دليلك الشامل لاستخدام Google Protocol Buffers في بايثون: تسريع نقل البيانات بفعالية

عندما يجتمع أشخاص يتحدثون لغات مختلفة، فإنهم يسعون لاستخدام لغة مشتركة يفهمها الجميع. لتحقيق ذلك، يتعين على كل فرد ترجمة أفكاره، التي عادة ما تكون بلغته الأم، إلى لغة المجموعة. لكن عملية “الترميز وفك الترميز” هذه للغة تؤدي إلى فقدان الكفاءة والسرعة والدقة.
ينطبق المفهوم ذاته على أنظمة الحاسوب ومكوناتها. لماذا يجب علينا إرسال البيانات بتنسيقات قابلة للقراءة البشرية مثل XML أو JSON أو أي تنسيق آخر، إذا لم تكن هناك حاجة مباشرة لفهم محتواها؟ طالما يمكننا ترجمتها إلى تنسيق سهل القراءة عند الحاجة الصريحة لذلك.
تُعد Protocol Buffers (اختصاراً: ProtoBuf) طريقة لترميز البيانات قبل نقلها، مما يقلص حجم كتل البيانات بكفاءة وبالتالي يزيد من سرعة إرسالها. إنها تجرد البيانات إلى تنسيق محايد للغة والمنصة، مما يجعلها حلاً مثالياً للاتصال بين الأنظمة المتنوعة.
جدول المحتويات
- لماذا نحتاج إلى Protocol Buffers؟
- ما هي Protocol Buffers وكيف تعمل؟
- Protocol Buffers في بايثون
- الخلاصة التقنية
لماذا نحتاج إلى Protocol Buffers؟
كان الغرض الأولي من Protocol Buffers هو تبسيط العمل مع بروتوكولات الطلب/الاستجابة. قبل ظهور ProtoBuf، كانت جوجل تستخدم تنسيقاً مختلفاً يتطلب معالجة إضافية لترتيب الرسائل المرسلة. بالإضافة إلى ذلك، كانت الإصدارات الجديدة من التنسيق السابق تتطلب من المطورين التأكد من فهم الإصدارات الجديدة قبل استبدال القديمة، مما جعل العمل معها أمراً مرهقاً.
هذا العبء الزائد حفز جوجل لتصميم واجهة تحل هذه المشكلات بدقة. تسمح ProtoBuf بإدخال تغييرات على البروتوكول دون كسر التوافق. كما يمكن للخوادم تمرير البيانات وتنفيذ عمليات القراءة عليها دون تعديل محتواها. نظراً لأن التنسيق وصفي ذاتياً إلى حد ما، تُستخدم ProtoBuf كأساس للتوليد التلقائي للكود الخاص بـ Serializers (المسلسلات) و Deserializers (مفككات التسلسل).
من حالات الاستخدام الأخرى المثيرة للاهتمام هي كيفية استخدام جوجل لها في استدعاءات الإجراءات عن بعد قصيرة الأجل (RPC) ولتخزين البيانات بشكل دائم في Bigtable. نظراً لحالة الاستخدام الخاصة بهم، قاموا بدمج واجهات RPC في ProtoBuf. وهذا يسمح بتوليد سريع ومباشر لـ code stub يمكن استخدامه كنقاط بداية للتطبيق الفعلي.
تشمل الأمثلة الأخرى التي يمكن أن تكون فيها ProtoBuf مفيدة أجهزة إنترنت الأشياء (IoT) المتصلة عبر شبكات الهاتف المحمول، حيث يجب الحفاظ على كمية البيانات المرسلة صغيرة، أو للتطبيقات في البلدان التي لا تزال فيها النطاقات الترددية العالية نادرة. يمكن أن يؤدي إرسال الحمولات بتنسيقات ثنائية محسّنة إلى اختلافات ملحوظة في تكلفة التشغيل والسرعة. يمكن أن يؤدي استخدام ضغط gzip في اتصال HTTPS الخاص بك إلى تحسين هذه المقاييس بشكل أكبر.
ما هي Protocol Buffers وكيف تعمل؟
بشكل عام، Protocol Buffers هي واجهة معرفة لتسلسل البيانات المهيكلة. إنها تحدد طريقة موحدة للاتصال، مستقلة تماماً عن اللغات والمنصات. تصف جوجل ProtoBuf الخاصة بها على النحو التالي:
Protocol buffersهي آلية جوجل المحايدة للغة، والمحايدة للمنصة، والقابلة للتوسيع لتسلسل البيانات المهيكلة – فكر فيXML، ولكنها أصغر وأسرع وأبسط. أنت تحدد كيف تريد أن تكون بياناتك مهيكلة مرة واحدة …
تصف واجهة ProtoBuf بنية البيانات المراد إرسالها. يتم تعريف هياكل الحمولة كـ “رسائل” في ما يسمى بـ Proto-Files. تنتهي هذه الملفات دائماً بملحق .proto. على سبيل المثال، تبدو البنية الأساسية لملف todolist.proto كما يلي. وسننظر أيضاً في مثال كامل في القسم التالي.
syntax = "proto3"; // Not necessary for Python, should still be declared to avoid name collisions // in the Protocol Buffers namespace and non-Python languages package protoblog; message TodoList { // Elements of the todo list will be defined here ... }تُستخدم هذه الملفات بعد ذلك لتوليد فئات التكامل أو stubs للغة التي تختارها باستخدام مولدات الكود ضمن مترجم protoc. يدعم الإصدار الحالي، Proto3، بالفعل جميع لغات البرمجة الرئيسية. ويدعم المجتمع العديد من اللغات الأخرى في تطبيقات مفتوحة المصدر من جهات خارجية.
الفئات المولّدة هي العناصر الأساسية لـ Protocol Buffers. إنها تسمح بإنشاء العناصر عن طريق إنشاء رسائل جديدة، بناءً على ملفات .proto، والتي تُستخدم بعد ذلك للتسلسل. سننظر في كيفية القيام بذلك باستخدام Python بالتفصيل في القسم التالي.
بغض النظر عن لغة التسلسل، يتم تسلسل الرسائل إلى تنسيق ثنائي غير وصفي ذاتياً، وهو عديم الفائدة تماماً بدون تعريف البنية الأولية. يمكن بعد ذلك تخزين البيانات الثنائية، وإرسالها عبر الشبكة، واستخدامها بأي طريقة أخرى تُستخدم بها البيانات القابلة للقراءة البشرية مثل JSON أو XML. بعد الإرسال أو التخزين، يمكن فك تسلسل تيار البايت واستعادته باستخدام أي فئة protobuf مجمعة خاصة باللغة نقوم بتوليدها من ملف .proto.
باستخدام Python كمثال، يمكن أن تبدو العملية كما يلي:
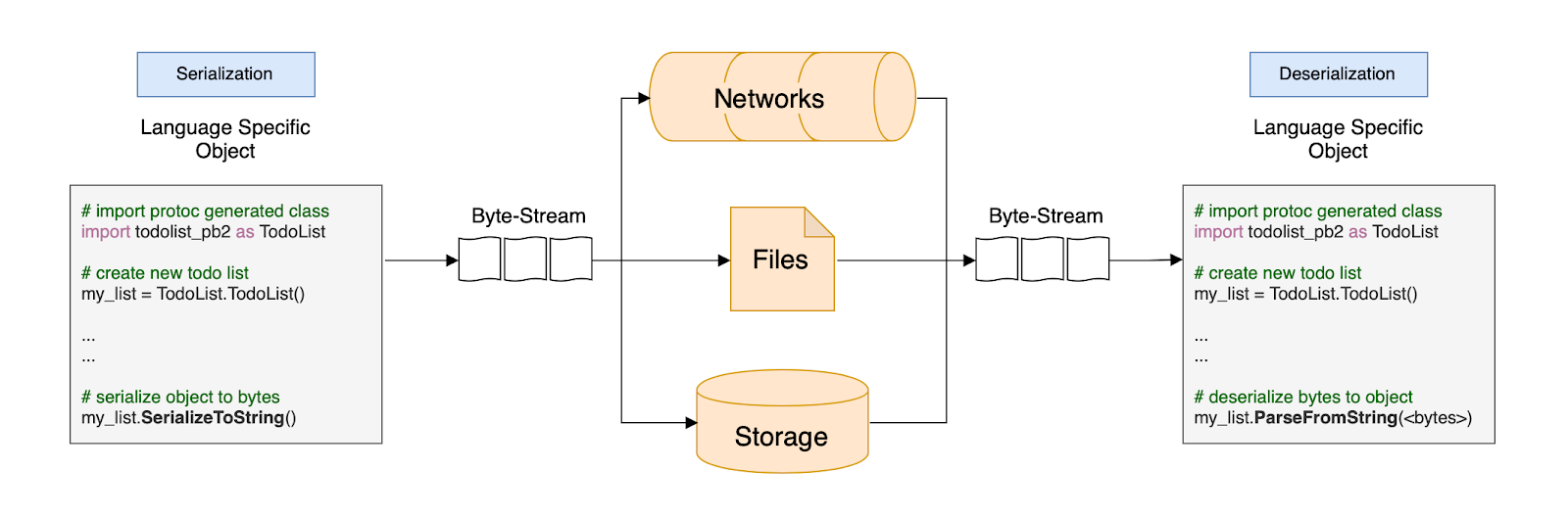
أولاً، نقوم بإنشاء قائمة مهام جديدة ونملأها ببعض المهام. يتم بعد ذلك تسلسل قائمة المهام هذه وإرسالها عبر الشبكة، أو حفظها في ملف، أو تخزينها بشكل دائم في قاعدة بيانات. يتم فك تسلسل تيار البايت المرسل باستخدام طريقة parse للفئة المجمعة الخاصة بلغتنا.
تعتمد معظم البنى التحتية والهياكل الحالية، وخاصة الخدمات المصغرة (microservices)، على اتصالات REST أو WebSockets أو GraphQL. ومع ذلك، عندما تكون السرعة والكفاءة ضرورية، يمكن أن تحدث استدعاءات الإجراءات عن بعد منخفضة المستوى (RPCs) فرقاً كبيراً. بدلاً من البروتوكولات ذات النفقات العامة العالية، يمكننا استخدام طريقة سريعة ومضغوطة لنقل البيانات بين الكيانات المختلفة في خدمتنا دون إهدار الكثير من الموارد.
ولكن لماذا لا تُستخدم في كل مكان بعد؟ تُعد Protocol Buffers أكثر تعقيداً بعض الشيء من التنسيقات الأخرى القابلة للقراءة البشرية. وهذا يجعلها أصعب نسبياً في تصحيح الأخطاء ودمجها في تطبيقاتك. تميل أوقات التكرار في الهندسة أيضاً إلى الزيادة نظراً لأن تحديثات البيانات تتطلب تحديث ملفات .proto قبل الاستخدام. يجب إجراء اعتبارات دقيقة لأن ProtoBuf قد يكون حلاً مبالغاً فيه في كثير من الحالات.
بدائل Protocol Buffers
تتبع العديد من المشاريع نهجاً مشابهاً لـ Google Protocol Buffers. تركز Flatbuffers من جوجل وتطبيق طرف ثالث يسمى Cap’n Proto بشكل أكبر على إزالة خطوة التحليل والتفكيك، وهي ضرورية للوصول إلى البيانات الفعلية عند استخدام ProtoBufs. لقد تم تصميمها خصيصاً للتطبيقات الحساسة للأداء، مما يجعلها أسرع وأكثر كفاءة في استخدام الذاكرة من ProtoBuf.
عند التركيز على إمكانيات RPC في ProtoBuf (المستخدمة مع gRPC)، هناك مشاريع من شركات كبيرة أخرى مثل فيسبوك (Apache Thrift) أو مايكروسوفت (Bond protocols) يمكن أن تقدم بدائل.
Protocol Buffers في بايثون
توفر Python بالفعل بعض طرق استمرارية البيانات باستخدام pickling. يُعد pickling مفيداً في تطبيقات Python فقط. إنه ليس مناسباً تماماً للسيناريوهات الأكثر تعقيداً التي تتضمن مشاركة البيانات مع لغات أخرى أو تغيير المخططات. على النقيض من ذلك، تم تطوير Protocol Buffers خصيصاً لهذه السيناريوهات.
تسمح ملفات .proto، التي تناولناها باختصار من قبل، للمستخدم بتوليد كود للعديد من اللغات المدعومة. لتجميع ملف .proto إلى فئة اللغة التي نختارها، نستخدم protoc، مترجم proto. إذا لم يكن لديك مترجم protoc مثبتاً، فهناك أدلة ممتازة حول كيفية القيام بذلك:
بمجرد تثبيت protoc على نظامنا، يمكننا استخدام مثال موسع لهيكل قائمة المهام الخاص بنا من قبل وتوليد فئة تكامل Python منه.
syntax = "proto3"; // Not necessary for Python but should still be declared to avoid name collisions // in the Protocol Buffers namespace and non-Python languages package protoblog; // Style guide prefers prefixing enum values instead of surrounding // with an enclosing message enum TaskState { TASK_OPEN = 0; TASK_IN_PROGRESS = 1; TASK_POST_PONED = 2; TASK_CLOSED = 3; TASK_DONE = 4; } message TodoList { int32 owner_id = 1; string owner_name = 2; message ListItems { TaskState state = 1; string task = 2; string due_date = 3; } repeated ListItems todos = 3; }فهم بنية ملف .proto
دعنا نلقي نظرة أكثر تفصيلاً على بنية ملف .proto لفهمها. في السطر الأول من ملف proto، نحدد ما إذا كنا نستخدم Proto2 أو Proto3. في هذه الحالة، نستخدم Proto3. العناصر الأكثر شيوعاً في ملفات proto هي الأرقام المخصصة لكل كيان في الرسالة. هذه الأرقام المخصصة تجعل كل سمة فريدة وتُستخدم لتحديد الحقول المخصصة في الإخراج الثنائي المرمز.
أحد المفاهيم المهمة التي يجب فهمها هو أن القيم من 1-15 فقط تُرمز ببايت واحد أقل (Hex)، وهو أمر مفيد لفهمه حتى نتمكن من تعيين أرقام أعلى للكيانات الأقل استخداماً. لا تحدد الأرقام ترتيب الترميز ولا موضع السمة المعطاة في الرسالة المرمزة.
يساعد تعريف package على منع تضارب الأسماء. في Python، تُعرف الحزم بواسطة دليلها. لذلك، فإن توفير سمة package ليس له أي تأثير على كود Python المولّد. يرجى ملاحظة أنه يجب الإعلان عن ذلك لتجنب تضارب الأسماء المتعلق بـ protocol buffer ولغات أخرى مثل Java.
التعدادات (Enumerations) هي قوائم بسيطة للقيم الممكنة لمتغير معين. في هذه الحالة، نحدد Enum للحالات الممكنة لكل مهمة في قائمة المهام. سنرى كيفية استخدامها بعد قليل عندما ننظر إلى الاستخدام في Python. كما نرى في المثال، يمكننا أيضاً تضمين الرسائل داخل الرسائل. إذا أردنا، على سبيل المثال، أن يكون لدينا قائمة مهام مرتبطة بقائمة مهام معينة، يمكننا استخدام الكلمة المفتاحية repeated، والتي يمكن مقارنتها بالمصفوفات ذات الحجم الديناميكي.
توليد كود بايثون من ملف .proto
لتوليد كود تكامل قابل للاستخدام، نستخدم مترجم proto الذي يقوم بتجميع ملف .proto معين إلى فئات تكامل خاصة باللغة. في حالتنا، نستخدم الوسيطة --python-out لتوليد كود خاص بـ Python.
protoc -I=. --python_out=. ./todolist.protoفي الطرفية، نستدعي مترجم protocol بثلاثة معلمات:
-I: يحدد الدليل الذي نبحث فيه عن أي تبعيات (نستخدم.وهو الدليل الحالي).--python_out: يحدد الموقع الذي نريد توليد فئة تكاملPythonفيه (مرة أخرى نستخدم.وهو الدليل الحالي).- المعلمة الأخيرة غير المسماة تحدد ملف
.protoالذي سيتم تجميعه (نستخدم ملفtodolist.protoفي الدليل الحالي).

ينشئ هذا ملف Python جديداً يسمى _pb2.py. في حالتنا، هو todolist_pb2.py. عند إلقاء نظرة فاحصة على هذا الملف، لن نتمكن من فهم الكثير عن هيكله على الفور. هذا لأن المولد لا ينتج عناصر وصول مباشرة للبيانات، بل يجرد التعقيد بشكل أكبر باستخدام metaclasses و descriptors لكل سمة. إنها تصف كيفية تصرف الفئة بدلاً من كل مثيل لتلك الفئة. الجزء الأكثر إثارة للاهتمام هو كيفية استخدام هذا الكود المولّد لإنشاء البيانات وبنائها وتسلسلها.
استخدام الكود المولّد لتسلسل البيانات
يمكن رؤية تكامل مباشر تم إجراؤه باستخدام الفئة التي تم توليدها مؤخراً في ما يلي:
import todolist_pb2 as TodoList my_list = TodoList.TodoList() my_list.owner_id = 1234 my_list.owner_name = "Tim" first_item = my_list.todos.add() first_item.state = TodoList.TaskState.Value("TASK_DONE") first_item.task = "Test ProtoBuf for Python" first_item.due_date = "31.10.2019" print(my_list)ينشئ هذا ببساطة قائمة مهام جديدة ويضيف إليها عنصراً واحداً. ثم نطبع عنصر قائمة المهام نفسه ويمكننا رؤية النسخة غير الثنائية وغير المتسلسلة للبيانات التي قمنا بتعريفها للتو في نصنا البرمجي.
owner_id: 1234 owner_name: "Tim" todos { state: TASK_DONE task: "Test ProtoBuf for Python" due_date: "31.10.2019" }تحتوي كل فئة Protocol Buffer على طرق لقراءة وكتابة الرسائل باستخدام ترميز خاص بـ Protocol Buffer، والذي يرمز الرسائل إلى تنسيق ثنائي. هاتان الطريقتان هما SerializeToString() و ParseFromString().
import todolist_pb2 as TodoList my_list = TodoList.TodoList() my_list.owner_id = 1234 # ... with open("./serializedFile", "wb") as fd: fd.write(my_list.SerializeToString()) my_list = TodoList.TodoList() with open("./serializedFile", "rb") as fd: my_list.ParseFromString(fd.read()) print(my_list)في مثال الكود أعلاه، نكتب السلسلة المتسلسلة من البايتات إلى ملف باستخدام علامات wb (الكتابة الثنائية). بما أننا كتبنا الملف بالفعل، يمكننا قراءة المحتوى مرة أخرى وتحليله باستخدام ParseFromString. تستدعي ParseFromString مثيلاً جديداً من فئتنا المتسلسلة باستخدام علامات rb (القراءة الثنائية) وتقوم بتحليله. إذا قمنا بتسلسل هذه الرسالة وطباعتها في وحدة التحكم، نحصل على تمثيل البايت الذي يبدو كالتالي:
b'\x08\xd2\t\x12\x03Tim\x1a(\x08\x04\x12\x18Test ProtoBuf for Python\x1a\n31.10.2019'لاحظ الحرف b أمام علامات الاقتباس. يشير هذا إلى أن السلسلة التالية تتكون من بايتات في Python. إذا قارنا هذا مباشرة، على سبيل المثال، بـ XML، يمكننا رؤية تأثير تسلسل ProtoBuf على الحجم.
<todolist> <owner_id>1234</owner_id> <owner_name>Tim</owner_name> <todos> <todo> <state>TASK_DONE</state> <task>Test ProtoBuf for Python</task> <due_date>31.10.2019</due_date> </todo> </todos> </todolist>سيبدو تمثيل JSON، غير المصغر، كالتالي:
{ "todoList": { "ownerId": "1234", "ownerName": "Tim", "todos": [ { "state": "TASK_DONE", "task": "Test ProtoBuf for Python", "dueDate": "31.10.2019" } ] } }بالحكم على التنسيقات المختلفة فقط من خلال العدد الإجمالي للبايتات المستخدمة، مع تجاهل الذاكرة اللازمة للنفقات العامة لتنسيقها، يمكننا بالطبع رؤية الفرق. ولكن بالإضافة إلى الذاكرة المستخدمة للبيانات، لدينا أيضاً 12 بايت إضافي في ProtoBuf لتنسيق البيانات المتسلسلة. بالمقارنة مع XML، لدينا 171 بايت إضافي في XML لتنسيق البيانات المتسلسلة. وبدون مخطط، نحتاج إلى 136 بايت إضافي في JSON لتنسيق البيانات المتسلسلة.
إذا كنا نتحدث عن آلاف الرسائل المرسلة عبر الشبكة أو المخزنة على القرص، يمكن أن تحدث ProtoBuf فرقاً. ومع ذلك، هناك محاذير. قامت منصة Auth0.com بإنشاء مقارنة شاملة بين ProtoBuf و JSON. وتظهر أنه عند الضغط، يمكن أن يكون فرق الحجم بين الاثنين هامشياً (حوالي 9% فقط). إذا كنت مهتماً بالأرقام الدقيقة، يرجى الرجوع إلى المقال الكامل، والذي يقدم تحليلاً مفصلاً لعدة عوامل مثل الحجم والسرعة.
ملاحظة جانبية مثيرة للاهتمام هي أن كل نوع بيانات له قيمة افتراضية. إذا لم يتم تعيين أو تغيير السمات، فإنها ستحتفظ بالقيم الافتراضية. في حالتنا، إذا لم نغير TaskState لعنصر ListItem، فستكون حالته “TASK_OPEN” افتراضياً. الميزة الكبيرة لذلك هي أن القيم غير المعينة لا يتم تسلسلها، مما يوفر مساحة إضافية. إذا قمنا، على سبيل المثال، بتغيير حالة مهمتنا من TASK_DONE إلى TASK_OPEN، فلن يتم تسلسلها.
owner_id: 1234 owner_name: "Tim" todos { task: "Test ProtoBuf for Python" due_date: "31.10.2019" }b'\x08\xd2\t\x12\x03Tim\x1a&\x12\x18Test ProtoBuf for Python\x1a\n31.10.2019'ملاحظات ختامية
كما رأينا، تُعد Protocol Buffers مفيدة جداً عندما يتعلق الأمر بالسرعة والكفاءة عند العمل مع البيانات. نظراً لطبيعتها القوية، قد يستغرق الأمر بعض الوقت للاعتياد على نظام ProtoBuf، على الرغم من أن بناء الجملة لتعريف الرسائل الجديدة مباشر. كملاحظة أخيرة، أود أن أشير إلى أن هناك مناقشات جارية حول ما إذا كانت Protocol Buffers “مفيدة” للتطبيقات العادية. لقد تم تطويرها خصيصاً للمشكلات التي كانت جوجل تواجهها.
الخلاصة التقنية
تُقدم Google Protocol Buffers حلاً قوياً وفعالاً لتسلسل البيانات، خاصة في البيئات التي تتطلب سرعة عالية وكفاءة في استهلاك الموارد وتبادلاً للبيانات بين أنظمة مبنية بلغات ومنصات مختلفة. على الرغم من أن تعقيدها الأولي قد يكون عائقاً أمام بعض المطورين، إلا أن فوائدها في تقليل حجم البيانات وزيادة سرعة النقل، إلى جانب قدرتها على توليد الكود تلقائياً، تجعلها خياراً ممتازاً لتطبيقات مثل الخدمات المصغرة (microservices) عالية الأداء، وأنظمة IoT، والتخزين المستمر للبيانات الكبيرة. يجب على المطورين تقييم احتياجاتهم بعناية لتحديد ما إذا كانت ProtoBuf هي الحل الأمثل، مع الأخذ في الاعتبار البدائل المتاحة التي قد تكون أكثر ملاءمة لسيناريوهات معينة.