هل أخطأ مالكوم غلادويل في قراءة البيانات فعلًا؟ تحليل تقني لبيانات لاعبي الهوكي
في عالم تحليل البيانات، قد تبدو بعض الأفكار الشائعة صحيحة حتى نختبرها بالأرقام. في هذا المقال، نستعرض تجربة عملية تجمع بين الرياضة وتحليل البيانات للإجابة عن سؤال مثير: هل يؤثر توقيت الميلاد خلال السنة في فرص الوصول إلى مستوى النخبة الرياضية؟

الفكرة هنا ليست مجرد إعادة طرح رأي مشهور، بل فحصه عمليًا بالاعتماد على بيانات فعلية من دوري الهوكي الوطني. كما أن هذا المثال يوضح درسًا مهمًا لكل من يعمل في التحليل: امتلاك البيانات وحده لا يكفي، بل يجب أيضًا اختيار الأداة الصحيحة لقراءتها وتمثيلها بصريًا.
هذه التجربة مناسبة لمن لديه أساس جيد في Python وأدوات تحليل البيانات، ويرغب في رؤية مثال واقعي يربط بين جمع البيانات، تنظيفها، وتحويلها إلى استنتاجات قابلة للنقاش.
هل يؤثر شهر الميلاد في النجاح الرياضي؟
السؤال الذي يدور حوله المقال بسيط ظاهريًا، لكنه غني من الناحية التحليلية: هل يكون الرياضي أكثر حظًا في الوصول إلى المستويات الاحترافية إذا وُلد في الأشهر الأولى من السنة؟
تستند هذه الفرضية إلى طريقة تنظيم كثير من الرياضات السنية، حيث يُحدد حد فاصل عمري سنوي ينتهي غالبًا في يوم 31 December. هذا يعني أن الأطفال المولودين في بداية السنة يكونون، داخل الفئة العمرية نفسها، أكبر عمرًا من أقرانهم المولودين في نهايتها بعدة أشهر. وفي الأعمار الصغيرة، قد تُحدث هذه الأشهر فارقًا واضحًا في:
- البنية الجسدية.
- التناسق الحركي.
- القوة والتحمل.
- فرص لفت انتباه المدربين والكشافين.
ومع مرور الوقت، قد تتحول هذه الأفضلية المبكرة إلى فرص تدريب أفضل، ومشاركة أكبر، وتطوير أسرع، وهو ما يعزز احتمالات الصعود إلى مستويات أعلى.
ما علاقة مالكوم غلادويل بهذه الفكرة؟
ارتبطت هذه الفرضية باسم الكاتب المعروف Malcolm Gladwell، خاصة بعد تناوله لها في كتاب Outliers. لكن الفكرة في أصلها لا تعود إليه مباشرة، بل إلى الباحث النفسي Roger Barnesley، الذي لاحظ نمطًا غير معتاد في تواريخ ميلاد لاعبي هوكي ناشئين في إحدى المباريات.
الملاحظة كانت لافتة: عدد كبير من اللاعبين المميزين وُلدوا في بدايات السنة. ومن هنا ظهر التساؤل: هل ما نراه مجرد صدفة مثيرة للاهتمام، أم أن البيانات الواسعة تدعم هذا التصور فعلًا؟
من أين يمكن الحصول على بيانات لاعبي NHL؟
لإجراء اختبار عملي، يمكن الاستفادة من واجهة برمجة تطبيقات غير موثقة رسميًا ولكنها فعالة تابعة لدوري الهوكي الوطني NHL API. هذه الواجهة تتيح الوصول إلى معلومات الفرق واللاعبين بصيغة JSON.
على سبيل المثال، هذا الرابط يعرض قائمة فريق Washington Capitals:
https://statsapi.web.nhl.com/api/v1/teams/15/rosterوعند تغيير رقم الفريق داخل الرابط، مثل استبدال 15 بـ 10، يمكن جلب بيانات فريق آخر مثل Toronto Maple Leafs.
هذه البنية مفيدة جدًا لأنها تسمح ببناء سكربت يجمع:
- قوائم اللاعبين لكل فريق.
- المعرف الفريد لكل لاعب
player ID. - تاريخ ميلاد كل لاعب من صفحته الخاصة في الواجهة.
استخدام Python لاستخراج أشهر ميلاد اللاعبين
الفكرة البرمجية تعتمد على المرور على الفرق، ثم استخراج قائمة اللاعبين، وبعدها الاستعلام عن صفحة كل لاعب للحصول على تاريخ الميلاد. ثم يُستخرج رقم الشهر ويُحفظ في إطار بيانات Pandas DataFrame لتحليله لاحقًا.
فيما يلي الكود كما هو:
import pandas as pd
import requests
import json
import matplotlib.pyplot as plt
import numpy as np
df3 = pd.DataFrame(columns=['months'])
for team_id in range(1, 11, 1):
url = 'https://statsapi.web.nhl.com/api/v1/teams/{}/roster'.format(team_id)
r = requests.get(url)
roster_data = r.json()
df = pd.json_normalize(roster_data['roster'])
for index, row in df.iterrows():
newrow = row['person.id']
url = 'https://statsapi.web.nhl.com/api/v1/people/{}'.format(newrow)
newerdata = requests.get(url)
player_stats = newerdata.json()
birthday = (player_stats['people'][0]['birthDate'])
newmonth = int(birthday.split('-')[1])
df3 = df3.append({'months': newmonth}, ignore_index=True)
df3.months.hist()ملاحظات مهمة قبل تشغيل السكربت
رغم أن الكود يؤدي المهمة، إلا أن هناك نقاطًا تقنية يجب الانتباه لها:
- وجود حلقات
forمتداخلة يعني تنفيذ عدد كبير من الطلبات على واجهةAPI، وقد يتجاوز ذلك ألف طلب في تشغيل واحد. - أي خطأ بسيط في المنطق أو التكرار قد يسبب ضغطًا غير ضروري على المصدر.
- النطاق
for team_id in range(1, 11, 1):لا يشمل جميع فرق الدوري، بل جزءًا منها فقط. - بعض نقاط النهاية
endpointsقد لا تستجيب بشكل متوقع، وهو ما قد يؤدي إلى توقف السكربت.
ومن الجيد بعد جمع البيانات تصديرها إلى ملف CSV حتى لا تضطر إلى إعادة الاتصال بالواجهة كل مرة. يمكن تنفيذ ذلك عبر:
df3.to_csv('player_data.csv')تصوير البيانات الخام: هل الرسم الأول يعطينا الحقيقة؟
بعد جمع أشهر ميلاد ما يقارب 1100 لاعب حالي في NHL، تأتي خطوة التصوير البياني لرؤية النمط العام.
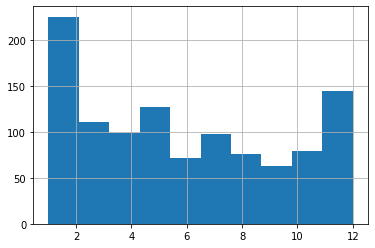
عند النظر إلى المدرج التكراري الأول، قد يبدو أن شهري January وDecember يملكان حضورًا مرتفعًا، وأن النمط ليس واضحًا بما يكفي لدعم فرضية غلادويل. لكن هذا الاستنتاج متسرع.
السبب أن الإعدادات الافتراضية للرسم قد لا تكون مناسبة لطبيعة البيانات. فبدل عرض الأشهر الاثني عشر بوضوح، ظهر الرسم بعدد أعمدة أقل، ما يشير إلى أن طريقة تقسيم البيانات لم تكن مثالية لهذا الاستخدام.
قراءة القيم الفعلية بدل الاكتفاء بالشكل البصري
للتأكد من التوزيع الحقيقي، من الأفضل الرجوع إلى القيم المباشرة داخل الملف الذي تم حفظه مسبقًا:
import pandas as pd
df = pd.read_csv('player_data.csv')
df['months'].value_counts()وكانت النتيجة على النحو التالي:
Month Frequency
5 127
2 121
3 111
1 104
4 99
7 98
10 79
8 76
12 75
6 71
11 69
9 63هنا تتغير الصورة بالكامل. يتضح أن:
- شهر
Mayسجّل127حالة. - شهر
Februaryسجّل121حالة. - شهر
Marchسجّل111حالة. - شهر
Decemberلم يسجل سوى75حالة.
وبذلك يظهر أن الأشهر ذات التكرار الأعلى تتركز فعلًا في النصف الأول من السنة، وهو ما ينسجم مع الفرضية الأصلية بدرجة ملحوظة.
ما المشكلة في المدرج التكراري الافتراضي؟
المدرج التكراري Histogram لا يعرض كل قيمة منفصلة بالضرورة، بل يجمع القيم داخل فئات تسمى bins. وعندما يكون عدد هذه الفئات غير مناسب، فقد تنتج صورة بصرية مضللة أو على الأقل غير دقيقة بما يكفي لاتخاذ استنتاج واضح.
لتحسين التمثيل، يمكن تحديد 12 bins يدويًا، أي فئة لكل شهر:
import pandas as pd
df = pd.read_csv('player_data.csv')
df.hist(column='months', bins=12);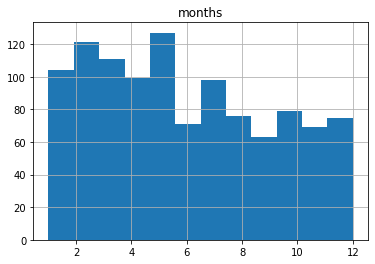
النتيجة هنا أقرب إلى التمثيل المنطقي للبيانات، لأن كل شهر أصبح ممثلًا بشكل أوضح. ومع ذلك، يظل السؤال: هل Histogram هو الأداة المثالية أصلًا في هذا النوع من البيانات؟
اختيار الأداة الصحيحة: لماذا قد يكون الرسم الشريطي أفضل؟
رغم فائدة المدرجات التكرارية في فهم التوزيعات الإحصائية، فإنها ليست دائمًا الخيار الأنسب للبيانات الفئوية المحددة مثل أشهر السنة. في هذه الحالة، يكون الرسم الشريطي Bar Chart أوضح وأسهل في القراءة.
يمكن إنشاء رسم شريطي باستخدام groupby() وcount() كما يلي:
df.groupby('months').count().plot(kind='bar')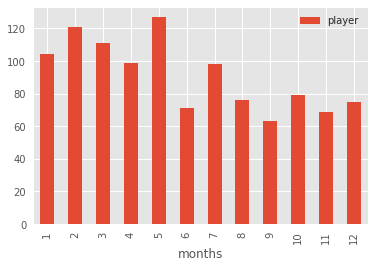
هذا الرسم يقدم صورة مباشرة وموثوقة نسبيًا، ويُظهر بوضوح أن الأشهر الخمسة الأولى من السنة تحتل المراتب الأعلى من حيث عدد اللاعبين.
متى تستخدم Histogram ومتى تستخدم Bar Chart؟
| الأداة | الاستخدام الأنسب | ملاحظة |
|---|---|---|
Histogram |
عرض توزيع القيم الرقمية ضمن نطاقات | مفيد للبيانات المستمرة، لكنه قد يربك عند تمثيل فئات محددة |
Bar Chart |
مقارنة فئات منفصلة مثل الأشهر أو الأقسام | أوضح بصريًا عندما تكون كل قيمة تمثل فئة مستقلة |
دروس مهمة من هذا المثال التحليلي
- البيانات وحدها لا تكفي إذا كان تمثيلها البصري غير مناسب.
- الإعدادات الافتراضية في الأدوات التحليلية ليست دائمًا الأفضل.
- العودة إلى القيم الخام خطوة أساسية قبل تبني أي استنتاج.
- اختيار الرسم البياني الصحيح قد يغير الفهم بالكامل.
- التحليل الجيد لا يكتفي بإثبات الفرضية أو نفيها، بل يراجع طريقة الوصول إلى النتيجة.
الخلاصة التقنية
توضح هذه التجربة أن فرضية تأثير شهر الميلاد في فرص النجاح الرياضي ليست مجرد قصة جذابة، بل فكرة يمكن أن تجد دعمًا في البيانات عند تحليلها بالشكل الصحيح. الدرس الأهم هنا ليس فقط أن Malcolm Gladwell ربما لم يكن مخطئًا، بل أن قراءة البيانات تتطلب وعيًا عميقًا بالأداة المستخدمة. في التحليل التقني، قد يقودك رسم غير مناسب إلى استنتاج خاطئ، بينما يكشف فحص القيم الخام واستخدام تمثيل بصري أدق عن الحقيقة بشكل أوضح وأكثر مهنية.