كيفية استخدام Texthero لإعداد مجموعات البيانات النصية لمشاريع معالجة اللغات الطبيعية (NLP)

تُعد معالجة اللغات الطبيعية (NLP) أحد أهم مجالات الدراسة والبحث في عالمنا المعاصر، وتمتلك تطبيقات واسعة ومتنوعة في القطاع التجاري، مثل روبوتات الدردشة (chatbots)، وتحليل المشاعر (sentiment analysis)، وتصنيف المستندات. ومع ذلك، فإن إعداد وتمثيل النصوص يمثلان جزءًا معقدًا وشاقًا في أي مشروع NLP، حيث يمكن أن تكون مجموعات البيانات النصية صعبة للغاية وتتطلب جهدًا كبيرًا في المعالجة المسبقة. لحسن الحظ، ظهرت حزمة بايثون حديثة تُدعى Texthero لتبسيط هذه التحديات وتقديم حلول فعالة.
ما هو Texthero؟
Texthero هي مجموعة أدوات بسيطة ومُحكمة في بايثون، مصممة خصيصًا لتبسيط التعامل مع مجموعات البيانات النصية. توفر هذه الحزمة وظائف سريعة وسهلة تمكنك من إجراء المعالجة المسبقة، وتمثيل البيانات النصية، وتحويلها إلى متجهات، وتصورها ببضعة أسطر من التعليمات البرمجية فقط.
![]()
صُممت Texthero لتعمل بسلاسة فوق مكتبة pandas، مما يسهل معالجة وتحليل سلاسل Pandas Series أو إطارات البيانات DataFrames النصية. إذا كنت تعمل على مشروع NLP، فإن Texthero يمكن أن يساعدك على إنجاز المهام بشكل أسرع، مما يتيح لك مزيدًا من الوقت للتركيز على الجوانب الأكثر أهمية في مشروعك.
ملاحظة هامة: مكتبة Texthero لا تزال في مرحلة الإصدار التجريبي (beta version). قد تواجه بعض الأخطاء البرمجية (bugs) أو قد تتغير بعض مسارات العمل (pipelines). من المتوقع إصدار نسخة أسرع وأفضل في المستقبل القريب، والتي ستجلب معها تحسينات وتغييرات جوهرية.
نظرة عامة على وحدات Texthero
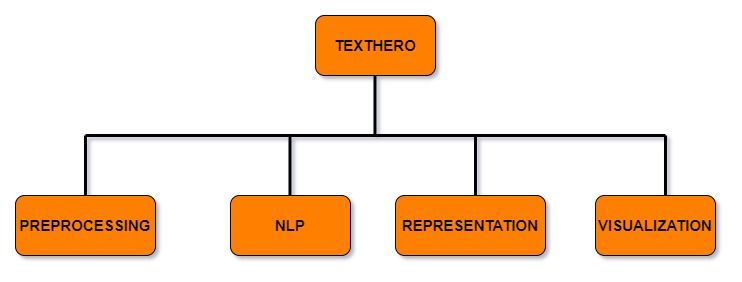
تتألف مكتبة Texthero من أربع وحدات رئيسية مفيدة، كل منها يتعامل مع مجموعة مختلفة من الوظائف التي يمكنك تطبيقها على مجموعات البيانات النصية الخاصة بك:
وحدة المعالجة المسبقة (Preprocessing)
تُمكن هذه الوحدة من المعالجة المسبقة الفعالة لسلاسل Pandas Series أو إطارات البيانات DataFrames النصية. توفر طرقًا متنوعة لتنظيف مجموعات البيانات النصية، مثل تحويل الأحرف إلى أحرف صغيرة باستخدام lowercase()HTML باستخدام remove_html_tags()remove_urls()
وحدة معالجة اللغات الطبيعية (NLP)
تتضمن هذه الوحدة عددًا من مهام NLP الجاهزة للاستخدام، مثل استخراج الكيانات المسماة (named_entities) وتحديد الكتل الاسمية (noun_chunks)، وغيرها من الوظائف المتقدمة.
وحدة التمثيل (Representation)
تحتوي هذه الوحدة على خوارزميات مختلفة لتحويل الكلمات إلى متجهات (vectors)، وهي خطوة أساسية في العديد من تطبيقات NLP. من الأمثلة على هذه الخوارزميات TF-IDF، وGloVe، وتحليل المكونات الرئيسية (Principal Component Analysis - PCA)، وتردد المصطلح (term_frequency).
وحدة التصور (Visualization)
تُعد هذه الوحدة الأخيرة أداة قوية لتصور الرؤى والإحصائيات المستخلصة من إطارات بيانات Pandas DataFrame النصية. توفر ثلاث طرق مختلفة للرسم البياني، مثل رسم المخططات المبعثرة (scatter plot) وإنشاء سحابة الكلمات (word cloud).
تثبيت مكتبة Texthero
تتميز مكتبة Texthero بكونها مجانية، مفتوحة المصدر، وموثقة بشكل جيد. لتثبيتها، كل ما عليك فعله هو فتح نافذة طرفية (terminal) أو موجه الأوامر (command prompt) وتنفيذ الأمر التالي:
pip install textheroتعتمد هذه الحزمة على عدد كبير من المكتبات الأخرى في الخلفية، مثل Gensim وSpaCy وscikit-learn وNLTK. لا داعي للقلق بشأن تثبيت كل منها على حدة، حيث سيتولى مدير الحزم pip مهمة تثبيت جميع التبعيات الضرورية تلقائيًا.
كيفية استخدام Texthero
في هذا المقال، سنستخدم مجموعة بيانات إخبارية لتوضيح كيفية الاستفادة من الطرق المختلفة التي توفرها وحدات Texthero في مشروع NLP الخاص بك. سنبدأ باستيراد حزم بايثون الأساسية التي سنحتاجها:
# استيراد الحزم الهامة
import texthero as hero
import pandas as pdبعد ذلك، سنقوم بتحميل مجموعة بيانات من دليل data. تركز مجموعة البيانات المستخدمة في هذا المقال على الأخبار المكتوبة باللغة السواحلية:
# تحميل مجموعة البيانات
data = pd.read_csv(
"data/swahili_news_dataset.csv"
)لنلقِ نظرة سريعة على أول 5 صفوف من مجموعة البيانات:
# عرض أول 5 صفوف
data.head()
كما نلاحظ، تحتوي مجموعة البيانات لدينا على ثلاثة أعمدة: id وcontent وcategory. في هذا المقال، سنركز بشكل أساسي على ميزة content (المحتوى).
# تحديد محتوى الأخبار فقط وعرض أول 5 صفوف
news_content = data[[ "content" ]]
news_content.head()لقد قمنا بإنشاء إطار بيانات جديد يركز فقط على عمود المحتوى، ثم عرضنا أول 5 صفوف منه.

المعالجة المسبقة باستخدام Texthero
يمكننا استخدام الدالة clean()Texthero لإجراء المعالجة المسبقة لسلاسل Pandas Series النصية.
# تنظيف محتوى الأخبار باستخدام الدالة clean من حزمة hero
news_content[ 'clean_content' ] = hero.clean(news_content[ 'content' ])تقوم الدالة clean()pandas إليها. هذه الوظائف هي:
lowercase(s)remove_diacritics()remove_stopwords()stopwords) التي لا تضيف قيمة دلالية كبيرة (مثل “و”، “من”، “في”).remove_digits()remove_punctuation()!"#$%&'()*+,-./:;<=>?@[]^ `{|}~).fillna(s)NaN) بمسافات فارغة.remove_whitespace()
الآن، يمكننا مقارنة محتوى الأخبار الأصلي بالمحتوى المنظف:
# عرض محتوى الأخبار غير النظيف والنظيف
news_content.head()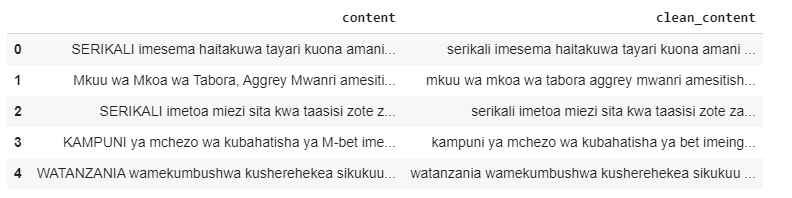
تنظيف مخصص (Custom Cleaning)
إذا لم تتناسب مسار العمل الافتراضي (default pipeline) لدالة clean()custom pipeline) يتضمن قائمة بالوظائف التي ترغب في تطبيقها على مجموعة بياناتك. على سبيل المثال، قمنا بإنشاء مسار عمل مخصص يضم 5 وظائف فقط لتنظيف مجموعة البيانات:
# إنشاء مسار عمل مخصص
from texthero import preprocessing
custom_pipeline = [
preprocessing.fillna,
preprocessing.lowercase,
preprocessing.remove_whitespace,
preprocessing.remove_punctuation,
preprocessing.remove_urls,
]الآن، يمكننا استخدام custom_pipeline لتنظيف مجموعة البيانات الخاصة بنا:
# بديل لمسار العمل المخصص
news_content[ 'clean_custom_content' ] = news_content[ 'content' ].pipe(hero.clean, custom_pipeline)يمكنك الآن رؤية مجموعة البيانات المنظفة التي أنشأناها باستخدام مسار العمل المخصص:
# عرض مخرجات مسار العمل المخصص
news_content.clean_custom_content.head()
وظائف معالجة مسبقة مفيدة أخرى
فيما يلي بعض الوظائف المفيدة الأخرى من وحدة المعالجة المسبقة (preprocessing) التي يمكنك تجربتها لتنظيف مجموعة البيانات النصية الخاصة بك:
إزالة الأرقام (Remove digits)
يمكنك استخدام الدالة remove_digits()
text = pd.Series( "Hi my phone number is +255 711 111 111 call me at 09:00 am" )
clean_text = hero.preprocessing.remove_digits(text)
print(clean_text)output:
Hi my phone number is + call me at : am
dtype: objectإزالة الكلمات الشائعة (Remove stopwords)
يمكنك استخدام الدالة remove_stopwords()stopwords) من مجموعات البيانات النصية:
text = pd.Series( "you need to know NLP to develop the chatbot that you desire" )
clean_text = hero.remove_stopwords(text)
print(clean_text)output:
need know NLP develop chatbot desire
dtype: objectإزالة الروابط (Remove URLs)
يمكنك استخدام الدالة remove_urls()URLs) من مجموعات البيانات النصية:
text = pd.Series( "Go to https://www.freecodecamp.org/news/ to read more articles you like" )
clean_text = hero.remove_urls(text)
print(clean_text)output:
Go to to read more articles you like
dtype: objectتقسيم الكلمات (Tokenize)
تقوم الدالة tokenize()Pandas Series المعطاة إلى كلمات (tokens)، وتعيد سلسلة Pandas Series حيث يحتوي كل صف على قائمة من هذه الكلمات:
text = pd.Series([ "You can think of Texthero as a tool to help you understand and work with text-based dataset. " ])
clean_text = hero.tokenize(text)
print(clean_text)output:
[You, can, think, of, Texthero, as, a, tool, to, help, you, understand, and, work, with, text, based, dataset]
dtype: objectإزالة وسوم HTML (Remove HTML tags)
يمكنك إزالة وسوم HTML من سلسلة Pandas Series المعطاة باستخدام الدالة remove_html_tags()
text = pd.Series( "<html><body><h2>hello world</h2></body></html>" )
clean_text = hero.remove_html_tags(text)
print(clean_text)output:
hello world
dtype: objectوظائف التصور المفيدة
تحتوي مكتبة Texthero على طرق متنوعة لتصور الرؤى والإحصائيات المستخلصة من إطار بيانات Pandas DataFrame النصي.
الكلمات الأكثر شيوعًا (Top words)
إذا كنت ترغب في معرفة الكلمات الأكثر شيوعًا في مجموعة البيانات النصية الخاصة بك، يمكنك استخدام الدالة top_words()visualization). هذه الدالة مفيدة بشكل خاص إذا كنت تبحث عن كلمات إضافية يمكنك إضافتها إلى قوائم الكلمات الشائعة (stopwords). نظرًا لأن هذه الدالة لا تُرجع رسمًا بيانيًا شريطيًا بشكل مباشر، سنستخدم مكتبة matplotlib لتصور الكلمات الأكثر شيوعًا في رسم بياني شريطي:
import matplotlib.pyplot as plt
NUM_TOP_WORDS = 20
top_20 = hero.visualization.top_words(news_content[ 'clean_content' ]).head(NUM_TOP_WORDS)
# رسم المخطط الشريطي
top_20.plot.bar(rot= 90 , title= "أكثر 20 كلمة شيوعًا" );
plt.show(block= True );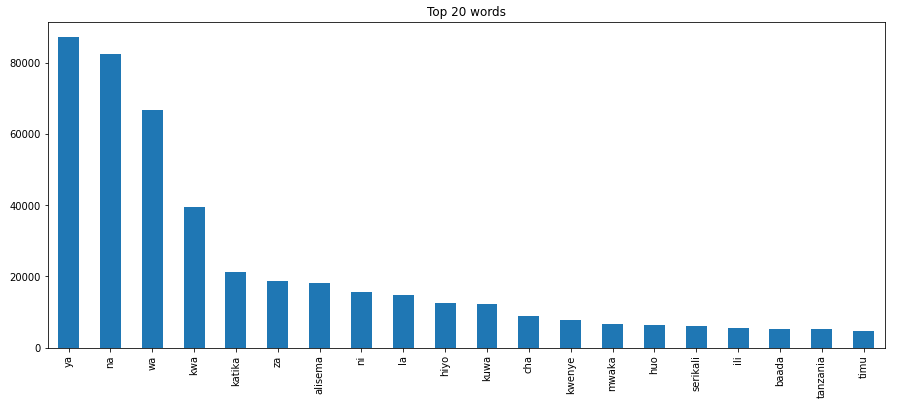
في الرسم البياني أعلاه، يمكننا تصور أكثر 20 كلمة شيوعًا من مجموعة البيانات الإخبارية الخاصة بنا.
سحابة الكلمات (Wordclouds)
تقوم الدالة wordcloud()visualization) برسم صورة باستخدام مكتبة WordCloud.
# رسم صورة سحابة الكلمات باستخدام دالة WordCloud
hero.wordcloud(news_content.clean_content, max_words= 100 ,)لقد قمنا بتمرير سلسلة إطار البيانات وعدد الكلمات القصوى (في هذا المثال، 100 كلمة) إلى الدالة wordcloud()

وظائف التمثيل المفيدة
تحتوي مكتبة Texthero على طرق متنوعة ضمن وحدة التمثيل (representation) تساعدك على تحويل الكلمات إلى متجهات (vectors) باستخدام خوارزميات مختلفة مثل TF-IDF وword2vec أو GloVe. في هذا القسم، سأوضح لك كيفية استخدام هذه الطرق.
TF-IDF (تردد المصطلح – معكوس تردد المستند)
يمكنك تمثيل سلسلة Pandas Series النصية باستخدام TF-IDF. لقد قمت بإنشاء سلسلة pandas جديدة تحتوي على جزأين من محتوى الأخبار، وقمت بتمثيلهما في ميزات TF-IDF باستخدام الدالة tfidf()
# إنشاء سلسلة Pandas Series نصية جديدة.
news = pd.Series([
"mkuu wa mkoa wa tabora aggrey mwanri amesitisha likizo za viongozi wote mkoani humo kutekeleza maazimio ya jukwaa la fursa za biashara la mkoa huo",
"serikali imetoa miezi sita kwa taasisi zote za umma ambazo hazitumii mfumo wa gepg katika ukusanyaji wa fedha kufanya hivyo na baada ya hapo itafanya ukaguzi na kuwawajibisha"
])
# تحويل إلى ميزات tfidf
hero.tfidf(news)output:
[0.187132760851739, 0.0, 0.187132760851739, 0....
[0.0, 0.18557550845969953, 0.0, 0.185575508459...
dtype: objectملاحظة: يرمز TF-IDF إلى Term Frequency-Inverse Document Frequency، وهو مقياس إحصائي يعكس مدى أهمية كلمة ما لمستند في مجموعة أو مجموعة نصية.
تردد المصطلح (Term Frequency - TF)
يمكنك تمثيل سلسلة Pandas Series النصية باستخدام الدالة term_frequency()TF) لإظهار مدى تكرار تعبير (مصطلح أو كلمة) في مستند أو محتوى نصي:
news = pd.Series([
"mkuu wa mkoa wa tabora aggrey mwanri amesitisha likizo za viongozi wote mkoani humo kutekeleza maazimio ya jukwaa la fursa za biashara la mkoa huo",
"serikali imetoa miezi sita kwa taasisi zote za umma ambazo hazitumii mfumo wa gepg katika ukusanyaji wa fedha kufanya hivyo na baada ya hapo itafanya ukaguzi na kuwawajibisha"
])
# تمثيل سلسلة Pandas Series نصية باستخدام term_frequency.
hero.term_frequency(news)output:
[1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, ...
[0, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, ...
dtype: objectتجميع K-means
يمكن لـ Texthero تنفيذ خوارزمية تجميع K-means باستخدام الدالة kmeans()unlabeled)، يمكنك استخدام هذه الدالة لتجميع المحتوى بناءً على أوجه التشابه بينه. في هذا المثال، سنقوم بإنشاء إطار بيانات pandas جديد يُسمى news مع الأعمدة التالية: content وtfidf وkmeans_labels.
column_names = [ "content" , "tfidf" , "kmeans_labels" ]
news = pd.DataFrame(columns = column_names)سنستخدم أول 30 جزءًا فقط من المحتوى المنظف من إطار بيانات news_content الخاص بنا، وسنقوم بتجميعها في مجموعات باستخدام الدالة kmeans()
# جمع 30 محتوى نظيف.
news[ "content" ] = news_content.clean_content[: 30 ]
# تحويلها إلى ميزات tf-idf.
news[ 'tfidf' ] = (
news[ 'content' ]
.pipe(hero.tfidf)
)
# تنفيذ خوارزمية التجميع باستخدام kmeans()
news[ 'kmeans_labels' ] = (
news[ 'tfidf' ]
.pipe(hero.kmeans, n_clusters= 5 )
.astype(str)
)في الشيفرة المصدرية أعلاه، قمنا بتمرير عدد المجموعات (n_clusters=5) إلى مسار عمل دالة k-means. هذا يعني أننا سنقوم بتجميع هذه المحتويات في 5 مجموعات. الآن، تم تصنيف محتوى الأخبار المحدد إلى خمس مجموعات.
# عرض المحتوى وتصنيفاته
news[[ "content" , "kmeans_labels" ]].head()
تحليل المكونات الرئيسية (PCA)
يمكنك أيضًا استخدام الدالة pca()Principal Component Analysis) على سلسلة Pandas Series المعطاة. تحليل المكونات الرئيسية (PCA) هو تقنية لتقليل أبعاد مجموعات البيانات الخاصة بك. تزيد هذه التقنية من قابلية التفسير مع تقليل فقدان المعلومات في نفس الوقت. في هذا المثال، سنستخدم ميزات tfidf من إطار بيانات news ونمثلها في مكونين باستخدام الدالة pca()scatterplot) باستخدام الدالة scatterplot()
# تنفيذ تحليل المكونات الرئيسية (pca)
news[ 'pca' ] = news[ 'tfidf' ].pipe(hero.pca)
# عرض المخطط المبعثر
hero.scatterplot(news, 'pca' , color= 'kmeans_labels' , title= "الأخبار" )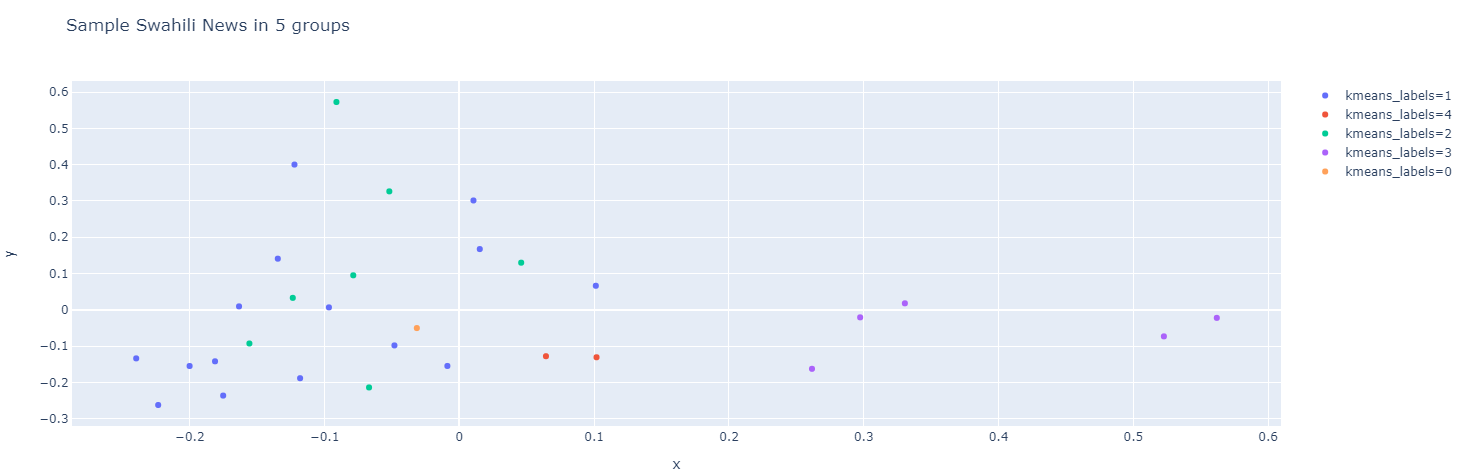
خاتمة
في هذا المقال، تعرفت على أساسيات كيفية استخدام حزمة أدوات بايثون Texthero في مشروع معالجة اللغات الطبيعية (NLP) الخاص بك. لقد استعرضنا كيفية تنظيف البيانات، وتصورها، وتحويلها إلى متجهات، وحتى تطبيق خوارزميات التجميع وتقليل الأبعاد.
يمكنك استكشاف المزيد حول الطرق المتاحة في توثيق Texthero الرسمي.
لتحميل مجموعة البيانات ودفتر الملاحظات (notebook) المستخدمين في هذا المقال، يمكنك زيارة مستودع GitHub هنا: https://github.com/Davisy/Texthero-Python-Toolkit.
إذا تعلمت شيئًا جديدًا أو استمتعت بقراءة هذا المقال، فلا تتردد في مشاركته لتعم الفائدة.
الخلاصة التقنية
يُظهر استعراضنا لحزمة Texthero أنها تمثل إضافة قيمة لمجموعة أدوات أي مطور أو باحث يعمل في مجال معالجة اللغات الطبيعية. في بيئة تتسم فيها مجموعات البيانات النصية بالتعقيد والتنوع، تُقدم Texthero حلاً متكاملاً وفعالاً لتبسيط مهام المعالجة المسبقة والتمثيل والتصور. إن دمجها السلس مع مكتبة pandas يقلل بشكل كبير من الشيفرة المطلوبة لإنجاز المهام، مما يحرر المطورين للتركيز على الجوانب الأكثر تحديًا وإبداعًا في مشاريعهم.
على الرغم من كونها لا تزال في مرحلة التطوير التجريبي، فإن قدرتها على توفير مسارات عمل افتراضية قابلة للتخصيص، بالإضافة إلى دعمها لتقنيات متقدمة مثل TF-IDF وK-means وPCA، يجعلها أداة واعدة للغاية. إنها تُسهم في تسريع دورة حياة تطوير مشاريع NLP، وتجعل تحليل البيانات النصية أكثر سهولة وفعالية، مما يعزز من إمكانية استخلاص رؤى قيمة من البيانات غير المهيكلة.