تعلّم الآلة مباشرة داخل SQL: كيف تستخدم خوارزميات ML في قواعد البيانات
مقدمة: هل يمكن تنفيذ تعلّم الآلة داخل قاعدة البيانات؟
لا يجب أن يبدو Machine Learning علماً غامضاً أو محصوراً في مكتبات عالية المستوى مثل scikit-learn. في الواقع، يمكن تنفيذ جزء مهم من مفاهيمه الأساسية مباشرة داخل قاعدة البيانات، دون الحاجة إلى نقل البيانات إلى بيئة خارجية. وهذا يفتح الباب أمام حلول عملية وسريعة، خاصة عندما تكون البيانات مخزنة أصلاً في PostgreSQL.
تسمح لك PostgreSQL بكتابة استعلامات قادرة على تنفيذ عدد من خوارزميات تعلّم الآلة بالاعتماد على الدوال الإحصائية والأنواع الهندسية والاستعلامات التكرارية. في هذا المقال سنستعرض أربع خوارزميات شائعة مكتوبة بالكامل بلغة SQL، مع شرح مبسط لكيفية عمل كل واحدة منها ومتى يمكن الاستفادة منها.

هذه الأمثلة تهدف إلى الفهم والتعلّم أكثر من كونها حلولاً جاهزة للإنتاج. لكنها ممتازة لتطوير فهمك لكل من SQL وتعلّم الآلة وأساليب التفكير التحليلي، وهي مهارات أساسية لأي متخصص بيانات أو مطور يعمل على الأنظمة المعتمدة على البيانات.
الانحدار الخطي داخل SQL
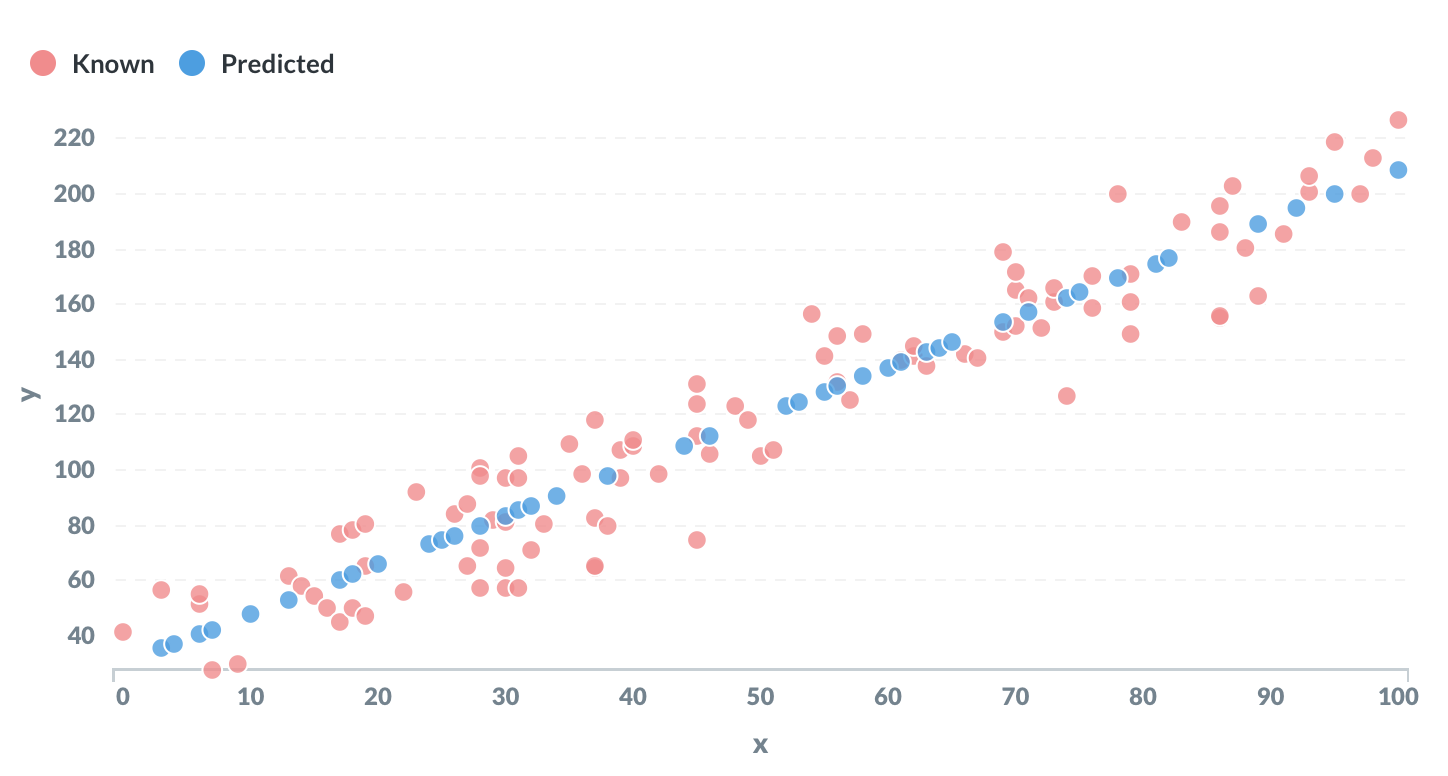
يُعد Linear Regression من أبسط تطبيقات تعلّم الآلة وأكثرها شهرة. الهدف منه هو تعلّم معاملي المعادلة الخطية y = mx + c انطلاقاً من بيانات تدريبية، بحيث يمثل m الميل ويمثل c الجزء الثابت.
في PostgreSQL توجد دوال مدمجة تسهّل هذه المهمة بشكل كبير. لنفترض أن لدينا جدولاً يحتوي على عمودين x وy، وأن بعض قيم y مفقودة ومخزنة على شكل NULL. المطلوب هنا هو تقدير هذه القيم المفقودة بالاعتماد على العلاقة الخطية بين المتغيرين.
WITH regression AS (
SELECT
regr_slope(y, x) AS gradient,
regr_intercept(y, x) AS intercept
FROM linear_regression
WHERE y IS NOT NULL
)
SELECT
x,
(x * gradient) + intercept AS prediction
FROM linear_regression
CROSS JOIN regression
WHERE y IS NULL;
يعتمد هذا الاستعلام على الدالتين regr_slope() وregr_intercept() لتقدير الميل والجزء الثابت. وهما يقابِلان مباشرةً القيمتين m وc في المعادلة الخطية.
ماذا يفعل هذا الاستعلام؟
- يستخرج أولاً الصفوف التي تحتوي على قيم معروفة في العمود
y. - يحسب منها خط الانحدار المناسب.
- ثم يستخدم هذا الخط لتقدير القيم المفقودة في الصفوف التي تحتوي على
NULL.
النتيجة النهائية ستكون مجموعة النقاط التي كانت مجهولة سابقاً، مع قيمة متوقعة للعمود y بناءً على قيمة x.
متى يكون الانحدار الخطي مناسباً؟
يكون هذا الأسلوب مناسباً عندما تكون العلاقة بين المتغيرات تقريباً خطية، مثل التنبؤ بسعر بناءً على مساحة، أو توقّع قيمة كمية بالاعتماد على مؤشر واحد أو أكثر في نماذج أبسط.
خوارزمية K-Nearest Neighbours للتصنيف داخل PostgreSQL
تُعد خوارزمية K-Nearest Neighbours أو KNN من أشهر خوارزميات التصنيف الموجّه Supervised Classification. فكرتها بسيطة: إذا أردت تصنيف نقطة جديدة، فانظر إلى أقرب النقاط المعروفة إليها، ثم اختر الفئة الأكثر تكراراً بينها.
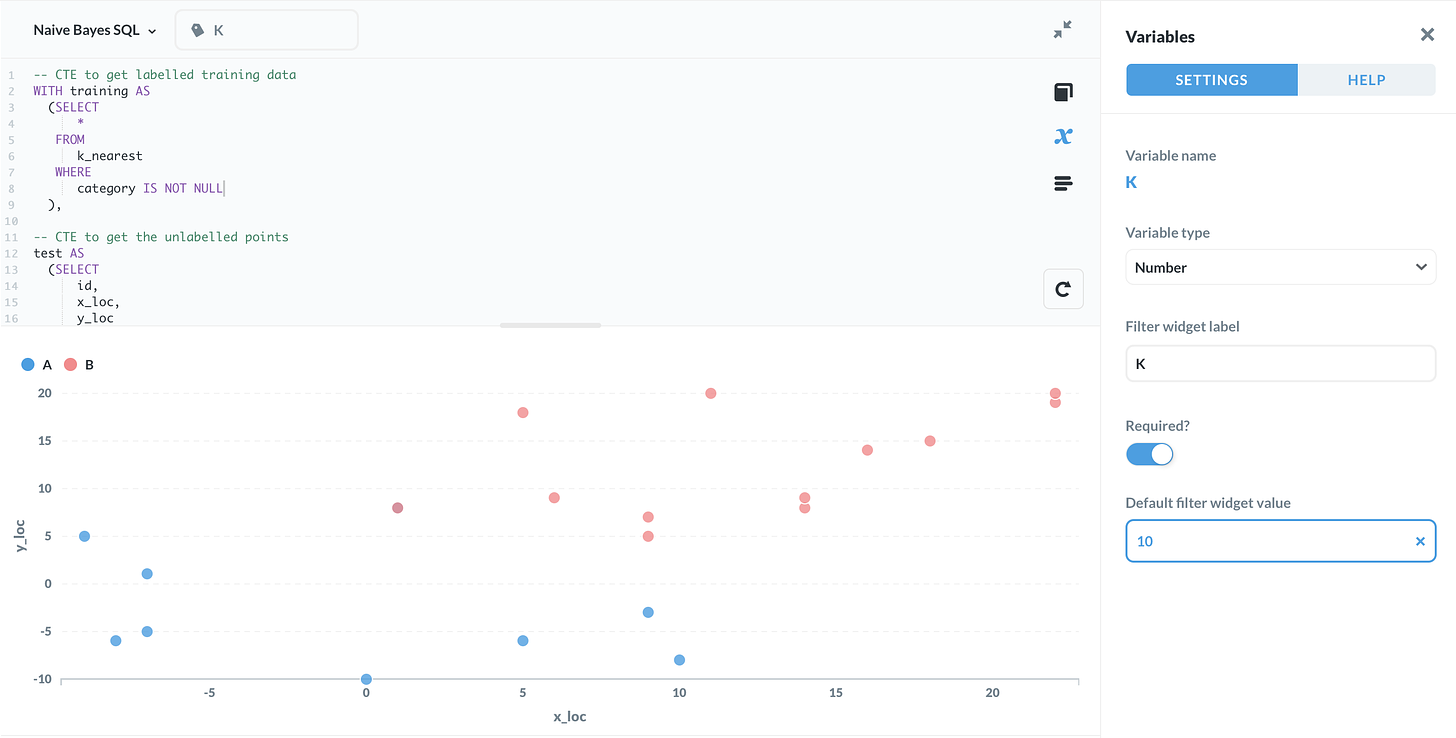
عدد الجيران الذين سنعتمد عليهم تحدده القيمة K. وإذا كان لدينا جدول يحوي الأعمدة id وx_loc وy_loc وcategory، وكانت بعض قيم category مفقودة، فيمكننا تصنيف هذه الصفوف المجهولة باستخدام أقرب الجيران.
-- CTE to get labelled training data
WITH training AS (
SELECT id, POINT(x_loc, y_loc) as xy, category
FROM k_nearest
WHERE category IS NOT NULL
),
-- CTE to get the unlabelled points
test AS (
SELECT id, POINT(x_loc, y_loc) as xy, category
FROM k_nearest
WHERE category IS NULL
),
-- calculate distances between unlabelled & labelled points
distances AS (
SELECT
test.id,
training.category,
test.xy <-> training.xy AS dist,
ROW_NUMBER() OVER (
PARTITION BY test.id
ORDER BY test.xy <-> training.xy
) AS row_no
FROM test
CROSS JOIN training
ORDER BY 1, 4 ASC
),
-- count the 'votes' per label for each unlabelled point
votes AS (
SELECT
id,
category,
count(*) AS votes
FROM distances
WHERE row_no <= {{K}}
GROUP BY 1, 2
ORDER BY 1
)
-- query for the label with the most votes
SELECT v.id, v.category
FROM votes v
JOIN (
SELECT id, max(votes) AS max_votes
FROM votes
GROUP BY 1
) mv
ON v.id = mv.id
AND v.votes = mv.max_votes
ORDER BY 1 ASC;
في هذا المثال، تمت كتابة قيمة K على شكل متغير {{K}} حتى يمكن تعديلها بسهولة في أدوات مثل Metabase.
كيف تعمل الخوارزمية هنا؟
- فصل البيانات المعروفة الفئة عن البيانات المجهولة.
- تمثيل كل نقطة باستخدام النوع الهندسي
POINT(). - حساب المسافة بين كل نقطة مجهولة وكل نقطة معروفة باستخدام عامل المسافة في
PostgreSQL. - ترتيب الجيران حسب القرب.
- اختيار أقرب
Kنقاط. - حساب عدد الأصوات لكل فئة، ثم إسناد الفئة الأعلى تصويتاً.
الناتج سيكون معرف كل نقطة مجهولة مع الفئة المتوقعة لها.
ملاحظة تقنية مهمة
اختيار قيمة K يؤثر مباشرة في جودة التصنيف. قيمة صغيرة قد تجعل النموذج حساساً للضجيج، بينما قد تؤدي قيمة كبيرة إلى تعميم مفرط. لذلك من الأفضل تجربة أكثر من قيمة قبل اعتماد النتيجة.
تصنيف Naive Bayes للنصوص باستخدام SQL
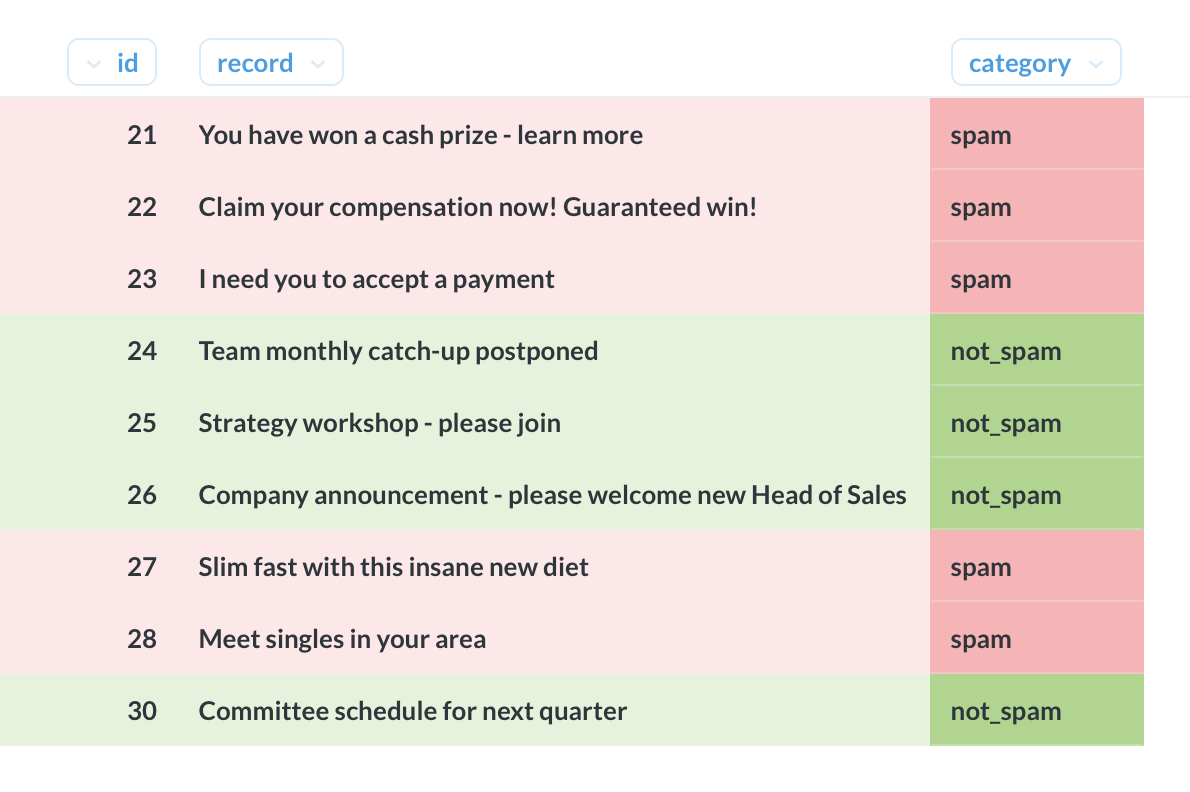
يُستخدم Naive Bayes كثيراً في مهام تصنيف النصوص، مثل اكتشاف الرسائل المزعجة، وتصنيف المستندات، وتحليل المشاعر. تعتمد الفكرة على قاعدة بايز لربط احتمال الفئة عند معرفة البيانات باحتمال البيانات عند معرفة الفئة.
إذا كان لدينا جدول بالأعمدة id وrecord وcategory، حيث يحتوي العمود record على نص، ويحتوي العمود category على الفئة، فيمكننا استخدام الصفوف المصنّفة لتوقّع فئة الصفوف التي تحتوي على NULL.
-- CTE to create one row per word
WITH staging AS (
SELECT
REGEXP_SPLIT_TO_TABLE(LOWER(record), '[^a-z]+') AS word,
category
FROM naive_bayes
WHERE category IS NOT NULL
),
-- testing data
test AS (
SELECT id, record
FROM naive_bayes
WHERE category is NULL
),
-- one row per word + category
cartesian AS (
SELECT *
FROM (
SELECT DISTINCT word FROM staging
) w
CROSS JOIN (
SELECT DISTINCT category FROM staging
) c
WHERE length(word) > 0
),
-- CTE of smoothed frequencies of each word by category
frequencies AS (
SELECT
c.word,
c.category,
-- numerator plus one
(
SELECT count(*) + 1
FROM staging s
WHERE s.word = c.word
AND s.category = c.category
) /
-- denominator plus two
(
SELECT count(*) + 2
FROM staging s1
WHERE s1.category = c.category
)::DECIMAL AS freq
FROM cartesian c
),
-- for each row in testing, get the probabilities
probabilities AS (
SELECT
t.id,
f.category,
SUM(LN(f.freq)) AS probability
FROM (
SELECT
id,
REGEXP_SPLIT_TO_TABLE(LOWER(record), '[^a-z]+') AS word
FROM test
) t
JOIN (
SELECT word, category, freq
FROM frequencies
) f
ON t.word = f.word
GROUP BY 1, 2
)
-- keep only the highest estimate
SELECT record, probabilities.category
FROM probabilities
JOIN (
SELECT id, max(probability) AS max_probability
FROM probabilities
GROUP BY 1
) p
ON probabilities.id = p.id
AND probabilities.probability = p.max_probability
JOIN test
ON probabilities.id = test.id
ORDER BY 1;
فهم خطوات التنفيذ
- تقسيم النص إلى كلمات باستخدام
REGEXP_SPLIT_TO_TABLE(). - تحويل جميع الكلمات إلى أحرف صغيرة عبر
LOWER(). - حساب تكرار كل كلمة داخل كل فئة.
- تطبيق تمهيد احتمالي
Smoothingلتجنب الأصفار في الاحتمالات. - حساب مجموع اللوغاريتمات بواسطة
LN()بدلاً من ضرب احتمالات صغيرة جداً. - اختيار الفئة التي تملك أعلى احتمال لكل سجل.
الناتج النهائي هو كل سجل نصي غير مصنّف مع الفئة المتوقعة له.
يجدر التنبيه إلى أن هذا المثال مبسط عمداً. فالمعالجة النصية هنا تقتصر على الاحتفاظ بالحروف الإنجليزية من A-Z وتحويل النص إلى أحرف صغيرة. كما أنه يفترض تساوي الاحتمال القبلي لجميع الفئات، أي أن كل فئة متساوية الاحتمال قبل النظر إلى البيانات.
متى يفيد هذا النهج؟
يكون هذا الأسلوب مفيداً عند الحاجة إلى تصنيف بيانات نصية بسيطة مباشرة من داخل قاعدة البيانات، مثل عناوين الرسائل أو الوسوم أو الأوصاف القصيرة، خاصة عندما لا تريد إنشاء خط معالجة خارجي معقد.
التجميع باستخدام K-means داخل قواعد البيانات
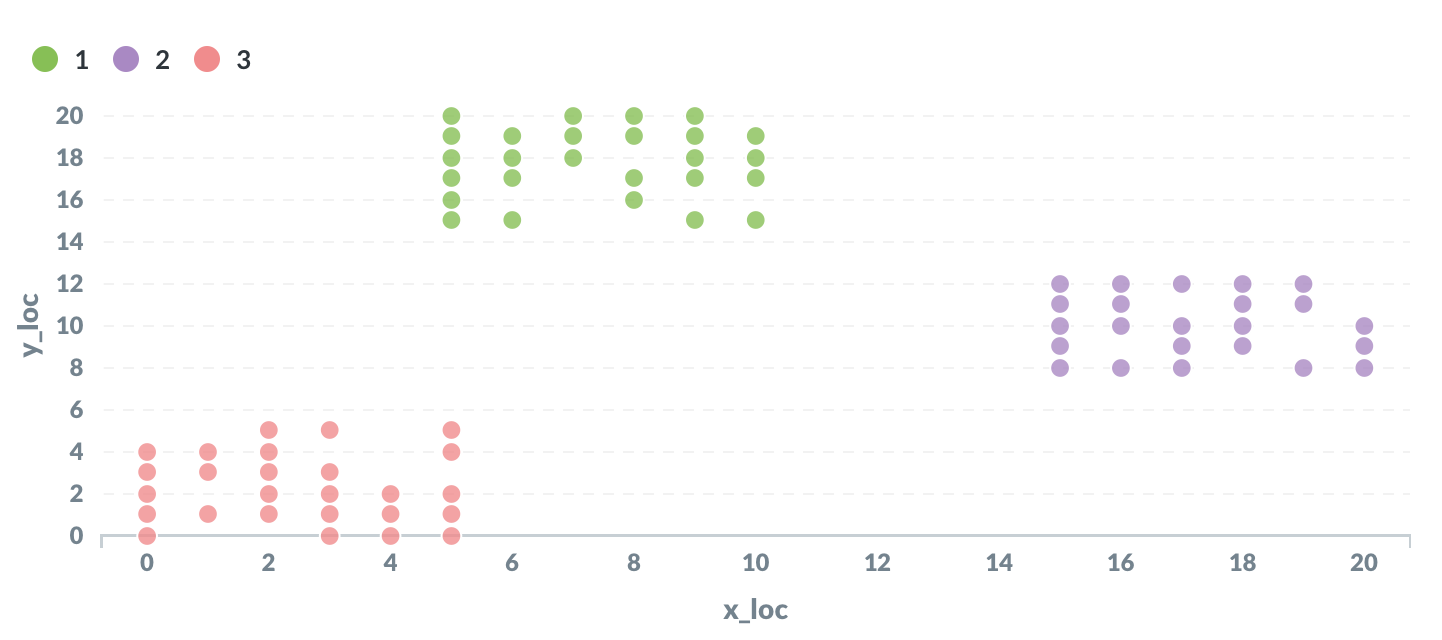
خوارزمية K-means من أشهر خوارزميات التجميع Clustering. وعلى عكس خوارزميات التصنيف الموجّه، فهي خوارزمية غير موجّهة Unsupervised، أي أنها لا تحتاج إلى بيانات تدريبية مصنّفة مسبقاً.
تعمل الخوارزمية عبر تمثيل كل سجل كنقطة في الفضاء، ثم توزيع النقاط أولياً على K مجموعات. بعد ذلك تُحسب مراكز هذه المجموعات، ثم يُعاد إسناد كل نقطة إلى أقرب مركز. تتكرر العملية حتى الوصول إلى حالة مستقرة أو حتى عدد معين من التكرارات.
إذا كان لدينا جدول بالأعمدة id وx_loc وy_loc، فيمكننا تقسيم النقاط إلى K عناقيد كما يلي:
WITH points AS (
SELECT id, POINT(x_loc, y_loc) AS xy
FROM k_means_clustering
),
initial AS (
SELECT RANK() OVER (ORDER BY random()) AS cluster, xy
FROM points
LIMIT {{K}}
),
iteration AS (
WITH RECURSIVE kmeans(iter, id, cluster, avg_point) AS (
SELECT 1, NULL::INTEGER, *
FROM initial
UNION ALL
SELECT iter + 1, id, cluster, midpoint
FROM (
SELECT DISTINCT ON (iter, id) *
FROM (
SELECT
iter,
cluster,
p.id,
p.xy <-> k.avg_point AS distance,
@@ LSEG(p.xy, k.avg_point) AS midpoint,
p.xy,
k.avg_point
FROM points p
CROSS JOIN kmeans k
) d
ORDER BY 1, 3, 4
) r
WHERE iter < {{max_iter}}
)
SELECT * FROM kmeans
)
SELECT k.*, cluster
FROM iteration i
JOIN k_means_clustering k USING (id)
WHERE iter = {{max_iter}}
ORDER BY 4, 1 ASC;
ما الذي يميز هذا التنفيذ؟
- استخدام الأنواع الهندسية في
PostgreSQLمثلPOINTوLSEG. - الاستفادة من الاستعلامات التكرارية عبر
WITH RECURSIVE. - إمكانية التحكم في عدد العناقيد من خلال المتغير
{{K}}. - إمكانية ضبط الحد الأقصى للتكرارات بواسطة
{{max_iter}}.
هذا التنفيذ لا يتوقف عند ثبات التعيينات فعلياً، بل يعتمد عدداً محدداً مسبقاً من التكرارات، وهي مقاربة مناسبة للتجارب والفهم، لكنها ليست المثالية دائماً للإنتاج.
متى تستخدم K-means داخل SQL؟
يمكن الاستفادة منها في تقسيم العملاء إلى مجموعات، أو تجميع المواقع الجغرافية، أو تحليل سلوك الاستخدام، خاصة عندما تكون البيانات عددية ومخزنة داخل قاعدة البيانات وترغب في تنفيذ تحليل أولي سريع دون تصديرها.
لماذا قد يكون تنفيذ ML داخل SQL مفيداً؟
- تقليل الحاجة إلى نقل البيانات بين الأنظمة.
- الاستفادة من بنية قاعدة البيانات الحالية وأذوناتها وفهارسها.
- تسريع التجارب الأولية
Prototyping. - تبسيط خطوط العمل عندما تكون النماذج المطلوبة أساسية أو تفسيرية.
- تعميق الفهم النظري للخوارزميات من خلال بنائها يدوياً.
قيود يجب الانتباه لها قبل الاعتماد على هذا النهج
رغم قوة الفكرة، فإن تنفيذ تعلّم الآلة مباشرة داخل SQL ليس مناسباً لكل الحالات. فمع ازدياد تعقيد البيانات أو الحاجة إلى تحسين الأداء أو استخدام نماذج متقدمة، يصبح الاعتماد على أدوات متخصصة مثل Python ومكتباته أمراً أكثر عملية.
- الأمثلة التعليمية لا تعني جاهزية كاملة للإنتاج.
- إدارة النماذج وتقييمها داخل
SQLقد تكون أكثر صعوبة. - الخوارزميات المتقدمة تحتاج غالباً إلى بيئات تحليلية أوسع.
- المعالجة المسبقة للبيانات، خصوصاً النصية، تكون محدودة مقارنة بالأدوات المتخصصة.
الخلاصة التقنية
يوضح هذا النهج أن SQL ليس مجرد أداة للاستعلام عن البيانات، بل يمكن أن يتحول إلى بيئة تحليلية قوية تدعم مفاهيم مهمة من Machine Learning. تقنياً، يُعد استخدام PostgreSQL في مثل هذه السيناريوهات خياراً ذكياً للتجارب السريعة، والتعليم، وبناء نماذج أولية قريبة من مصدر البيانات. لكن كلما ارتفع مستوى التعقيد أو متطلبات الأداء، يصبح من الأفضل الدمج بين قاعدة البيانات وأدوات تعلم الآلة المتخصصة بدلاً من الاعتماد على SQL وحده.