قواعد البيانات الرسومية مقابل قواعد البيانات العلائقية: كيف تعمل Graph Database عمليًا؟
مقدمة: لماذا يزداد الاهتمام بـ Graph Databases؟
مع التوسع الهائل في حجم البيانات وتنوع مصادرها، لم يعد تخزين البيانات وحده كافيًا، بل أصبحت القدرة على فهم العلاقات بين العناصر جزءًا أساسيًا من أي نظام حديث. وهنا تظهر أهمية Graph Databases التي صُممت خصيصًا للتعامل مع البيانات المترابطة بطريقة طبيعية وسريعة.
إذا كنت تتساءل عن الفرق بين Graph Database وRelational Database Management Systems (RDBMS)، فهذا الدليل موجّه لك. سنشرح الفكرة بأسلوب عملي مبسط، مع مقارنة مباشرة بين النموذجين، والاعتماد على مثال شهير من Neo4j مبني على بيانات أفلام.

ما الذي ستتعلمه في هذا المقال؟
- ما هي Graph Databases ولماذا تُعد من حلول NoSQL.
- الفرق المفاهيمي بين قواعد البيانات الرسومية والعلائقية.
- أنواع قواعد البيانات الرسومية وأشهر نماذجها.
- كيف يعمل Property Graph داخل Neo4j.
- مقارنة عملية بين استعلامات Cypher وSQL.
- كيف تساعد العلاقات المباشرة في تحسين الأداء والاستعلام.
ما هي Graph Database؟
Graph Database هي نوع من قواعد البيانات ضمن عائلة NoSQL، وتُستخدم لتخزين البيانات واسترجاعها على هيئة Graph Structure. هذا يعني أن البيانات لا تُخزن فقط كعناصر منفصلة، بل كعناصر وروابط توضح كيفية اتصالها ببعضها.
تختلف آلية التخزين من نظام إلى آخر:
- بعض الأنظمة تبني طبقة رسومية فوق بنية تقليدية مثل الجداول.
- أنظمة أخرى تُعد Native Graph Databases، حيث تكون البنية الرسومية جزءًا أصيلًا من التخزين والإدارة والاستعلام.
الميزة الجوهرية هنا أن العلاقات بين الكيانات تُعامل كعناصر أساسية، وليست مجرد مفاتيح أو جداول وسيطة كما في الأنظمة العلائقية.
أنواع Graph Databases
يمكن تقسيم قواعد البيانات الرسومية عمومًا إلى نوعين رئيسيين:
1) RDF / Triple Stores / Semantic Graph Databases
يعتمد هذا النوع على مفهوم Triple، وهو عبارة عن ثلاثة عناصر:
- Subject
- Predicate
- Object
يمثل Subject موردًا أو عقدة، بينما يمثل Object عقدة أخرى أو قيمة مباشرة، أما Predicate فيصف العلاقة بينهما. في هذا النموذج لا توجد بنية داخلية غنية للعقد أو العلاقات، وغالبًا ما يُعتمد على URI للتعريف الفريد.
يُستخدم هذا النموذج بكثرة في تبادل البيانات والنشر الدلالي وربط المعرفة.
2) Property Graph Databases
يركز هذا النوع على تمثيل البيانات بطريقة قريبة من النموذج المنطقي الفعلي للتطبيق. ويُعد مناسبًا جدًا عندما تكون الأسئلة المطروحة على البيانات مرتبطة بالعلاقات والمسارات والتوصيات والتحليلات الشبكية.
في Property Graph نجد:
- عقدًا Nodes تحمل خصائص.
- علاقات Relationships تحمل نوعًا واتجاهًا.
- إمكانية إضافة Properties لكل من العقد والعلاقات.
وهذا يمنحنا تمثيلًا غنيًا ومرنًا للبيانات والبيانات الوصفية معًا.


تشريح Property Graph Database
في بقية هذا المقال سنركز على Native Property Graph Database، وبالتحديد Neo4j.
العناصر الأساسية
- Node: تمثل الكيان الأساسي في الرسم البياني، مثل شخص أو فيلم.
- Relationship: تمثل الرابط بين عقدتين، ولها اتجاه ونوع محدد.
- Label: لتصنيف العقد، ويمكن أن تحمل العقدة أكثر من تصنيف.
- Property: خصائص إضافية تُضاف إلى العقدة أو العلاقة مثل الاسم أو سنة الإصدار أو الدور.
في هذا النموذج، يمكن وجود عقدة دون علاقات، لكن لا يمكن وجود علاقة من دون عقدتين تربط بينهما.


مراجعة سريعة: كيف تعمل Relational Databases؟
في قواعد البيانات العلائقية، تُخزن البيانات داخل Tables ذات مخطط واضح. كل صف يمثل كيانًا مستقلًا، ويحتوي عادة على Primary Key لتحديده بشكل فريد.
ولتقليل التكرار، تُستخدم عملية Normalization لنقل البيانات المكررة إلى جداول منفصلة. على سبيل المثال، بدلًا من تكرار عنوان الشخص في كل سجل، يمكن حفظ العنوان في جدول آخر وربطه بالشخص عبر Foreign Key.
عند تنفيذ الاستعلامات، نحتاج إلى إعادة تجميع البيانات من الجداول المختلفة باستخدام JOIN. وهنا تكمن الفكرة الأساسية: الربط يتم غالبًا وقت القراءة، أي أثناء تنفيذ الاستعلام.
هذا النموذج مناسب جدًا لكثير من التطبيقات التقليدية، لكنه قد يصبح أكثر تعقيدًا عندما تكون العلاقات متشعبة ومتعددة المستويات.


كيف تعمل Native Graph Databases؟
الاتصالات المباشرة بدل الربط وقت الاستعلام
في قاعدة البيانات الرسومية، الكيان الأساسي هو Node بدل الصف. وعندما نريد ربط شخص بعنوان أو ممثل بفيلم، لا نحتاج إلى جدول وسيط أو عملية JOIN معقدة، بل ننشئ Relationship فعلية بين الطرفين.
هذا يعني أن العلاقة تكون معروفة ومخزنة مسبقًا، وليس مطلوبًا من النظام أن يكتشفها كل مرة عند تنفيذ الاستعلام.
ما المقصود بـ Index-Free Adjacency؟
هذا المفهوم من أهم أسباب قوة Native Graph Databases. فبدلًا من البحث داخل مجموعات كبيرة من البيانات لإيجاد نقاط الالتقاء، يكفي أن يتبع النظام العلاقات المخزنة مباشرة بين العقد.
بعبارة أبسط:
- في RDBMS يعتمد الأداء على كفاءة JOIN وحجم الجداول.
- في Graph Database يعتمد الأداء غالبًا على عدد العلاقات المرتبطة بالعقد التي تمر بها أثناء الاستعلام، لا على الحجم الكلي للبيانات.
وهذا يجعل قواعد البيانات الرسومية فعالة جدًا عند التعامل مع الأسئلة التي تتطلب استكشاف الشبكات، مثل:
- من يعرف من؟
- ما أقصر طريق بين عنصرين؟
- من هم الأشخاص الذين يرتبطون بمجموعة اهتمامات مشتركة؟
- ما أفضل التوصيات الممكنة بناءً على العلاقات القائمة؟
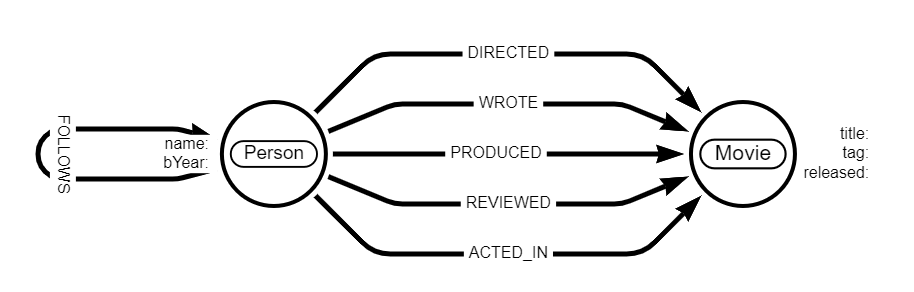
نظرة على Movie Graph في Neo4j
بعد توضيح الجانب النظري، لننتقل إلى مثال عملي. يعتمد هذا الشرح على مجموعة بيانات أفلام داخل Neo4j Browser، ويمكن تشغيلها عبر الأمر:
:PLAY moviesتتضمن هذه البيانات:
- 133 عقدة من نوع Person.
- 38 عقدة من نوع Movie.
- 253 علاقة تصف الصلات بين الأشخاص والأفلام.
ومن بين هذه العلاقات:
- من أخرج الفيلم.
- من مثّل في الفيلم وما الدور الذي أداه.
- من كتب الفيلم.
- من أنتج الفيلم.
- من راجع الفيلم وما التقييم الذي منحه.
- من يتابع من.
ورغم أن هذه المجموعة صغيرة نسبيًا، فإنها تُظهر بوضوح كيف يمكن للنموذج الرسومي أن يصف علاقات معقدة بطريقة مباشرة وسهلة الفهم.
مقارنة نماذج البيانات
أي نموذج بيانات يجب أن يُبنى وفقًا للأسئلة التي تريد أن تجيب عنها. لنفترض أننا نريد معرفة ما يلي:
- ما الأفلام التي شارك فيها شخص ما؟
- ما جميع أنواع ارتباط شخص معين بالأفلام؟
- من هم جميع الممثلين الذين عمل معهم هذا الشخص؟
في النظام العلائقي، غالبًا سنحتاج إلى جداول إضافية ومفاتيح وعلاقات وسيطة. أما في النظام الرسومي، فتظهر العلاقة نفسها بشكل مباشر داخل النموذج.


أول ما ستلاحظه هنا هو أن الحاجة إلى كثير من الجداول الوسيطة والمعرّفات تقل بشكل واضح، لأن الاتصال بين العناصر صار جزءًا من بنية البيانات نفسها.
مقارنة الاستعلامات: Cypher مقابل SQL
Cypher هي لغة استعلامات رسومية تُستخدم في Neo4j، وتتميز بصياغة قريبة جدًا من شكل العلاقات داخل الرسم البياني. لذلك تبدو الاستعلامات فيها أكثر تعبيرًا عندما يكون الهدف هو استكشاف الروابط بين البيانات.
كيفية العثور على Tom Hanks
MATCH (p:Person {name: "Tom Hanks"}) RETURN pSELECT * FROM person WHERE person.name = "Tom Hanks"كيفية العثور على أفلام Tom Hanks
MATCH (:Person {name: "Tom Hanks"})-->(m:Movie) RETURN m.titleSELECT movie.title
FROM movie
INNER JOIN movie_person ON movie.movie_id = person_movie.movie_id
INNER JOIN person ON person_movie.person_id = person.person_id
WHERE person.name = "Tom Hanks"كيفية العثور على الأفلام التي أخرجها Tom Hanks
MATCH (:Person {name: "Tom Hanks"})-[:DIRECTED]->(m:Movie) RETURN m.titleSELECT movie.title
FROM movie
INNER JOIN person_movie ON movie.movie_id = person_movie.movie_id
INNER JOIN person ON person_movie.person_id = person.person_id
INNER JOIN involvement ON person_movie.involve_id = involvement.involve_id
WHERE person.name = "Tom Hanks" AND involvement.title = "Director"كيفية العثور على الممثلين المشاركين مع Tom Hanks
MATCH (:Person {name: "Tom Hanks"})-->(:Movie)<-[:ACTED_IN]-(coActor:Person) RETURN coActor.nameWITH tom_movies AS (
SELECT movie.movie_id
FROM movie
INNER JOIN person_movie ON movie.movie_id = person_movie.movie_id
INNER JOIN person ON person_movie.person_id = person.person_id
WHERE person.name = "Tom Hanks"
)
SELECT person.name
FROM person
INNER JOIN person_movie ON tom_movies = person_movie.movie_id
INNER JOIN person ON person_movie.person_id = person.person_id
INNER JOIN involvement ON person_movie.involve_id = involvement.involve_id
WHERE involvement.title = "Actor"يتضح من المقارنة أن Cypher يعبّر عن المسار نفسه بشكل بصري ومنطقي، بينما تتطلب SQL سلسلة من عمليات JOIN حتى للوصول إلى نتيجة بسيطة نسبيًا.
استعلامات أكثر تقدمًا باستخدام Cypher
استكشاف Kevin Bacon Number
من أشهر الأسئلة في عالم بيانات الأفلام: ما مدى قرب أي ممثل من Kevin Bacon عبر الأعمال المشتركة؟ في الرسم البياني، يصبح هذا النوع من الأسئلة طبيعيًا جدًا.
MATCH (bacon:Person {name:"Kevin Bacon"})-[*1..4]-(hollywood)
RETURN DISTINCT hollywoodفي هذا الاستعلام:
*تعني السير عبر أي نوع من العلاقات.1..4تعني من خطوة واحدة حتى أربع خطوات.
بذلك نطلب من Neo4j جلب جميع الأشخاص والأفلام المرتبطة بـ Kevin Bacon ضمن هذا النطاق.
العثور على أقصر مسار بين Kevin Bacon وMeg Ryan
MATCH p=shortestPath( (bacon:Person { name : "Kevin Bacon" })-[*]-(meg:Person { name : "Meg Ryan" }))
RETURN pهنا نستخدم:
p=لتخزين المسار كاملًا في متغير.shortestPath()للعثور على أول أقصر مسار بين العقدتين.
هذا النوع من الاستعلامات يكشف إحدى نقاط القوة الكبرى في Graph Databases، لأن تحليل المسارات جزء أصيل من النموذج نفسه.
تنبيه مهم عند استخدام [*]
استخدام [*] دون قيود قد يؤدي إلى عدد هائل جدًا من المسارات المحتملة، حتى في مجموعات بيانات صغيرة. لذلك من الأفضل دائمًا:
- تحديد نطاق مثل
*1..4. - أو استخدام دوال مضبوطة مثل
shortestPath().
توصيات ذكية عبر العلاقات البيانية
من أكثر التطبيقات العملية لقواعد البيانات الرسومية: أنظمة التوصية. فعندما تكون العلاقات واضحة، يصبح اقتراح الأشخاص أو المنتجات أو المحتوى أكثر دقة وسهولة.
اقتراح ممثلين جدد للعمل مع Tom Hanks
MATCH (tom:Person {name:"Tom Hanks"})-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors),
(coActors)-[:ACTED_IN]->(m2)<-[:ACTED_IN]-(cocoActors)
WHERE NOT (tom)-[:ACTED_IN]->()<-[:ACTED_IN]-(cocoActors)
AND tom <> cocoActors
RETURN cocoActors.name AS Recommended, count(*) AS Strength
ORDER BY Strength DESCمنطق الاستعلام كالتالي:
- العثور على الممثلين الذين عملوا سابقًا مع Tom Hanks.
- البحث عن الممثلين الذين عملوا مع هؤلاء الممثلين.
- استبعاد من سبق لـ Tom Hanks العمل معهم.
- ترتيب النتائج حسب قوة الترشيح.
هذا مثال عملي ممتاز على كيف يمكن استخدام الرسم البياني لتوليد توصيات قائمة على القرب الشبكي.
من يمكنه تقديم Tom Hanks إلى Tom Cruise؟
MATCH (tom:Person {name:"Tom Hanks"})-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors),
(coActors)-[:ACTED_IN]->(m2)<-[:ACTED_IN]-(cruise:Person {name:"Tom Cruise"})
RETURN tom, m, coActors, m2, cruiseهذا الاستعلام يبحث عن ممثلين مشتركين يمكنهم تشكيل حلقة وصل بين Tom Hanks وTom Cruise، مع إظهار الأفلام التي جمعت كل طرف بالوسيط نفسه. مثل هذه الأسئلة تكون مرهقة في الأنظمة العلائقية، لكنها تبدو طبيعية جدًا في البيئة الرسومية.
متى تختار Graph Database بدل Relational Database؟
اختيار نوع قاعدة البيانات لا يعتمد على الموضة التقنية، بل على طبيعة البيانات والأسئلة التي تريد الإجابة عنها.
استخدم Relational Database عندما:
- تكون البيانات منظمة بوضوح داخل جداول ثابتة.
- تكون العمليات الأساسية معاملات مالية أو سجلات تقليدية.
- تكون العلاقات محدودة نسبيًا ولا تتطلب استكشافًا عميقًا.
استخدم Graph Database عندما:
- تكون العلاقات محورًا أساسيًا في التطبيق.
- تحتاج إلى تحليل المسارات والروابط والتوصيات.
- تتعامل مع شبكات اجتماعية أو كشف احتيال أو محركات توصية أو خرائط معرفة.
- تريد تمثيلًا أقرب للطبيعة الحقيقية للبيانات المتصلة.
مزايا Graph Databases باختصار
| الجانب | Graph Database | Relational Database |
|---|---|---|
| تمثيل العلاقات | مباشر وطبيعي | عبر مفاتيح وجداول وسيطة |
| الاستعلام عن المسارات | سهل وفعّال | أكثر تعقيدًا |
| التعامل مع البيانات المترابطة | ممتاز | جيد حتى حد معين |
| الاعتماد على JOIN | منخفض جدًا | مرتفع |
| أفضل سيناريوهات الاستخدام | التوصيات والشبكات والتحليلات العلائقية | الأنظمة التقليدية والبيانات الجدولية |
الخلاصة التقنية
إذا كانت بياناتك تتمحور حول العلاقات أكثر من الجداول، فإن Graph Database ليست مجرد بديل، بل قد تكون الخيار الأكثر منطقية وكفاءة. أما إذا كانت تطبيقاتك تعتمد على هياكل ثابتة ومعاملات تقليدية، فستظل Relational Databases خيارًا قويًا وعمليًا. تقنيًا، تكمن قوة Neo4j وProperty Graph في أن العلاقة نفسها تتحول إلى عنصر قابل للاستعلام والتحليل، وهذا ما يمنح قواعد البيانات الرسومية أفضلية واضحة في سيناريوهات الاستكشاف، والتوصية، وربط المعرفة.