هل أخطأ مالكوم غلادويل في قراءة البيانات فعلًا؟ تحليل تقني لبيانات لاعبي الهوكي باستخدام بايثون
في عالم تحليل البيانات، تبدو بعض الأفكار الشائعة مقنعة جدًا إلى أن نضعها تحت اختبار الأرقام. في هذا المقال، نستعرض تجربة عملية تجمع بين الرياضة وتحليل البيانات، للتحقق من فرضية شهيرة تقول إن اللاعبين المولودين في بداية السنة يمتلكون فرصة أكبر للوصول إلى مستويات احترافية في الرياضات التنافسية.

الفكرة هنا لا تتعلق فقط بإثبات صحة رأي أو نفيه، بل بفهم كيفية جمع البيانات، ومعالجتها، واختيار أداة التصور المناسبة لها. وهذا بالضبط ما يجعل هذا النوع من المحتوى مفيدًا لكل من يهتم بتحليل البيانات، أو البرمجة، أو حتى بفهم كيفية قراءة الرسوم البيانية بشكل صحيح.
ما هي فرضية تأثير شهر الميلاد في الرياضة؟
السؤال المركزي بسيط: هل تزداد فرص النجاح الرياضي الاحترافي إذا كان تاريخ ميلاد اللاعب يقع في الأشهر الأولى من السنة؟
هذه الفرضية ترتبط بما يُعرف بتأثير العمر النسبي، حيث تُقسَّم الفئات العمرية في كثير من الرياضات الشبابية وفق تاريخ حدّي سنوي مثل 31 December. ونتيجة لذلك، قد يتنافس طفل وُلد في شهر يناير مع آخر وُلد في نوفمبر من العام نفسه، رغم أن الفارق العمري بينهما قد يصل إلى قرابة سنة كاملة.
في المراحل العمرية المبكرة، يمكن لهذا الفارق أن يؤثر بشكل واضح في:
- القوة البدنية
- الحجم والبنية الجسدية
- التناسق الحركي
- الجاهزية الذهنية والثقة بالنفس
ومع مرور الوقت، قد يحصل اللاعب الأكبر نسبيًا على فرص تدريب أفضل، واهتمام أكبر من المدربين، ومسار تطوير أسرع من أقرانه الأصغر سنًا.
علاقة مالكوم غلادويل بهذه الفكرة
ارتبط اسم الكاتب والمفكر Malcolm Gladwell بهذه الفرضية بعد أن تناولها في كتابه Outliers. لكن الإشارة الأولى للفكرة لم تكن من ابتكاره، بل تعود إلى عالم النفس Roger Barnsley، الذي لاحظ نمطًا غير معتاد في تواريخ ميلاد لاعبي هوكي شباب ضمن بطولة نخبوية.
السؤال الذي يفرض نفسه هنا: هل كانت تلك الملاحظة مجرد انطباع مثير للاهتمام، أم أن بيانات العالم الحقيقي تدعمها فعلًا؟
من أين يمكن الحصول على بيانات لاعبي دوري الهوكي؟
لإجراء اختبار عملي، يمكن الاستفادة من واجهة برمجة تطبيقات غير موثقة رسميًا لكنها فعالة وتتبع دوري الهوكي الوطني NHL API. هذه الواجهة تتيح الوصول إلى بيانات الفرق واللاعبين بصيغة JSON.
على سبيل المثال، الرابط التالي يعرض قائمة الفريق الرسمية لفريق Washington Capitals:
https://statsapi.web.nhl.com/api/v1/teams/15/rosterوعند تغيير رقم الفريق داخل الرابط، مثل استبدال 15 بـ 10، يمكن استرجاع بيانات فريق آخر مثل Toronto Maple Leafs.
هذا الأسلوب يفتح الباب أمام جمع بيانات اللاعبين، ثم استخراج معرف كل لاعب player ID، ومنه الوصول إلى صفحة البيانات الخاصة به لمعرفة تاريخ ميلاده.
كيفية استخدام بايثون لاستخراج بيانات تواريخ الميلاد
الفكرة التقنية تعتمد على المرور على قوائم الفرق، ثم قراءة قائمة اللاعبين، وبعدها تنفيذ طلب منفصل لكل لاعب للحصول على بياناته الشخصية، واستخراج شهر الميلاد من الحقل birthDate.
الكود التالي يوضح الآلية المستخدمة:
import pandas as pd
import requests
import json
import matplotlib.pyplot as plt
import numpy as np
df3 = pd.DataFrame(columns=['months'])
for team_id in range(1, 11, 1):
url = 'https://statsapi.web.nhl.com/api/v1/teams/{}/roster'.format(team_id)
r = requests.get(url)
roster_data = r.json()
df = pd.json_normalize(roster_data['roster'])
for index, row in df.iterrows():
newrow = row['person.id']
url = 'https://statsapi.web.nhl.com/api/v1/people/{}'.format(newrow)
newerdata = requests.get(url)
player_stats = newerdata.json()
birthday = (player_stats['people'][0]['birthDate'])
newmonth = int(birthday.split('-')[1])
df3 = df3.append({'months': newmonth}, ignore_index=True)
df3.months.hist()ملاحظات مهمة قبل تشغيل السكربت
- الكود يحتوي على حلقات متداخلة
nested for loops، ما يعني أنه قد يرسل عددًا كبيرًا جدًا من الطلبات إلى الواجهةAPI. - تشغيل السكربت مرة واحدة قد ينتج عنه أكثر من ألف طلب، لذلك يجب استخدامه بحذر لتجنب الضغط غير الضروري على المصدر.
- النطاق
for team_id in range(1, 11, 1)لا يشمل كل فرق الدوري، بل يغطي جزءًا منها فقط. - بعض نقاط النهاية
endpointsقد لا تستجيب أحيانًا، وقد يؤدي ذلك إلى توقف السكربت. - إذا كررت التنفيذ، فمن الأفضل عدم إعادة تهيئة إطار البيانات
DataFrameبالسطرdf3 = pd.DataFrame(columns=['months'])في كل مرة، حتى لا تفقد البيانات المجمعة سابقًا. - من المفيد حفظ النتائج في ملف
CSVعبرdf3.to_csv('player_data.csv')لمتابعة التحليل لاحقًا دون الحاجة إلى إعادة سحب البيانات من الواجهة.
التصور الأولي للبيانات: هل يكفي المدرج التكراري؟
بعد جمع أشهر ميلاد ما يقارب 1,100 لاعب من لاعبي NHL، جاءت الخطوة التالية: عرض البيانات بصريًا لفهم النمط العام.
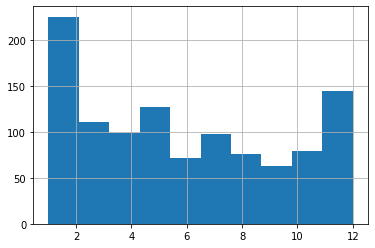
عند النظرة الأولى، قد يبدو أن شهر يناير يمثل نسبة مرتفعة، لكن شهر ديسمبر أيضًا يظهر بشكل لافت. وهذا قد يقود إلى استنتاج سريع مفاده أن الفرضية ليست واضحة كما كان متوقعًا.
لكن هنا تظهر مشكلة شائعة في تحليل البيانات: الرسم البياني ليس دائمًا دليلًا كافيًا إذا لم نفهم طريقة بنائه.
لماذا قد يكون تفسير المدرج التكراري مضللًا؟
المدرج التكراري Histogram لا يعرض دائمًا القيم الفردية كما نتخيل، بل يجمع البيانات ضمن حاويات إحصائية تُسمى bins. وإذا استُخدمت الإعدادات الافتراضية، فقد ينتج عرض لا يعكس التوزيع الحقيقي لشهور السنة بدقة، خاصة إذا كان عدد الأعمدة لا يساوي عدد الفئات الفعلية.
في هذه الحالة، كنا نتعامل مع 12 شهرًا، لكن الرسم الافتراضي لم يعرضها كلها بالشكل المتوقع. لذلك كان من الأفضل الرجوع إلى الأرقام الخام أولًا.
قراءة البيانات من ملف محفوظ
import pandas as pd
df = pd.read_csv('player_data.csv')
df['months'].value_counts()وكانت المخرجات على النحو التالي:
Month Frequency
5 127
2 121
3 111
1 104
4 99
7 98
10 79
8 76
12 75
6 71
11 69
9 63هذه الأرقام تكشف صورة أوضح بكثير. شهر مايو جاء في الصدارة، يليه فبراير ثم مارس ثم يناير ثم أبريل. وبذلك نجد أن الأشهر الخمسة الأولى من السنة تضم أعلى التكرارات، وهو ما يدعم الفرضية الأساسية بدلًا من نفيها.
إعادة رسم المدرج التكراري بطريقة أدق
لتحسين التمثيل البصري، يمكن تحديد عدد الحاويات يدويًا ليطابق عدد أشهر السنة:
import pandas as pd
df = pd.read_csv('player_data.csv')
df.hist(column='months', bins=12);وعندها نحصل على رسم أكثر دقة:
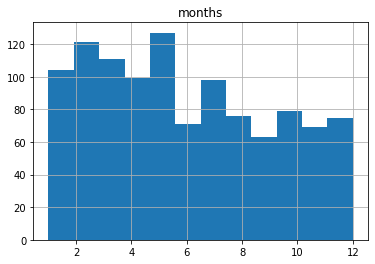
الفرق هنا مهم؛ إذ إن تحديد bins=12 يجعل توزيع الأشهر أقرب إلى الواقع الذي نريد قياسه. ومع ذلك، يظل السؤال الأهم: هل المدرج التكراري أصلًا هو أفضل أداة لعرض هذه البيانات؟
اختيار أداة التصور المناسبة للبيانات
رغم أن Histogram ممتاز لعرض التوزيعات العامة للبيانات الكبيرة، فإنه ليس الخيار الأمثل عندما تكون الفئات منفصلة ومحددة مسبقًا، مثل أشهر السنة من 1 إلى 12.
في هذا النوع من الحالات، يكون المخطط الشريطي Bar Chart أكثر وضوحًا وسهولة في القراءة، لأنه يعرض كل فئة على حدة دون دمج تقريبي.
يمكن إنشاء هذا الرسم باستخدام groupby() وcount() كما يلي:
df.groupby('months').count().plot(kind='bar')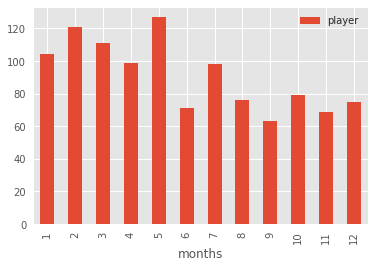
هذا الرسم يوضح النمط بشكل أسهل: التكرارات الأعلى تتركز في الأشهر الأولى من العام، وهو ما ينسجم مع الفرضية القائلة إن تاريخ الميلاد قد يلعب دورًا غير مباشر في فرص التطور الرياضي.
الدروس المستفادة من هذا التحليل
- البيانات الخام قد تقول شيئًا مختلفًا تمامًا عن الانطباع الأول الناتج من الرسم البياني.
- اختيار الأداة التحليلية الخاطئة قد يؤدي إلى استنتاجات غير دقيقة.
- الإعدادات الافتراضية في مكتبات التصور ليست دائمًا مناسبة لكل حالة.
- التحقق من النتائج بالأرقام الفعلية خطوة لا غنى عنها قبل تبني أي استنتاج.
- حتى الفرضيات الشائعة التي تبدو مبالغًا فيها قد تجد دعمًا فعليًا عندما تُختبر بطريقة علمية.
لماذا يهم هذا النوع من التحليل لمتخصصي التقنية؟
هذا المثال ليس مهمًا فقط لمحبي الرياضة، بل أيضًا لكل من يعمل في مجالات تحليل البيانات، وعلوم البيانات، وتطوير البرمجيات، وإعداد التقارير. السبب بسيط: كثير من الأخطاء التحليلية لا تنتج عن نقص البيانات، بل عن سوء قراءتها أو عرضها.
ومن هنا تأتي القيمة الحقيقية لأي تجربة تحليلية ناجحة:
- جمع بيانات موثوقة من مصدر فعلي
- تنظيفها ومعالجتها بطريقة صحيحة
- اختيار نموذج العرض الأنسب
- مراجعة النتائج رقميًا قبل إصدار الحكم
الخلاصة التقنية
الاستنتاج الأهم هنا أن مالكوم غلادويل لم يكن بعيدًا عن الحقيقة كما قد يبدو من النظرة الأولى. المشكلة لم تكن في الفرضية نفسها، بل في طريقة قراءة البيانات وعرضها. تقنيًا، يثبت هذا المثال أن نجاح التحليل لا يعتمد فقط على كتابة كود مثل split() أو استخدام Pandas وMatplotlib، بل على فهم طبيعة البيانات واختيار الأداة البصرية المناسبة لها. باختصار: البيانات قوية، لكن قيمتها الحقيقية تظهر فقط عندما نفسرها بشكل صحيح.