تقنيات تحسين المعاملات الفائقة (Hyperparameters) لرفع كفاءة نماذج التعلم الآلي

عند العمل على أي مشروع للتعلم الآلي، يتوجب عليك اتباع سلسلة من الخطوات المنهجية للوصول إلى الهدف المنشود. من بين هذه الخطوات الحاسمة، تبرز عملية تحسين المعاملات الفائقة (Hyperparameter Optimization) للنموذج الذي تم اختياره. تأتي هذه المهمة عادةً بعد مرحلة اختيار النموذج الأولي، حيث يتم تحديد النموذج الأفضل أداءً مقارنةً بغيره.
ما هو تحسين المعاملات الفائقة (Hyperparameter Optimization)؟
قبل الخوض في تعريف تحسين المعاملات الفائقة، من الضروري فهم ماهية المعامل الفائق (Hyperparameter) نفسه. باختصار، المعاملات الفائقة هي قيم معلمات مختلفة تُستخدم للتحكم في عملية التعلم، ولها تأثير كبير على أداء نماذج التعلم الآلي. على سبيل المثال، في خوارزمية الغابات العشوائية (Random Forest)، تشمل المعاملات الفائقة عدد المقدرات (n_estimators)، والعمق الأقصى (max_depth)، ومعيار التقسيم (criterion). هذه المعاملات قابلة للضبط ويمكن أن تؤثر بشكل مباشر على مدى جودة تدريب النموذج.
بناءً على ذلك، فإن تحسين المعاملات الفائقة (Hyperparameter Optimization) هو عملية البحث عن التوليفة الصحيحة من قيم المعاملات الفائقة لتحقيق أقصى أداء ممكن على البيانات في فترة زمنية معقولة. تلعب هذه العملية دورًا حيويًا في دقة التنبؤ لخوارزميات التعلم الآلي. ولهذا السبب، يُعتبر تحسين المعاملات الفائقة الجزء الأكثر تعقيدًا في بناء نماذج التعلم الآلي.
تأتي معظم خوارزميات التعلم الآلي بقيم افتراضية لمعاملاتها الفائقة. ولكن هذه القيم الافتراضية لا تؤدي دائمًا بشكل جيد مع جميع أنواع مشاريع التعلم الآلي. لذا، فإن تحسينها ضروري للحصول على التوليفة المثلى التي تضمن أفضل أداء. إن الاختيار الجيد للمعاملات الفائقة يمكن أن يجعل الخوارزمية تتألق حقًا. هناك العديد من الاستراتيجيات الشائعة لتحسين المعاملات الفائقة، دعنا نتعمق في كل منها بالتفصيل.
كيفية تحسين المعاملات الفائقة؟
البحث الشبكي (Grid Search)
تُعد هذه الطريقة تقليدية وشائعة الاستخدام لضبط المعاملات الفائقة، بهدف تحديد القيم المثلى لنموذج معين. يعمل البحث الشبكي عن طريق تجربة كل توليفة ممكنة من المعاملات التي ترغب في اختبارها في نموذجك. هذا يعني أن العملية قد تستغرق وقتًا طويلاً للغاية وتكون مكلفة من الناحية الحسابية (computationally expensive).
البحث العشوائي (Random Search)
تختلف هذه الطريقة قليلًا: حيث تُستخدم توليفات عشوائية من قيم المعاملات الفائقة للعثور على أفضل حل للنموذج المبني. العيب الرئيسي للبحث العشوائي هو أنه قد يفوّت أحيانًا نقاطًا (قيمًا) مهمة في مساحة البحث.
تقنيات بديلة لتحسين المعاملات الفائقة
الآن، سأقدم لك بعض التقنيات/الأساليب البديلة والمتقدمة لتحسين المعاملات الفائقة. يمكن أن تساعدك هذه التقنيات في الحصول على أفضل المعاملات لنموذج معين. سننظر في التقنيات التالية:
HyperoptScikit-OptimizeOptuna
Hyperopt
تُعد Hyperopt مكتبة بايثون قوية لتحسين المعاملات الفائقة، وقد طورها جيمس بيرغسترا (James Bergstra). تستخدم هذه المكتبة شكلًا من أشكال التحسين البايزي (Bayesian optimization) لضبط المعاملات، مما يتيح لك الحصول على أفضل المعاملات لنموذج معين. يمكنها تحسين نموذج يحتوي على مئات المعاملات على نطاق واسع.
تتميز Hyperopt بأربع ميزات مهمة يجب أن تعرفها لتشغيل أول عملية تحسين لك.
مساحة البحث (Search Space)
توفر Hyperopt دوالًا مختلفة لتحديد نطاقات للمعاملات المدخلة. تُسمى هذه المساحات بمساحات البحث العشوائية (stochastic search spaces). الخيارات الأكثر شيوعًا لمساحة البحث هي:
hp.choice(label, options)– يمكن استخدامه للمعاملات الفئوية (categorical parameters). يُرجع أحد الخيارات، والذي يجب أن يكون قائمة أو مجموعة (list or tuple). مثال:hp.choice("criterion", ["gini","entropy",])hp.randint(label, upper)– يمكن استخدامه للمعاملات الصحيحة (Integer parameters). يُرجع عددًا صحيحًا عشوائيًا في النطاق (0, upper). مثال:hp.randint("max_features",50)hp.uniform(label, low, high)– يُرجع قيمة موزعة بشكل منتظم (uniformly) بينlowوhigh. مثال:hp.uniform("max_leaf_nodes",1,10)
خيارات أخرى يمكنك استخدامها هي:
hp.normal(label, mu, sigma)– يُرجع قيمة حقيقية موزعة طبيعيًا بمتوسطmuوانحراف معياريsigma.hp.qnormal(label, mu, sigma, q)– يُرجع قيمة مشابهة لـround(normal(mu, sigma) / q) * q.hp.lognormal(label, mu, sigma)– يُرجع قيمة مستمدة وفقًا لـexp(normal(mu, sigma)).hp.qlognormal(label, mu, sigma, q)– يُرجع قيمة مشابهة لـround(exp(normal(mu, sigma)) / q) * q.
ملاحظة سريعة: كل تعبير عشوائي قابل للتحسين له تسمية (label) (على سبيل المثال، n_estimators) كأول وسيط. تُستخدم هذه التسميات لإرجاع خيارات المعلمات إلى الدالة المستدعية (caller) أثناء عملية التحسين.
دالة الهدف (Objective Function)
هذه دالة تصغير (minimization function) تستقبل قيم المعاملات الفائقة كمدخلات من مساحة البحث وتُرجع قيمة الخسارة (loss). هذا يعني أنه خلال عملية التحسين، نقوم بتدريب النموذج باستخدام قيم المعاملات الفائقة المختارة والتنبؤ بالميزة المستهدفة (target feature). ثم نقوم بتقييم خطأ التنبؤ وإعادته إلى المُحسّن (optimizer). سيقرر المُحسّن أي القيم يجب فحصها وتكرارها مرة أخرى. ستتعلم كيفية إنشاء دوال الهدف في المثال العملي.
الدالة fmin
الدالة fmin هي دالة التحسين التي تتكرر على مجموعات مختلفة من الخوارزميات ومعاملاتها الفائقة، ثم تقوم بتصغير دالة الهدف. تستقبل fmin خمسة مدخلات، وهي:
- دالة الهدف المراد تصغيرها.
- مساحة البحث المحددة.
- خوارزمية البحث المراد استخدامها، مثل البحث العشوائي (
Random search)، وتقديرات بارزن الشجرية (TPE - Tree Parzen Estimators)، وAdaptive TPE.
ملاحظة: توفر الدالتان hyperopt.rand.suggest و hyperopt.tpe.suggest منطقًا للبحث المتسلسل في مساحة المعاملات الفائقة.
- الحد الأقصى لعدد التقييمات.
- كائن التجارب (
trials object) (اختياري).
مثال:
from hyperopt import fmin, tpe, hp,Trials
trials = Trials()
best = fmin(fn= lambda x: x ** 2 , space= hp.uniform( 'x' , -10 , 10 ), algo=tpe.suggest, max_evals= 50 , trials = trials)
print(best)كائن التجارب (Trials Object)
يُستخدم كائن Trials للاحتفاظ بجميع المعاملات الفائقة، وقيم الخسارة (loss)، وغيرها من المعلومات. هذا يعني أنه يمكنك الوصول إليه بعد تشغيل عملية التحسين. كما يمكن أن تساعدك التجارب في حفظ المعلومات الهامة وتحميلها لاحقًا لاستئناف عملية التحسين. ستتعلم المزيد عن هذا في المثال العملي أدناه.
from hyperopt import Trials
trials = Trials()الآن بعد أن فهمت الميزات المهمة لـ Hyperopt، سنرى كيفية استخدامها. ستتبع هذه الخطوات:
- تهيئة المساحة التي سيتم البحث فيها.
- تحديد دالة الهدف.
- اختيار خوارزمية البحث المراد استخدامها.
- تشغيل دالة
hyperopt. - تحليل مخرجات التقييمات المخزنة في كائن
trials.
Hyperopt عمليًا
في هذا المثال العملي، سنستخدم مجموعة بيانات أسعار الهواتف المحمولة (Mobile Price Dataset). مهمتنا هي إنشاء نموذج يتنبأ بمدى ارتفاع سعر الجهاز المحمول: 0 (تكلفة منخفضة)، 1 (تكلفة متوسطة)، 2 (تكلفة عالية)، أو 3 (تكلفة عالية جدًا).
تثبيت Hyperopt
يمكنك تثبيت Hyperopt من PyPI عن طريق تشغيل هذا الأمر:
pip install hyperoptثم استورد الحزم المهمة التالية، بما في ذلك hyperopt:
# import packages
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
from hyperopt import tpe, hp, fmin, STATUS_OK,Trials
from hyperopt.pyll.base import scope
import warnings
warnings.filterwarnings( "ignore" )مجموعة البيانات (Dataset)
دعنا نحمل مجموعة البيانات من دليل البيانات (data directory).
# load data
data = pd.read_csv( "data/mobile_price_data.csv" )تحقق من أول خمسة صفوف من مجموعة البيانات بهذا الشكل:
#read data
data.head()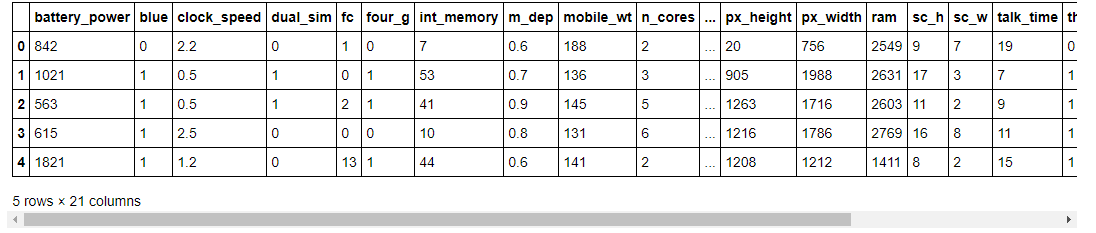
أول خمسة صفوف
كما ترى، في مجموعة بياناتنا لدينا ميزات مختلفة بقيم رقمية. دعنا نلقي نظرة على شكل مجموعة البيانات.
#show shape
data.shapeنحصل على التالي: (2000, 21). في مجموعة البيانات هذه لدينا 2000 صف و 21 عمود. الآن دعنا نفهم قائمة الميزات التي لدينا في مجموعة البيانات هذه.
#show list of columns
list(data.columns)['battery_power', 'blue', 'clock_speed', 'dual_sim', 'fc', 'four_g', 'int_memory', 'm_dep', 'mobile_wt', 'n_cores', 'pc', 'px_height', 'px_width', 'ram', 'sc_h', 'sc_w', 'talk_time', 'three_g', 'touch_screen', 'wifi', 'price_range']
تقسيم مجموعة البيانات إلى ميزة مستهدفة وميزات مستقلة
هذه مشكلة تصنيف (classification problem). لذلك سنقوم الآن بتقسيم الميزة المستهدفة والميزات المستقلة من مجموعة البيانات. ميزتنا المستهدفة هي price_range.
# split data into features and target
X = data.drop( "price_range" , axis= 1 ).values
y = data.price_range.valuesمعالجة مسبقة لمجموعة البيانات (Preprocessing the Dataset)
بعد ذلك، سنقوم بتوحيد الميزات المستقلة باستخدام طريقة StandardScaler من مكتبة scikit-learn.
# standardize the feature variables
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)تحديد مساحة المعاملات للتحسين (Define Parameter Space for Optimization)
سنستخدم ثلاثة معاملات فائقة لخوارزمية الغابات العشوائية (Random Forest): n_estimators، و max_depth، و criterion.
space = {
"n_estimators" : hp.choice( "n_estimators" , [ 100 , 200 , 300 , 400 , 500 , 600 ]),
"max_depth" : hp.quniform( "max_depth" , 1 , 15 , 1 ),
"criterion" : hp.choice( "criterion" , [ "gini" , "entropy" ]),
}لقد قمنا بتعيين قيم مختلفة في المعاملات الفائقة المختارة أعلاه. الآن سنقوم بتعريف دالة الهدف.
تعريف دالة للتصغير (دالة الهدف)
دالتنا التي نريد تصغيرها تسمى hyperparameter_tuning. خوارزمية التصنيف التي سيتم تحسين معاملاتها الفائقة هي Random Forest. أستخدم التحقق المتقاطع (cross validation) لتجنب الإفراط في الملاءمة (overfitting)، ثم ستُرجع الدالة قيم الخسارة وحالتها.
# define objective function
def hyperparameter_tuning ( params ):
clf = RandomForestClassifier(**params,n_jobs= -1 )
acc = cross_val_score(clf, X_scaled, y,scoring= "accuracy" ).mean()
return { "loss" : -acc, "status" : STATUS_OK}تذكر أن hyperopt تقوم بتصغير الدالة. لهذا السبب أضفت علامة السالب إلى acc.
ضبط النموذج (Fine Tune the Model)
أخيرًا، سنقوم أولاً بإنشاء كائن Trial، ثم ضبط النموذج، ثم طباعة أفضل خسارة مع قيم معاملاتها الفائقة.
# Initialize trials object
trials = Trials()
best = fmin(
fn=hyperparameter_tuning,
space = space,
algo=tpe.suggest,
max_evals= 100 ,
trials=trials
)
print( "Best: {}" .format(best))100%|█████████████████████████████████████████████████████████| 100/100 [10:30<00:00, 6.30s/trial, best loss: -0.8915]
Best: {'criterion': 1, 'max_depth': 11.0, 'n_estimators': 2}بعد إجراء تحسين المعاملات الفائقة، كانت الخسارة -0.8915. هذا يعني أن أداء النموذج لديه دقة تبلغ 89.15% باستخدام n_estimators = 300، و max_depth = 11، و criterion = "entropy" في مصنف الغابات العشوائية (Random Forest classifier).
تحليل النتائج باستخدام كائن التجارب (trials object)
يمكن أن يساعدنا كائن trials في فحص جميع القيم المرجعة التي تم حسابها أثناء التجربة.
(أ) trials.results
يعرض هذا قائمة بالقاموسات التي أعادتها الدالة ‘objective‘ أثناء البحث.
trials.results[{'loss': -0.8790000000000001, 'status': 'ok'}, {'loss': -0.877, 'status': 'ok'}, {'loss': -0.768, 'status': 'ok'}, {'loss': -0.8205, 'status': 'ok'}, {'loss': -0.8720000000000001, 'status': 'ok'}, {'loss': -0.883, 'status': 'ok'}, {'loss': -0.8554999999999999, 'status': 'ok'}, {'loss': -0.8789999999999999, 'status': 'ok'}, {'loss': -0.595, 'status': 'ok'},.......](ب) trials.losses()
يعرض هذا قائمة بالخسائر (float لكل تجربة ‘ok‘).
trials.losses()[-0.8790000000000001, -0.877, -0.768, -0.8205, -0.8720000000000001, -0.883, -0.8554999999999999, -0.8789999999999999, -0.595, -0.8765000000000001, -0.877, .........](ج) trials.statuses()
يعرض هذا قائمة بسلاسل الحالة (status strings).
trials.statuses()['ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', ..........]ملاحظة: يمكن حفظ كائن trials هذا، أو تمريره إلى إجراءات الرسم البياني المضمنة، أو تحليله باستخدام الكود المخصص الخاص بك.
الآن بعد أن عرفت كيفية تطبيق Hyperopt، دعنا نتعلم تقنية تحسين المعاملات الفائقة البديلة الثانية التي تسمى Scikit-Optimize.
Scikit-Optimize
تُعد Scikit-optimize مكتبة بايثون أخرى مفتوحة المصدر لتحسين المعاملات الفائقة. تطبق هذه المكتبة عدة طرق للتحسين المتسلسل القائم على النموذج (sequential model-based optimization). المكتبة سهلة الاستخدام للغاية وتوفر مجموعة أدوات عامة للتحسين البايزي (Bayesian optimization) يمكن استخدامها لضبط المعاملات الفائقة. كما توفر دعمًا لضبط المعاملات الفائقة لخوارزميات التعلم الآلي التي تقدمها مكتبة scikit-learn. تم بناء Scikit-optimize على أساس Scipy و NumPy و Scikit-Learn.
تتميز Scikit-optimize بأربع ميزات مهمة على الأقل يجب أن تعرفها لتشغيل أول عملية تحسين لك. دعنا نلقي نظرة عليها بالتفصيل الآن.
مساحة البحث (Space)
توفر scikit-optimize دوالًا مختلفة لتحديد مساحة التحسين التي تحتوي على بُعد واحد أو عدة أبعاد. الخيارات الأكثر شيوعًا لمساحة البحث هي:
Real– هذا بُعد لمساحة البحث يمكن أن يأخذ أي قيمة حقيقية. تحتاج إلى تحديد الحد الأدنى (lower bound) والحد الأقصى (upper bound)، وكلاهما شامل. مثال:Real(low=0.2, high=0.9, name="min_samples_leaf")Integer– هذا بُعد لمساحة البحث يمكن أن يأخذ قيمًا صحيحة. مثال:Integer(low=3, high=25, name="max_features")Categorical– هذا بُعد لمساحة البحث يمكن أن يأخذ قيمًا فئوية. مثال:Categorical(["gini","entropy"],name="criterion")
ملاحظة: في كل مساحة بحث، يجب عليك تحديد اسم المعامل الفائق المراد تحسينه باستخدام الوسيط name.
BayesSearchCV
توفر فئة BayesSearchCV واجهة مشابهة لـ GridSearchCV أو RandomizedSearchCV، لكنها تقوم بالتحسين البايزي على المعاملات الفائقة. تطبق BayesSearchCV طريقة ‘fit‘ وطريقة ‘score‘ وغيرها من الطرق الشائعة مثل _predict()، و predict_proba()، و decision_function()، و transform()، و _inverse_transform() إذا كانت مطبقة في المقدر المستخدم. على عكس GridSearchCV، لا يتم تجربة جميع قيم المعلمات. بدلاً من ذلك، يتم أخذ عينة لعدد ثابت من إعدادات المعلمات من التوزيعات المحددة. يُعطى عدد إعدادات المعلمات التي يتم تجربتها بواسطة n_iter. لاحظ أنك ستتعلم كيفية تطبيق BayesSearchCV في مثال عملي أدناه.
دالة الهدف (Objective Function)
هذه دالة سيتم استدعاؤها بواسطة إجراء البحث. تستقبل قيم المعاملات الفائقة كمدخلات من مساحة البحث وتُرجع قيمة الخسارة (الأقل أفضل). هذا يعني أنه خلال عملية التحسين، نقوم بتدريب النموذج باستخدام قيم المعاملات الفائقة المختارة والتنبؤ بالميزة المستهدفة. ثم نقوم بتقييم خطأ التنبؤ وإعادته إلى المُحسّن. سيقرر المُحسّن أي القيم يجب فحصها وتكرارها مرة أخرى. ستتعلم كيفية إنشاء دالة هدف في المثال العملي أدناه.
المُحسّن (Optimizer)
هذه هي الدالة التي تقوم بعملية تحسين المعاملات الفائقة البايزية (Bayesian Hyperparameter Optimization). تتكرر دالة التحسين عند كل نموذج ومساحة البحث للتحسين ثم تقوم بتصغير دالة الهدف. توفر مكتبة scikit-optimize دوال تحسين مختلفة، مثل:
dummy_minimize– بحث عشوائي عن طريق أخذ عينات موحدة (uniform sampling) ضمن الحدود المعطاة.forest_minimize– تحسين متسلسل باستخدام أشجار القرار (decision trees).gbrt_minimize– تحسين متسلسل باستخدام أشجار معززة بالانحدار (gradient boosted trees).gp_minimize– تحسين بايزي باستخدام العمليات الغاوسية (Gaussian Processes).
ملاحظة: سنقوم بتطبيق gp_minimize في المثال العملي أدناه.
ميزات أخرى يجب أن تتعلمها هي كالتالي:
- محولات المساحة (
Space Transformers) - دوَال المساعدة (
Utils Functions) - دوَال الرسم البياني (
Plotting Functions) - ملحقات التعلم الآلي للتحسين القائم على النموذج (
Machine learning extensions for model-based optimization)
Scikit-optimize عمليًا
الآن بعد أن عرفت الميزات المهمة لـ scikit-optimize، دعنا نلقي نظرة على مثال عملي. سنستخدم نفس مجموعة البيانات المسماة Mobile Price Dataset التي استخدمناها مع Hyperopt.
تثبيت Scikit-Optimize
تتطلب scikit-optimize إصدار بايثون والحزم التالية:
- Python >= 3.6
- NumPy (>= 1.13.3)
- SciPy (>= 0.19.1)
- joblib (>= 0.11)
- scikit-learn >= 0.20
- matplotlib >= 2.0.0
يمكنك تثبيت أحدث إصدار باستخدام هذا الأمر:
pip install scikit-optimizeثم استورد الحزم المهمة، بما في ذلك scikit-optimize:
# import packages
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
from skopt.searchcv import BayesSearchCV
from skopt.space import Integer, Real, Categorical
from skopt.utils import use_named_args
from skopt import gp_minimize
import warnings
warnings.filterwarnings( "ignore" )النهج الأول (The First Approach)
في النهج الأول، سنستخدم BayesSearchCV لإجراء تحسين المعاملات الفائقة لخوارزمية الغابات العشوائية (Random Forest).
تحديد مساحة البحث (Define Search Space)
سنقوم بضبط المعاملات الفائقة التالية لنموذج الغابات العشوائية:
n_estimators– عدد الأشجار في الغابة.max_depth– أقصى عمق للشجرة.criterion– الدالة المستخدمة لقياس جودة التقسيم.
# define search space
params = {
"n_estimators" : [ 100 , 200 , 300 , 400 ],
"max_depth" : ( 1 , 9 ),
"criterion" : [ "gini" , "entropy" ],
}لقد قمنا بتعريف مساحة البحث كقاموس (dictionary). يحتوي على أسماء المعاملات الفائقة المستخدمة كمفتاح، ونطاق المتغير كقيمة.
تحديد إعدادات BayesSearchCV
فائدة BayesSearchCV هي أن إجراء البحث يتم تلقائيًا، مما يتطلب الحد الأدنى من الإعدادات. يمكن استخدام الفئة بنفس طريقة Scikit-Learn (GridSearchCV و RandomizedSearchCV).
# define the search
search = BayesSearchCV(
estimator=rf_classifier,
search_spaces=params,
n_jobs= 1 ,
cv= 5 ,
n_iter= 30 ,
scoring= "accuracy" ,
verbose= 4 ,
random_state= 42
)ضبط النموذج (Fine Tune the Model)
ثم نقوم بتنفيذ البحث عن طريق تمرير الميزات المعالجة مسبقًا والميزة المستهدفة (price_range).
# perform the search
search.fit(X_scaled,y)يمكنك العثور على أفضل نتيجة باستخدام خاصية best_score_ وأفضل المعاملات باستخدام خاصية best_params_ من كائن البحث (search).
# report the best result
print(search.best_score_)
print(search.best_params_)لاحظ أن الإصدار الحالي من scikit-optimize (0.7.4) غير متوافق مع أحدث إصدارات scikit-learn (0.23.1 و 0.23.2). لذلك عند تشغيل عملية التحسين باستخدام هذا النهج، قد تحصل على أخطاء مثل هذا:
TypeError: object.__init__() takes exactly one argument (the instance to initialize)يمكنك العثور على مزيد من المعلومات حول هذا الخطأ في حسابهم على GitHub:
- https://github.com/scikit-optimize/scikit-optimize/issues/928
- https://github.com/scikit-optimize/scikit-optimize/issues/924
- https://github.com/scikit-optimize/scikit-optimize/issues/902
آمل أن يحلوا مشكلة عدم التوافق هذه قريبًا جدًا.
النهج الثاني (The Second Approach)
في النهج الثاني، نقوم أولاً بتحديد مساحة البحث باستخدام طرق المساحة (space methods) التي توفرها scikit-optimize، وهي Categorical و Integer.
# define the space of hyperparameters to search
search_space = list()
search_space.append(Categorical([ 100 , 200 , 300 , 400 ], name= 'n_estimators' ))
search_space.append(Categorical([ 'gini' , 'entropy' ], name= 'criterion' ))
search_space.append(Integer( 1 , 9 , name= 'max_depth' ))لقد قمنا بتعيين قيم مختلفة في المعاملات الفائقة المختارة أعلاه. ثم سنقوم بتعريف دالة الهدف.
تعريف دالة للتصغير (دالة الهدف)
دالتنا المراد تصغيرها تسمى evaluate_model وخوارزمية التصنيف التي سيتم تحسين معاملاتها الفائقة هي Random Forest. أستخدم التحقق المتقاطع لتجنب الإفراط في الملاءمة، ثم ستُرجع الدالة قيم الخسارة.
# define the function used to evaluate a given configuration
@use_named_args(search_space)
def evaluate_model ( **params ):
# configure the model with specific hyperparameters
clf = RandomForestClassifier(**params, n_jobs= -1 )
acc = cross_val_score(clf, X_scaled, y, scoring= "accuracy" ).mean()
return -accيسمح لك المزين (decorator) use_named_args() لدالة الهدف الخاصة بك باستقبال المعلمات كوسيطات كلمات مفتاحية (keyword arguments). هذا مناسب بشكل خاص عندما تريد تعيين معلمات مقدر scikit-learn. تذكر أن scikit-optimize تقوم بتصغير الدالة، ولهذا السبب أضفت علامة سالب إلى acc.
ضبط النموذج (Fine Tune the Model)
أخيرًا، نقوم بضبط النموذج باستخدام طريقة gp_minimize (التي تستخدم التحسين القائم على العملية الغاوسية) من scikit-optimize. ثم نطبع أفضل خسارة مع قيم معاملاتها الفائقة.
# perform optimization
result = gp_minimize(
func=evaluate_model,
dimensions=search_space,
n_calls= 30 ,
random_state= 42 ,
verbose= True ,
n_jobs= 1 ,
)Output:
Iteration No: 1 started. Evaluating function at random point.
Iteration No: 1 ended. Evaluation done at random point. Time taken: 8.6910 Function value obtained: -0.8585 Current minimum: -0.8585
Iteration No: 2 started. Evaluating function at random point.
Iteration No: 2 ended. Evaluation done at random point. Time taken: 4.5096 Function value obtained: -0.7680 Current minimum: -0.8585
………………….لاحظ أنه سيستمر في العمل حتى يصل إلى التكرار الأخير. بالنسبة لعملية التحسين لدينا، إجمالي عدد التكرارات هو 30. ثم يمكننا طباعة أفضل دقة وقيم المعاملات الفائقة المختارة التي استخدمناها.
# summarizing finding:
print( 'Best Accuracy: %.3f' % (result.fun))
print( 'Best Parameters: %s' % (result.x))Best Accuracy: -0.882
Best Parameters: [300, 'entropy', 9]بعد إجراء تحسين المعاملات الفائقة، كانت الخسارة -0.882. هذا يعني أن أداء النموذج لديه دقة تبلغ 88.2% باستخدام n_estimators = 300، و max_depth = 9، و criterion = “entropy” في مصنف الغابات العشوائية (Random Forest classifier). نتيجتنا لا تختلف كثيرًا عن Hyperopt في الجزء الأول (دقة 89.15%).
طباعة قيم الدالة (Print Function Values)
يمكنك طباعة جميع قيم الدالة في كل تكرار باستخدام خاصية func_vals من كائن OptimizeResult (result).
print(result.func_vals)Output:
array([-0.8665, -0.7765, -0.7485, -0.86 , -0.872 , -0.545 , -0.81 , -0.7725, -0.8115, -0.8705, -0.8685, -0.879 , -0.816 , -0.8815, -0.8645, -0.8745, -0.867 , -0.8785, -0.878 , -0.878 , -0.8785, -0.874 , -0.875 , -0.8785, -0.868 , -0.8815, -0.877 , -0.879 , -0.8705, -0.8745])رسم بياني لآثار التقارب (Plot Convergence Traces)
يمكننا استخدام طريقة plot_convergence من scikit-optimize لرسم أثر تقارب واحد أو عدة آثار. نحتاج فقط إلى تمرير كائن OptimizeResult (result) في طريقة plot_convergence.
# plot convergence
from skopt.plots import plot_convergence
plot_convergence(result)
يوضح الرسم البياني قيم الدالة في تكرارات مختلفة أثناء عملية التحسين.
الآن بعد أن عرفت كيفية تطبيق scikit-optimize، دعنا نتعلم تقنية تحسين المعاملات الفائقة البديلة الثالثة والأخيرة التي تسمى Optuna.
Optuna
تُعد Optuna إطار عمل بايثون آخر مفتوح المصدر لتحسين المعاملات الفائقة، يستخدم الطريقة البايزية لأتمتة مساحة البحث للمعاملات الفائقة. تم تطوير الإطار بواسطة شركة يابانية للذكاء الاصطناعي تسمى Preferred Networks. Optuna أسهل في التنفيذ والاستخدام من Hyperopt. يمكنك أيضًا تحديد المدة التي يجب أن تستغرقها عملية التحسين.
تتميز Optuna بخمس ميزات مهمة على الأقل يجب أن تعرفها لتشغيل أول عملية تحسين لك.
مساحات البحث (Search Spaces)
توفر Optuna خيارات مختلفة لجميع أنواع المعاملات الفائقة. الخيارات الأكثر شيوعًا للاختيار هي كالتالي:
- المعاملات الفئوية (
Categorical parameters) – تستخدم طريقةtrials.suggest_categorical(). تحتاج إلى توفير اسم المعامل وخياراته. - المعاملات الصحيحة (
Integer parameters) – تستخدم طريقةtrials.suggest_int(). تحتاج إلى توفير اسم المعامل، والقيمة الدنيا (low)، والقيمة القصوى (high). - المعاملات العشرية (
Float parameters) – تستخدم طريقةtrials.suggest_float(). تحتاج إلى توفير اسم المعامل، والقيمة الدنيا (low)، والقيمة القصوى (high). - المعاملات المستمرة (
Continuous parameters) – تستخدم طريقةtrials.suggest_uniform(). تحتاج إلى توفير اسم المعامل، والقيمة الدنيا (low)، والقيمة القصوى (high). - المعاملات المتقطعة (
Discrete parameters) – تستخدم طريقةtrials.suggest_discrete_uniform(). تحتاج إلى توفير اسم المعامل، والقيمة الدنيا (low)، والقيمة القصوى (high)، وخطوة التقطيع (step of discretization).
طرق التحسين (Samplers)
لدى Optuna طرق مختلفة لإجراء عملية تحسين المعاملات الفائقة. الطرق الأكثر شيوعًا هي:
GridSampler– يستخدم بحثًا شبكيًا (grid search). تقترح التجارب جميع توليفات المعاملات في مساحة البحث المعطاة أثناء الدراسة.RandomSampler– يستخدم أخذ عينات عشوائية. هذا المُجمّع (sampler) يعتمد على أخذ العينات المستقلة.TPESampler– يستخدم خوارزميةTPE(Tree-structured Parzen Estimator).CmaEsSampler– يستخدم خوارزميةCMA-ES.
دالة الهدف (Objective Function)
تعمل دالة الهدف بنفس طريقة تقنيات hyperopt و scikit-optimize. الفرق الوحيد هو أن Optuna تسمح لك بتعريف مساحة البحث والهدف في دالة واحدة. مثال:
def objective ( trial ):
# Define the search space
criterions = trial.suggest_categorical( 'criterion' , [ 'gini' , 'entropy' ])
max_depths = trial.suggest_int( 'max_depth' , 1 , 9 , 1 )
n_estimators = trial.suggest_int( 'n_estimators' , 100 , 1000 , 100 )
clf = sklearn.ensemble.RandomForestClassifier(n_estimators=n_estimators, criterion=criterions, max_depth=max_depths, n_jobs= -1 )
score = cross_val_score(clf, X_scaled, y, scoring= "accuracy" ).mean()
return scoreالدراسة (Study)
تتوافق الدراسة (Study) مع مهمة تحسين (مجموعة من التجارب). إذا كنت بحاجة لبدء عملية التحسين، فأنت بحاجة إلى إنشاء كائن دراسة (study object) وتمرير دالة الهدف إلى طريقة تسمى optimize() وتعيين عدد التجارب على النحو التالي:
study = optuna.create_study()
study.optimize(objective, n_trials= 100 )تسمح لك طريقة create_study() باختيار ما إذا كنت تريد تعظيم (maximize) أو تصغير (minimize) دالة الهدف الخاصة بك. هذه إحدى الميزات الأكثر فائدة التي تعجبني في Optuna لأن لديك القدرة على اختيار اتجاه عملية التحسين. لاحظ أنك ستتعلم كيفية تطبيق هذا في المثال العملي أدناه.
التصور (Visualization)
توفر وحدة التصور (visualization module) في Optuna طرقًا مختلفة لإنشاء رسوم بيانية لنتائج التحسين. تساعدك هذه الطرق على الحصول على معلومات حول التفاعلات بين المعاملات وتتيح لك معرفة كيفية المضي قدمًا. فيما يلي بعض الطرق التي يمكنك استخدامها:
plot_contour()– ترسم هذه الطريقة العلاقة بين المعاملات كمخطط كفافي (contour plot) في دراسة.plot_intermediate_values()– ترسم هذه الطريقة القيم الوسيطة لجميع التجارب في دراسة.plot_optimization_history()– ترسم هذه الطريقة سجل التحسين لجميع التجارب في دراسة.plot_param_importances()– ترسم هذه الطريقة أهمية المعاملات الفائقة وقيمها.plot_edf()– ترسم هذه الطريقة دالة التوزيع التجريبية (empirical distribution function - EDF) لقيمة الهدف في دراسة.
سنستخدم بعض الطرق المذكورة أعلاه في المثال العملي أدناه.
Optuna عمليًا
الآن بعد أن عرفت الميزات المهمة لـ Optuna، في هذا المثال العملي سنستخدم نفس مجموعة البيانات (Mobile Price Dataset) التي استخدمناها في الطريقتين السابقتين.
تثبيت Optuna
يمكنك تثبيت أحدث إصدار باستخدام:
pip install optunaثم استورد الحزم المهمة، بما في ذلك optuna:
# import packages
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
import joblib
import optuna
from optuna.samplers import TPESampler
import warnings
warnings.filterwarnings( "ignore" )تحديد مساحة البحث والهدف في دالة واحدة
كما أوضحت أعلاه، تسمح لك Optuna بتعريف مساحة البحث والهدف في دالة واحدة. سنقوم بتحديد مساحات البحث للمعاملات الفائقة التالية لنموذج الغابات العشوائية (Random Forest):
n_estimators– عدد الأشجار في الغابة.max_depth– أقصى عمق للشجرة.criterion– الدالة المستخدمة لقياس جودة التقسيم.
# define the search space and the objecive function
def objective ( trial ):
# Define the search space
criterions = trial.suggest_categorical( 'criterion' , [ 'gini' , 'entropy' ])
max_depths = trial.suggest_int( 'max_depth' , 1 , 9 , 1 )
n_estimators = trial.suggest_int( 'n_estimators' , 100 , 1000 , 100 )
clf = RandomForestClassifier(n_estimators=n_estimators, criterion=criterions, max_depth=max_depths, n_jobs= -1 )
score = cross_val_score(clf, X_scaled, y, scoring= "accuracy" ).mean()
return scoreسنستخدم طريقة trial.suggest_categorical() لتحديد مساحة بحث لـ criterion و trial.suggest_int() لكل من max_depth و n_estimators. كما سنستخدم التحقق المتقاطع لتجنب الإفراط في الملاءمة، ثم ستُرجع الدالة متوسط الدقة.
إنشاء كائن دراسة (Create a Study Object)
بعد ذلك، نقوم بإنشاء كائن دراسة (study object) يتوافق مع مهمة التحسين. تسمح لنا طريقة create_study() بتوفير اسم الدراسة، واتجاه التحسين (تعظيم maximize أو تصغير minimize)، وطريقة التحسين التي نريد استخدامها.
# create a study object
study = optuna.create_study(study_name= "randomForest_optimization" , direction= "maximize" , sampler=TPESampler())في حالتنا، أطلقنا على كائن الدراسة الخاص بنا اسم randomForest_optimization. اتجاه التحسين هو تعظيم (مما يعني أن النتيجة الأعلى أفضل) وطريقة التحسين المستخدمة هي TPESampler().
ضبط النموذج (Fine Tune the Model)
لتشغيل عملية التحسين، نحتاج إلى تمرير دالة الهدف وعدد التجارب إلى طريقة optimize() من كائن الدراسة الذي أنشأناه. لقد قمنا بتعيين عدد التجارب ليكون 10 (ولكن يمكنك تغيير العدد إذا كنت تريد تشغيل المزيد من التجارب).
# pass the objective function to method optimize()
study.optimize(objective, n_trials= 10 )
مخرجات عملية التحسين
ثم يمكننا طباعة أفضل دقة وقيم المعاملات الفائقة المختارة المستخدمة. لعرض أفضل قيم المعاملات الفائقة المختارة:
print(study.best_params)Output:
{‘criterion’: ‘entropy’, ‘max_depth’: 8, ‘n_estimators’: 700}لعرض أفضل نتيجة أو دقة:
print(study.best_value)Output:
0.8714999999999999.أفضل نتيجة لدينا حوالي 87.15%.
رسم بياني لسجل التحسين (Plot Optimization History)
يمكننا استخدام طريقة plot_optimization_history() من Optuna لرسم سجل التحسين لجميع التجارب في دراسة. نحتاج فقط إلى تمرير كائن الدراسة المحسن في الطريقة.
optuna.visualization.plot_optimization_history(study)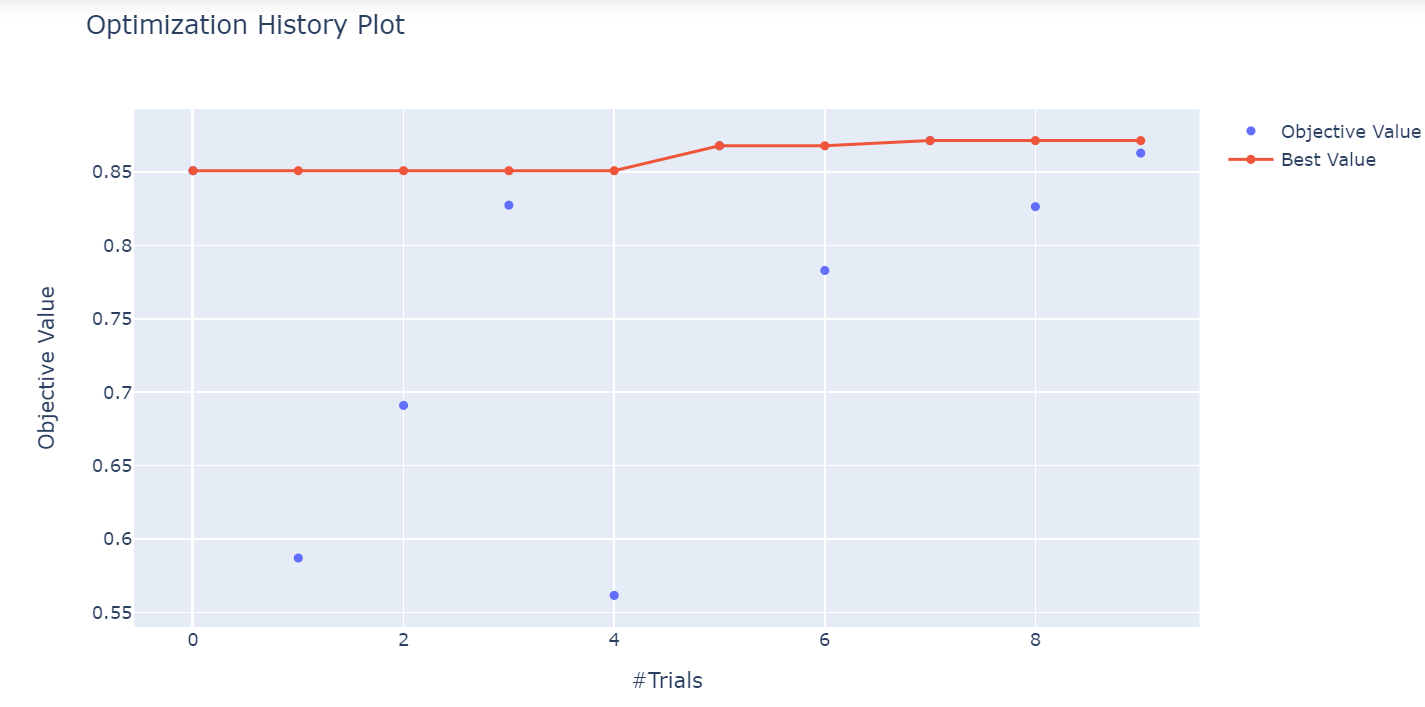
يوضح الرسم البياني أفضل القيم في تجارب مختلفة أثناء عملية التحسين.
رسم بياني لأهمية المعاملات الفائقة (Plot Hyperparameter Importances)
توفر Optuna طريقة تسمى plot_param_importances() لرسم أهمية المعاملات الفائقة. نحتاج فقط إلى تمرير كائن الدراسة المحسن في الطريقة.
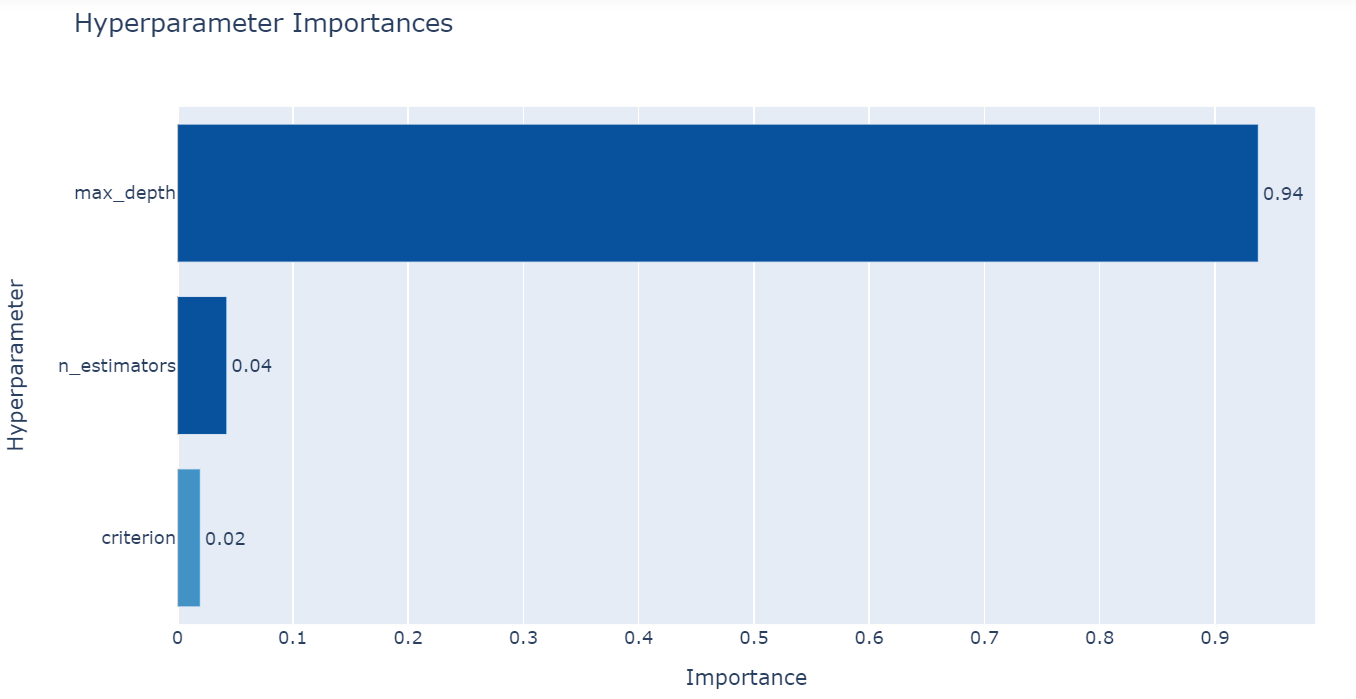
من الشكل أعلاه، يمكنك أن ترى أن max_depth هو المعامل الفائق الأكثر أهمية.
حفظ وتحميل عمليات البحث عن المعاملات الفائقة (Save and Load Hyperparameter Searches)
يمكنك حفظ وتحميل عمليات البحث عن المعاملات الفائقة باستخدام حزمة joblib. أولاً، سنقوم بحفظ عمليات البحث عن المعاملات الفائقة في دليل optuna_searches.
# save your hyperparameter searches
joblib.dump(study, 'optuna_searches/study.pkl' )ثم إذا كنت ترغب في تحميل عمليات البحث عن المعاملات الفائقة من دليل optuna_searches، يمكنك استخدام طريقة load() من joblib.
# load your hyperparameter searches
study = joblib.load( 'optuna_searches/study.pkl' )الخلاصة التقنية
تهانينا، لقد وصلت إلى نهاية المقال! دعنا نلقي نظرة على النتائج الإجمالية وقيم المعاملات الفائقة التي تم اختيارها بواسطة تقنيات تحسين المعاملات الفائقة الثلاث التي ناقشناها في هذا المقال.
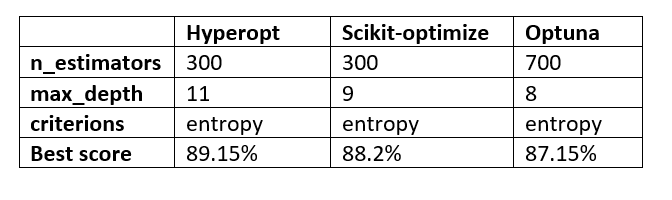
النتائج التي قدمتها كل تقنية لا تختلف كثيرًا عن بعضها البعض. عدد التكرارات أو التجارب المختارة هو ما يصنع الفارق. بالنسبة لي، Optuna سهلة التنفيذ وهي خياري الأول في تقنيات تحسين المعاملات الفائقة.
رأي تقني موجز: تُظهر المقارنة بين Hyperopt و Scikit-optimize و Optuna أن جميعها توفر حلولًا فعالة لتحسين أداء نماذج التعلم الآلي. بينما قد تختلف الدقة النهائية بشكل طفيف بناءً على عدد التكرارات وتكوين مساحة البحث، فإن الهدف الأساسي هو إيجاد التوليفة المثلى للمعاملات الفائقة بأقل جهد حسابي ممكن. Optuna تبرز بمرونتها وسهولة استخدامها، خاصة مع ميزة تحديد اتجاه التحسين المباشر (تعظيم/تصغير) ووحدات التصور المدمجة التي تساعد على فهم سلوك النموذج. إن اختيار التقنية يعتمد بشكل كبير على تفضيلات المطور ومتطلبات المشروع، ولكن فهم المبادئ الأساسية للتحسين البايزي وكيفية تطبيقها يظل هو المفتاح لرفع كفاءة أي نموذج تعلم آلي.
يرجى إعلامي بما تفكر فيه!
يمكنك تحميل مجموعة البيانات وجميع الدفاتر (notebooks) المستخدمة في هذا المقال هنا: https://github.com/Davisy/Hyperparameter-Optimization-Techniques
إذا تعلمت شيئًا جديدًا أو استمتعت بقراءة هذا المقال، يرجى مشاركته حتى يتمكن الآخرون من رؤيته. حتى ذلك الحين، أراك في مقالي التالي! يمكن الوصول إليّ أيضًا على Twitter عبر @Davis_McDavid.