أساسيات تعلم الآلة للمطورين: دليلك الشامل لبناء نماذج ذكية

في المشهد التقني المعاصر، يُتوقع من المطورين امتلاك مجموعة متنوعة من المهارات، وهو ما يمتلكه العديد منهم بالفعل. تتوفر أيضًا مسارات وظيفية متعددة للمطورين تستفيد من مهاراتهم الحالية مع بعض التعديلات. فمسؤولو قواعد البيانات، ومناصرو المطورين، ومهندسو تعلم الآلة، يتشاركون جميعًا في سمة أساسية واحدة مع جميع المطورين: معرفتهم بالبرمجة. بغض النظر عن لغات البرمجة المستخدمة، فإنهم جميعًا يدركون المفاهيم الجوهرية وراء كتابة شيفرة برمجية جيدة.
هذا أحد الأسباب الرئيسية التي تجعل العديد من مطوري البرمجيات يفكرون في التحول إلى مهندسي تعلم الآلة. مع توفر جميع الأدوات والحزم اللازمة، لم يعد الحصول على نتائج دقيقة يتطلب خلفية رياضية عميقة. إذا كنت مستعدًا لتعلم كيفية استخدام بعض المكتبات واكتساب فهم عالي المستوى للرياضيات الأساسية، فيمكنك أن تصبح مهندس تعلم آلة.
في هذا المقال، سنستعرض معك بعض المفاهيم الرئيسية في تعلم الآلة التي تحتاج إلى فهمها بصفتك مطور برمجيات. وسنختتم بمثال لمشروع تعلم آلة كامل، بدءًا من الحصول على البيانات وصولًا إلى التنبؤ بقيمة باستخدام نموذج. بحلول نهاية المقال، سيكون لديك ما يكفي من المعرفة لإنجاز مشروع تعلم آلة صغير خاص بك من الصفر.
ما هو تعلم الآلة (Machine Learning)؟
تتعدد تعريفات تعلم الآلة (Machine Learning)، ولكن جوهره يكمن في استخدام الرياضيات لاكتشاف الأنماط المخفية ضمن كميات هائلة من البيانات، بهدف بناء تنبؤات مستنيرة بناءً على بيانات جديدة. بمجرد اكتشاف هذه الأنماط، يمكننا القول إن لدينا “نموذج تعلم آلة” (Machine Learning Model). من هذه النقطة، يمكن استخدام النموذج لإجراء تنبؤات على بيانات جديدة لم يسبق للنموذج رؤيتها.
الهدف الأسمى لتعلم الآلة هو تمكين أجهزة الكمبيوتر من التحسن تلقائيًا مع الخبرة، وذلك بالاعتماد على الخوارزميات (Algorithms) المبرمجة فيها. الخوارزمية هي ببساطة معادلة رياضية أو مجموعة من المعادلات التي تقدم نتيجة بناءً على بيانات الإدخال الخاصة بك. يستخدم تعلم الآلة هذه الخوارزميات للعثور على الأنماط التي نبحث عنها. كلما تعرضت الخوارزميات لمزيد من البيانات، بدأت في إجراء تنبؤات أكثر دقة. في نهاية المطاف، سيصبح النموذج الذي بنته الخوارزميات قادرًا على استنتاج النتيجة الصحيحة دون الحاجة إلى برمجته صراحةً لذلك. هذا يعني أن الكمبيوتر يجب أن يكون قادرًا على استيعاب البيانات واتخاذ القرارات (التنبؤات) دون أي مساعدة بشرية.
تعلم الآلة مقابل علم البيانات مقابل الذكاء الاصطناعي
كثير من الناس يستخدمون مصطلحات Machine Learning (تعلم الآلة)، وData Science (علم البيانات)، وArtificial Intelligence (الذكاء الاصطناعي) بالتبادل، لكنها ليست مترادفات:
- تعلم الآلة (
Machine Learning): يُستخدم في علم البيانات لإجراء التنبؤات واكتشاف الأنماط في بياناتك. يركز تعلم الآلة بشكل أكبر على الجانب البرمجي وأتمتة المهام. - علم البيانات (
Data Science): يركز بشكل أكبر على الإحصاء والخوارزميات وتفسير النتائج. هو مجال أوسع يستخدم تعلم الآلة كأداة أساسية. - الذكاء الاصطناعي (
Artificial Intelligence): يشير إلى قدرة الكمبيوتر على فهم البيانات والتعلم منها، مع اتخاذ القرارات بناءً على أنماط مخفية قد يكون من المستحيل على البشر اكتشافها.
يمكن اعتبار تعلم الآلة فرعًا من فروع الذكاء الاصطناعي؛ فنحن نستخدم تعلم الآلة لتحقيق الذكاء الاصطناعي. الذكاء الاصطناعي موضوع واسع يشمل مجالات مثل الرؤية الحاسوبية (Computer Vision)، وتفاعلات الإنسان مع الحاسوب (Human-Computer Interactions)، والأنظمة الذاتية (Autonomy)، حيث يُستخدم تعلم الآلة في كل من هذه التطبيقات.
أنواع تعلم الآلة المختلفة
التعلم الخاضع للإشراف (Supervised Learning)
تندرج معظم مشكلات تعلم الآلة ضمن هذه الفئة. يحدث هذا النوع عندما يكون لديك متغيرات إدخال وإخراج، وتحاول إنشاء علاقة (تطابق) بينها. يُطلق عليه اسم التعلم الخاضع للإشراف (Supervised Learning) لأنه يمكننا استخدام البيانات لتعليم النموذج الإجابة الصحيحة. ستقوم الخوارزمية بإجراء تنبؤات بناءً على البيانات، وسيتم تصحيحها ببطء حتى تتطابق هذه التنبؤات مع المخرجات المتوقعة. يمكن حل معظم المشكلات التي يغطيها التعلم الخاضع للإشراف باستخدام التصنيف (Classification) أو الانحدار (Regression). طالما أن لديك بيانات مُصنفة (Labeled Data)، فأنت تعمل ضمن نطاق التعلم الآلي الخاضع للإشراف.
التعلم شبه الخاضع للإشراف (Semi-supervised Learning)
تقع معظم المشكلات الواقعية ضمن هذا المجال بسبب طبيعة مجموعات البيانات لدينا. في كثير من الحالات، سيكون لديك مجموعة بيانات كبيرة يكون بعضها مُصنفًا (Labeled)، ولكن معظمها غير مُصنف. قد يكون من المكلف أحيانًا الاستعانة بخبير لتصنيف جميع هذه البيانات، لذا يتم اللجوء إلى مزيج من التعلم الخاضع للإشراف وغير الخاضع للإشراف. تتمثل إحدى الاستراتيجيات في استخدام البيانات المُصنفة لعمل تخمينات حول البيانات غير المُصنفة، ثم استخدام هذه التنبؤات كـ “تسميات” لها. بعد ذلك، يمكنك استخدام جميع البيانات في نوع من نماذج التعلم الخاضع للإشراف. نظرًا لأنه من الممكن أيضًا إجراء التعلم غير الخاضع للإشراف على مجموعات البيانات هذه، فكر فيما إذا كان ذلك سيكون طريقة أكثر كفاءة.
التعلم غير الخاضع للإشراف (Unsupervised Learning)
عندما يكون لديك بيانات إدخال فقط ولا توجد بيانات إخراج مرتبطة بها، وترغب في أن يكتشف النموذج النمط الذي تبحث عنه، فهنا يأتي دور التعلم غير الخاضع للإشراف (Unsupervised Learning). ستقوم الخوارزمية بإنشاء شيء منطقي بالنسبة لها بناءً على المعلمات التي تقدمها. يكون هذا مفيدًا عندما يكون لديك الكثير من البيانات العشوائية ظاهريًا وترغب في معرفة ما إذا كانت هناك أي أنماط مثيرة للاهتمام فيها. هذه المشكلات غالبًا ما تكون مثالية لخوارزميات التجميع (Clustering Algorithms) وتوفر لك بعض النتائج غير المتوقعة.
تطبيقات عملية لتعلم الآلة للمطورين
التصنيف (Classification)
عندما ترغب في التنبؤ بـ “تسمية” (Label) لبعض بيانات الإدخال، فهذه مشكلة تصنيف (Classification). يتعامل تعلم الآلة مع التصنيف عن طريق بناء نموذج يأخذ البيانات التي تم تصنيفها بالفعل ويستخدمها لإجراء تنبؤات على بيانات جديدة. بشكل أساسي، تعطيه إدخالًا جديدًا، وهو يعطيك التسمية التي يعتقد أنها صحيحة. تعتمد مهام مثل التنبؤ بتسرب العملاء (Customer Churn)، وتصنيف الوجوه (Face Classification)، واختبارات التشخيص الطبي (Medical Diagnostic Tests) جميعها على أنواع مختلفة من التصنيف. بينما تقع كل هذه المهام ضمن مجالات مختلفة من التصنيف، فإنها جميعًا تُسند قيمًا بناءً على البيانات التي استخدمتها نماذجها للتدريب. جميع القيم المتنبأ بها تكون دقيقة، لذا ستتنبأ بقيم مثل اسم أو قيمة منطقية (Boolean).
الانحدار (Regression)
يُعد الانحدار (Regression) مثيرًا للاهتمام لأنه يتقاطع بين تعلم الآلة والإحصاء. إنه مشابه للتصنيف لأنه يُستخدم للتنبؤ بالقيم، باستثناء أنه يتنبأ بالقيم المستمرة (Continuous Values) بدلاً من القيم المنفصلة (Discrete Values). لذا، إذا كنت ترغب في التنبؤ بنطاق راتب بناءً على سنوات الخبرة واللغات المعروفة، أو كنت ترغب في التنبؤ بسعر منزل بناءً على الموقع والمساحة بالقدم المربع، فأنت تتعامل مع مشكلة انحدار.
توجد تقنيات انحدار مختلفة للتعامل مع جميع أنواع مجموعات البيانات، حتى البيانات غير الخطية. هناك انحدار المتجهات الداعمة (Support Vector Regression)، والانحدار الخطي البسيط (Simple Linear Regression)، والانحدار متعدد الحدود (Polynomial Regression)، وغيرها الكثير. هناك ما يكفي من تقنيات الانحدار لتناسب أي مجموعة بيانات لديك تقريبًا.
التجميع (Clustering)
ينتقل هذا المفهوم إلى نوع مختلف من تعلم الآلة. يتعامل التجميع (Clustering) مع مهام التعلم غير الخاضع للإشراف. إنه يشبه التصنيف، ولكن لا توجد بيانات مُصنفة. الأمر متروك للخوارزمية لاكتشاف وتصنيف نقاط البيانات. هذا مفيد للغاية عندما يكون لديك مجموعة بيانات ضخمة ولا تعرف أي أنماط بينها، أو تبحث عن روابط غير شائعة.
يساعد التجميع عندما ترغب في العثور على الشذوذ (Anomalies) والقيم الشاذة (Outliers) في بياناتك دون قضاء مئات الساعات في تصنيف نقاط البيانات يدويًا. في هذه الحالة، غالبًا لا توجد “أفضل” خوارزمية واحدة، وأفضل طريقة للعثور على ما يناسب بياناتك هي من خلال اختبار خوارزميات مختلفة. تتضمن بعض خوارزميات التجميع: K-Means، DBSCAN، Agglomerative Clustering، وAffinity Propagation. سيساعدك بعض التجريب والخطأ في العثور بسرعة على الخوارزمية الأكثر كفاءة بالنسبة لك.
التعلم العميق (Deep Learning)
هذا هو مجال من مجالات تعلم الآلة يستخدم خوارزميات مستوحاة من طريقة عمل الدماغ البشري. يتضمن الشبكات العصبية (Neural Networks) التي تستخدم مجموعات بيانات كبيرة غير مُصنفة. عادةً ما يتحسن الأداء مع زيادة كمية البيانات التي تغذيها لخوارزمية التعلم العميق (Deep Learning). تتعامل هذه الأنواع من المشكلات مع البيانات غير المُصنفة، والتي تمثل غالبية البيانات المتاحة.
هناك عدد من الخوارزميات التي يمكنك استخدامها مع هذه التقنية، مثل الشبكات العصبية الالتفافية (Convolutional Neural Networks)، وشبكات الذاكرة طويلة المدى قصيرة الأجل (Long Short-Term Memory Networks)، أو شبكة Deep Q-Network. تُستخدم كل من هذه التقنيات في مشاريع مثل الرؤية الحاسوبية (Computer Vision)، والمركبات ذاتية القيادة (Autonomous Vehicles)، أو تحليل إشارات تخطيط الدماغ (EEG Signals).
أدوات ومكتبات شائعة في تعلم الآلة
يتوفر عدد من الأدوات التي يمكنك استخدامها لأي مشكلة تعلم آلة تقريبًا. إليك قائمة موجزة ببعض الحزم الشائعة التي ستجدها في العديد من تطبيقات تعلم الآلة:
-
Pandas: هذه أداة تحليل بيانات عامة في لغةPython. تساعدك عندما تحتاج إلى العمل مع البيانات الخام. تتعامل مع البيانات النصية، والجداول، وبيانات السلاسل الزمنية، والمزيد. تُستخدم هذه الحزمة لتنسيق البيانات قبل تدريب نموذج تعلم الآلة في كثير من الحالات. -
TensorFlow: يمكنك بناء أي عدد من تطبيقات تعلم الآلة باستخدام هذه المكتبة. يمكنك تشغيلها على وحدات معالجة الرسوميات (GPUs)، واستخدامها لحل مشكلات إنترنت الأشياء (IoT)، وهي ممتازة للتعلم العميق. هذه المكتبة قادرة على التعامل مع أي شيء تقريبًا، لكنها تتطلب بعض الوقت لإتقانها. -
Scikit-learn: هذه المكتبة مشابهة لـTensorFlowمن حيث نطاق تطبيقات تعلم الآلة التي يمكن استخدامها فيها. الفرق الكبير هو البساطة التي تحصل عليها مع هذه الحزمة. إذا كنت على دراية بـNumPyوmatplotlibوSciPy، فلن تواجه أي مشاكل في البدء بها. يمكنك إنشاء نماذج للتعامل مع بيانات مستشعرات المركبات، وبيانات اللوجستيات، والبيانات المصرفية، وغيرها من السياقات. -
Keras: عندما ترغب في العمل على مشروع تعلم عميق، مثل مشروع روبوتات معقد، فهذه مكتبة محددة ستساعدك. إنها مبنية فوقTensorFlowوتجعل من السهل على الأشخاص إنشاء نماذج تعلم عميق ونشرها في بيئات الإنتاج. ستراها تُستخدم كثيرًا في تطبيقات معالجة اللغات الطبيعية (Natural Language Processing) وتطبيقات الرؤية الحاسوبية (Computer Vision). -
NLTK: معالجة اللغات الطبيعية (Natural Language Processing) هي مجال ضخم في تعلم الآلة، وهذه الحزمة تركز عليه. إنها إحدى الحزم التي يمكنك استخدامها لتبسيط مشاريعNLPالخاصة بك. لا تزال قيد التطوير النشط ولديها مجتمع جيد يدعمها. -
BERT:BERTهي مكتبة مفتوحة المصدر تم إنشاؤها في عام 2018 فيGoogle. إنها تقنية جديدة لمعالجة اللغات الطبيعية (NLP) وتتبع نهجًا مختلفًا تمامًا لتدريب النماذج عن أي تقنية أخرى.BERTهو اختصار لـBidirectional Encoder Representations from Transformers. هذا يعني أنه على عكس معظم التقنيات التي تحلل الجمل من اليسار إلى اليمين أو من اليمين إلى اليسار، فإنBERTيتجه في كلا الاتجاهين باستخدام مُشفّر المحولات (Transformer Encoder). هدفها هو إنشاء نموذج لغوي. -
Brain.js: هذه إحدى أفضل مكتبات تعلم الآلة بلغةJavaScript. يمكنك تحويل نموذجك إلىJSONأو استخدامه مباشرة في المتصفح كدالة، ولا يزال لديك المرونة للتعامل مع معظم مشاريع تعلم الآلة الشائعة. من السهل جدًا البدء بها ولديها بعض الوثائق والدروس التعليمية الرائعة.
مثال عملي لمشروع تعلم آلة متكامل
1. الحصول على البيانات (Getting Data)
يمكن القول إن أصعب جزء في مشروع تعلم الآلة هو الحصول على البيانات. هناك العديد من الموارد المتاحة عبر الإنترنت التي يمكنك استخدامها للحصول على مجموعات بيانات لتعلم الآلة، وإليك قائمة ببعضها:
- مجموعة بيانات الرعاية الحرجة
- أطوال وأوزان البشر
- احتيال بطاقات الائتمان
- مراجعات
IMDB - تحليل المشاعر لشركات الطيران على
Twitter - مجموعة بيانات الأغاني
- مجموعة بيانات جودة النبيذ (
Wine Quality Data Set) - مجموعة بيانات أسعار المنازل في بوسطن
- أرقام
MNISTالمكتوبة بخط اليد - تقييمات النكات
- مراجعات أمازون
- مجموعة رسائل البريد العشوائي النصية
- رسائل البريد الإلكتروني لشركة
Enron - مجموعات بيانات أنظمة التوصية
- مجموعة بيانات
COVID
سنستخدم مجموعة بيانات جودة النبيذ الأبيض (White Wine Quality Data Set) لهذا المثال وسنحاول التنبؤ بكثافة النبيذ (Wine Density). في معظم الأحيان، لن تكون البيانات نظيفة بهذا الشكل عندما تصل إليك، وسيتعين عليك العمل عليها لتنسيقها بالطريقة التي تريدها. ولكن حتى مع بيانات كهذه، لا يزال يتعين علينا إجراء بعض التنظيف.
2. اختيار الميزات (Choosing Features)
سنختار بعض الميزات للتنبؤ بكثافة النبيذ. الميزات التي سنعمل عليها هي: quality (الجودة)، pH (الرقم الهيدروجيني)، alcohol (الكحول)، fixed acidity (الحموضة الثابتة)، وtotal sulfur dioxide (إجمالي ثاني أكسيد الكبريت). كان من الممكن أن يكون هذا أي مزيج من الميزات المتاحة، وقد اخترت هذه الميزات بشكل عشوائي. لا تتردد في استخدام أي من الميزات الأخرى بدلاً من هذه، أو لا تتردد في استخدامها جميعًا!
3. اختيار الخوارزميات (Choosing Algorithms)
الآن بعد أن عرفت المشكلة التي تحاول حلها والبيانات المتوفرة لديك، يمكنك البدء في البحث عن الخوارزميات المناسبة. بما أننا نحاول التنبؤ بقيمة مستمرة بناءً على عدة ميزات، فمن المرجح أن تكون هذه مشكلة انحدار (Regression Problem). لو كنا نحاول التنبؤ بقيمة منفصلة، مثل نوع النبيذ، لكانت هذه على الأرجح مشكلة تصنيف (Classification Problem). لهذا السبب، يجب أن تكون على دراية ببياناتك قبل الغوص في أدوات تعلم الآلة، فهذا يساعدك على تضييق نطاق الخوارزميات التي يمكنك اختيارها لمشكلتك.
سنبدأ بخوارزمية الانحدار متعدد المتغيرات (Multivariate Regression Algorithm). تُستخدم هذه الخوارزمية عادةً عندما تتعامل مع عدة معلمات تؤثر على النتيجة النهائية. تشبه خوارزمية الانحدار متعدد المتغيرات خوارزمية الانحدار العادية، باستثناء أنه يمكنك الحصول على مدخلات متعددة. المعادلة الأساسية لها هي:
y = theta_0 + sum(theta_n * X_n)
نقوم بتهيئة كل من الحد theta_0 (مصطلح التحيز bias term) والمصطلحات theta_n إلى قيمة معينة، عادةً 1 أو 0، ما لم يكن لديك معلومات أخرى تستند إليها هذه القيم. بعد تعيين القيم الأولية، نحاول تحسينها لتناسب المشكلة. نقوم بذلك عن طريق حل معادلات الانحدار التدرجي (Gradient Descent):
theta_0 = theta_0 - alpha * (1 / m) * sum(y_n - y_i)
theta_n = theta_n - alpha * (1 / m) * sum(y_n - y_i) * X_nحيث y_n هي القيمة المتنبأ بها بناءً على حسابات الخوارزمية، وy_i هي القيمة التي لدينا من بياناتنا أو القيمة المتوقعة. نريد أن يكون هامش الخطأ بين القيمة المتنبأ بها والقيمة الحقيقية صغيرًا قدر الإمكان. هذا هو السبب في أننا نحاول تحسين قيم theta. هذا يسمح لنا بتقليل دالة التكلفة (Cost Function) للتنبؤ بقيم المخرجات. إليك معادلة دالة التكلفة:
J(theta_n) = (1 / 2m) * sum(y_n - y_i)^2
هذه هي كل الرياضيات التي نحتاجها لبناء النموذج وتدريبه، فلنبدأ.
4. معالجة البيانات الأولية (Pre-processing Data)
أول شيء تريد القيام به هو التحقق من شكل بياناتنا. لقد أجريت بعض التعديلات على مجموعة بيانات جودة النبيذ لكي تتوافق مع خوارزميتنا. يمكنك تنزيلها من هنا: https://github.com/flippedcoder/probable-waddle/blob/master/wine-quality-data.csv. كل ما فعلته هو أخذ الملف الأصلي، وإزالة الميزات غير الضرورية، ونقل الكثافة إلى النهاية، وتنظيف التنسيق.
الآن يمكننا الانتقال إلى جزء المعالجة الأولية الحقيقي! أنشئ ملفًا جديدًا باسم multivariate-wine.py. يجب أن يكون هذا الملف في نفس المجلد الذي توجد به مجموعة البيانات. أول شيء سنفعله في هذا الملف هو استيراد بعض الحزم ورؤية كيف تبدو مجموعة البيانات.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('./wine-quality-data.csv', header=None)
print(df.head())يجب أن ترى شيئًا كهذا في نافذة الأوامر (terminal) الخاصة بك:
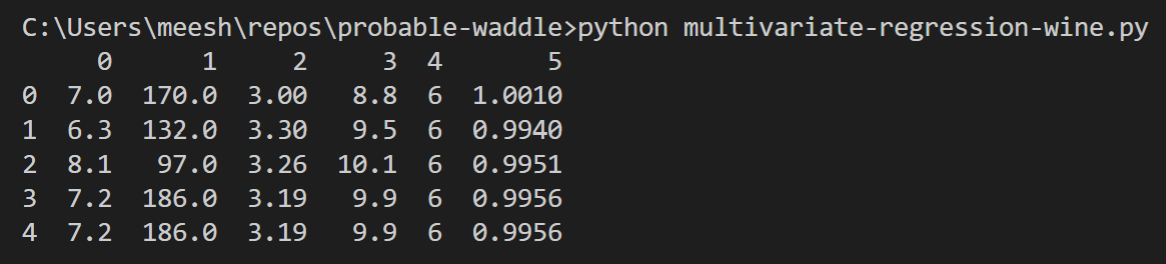
تبدو البيانات جاهزة لخوارزمية الانحدار متعدد المتغيرات، لذا يمكننا البدء في بناء النموذج. أشجعك على محاولة البدء بمجموعة بيانات النبيذ الأبيض الخام لمعرفة ما إذا كان يمكنك إيجاد طريقة لجعلها بالتنسيق الصحيح.
5. بناء النموذج (Building the Model)
نحتاج إلى إضافة حد التحيز (bias term) إلى البيانات لأنه، كما رأيت في شرح الخوارزمية، نحتاجه كونه يمثل الحد theta_0.
df = pd.concat([pd.Series(1, index=df.index, name='00'), df], axis=1)بما أن البيانات جاهزة، يمكننا تعريف المتغيرات المستقلة والتابعة للخوارزمية.
X = df.drop(columns=5)
y = df.iloc[:, 6]الآن دعنا نقوم بتطبيع البيانات (normalize) عن طريق قسمة كل عمود على القيمة القصوى في ذلك العمود. ليس عليك بالضرورة القيام بهذه الخطوة، لكنها ستساعد في تسريع وقت تدريب الخوارزمية. كما أنها تساعد في منع ميزة واحدة من أن تكون مهيمنة أكثر من الميزات الأخرى.
for i in range(1, len(X.columns)):
X[i-1] = X[i-1]/np.max(X[i-1])دعنا نلقي نظرة على البيانات بعد التطبيع.
print(X.head())
يجب أن ترى شيئًا مشابهًا لهذا في نافذة الأوامر.
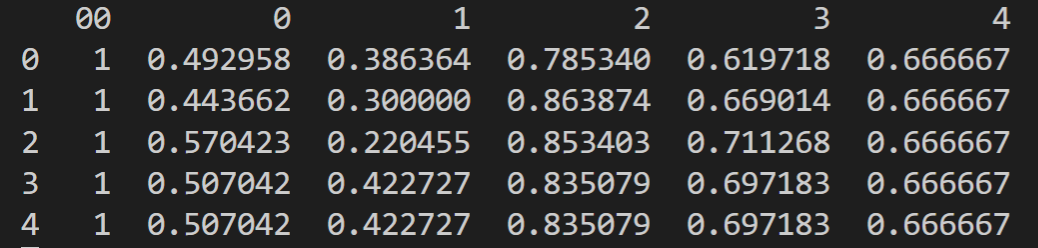
البيانات جاهزة الآن ويمكننا تهيئة معلمة theta. هذا يعني ببساطة أننا سننشئ مصفوفة من الآحاد تحتوي على نفس عدد الأعمدة مثل متغير الإدخال X.
theta = np.array([1]*len(X.columns))يجب أن تبدو هكذا إذا قمت بطباعتها في نافذة الأوامر الخاصة بك، على الرغم من أنك لست بحاجة إلى طباعتها إذا كنت لا ترغب في ذلك.
[1 1 1 1 1 1]
بعد ذلك، سنحدد عدد نقاط التدريب التي سنأخذها من البيانات. سنترك 500 نقطة بيانات جانبًا حتى نتمكن من استخدامها للاختبار لاحقًا. ستكون هذه هي قيمة m من معادلة الانحدار التدرجي التي استعرضناها سابقًا.
m = len(df) - 500الآن نبدأ بكتابة الدوال التي سنحتاجها لتدريب النموذج بعد بنائه. سنبدأ بدالة الفرضية (hypothesis function) وهي ببساطة متغير الإدخال مضروبًا في المعلمة theta_n.
def hypothesis(theta, X):
return theta * Xبعد ذلك، سنعرف نموذج التكلفة (cost model) الذي سيعطينا هامش الخطأ بين القيم الحقيقية والمتنبأ بها.
def calculateCost(X, y, theta):
y1 = hypothesis(theta, X)
y1 = np.sum(y1, axis=1)
return (1 / (2 * m)) * sum(np.sqrt((y1 - y) ** 2))الدالة الأخيرة التي نحتاجها قبل أن يصبح نموذجنا جاهزًا للتشغيل هي دالة لحساب قيم الانحدار التدرجي.
def gradientDescent(X, y, theta, alpha, i):
J = [] # cost function for each iteration
k = 0
while k < i:
y1 = hypothesis(theta, X)
y1 = np.sum(y1, axis=1)
for c in range(1, len(X.columns)):
theta[c] = theta[c] - alpha * (1 / m) * (sum((y1 - y) * X.iloc[:, c]))
j = calculateCost(X, y, theta)
J.append(j)
k += 1
return J, j, theta6. تدريب النموذج (Training the Model)
مع وجود هذه الدوال الثلاث وبياناتنا النظيفة، يمكننا أخيرًا البدء في تدريب النموذج. جزء التدريب هو الجزء الممتع والأسهل أيضًا. إذا قمت بإعداد خوارزميتك بشكل صحيح، فكل ما عليك فعله هو أخذ المعلمات المُحسّنة التي توفرها لك وإجراء التنبؤات.
نحن نعيد قائمة بالتكاليف في كل تكرار، والتكلفة النهائية، وقيم theta المُحسّنة من دالة الانحدار التدرجي. لذا سنحصل على قيم theta المُحسّنة ونستخدمها للاختبار.
J, j, theta = gradientDescent(X, y, theta, 0.1, 10000)بعد كل العمل الشاق في إعداد الدوال والبيانات بشكل صحيح، يقوم هذا السطر الواحد من الشيفرة بتدريب النموذج ويزودنا بقيم theta التي نحتاجها للبدء في التنبؤ بالقيم واختبار دقة النموذج.
7. اختبار النموذج (Testing the Model)
الآن يمكننا اختبار النموذج عن طريق إجراء تنبؤ باستخدام البيانات.
y_hat = hypothesis(theta, X)
y_hat = np.sum(y_hat, axis=1)بعد التحقق من بعض القيم، ستعرف ما إذا كان نموذجك دقيقًا بما يكفي أو إذا كنت بحاجة إلى إجراء المزيد من الضبط على قيم theta. إذا كنت مرتاحًا لنتائج اختباراتك، فيمكنك المضي قدمًا والبدء في استخدام هذا النموذج في مشاريعك.
8. استخدام النموذج (Using the Model)
القيم المُحسّنة لـ theta هي كل ما تحتاجه حقًا للبدء في استخدام النموذج. ستستمر في استخدام نفس المعادلات، حتى في بيئات الإنتاج، ولكن مع أفضل قيم theta لتعطيك أدق التنبؤات. يمكنك حتى مواصلة تدريب النموذج ومحاولة العثور على قيم theta أفضل.
الخلاصة التقنية
تعلم الآلة، في جوهره، ليس حكرًا على علماء الرياضيات البحتة. لقد تطورت الأدوات والمكتبات الحديثة لتمكين المطورين من بناء نماذج قوية دون الحاجة إلى الغوص في التفاصيل الرياضية المعقدة. يكمن التحدي الحقيقي والقيمة المضافة في فهم البيانات، وكيفية جمعها، تنظيفها، وتجهيزها. هذا المقال يقدم خريطة طريق واضحة للمطورين للانتقال إلى هذا المجال المثير، مؤكدًا أن المهارات البرمجية الأساسية هي حجر الزاوية للنجاح في هندسة تعلم الآلة.