كيفية تحسين أداء نماذج التعلّم الآلي عبر دمج السمات الفئوية
مقدمة: لماذا تؤثر السمات الفئوية في أداء النموذج؟
عند بناء نموذج في مجال Machine Learning، غالباً ما تتضمن البيانات سمات فئوية تصف حالات أو مجموعات محددة بدلاً من قيم رقمية مباشرة. هذا النوع من البيانات مهم جداً، لكنه يحتاج إلى معالجة مناسبة قبل إدخاله إلى الخوارزميات، لأن معظم نماذج التعلّم الآلي تعمل بكفاءة أكبر عندما تكون المدخلات رقمية.
السمات الفئوية يمكن تقسيمها عادة إلى ثلاثة أنواع رئيسية:
- فئوية ترتيبية: تمتلك ترتيباً منطقياً بين القيم، مثل مستوى التقييم من 1 إلى 10.
- فئوية ثنائية: تحتوي على قيمتين فقط، مثل نعم/لا أو حار/بارد.
- فئوية اسمية: تتكون من قيم غير مرتبة، مثل أسماء الدول أو أنواع الوظائف.
ولأن الخوارزميات لا تتعامل مباشرة مع النصوص أو الفئات، نلجأ عادة إلى تقنيات مثل LabelEncoder للسمات الثنائية، وOne-Hot Encoding للسمات الاسمية. لكن هناك أسلوباً إضافياً قد يرفع جودة التنبؤ في بعض الحالات، وهو دمج السمات الفئوية لإنشاء سمة جديدة أكثر تعبيراً عن العلاقة بين المتغيرات.

ما المقصود بدمج السمات الفئوية؟
المقصود هو إنشاء سمة جديدة من خلال جمع قيم سمتين أو أكثر في عمود واحد. هذا الأسلوب يسمح للنموذج بالتقاط تفاعلات قد لا تكون واضحة عند التعامل مع كل سمة بشكل منفصل.
على سبيل المثال، يمكن دمج السمتين feature_1 وfeature_2 في سمة واحدة كالتالي:
df["new_feature"] = df.feature_1.astype(str) + "_" + df.feature_2.astype(str)بهذه الطريقة، تتحول الأزواج المختلفة من القيم إلى فئات جديدة مستقلة. وقد يكون ذلك مفيداً عندما تكون العلاقة المشتركة بين السمتين أكثر تأثيراً من كل واحدة على حدة.
متى يكون دمج السمات مفيداً؟
لا توجد قاعدة ثابتة تقول إن دمج السمات سيحسن الأداء دائماً. نجاح هذه الفكرة يعتمد على:
- طبيعة البيانات نفسها.
- مدى الارتباط بين السمات الفئوية.
- فهمك للمجال أو المشكلة.
- نوع النموذج المستخدم في التدريب.
لذلك، يعد دمج السمات خطوة تجريبية ذكية، لكنها تحتاج إلى تقييم عملي ومقارنة النتائج قبل اعتمادها.
تطبيق عملي على مجموعة بيانات الشمول المالي في أفريقيا
لتوضيح الفكرة عملياً، سنعتمد على مجموعة بيانات Financial Inclusion in Africa، وهي بيانات تهدف إلى التنبؤ بالأشخاص الأكثر احتمالاً لامتلاك حساب بنكي. وبما أن الهدف هو التنبؤ بفئة Yes أو No، فالمسألة هنا هي تصنيف.
الخطوة الأولى: تحميل البيانات والمكتبات
نبدأ أولاً باستيراد الحزم الأساسية:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
np.random.seed(123)
warnings.filterwarnings('ignore')
%matplotlib inlineثم نحمّل ملف التدريب:
data = pd.read_csv('data/Train_v2.csv')ولمعرفة أبعاد البيانات:
print('data shape:', data.shape)الناتج يوضح أن مجموعة البيانات تحتوي على 23524 صفاً و13 عموداً. وهذا يعني وجود 12 متغيراً مستقلاً ومتغير هدف واحد.
يمكن إلقاء نظرة أولية على أول خمسة صفوف عبر الدالة head():
data.head()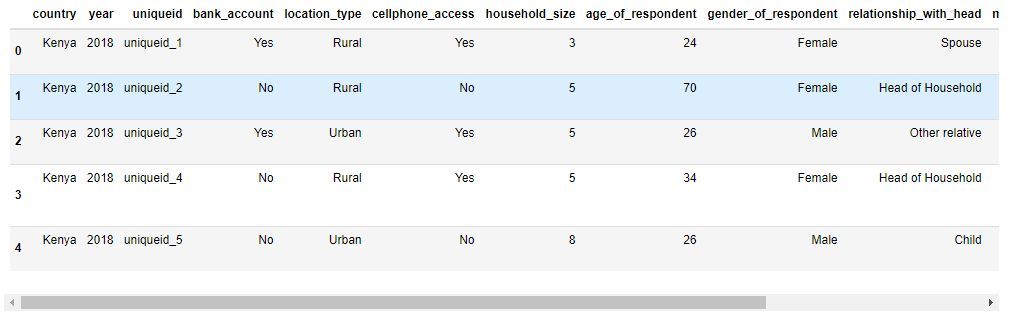
فهم معنى كل متغير خطوة ضرورية قبل بدء أي معالجة. لذلك من المفيد الرجوع إلى ملف VariableDefinition.csv لمعرفة دلالة كل عمود داخل البيانات.
الخطوة الثانية: فهم بنية مجموعة البيانات
يمكن الحصول على معلومات تفصيلية عن الأعمدة وأنواع البيانات عبر الدالة info():
print(data.info())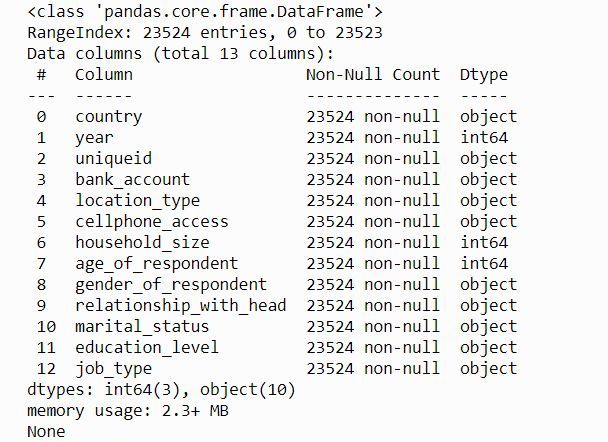
تُظهر هذه المعاينة عدة نقاط مهمة:
- لا توجد قيم مفقودة في البيانات.
- هناك ثلاث سمات رقمية من النوع
integer. - معظم السمات الأخرى من النوع
object، أي أنها فئوية في الغالب.
الخطوة الثالثة: تجهيز البيانات للنموذج
قبل التدريب، يجب فصل متغير الهدف bank_account عن بقية السمات، ثم تحويل قيمه النصية إلى أرقام باستخدام LabelEncoder.
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
le = LabelEncoder()
data['bank_account'] = le.fit_transform(data['bank_account'])
X = data.drop(['bank_account'], axis=1)
y = data['bank_account']
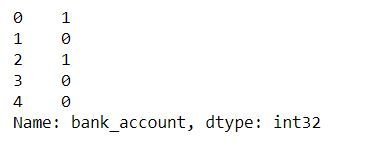
print(y)بعد التحويل، تصبح القيمة 1 ممثلة لـ Yes، والقيمة 0 ممثلة لـ No.
بعد ذلك، يمكن إنشاء دالة مخصصة للمعالجة المسبقة تشمل:
- تحويل بعض الأعمدة الرقمية إلى نوع
float. - تحويل السمات الفئوية إلى تمثيل رقمي باستخدام
One-Hot EncodingأوLabelEncoder. - حذف العمود الفريد
uniqueid. - تطبيق مقياس موحد على البيانات.
from sklearn.preprocessing import StandardScaler
# function to preprocess our data
def preprocessing_data(data):
# Convert the following numerical labels from interger to float
float_array = data[["household_size", "age_of_respondent", "year"]].values.astype(float)
# categorical features to be converted to One Hot Encoding
categ = [
"relationship_with_head",
"marital_status",
"education_level",
"job_type",
"country",
]
# One Hot Encoding conversion
data = pd.get_dummies(data, prefix_sep="_", columns=categ)
# Label Encoder conversion
data["location_type"] = le.fit_transform(data["location_type"])
data["cellphone_access"] = le.fit_transform(data["cellphone_access"])
data["gender_of_respondent"] = le.fit_transform(data["gender_of_respondent"])
# drop uniquid column
data = data.drop(["uniqueid"], axis=1)
# scale our data
scaler = StandardScaler()
data = scaler.fit_transform(data)
return dataثم نعالج بيانات التدريب:
processed_train_data = preprocessing_data(X)الخطوة الرابعة: بناء النموذج وإجراء التجارب
الآن نحتاج إلى تقسيم البيانات إلى مجموعة تدريب ومجموعة تحقق لتقييم الأداء:
from sklearn.model_selection import train_test_split
X_Train, X_val, y_Train, y_val = train_test_split(
processed_train_data,
y,
stratify=y,
test_size=0.1,
random_state=42
)استخدام المعامل stratify=y مهم للحفاظ على توازن الفئات بين بيانات التدريب والتحقق.
سنستخدم خوارزمية LogisticRegression لأنها مناسبة لمسائل التصنيف الثنائي:
from sklearn.linear_model import LogisticRegression
lg_model = LogisticRegression()
lg_model.fit(X_Train, y_Train)وبعد التدريب، نقيس الدقة باستخدام accuracy_score:
from sklearn.metrics import confusion_matrix, accuracy_score
y_pred = lg_model.predict(X_val)
print("Accuracy Score of Logistic Regression classifier:", "{:.4f}".format(accuracy_score(y_val, y_pred)))النتيجة الأساسية كانت تقريباً 0.8874. هذه ستكون نقطة المقارنة قبل دمج السمات.
التجربة الأولى: دمج education_level مع job_type
في هذه التجربة، سننشئ سمة جديدة تجمع بين مستوى التعليم ونوع الوظيفة، لأن التفاعل بينهما قد يعبّر عن السلوك المالي بصورة أدق.
def preprocessing_data(data):
# Convert the following numerical labels from integer to float
float_array = data[["household_size", "age_of_respondent", "year"]].values.astype(float)
# combine some cat features
data["features_combination"] = (
data.education_level.astype(str) + "_" + data.job_type.astype(str)
)
# remove individual features that are combined together
data = data.drop(['education_level', 'job_type'], axis=1)
# categorical features to be converted by One Hot Encoding
categ = [
"relationship_with_head",
"marital_status",
"features_combination",
"country"
]
# One Hot Encoding conversion
data = pd.get_dummies(data, prefix_sep="_", columns=categ)
# Label Encoder conversion
data["location_type"] = le.fit_transform(data["location_type"])
data["cellphone_access"] = le.fit_transform(data["cellphone_access"])
data["gender_of_respondent"] = le.fit_transform(data["gender_of_respondent"])
# drop uniquid column
data = data.drop(["uniqueid"], axis=1)
# scale our data
scaler = StandardScaler()
data = scaler.fit_transform(data)
return dataما الذي تغيّر هنا؟
- إنشاء سمة جديدة باسم
features_combination. - حذف العمودين الأصليين
education_levelوjob_type. - إضافة السمة الجديدة إلى قائمة الأعمدة التي ستخضع إلى
One-Hot Encoding.
بعد إعادة تدريب نموذج LogisticRegression، ارتفعت الدقة من 0.8874 إلى 0.8882. ورغم أن التحسن بسيط، إلا أنه يؤكد أن دمج السمات الفئوية قد يمنح النموذج معلومات إضافية ذات قيمة.
التجربة الثانية: دمج relationship_with_head مع marital_status
في التجربة التالية، سنختبر زوجاً مختلفاً من السمات الفئوية لمعرفة ما إذا كان الدمج سيقدم نتيجة أفضل.
def preprocessing_data(data):
# Convert the following numerical labels from integer to float
float_array = data[["household_size", "age_of_respondent", "year"]].values.astype(float)
# combine some cat features
data["features_combination"] = (
data.relationship_with_head.astype(str) + "_" + data.marital_status.astype(str)
)
# remove individual features that are combined together
data = data.drop(['relationship_with_head', 'marital_status'], axis=1)
# categorical features to be converted by One Hot Encoding
categ = [
"features_combination",
"education_level",
"job_type",
"country",
]
# One Hot Encoding conversion
data = pd.get_dummies(data, prefix_sep="_", columns=categ)
# Label Encoder conversion
data["location_type"] = le.fit_transform(data["location_type"])
data["cellphone_access"] = le.fit_transform(data["cellphone_access"])
data["gender_of_respondent"] = le.fit_transform(data["gender_of_respondent"])
# drop uniquid column
data = data.drop(["uniqueid"], axis=1)
# scale our data
scaler = StandardScaler()
data = scaler.fit_transform(data)
return dataفي هذه الحالة، انخفضت الدقة من 0.8874 إلى 0.8865. وهذا يوضح حقيقة مهمة في بناء النماذج: ليس كل دمج للسمات يؤدي إلى تحسن.
أحياناً يؤدي الدمج إلى:
- إضافة ضوضاء غير مفيدة.
- زيادة عدد الفئات بشكل يربك النموذج.
- تمثيل علاقات لا تحمل قيمة تنبؤية حقيقية.
كيف تختار السمات المناسبة للدمج؟
اختيار السمات لا يجب أن يكون عشوائياً. الأفضل أن تعتمد على مزيج من التحليل العملي وفهم المجال. إليك بعض الإرشادات المفيدة:
- ابدأ بالسمات التي تتوقع وجود علاقة منطقية بينها.
- جرّب دمج السمات ذات التأثير السلوكي أو الاجتماعي المتقارب.
- راقب أثر الدمج على الدقة، وليس على الشعور الحدسي فقط.
- تجنب الإفراط في الدمج حتى لا يتضخم عدد الفئات الناتجة.
- استخدم التحقق المتقاطع
Cross Validationإن أمكن للحصول على تقييم أكثر موثوقية.
ملاحظات تقنية مهمة قبل اعتماد هذا الأسلوب
- التحسن في الأداء قد يكون طفيفاً، لكنه قد يصبح مهماً في المنافسات أو الأنظمة الحساسة.
- بعض النماذج تستفيد من تفاعلات السمات أكثر من غيرها.
- دمج السمات يرفع أحياناً عدد الأعمدة الناتجة بعد
One-Hot Encoding، ما قد يزيد استهلاك الذاكرة. - الفهم الجيد للبيانات أكثر قيمة من تطبيق تقنيات كثيرة بلا اختبار.
الخلاصة التقنية
دمج السمات الفئوية أسلوب عملي في هندسة السمات Feature Engineering، وقد يساعد على تحسين أداء نماذج التعلّم الآلي عندما يعكس علاقة حقيقية بين المتغيرات. لكن هذا الأسلوب ليس وصفة جاهزة؛ فقد يرفع الدقة في تجربة، ويخفضها في أخرى. الرأي التقني الأهم هنا هو أن نجاح الدمج يعتمد على جودة الفرضية، وفهم المجال، والانضباط في الاختبار والمقارنة. إذا كنت تعمل على نموذج تصنيفي يحتوي على عدد كبير من السمات الفئوية، فإن تجربة دمج بعض السمات المختارة بعناية تستحق التنفيذ بلا شك.