كيف تتجنب إيقاف الأنظمة الحية: خطأين برمجيين كارثيين ارتكبتهما وكيفية تفاديهما

في عالم تطوير البرمجيات، حيث تتسارع وتيرة الابتكار وتتزايد تعقيدات الأنظمة، تُعد الأخطاء جزءًا لا يتجزأ من الرحلة. لا يقتصر الأمر على المطورين المبتدئين فحسب، بل يمتد ليشمل الأكثر خبرة. في هذا المقال، أشارككم تجربتي مع خطأين برمجيين كبيرين كادا أن يتسببا في كوارث حقيقية في بيئة الإنتاج، وكيف تمكنا من التعامل معهما. هذه الأخطاء لم تكن مجرد هفوات بسيطة، بل تطلبت جهدًا جماعيًا لإصلاح الضرر، وتركت بصمة عميقة في ذاكرتي المهنية. الهدف من مشاركة هذه القصص ليس إظهار الضعف، بل تقديم دروس عملية قيمة لمساعدتكم على فهم كيفية التصرف عند مواجهة مثل هذه التحديات، وكيف يمكن تحويل الأخطاء إلى فرص للتعلم والتحسين. ففي نهاية المطاف، كل مطور سيواجه لحظة يخطئ فيها، ولكن الأهم هو كيفية التعافي من هذا الخطأ.
الاختبار، الأمل، والدعاء: هل تكفي الممارسات الجيدة؟
على مر السنين، تبنى عالم تطوير البرمجيات مجموعة من الممارسات الصارمة التي تهدف إلى تقليل احتمالية حدوث الأخطاء وتخفيف وطأتها. نعتمد على كتابة الاختبارات الآلية (Automated Tests)، ونقوم باختبار التغييرات في بيئات تجريبية (Staging Environments) تحاكي بيئة الإنتاج، ونُجري مراجعات دقيقة للكود (Code Reviews)، بالإضافة إلى أتمتة عمليات النشر (Deployment Processes) باستخدام السكريبتات. كل هذه الممارسات تلتقط وتُصلح عددًا لا يُحصى من الأخطاء يوميًا قبل وصولها إلى المستخدمين.
ومع ذلك، وعلى الرغم من كل هذه الإجراءات والعمليات المحكمة، لا تزال الأخطاء تحدث. ففي نهاية المطاف، نحن بشر، والبشر يخطئون. قد نغفل عن حالات الحافة (Edge Cases)، أو ننسى التحقق من التوافقية مع متصفحات معينة، أو نحذف سجلًا خاطئًا، أو حتى نتسبب في تعطيل جزء من النظام بتمرير معلمة غير صحيحة إلى سكربت النشر. الأخطاء التي سأشاركها معكم تقع في مكان ما بين هذه السيناريوهات، وبدأت أولها في وظيفتي الأولى كمطور.
الخطأ الأول: درس قاسٍ في إدارة قواعد البيانات
ارتكبت الخطأ الأول في مسيرتي المهنية خلال وظيفتي الأولى كمطور. كنت قد أمضيت ما يقارب العام في هذه الوظيفة، وكان فريقي مسؤولاً عن بناء تطبيقات داخلية تدعم سير العمل في الشركة. شمل عملنا تطوير أدوات لدعم العملاء والإدارة، بالإضافة إلى إعداد وإدارة قواعد البيانات وخدمات الويب المبنية عليها والتي كانت تشغل منتجات الشركة. باختصار، كنا مسؤولين عن عدد كبير من استعلامات SQL المعقدة والحساسة وقواعد البيانات المرتبطة بها.
كونها وظيفتي الأولى كمطور، كنت أتعلم SQL بأسرع ما يمكن. كانت لدينا بيئة ضمان الجودة (QA environment)، أو ما يُعرف ببيئة الاختبار، تحتوي على نسخة طبق الأصل من كل قاعدة بيانات لإجراء الاختبارات عليها. لم يكن المطورون الجدد مثلي يمتلكون صلاحيات الكتابة المباشرة على قواعد بيانات الإنتاج (وهو أمر صائب تمامًا).
لإجراء أي تغيير في بيئة الإنتاج، كان علي أولاً كتابة الاستعلام واختباره على قاعدة بياناتي المحلية. بعد التأكد من صحته محليًا، كان يجب علي طلب مراجعة الكود (code review) من عضو فريق أكثر خبرة، والذي بدوره يقوم بمراجعة الاستعلام، وإذا كان سليمًا، يقوم بتشغيل أي عمليات ترحيل هيكلية (structural migrations) في بيئة ضمان الجودة. بعد ذلك، كنت أُعيد الاختبار في بيئة ضمان الجودة. وبمجرد أن أثق في أن استعلامي يعمل بشكل صحيح في بيئة ضمان الجودة، كان علي طلب مراجعة كود أخرى وطلب تنفيذ الاستعلام في بيئة الإنتاج.
كان هذا الإجراء يبدو جيدًا للغاية، أليس كذلك؟ مساحة واسعة للممارسة والكثير من نقاط التفتيش لضمان أن كل ما يصل إلى الإنتاج يكون متينًا وخاليًا من المشاكل.
الحصول على صلاحيات الكتابة المباشرة للإنتاج
بعد فترة من تكرار هذه العملية بنجاح، بدأت أحصل على صلاحيات الكتابة المباشرة (write access) لبعض قواعد البيانات في بيئة الإنتاج، وتحديدًا تلك التي كنت على دراية بها وكانت مرتبطة بعملي بشكل مباشر. كنت قد أثبت أنني حذر ويمكن الوثوق بي في التعامل مع بيئة الإنتاج (وأنتم تعلمون الآن إلى أين يتجه هذا السرد).
إذا لم تكن ملمًا بلغة SQL، فهناك عدة أنواع مختلفة من الاستعلامات التي يمكنك تشغيلها. أحيانًا ترغب فقط في استرداد المعلومات، وأحيانًا أخرى ترغب في إدراج (INSERT)، أو تحديث (UPDATE)، أو حذف (DELETE) المعلومات. غالبية الاستعلامات التي تكتبها هي استعلامات SELECT لاسترداد المعلومات. فقط في بعض الأحيان النادرة تقوم بعملية INSERT أو UPDATE أو DELETE. لذلك، في معظم الأوقات تكون استعلاماتك غير ضارة؛ فاستعلام SELECT لا يغير أي بيانات، ولا يوجد خطر من حدوث خطأ. ولكن، في بعض الأحيان تحتاج بالفعل إلى تغيير البيانات—وهنا يجب أن تكون حذرًا للغاية.
خطأ في استعلام UPDATE: الكارثة
لا أتذكر حتى المهمة التي كنت أقوم بها أو سببها. الشيء الوحيد الذي أتذكره الآن هو استعلام UPDATE المشؤوم. كنت أقوم بتحديث معلومات تتعلق بالعملاء – مثل أسمائهم أو بريدهم الإلكتروني أو عناوينهم. كنت قد كتبت استعلامًا اعتقدت أنه صحيح، وكنت أختبره كاستعلام SELECT:
--UPDATE users SET name = 'blah', ...
SELECT * FROM users WHERE ...لاحظوا أن استعلام UPDATE معلق (commented out) فوق استعلام SELECT. كانت هذه صيغة مفيدة تعلمتها في هذه الوظيفة وساعدت في تقليل الأخطاء عند تشغيل الاستعلامات. أولاً، تكتب استعلام UPDATE معلقًا بالقيم التي تريد تعيينها. بعد ذلك، تكتب استعلام SELECT أسفل هذا الاستعلام وتستخدم SELECT لاختبار النتيجة النهائية للاستعلام. من خلال تعليق الاستعلام الأول، فإنك تقضي على احتمالية تشغيل UPDATE عن طريق الخطأ قبل أن تكون مستعدًا. الطريقة الوحيدة لتشغيل الاستعلام هي إما إزالة التعليق عنه (وهو إجراء يتطلب تدخلًا)، أو بتحديد النص بعد التعليق مع بقية الاستعلام ثم تشغيله (وهو أيضًا إجراء متعمد). تمنع هذه التقنية الصغيرة العديد من الأخطاء.
ولكن بالعودة إلى كتابة استعلامي. عندما كنت مستعدًا، كل ما كان علي فعله هو إزالة التعليق من سطر UPDATE، وتعليق سطر SELECT، ثم الضغط على زر التشغيل.
الاستعلام النموذجي الذي عرضته أعلاه مبسط للغاية مقارنة بالاستعلام الذي كتبته آنذاك. كان الاستعلام الذي كتبته معقدًا إلى حد ما. كان يحتوي على الكثير من عمليات الربط (joins)، والاستعلامات الفرعية (subqueries)، وكان يتحقق من نطاق معين من الطلبات أو المنتجات أو أي شيء آخر—لم يكن مجرد شيء بسيط مثل WHERE id = blah. ربما كان يبدو أشبه بهذا:
--UPDATE users SET name = 'blah', ...
SELECT * FROM users
JOIN something ON something.user_id = users.id
JOIN another_thing ON another_thing.something_id = something.id
WHERE 1 = 1
AND something.blah = 'bleh'
AND another_thing.bleh = 'blah'
OR ( users.name <> 'Karen' AND thing = thing );(أقسم أن هذه ليست قصة “السمكة كانت بهذا الحجم”.)
لقد تحققت من أن المستخدمين الذين استرجعتهم كانوا هم المستخدمين الذين أتوقعهم. لقد قمت بالتحقق محليًا، واختبرته في بيئة ضمان الجودة، وحصلت على موافقة من عضو الفريق لتشغيله في بيئة الإنتاج (انظروا، لم يكن خطأي (أنا أمزح)).
هنا تكمن المشكلة. وقبل أن أخبركم ما هي، سأقدم لكم نصيحة احترافية صغيرة ستمنع حدوث ذلك لكم على الإطلاق. عند تشغيل استعلام سيقوم بعملية كتابة في قاعدة البيانات: اسحب المؤشر من أسفل الاستعلام إلى أعلاه.
لماذا السحب من الأسفل إلى الأعلى؟ سؤال جيد.
نصيحة احترافية: السحب من الأسفل إلى الأعلى
لنفترض أنني بدأت من أسفل هذا الاستعلام وسحبت المؤشر إلى منتصفه ثم شغلت الاستعلام:
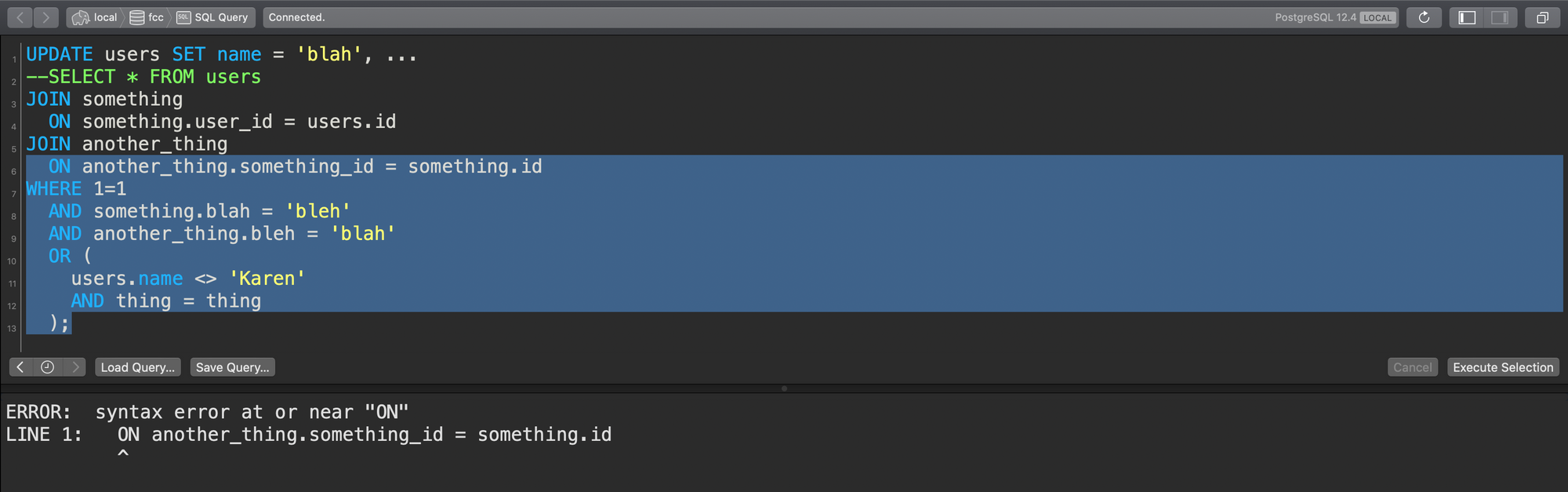
ماذا يحدث؟ حسنًا، لا شيء. لم أقم بتحديد استعلام صالح. سيقوم محلل الاستعلام (query parser) بإلقاء خطأ ويقول: “يا لك من غبي يا جون، هذا ليس استعلامًا صالحًا”. شكرًا لك يا محلل الاستعلام! لا مشكلة كبيرة. سأحاول مرة أخرى:

الآن لقد حددت الاستعلام بالكامل، وقد تم تشغيله. رائع! كل شيء على ما يرام، أليس كذلك؟
الآن ماذا لو كنت تعمل على هذا الاستعلام وبسبب حجم نافذتك أو موضع التمرير في أداة الاستعلام الخاصة بك، بدأت من أعلى الاستعلام وسحبت إلى الأسفل…

هذا الاستعلام يعمل – ولكن يا إلهي! كان بقية الاستعلام خارج منطقة العرض الخاصة بي، وقد قمت بتضمين نصف عبارة WHERE فقط!
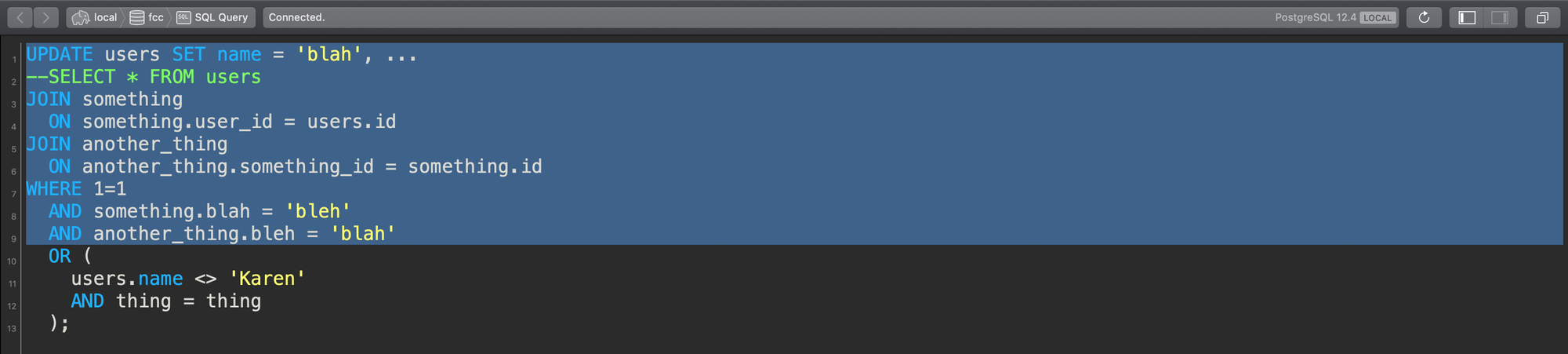
وبهذه البساطة، يحدث الخطأ. استعلام UPDATE يخرج عن السيطرة. هذا بالضبط ما فعلته. لقد قمت بتشغيل جزء من الاستعلام، وكان ينقصه بعض شروط التصفية (filtering conditions) لتحديد مجموعة النتائج التي أعمل عليها بشكل صحيح، وانتهى بي الأمر بتحديث جدول users بأكمله بمعلومات شخص واحد. كل مستخدم في نظامنا أصبح الآن “جون سميث في 1234 شارع مين”. لقد أخطأت، وأدركت المشكلة بعد فوات الأوان.
ماذا تفعل عند ارتكاب خطأ في الإنتاج؟ أبلغ فوراً!
إذًا، ماذا فعلت؟ “الأسرار الخفية ليست ممتعة. الأسرار الخفية تؤذي شخصًا ما.” – مسلسل المكتب، الموسم الثالث، الحلقة 15.
هنا تأتي الخلاصة الرئيسية الأولى (بصرف النظر عن نصيحة السحب من الأسفل إلى الأعلى الرائعة): إذا ارتكبت خطأً، أخبر أحدهم. فورًا. قد يكون من المغري جدًا محاولة إخفاء الخطأ الذي ارتكبته أو تجاهله – خاصة إذا كان خطيرًا. لقد مررت بذلك. شعرت بتلك الدوافع. تدرك خطأك ويبدأ الشعور بالخوف: “يا إلهي، ماذا فعلت؟”
عندما يحدث هذا، هناك بعض الأشياء التي يجب تذكرها:
- كل مطور ذي خبرة معقولة ارتكب أخطاء في بيئة الإنتاج.
- العديد من هذه الأخطاء حساسة للوقت.
- لا أعرف أي شخص تم فصله بسبب خطأ صادق.
كل مطور ارتكب أخطاء في بيئة الإنتاج. لقد ارتكبتها، وسأرتكبها مرة أخرى (ولكن آمل ألا تكون نفس الأخطاء). أي شخص ينتقدك بسبب ذلك إما أنه عديم الخبرة أو شخص غير مهني. في كلتا الحالتين، لا يجب أن تهتم.
العديد من هذه الأخطاء أيضًا “حساسة للوقت” (time-sensitive). هذا يعني أنه كلما أسرعت في إصلاح المشكلة أو التراجع عن التغيير، قل الضرر الذي سيحدث. الانتظار للاعتراف بالمشكلة يمكن أن يؤدي إلى عملية إصلاح أكثر صعوبة.
من بين جميع الأخطاء التي ارتكبتها وجميع الأخطاء التي رأيت الآخرين يرتكبونها، لا أعرف شخصًا واحدًا تم فصله أو حتى توبيخه بجدية بسبب خطأ صادق. أعتقد أن هذا يرجع إلى أن البرمجة صعبة، وأي شخص وصل إلى المناصب القيادية قد فعل شيئًا مشابهًا أو أسوأ.
إذًا، إليك ما تفعله:
- تحمل المسؤولية.
- تحمل المسؤولية بسرعة.
- اعمل للمساعدة في الإصلاح.
تحمل مسؤولية الخطأ. لا تحول اللوم أو تختلق الأعذار – فقط اشرح ما حدث بشكل خاطئ وما رأيته أو فعلته. نبه رئيسك أو قائد فريقك بمجرد أن تدرك المشكلة. شدة الإنذار الذي تطلقه تتناسب على الأرجح مع حجم الخطأ.
“عفوًا، لقد أفسدت التحقق من صحة هذا الحقل، لقد قمت بإنشاء طلب سحب (PR) آخر لإصلاحه.” إذا كان الأمر بسيطًا، ربما يمكنك فقط إنشاء طلب سحب جديد لإصلاحه وإخبار شخص ما بمراجعته. مشكلة صغيرة، إصلاح صغير – لا مشكلة كبيرة.
إذا، بالصدفة، قمت بتحديث جدول إنتاج بقيمة واحدة عبر الجدول بأكمله – فعليك إطلاق الإنذار بسرعة.
تحديث جدول بأكمله: لحظة الحقيقة
بمجرد أن استقر شعور “يا إلهي” في داخلي، أمسكت بقائد فريقي وأخبرته بما حدث. لحسن الحظ، كان متفهمًا، وبدأنا العمل على محاولة التراجع عن الخطأ.
الشيء المؤسف في تحديث قاعدة بيانات خاطئ هو أنه لا توجد طريقة سهلة للتراجع عن هذا التغيير. لا يمكنك ببساطة التراجع عن بعض الالتزامات (commits) وإعادة النشر (re-deploy) – فقاعدة البيانات هي تخزين دائم لسبب وجيه. عندما يحدث خطأ ما في البيانات، لديك خياران:
- كتابة استعلام جديد للتراجع عن البيانات (إذا كان ذلك ممكنًا).
- تحميل نسخة احتياطية من قاعدة البيانات والعثور على البيانات الصحيحة، استخراجها، وتشغيل تحديث جديد.
بقدر ما يبدو الخيار الثالث (الذهاب إلى المكسيك) مغريًا، فقد اخترنا الخيار الثاني. حدث هذا قبل ما يقرب من عشر سنوات، لذلك كانت ممارسات DevOps مختلفة بعض الشيء آنذاك. كانت هذه الشركة تدير خوادمها وقواعد بياناتها الخاصة، وكانت تعتمد على “النسخ الاحتياطية على الأشرطة” (tape backups). كما أنها كانت تحتفظ بنسخ احتياطية يومية فقط، لذلك في أفضل الأحوال، كان بإمكاننا استعادة بيانات من وقت مبكر من اليوم السابق. وغني عن القول، أن هذا كان سيكون مؤلمًا.
باختصار، حاولنا معرفة ما إذا كانت هناك طريقة لإعادة إنشاء البيانات الأصلية وإعادة تحديثها. بعد بضع ساعات، استعدنا البيانات إلى حالتها الأصلية – لكن هذا ليس الجزء المهم من القصة. الجزء المهم هو الاعتراف بالخطأ. حاول إصلاحه. تعلم ولا تدعه يتكرر مرة أخرى. إذا ارتكبت خطأ، سيقدر زملاؤك في الفريق كثيرًا عملك النشط لمحاولة إصلاحه. حتى لو كان ذلك مجرد المشاركة في حل المشكلة أو مشاهدتهم وهم يصلحونها، انغمس وشارك. أخيرًا، تعلم من هذا الخطأ ولا ترتكب نفس الخطأ مرتين. (تذكر: اسحب من الأسفل إلى الأعلى).
الخطأ الثاني: سبع سنوات لاحقًا…
بعد تلك الفترة، استمتعت بفترة طويلة خالية من الأخطاء الكبيرة استمرت حوالي سبع سنوات. الآن، بعد سبع سنوات، وبدلاً من لقب “مطور مبتدئ” (Junior Developer)، كنت أرتدي قبعة “مهندس برمجيات أول” (Senior Software Engineer) اللامعة.
كان يومًا عاديًا كأي يوم آخر. كتابة الكود، رفعه، مراجعات الكود، النشر – مجرد سحق عام للأكواد. تلقيت إشعارًا على Slack حول مجموعة من مهام الخلفية (background workers) التي كانت تفشل. قال زميلي في العمل إن الأمر يبدو مرتبطًا بآخر طلب سحب (PR) قمت بدمجه مؤخرًا. “حسنًا شكرًا، سأتحقق من ذلك”، أجبت.
نعم، كان هناك بالتأكيد عدد كبير من المهام تفشل وتتراكم. لم أكن قلقًا جدًا في البداية. يتم عادةً كتابة مهام الخلفية بطريقة “متطابقة التأثير” (idempotent) – أي أنها آمنة بشكل عام لإعادة تشغيلها عند فشلها. تحتوي معظم أنظمة قائمة الانتظار الخلفية (background queueing systems) أيضًا على طريقة مدمجة لإعادة محاولة تشغيل المهام تلقائيًا بعد فشلها.
لم يمض وقت طويل بعد ذلك، ومع ذلك، حتى ساءت الأمور. بدأت أجراس الإنذار تدق – أو بشكل أكثر واقعية – بدأت إشعارات Slack في غرفة المناوبة (on-call room) تصدر أصواتًا. مهلة بعد مهلة بعد مهلة (Timeouts after timeouts). استخدام قاعدة البيانات وصل إلى 100%. النظام بأكمله كان يتجه نحو حالة توقف تام (deadlock). جميع منتجات الشركة توقفت تمامًا. يا إلهي!
لم أكن أعرف لماذا يحدث هذا، لكنني كنت أعرف أنه أمر سيء. وهكذا فعلت الشيء الوحيد الذي عرفت كيف أفعله: تسجيل الخروج والتوجه إلى المكسي—أقصد إخبار أحدهم فورًا.
قفزنا إلى مكالمة Zoom (قبل أن يصبح Zoom معروفًا للعالم بأسره بفضل عام 2020). بينما كنا نحقق في الأمر، لاحظنا أن استعلامًا معينًا كان يستغرق وقتًا طويلاً جدًا لإكماله. كانت كل نسخة من هذا الاستعلام تستغرق عدة دقائق للتشغيل، وكان هناك عدد متزايد باستمرار منها يتم تشغيله كل دقيقة.
بدأنا في البحث في الالتزامات الأخيرة (recent commits) في منطقة قاعدة الكود حيث بدا أن المشكلة تنبع منها، ووجدنا شيئًا مشبوهًا: آخر طلب سحب لي. في طلب السحب هذا، قمت بتحديث مهمة خلفية وغيرت سلوكها. كان هذا المشروع يعتمد على إطار عمل Ruby on Rails، وكان التغيير الذي أجريته شيئًا كهذا – ولكن إذا لم ترَ Rails من قبل، فلا تقلق، سأشرح كل سطر:
def run (some_status)
items = Item.where( status: some_status).all
items.each do |item|
# do some database querying and updating
end
endتستدعي مهمة الخلفية هذه دالة، run، ويتم تمرير قيمة حالة (status value) كمعلمة (some_status). السطر الأول من الدالة يستعلم عن بعض السجلات من قاعدة البيانات. يستخدم هذا السطر طرقًا من جزء ActiveRecord من إطار عمل Rails، ولكنه في الواقع مجرد أغلفة لطيفة حول استعلامات SQL الأساسية.
items = Item.where( status: some_status).allهذا السطر هو في الواقع مجرد عبارة SQL بسيطة:
SELECT * FROM items WHERE status = ?عند تشغيل الاستعلام، يتم ربط قيمة some_status بالرمز النائب (placeholder) (?) في الاستعلام ثم يتم تنفيذه. بعد أن تُرجع قاعدة البيانات نتائج الاستعلام، يأخذ Rails هذه السجلات ويُنشئ منها كائنات Ruby أنيقة ومرتبة.
باختصار، نستعلم عن جدول items حيث تكون قيمة status قيمة معينة. (مرة أخرى، هذا ليس بالضبط ما كنت أفعله ولكنه قريب بما يكفي لتوضيح السيناريو).
الأسطر القليلة التالية هي حلقة بسيطة (loop) على العناصر التي استرجعناها، ولكل عنصر نقوم ببعض الاستعلامات الإضافية على قاعدة البيانات ثم نقوم بتحديث بعض المعلومات حول العنصر.
items.each do |item|
# do some database querying
# then update the item
endبسيط جدًا، أليس كذلك؟ احصل على الأشياء. كرر على الأشياء. حدث الأشياء. ومع ذلك، هناك شيء واحد لم أدركه هنا – وهو أمر كبير.
المشكلة الخفية: قيمة NULL أو nil
حقل status لا يحتوي على قيد NOT NULL. هذا يعني أن حقل status يمكن أن يكون NULL – أو في عالم Ruby: nil (أو null في لغات أخرى). من السهل أن تعتاد على الاستعلام بناءً على أشياء مثل المعرفات (IDs) التي تعرف أنها ستكون موجودة دائمًا. سطر مشابه مثل:
items = Item.where(id: list_of_ids).all…لم يكن ليُنتج نفس المشكلة. استعلام يبحث عن سجلات بمعرفاتها مع قائمة معرفات فارغة لا يُرجع شيئًا، وبالتالي لا يتم فعل أي شيء.
ولكن في هذه الحالة، هنا تكمن المشكلة. هذا الجزء من الكود:
items = Item.where( status: some_status).allيبحث عن جميع سجلات Item حسب حالة محددة – تلك التي تم تمريرها عبر معلمة some_status. ولكن، يمكن أن تكون قيمة هذا العمود NULL (أو nil). لذا، إذا تم تمرير معلمة some_status كـ nil، فسيحاول البحث عن جميع سجلات Item حيث status = nil.
حسنًا، لكن هذا لا يبدو سيئًا جدًا، أليس كذلك؟ حسنًا، الطبقة التالية في “بصلة الرعب” هذه هي حقيقة أن جدول items هذا يحتوي على 40 مليون صف – ومعظمها لم يكن له حالة (status). هذه الدالة الصغيرة التي كانت تحاول في الأصل تحميل عدد قليل من السجلات، والتكرار عليها، والقيام ببعض العمل، أصبحت الآن تتكرر عبر الجدول بأكمله.
لذلك، عندما بدأت كل واحدة من هذه المئات أو الآلاف من المهام التي كانت تُشغل على فترات منتظمة (إذا تذكرت بشكل صحيح، كل 15 دقيقة تقريبًا)، بدأت كل منها في تنفيذ استعلامات مكلفة للغاية لكل سجل تقريبًا في الجدول. كان ذلك وحده ربما كافيًا لإغراق النظام، لكن الأمور ساءت بالفعل.
كما ترون، لم أكن أتوقع تمرير قيمة nil. هذه القيمة nil أدت أيضًا إلى تعطيل جزء من الكود الذي كان من المفترض أن تقوم به المهمة، وهكذا بدأت كل من هذه المهام في الفشل بدورها. عادةً، لن يكون هذا أمرًا كبيرًا، ولكن في معظم الأنظمة، عندما تفشل مهمة خلفية، يتم إعادة إدراجها في قائمة الانتظار بعد فترة قصيرة. لذا، لم تكن جميع هذه المهام المكلفة للغاية تفشل فحسب، بل كانت تفشل وتبدأ مرة أخرى بعد فترة قصيرة – واستمرت في التراكم. المهام الفاشلة كانت ستُقابل في النهاية بدفعة جديدة من المهام التي تبدأ في فتراتها الخاصة، وتوقف النظام تمامًا.
الضربة القاضية الأخيرة هي أن العمل الذي كان من المفترض أن تقوم به مهمة الخلفية هذه هو تحديث جميع تلك السجلات. وهذا يعني أنني كنت أتكرر عبر كل سجل في هذا الجدول وأقوم مرة أخرى بتحديث الجدول بأكمله ببيانات خاطئة.
بمحض الحظ، كان لدي نعمة واحدة هنا. لم تكن نتيجة هذا الاستعلام مرتبة. وهذا يعني أنه بشكل افتراضي، تم إرجاع أقدم (أو أول) سجلات الجدول أولاً. قد لا يبدو هذا ذا صلة، لكن السجلات الأولى والأقدم كانت في الواقع بيانات قديمة (legacy data) – لذا فإن تحديث هذه السجلات لم يكن سيئًا تقريبًا مثل السجلات التي يتفاعل معها العملاء يوميًا.
بالإضافة إلى ذلك، استمرت المهمة في الانهيار مبكرًا في تنفيذها وإعادة التشغيل – مما أدى إلى قيام المهام بتحديث نفس الجزء الصغير والقديم من الجدول مرارًا وتكرارًا فقط. وهذا يعني أن هذه المهام لم تصل أبدًا إلى الصفوف الأحدث والأكثر صلة في الجدول. في الأساس، قامت المهمة بتحديث جزء صغير وغير مهم من الجدول قبل إيقاف التشغيل والمحاولة مرة أخرى (إذا تذكرت بشكل صحيح، بضعة آلاف فقط من الصفوف من أصل حوالي 40 مليونًا). كان الأمر كما لو أنني تعثرت وسقطت مجازًا أثناء السير نحو معبر للمشاة – مما منعني من الاصطدام بالسيارة التي كانت ستتجاوز إشارة التوقف.
الحل البسيط: منع تمرير nil
بينما كنا نراجع طلب السحب (PR) الخاص بي في مكالمة Zoom، عثر أحدهم في النهاية على الخطأ وأشار إلى السطر المسبب للمشكلة (الاستعلام الذي يبحث عن السجلات بناءً على status). حتى بعد أن ذكروا المشكلة بصوت عالٍ، لم أستطع رؤيتها. بعد أن حاولوا شرحها مرة أخرى (وربما مرة أخرى)، استوعبت الأمر أخيرًا. إنه سطر كود خادع مثل هذا:
items = Item.where( status: some_status).allالبحث عن العنصر حسب حالته—يبدو جيدًا بالتأكيد. إذا لم تكن حذرًا ستفعل مثلي وتفوت حالة البحث الحرجة عندما تكون القيمة nil.
لحسن الحظ، الإصلاح لذلك سهل حقًا. قم بحماية الدالة وقم بإجراء عودة سريعة (quick-return) كهذه إذا كانت الحالة nil:
def run (some_status)
return if some_status. nil ?
items = Item.where( status: some_status).all
...
endإذا لم تكن ملمًا بلغة Ruby وإطار عمل Rails، فإن هذا السطر الواحد هو مجرد “سكر نحوي” (syntactic sugar) لهذا:
def run (some_status)
if some_status == nil
return
end
items = Item.where( status: some_status).all
...
endبشكل أساسي، إذا كانت قيمة some_status هي nil، فما عليك سوى العودة مبكرًا من الدالة ومغادرة المكان.
هذا هو الإصلاح الذي قمنا بنشره في النهاية، وبعد بعض عمليات إعادة تشغيل الخوادم وإيقاف قائمة انتظار مهام الخلفية المتزايدة والاستعلامات طويلة الأمد، عادت الأمور تدريجيًا إلى طبيعتها. وبما أن هذا حدث في عام 2019، فقد كانت لدينا حلول نسخ احتياطي أفضل. قمنا بتحميل نسخة احتياطية حديثة وقمنا (بعناية) بإنشاء عبارة تحديث لإعادة البيانات إلى حالتها السابقة. وهكذا، انتهت “أزمة التحديث 2019” (UpdateGate2019™) أخيرًا.
الدروس المستفادة من هذه التجارب
هناك بعض الدروس الرئيسية المستفادة من هذه القصص:
-
استعلامات التحديث (
UPDATE) خطيرة: كان كلا خطأي يتعلقان باستعلامات التحديث. عند تحديث (أو حذف) السجلات، توخَّ حذرًا إضافيًا لضمان أن السجلات التي ستقوم بتحديثها هي السجلات الصحيحة.- إذا كنت تقوم بتنفيذ استعلام
SQLخام (raw SQL query)، فتأكد من السحب “من الأسفل إلى الأعلى” لضمان تشغيل العبارة بأكملها. - إذا كنت تقوم بتحديث من خلال الكود، فكن حذرًا جدًا من المعلمات (
parameters) والأجزاء الديناميكية من استعلامك. تحقق من قيمnilأوNULLأوnullاعتمادًا على لغتك البرمجية.
- إذا كنت تقوم بتنفيذ استعلام
- إذا حدث خطأ ما، أخبر أحدهم فورًا: إخفاء المشكلة أو تجاهلها سيجعل الأمور أسوأ فقط. كلما أسرعت في إبلاغ فريقك بالمشكلة، كلما أمكنك إيقاف استمرار الضرر مبكرًا، وسيوفر عليك الكثير من المعاناة على المدى الطويل.
-
لا أحد يُفصل بسبب خطأ صادق: في كلتا الحالتين، أدرك فريقي أن الخطأ كان صادقًا. بعد ذلك، قمنا بإجراء مراجعة بعدية (
retrospective) لتحديد كيف حدث الخطأ وما يمكننا فعله لتجنب نفس الخطأ في المستقبل. غالبًا ما تنبع الأخطاء من نفس السبب الجذري: التسرع في إنجاز العمل. المواعيد النهائية الوشيكة، العقول المتعبة، وعدم مراجعة طلبات السحب (PRs) بالتدقيق الكافي يمكن أن يتسبب في تسرب العديد من الأخطاء.
الخلاصة التقنية
تُظهر هذه التجارب بوضوح أن الأخطاء جزء لا مفر منه من دورة حياة تطوير البرمجيات، حتى بالنسبة للمهندسين ذوي الخبرة. تكمن القيمة الحقيقية ليس في تجنب الأخطاء تمامًا، بل في تطوير ثقافة الشفافية، والتعلم السريع من الفشل، وتطبيق أفضل الممارسات التي تقلل من تأثير هذه الأخطاء. إن استخدام تقنيات مثل “السحب من الأسفل إلى الأعلى” في استعلامات SQL، والتحقق من حالات القيم الفارغة (nil/NULL) في الكود، والأهم من ذلك، الإبلاغ الفوري عن المشاكل، هي ركائز أساسية للحفاظ على استقرار الأنظمة الحية وضمان استمرارية الأعمال. هذه الدروس لا تحمي بيئة الإنتاج فحسب، بل تعزز أيضًا من مرونة الفريق وقدرته على التعلم والتطور.
نحو الأمام
يسعدني أن أعرف أن لدي ست سنوات جيدة أخرى قبل أن أرتكب خطأ فادحًا آخر (أمزح). أعلم أنني سأرتكب خطأ آخر – فالأخطاء تحدث. لكن هذه الأخطاء لم تدمر مسيرتي المهنية أو تملأني بالخجل. إنه مجرد خطأ. لقد حاولت التعلم منه، وآمل أن تتعلموا أنتم أيضًا من أخطائي بقراءة هذا المقال دون الحاجة إلى تجربتها بأنفسكم.
إذا استمتعت بهذا المنشور، يمكنك متابعتي على Twitter حيث أتحدث عن أشياء مثل هذه – تطوير المسار الوظيفي وكيفية النجاح كمطور. أكتب أيضًا عن نفس هذه المواضيع على موقعي. شكرًا للقراءة!
جون