شرح m2cgen: تحويل نماذج تعلم الآلة إلى كود أصلي بلا تبعيات
مقدمة: لماذا قد تحتاج إلى تحويل نموذج تعلم الآلة إلى كود أصلي؟
في كثير من مشاريع Machine Learning، يتم حفظ النموذج المدرّب بصيغة pickle داخل بيئة Python. هذا الأسلوب شائع وفعّال، لكنه يفرض وجود مكدس تشغيل كامل يتضمن المكتبات اللازمة لتحميل النموذج وتنفيذ التنبؤات. هنا تظهر الحاجة إلى حل أبسط، خاصة عند النشر في بيئات محدودة لا تسمح بتثبيت حزم Python أو عند الرغبة في دمج النموذج مباشرة داخل تطبيق بلغة أخرى.
في هذا الدليل، ستتعرّف على مكتبة m2cgen، وهي أداة تمكّنك من تحويل نموذج تعلم آلة مدرّب إلى كود أصلي Native Code يعمل دون أي تبعيات إضافية. وسنستعرض كيفية استخدامها عملياً لتحويل نموذج إلى Python وPHP وJavaScript.

ما هي مكتبة m2cgen؟
مكتبة m2cgen، اختصاراً لـ Model 2 Code Generator، هي مكتبة في Python مخصّصة لتحويل النماذج المدرّبة إلى شيفرة برمجية جاهزة بلغات متعددة. الفكرة الأساسية بسيطة: بدلاً من شحن النموذج مع بيئة تشغيله الكاملة، يمكنك تصدير المعادلات والمنطق الداخلي للنموذج في صورة كود يمكن دمجه مباشرة في مشروعك.
هذا النهج مفيد بشكل خاص في الحالات التالية:
- نشر النموذج في خوادم لا تدعم بيئة
Python. - دمج التنبؤات داخل تطبيقات ويب أو جوال بلغات مختلفة.
- تقليل التبعيات الخارجية وتسهيل النشر.
- تشغيل النموذج في بيئات مقيدة أو حساسة للأداء.
اللغات التي تدعمها مكتبة m2cgen
تدعم المكتبة عدداً كبيراً من اللغات البرمجية، ما يمنحك مرونة عالية في التصدير والتكامل. ومن أبرز اللغات المدعومة:
CC#DartF#GoHaskellJavaJavaScriptPHPPowerShellPythonRRubyVisual Basicالمتوافق معVBA
ما النماذج التي يمكن تحويلها باستخدام m2cgen؟
تدعم المكتبة عدداً من نماذج الانحدار والتصنيف من مكتبة Scikit-learn، كما تدعم أطر تعزيز التدرج مثل XGBoost وLightGBM. وهذا يجعلها خياراً مناسباً لعدد واسع من سيناريوهات تعلم الآلة التقليدية.
للاطلاع على القائمة المحدثة للنماذج المدعومة، يمكن الرجوع إلى المستودع الرسمي:
https://github.com/BayesWitnesses/m2cgen#supported-models
كيفية تثبيت مكتبة m2cgen
لتثبيت المكتبة، شغّل الأمر التالي في الطرفية:
pip install m2cgenيجدر التنبيه إلى أن المكتبة تعمل مع إصدارات Python الأحدث من أو المساوية لـ 3.6.
تطبيق عملي: تحويل نموذج موافقة القروض إلى كود أصلي
في هذا المثال العملي، سنستخدم مجموعة بيانات خاصة بطلبات القروض، ثم نبني نموذجاً بسيطاً باستخدام خوارزمية LogisticRegression. بعد التدريب، سنحوّل النموذج إلى كود أصلي بعدة لغات ونتحقق من أن نتائج التنبؤ متقاربة مع النموذج الأصلي.
استيراد الحزم الأساسية
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import m2cgen as m2c
import warnings
# To ignore any warnings
warnings.filterwarnings("ignore")تحميل مجموعة البيانات
يمكن تحميل البيانات باستخدام Pandas عبر الأمر التالي:
data = pd.read_csv("data/loans_data.csv")عرض أعمدة البيانات
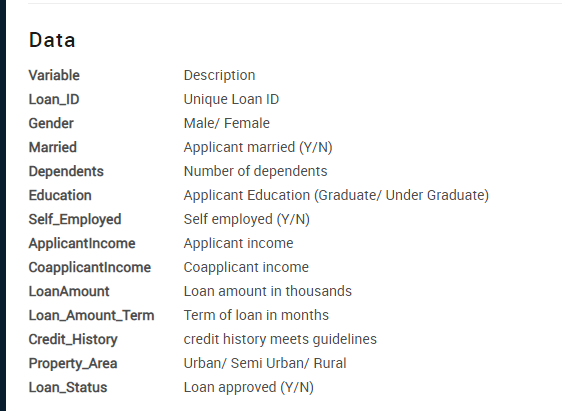
list(data.columns)الأعمدة الأساسية في مجموعة البيانات هي:
Loan_IDGenderMarriedDependentsEducationSelf_EmployedApplicantIncomeCoapplicantIncomeLoanAmountLoan_Amount_TermCredit_HistoryProperty_AreaLoan_Status
لدينا هنا 12 سمة مستقلة، بالإضافة إلى المتغير الهدف Loan_Status.
معاينة أول الصفوف من البيانات
# show the first 5 rows of the dataset
data.head()
كما يظهر، تتضمن البيانات قيماً مفقودة وحقولاً تصنيفية تحتاج إلى تحويلها إلى تمثيل عددي قبل تدريب النموذج.
المعالجة المسبقة للبيانات
الدالة التالية تتولى تنظيف البيانات، وملء القيم المفقودة، وتحويل بعض الحقول إلى صيغة رقمية، ثم تعيد السمات المعالجة والهدف النهائي:
# preprocessing the dataset.
def preprocessing(data):
# replace with numerical values
data['Dependents'].replace('3+', 3, inplace=True)
data['Loan_Status'].replace('N', 0, inplace=True)
data['Loan_Status'].replace('Y', 1, inplace=True)
# handle missing data
data['Gender'].fillna(data['Gender'].mode()[0], inplace=True)
data['Married'].fillna(data['Married'].mode()[0], inplace=True)
data['Dependents'].fillna(data['Dependents'].mode()[0], inplace=True)
data['Self_Employed'].fillna(data['Self_Employed'].mode()[0], inplace=True)
data['Credit_History'].fillna(data['Credit_History'].mode()[0], inplace=True)
data['Loan_Amount_Term'].fillna(data['Loan_Amount_Term'].mode()[0], inplace=True)
data['LoanAmount'].fillna(data['LoanAmount'].median(), inplace=True)
# drop ID column
data = data.drop('Loan_ID', axis=1)
# split features and target
X = data.drop('Loan_Status', axis=1)
y = data.Loan_Status.values
# scale the features
X = pd.get_dummies(X, columns=["Gender", "Married", "Education", "Self_Employed", "Property_Area"])
X = StandardScaler().fit_transform(X)
return X, yبعد ذلك، ننفذ المعالجة المسبقة:
X, y = preprocessing(data)تقسيم البيانات إلى تدريب واختبار
سنستخدم الدالة train_test_split() من مكتبة Scikit-learn لتقسيم البيانات:
# split into train and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1)تدريب نموذج LogisticRegression
# create and train the classifier
classifier = LogisticRegression()
classifier.fit(X_train, y_train)تحويل النموذج المدرّب إلى كود Python
توفر مكتبة m2cgen دوال تصدير جاهزة لكل لغة مدعومة. لتحويل النموذج إلى كود Python خالص، نستخدم الدالة export_to_python():
# convert model to pure python code
model_to_python = m2c.export_to_python(classifier)مثال على الدالة التي يتم توليدها:
# pure python code
def score(input):
return (((((((((((((((((0.7929123964945446) + ((input[0]) * (0.07801862594632314))) + ((input[1]) * (-0.014853900985478468))) + ((input[2]) * (-0.15783041201914427))) + ((input[3]) * (-0.05222073553791883))) + ((input[4]) * (-0.0787403404504791))) + ((input[5]) * (1.3714807410150505))) + ((input[6]) * (0.015077765348160292))) + ((input[7]) * (-0.015077765348160353))) + ((input[8]) * (-0.12161041350915254))) + ((input[9]) * (0.12161041350915253))) + ((input[10]) * (0.09387440269562626))) + ((input[11]) * (-0.09387440269562626))) + ((input[12]) * (-0.0047109053878701835))) + ((input[13]) * (0.004710905387870008))) + ((input[14]) * (-0.14569247529698154))) + ((input[15]) * (0.19858601990225683))) + ((input[16]) * (-0.06417592734444703)))هذه الدالة تستقبل مصفوفة إدخال واحدة وتعيد نتيجة التنبؤ بناءً على الأوزان التي تعلّمها النموذج.
اختبار التنبؤ باستخدام النموذج الأصلي
سنأخذ عينة من بيانات الاختبار:
test_data = X_test[6]
print(test_data)
array([ 1.24474546, 1.9817189 , -0.55448733, 3.02536229, 0.2732313 ,
0.41173269, -0.47234264, 0.47234264, -0.72881553, 0.72881553,
0.52836225, -0.52836225, -2.54711697, 2.54711697, 1.55889948,
-0.7820157 , -0.70020801])ثم ننفذ التنبؤ عبر النموذج الأصلي:
pred = classifier.predict(test_data.reshape(1, -1))
print("prediction result: {}".format(pred))
prediction result: [1]النتيجة 1 تعني أن العميل مؤهل للحصول على القرض وفقاً للنموذج.
اختبار الكود المولّد في Python
# test prediction in pure python code
input = [1.24474546, 1.9817189, -0.55448733, 3.02536229, 0.2732313, 0.41173269,
-0.47234264, 0.47234264, -0.72881553, 0.72881553, 0.52836225, -0.52836225,
-2.54711697, 2.54711697, 1.55889948, -0.7820157, -0.70020801]
pred = score(input)
print("prediction result: {}".format(int(pred)))
prediction result: 1كما نلاحظ، أعطى الكود الناتج النتيجة نفسها، وهذا مؤشر ممتاز على نجاح عملية التحويل.
تحويل النموذج إلى كود PHP
إذا كنت تريد تضمين النموذج داخل تطبيق ويب يعمل بـ PHP، يمكنك استخدام الدالة export_to_php():
# convert model to pure PHP code
model_to_php = m2c.export_to_php(classifier)مثال على الكود الناتج:
function score(array $input) {
return (((((((((((((((((0.8166973302490392) + (($input[0]) * (0.035269518507829584))) + (($input[1]) * (0.05203333118549156))) + (($input[2]) * (-0.13217178253938103))) + (($input[3]) * (-0.13136526173536608))) + (($input[4]) * (-0.024875019809902837))) + (($input[5]) * (1.2864103414352563))) + (($input[6]) * (-0.005259373701309709))) + (($input[7]) * (0.005259373701309715))) + (($input[8]) * (-0.11512289603368371))) + (($input[9]) * (0.11512289603368378))) + (($input[10]) * (0.06905305123713898))) + (($input[11]) * (-0.06905305123713898))) + (($input[12]) * (0.021080906307735767))) + (($input[13]) * (-0.02108090630773594))) + (($input[14]) * (-0.14491490189610398))) + (($input[15]) * (0.2189862115713242))) + (($input[16]) * (-0.08599736364921017)));
}اختبار التنبؤ في PHP
$input = [1.24474546, 1.9817189, -0.55448733, 3.02536229, 0.2732313, 0.41173269,
-0.47234264, 0.47234264, -0.72881553, 0.72881553, 0.52836225, -0.52836225,
-2.54711697, 2.54711697, 1.55889948, -0.7820157, -0.70020801];
// perform prediction with pure php code
$pred = score($input);
echo "Prediction result: " . round($pred);
Prediction result: 1مرة أخرى، جاءت النتيجة مطابقة لتنبؤ النموذج الأصلي.
تحويل النموذج إلى كود JavaScript
أما إذا كنت تريد تشغيل النموذج داخل المتصفح أو في بيئة Node.js، فبإمكانك تصديره إلى JavaScript باستخدام export_to_javascript():
# convert model to pure Javascript code
model_to_javascript = m2c.export_to_javascript(classifier)مثال على الدالة الناتجة:
function score(input) {
return (((((((((((((((((0.8166973302490392) + ((input[0]) * (0.035269518507829584))) + ((input[1]) * (0.05203333118549156))) + ((input[2]) * (-0.13217178253938103))) + ((input[3]) * (-0.13136526173536608))) + ((input[4]) * (-0.024875019809902837))) + ((input[5]) * (1.2864103414352563))) + ((input[6]) * (-0.005259373701309709))) + ((input[7]) * (0.005259373701309715))) + ((input[8]) * (-0.11512289603368371))) + ((input[9]) * (0.11512289603368378))) + ((input[10]) * (0.06905305123713898))) + ((input[11]) * (-0.06905305123713898))) + ((input[12]) * (0.021080906307735767))) + ((input[13]) * (-0.02108090630773594))) + ((input[14]) * (-0.14491490189610398))) + ((input[15]) * (0.2189862115713242))) + ((input[16]) * (-0.08599736364921017)));
}اختبار التنبؤ في JavaScript
// perform prediction with pure Javascript code
let input = [1.24474546, 1.9817189, -0.55448733, 3.02536229, 0.2732313, 0.41173269,
-0.47234264, 0.47234264, -0.72881553, 0.72881553, 0.52836225, -0.52836225,
-2.54711697, 2.54711697, 1.55889948, -0.7820157, -0.70020801];
let pred = score(input);
console.log("Prediction result:", Math.round(pred));
"Prediction result:", 1وهكذا يمكن تشغيل النموذج مباشرة في JavaScript دون تحميل أي مكتبات تعلم آلة إضافية.
ملاحظات مهمة حول دقة النتائج بعد التحويل
رغم أن m2cgen فعّالة جداً، فإن المطابقة الكاملة مع نتائج النموذج الأصلي ليست مضمونة دائماً في كل الحالات. ويوضح مطورو المكتبة أن بعض النماذج تفرض نوع بيانات محدداً أثناء التنبؤ داخل مكتباتها الأصلية، بينما تعتمد m2cgen حالياً على النوع float64 أو double.
لذلك قد تلاحظ فروقات طفيفة في النتائج بسبب:
- اختلاف نوع البيانات المستخدم أثناء التنبؤ.
- اختلاف تنفيذ العمليات العشرية بين اللغات المختلفة.
- التقريب المرتبط بالحسابات ذات الفاصلة العائمة
floating-point arithmetic.
في الأمثلة السابقة، تم استخدام:
int()فيPython.round()فيPHP.Math.round()فيJavaScript.
وذلك لتحويل النتيجة من قيمة عشرية إلى قيمة صحيحة مفهومة في سياق التصنيف.
متى تكون m2cgen خياراً مناسباً؟
تُعد هذه المكتبة مناسبة عندما تحتاج إلى نشر نموذج بسيط أو متوسط التعقيد دون الاعتماد على بنية تشغيل ثقيلة. وهي مفيدة خصوصاً في السيناريوهات التالية:
- تضمين نموذج داخل تطبيق
PHPأوJavaScript. - تشغيل تنبؤات محلية دون خادم تعلم آلة منفصل.
- تقليل تكاليف النشر والصيانة.
- تسريع التكامل مع أنظمة قائمة لا تستخدم
Python.
لكن إذا كان مشروعك يعتمد على نماذج عميقة أو تدفقات استدلال معقدة، فقد تحتاج إلى حلول أكثر تخصصاً من مجرد تصدير المعادلات إلى كود أصلي.
رابط الملفات والمصادر
إذا أردت الاطلاع على الملفات المستخدمة في المثال، بما في ذلك مجموعة البيانات وملفات Notebook والسكربتات، يمكنك الرجوع إلى الرابط التالي:
https://github.com/Davisy/Convert-Trained-ML-Models-To-Native-Code
الخلاصة التقنية
تقدم مكتبة m2cgen حلاً عملياً ومباشراً لتحويل نماذج تعلم الآلة التقليدية إلى كود أصلي قابل للتشغيل دون تبعيات، وهو ما يجعلها أداة مفيدة جداً في مشاريع النشر الخفيف والتكامل متعدد اللغات. من الناحية التقنية، تكمن قوتها في تبسيط مرحلة deployment وتقليل الاعتماد على بيئة Python، لكن يجب دائماً اختبار النتائج بعد التحويل، خاصة عند التعامل مع فروقات الأنواع العددية والدقة العشرية بين اللغات المختلفة.