Cloud. ماذا يجب أن تفعل؟
- أ. إنشاء حساب خدمة مخصص واستخدام التشفير أثناء السكون للإشارة إلى بياناتك المخزنة في Cloud Storage وبيانات Compute Engine كجزء من استدعاءات خدمة API الخاصة بك.
- ب. تحميل مفتاح التشفير الخاص بك إلى Cloud Key Management Service واستخدامه لتشفير بياناتك في Cloud Storage. استخدام مفتاح التشفير الذي قمت بتحميله والإشارة إليه كجزء من استدعاءات خدمة API الخاصة بك لتشفير بياناتك في عقدة Kafka المستضافة على Compute Engine.
- ج. تحميل مفتاح التشفير الخاص بك إلى Cloud Key Management Service واستخدامه لتشفير بياناتك في عقدة Kafka المستضافة على Compute Engine.
- د. توفير مفتاح التشفير الخاص بك، والإشارة إليه كجزء من استدعاءات خدمة API الخاصة بك لتشفير بياناتك في Cloud Storage وعقدة Kafka المستضافة على Compute Engine.
السؤال 10:
أنت تقوم بتصميم مستودع بيانات علائقية على Google Cloud لينمو حسب الحاجة. ستكون البيانات متسقة ترانزكسيونيًا وتُضاف من أي موقع في العالم. تريد مراقبة وضبط عدد العقد لحركة المرور الواردة، والتي يمكن أن ترتفع بشكل غير متوقع. ماذا يجب أن تفعل؟
- أ. استخدام Cloud Spanner للتخزين. مراقبة استخدام التخزين وزيادة عدد العقد إذا زاد الاستخدام عن 70%.
- ب. استخدام Cloud Spanner للتخزين. مراقبة استخدام CPU وزيادة عدد العقد إذا زاد الاستخدام عن 70% خلال الفترة الزمنية المحددة.
- ج. استخدام Cloud Bigtable للتخزين. مراقبة البيانات المخزنة وزيادة عدد العقد إذا زاد الاستخدام عن 70%.
- د. استخدام Cloud Bigtable للتخزين. مراقبة استخدام CPU وزيادة عدد العقد إذا زاد الاستخدام عن 70% خلال الفترة الزمنية المحددة.
الإجابات
- السؤال 1: ب
- السؤال 2: أ، هـ
- السؤال 3: ج
- السؤال 4: أ، د
- السؤال 5: ج
- السؤال 6: د
- السؤال 7: ب
- السؤال 8: ج
- السؤال 9: د
- السؤال 10: ب
عودة إلى الاقتراح الأولي
في بداية هذا المقال، ذكرت أنك ستتعلم كيفية تصميم منصة لتحليل بيانات ألعاب الهاتف المحمول التي تجمع وتخزن وتحلل كميات هائلة من بيانات القياس عن بعد للاعبين، سواء من دفعات البيانات أو الأحداث في الوقت الفعلي. فهل تعتقد أنك تستطيع الآن القيام بذلك؟
خذ قلمًا وورقة وحاول التوصل إلى حلك الخاص بناءً على الخدمات التي وصفتها هنا. إذا واجهتك صعوبة، فقد تساعدك الأسئلة التالية:
- تحتاج المنصة إلى جمع الأحداث في الوقت الفعلي من اللعبة: أين قد تعمل اللعبة؟
- كيف يمكنك استيعاب بيانات التدفق من اللعبة إلى GCP؟
- كيف يمكنك تخزينها؟
- كيف يمكنك جمع وتخزين تحميلات دفعات البيانات؟
- هل يمكنك تحليل جميع البيانات المستوعبة فور وصولها؟ هل تحتاج إلى معالجتها؟
- ما هي الخدمات التي يمكنك استخدامها لتحليل البيانات؟
- كيف سيتغير هذا إذا أصبح زمن الاستجابة المنخفض متطلبًا جديدًا؟
لقد تعمدت تعريف المشكلة بطريقة غامضة للغاية. هذا ما يمكنك توقعه عندما تواجه هذا النوع من التحديات: عدم اليقين. إنه جزء من عملك جمع المتطلبات وتوثيق افتراضاتك. لا تقلق إذا لم يبدُ حلك مثل حل Google. هذا مجرد حل ممكن واحد. تعلم تصميم الأنظمة المعقدة هو مهارة تستغرق مدى الحياة لإتقانها. لحسن الحظ، أنت تسير في الاتجاه الصحيح.
الخلاصة التقنية
يقدم هذا الدليل نظرة شاملة ومتعمقة لمنصة Google Cloud Platform، بدءًا من الأساسيات وحتى الخدمات المتقدمة في مجالات الحوسبة، والتخزين، والشبكات، والبيانات الضخمة، والذكاء الاصطناعي، والأمان. لقد تم تصميم المحتوى لتمكين المستخدمين من فهم كيفية بناء حلول سحابية مرنة، فعالة من حيث التكلفة، وقابلة للتوسع. إن التركيز على أفضل الممارسات، مثل تحسين التكاليف وإدارة الهوية والوصول، يضمن أن القارئ لا يكتسب المعرفة التقنية فحسب، بل يفهم أيضًا الجوانب التشغيلية والأمنية الحيوية لنشر التطبيقات في بيئة سحابية حديثة.
الخلاصة
سيساعدك هذا الدليل على البدء في GCP وسيعطيك منظورًا واسعًا لما يمكنك فعله به. لن تصبح خبيرًا بأي حال من الأحوال بعد الانتهاء من هذا الدليل، أو أي دليل آخر في هذا الشأن. الطريقة الوحيدة للتعلم حقًا هي الممارسة. ستتعلم أكثر بكثير من خلال العمل مقارنة بالقراءة أو المشاهدة. أوصي بشدة باستخدام الفترة التجريبية المجانية الخاصة بك و Code Labs إذا كنت جادًا في التعلم. يمكنك زيارة مدونتي www.yourdevopsguy.com ومتابعتي على Twitter للحصول على المزيد من المحتوى التقني عالي الجودة.
إخلاء مسؤولية: في وقت نشر هذا المقال، أنا لا أعمل أو لم أعمل أبدًا لدى Google. لقد أردت تنظيم وتلخيص المعرفة التي اكتسبتها من خلال وثائق Google، ومقاطع فيديو YouTube، والدورات التي أخذتها، والأهم من ذلك من خلال الممارسة العملية باستخدام GCP يوميًا في عملي. جميع هذه المعلومات متاحة مجانًا. الأرقام والإصدارات التي تراها هنا تأتي من الوثائق في وقت نشر هذا المقال. للتأكد من أنك تستخدم بيانات حديثة، يرجى زيارة الوثائق الرسمية.