دليل Kubernetes الشامل: تعلم Kubernetes للمبتدئين

يُعد Kubernetes، الذي يُعرف اختصارًا بـ K8s، منصة مفتوحة المصدر لتنسيق الحاويات (container orchestration) تُعنى بأتمتة عمليات نشر التطبيقات وإدارتها وتوسيع نطاقها وتوفير الشبكات اللازمة لها. طوّرته شركة Google باستخدام لغة البرمجة Go، وأصبح متاحًا كمشروع مفتوح المصدر منذ عام 2014. وفقًا لاستبيان مطوري Stack Overflow لعام 2020، يحتل Kubernetes المرتبة الثالثة كأكثر المنصات المحبوبة والمرغوبة.
بالرغم من قوته الهائلة، يُعرف Kubernetes بصعوبة البدء به. لن أقول إنه سهل، ولكن إذا كنت مجهزًا بالمتطلبات الأساسية وتتبعت هذا الدليل بانتباه وصبر، فستتمكن من تحقيق الآتي:
- فهم قوي للأساسيات.
- إنشاء وإدارة مجموعات
Kubernetes(clusters). - نشر (تقريبًا) أي تطبيق على مجموعة
Kubernetes.
المتطلبات الأساسية
- الإلمام بـ
JavaScript - الإلمام بـ
Linux Terminal - الإلمام بـ
Docker(قراءة مقترحة: دليلDockerالشامل)
كود المشروع
يمكن العثور على الكود الخاص بالمشاريع التجريبية في المستودع التالي:
https://github.com/fhsinchy/kubernetes-handbook-projectsيمكنك العثور على الكود الكامل في فرع completed.
جدول المحتويات
- مقدمة إلى تنسيق الحاويات و
Kubernetes - تثبيت
Kubernetes - تطبيق
Hello WorldفيKubernetes - هندسة
Kubernetesالمعمارية - مكونات مستوى التحكم (
Control Plane) - مكونات العقدة (
Node) - كائنات
Kubernetes - الـ
Pods - الـ
Services - الصورة الكاملة
- التخلص من موارد
Kubernetes - نهج النشر التصريحي (
Declarative Deployment Approach) - كتابة أول مجموعة من التكوينات
- لوحة تحكم
Kubernetes(Dashboard) - العمل مع التطبيقات متعددة الحاويات
- خطة النشر
- وحدات التحكم بالنسخ المتماثلة (
Replication Controllers) ومجموعات النسخ المتماثلة (Replica Sets) وعمليات النشر (Deployments) - إنشاء أول عملية نشر لك
- فحص موارد
Kubernetes - الحصول على سجلات الحاوية من الـ
Pods - متغيرات البيئة
- إنشاء نشر قاعدة البيانات
- وحدات التخزين المستمرة (
Persistent Volumes) ومطالبات وحدات التخزين المستمرة (Persistent Volume Claims) - التوفير الديناميكي لوحدات التخزين المستمرة
- ربط وحدات التخزين مع الـ
Pods - ربط كل شيء معًا
- العمل مع وحدات التحكم بالـ
Ingress - إعداد وحدة التحكم بـ
NGINX Ingress - الـ
SecretsوالـConfig MapsفيKubernetes - تنفيذ عمليات طرح التحديثات في
Kubernetes - دمج التكوينات
- استكشاف الأخطاء وإصلاحها
- الخلاصة
مقدمة إلى تنسيق الحاويات و Kubernetes
وفقًا لـ Red Hat، «تنسيق الحاويات هو عملية أتمتة مهام نشر الحاويات وإدارتها وتوسيع نطاقها وتوفير الشبكات اللازمة لها. يمكن استخدامه في أي بيئة تستخدم فيها الحاويات، ويمكن أن يساعدك في نشر نفس التطبيق عبر بيئات مختلفة دون الحاجة إلى أي إعادة تصميم.»
دعني أوضح لك بمثال. لنفترض أنك طوّرت تطبيقًا رائعًا يقترح على الأشخاص ما يجب عليهم تناوله بناءً على وقت اليوم. الآن، لنفترض أنك قمت بحوسبة التطبيق (containerized) باستخدام Docker ونشرته على AWS.

إذا تعطل التطبيق لأي سبب، سيفقد المستخدمون الوصول إلى خدمتك فورًا. لحل هذه المشكلة، يمكنك إنشاء نسخ متعددة أو مثيلات (replicas) من نفس التطبيق لجعله عالي التوافر (highly available).

حتى لو تعطل أحد المثيلات، سيظل الاثنان الآخران متاحين للمستخدمين. الآن، لنفترض أن تطبيقك أصبح شائعًا بشكل كبير بين محبي السهر، وأن خوادمك تُغمر بالطلبات ليلًا بينما أنت نائم. ماذا لو تعطلت جميع المثيلات بسبب الحمل الزائد؟ من سيقوم بتوسيع النطاق (scaling)؟ حتى لو قمت بتوسيع النطاق وجعلت 50 نسخة من تطبيقك، من سيتولى فحص حالتها الصحية؟ كيف ستقوم بإعداد الشبكة بحيث تصل الطلبات إلى نقطة النهاية الصحيحة؟ موازنة التحميل (Load balancing) ستكون مصدر قلق كبير أيضًا، أليس كذلك؟
يمكن لـ Kubernetes أن يجعل الأمور أسهل بكثير في مثل هذه الحالات. إنها منصة لتنسيق الحاويات تتكون من عدة مكونات وتعمل بلا كلل للحفاظ على خوادمك في الحالة التي ترغب فيها. لنفترض أنك تريد تشغيل 50 نسخة من تطبيقك باستمرار. حتى لو حدث ارتفاع مفاجئ في عدد المستخدمين، يجب أن يتم توسيع نطاق الخادم تلقائيًا. كل ما عليك فعله هو إخبار Kubernetes باحتياجاتك، وسيقوم هو بالباقي.

لن يقوم Kubernetes بتنفيذ الحالة المطلوبة فحسب، بل سيحافظ عليها أيضًا. سيقوم بإنشاء نسخ إضافية إذا تعطلت أي من النسخ القديمة، وإدارة الشبكات والتخزين، وطرح أو التراجع عن التحديثات، أو حتى توسيع نطاق الخادم إذا لزم الأمر.
تثبيت Kubernetes
تشغيل Kubernetes على جهازك المحلي يختلف كثيرًا عن تشغيله على السحابة. لتشغيل Kubernetes، تحتاج إلى برنامجين:
minikube: يقوم بتشغيل مجموعةKubernetesذات عقدة واحدة (single-node Kubernetes cluster) داخل جهاز افتراضي (VM) على جهاز الكمبيوتر المحلي الخاص بك.kubectl: أداة سطر الأوامر (command-line tool) لـKubernetes، والتي تتيح لك تشغيل الأوامر ضد مجموعاتKubernetes.
بصرف النظر عن هذين البرنامجين، ستحتاج أيضًا إلى برنامج تشغيل افتراضي (hypervisor) ومنصة لحوسبة الحاويات (containerization platform). يُعد Docker الخيار الواضح لمنصة حوسبة الحاويات. برامج التشغيل الافتراضية الموصى بها هي كما يلي:
Hyper-VلنظامWindowsHyperKitلنظامMacDockerلنظامLinux
يأتي Hyper-V مدمجًا في Windows 10 (إصدارات Pro و Enterprise و Education) كميزة اختيارية ويمكن تشغيله من لوحة التحكم. يأتي HyperKit مدمجًا مع Docker Desktop لنظام Mac كمكون أساسي. وعلى نظام Linux، يمكنك تجاوز طبقة الـ hypervisor بالكامل باستخدام Docker مباشرة. إنها أسرع بكثير من استخدام أي hypervisor وهي الطريقة الموصى بها لتشغيل Kubernetes على Linux.
يمكنك المضي قدمًا وتثبيت أي من برامج التشغيل الافتراضية المذكورة أعلاه. أو إذا كنت تريد إبقاء الأمور بسيطة، فما عليك سوى الحصول على VirtualBox. لبقية المقال، سأفترض أنك تستخدم VirtualBox. لا تقلق، حتى لو كنت تستخدم شيئًا آخر، فلن يكون هناك فرق كبير. سأستخدم minikube مع مشغل Docker على جهاز Ubuntu طوال المقال.
بمجرد تثبيت الـ hypervisor ومنصة حوسبة الحاويات، حان الوقت لتثبيت برنامجي minikube و kubectl. يأتي kubectl عادةً مجمعًا مع Docker Desktop على نظامي Mac و Windows. يمكن العثور على تعليمات التثبيت لنظام Linux هنا. أما minikube، فيجب تثبيته على جميع الأنظمة الثلاثة. يمكنك استخدام Homebrew على نظام Mac، و Chocolatey على نظام Windows لتثبيت minikube. يمكن العثور على تعليمات التثبيت لنظام Linux هنا.
بمجرد تثبيتهما، يمكنك اختبار كلا البرنامجين بتنفيذ الأوامر التالية:
minikube version
# minikube version: v1.12.1
# commit: 5664228288552de9f3a446ea4f51c6f29bbdd0e0
kubectl version
# Client Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.6", GitCommit:"dff82dc0de47299ab66c83c626e08b245ab19037", GitTreeState:"clean", BuildDate:"2020-07-16T00:04:31Z", GoVersion:"go1.14.4", Compiler:"gc", Platform:"darwin/amd64"}
# Server Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.3", GitCommit:"2e7996e3e2712684bc73f0dec0200d64eec7fe40", GitTreeState:"clean", BuildDate:"2020-05-20T12:43:34Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"linux/amd64"}إذا قمت بتنزيل الإصدارات الصحيحة لنظام التشغيل الخاص بك وقمت بإعداد المسارات بشكل صحيح، فيجب أن تكون جاهزًا للبدء. كما ذكرت سابقًا، يقوم minikube بتشغيل مجموعة Kubernetes ذات عقدة واحدة داخل جهاز افتراضي (VM) على جهاز الكمبيوتر المحلي الخاص بك. سأشرح المجموعات (clusters) والعقد (nodes) بتفاصيل أكبر في قسم قادم. في الوقت الحالي، افهم أن minikube ينشئ جهازًا افتراضيًا عاديًا باستخدام مشغل الـ hypervisor الذي تختاره ويعامله كمجموعة Kubernetes.
إذا واجهت أي مشاكل في هذا القسم، يرجى إلقاء نظرة على قسم استكشاف الأخطاء وإصلاحها في نهاية هذا المقال. قبل البدء في تشغيل minikube، يجب عليك تعيين مشغل الـ hypervisor الصحيح الذي سيستخدمه. لتعيين VirtualBox كمشغل افتراضي، نفذ الأمر التالي:
minikube config set driver virtualbox
# ❗ These changes will take effect upon a minikube delete and then a minikube startيمكنك استبدال virtualbox بـ hyperv أو hyperkit أو docker حسب تفضيلك. هذا الأمر ضروري في المرة الأولى فقط. لبدء تشغيل minikube، نفذ الأمر التالي:
minikube start
# ? minikube v1.12.1 on Ubuntu 20.04
# ✨ Using the virtualbox driver based on existing profile
# ? Starting control plane node minikube in cluster minikube
# ? Updating the running virtualbox "minikube" VM ...
# ? Preparing Kubernetes v1.18.3 on Docker 19.03.12 ...
# ? Verifying Kubernetes components...
# ? Enabled addons: default-storageclass, storage-provisioner
# ? Done! kubectl is now configured to use "minikube"يمكنك إيقاف minikube بتنفيذ الأمر minikube stop.
تطبيق Hello World في Kubernetes
الآن بعد أن أصبح لديك Kubernetes على نظامك المحلي، حان الوقت لتطبيق ما تعلمته. في هذا المثال، ستقوم بنشر تطبيق بسيط جدًا على مجموعتك المحلية وتتعرف على الأساسيات. سيكون هناك مصطلحات مثل pod و service و load balancer وما إلى ذلك في هذا القسم. لا تقلق إذا لم تفهمها على الفور. سأشرح كل منها بالتفصيل في قسم الصورة الكاملة.
إذا كنت قد بدأت تشغيل minikube في القسم السابق، فأنت جاهز للمتابعة. وإلا، سيتعين عليك تشغيله الآن. بمجرد بدء تشغيل minikube، نفذ الأمر التالي في محطتك الطرفية (terminal):
kubectl run hello-kube --image=fhsinchy/hello-kube --port=80
# pod/hello-kube createdسترى رسالة pod/hello-kube created على الفور تقريبًا. يقوم الأمر run بتشغيل صورة الحاوية (container image) المحددة داخل pod. الـ Pods تشبه صندوقًا يغلف حاوية. للتأكد من إنشاء الـ pod وتشغيله، نفذ الأمر التالي:
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# hello-kube 1/1 Running 0 3m3sيجب أن ترى Running في عمود STATUS. إذا رأيت شيئًا مثل ContainerCreating، انتظر دقيقة أو دقيقتين وتحقق مرة أخرى. الـ Pods بشكل افتراضي غير قابلة للوصول من خارج المجموعة. لجعلها قابلة للوصول، يجب عليك كشفها (expose) باستخدام خدمة (service). لذا، بمجرد أن يكون الـ pod قيد التشغيل، نفذ الأمر التالي لكشف الـ pod:
kubectl expose pod hello-kube --type=LoadBalancer --port=80
# service/hello-kube exposedللتأكد من إنشاء خدمة موازنة التحميل (load balancer service) بنجاح، نفذ الأمر التالي:
kubectl get service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# hello-kube LoadBalancer 10.109.60.75 <pending> 80:30848/TCP 119s
# kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7h47mتأكد من رؤية خدمة hello-kube في القائمة. الآن بعد أن أصبح لديك pod قيد التشغيل ومكشوف، يمكنك المضي قدمًا والوصول إليه. نفذ الأمر التالي للقيام بذلك:
minikube service hello-kube
# |-----------|------------|-------------|-----------------------------|
# | NAMESPACE | NAME | TARGET PORT | URL |
# |-----------|------------|-------------|-----------------------------|
# | default | hello-kube | 80 | http://192.168.99.101:30848 |
# |-----------|------------|-------------|-----------------------------|
# ? Opening service default/hello-kube in default browser...يجب أن يفتح متصفح الويب الافتراضي الخاص بك تلقائيًا ويجب أن ترى شيئًا كهذا:

هذا تطبيق JavaScript بسيط جدًا قمت بإنشائه باستخدام Vite وقليل من CSS. لفهم ما قمت به للتو، يجب أن تكتسب فهمًا جيدًا لهندسة Kubernetes المعمارية.
هندسة Kubernetes المعمارية
في عالم Kubernetes، يمكن أن تكون العقدة (node) إما جهازًا ماديًا أو افتراضيًا له دور محدد. تُسمى مجموعة من هذه الأجهزة أو الخوادم التي تستخدم شبكة مشتركة للتواصل بين بعضها البعض بـ «المجموعة» (cluster).

في إعدادك المحلي، minikube هو مجموعة Kubernetes ذات عقدة واحدة. لذا، بدلاً من وجود خوادم متعددة كما في الرسم البياني أعلاه، يحتوي minikube على خادم واحد فقط يعمل كخادم رئيسي (main server) وعقدة (node) في آن واحد.

يُمنح كل خادم في مجموعة Kubernetes دورًا. هناك دوران محتملان:
control-plane(مستوى التحكم): يتخذ معظم القرارات الضرورية ويعمل كدماغ للمجموعة بأكملها. يمكن أن يكون هذا خادمًا واحدًا أو مجموعة من الخوادم في المشاريع الكبيرة.node(العقدة): مسؤول عن تشغيل أعباء العمل (workloads). تتم إدارة هذه الخوادم عادةً بشكل دقيق بواسطة مستوى التحكم وتنفذ مهام مختلفة باتباع التعليمات المقدمة.
سيحتوي كل خادم في مجموعتك على مجموعة مختارة من المكونات. يمكن أن يختلف عدد ونوع هذه المكونات اعتمادًا على الدور الذي يلعبه الخادم في مجموعتك. هذا يعني أن العقد لا تحتوي على جميع المكونات التي يحتوي عليها مستوى التحكم. في الأقسام الفرعية القادمة، ستلقي نظرة أكثر تفصيلاً على المكونات الفردية التي تشكل مجموعة Kubernetes.
مكونات مستوى التحكم (Control Plane)
يتكون مستوى التحكم في مجموعة Kubernetes من خمسة مكونات. وهي كالتالي:
kube-api-server: يعمل كمدخل إلى مستوى التحكم فيKubernetes، وهو مسؤول عن التحقق من صحة ومعالجة الطلبات المقدمة باستخدام مكتبات العميل مثل برنامجkubectl.etcd: هذا متجر قيم-مفتاح موزع (distributed key-value store) يعمل كمصدر وحيد للحقيقة حول مجموعتك. يحتفظ ببيانات التكوين ومعلومات حول حالة المجموعة.etcdهو مشروع مفتوح المصدر تم تطويره بواسطة فريقRed Hat. كود المشروع متاح على مستودعGitHubالخاص بـetcd-io/etcd.kube-controller-manager: وحدات التحكم (controllers) فيKubernetesمسؤولة عن التحكم في حالة المجموعة. عندما تُعلمKubernetesبما تريده في مجموعتك، تتأكد وحدات التحكم من تلبية طلبك.kube-controller-managerهو جميع عمليات وحدات التحكم مجمعة في عملية واحدة.kube-scheduler: يُعرف تعيين المهام لعقدة معينة مع الأخذ في الاعتبار مواردها المتاحة ومتطلبات المهمة بـ «الجدولة» (scheduling). يقوم مكونkube-schedulerبمهمة الجدولة فيKubernetes، مما يضمن عدم تحميل أي من الخوادم في المجموعة فوق طاقتها.cloud-controller-manager: في بيئة سحابية حقيقية، يتيح لك هذا المكون ربط مجموعتك بواجهة برمجة تطبيقات (API) لمزود الخدمة السحابية الخاص بك (مثلGKE/EKS). بهذه الطريقة، تظل المكونات التي تتفاعل مع تلك المنصة السحابية معزولة عن المكونات التي تتفاعل فقط مع مجموعتك. في مجموعة محلية مثلminikube، لا يوجد هذا المكون.
مكونات العقدة (Node)
مقارنة بمستوى التحكم، تحتوي العقد على عدد قليل جدًا من المكونات. هذه المكونات هي كما يلي:
kubelet: تعمل هذه الخدمة كبوابة بين مستوى التحكم وكل عقدة في المجموعة. تمر جميع التعليمات من مستوى التحكم إلى العقد عبر هذه الخدمة. كما تتفاعل مع متجرetcdللحفاظ على معلومات الحالة محدثة.kube-proxy: تعمل هذه الخدمة الصغيرة على كل خادم عقدة وتحافظ على قواعد الشبكة عليها. أي طلب شبكة يصل إلى خدمة داخل مجموعتك يمر عبر هذه الخدمة.Container Runtime(بيئة تشغيل الحاويات):Kubernetesهي أداة لتنسيق الحاويات، وبالتالي فهي تشغل التطبيقات في حاويات. هذا يعني أن كل عقدة تحتاج إلى بيئة تشغيل حاويات مثلDockerأوrktأوcri-o.
كائنات Kubernetes
وفقًا لوثائق Kubernetes الرسمية، «الكائنات هي كيانات دائمة في نظام Kubernetes. يستخدم Kubernetes هذه الكيانات لتمثيل حالة مجموعتك. على وجه التحديد، يمكنها وصف التطبيقات المحوسبة التي تعمل، والموارد المتاحة لها، والسياسات المحيطة بسلوكها.»
عندما تقوم بإنشاء كائن Kubernetes، فإنك تخبر نظام Kubernetes بشكل فعال أنك تريد أن يوجد هذا الكائن مهما حدث، وسيعمل نظام Kubernetes باستمرار للحفاظ على تشغيل الكائن.
الـ Pods
وفقًا لوثائق Kubernetes الرسمية، «الـ Pods هي أصغر وحدات الحوسبة القابلة للنشر التي يمكنك إنشاؤها وإدارتها في Kubernetes.» يغلف الـ pod عادةً حاوية واحدة أو أكثر تكون مرتبطة ارتباطًا وثيقًا، وتتشارك دورة حياة وموارد قابلة للاستهلاك.

على الرغم من أن الـ pod يمكن أن يستضيف أكثر من حاوية واحدة، إلا أنه لا ينبغي عليك وضع الحاويات في الـ pod بشكل عشوائي. يجب أن تكون الحاويات في الـ pod مرتبطة ارتباطًا وثيقًا لدرجة أنها يمكن أن تُعامل كتطبيق واحد. على سبيل المثال، قد تعتمد واجهة برمجة التطبيقات الخلفية (back-end API) الخاصة بك على قاعدة البيانات، ولكن هذا لا يعني أنك ستضع كليهما في نفس الـ pod. طوال هذا المقال، لن ترى أي pod يحتوي على أكثر من حاوية واحدة تعمل. عادةً، لا يجب عليك إدارة الـ pod مباشرة. بدلاً من ذلك، يجب عليك العمل مع كائنات عالية المستوى يمكن أن توفر لك قابلية إدارة أفضل بكثير. ستتعرف على هذه الكائنات عالية المستوى في الأقسام اللاحقة.
الـ Services
وفقًا لوثائق Kubernetes الرسمية، «الخدمة (Service) في Kubernetes هي طريقة مجردة لكشف تطبيق يعمل على مجموعة من الـ pods كخدمة شبكة.» تتميز الـ pods في Kubernetes بطبيعتها العابرة (ephemeral). يتم إنشاؤها وبعد فترة، عندما يتم تدميرها، لا يتم إعادة تدويرها. بدلاً من ذلك، تحل pods جديدة متطابقة محل القديمة. بعض كائنات Kubernetes عالية المستوى قادرة حتى على إنشاء وتدمير الـ pods ديناميكيًا.
يتم تعيين عنوان IP جديد لكل pod وقت إنشائه. ولكن في حالة الكائنات عالية المستوى التي يمكنها إنشاء وتدمير وتجميع عدد من الـ pods، فإن مجموعة الـ pods التي تعمل في لحظة معينة قد تختلف عن مجموعة الـ pods التي تشغل هذا التطبيق بعد لحظة. يؤدي هذا إلى مشكلة: إذا كانت مجموعة من الـ pods في مجموعتك تعتمد على مجموعة أخرى من الـ pods داخل مجموعتك، فكيف تكتشف وتتتبع عناوين IP لبعضها البعض؟
تقول وثائق Kubernetes: «الخدمة (Service) هي تجريد يحدد مجموعة منطقية من الـ Pods وسياسة للوصول إليها.» وهذا يعني أساسًا أن الخدمة تجمع عددًا من الـ pods التي تؤدي نفس الوظيفة وتقدمها ككيان واحد. بهذه الطريقة، يزول الارتباك الناتج عن تتبع الـ pods المتعددة حيث تعمل تلك الخدمة الواحدة الآن كنوع من وسيط الاتصال لجميعها. في مثال hello-kube، قمت بإنشاء خدمة من نوع LoadBalancer تسمح للطلبات من خارج المجموعة بالاتصال بالـ pods التي تعمل داخل المجموعة.

في أي وقت تحتاج فيه إلى منح الوصول إلى pod واحد أو أكثر لتطبيق آخر أو لشيء خارج المجموعة، يجب عليك إنشاء خدمة. على سبيل المثال، إذا كان لديك مجموعة من الـ pods التي تشغل خوادم ويب ويجب أن تكون قابلة للوصول من الإنترنت، فستوفر الخدمة التجريد الضروري.
الصورة الكاملة
الآن بعد أن أصبح لديك فهم صحيح لمكونات Kubernetes الفردية، إليك تمثيل مرئي لكيفية عملها معًا خلف الكواليس:
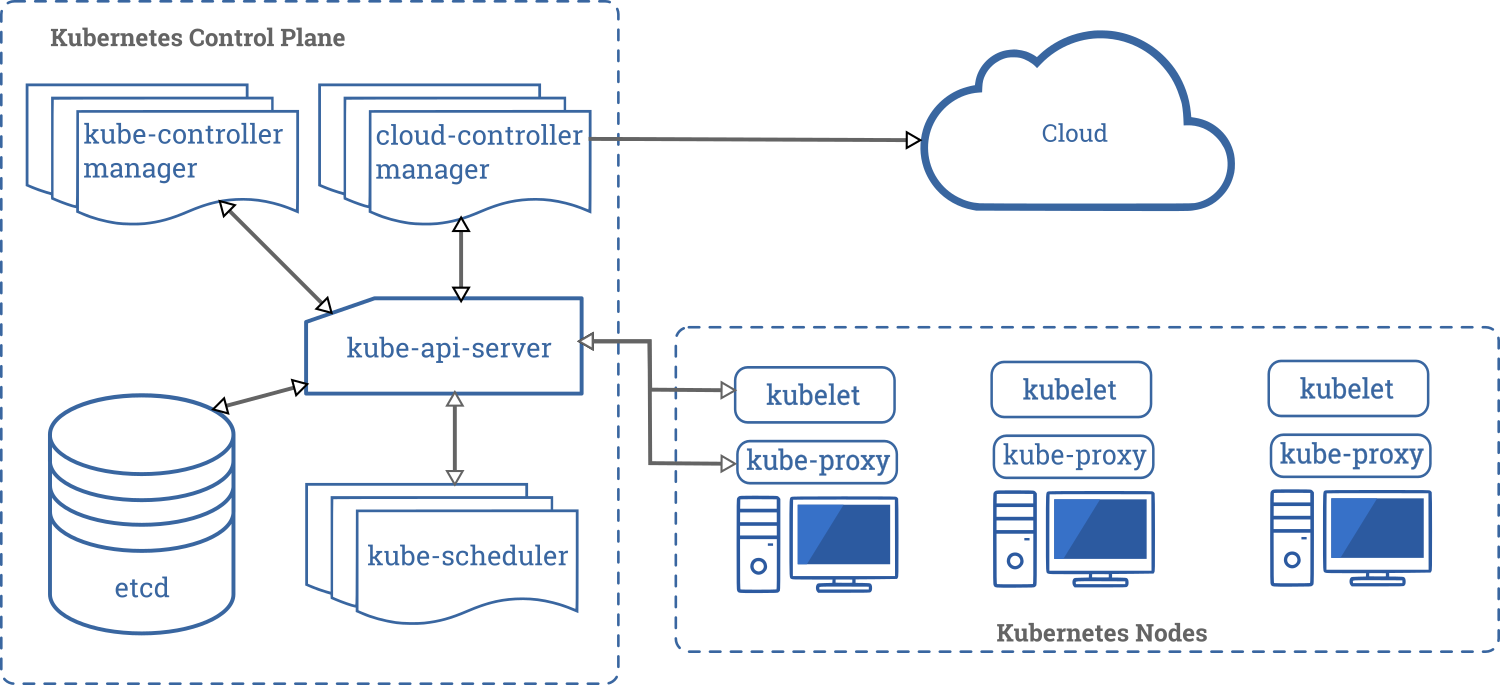
المصدر: kubernetes.io/docs/concepts/overview/components/
قبل أن أتعمق في شرح التفاصيل الفردية، ألقِ نظرة على ما تقوله وثائق Kubernetes: «للعمل مع كائنات Kubernetes – سواء لإنشائها أو تعديلها أو حذفها – ستحتاج إلى استخدام واجهة برمجة تطبيقات Kubernetes (Kubernetes API). عندما تستخدم واجهة سطر الأوامر kubectl، تقوم الـ CLI بإجراء استدعاءات Kubernetes API الضرورية نيابة عنك.»
كان أول أمر قمت بتشغيله هو أمر run. وكان كالتالي:
kubectl run hello-kube --image=fhsinchy/hello-kube --port=80الأمر run مسؤول عن إنشاء pod جديد يشغل الصورة المحددة. بمجرد إصدار هذا الأمر، تحدث مجموعة الأحداث التالية داخل مجموعة Kubernetes:
- يستقبل مكون
kube-api-serverالطلب، ويتحقق من صحته ويعالجه. - ثم يتصل
kube-api-serverبمكونkubeletعلى العقدة ويوفر التعليمات اللازمة لإنشاء الـpod. - ثم يبدأ مكون
kubeletالعمل على جعل الـpodقيد التشغيل ويحافظ أيضًا على تحديث معلومات الحالة في متجرetcd.
الصيغة العامة لأمر run هي كالتالي:
kubectl run <pod name> --image=<image name> --port=<port to expose>يمكنك تشغيل أي صورة حاوية صالحة داخل pod. تحتوي صورة Docker المسماة fhsinchy/hello-kube على تطبيق JavaScript بسيط جدًا يعمل على المنفذ 80 داخل الحاوية. يسمح الخيار --port=80 للـ pod بكشف المنفذ 80 من داخل الحاوية.

يعمل الـ pod الذي تم إنشاؤه حديثًا داخل مجموعة minikube ولا يمكن الوصول إليه من الخارج. لكشف الـ pod وجعله قابلاً للوصول، كان الأمر الثاني الذي أصدرته كالتالي:
kubectl expose pod hello-kube --type=LoadBalancer --port=80الأمر expose مسؤول عن إنشاء خدمة Kubernetes من نوع LoadBalancer تسمح للمستخدمين بالوصول إلى التطبيق الذي يعمل داخل الـ pod. تمامًا مثل أمر run، يمر تنفيذ أمر expose بنفس الخطوات داخل المجموعة. ولكن بدلاً من الـ pod، يوفر kube-api-server التعليمات اللازمة لإنشاء خدمة في هذه الحالة لمكون kubelet.
الصيغة العامة لأمر expose هي كالتالي:
kubectl expose <resource kind to expose> <resource name> --type=<type of service to create> --port=<port to expose>يمكن أن يكون نوع الكائن (object type) أي نوع كائن Kubernetes صالح. يجب أن يتطابق الاسم مع اسم الكائن الذي تحاول كشفه. يشير --type إلى نوع الخدمة التي تريدها. هناك أربعة أنواع مختلفة من الخدمات المتاحة للشبكات الداخلية أو الخارجية. أخيرًا، --port هو رقم المنفذ الذي تريد كشفه من الحاوية قيد التشغيل.

بمجرد إنشاء الخدمة، كانت القطعة الأخيرة من اللغز هي الوصول إلى التطبيق الذي يعمل داخل الـ pod. للقيام بذلك، كان الأمر الذي نفذته كالتالي:
minikube service hello-kubeعلى عكس الأوامر السابقة، لا يذهب هذا الأمر الأخير إلى kube-api-server. بدلاً من ذلك، يتصل بالمجموعة المحلية باستخدام برنامج minikube. يعيد أمر service الخاص بـ minikube عنوان URL كاملاً لخدمة معينة. عندما أنشأت hello-kube pod باستخدام الخيار --port=80، أصدرت تعليمات لـ Kubernetes للسماح للـ pod بكشف المنفذ 80 من داخل الحاوية، لكنه لم يكن قابلاً للوصول من خارج المجموعة. ثم عندما أنشأت خدمة LoadBalancer باستخدام الخيار --port=80، قامت بربط المنفذ 80 من تلك الحاوية بمنفذ عشوائي في النظام المحلي، مما جعله قابلاً للوصول من خارج المجموعة.
على نظامي، يعيد أمر service عنوان URL التالي للـ pod: 192.168.99.101:30848. عنوان IP في هذا الـ URL هو في الواقع عنوان IP للجهاز الافتراضي minikube. يمكنك التحقق من ذلك بتنفيذ الأمر التالي:
minikube ip
# 192.168.99.101للتحقق من أن المنفذ 30848 يشير إلى المنفذ 80 داخل الـ pod، يمكنك تنفيذ الأمر التالي:
kubectl get service hello-kube
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# hello-kube LoadBalancer 10.109.60.75 <pending> 80:30848/TCP 119sفي عمود PORT(S)، يمكنك أن ترى أن المنفذ 80 يرتبط بالفعل بالمنفذ 30484 على النظام المحلي. لذا، بدلاً من تشغيل أمر service، يمكنك فقط فحص عنوان IP والمنفذ ثم وضعهما في متصفحك يدويًا للوصول إلى تطبيق hello-kube.

الآن، يمكن تصور الحالة النهائية للمجموعة كالتالي:

إذا كنت قادمًا من عالم Docker، فقد يبدو لك أهمية استخدام الخدمة لكشف الـ pod مطولًا بعض الشيء في الوقت الحالي. ولكن عندما تنتقل إلى الأمثلة التي تتعامل مع أكثر من pod واحد، ستبدأ في تقدير كل ما يقدمه Kubernetes.
التخلص من موارد Kubernetes
الآن بعد أن عرفت كيفية إنشاء موارد Kubernetes مثل الـ pods والـ Services، تحتاج إلى معرفة كيفية التخلص منها. الطريقة الوحيدة للتخلص من مورد Kubernetes هي حذفه. يمكنك القيام بذلك باستخدام الأمر delete لـ kubectl. الصيغة العامة للأمر هي كالتالي:
kubectl delete <resource type> <resource name>لحذف pod باسم hello-kube، سيكون الأمر كالتالي:
kubectl delete pod hello-kube
# pod "hello-kube" deletedولحذف خدمة باسم hello-kube، سيكون الأمر كالتالي:
kubectl delete service hello-kube
# service "hello-kube" deletedأو إذا كنت في مزاج تدميري، يمكنك حذف جميع الكائنات من نوع معين دفعة واحدة باستخدام الخيار --all لأمر delete. الصيغة العامة للخيار هي كالتالي:
kubectl delete <object type> --allلذا لحذف جميع الـ pods والـ services، يجب عليك تنفيذ kubectl delete pod --all و kubectl delete service --all على التوالي.
نهج النشر التصريحي (Declarative Deployment Approach)
بصراحة، مثال hello-kube الذي رأيته للتو في القسم السابق ليس طريقة مثالية لتنفيذ النشر باستخدام Kubernetes. النهج الذي اتبعته في ذلك القسم هو نهج إلزامي (imperative approach) مما يعني أنه كان عليك تنفيذ كل أمر واحدًا تلو الآخر يدويًا. اتباع نهج إلزامي يتنافى مع الغرض الكامل من Kubernetes.
النهج المثالي للنشر باستخدام Kubernetes هو النهج التصريحي (declarative approach). فيه، أنت كمطور، تُعلم Kubernetes بالحالة التي ترغب أن تكون عليها خوادمك، ويقوم Kubernetes باكتشاف طريقة لتنفيذ ذلك. في هذا القسم، ستقوم بنشر نفس تطبيق hello-kube بنهج تصريحي. إذا لم تكن قد استنسخت (cloned) مستودع الكود المرتبط أعلاه، فافعل ذلك الآن. بمجرد حصولك عليه، انتقل إلى دليل hello-kube. يحتوي هذا الدليل على كود تطبيق hello-kube بالإضافة إلى ملف Dockerfile لبناء الصورة.
├── Dockerfile
├── index.html
├── package.json
├── public
└── src
2 directories, 3 filesيعيش كود JavaScript داخل مجلد src ولكن هذا ليس ذا أهمية لك. الملف الذي يجب أن تنظر إليه هو Dockerfile لأنه يمكن أن يمنحك نظرة ثاقبة حول كيفية التخطيط لنشرك. محتويات Dockerfile هي كالتالي:
FROM node as builder
WORKDIR /usr/app
COPY ./package.json ./
RUN npm install
COPY . .
RUN npm run build
EXPOSE 80
FROM nginx
COPY --from=builder /usr/app/dist /usr/share/nginx/htmlكما ترى، هذه عملية بناء متعددة المراحل (multi-staged build process). تستخدم المرحلة الأولى صورة node كصورة أساسية وتقوم بتجميع تطبيق JavaScript في مجموعة من الملفات الجاهزة للإنتاج. تنسخ المرحلة الثانية الملفات التي تم بناؤها خلال المرحلة الأولى، وتلصقها داخل جذر مستند NGINX الافتراضي. نظرًا لأن الصورة الأساسية للمرحلة الثانية هي nginx، فإن الصورة الناتجة ستكون صورة nginx تقدم الملفات التي تم بناؤها خلال المرحلة الأولى على المنفذ 80 (المنفذ الافتراضي لـ nginx). الآن لنشر هذا التطبيق على Kubernetes، سيتعين عليك إيجاد طريقة لتشغيل الصورة كحاوية وجعل المنفذ 80 قابلاً للوصول من العالم الخارجي.
كتابة أول مجموعة من التكوينات
في النهج التصريحي، بدلاً من إصدار الأوامر الفردية في المحطة الطرفية، تقوم بكتابة التكوين الضروري في ملف YAML وتغذية Kubernetes به. في دليل مشروع hello-kube، أنشئ دليلًا آخر باسم k8s. k8s هو اختصار لـ k(ubernete = 8 character)s. لست بحاجة إلى تسمية المجلد بهذه الطريقة، يمكنك تسميته بما تريد. ليس من الضروري حتى الاحتفاظ به داخل دليل المشروع. يمكن أن تعيش ملفات التكوين هذه في أي مكان على جهاز الكمبيوتر الخاص بك، حيث لا علاقة لها بكود مصدر المشروع.
الآن داخل دليل k8s هذا، أنشئ ملفًا جديدًا باسم hello-kube-pod.yaml. سأقوم بكتابة الكود للملف أولاً ثم سأشرحه لك سطرًا بسطر. محتوى هذا الملف هو كالتالي:
apiVersion: v1
kind: Pod
metadata:
name: hello-kube-pod
labels:
component: web
spec:
containers:
- name: hello-kube
image: fhsinchy/hello-kube
ports:
- containerPort: 80يحتوي كل ملف تكوين Kubernetes صالح على أربعة حقول مطلوبة. وهي كالتالي:
apiVersion: أي إصدار من واجهة برمجة تطبيقاتKubernetesتستخدمه لإنشاء هذا الكائن. قد تتغير هذه القيمة اعتمادًا على نوع الكائن الذي تقوم بإنشائه. لإنشاءPod، الإصدار المطلوب هوv1.kind: نوع الكائن الذي تريد إنشاءه. يمكن أن تكون الكائنات فيKubernetesمن أنواع عديدة. بينما تتقدم في المقال، ستتعرف على الكثير منها، ولكن في الوقت الحالي، افهم أنك تقوم بإنشاء كائنPod.metadata: بيانات تساعد في تحديد الكائن بشكل فريد. تحت هذا الحقل، يمكنك الحصول على معلومات مثلnameوlabelsوannotationوما إلى ذلك. ستظهر سلسلةmetadata.nameفي المحطة الطرفية وستُستخدم في أوامرkubectl. لا يجب أن يكون زوج المفتاح والقيمة تحت حقلmetadata.labelsهوcomponents: web. يمكنك إعطائه أي تسمية مثلapp: hello-kube. ستُستخدم هذه القيمة كـselectorعند إنشاء خدمةLoadBalancerقريبًا جدًا.spec: يحتوي على الحالة التي ترغب فيها للكائن. يحتوي الحقل الفرعيspec.containersعلى معلومات حول الحاويات التي ستعمل داخل هذا الـPod. قيمةspec.containers.nameهي ما ستعيّنه بيئة تشغيل الحاويات داخل العقدة للحاوية التي تم إنشاؤها حديثًا.spec.containers.imageهي صورة الحاوية التي ستُستخدم لإنشاء هذه الحاوية. ويحتوي حقلspec.containers.portsعلى تكوين بخصوص تكوينات المنافذ المختلفة. يشيرcontainerPort: 80إلى أنك تريد كشف المنفذ80من الحاوية.
إذا كنت تستخدم جهاز Raspberry Pi، فاستخدم raed667/hello-kube كصورة بدلاً من fhsinchy/hello-kube.
الآن لتغذية ملف التكوين هذا إلى Kubernetes، ستستخدم الأمر apply. الصيغة العامة للأمر هي كالتالي:
kubectl apply -f <configuration file>لتغذية ملف تكوين باسم hello-kube-pod.yaml، سيكون الأمر كالتالي:
kubectl apply -f hello-kube-pod.yaml
# pod/hello-kube-pod createdللتأكد من أن الـ Pod قيد التشغيل، نفذ الأمر التالي:
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# hello-kube 1/1 Running 0 3m3sيجب أن ترى Running في عمود STATUS. إذا رأيت شيئًا مثل ContainerCreating، انتظر دقيقة أو دقيقتين وتحقق مرة أخرى. بمجرد أن يكون الـ Pod قيد التشغيل، حان الوقت لكتابة ملف التكوين لخدمة LoadBalancer. أنشئ ملفًا آخر داخل دليل k8s باسم hello-kube-load-balancer-service.yaml وضع فيه الكود التالي:
apiVersion: v1
kind: Service
metadata:
name: hello-kube-load-balancer-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 80
selector:
component: webمثل ملف التكوين السابق، تخدم حقول apiVersion و kind و metadata نفس الغرض هنا. كما ترى، لا يوجد حقل labels داخل metadata هنا. هذا لأن الخدمة تختار كائنات أخرى باستخدام labels، ولا تختار الكائنات الأخرى خدمة. تذكر، الخدمات تُعد سياسة وصول للكائنات الأخرى، ولا تُعد الكائنات الأخرى سياسة وصول لخدمة.
داخل حقل spec، يمكنك رؤية مجموعة جديدة من القيم. على عكس الـ Pod، تحتوي الخدمات على أربعة أنواع. وهي ClusterIP و NodePort و LoadBalancer و ExternalName. في هذا المثال، أنت تستخدم النوع LoadBalancer، وهي الطريقة القياسية لكشف خدمة خارج المجموعة. ستمنحك هذه الخدمة عنوان IP يمكنك استخدامه بعد ذلك للاتصال بالتطبيقات التي تعمل داخل مجموعتك.

يتطلب نوع LoadBalancer قيمتي منفذ للعمل بشكل صحيح. تحت حقل ports، قيمة port هي للوصول إلى الـ pod نفسه ويمكن أن تكون أي شيء تريده. قيمة targetPort هي من داخل الحاوية ويجب أن تتطابق مع المنفذ الذي تريد كشفه من داخل الحاوية. لقد ذكرت بالفعل أن تطبيق hello-kube يعمل على المنفذ 80 داخل الحاوية. لقد قمت أيضًا بكشف هذا المنفذ في ملف تكوين الـ Pod، لذا ستكون targetPort هي 80.
يُستخدم حقل selector لتحديد الكائنات التي ستتصل بهذه الخدمة. يجب أن يتطابق زوج المفتاح والقيمة component: web مع زوج المفتاح والقيمة تحت حقل labels في ملف تكوين الـ Pod. إذا كنت قد استخدمت زوج مفتاح وقيمة آخر مثل app: hello-kube في ملف التكوين هذا، فاستخدمه بدلاً من ذلك. لتغذية هذا الملف إلى Kubernetes، ستستخدم مرة أخرى الأمر apply. سيكون الأمر لتغذية ملف باسم hello-kube-load-balancer-service.yaml كالتالي:
kubectl apply -f hello-kube-load-balancer-service.yaml
# service/hello-kube-load-balancer-service createdللتأكد من إنشاء موازن التحميل بنجاح، نفذ الأمر التالي:
kubectl get service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# hello-kube-load-balancer-service LoadBalancer 10.107.231.120 <pending> 80:30848/TCP 7s
# kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 21hتأكد من رؤية اسم hello-kube-load-balancer-service في القائمة. الآن بعد أن أصبح لديك pod قيد التشغيل ومكشوف، يمكنك المضي قدمًا والوصول إليه. نفذ الأمر التالي للقيام بذلك:
minikube service hello-kube-load-balancer-service
# |-----------|----------------------------------|-------------|-----------------------------|
# | NAMESPACE | NAME | TARGET PORT | URL |
# |-----------|----------------------------------|-------------|-----------------------------|
# | default | hello-kube-load-balancer-service | 80 | http://192.168.99.101:30848 |
# |-----------|----------------------------------|-------------|-----------------------------|
# ? Opening service default/hello-kube-load-balancer in default browser...يجب أن يفتح متصفح الويب الافتراضي الخاص بك تلقائيًا ويجب أن ترى شيئًا كهذا:

يمكنك أيضًا تغذية كلا الملفين معًا بدلاً من تغذيتهما بشكل فردي. للقيام بذلك، يمكنك استبدال اسم الملف باسم الدليل كالتالي:
kubectl apply -f k8s
# service/hello-kube-load-balancer-service created
# pod/hello-kube-pod createdفي هذه الحالة، تأكد من أن محطتك الطرفية في الدليل الأب لدليل k8s. إذا كنت داخل دليل k8s، يمكنك استخدام نقطة (.) للإشارة إلى الدليل الحالي. عند تطبيق التكوينات بشكل جماعي، قد يكون من الجيد التخلص من الموارد التي تم إنشاؤها مسبقًا. بهذه الطريقة، تقل احتمالية حدوث تعارضات بشكل كبير. النهج التصريحي هو النهج المثالي عند العمل مع Kubernetes، باستثناء بعض الحالات الخاصة التي ستراها قرب نهاية المقال.
لوحة تحكم Kubernetes (Dashboard)
في قسم سابق، استخدمت الأمر delete للتخلص من كائن Kubernetes. في هذا القسم، ومع ذلك، اعتقدت أن تقديم لوحة التحكم سيكون فكرة رائعة. لوحة تحكم Kubernetes هي واجهة مستخدم رسومية (graphical UI) يمكنك استخدامها لإدارة أعباء العمل والخدمات والمزيد.
لتشغيل لوحة تحكم Kubernetes، نفذ الأمر التالي في محطتك الطرفية:
minikube dashboard
# ? Verifying dashboard health ...
# ? Launching proxy ...
# ? Verifying proxy health ...
# ? Opening http://127.0.0.1:52393/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/ in your default browser...يجب أن تفتح لوحة التحكم تلقائيًا في متصفحك الافتراضي:

الواجهة سهلة الاستخدام ويمكنك التجول فيها بحرية. على الرغم من أنه من الممكن تمامًا إنشاء الكائنات وإدارتها وحذفها من هذه الواجهة، إلا أنني سأستخدم واجهة سطر الأوامر (CLI) لبقية هذا المقال. هنا في قائمة الـ Pods، يمكنك استخدام قائمة النقاط الثلاث على الجانب الأيمن لحذف الـ Pod. يمكنك فعل الشيء نفسه مع خدمة LoadBalancer أيضًا. في الواقع، قائمة الخدمات موضوعة بشكل ملائم مباشرة بعد قائمة الـ Pods. يمكنك إغلاق لوحة التحكم بالضغط على مجموعة مفاتيح Ctrl + C أو إغلاق نافذة المحطة الطرفية.
العمل مع التطبيقات متعددة الحاويات
حتى الآن، عملت مع تطبيقات تعمل داخل حاوية واحدة. في هذا القسم، ستعمل مع تطبيق يتكون من حاويتين. ستتعرف أيضًا على Deployment و ClusterIP و PersistentVolume و PersistentVolumeClaim وبعض تقنيات تصحيح الأخطاء. التطبيق الذي ستعمل معه هو واجهة برمجة تطبيقات (API) بسيطة للملاحظات باستخدام Express مع وظائف CRUD كاملة. يستخدم التطبيق PostgreSQL كنظام قاعدة بيانات له. لذا لن تقوم بنشر التطبيق فحسب، بل ستقوم أيضًا بإعداد الشبكات الداخلية بين التطبيق وقاعدة البيانات.
يوجد كود التطبيق داخل دليل notes-api داخل مستودع المشروع.
.
├── api
├── docker-compose.yaml
└── postgres
2 directories, 1 fileيوجد كود مصدر التطبيق داخل دليل api، ويحتوي دليل postgres على ملف Dockerfile لإنشاء صورة postgres مخصصة. يحتوي ملف docker-compose.yaml على التكوين الضروري لتشغيل التطبيق باستخدام docker-compose. تمامًا مثل المشروع السابق، يمكنك البحث في ملف Dockerfile الفردي لكل خدمة للحصول على فكرة عن كيفية تشغيل التطبيق داخل الحاوية. أو يمكنك فقط فحص ملف docker-compose.yaml والتخطيط لنشر Kubernetes الخاص بك باستخدام ذلك.
version: "3.8"
services:
db:
build:
context: ./postgres
dockerfile: Dockerfile.dev
volumes:
- db-data:/var/lib/postgresql/data
environment:
POSTGRES_PASSWORD: 63eaQB9wtLqmNBpg
POSTGRES_DB: notesdb
api:
build:
context: ./api
dockerfile: Dockerfile.dev
ports:
- 3000:3000
volumes:
- /home/node/app/node_modules
- ./api:/home/node/app
environment:
DB_CONNECTION: pg
DB_HOST: db
DB_PORT: 5432
DB_USER: postgres
DB_DATABASE: notesdb
DB_PASSWORD: 63eaQB9wtLqmNBpg
volumes:
db-data:
name: notes-db-dev-dataبالنظر إلى تعريف خدمة api، يمكنك أن ترى أن التطبيق يعمل على المنفذ 3000 داخل الحاوية. كما يتطلب مجموعة من متغيرات البيئة للعمل بشكل صحيح. يمكن تجاهل وحدات التخزين (volumes) لأنها كانت ضرورية لأغراض التطوير فقط، وتكوين البناء خاص بـ Docker. لذا، مجموعتا المعلومات اللتان يمكنك نقلهما إلى ملفات تكوين Kubernetes الخاصة بك دون تغيير تقريبًا هما كالتالي:
- تعيينات المنافذ (
Port mappings): لأنك ستحتاج إلى كشف نفس المنفذ من الحاوية. - متغيرات البيئة (
Environment variables): لأن هذه المتغيرات ستكون هي نفسها عبر جميع البيئات (القيم ستتغير، بالطبع).
خدمة db أبسط. كل ما لديها هو مجموعة من متغيرات البيئة. يمكنك حتى استخدام صورة postgres الرسمية بدلاً من صورة مخصصة. ولكن السبب الوحيد لوجود صورة مخصصة هو إذا كنت تريد أن يأتي مثيل قاعدة البيانات مع جدول notes الذي تم إنشاؤه مسبقًا. هذا الجدول ضروري للتطبيق. إذا نظرت داخل دليل postgres/docker-entrypoint-initdb.d، سترى ملفًا باسم notes.sql يُستخدم لإنشاء قاعدة البيانات أثناء التهيئة.
خطة النشر
على عكس المشروع السابق الذي قمت بنشره، سيكون هذا المشروع أكثر تعقيدًا بعض الشيء. في هذا المشروع، لن تقوم بإنشاء مثيل واحد فقط، بل ثلاثة مثيلات لواجهة برمجة تطبيقات الملاحظات. سيتم كشف هذه المثيلات الثلاثة خارج المجموعة باستخدام خدمة LoadBalancer.

بصرف النظر عن هذه المثيلات الثلاثة، سيكون هناك مثيل آخر لنظام قاعدة بيانات PostgreSQL. ستتصل جميع المثيلات الثلاثة لتطبيق واجهة برمجة تطبيقات الملاحظات بمثيل قاعدة البيانات هذا باستخدام خدمة ClusterIP. خدمة ClusterIP هي نوع آخر من خدمات Kubernetes التي تكشف تطبيقًا داخل مجموعتك. هذا يعني أنه لا يمكن لأي حركة مرور خارجية الوصول إلى التطبيق باستخدام خدمة ClusterIP.

في هذا المشروع، يجب الوصول إلى قاعدة البيانات بواسطة واجهة برمجة تطبيقات الملاحظات فقط، لذا فإن كشف خدمة قاعدة البيانات داخل المجموعة هو خيار مثالي. لقد ذكرت بالفعل في قسم سابق أنه لا يجب عليك إنشاء الـ pods مباشرة. لذا في هذا المشروع، ستستخدم Deployment بدلاً من Pod.
وحدات التحكم بالنسخ المتماثلة (Replication Controllers) ومجموعات النسخ المتماثلة (Replica Sets) وعمليات النشر (Deployments)
وفقًا لوثائق Kubernetes الرسمية، «في Kubernetes، وحدات التحكم (controllers) هي حلقات تحكم تراقب حالة مجموعتك، ثم تُجري أو تطلب تغييرات عند الحاجة. تحاول كل وحدة تحكم تحريك حالة المجموعة الحالية أقرب إلى الحالة المطلوبة. حلقة التحكم هي حلقة غير منتهية تنظم حالة النظام.»
ReplicationController، كما يوحي الاسم، يتيح لك إنشاء نسخ متماثلة متعددة بسهولة بالغة. بمجرد إنشاء العدد المطلوب من النسخ المتماثلة، ستتأكد وحدة التحكم من بقاء الحالة على هذا النحو. إذا قررت بعد بعض الوقت تقليل عدد النسخ المتماثلة، فسيتخذ ReplicationController إجراءات فورية ويتخلص من الـ pods الزائدة. وإلا، إذا أصبح عدد النسخ المتماثلة أقل مما كنت تريده (ربما تعطلت بعض الـ pods)، فسيقوم ReplicationController بإنشاء نسخ جديدة لتتناسب مع الحالة المطلوبة.
على الرغم من فائدتها، فإن ReplicationController ليست الطريقة الموصى بها لإنشاء النسخ المتماثلة في الوقت الحاضر. لقد حلت واجهة برمجة تطبيقات أحدث تسمى ReplicaSet محلها. بصرف النظر عن حقيقة أن ReplicaSet يمكن أن توفر لك نطاقًا أوسع من خيارات التحديد، فإن كل من ReplicationController و ReplicaSet متشابهان إلى حد كبير. إن وجود نطاق أوسع من خيارات المحددات أمر جيد، ولكن الأفضل هو الحصول على مزيد من المرونة فيما يتعلق بطرح التحديثات والتراجع عنها. هذا هو المكان الذي تظهر فيه واجهة برمجة تطبيقات Kubernetes أخرى تسمى Deployment.
Deployment يشبه امتدادًا لواجهة برمجة تطبيقات ReplicaSet الرائعة بالفعل. لا يسمح لك Deployment بإنشاء نسخ متماثلة في وقت قصير فحسب، بل يتيح لك أيضًا إصدار تحديثات أو العودة إلى وظيفة سابقة باستخدام أمر أو أمرين فقط من أوامر kubectl.
ReplicationController |
ReplicaSet |
Deployment |
|---|---|---|
يسمح بإنشاء pods متعددة بسهولة |
يسمح بإنشاء pods متعددة بسهولة |
يسمح بإنشاء pods متعددة بسهولة |
الطريقة الأصلية للنسخ المتماثل في Kubernetes |
يحتوي على محددات أكثر مرونة | يمتد على ReplicaSets مع طرح وتراجع سهل للتحديثات |
في هذا المشروع، ستستخدم Deployment للحفاظ على مثيلات التطبيق.
إنشاء أول عملية نشر لك
لنبدأ بكتابة ملف التكوين لنشر واجهة برمجة تطبيقات الملاحظات. أنشئ دليل k8s داخل دليل مشروع notes-api. داخل هذا الدليل، أنشئ ملفًا باسم api-deployment.yaml وضع المحتوى التالي فيه:
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000في هذا الملف، تخدم حقول apiVersion و kind و metadata و spec نفس الغرض كما في المشروع السابق. التغييرات الملحوظة في هذا الملف عن الملف الأخير هي كالتالي:
- لإنشاء
Pod، كانapiVersionالمطلوب هوv1. ولكن لإنشاءDeployment، الإصدار المطلوب هوapps/v1. يمكن أن تكون إصداراتKubernetes APIمربكة بعض الشيء في بعض الأحيان، ولكن مع استمرارك في العمل معKubernetes، ستعتاد عليها. يمكنك أيضًا الرجوع إلى الوثائق الرسمية للحصول على أمثلة لملفاتYAML. - النوع (
kind) هوDeploymentوهو واضح بذاته. - يحدد
spec.replicasعدد النسخ المتماثلة قيد التشغيل. تعيين هذه القيمة على3يعني أنك تُعلمKubernetesأنك تريد ثلاثة مثيلات من تطبيقك تعمل في جميع الأوقات. spec.selectorهو المكان الذي تُعلم فيه الـDeploymentأي الـpodsيجب التحكم فيها. لقد ذكرت بالفعل أن الـDeploymentهو امتداد لـReplicaSetويمكنه التحكم في مجموعة من كائناتKubernetes. تعيينselector.matchLabelsعلىcomponent: apiيعني أن هذا الـDeploymentسيتحكم في الـpodsالتي تحتوي على تسميةcomponent: api. هذا السطر يُعلمKubernetesأنك تريد أن يتحكم هذا الـDeploymentفي جميع الـpodsالتي تحتوي على تسميةcomponent: api.spec.templateهو القالب لتكوين الـpods. إنه مطابق تقريبًا لملف التكوين السابق.
إذا كنت تستخدم جهاز Raspberry Pi، فاستخدم raed667/notes-api بدلاً من fhsinchy/notes-api كصورة.
الآن لرؤية هذا التكوين عمليًا، طبق الملف تمامًا كما في المشروع السابق:
kubectl apply -f api-deployment.yaml
# deployment.apps/api-deployment createdللتأكد من إنشاء الـ Deployment، نفذ الأمر التالي:
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 0/3 3 0 2m7sإذا نظرت إلى عمود READY، سترى 0/3. هذا يعني أن الـ pods لم يتم إنشاؤها بعد. انتظر بضع دقائق وحاول مرة أخرى.
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 0/3 3 0 28mكما ترى، لقد انتظرت ما يقرب من نصف ساعة وما زالت أي من الـ pods غير جاهزة. واجهة برمجة التطبيقات نفسها لا تتجاوز بضع مئات من الكيلوبايت. نشر بهذا الحجم لا ينبغي أن يستغرق كل هذا الوقت. مما يعني أن هناك مشكلة وعلينا إصلاحها.
فحص موارد Kubernetes
قبل أن تتمكن من حل مشكلة، يجب عليك أولاً معرفة مصدرها. نقطة البداية الجيدة هي الأمر get. أنت تعرف بالفعل الأمر get الذي يطبع جدولاً يحتوي على معلومات مهمة حول مورد Kubernetes واحد أو أكثر. الصيغة العامة للأمر هي كالتالي:
kubectl get <resource type> <resource name>لتشغيل الأمر get على api-deployment الخاص بك، نفذ سطر الكود التالي في محطتك الطرفية:
kubectl get deployment api-deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 0/3 3 0 15mيمكنك حذف اسم api-deployment للحصول على قائمة بجميع عمليات النشر المتاحة. يمكنك أيضًا تشغيل الأمر get على ملف تكوين. إذا كنت ترغب في الحصول على معلومات حول عمليات النشر الموصوفة في ملف api-deployment.yaml، فيجب أن يكون الأمر كالتالي:
kubectl get -f api-deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 0/3 3 0 18mبشكل افتراضي، يعرض الأمر get كمية صغيرة جدًا من المعلومات. يمكنك الحصول على المزيد منه باستخدام الخيار -o. يحدد الخيار -o تنسيق الإخراج لأمر get. يمكنك استخدام تنسيق الإخراج wide لرؤية المزيد من التفاصيل.
kubectl get -f api-deployment.yaml -o wide
# NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
# api-deployment 0/3 3 0 19m api fhsinchy/notes-api component=apiكما ترى، تحتوي القائمة الآن على معلومات أكثر من ذي قبل. يمكنك معرفة المزيد عن خيارات الأمر get من الوثائق الرسمية. تشغيل get على الـ Deployment لا يعرض أي شيء مثير للاهتمام، بصراحة. في مثل هذه الحالات، يجب عليك الانتقال إلى موارد المستوى الأدنى. ألقِ نظرة على قائمة الـ pods وانظر إذا كان يمكنك العثور على شيء مثير للاهتمام هناك:
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# api-deployment-d59f9c884-88j45 0/1 CrashLoopBackOff 10 30m
# api-deployment-d59f9c884-96hfr 0/1 CrashLoopBackOff 10 30m
# api-deployment-d59f9c884-pzdxg 0/1 CrashLoopBackOff 10 30mالآن هذا مثير للاهتمام. جميع الـ pods لديها حالة STATUS من نوع CrashLoopBackOff وهي جديدة. في السابق، رأيت فقط حالتي ContainerCreating و Running. قد ترى Error بدلاً من CrashLoopBackOff أيضًا. بالنظر إلى عمود RESTARTS، يمكنك أن ترى أن الـ pods قد أعيد تشغيلها 10 مرات بالفعل. هذا يعني لسبب ما أن الـ pods تفشل في البدء. الآن للحصول على نظرة أكثر تفصيلاً على أحد الـ pods، يمكنك استخدام أمر آخر يسمى describe. إنه يشبه إلى حد كبير الأمر get. الصيغة العامة للأمر هي كالتالي:
kubectl describe <resource type> <resource name>للحصول على تفاصيل الـ pod الذي يحمل اسم api-deployment-d59f9c884-88j45، يمكنك تنفيذ الأمر التالي:
kubectl describe pod api-deployment-d59f9c884-88j45
# Name: api-deployment-d59f9c884-88j45
# Namespace: default
# Priority: 0
# Node: minikube/172.28.80.217
# Start Time: Sun, 09 Aug 2020 16:01:28 +0600
# Labels: component=api
# pod-template-hash=d59f9c884
# Annotations: <none>
# Status: Running
# IP: 172.17.0.4
# IPs:
# IP: 172.17.0.4
# Controlled By: ReplicaSet/api-deployment-d59f9c884
# Containers:
# api:
# Container ID: docker://d2bc15bda9bf4e6d08f7ca8ff5d3c8593655f5f398cf8bdd18b71da8807930c1
# Image: fhsinchy/notes-api
# Image ID: docker-pullable://fhsinchy/notes-api@sha256:4c715c7ce3ad3693c002fad5e7e7b70d5c20794a15dbfa27945376af3f3bb78c
# Port: 3000/TCP
# Host Port: 0/TCP
# State: Waiting
# Reason: CrashLoopBackOff
# Last State: Terminated
# Reason: Error
# Exit Code: 1
# Started: Sun, 09 Aug 2020 16:13:12 +0600
# Finished: Sun, 09 Aug 2020 16:13:12 +0600
# Ready: False
# Restart Count: 10
# Environment: <none>
# Mounts:
# /var/run/secrets/kubernetes.io/serviceaccount from default-token-gqfr4 (ro)
# Conditions:
# Type Status
# Initialized True
# Ready False
# ContainersReady False
# PodScheduled True
# Volumes:
# default-token-gqfr4:
# Type: Secret (a volume populated by a Secret)
# SecretName: default-token-gqfr4
# Optional: false
# QoS Class: BestEffort
# Node-Selectors: <none>
# Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
# node.kubernetes.io/unreachable:NoExecute for 300s
# Events:
# Type Reason Age From Message
# ---- ------ ---- ---- -------
# Normal Scheduled <unknown> default-scheduler Successfully assigned default/api-deployment-d59f9c884-88j45 to minikube
# Normal Pulled 2m40s (x4 over 3m47s) kubelet, minikube Successfully pulled image "fhsinchy/notes-api"
# Normal Created 2m40s (x4 over 3m47s) kubelet, minikube Created container api
# Normal Started 2m40s (x4 over 3m47s) kubelet, minikube Started container api
# Normal Pulling 107s (x5 over 3m56s) kubelet, minikube Pulling image "fhsinchy/notes-api"
# Warning BackOff <invalid> (x44 over 3m32s) kubelet, minikube Back-off restarting failed containerالجزء الأكثر إثارة للاهتمام في هذا النص الطويل هو قسم Events. ألقِ نظرة فاحصة:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/api-deployment-d59f9c884-88j45 to minikube
Normal Pulled 2m40s (x4 over 3m47s) kubelet, minikube Successfully pulled image "fhsinchy/notes-api"
Normal Created 2m40s (x4 over 3m47s) kubelet, minikube Created container api
Normal Started 2m40s (x4 over 3m47s) kubelet, minikube Started container api
Normal Pulling 107s (x5 over 3m56s) kubelet, minikube Pulling image "fhsinchy/notes-api"
Warning BackOff <invalid> (x44 over 3m32s) kubelet, minikube Back-off restarting failed containerمن هذه الأحداث، يمكنك أن ترى أن صورة الحاوية تم سحبها بنجاح. تم إنشاء الحاوية أيضًا، ولكن من الواضح من رسالة Back-off restarting failed container أن الحاوية فشلت في البدء. أمر describe مشابه جدًا لأمر get وله نفس النوع من الخيارات. يمكنك حذف اسم api-deployment-d59f9c884-88j45 للحصول على معلومات حول جميع الـ pods المتاحة. أو يمكنك أيضًا استخدام الخيار -f لتمرير ملف تكوين إلى الأمر. قم بزيارة الوثائق الرسمية لمعرفة المزيد.
الآن بعد أن عرفت أن هناك خطأ ما في الحاوية، يجب عليك الانتقال إلى مستوى الحاوية ومعرفة ما يحدث هناك.
الحصول على سجلات الحاوية من الـ Pods
يوجد أمر kubectl آخر يسمى logs يمكن أن يساعدك في الحصول على سجلات الحاوية من داخل الـ pod. الصيغة العامة للأمر هي كالتالي:
kubectl logs <pod>لعرض السجلات داخل الـ pod الذي يحمل اسم api-deployment-d59f9c884-88j45، يجب أن يكون الأمر كالتالي:
kubectl logs api-deployment-d59f9c884-88j45
# > api@1.0.0 start /usr/app
# > cross-env NODE_ENV=production node bin/www
# /usr/app/node_modules/knex/lib/client.js:55
# throw new Error(`knex: Required configuration option 'client' is missing.`);
# ^
# Error: knex: Required configuration option 'client' is missing.
# at new Client (/usr/app/node_modules/knex/lib/client.js:55:11)
# at Knex (/usr/app/node_modules/knex/lib/knex.js:53:28)
# at Object.<anonymous> (/usr/app/services/knex.js:5:18)
# at Module._compile (internal/modules/cjs/loader.js:1138:30)
# at Object.Module._extensions..js (internal/modules/cjs/loader.js:1158:10)
# at Module.load (internal/modules/cjs/loader.js:986:32)
# at Function.Module._load (internal/modules/cjs/loader.js:879:14)
# at Module.require (internal/modules/cjs/loader.js:1026:19)
# at require (internal/modules/cjs/helpers.js:72:18)
# at Object.<anonymous> (/usr/app/services/index.js:1:14)
# npm ERR! code ELIFECYCLE
# npm ERR! errno 1
# npm ERR! api@1.0.0 start: `cross-env NODE_ENV=production node bin/www`
# npm ERR! Exit status 1
# npm ERR!
# npm ERR! Failed at the api@1.0.0 start script.
# npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
# npm ERR! A complete log of this run can be found in:
# npm ERR! /root/.npm/_logs/2020-08-09T10_28_52_779Z-debug.logالآن هذا ما تحتاجه لتصحيح المشكلة. يبدو أن مكتبة knex.js تفتقر إلى قيمة مطلوبة، مما يمنع التطبيق من البدء. يمكنك معرفة المزيد عن أمر logs من الوثائق الرسمية. يحدث هذا لأنك تفتقد بعض متغيرات البيئة المطلوبة في تعريف النشر. إذا ألقيت نظرة أخرى على تعريف خدمة api داخل ملف docker-compose.yaml، يجب أن ترى شيئًا كهذا:
api:
build:
context: ./api
dockerfile: Dockerfile.dev
ports:
- 3000:3000
volumes:
- /home/node/app/node_modules
- ./api:/home/node/app
environment:
DB_CONNECTION: pg
DB_HOST: db
DB_PORT: 5432
DB_USER: postgres
DB_DATABASE: notesdb
DB_PASSWORD: 63eaQB9wtLqmNBpgمتغيرات البيئة هذه مطلوبة لكي يتواصل التطبيق مع قاعدة البيانات. لذا، يجب أن يؤدي إضافة هذه المتغيرات إلى تكوين النشر إلى حل المشكلة.
متغيرات البيئة
إضافة متغيرات البيئة إلى ملف تكوين Kubernetes أمر مباشر للغاية. افتح ملف api-deployment.yaml وحدث محتواه ليبدو كالتالي:
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
# these are the environment variables
env:
- name: DB_CONNECTION
value: pgيحتوي حقل containers.env على جميع متغيرات البيئة. إذا نظرت عن كثب، سترى أنني لم أضف جميع متغيرات البيئة من ملف docker-compose.yaml. لقد أضفت واحدًا فقط. يشير DB_CONNECTION إلى أن التطبيق يستخدم قاعدة بيانات PostgreSQL. يجب أن يؤدي إضافة هذا المتغير الوحيد إلى حل المشكلة. الآن طبق ملف التكوين مرة أخرى بتنفيذ الأمر التالي:
kubectl apply -f api-deployment.yaml
# deployment.apps/api-deployment configuredعلى عكس المرات الأخرى، يقول الإخراج هنا إن المورد قد تم configured (تكوينه). هذا هو جمال Kubernetes. يمكنك فقط إصلاح المشكلات وإعادة تطبيق نفس ملف التكوين على الفور. الآن استخدم الأمر get مرة أخرى للتأكد من أن كل شيء يعمل بشكل صحيح.
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 3/3 3 3 68m
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# api-deployment-66cdd98546-l9x8q 1/1 Running 0 7m26s
# api-deployment-66cdd98546-mbfw9 1/1 Running 0 7m31s
# api-deployment-66cdd98546-pntxv 1/1 Running 0 7m21sجميع الـ pods الثلاثة تعمل، والـ Deployment يعمل بشكل جيد أيضًا.
إنشاء نشر قاعدة البيانات
الآن بعد أن أصبحت واجهة برمجة التطبيقات (API) قيد التشغيل، حان الوقت لكتابة التكوين لمثيل قاعدة البيانات. أنشئ ملفًا آخر باسم postgres-deployment.yaml داخل دليل k8s وضع المحتوى التالي فيه:
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
spec:
replicas: 1
selector:
matchLabels:
component: postgres
template:
metadata:
labels:
component: postgres
spec:
containers:
- name: postgres
image: fhsinchy/notes-postgres
ports:
- containerPort: 5432
env:
- name: POSTGRES_PASSWORD
value: 63eaQB9wtLqmNBpg
- name: POSTGRES_DB
value: notesdbإذا كنت تستخدم جهاز Raspberry Pi، فاستخدم raed667/notes-postgres بدلاً من fhsinchy/notes-postgres كصورة. التكوين نفسه مشابه جدًا للتكوين السابق. لن أشرح كل شيء في هذا الملف – نأمل أن تفهمه بنفسك بالمعرفة التي اكتسبتها من هذا المقال حتى الآن. يعمل PostgreSQL على المنفذ 5432 بشكل افتراضي، ومتغير POSTGRES_PASSWORD مطلوب لتشغيل حاوية postgres. سيتم استخدام كلمة المرور هذه أيضًا للاتصال بقاعدة البيانات هذه بواسطة واجهة برمجة التطبيقات. متغير POSTGRES_DB اختياري. ولكن بسبب طريقة هيكلة هذا المشروع، فهو ضروري هنا – وإلا ستفشل التهيئة. يمكنك معرفة المزيد عن صورة Docker الرسمية لـ postgres من صفحتهم على Docker Hub. لغرض التبسيط، سأبقي عدد النسخ المتماثلة على 1 في هذا المشروع. لتطبيق هذا الملف، نفذ الأمر التالي:
kubectl apply -f postgres-deployment.yaml
# deployment.apps/postgres-deployment createdاستخدم الأمر get للتأكد من أن النشر والـ pods تعمل بشكل صحيح:
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# postgres-deployment 1/1 1 1 13m
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# postgres-deployment-76fcc75998-mwnb7 1/1 Running 0 13mعلى الرغم من أن النشر والـ pods تعمل بشكل صحيح، إلا أن هناك مشكلة كبيرة في نشر قاعدة البيانات. إذا كنت قد عملت مع أي نظام قاعدة بيانات من قبل، فقد تعرف بالفعل أن قواعد البيانات تخزن البيانات في نظام الملفات. في الوقت الحالي، يبدو نشر قاعدة البيانات كالتالي:

حاوية postgres مغلفة بـ pod. أي بيانات يتم حفظها تبقى داخل نظام الملفات الداخلي للحاوية. الآن، إذا تعطلت الحاوية لأي سبب، أو تعطل الـ pod الذي يغلف الحاوية، فستفقد جميع البيانات المخزنة داخل نظام الملفات. عند التعطل، سيقوم Kubernetes بإنشاء pod جديد للحفاظ على الحالة المطلوبة، ولكن لا توجد آلية لنقل البيانات بين الـ pods على الإطلاق. لحل هذه المشكلة، يمكنك تخزين البيانات في مساحة منفصلة خارج الـ pod داخل المجموعة.

تُعد إدارة مثل هذا التخزين مشكلة مميزة عن إدارة مثيلات الحوسبة. يوفر النظام الفرعي PersistentVolume في Kubernetes واجهة برمجة تطبيقات للمستخدمين والمسؤولين تجرد تفاصيل كيفية توفير التخزين من كيفية استهلاكه.
وحدات التخزين المستمرة (Persistent Volumes) ومطالبات وحدات التخزين المستمرة (Persistent Volume Claims)
وفقًا لوثائق Kubernetes الرسمية، «PersistentVolume (PV) هو جزء من التخزين في المجموعة تم توفيره بواسطة مسؤول أو تم توفيره ديناميكيًا باستخدام StorageClass. إنه مورد في المجموعة تمامًا مثل العقدة مورد في المجموعة.» وهذا يعني أساسًا أن PersistentVolume هو طريقة لأخذ شريحة من مساحة التخزين الخاصة بك وحجزها لـ pod معين. يتم استهلاك وحدات التخزين دائمًا بواسطة الـ pods وليس بواسطة كائن عالي المستوى مثل الـ deployment. إذا كنت ترغب في استخدام وحدة تخزين مع deployment يحتوي على عدة pods، فسيتعين عليك المرور ببعض الخطوات الإضافية.
أنشئ ملفًا جديدًا باسم database-persistent-volume.yaml داخل دليل k8s وضع المحتوى التالي في هذا الملف:
apiVersion: v1
kind: PersistentVolume
metadata:
name: database-persistent-volume
spec:
storageClassName: manual
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"تخدم حقول apiVersion و kind و metadata نفس الغرض كما في أي ملف تكوين آخر. ومع ذلك، يحتوي حقل spec على بعض الحقول الجديدة.
spec.storageClassName: يشير إلى اسم الفئة لوحدة التخزين هذه. لنفترض أن مزود خدمة سحابية لديه ثلاثة أنواع من التخزين المتاحة. يمكن أن تكون هذه الأنواعslowوfastوvery fast. سيعتمد نوع التخزين الذي تحصل عليه من المزود على المبلغ الذي تدفعه. إذا طلبت تخزينًا سريعًا جدًا، فسيتعين عليك دفع المزيد. هذه الأنواع المختلفة من التخزين هي الفئات. أنا أستخدمmanualكمثال هنا. يمكنك استخدام ما تريد في مجموعتك المحلية.spec.capacity.storage: هو مقدار التخزين الذي ستحتوي عليه وحدة التخزين هذه. أنا أمنحه 5 جيجابايت من التخزين في هذا المشروع.spec.accessModes: يحدد وضع الوصول لوحدة التخزين. هناك ثلاثة أوضاع وصول ممكنة.ReadWriteOnceيعني أنه يمكن تحميل وحدة التخزين للقراءة والكتابة بواسطة عقدة واحدة.ReadWriteMany، من ناحية أخرى، يعني أنه يمكن تحميل وحدة التخزين للقراءة والكتابة بواسطة العديد من العقد.ReadOnlyManyيعني أنه يمكن تحميل وحدة التخزين للقراءة فقط بواسطة العديد من العقد.spec.hostPath: هو شيء خاص بالتطوير. يشير إلى الدليل في مجموعتك المحلية ذات العقدة الواحدة الذي سيتم التعامل معه كوحدة تخزين مستمرة./mnt/dataيعني أن البيانات المحفوظة في وحدة التخزين المستمرة هذه ستعيش داخل دليل/mnt/dataفي المجموعة.
لتطبيق هذا الملف، نفذ الأمر التالي:
kubectl apply -f database-persistent-volume.yaml
# persistentvolume/database-persistent-volume createdالآن استخدم الأمر get للتحقق من إنشاء وحدة التخزين:
kubectl get persistentvolume
# NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
# database-persistent-volume 5Gi RWO Retain Available manual 58sالآن بعد إنشاء وحدة التخزين المستمرة، تحتاج إلى طريقة للسماح لـ pod قاعدة البيانات بالوصول إليها. هذا هو المكان الذي يأتي فيه PersistentVolumeClaim (PVC). PersistentVolumeClaim هو طلب تخزين بواسطة pod. لنفترض أن لديك عددًا كبيرًا من وحدات التخزين في مجموعة. سيحدد هذا الطلب الخصائص التي يجب أن تفي بها وحدة التخزين لتكون قادرة على تلبية احتياجات الـ pods. مثال واقعي يمكن أن يكون شراء قرص SSD من متجر. تذهب إلى المتجر ويعرض عليك البائع النماذج التالية:
| النموذج 1 | النموذج 2 | النموذج 3 |
|---|---|---|
| 128 جيجابايت | 256 جيجابايت | 512 جيجابايت |
SATA |
NVME |
SATA |
الآن، أنت تطلب نموذجًا بسعة تخزين لا تقل عن 200 جيجابايت ويكون من نوع NVME. الأول أقل من 200 جيجابايت وهو SATA، لذا لا يتطابق مع طلبك. الثالث أكثر من 200 جيجابايت، لكنه ليس NVME. الثاني، ومع ذلك، أكثر من 200 جيجابايت وهو أيضًا NVME. لذا هذا هو ما تحصل عليه. نماذج SSD التي عرضها عليك البائع تعادل وحدات التخزين المستمرة، ومتطلباتك تعادل مطالبات وحدات التخزين المستمرة.
أنشئ ملفًا جديدًا آخر باسم database-persistent-volume-claim.yaml داخل دليل k8s وضع المحتوى التالي في هذا الملف:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: database-persistent-volume-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Giمرة أخرى، تخدم حقول apiVersion و kind و metadata نفس الغرض كما في أي ملف تكوين آخر. يشير spec.storageClass في ملف تكوين المطالبة إلى نوع التخزين الذي تريده هذه المطالبة. هذا يعني أن أي PersistentVolume يحتوي على spec.storageClass مضبوطًا على manual مناسب للاستهلاك بواسطة هذه المطالبة. إذا كان لديك وحدات تخزين متعددة بفئة manual، فستحصل المطالبة على أي منها، وإذا لم يكن لديك أي وحدة تخزين بفئة manual، فسيتم توفير وحدة تخزين ديناميكيًا.
يحدد spec.accessModes مرة أخرى وضع الوصول هنا. يشير هذا إلى أن هذه المطالبة تريد تخزينًا له accessMode من نوع ReadWriteOnce. لنفترض أن لديك وحدتي تخزين مع ضبط الفئة على manual. إحداهما لديها accessModes مضبوطًا على ReadWriteOnce والأخرى على ReadWriteMany. ستحصل هذه المطالبة على تلك التي لديها ReadWriteOnce.
resources.requests.storage هو مقدار التخزين الذي تريده هذه المطالبة. 2Gi لا يعني أن وحدة التخزين المعطاة يجب أن تحتوي على سعة تخزين 2 جيجابايت بالضبط. بل يعني أنها يجب أن تحتوي على 2 جيجابايت على الأقل. آمل أن تتذكر أنك قمت بتعيين سعة وحدة التخزين المستمرة لتكون 5 جيجابايت، وهي أكثر من 2 جيجابايت. لتطبيق هذا الملف، نفذ الأمر التالي:
kubectl apply -f database-persistent-volume-claim.yaml
# persistentvolumeclaim/database-persistent-volume-claim createdالآن استخدم الأمر get للتحقق من إنشاء وحدة التخزين:
kubectl get persistentvolumeclaim
# NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
# database-persistent-volume-claim Bound database-persistent-volume 5Gi RWO manual 37sانظر إلى عمود VOLUME. هذه المطالبة مرتبطة بوحدة التخزين المستمرة database-persistent-volume التي أنشأتها سابقًا. انظر أيضًا إلى CAPACITY. إنها 5Gi، لأن المطالبة طلبت وحدة تخزين بسعة تخزين 2 جيجابايت على الأقل.
التوفير الديناميكي لوحدات التخزين المستمرة
في القسم الفرعي السابق، قمت بإنشاء وحدة تخزين مستمرة ثم أنشأت مطالبة. ولكن، ماذا لو لم تكن هناك أي وحدة تخزين مستمرة تم توفيرها مسبقًا؟ في مثل هذه الحالات، سيتم توفير وحدة تخزين مستمرة متوافقة مع المطالبة تلقائيًا. لبدء هذا العرض التوضيحي، قم بإزالة وحدة التخزين المستمرة ومطالبة وحدة التخزين المستمرة التي تم إنشاؤها مسبقًا باستخدام الأوامر التالية:
kubectl delete persistentvolumeclaim --all
# persistentvolumeclaim "database-persistent-volume-claim" deleted
kubectl delete persistentvolume --all
# persistentvolume "database-persistent-volume" deletedافتح ملف database-persistent-volume-claim.yaml وحدث محتواه ليكون كالتالي:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: database-persistent-volume-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Giلقد أزلت حقل spec.storageClass من الملف. الآن أعد تطبيق ملف database-persistent-volume-claim.yaml دون تطبيق ملف database-persistent-volume.yaml:
kubectl apply -f database-persistent-volume-claim.yaml
# persistentvolumeclaim/database-persistent-volume-claim createdالآن استخدم الأمر get للنظر في معلومات المطالبة:
kubectl get persistentvolumeclaim
# NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
# database-persistent-volume-claim Bound pvc-525ae8af-00d3-4cc7-ae47-866aa13dffd5 2Gi RWO standard 2sكما ترى، تم توفير وحدة تخزين باسم pvc-525ae8af-00d3-4cc7-ae47-866aa13dffd5 وسعة تخزين 2Gi وربطها بالمطالبة ديناميكيًا. يمكنك استخدام وحدة تخزين مستمرة ثابتة أو ديناميكية التوفير لبقية هذا المشروع. سأستخدم واحدة تم توفيرها ديناميكيًا.
ربط وحدات التخزين مع الـ Pods
الآن بعد أن أنشأت وحدة تخزين مستمرة ومطالبة، حان الوقت للسماح لـ pod قاعدة البيانات باستخدام وحدة التخزين هذه. يمكنك القيام بذلك عن طريق ربط الـ pod بمطالبة وحدة التخزين المستمرة التي أنشأتها في القسم الفرعي السابق. افتح ملف postgres-deployment.yaml وحدث محتواه ليكون كالتالي:
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
spec:
replicas: 1
selector:
matchLabels:
component: postgres
template:
metadata:
labels:
component: postgres
spec:
# volume configuration for the pod
volumes:
- name: postgres-storage
persistentVolumeClaim:
claimName: database-persistent-volume-claim
containers:
- name: postgres
image: fhsinchy/notes-postgres
ports:
- containerPort: 5432
# volume mounting configuration for the container
volumeMounts:
- name: postgres-storage
mountPath: /var/lib/postgresql/data
subPath: postgres
env:
- name: POSTGRES_PASSWORD
value: 63eaQB9wtLqmNBpg
- name: POSTGRES_DB
value: notesdbلقد أضفت حقلين جديدين في ملف التكوين هذا. يحتوي حقل spec.volumes على المعلومات الضرورية لكي يجد الـ pod مطالبة وحدة التخزين المستمرة. يمكن أن يكون spec.volumes.name أي شيء تريده. يجب أن يتطابق spec.volumes.persistentVolumeClaim.claimName مع قيمة metadata.name من ملف database-persistent-volume-claim.yaml.
يحتوي containers.volumeMounts على المعلومات الضرورية لتركيب وحدة التخزين داخل الحاوية. يجب أن يتطابق containers.volumeMounts.name مع القيمة من spec.volumes.name. يشير containers.volumeMounts.mountPath إلى الدليل الذي سيتم تركيب وحدة التخزين فيه. /var/lib/postgresql/data هو دليل البيانات الافتراضي لـ PostgreSQL. يشير containers.volumeMounts.subPath إلى دليل سيتم إنشاؤه داخل وحدة التخزين. لنفترض أنك تستخدم نفس وحدة التخزين مع pods أخرى أيضًا. في هذه الحالة، يمكنك وضع البيانات الخاصة بالـ pod داخل دليل آخر داخل وحدة التخزين هذه. ستذهب جميع البيانات المحفوظة داخل دليل /var/lib/postgresql/data داخل دليل postgres داخل وحدة التخزين.
الآن أعد تطبيق ملف postgres-deployment.yaml بتنفيذ الأمر التالي:
kubectl apply -f postgres-deployment.yaml
# deployment.apps/postgres-deployment configuredالآن لديك نشر قاعدة بيانات صحيح مع مخاطر أقل بكثير لفقدان البيانات. شيء واحد أود ذكره هنا هو أن نشر قاعدة البيانات في هذا المشروع يحتوي على نسخة متماثلة واحدة فقط. إذا كان هناك أكثر من نسخة متماثلة واحدة، لكانت الأمور مختلفة. يمكن أن يؤدي وصول عدة pods إلى نفس وحدة التخزين دون علم بعضها البعض إلى نتائج كارثية. في مثل هذه الحالات، قد يكون إنشاء أدلة فرعية للـ pods داخل وحدة التخزين فكرة جيدة.
ربط كل شيء معًا
الآن بعد أن أصبحت واجهة برمجة التطبيقات وقاعدة البيانات تعملان، حان الوقت لإنهاء بعض الأعمال غير المكتملة وإعداد الشبكات. لقد تعلمت بالفعل في الأقسام السابقة أنه لإعداد الشبكات في Kubernetes، تستخدم الخدمات. قبل البدء في كتابة الخدمات، ألقِ نظرة على خطة الشبكات التي لدي لهذا المشروع.

- سيتم كشف قاعدة البيانات فقط داخل المجموعة باستخدام خدمة
ClusterIP. لن يُسمح بحركة المرور الخارجية. - نشر واجهة برمجة التطبيقات، ومع ذلك، سيتم كشفه للعالم الخارجي. سيتواصل المستخدمون مع واجهة برمجة التطبيقات، وستتواصل واجهة برمجة التطبيقات مع قاعدة البيانات.
لقد عملت سابقًا مع خدمة LoadBalancer التي تكشف تطبيقًا للعالم الخارجي. أما ClusterIP، من ناحية أخرى، فيكشف تطبيقًا داخل المجموعة ولا يسمح بحركة المرور الخارجية.

نظرًا لأن خدمة قاعدة البيانات يجب أن تكون متاحة فقط داخل المجموعة، فإن خدمة ClusterIP هي الأنسب لهذا السيناريو. أنشئ ملفًا جديدًا باسم postgres-cluster-ip-service.yaml داخل دليل k8s وضع المحتوى التالي فيه:
apiVersion: v1
kind: Service
metadata:
name: postgres-cluster-ip-service
spec:
type: ClusterIP
selector:
component: postgres
ports:
- port: 5432
targetPort: 5432كما ترى، ملف التكوين لـ ClusterIP مطابق لملف LoadBalancer. الشيء الوحيد الذي يختلف هو قيمة spec.type. يجب أن تكون قادرًا على تفسير هذا الملف دون أي مشكلة الآن. 5432 هو المنفذ الافتراضي الذي يعمل عليه PostgreSQL. لهذا السبب يجب كشف هذا المنفذ. ملف التكوين التالي هو لخدمة LoadBalancer، المسؤولة عن كشف واجهة برمجة التطبيقات للعالم الخارجي. أنشئ ملفًا آخر باسم api-load-balancer-service.yaml وضع المحتوى التالي فيه:
apiVersion: v1
kind: Service
metadata:
name: api-load-balancer-service
spec:
type: LoadBalancer
ports:
- port: 3000
targetPort: 3000
selector:
component: apiهذا التكوين مطابق للتكوين الذي كتبته في قسم سابق. تعمل واجهة برمجة التطبيقات على المنفذ 3000 داخل الحاوية وهذا هو السبب في ضرورة كشف هذا المنفذ. آخر شيء يجب فعله هو إضافة بقية متغيرات البيئة إلى نشر واجهة برمجة التطبيقات. لذا افتح ملف api-deployment.yaml وحدث محتواه كالتالي:
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
env:
- name: DB_CONNECTION
value: pg
- name: DB_HOST
value: postgres-cluster-ip-service
- name: DB_PORT
value: '5432'
- name: DB_USER
value: postgres
- name: DB_DATABASE
value: notesdb
- name: DB_PASSWORD
value: 63eaQB9wtLqmNBpgفي السابق، كان هناك فقط متغير DB_CONNECTION تحت spec.containers.env. المتغيرات الجديدة هي كالتالي:
DB_HOST: يشير إلى عنوان المضيف لخدمة قاعدة البيانات. في بيئة غير محوسبة، تكون القيمة عادةً127.0.0.1. ولكن في بيئةKubernetes، لا تعرف عنوانIPلـpodقاعدة البيانات. وبالتالي، تستخدم فقط اسم الخدمة التي تكشف قاعدة البيانات بدلاً من ذلك.DB_PORT: هو المنفذ المكشوف من خدمة قاعدة البيانات، وهو5432.DB_USER: هو المستخدم للاتصال بقاعدة البيانات.postgresهو اسم المستخدم الافتراضي.DB_DATABASE: هي قاعدة البيانات التي ستتصل بها واجهة برمجة التطبيقات. يجب أن يتطابق هذا مع قيمةspec.containers.env.DB_DATABASEمن ملفpostgres-deployment.yaml.DB_PASSWORD: هي كلمة المرور للاتصال بقاعدة البيانات. يجب أن يتطابق هذا مع قيمةspec.containers.env.DB_PASSWORDمن ملفpostgres-deployment.yaml.
مع الانتهاء من ذلك، أنت الآن جاهز لاختبار واجهة برمجة التطبيقات. قبل القيام بذلك، أقترح تطبيق جميع ملفات التكوين مرة أخرى بتنفيذ الأمر التالي:
kubectl apply -f k8s
# deployment.apps/api-deployment created
# service/api-load-balancer-service created
# persistentvolumeclaim/database-persistent-volume-claim created
# service/postgres-cluster-ip-service created
# deployment.apps/postgres-deployment createdإذا واجهت أي أخطاء، فما عليك سوى حذف جميع الموارد وإعادة تطبيق الملفات. يجب إنشاء الخدمات ووحدات التخزين المستمرة ومطالبات وحدات التخزين المستمرة على الفور. استخدم الأمر get للتأكد من أن عمليات النشر تعمل جميعها:
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 3/3 3 3 106s
# postgres-deployment 1/1 1 1 106sكما ترى من عمود READY، جميع الـ pods قيد التشغيل. للوصول إلى واجهة برمجة التطبيقات، استخدم الأمر service لـ minikube.
minikube service api-load-balancer-service
# |-----------|---------------------------|-------------|-----------------------------|
# | NAMESPACE | NAME | TARGET PORT | URL |
# |-----------|---------------------------|-------------|-----------------------------|
# | default | api-load-balancer-service | 3000 | http://172.19.186.112:31546 |
# |-----------|---------------------------|-------------|-----------------------------|
# * Opening service default/api-load-balancer-service in default browser...يجب أن تفتح واجهة برمجة التطبيقات تلقائيًا في متصفحك الافتراضي:

هذه هي الاستجابة الافتراضية لواجهة برمجة التطبيقات. يمكنك أيضًا استخدام http://172.19.186.112:31546/ مع أداة اختبار واجهة برمجة التطبيقات مثل Insomnia أو Postman لاختبار واجهة برمجة التطبيقات. تحتوي واجهة برمجة التطبيقات على وظائف CRUD كاملة. يمكنك رؤية الاختبارات التي تأتي مع كود مصدر واجهة برمجة التطبيقات كوثائق. ما عليك سوى فتح ملف api/tests/e2e/api/routes/notes.test.js. يجب أن تكون قادرًا على فهم الملف دون عناء كبير إذا كان لديك خبرة في JavaScript و Express.
العمل مع وحدات التحكم بالـ Ingress
حتى الآن في هذا المقال، استخدمت ClusterIP لكشف تطبيق داخل المجموعة و LoadBalancer لكشف تطبيق خارج المجموعة. على الرغم من أنني ذكرت LoadBalancer كنوع الخدمة القياسي لكشف تطبيق خارج المجموعة، إلا أن له بعض السلبيات. عند استخدام خدمات LoadBalancer لكشف التطبيقات في بيئة سحابية، سيتعين عليك الدفع مقابل كل خدمة مكشوفة على حدة، مما قد يكون مكلفًا في المشاريع الضخمة.
يوجد نوع آخر من الخدمات يسمى NodePort يمكن استخدامه كبديل لخدمات LoadBalancer.

يفتح NodePort منفذًا محددًا على جميع العقد في مجموعتك، ويتعامل مع أي حركة مرور تأتي عبر هذا المنفذ المفتوح. كما تعلم بالفعل، تجمع الخدمات عددًا من الـ pods، وتتحكم في طريقة الوصول إليها. لذا، فإن أي طلب يصل إلى الخدمة عبر المنفذ المكشوف سينتهي به المطاف في الـ pod الصحيح. يمكن أن يكون ملف التكوين المثال لإنشاء NodePort كالتالي:
apiVersion: v1
kind: Service
metadata:
name: hello-kube-node-port
spec:
type: NodePort
ports:
- port: 8080
targetPort: 8080
nodePort: 31515
selector:
component: webيجب أن تكون قيمة حقل spec.ports.nodePort هنا بين 30000 و 32767. هذا النطاق خارج المنافذ المعروفة التي تستخدمها عادةً الخدمات المختلفة، ولكنه أيضًا غير عادي. أعني، كم مرة ترى منفذًا به الكثير من الأرقام؟ يمكنك محاولة استبدال خدمات LoadBalancer التي أنشأتها في الأقسام السابقة بخدمة NodePort. لا ينبغي أن يكون هذا صعبًا ويمكن اعتباره اختبارًا لما تعلمته حتى الآن.
لحل المشكلات التي ذكرتها، تم إنشاء واجهة برمجة تطبيقات Ingress. لكي نكون واضحين جدًا، Ingress ليس نوعًا من الخدمات في الواقع. بدلاً من ذلك، فإنه يجلس أمام خدمات متعددة ويعمل كنوع من الموجه (router). يلزم وجود IngressController للعمل مع موارد Ingress في مجموعتك. يمكن العثور على قائمة بوحدات التحكم بالـ ingress المتاحة في وثائق Kubernetes.
إعداد وحدة التحكم بـ NGINX Ingress
في هذا المثال، ستقوم بتوسيع واجهة برمجة تطبيقات الملاحظات عن طريق إضافة واجهة أمامية (front end) إليها. وبدلاً من استخدام خدمة مثل LoadBalancer أو NodePort، ستستخدم Ingress لكشف التطبيق. وحدة التحكم التي ستستخدمها هي NGINX Ingress Controller لأن NGINX سيُستخدم لتوجيه الطلبات إلى خدمات مختلفة هنا. يجعل NGINX Ingress Controller العمل مع تكوينات NGINX في مجموعة Kubernetes سهلاً للغاية.
يوجد كود المشروع داخل دليل fullstack-notes-application.
.
├── api
├── client
├── docker-compose.yaml
├── k8s
│ ├── api-deployment.yaml
│ ├── database-persistent-volume-claim.yaml
│ ├── postgres-cluster-ip-service.yaml
│ └── postgres-deployment.yaml
├── nginx
└── postgres
5 directories, 1 fileسترى دليل k8s هناك. يحتوي على جميع ملفات التكوين التي كتبتها في القسم الفرعي الأخير، باستثناء ملف api-load-balancer-service.yaml. والسبب في ذلك هو أنه في هذا المشروع، سيتم استبدال خدمة LoadBalancer القديمة بـ Ingress. أيضًا، بدلاً من كشف واجهة برمجة التطبيقات، ستقوم بكشف تطبيق الواجهة الأمامية للعالم. قبل البدء في كتابة ملفات التكوين الجديدة، ألقِ نظرة على كيفية عمل الأمور خلف الكواليس.

يزور المستخدم تطبيق الواجهة الأمامية ويقدم البيانات الضرورية. ثم يقوم تطبيق الواجهة الأمامية بإعادة توجيه البيانات المقدمة إلى واجهة برمجة التطبيقات الخلفية. ثم تقوم واجهة برمجة التطبيقات بحفظ البيانات في قاعدة البيانات وإرسالها مرة أخرى إلى تطبيق الواجهة الأمامية. ثم يتم تحقيق توجيه الطلبات باستخدام NGINX. يمكنك إلقاء نظرة على ملف nginx/production.conf لفهم كيفية إعداد هذا التوجيه. الآن الشبكات الضرورية لجعل هذا يحدث هي كالتالي:

يمكن شرح هذا الرسم البياني كالتالي:
- سيعمل
Ingressكنقطة دخول وموجه لهذا التطبيق. هذاIngressمن نوعNGINX، لذا سيكون المنفذ هو منفذnginxالافتراضي وهو80. - سيتم توجيه كل طلب يأتي إلى
/نحو تطبيق الواجهة الأمامية (الخدمة على اليسار). لذا إذا كان عنوانURLلهذا التطبيق هوhttps://kube-notes.test، فإن أي طلب يأتي إلىhttps://kube-notes.test/fooأوhttps://kube-notes.test/barسيتعامل معه تطبيق الواجهة الأمامية. - سيتم توجيه كل طلب يأتي إلى
/apiنحو واجهة برمجة التطبيقات الخلفية (الخدمة على اليمين). لذا إذا كان عنوانURLمرة أخرى هوhttps://kube-notes.test، فإن أي طلب يأتي إلىhttps://kube-notes.test/api/fooأوhttps://kube-notes.test/api/barسيتعامل معه واجهة برمجة التطبيقات الخلفية.
كان من الممكن تمامًا تكوين خدمة Ingress للعمل مع النطاقات الفرعية بدلاً من المسارات مثل هذه، لكنني اخترت النهج القائم على المسار لأن هذا هو كيفية تصميم تطبيقي. في هذا القسم الفرعي، سيتعين عليك كتابة أربعة ملفات تكوين جديدة:
- تكوين
ClusterIPلنشر واجهة برمجة التطبيقات. - تكوين
Deploymentلتطبيق الواجهة الأمامية. - تكوين
ClusterIPلتطبيق الواجهة الأمامية. - تكوين
Ingressللتوجيه.
سأمر على الملفات الثلاثة الأولى بسرعة كبيرة دون قضاء الكثير من الوقت في شرحها. الأول هو تكوين api-cluster-ip-service.yaml ومحتويات الملف هي كالتالي:
apiVersion: v1
kind: Service
metadata:
name: api-cluster-ip-service
spec:
type: ClusterIP
selector:
component: api
ports:
- port: 3000
targetPort: 3000على الرغم من أنك في القسم الفرعي السابق كشفت واجهة برمجة التطبيقات مباشرة إلى العالم الخارجي، إلا أنك في هذا القسم ستدع Ingress يقوم بالعمل الشاق بينما تكشف واجهة برمجة التطبيقات داخليًا باستخدام خدمة ClusterIP القديمة الجيدة. يجب أن يكون التكوين نفسه واضحًا بذاته في هذه المرحلة، لذا لن أقضي أي وقت في شرحه.
بعد ذلك، أنشئ ملفًا باسم client-deployment.yaml مسؤولاً عن تشغيل تطبيق الواجهة الأمامية. محتويات الملف هي كالتالي:
apiVersion: apps/v1
kind: Deployment
metadata:
name: client-deployment
spec:
replicas: 3
selector:
matchLabels:
component: client
template:
metadata:
labels:
component: client
spec:
containers:
- name: client
image: fhsinchy/notes-client
ports:
- containerPort: 8080
env:
- name: VUE_APP_API_URL
value: /apiإنه مطابق تقريبًا لملف api-deployment.yaml وأفترض أنك ستكون قادرًا على تفسير ملف التكوين هذا بنفسك. يشير متغير البيئة VUE_APP_API_URL هنا إلى المسار الذي يجب إعادة توجيه طلبات واجهة برمجة التطبيقات إليه. ستتعامل Ingress بدورها مع هذه الطلبات المعاد توجيهها. لكشف تطبيق العميل هذا داخليًا، يلزم وجود خدمة ClusterIP أخرى. أنشئ ملفًا جديدًا باسم client-cluster-ip-service.yaml وضع المحتوى التالي فيه:
apiVersion: v1
kind: Service
metadata:
name: client-cluster-ip-service
spec:
type: ClusterIP
selector:
component: client
ports:
- port: 8080
targetPort: 8080كل ما يفعله هذا هو كشف المنفذ 8080 داخل المجموعة الذي يعمل عليه تطبيق الواجهة الأمامية بشكل افتراضي. الآن بعد الانتهاء من التكوينات القديمة المملة، فإن التكوين التالي هو ملف ingress-service.yaml ومحتوى الملف هو كالتالي:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-service
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /$1
spec:
rules:
- http:
paths:
- pathType: Prefix
path: "/?(.*)"
backend:
service:
name: client-cluster-ip-service
port:
number: 8080
- pathType: Prefix
path: "/api/?(.*)"
backend:
service:
name: api-cluster-ip-service
port:
number: 3000قد يبدو ملف التكوين هذا غير مألوف بعض الشيء بالنسبة لك ولكنه في الواقع مباشر تمامًا. لا تزال واجهة برمجة تطبيقات Ingress في مرحلة البيتا، وبالتالي فإن apiVersion هو networking.k8s.io/v1 (ملاحظة: النص الأصلي ذكر extensions/v1 ولكن networking.k8s.io/v1 هو الإصدار المستقر الحالي). تخدم حقلا kind و metadata.name نفس الغرض كما في أي من التكوينات التي كتبتها سابقًا. يمكن أن تحتوي metadata.annotations على معلومات بخصوص تكوين Ingress. يشير kubernetes.io/ingress.class: nginx إلى أن كائن Ingress يجب أن تتحكم فيه وحدة التحكم ingress-nginx. يشير nginx.ingress.kubernetes.io/rewrite-target إلى أنك تريد إعادة كتابة هدف URL في أماكن. يحتوي spec.rules.http.paths على تكوين بخصوص توجيهات المسار الفردية التي رأيتها سابقًا داخل ملف nginx/production.conf. يتوافق paths.pathType مع نوع المسار. بشكل افتراضي هو Prefix في NGINX. يشير حقل paths.path إلى المسار الذي يجب توجيهه. backend.service.name هي الخدمة التي يجب توجيه المسار المذكور إليها و backend.service.port.number هو المنفذ المستهدف داخل تلك الخدمة. /?(.*) و /api/?(.*) هي تعبيرات منتظمة بسيطة تعني أن جزء ?(.*) سيتم توجيهه نحو الخدمات المعينة. يمكن أن تتغير طريقة تكوين إعادة الكتابة من وقت لآخر، لذا فإن التحقق من الوثائق الرسمية سيكون فكرة جيدة.
قبل تطبيق التكوينات الجديدة، سيتعين عليك تفعيل إضافة ingress لـ minikube باستخدام الأمر addons. الصيغة العامة هي كالتالي:
minikube addons <option> <addon name>لتفعيل إضافة ingress، نفذ الأمر التالي:
minikube addons enable ingress
# ? Verifying ingress addon...
# ? The 'ingress' addon is enabledيمكنك استخدام خيار disable لأمر addon لتعطيل أي إضافة. يمكنك معرفة المزيد عن أمر addon في الوثائق الرسمية. بمجرد تفعيل الإضافة، يمكنك تطبيق ملفات التكوين. أقترح حذف جميع الموارد (الخدمات، عمليات النشر، ومطالبات وحدات التخزين المستمرة) قبل تطبيق الموارد الجديدة.
kubectl delete ingress --all
# ingress.networking.k8s.io "ingress-service" deleted
kubectl delete service --all
# service "api-cluster-ip-service" deleted
# service "client-cluster-ip-service" deleted
# service "kubernetes" deleted
# service "postgres-cluster-ip-service" deleted
kubectl delete deployment --all
# deployment.apps "api-deployment" deleted
# deployment.apps "client-deployment" deleted
# deployment.apps "postgres-deployment" deleted
kubectl delete persistentvolumeclaim --all
# persistentvolumeclaim "database-persistent-volume-claim" deleted
kubectl apply -f k8s
# service/api-cluster-ip-service created
# deployment.apps/api-deployment created
# service/client-cluster-ip-service created
# deployment.apps/client-deployment created
# persistentvolumeclaim/database-persistent-volume-claim created
# ingress.networking.k8s.io/ingress-service created
# service/postgres-cluster-ip-service created
# deployment.apps/postgres-deployment createdانتظر حتى يتم إنشاء جميع الموارد. يمكنك استخدام الأمر get للتأكد من ذلك. بمجرد تشغيل جميعها، يمكنك الوصول إلى التطبيق على عنوان IP لمجموعة minikube. للحصول على عنوان IP، يمكنك تنفيذ الأمر التالي:
minikube ip
# 172.17.0.2يمكنك أيضًا الحصول على عنوان IP هذا عن طريق فحص Ingress:
kubectl get ingress
# NAME CLASS HOSTS ADDRESS PORTS AGE
# ingress-service <none> * 172.17.0.2 80 2m33sكما ترى، عنوان IP والمنفذ مرئيان تحت عمودي ADDRESS و PORTS. بالوصول إلى 127.17.0.2:80، يجب أن تهبط مباشرة على تطبيق الملاحظات.

يمكنك إجراء عمليات CRUD بسيطة في هذا التطبيق. المنفذ 80 هو المنفذ الافتراضي لـ NGINX، لذا لا تحتاج إلى كتابة رقم المنفذ في عنوان URL. يمكنك فعل الكثير باستخدام وحدة التحكم بالـ ingress هذه إذا كنت تعرف كيفية تكوين NGINX. بعد كل شيء، هذا هو الغرض من وحدة التحكم هذه – تخزين تكوينات NGINX على ConfigMap في Kubernetes، والذي ستتعلم عنه في القسم الفرعي التالي.
الـ Secrets والـ Config Maps في Kubernetes
حتى الآن في عمليات النشر الخاصة بك، قمت بتخزين معلومات حساسة مثل POSTGRES_PASSWORD كنص عادي، وهي ليست فكرة جيدة جدًا. لتخزين مثل هذه القيم في مجموعتك، يمكنك استخدام Secret وهي طريقة أكثر أمانًا لتخزين كلمات المرور والرموز المميزة وما إلى ذلك. قد لا تعمل الخطوة التالية بنفس الطريقة في سطر أوامر Windows. يمكنك استخدام git bash أو cmder للمهمة. لتخزين المعلومات في Secret، يجب عليك أولاً تمرير بياناتك عبر base64. إذا كانت كلمة المرور النصية العادية هي 63eaQB9wtLqmNBpg، فنفذ الأمر التالي للحصول على نسخة مشفرة بـ base64:
echo -n "63eaQB9wtLqmNBpg" | base64
# NjNlYVFCOXd0THFtTkJwZw==هذه الخطوة ليست اختيارية، يجب عليك تشغيل السلسلة النصية العادية عبر base64. الآن أنشئ ملفًا باسم postgres-secret.yaml داخل دليل k8s وضع المحتوى التالي فيه:
apiVersion: v1
kind: Secret
metadata:
name: postgres-secret
data:
password: NjNlYVFCOXd0THFtTkJwZw==تعتبر حقول apiVersion و kind و metadata واضحة بذاتها. يحتوي حقل data على السر الفعلي. كما ترى، لقد أنشأت زوجًا من المفتاح والقيمة حيث المفتاح هو password والقيمة هي NjNlYVFCOXd0THFtTkJwZw==. ستستخدم قيمة metadata.name لتحديد هذا الـ Secret في ملفات التكوين الأخرى والمفتاح للوصول إلى قيمة كلمة المرور. الآن لاستخدام هذا السر داخل تكوين قاعدة البيانات الخاصة بك، حدث ملف postgres-deployment.yaml كالتالي:
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
spec:
replicas: 1
selector:
matchLabels:
component: postgres
template:
metadata:
labels:
component: postgres
spec:
volumes:
- name: postgres-storage
persistentVolumeClaim:
claimName: database-persistent-volume-claim
containers:
- name: postgres
image: fhsinchy/notes-postgres
ports:
- containerPort: 5432
volumeMounts:
- name: postgres-storage
mountPath: /var/lib/postgresql/data
subPath: postgres
env:
# not putting the password directly anymore
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: password
- name: POSTGRES_DB
value: notesdbكما ترى، الملف بأكمله هو نفسه باستثناء حقل spec.template.spec.containers.env. كان متغير البيئة name المستخدم لتخزين قيمة كلمة المرور نصًا عاديًا من قبل. ولكن الآن يوجد حقل valueFrom.secretKeyRef جديد. يشير حقل name هنا إلى اسم الـ Secret الذي أنشأته قبل لحظات، وتشير قيمة key إلى المفتاح من زوج المفتاح والقيمة في ملف تكوين الـ Secret هذا. سيتم فك تشفير القيمة المشفرة إلى نص عادي داخليًا بواسطة Kubernetes.
بصرف النظر عن تكوين قاعدة البيانات، سيتعين عليك أيضًا تحديث ملف api-deployment.yaml كالتالي:
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
env:
- name: DB_CONNECTION
value: pg
- name: DB_HOST
value: postgres-cluster-ip-service
- name: DB_PORT
value: '5432'
- name: DB_USER
value: postgres
- name: DB_DATABASE
value: notesdb
# not putting the password directly anymore
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: passwordالآن طبق جميع هذه التكوينات الجديدة بتنفيذ الأمر التالي:
kubectl apply -f k8s
# service/api-cluster-ip-service created
# deployment.apps/api-deployment created
# service/client-cluster-ip-service created
# deployment.apps/client-deployment created
# persistentvolumeclaim/database-persistent-volume-claim created
# secret/postgres-secret created
# ingress.networking.k8s.io/ingress-service created
# service/postgres-cluster-ip-service created
# deployment.apps/postgres-deployment createdاعتمادًا على حالة مجموعتك، قد ترى مجموعة مختلفة من المخرجات. في حال واجهت أي مشكلة، احذف جميع موارد Kubernetes وأعد إنشائها عن طريق تطبيق التكوينات. استخدم الأمر get للفحص والتأكد من أن جميع الـ pods قيد التشغيل. الآن لاختبار التكوين الجديد، ادخل إلى تطبيق الملاحظات باستخدام minikube IP وحاول إنشاء ملاحظات جديدة. للحصول على عنوان IP، يمكنك تنفيذ الأمر التالي:
minikube ip
# 172.17.0.2بالوصول إلى 127.17.0.2:80، يجب أن تهبط مباشرة على تطبيق الملاحظات.

هناك طريقة أخرى لإنشاء الـ secrets بدون أي ملف تكوين. لإنشاء نفس الـ Secret باستخدام kubectl، نفذ الأمر التالي:
kubectl create secret generic postgres-secret --from-literal=password=63eaQB9wtLqmNBpg
# secret/postgres-secret createdهذا نهج أكثر ملاءمة حيث يمكنك تخطي خطوة تشفير base64 بالكامل. سيتم تشفير السر في هذه الحالة تلقائيًا. ConfigMap مشابه لـ Secret ولكنه مخصص للاستخدام مع المعلومات غير الحساسة. لوضع جميع متغيرات البيئة الأخرى في نشر واجهة برمجة التطبيقات داخل ConfigMap، أنشئ ملفًا جديدًا باسم api-config-map.yaml داخل دليل k8s وضع المحتوى التالي فيه:
apiVersion: v1
kind: ConfigMap
metadata:
name: api-config-map
data:
DB_CONNECTION: pg
DB_HOST: postgres-cluster-ip-service
DB_PORT: '5432'
DB_USER: postgres
DB_DATABASE: notesdbتعتبر حقول apiVersion و kind و metadata واضحة بذاتها مرة أخرى. يمكن أن يحتوي حقل data على متغيرات البيئة كأزواج مفتاح-قيمة. على عكس الـ Secret، يجب أن تتطابق المفاتيح هنا مع المفتاح الدقيق المطلوب بواسطة واجهة برمجة التطبيقات. وبالتالي، لقد قمت بنسخ المتغيرات من ملف api-deployment.yaml ولصقها هنا مع تعديل طفيف في الصيغة. لاستخدام هذا السر في نشر واجهة برمجة التطبيقات، افتح ملف api-deployment.yaml وحدث محتواه كالتالي:
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
# not putting environment variables directly
envFrom:
- configMapRef:
name: api-config-map
env:
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: passwordالملف بأكمله لم يتغير تقريبًا باستثناء حقل spec.template.spec.containers.env. لقد نقلت متغيرات البيئة إلى ConfigMap. يُستخدم spec.template.spec.containers.envFrom للحصول على البيانات من ConfigMap. يشير configMapRef.name هنا إلى ConfigMap الذي سيتم سحب متغيرات البيئة منه. الآن طبق جميع هذه التكوينات الجديدة بتنفيذ الأمر التالي:
kubectl apply -f k8s
# service/api-cluster-ip-service created
# configmap/api-config-map created
# deployment.apps/api-deployment created
# service/client-cluster-ip-service created
# deployment.apps/client-deployment created
# persistentvolumeclaim/database-persistent-volume-claim created
# ingress.networking.k8s.io/ingress-service configured
# service/postgres-cluster-ip-service created
# deployment.apps/postgres-deployment created
# secret/postgres-secret createdاعتمادًا على حالة مجموعتك، قد ترى مجموعة مختلفة من المخرجات. في حال واجهت أي مشكلة، احذف جميع موارد Kubernetes وأعد إنشائها عن طريق تطبيق التكوينات. بعد التأكد من أن الـ pods قيد التشغيل باستخدام الأمر get، ادخل إلى تطبيق الملاحظات باستخدام minikube IP وحاول إنشاء ملاحظات جديدة. للحصول على عنوان IP، يمكنك تنفيذ الأمر التالي:
minikube ip
# 172.17.0.2بالوصول إلى 127.17.0.2:80، يجب أن تهبط مباشرة على تطبيق الملاحظات.
يحتوي كل من Secret و ConfigMap على بعض الحيل الأخرى التي لن أتعمق فيها الآن. ولكن إذا كنت فضوليًا، يمكنك مراجعة الوثائق الرسمية.
تنفيذ عمليات طرح التحديثات في Kubernetes
الآن بعد أن قمت بنشر تطبيق يتكون من حاويات متعددة بنجاح على Kubernetes، حان الوقت للتعرف على تنفيذ التحديثات. على الرغم من أن Kubernetes قد يبدو سحريًا لك، إلا أن تحديث حاوية إلى إصدار صورة أحدث يمثل بعض الصعوبة. هناك طرق متعددة يتخذها الأشخاص غالبًا لتحديث حاوية، لكنني لن أتناولها جميعًا. بدلاً من ذلك، سأنتقل مباشرة إلى النهج الذي أتبعه غالبًا في تحديث حاوياتي. إذا فتحت ملف client-deployment.yaml ونظرت إلى حقل spec.template.spec.containers، ستجد شيئًا يبدو كالتالي:
containers:
- name: client
image: fhsinchy/notes-clientكما ترى، في حقل image لم أستخدم أي وسم (tag) للصورة. الآن إذا كنت تعتقد أن إضافة :latest في نهاية اسم الصورة سيضمن أن النشر يسحب دائمًا أحدث صورة متاحة، فستكون مخطئًا تمامًا. النهج الذي أتبعه عادة هو نهج إلزامي (imperative one). لقد ذكرت بالفعل في قسم سابق أنه في بعض الحالات، يكون استخدام نهج إلزامي بدلاً من نهج تصريحي فكرة جيدة. إنشاء Secret أو تحديث حاوية هو إحدى هذه الحالات.
الأمر الذي يمكنك استخدامه لتنفيذ التحديث هو الأمر set، والصيغة العامة هي كالتالي:
kubectl set image <resource type>/<resource name> <container name>=<image name with tag>نوع المورد هو deployment واسم المورد هو client-deployment. يمكن العثور على اسم الحاوية تحت حقل containers داخل ملف client-deployment.yaml، وهو client في هذه الحالة. لقد قمت بالفعل ببناء إصدار من صورة fhsinchy/notes-client بوسم edge سأستخدمه لتحديث هذا النشر. لذا يجب أن يكون الأمر النهائي كالتالي:
kubectl set image deployment/client-deployment client=fhsinchy/notes-client:edge
# deployment.apps/client-deployment image updatedقد تستغرق عملية التحديث بعض الوقت، حيث سيعيد Kubernetes إنشاء جميع الـ pods. يمكنك تشغيل الأمر get لمعرفة ما إذا كانت جميع الـ pods تعمل مرة أخرى. بمجرد إعادة إنشائها جميعًا، ادخل إلى تطبيق الملاحظات باستخدام minikube IP وحاول إنشاء ملاحظات جديدة. للحصول على عنوان IP، يمكنك تنفيذ الأمر التالي:
minikube ip
# 172.17.0.2بالوصول إلى 127.17.0.2:80، يجب أن تهبط مباشرة على تطبيق الملاحظات.
نظرًا لأنني لم أجرِ أي تغييرات فعلية على كود التطبيق، سيبقى كل شيء كما هو. يمكنك التأكد من أن الـ pods تستخدم الصورة الجديدة باستخدام الأمر describe.
kubectl describe pod client-deployment-849bc58bcc-gz26b | grep 'Image'
# Image: fhsinchy/notes-client:edge
# Image ID: docker-pullable://fhsinchy/notes-client@sha256:58bce38c16376df0f6d1320554a56df772e30a568d251b007506fd3b5eb8d7c2الأمر grep متاح على Mac و Linux. إذا كنت تستخدم Windows، فاستخدم git bash بدلاً من سطر أوامر Windows. على الرغم من أن عملية التحديث الإلزامية مملة بعض الشيء، إلا أنه يمكن جعلها أسهل بكثير باستخدام سير عمل CI/CD جيد.
دمج التكوينات
كما رأيت بالفعل، فإن عدد ملفات التكوين في هذا المشروع كبير جدًا على الرغم من أنه يحتوي على ثلاث حاويات فقط. يمكنك في الواقع دمج ملفات التكوين كالتالي:
apiVersion: apps/v1
kind: Deployment
metadata:
name: client-deployment
spec:
replicas: 3
selector:
matchLabels:
component: client
template:
metadata:
labels:
component: client
spec:
containers:
- name: client
image: fhsinchy/notes-client
ports:
- containerPort: 8080
env:
- name: VUE_APP_API_URL
value: /api
---
apiVersion: v1
kind: Service
metadata:
name: client-cluster-ip-service
spec:
type: ClusterIP
selector:
component: client
ports:
- port: 8080
targetPort: 8080كما ترى، لقد قمت بدمج محتويات ملفي client-deployment.yaml و client-cluster-ip-service.yaml باستخدام فاصل (---). على الرغم من أن هذا ممكن ويمكن أن يساعد في المشاريع التي يكون فيها عدد الحاويات مرتفعًا جدًا، إلا أنني أوصي بإبقائها منفصلة ونظيفة وموجزة.
استكشاف الأخطاء وإصلاحها
في هذا القسم، سأدرج بعض المشكلات الشائعة التي قد تواجهها أثناء عملك مع Kubernetes:
- إذا كنت تستخدم نظام
WindowsأوMacوتستخدم مشغلDockerلـminikube، فلن تعمل إضافةIngress. - إذا كان لديك
Laravel Valetيعمل علىMacوتستخدم مشغلHyperKitلـminikube، فسيفشل في الاتصال بالإنترنت. سيؤدي إيقاف خدمةdnsmasqإلى حل المشكلة. - إذا كان لديك جهاز كمبيوتر بمعالج
Ryzen(معالجي هوR5 1600) وتشغلWindows 10، فقد يفشل مشغلVirtualBoxفي البدء بسبب نقص الدعم للـnested virtualization(المحاكاة الافتراضية المتداخلة). سيتعين عليك استخدام مشغلHyper-VعلىWindows 10(إصداراتProوEnterpriseوEducation). بالنسبة لمستخدمي إصدارHome، للأسف لا يوجد خيار آمن على هذا الجهاز. - إذا كنت تشغل
Windows 10(إصداراتProوEnterpriseوEducation) مع مشغلHyper-Vلـminikube، فقد يفشل الجهاز الافتراضي في البدء برسالة تتعلق بذاكرة غير كافية. لا داعي للذعر، ونفذ الأمرminikube startمرة أخرى لبدء تشغيل الجهاز الافتراضي بشكل صحيح. - إذا رأيت بعض الأوامر المنفذة في هذا المقال مفقودة أو تعمل بشكل غير صحيح في سطر أوامر
Windows، فاستخدمgit bashأوcmderبدلاً من ذلك. - إذا كنت تستخدم جهاز
Raspberry Pi، فلن تعمل صوري. استخدم الصور التي بناها رائد شمام. يمكن العثور على جميع الصور الثلاث على ملفه الشخصي علىDocker Hub. يمكن العثور على تعليمات بخصوص بناء الصور لـRaspberry Piفي مشكلةGitHubهذه. - أقترح تثبيت توزيعة
Linuxجيدة على نظامك واستخدام مشغلDockerلـminikube. هذا هو أسرع وأكثر الإعدادات موثوقية حتى الآن.
الخلاصة التقنية
يُبرز هذا الدليل بوضوح قوة Kubernetes كمنصة لتنسيق الحاويات، حيث يُمكن للمطورين والمشغلين تحديد الحالة المرغوبة لتطبيقاتهم، ليقوم Kubernetes بتنفيذها والمحافظة عليها تلقائيًا. من خلال الانتقال من النهج الإلزامي إلى النهج التصريحي، نرى كيف تتحول إدارة البنية التحتية إلى عملية أكثر كفاءة ومرونة. تُظهر الأمثلة العملية، من نشر تطبيق بسيط إلى إدارة تطبيق متعدد الحاويات مع تخزين مستمر وتوجيه متقدم عبر Ingress، أن Kubernetes يوفر حلولًا شاملة لتحديات النشر الحديثة. كما أن استخدام الـ Secrets والـ ConfigMaps يؤكد على أهمية ممارسات الأمان وإدارة التكوينات بفعالية. على الرغم من منحنى التعلم الأولي، فإن الفوائد طويلة الأجل في قابلية التوسع، التوافر العالي، وسهولة إدارة التطبيقات السحابية تجعل من Kubernetes أداة لا غنى عنها في مشهد تكنولوجيا المعلومات اليوم.
أود أن أشكرك من أعماق قلبي على الوقت الذي قضيته في قراءة هذا المقال. آمل أن تكون قد استمتعت بوقتك وتعلمت جميع أساسيات Kubernetes. بصرف النظر عن هذا الدليل، لقد كتبت أدلة شاملة حول مواضيع معقدة أخرى متاحة مجانًا على freeCodeCamp. هذه الأدلة هي جزء من مهمتي لتبسيط التقنيات الصعبة الفهم للجميع. يستغرق كل من هذه الأدلة الكثير من الوقت والجهد في الكتابة. إذا استمتعت بكتاباتي وتريد أن تبقيني متحفزًا، فكر في ترك نجوم على GitHub وادعمني للمهارات ذات الصلة على LinkedIn. أقبل أيضًا الرعاية، لذا يمكنك التفكير في شراء لي قهوة إذا أردت. أنا دائمًا منفتح على الاقتراحات والمناقشات على Twitter أو LinkedIn. راسلني مباشرة. في النهاية، فكر في مشاركة الموارد مع الآخرين، لأن مشاركة المعرفة هي أسمى أفعال الصداقة. لأنها طريقة يمكنك بها أن تعطي شيئًا دون أن تخسر شيئًا. — ريتشارد ستالمان. حتى المرة القادمة، ابقَ آمنًا واستمر في التعلم.
فرحان حسين شودري، مطور برامج يتمتع بمهارة في تعلم أشياء جديدة والكتابة عنها. إذا كان هذا المقال مفيدًا، فشاركه. تعلم البرمجة مجانًا. ساعد منهج freeCodeCamp مفتوح المصدر أكثر من 40,000 شخص في الحصول على وظائف كمطورين. ابدأ.
إعلان