مشروع تعلم الآلة لتحليل البيانات وتنظيفها وبناء نموذج تنبؤ وإنشاء واجهة API

في هذا الدليل العملي سنبني مشروعاً متكاملاً في مجال Machine Learning يبدأ من فهم بيانات أسعار المنازل، ثم إجراء التحليل الاستكشافي، وبعد ذلك تنظيف البيانات، وتدريب نموذج تنبؤ، وأخيراً نشر النموذج عبر واجهة API قابلة للاستخدام. الهدف هنا ليس مجرد تنفيذ خطوات تقنية، بل بناء مسار واضح يمكن الاعتماد عليه في المشاريع الحقيقية.
يعتمد المشروع على مجموعة بيانات خاصة بأسعار المنازل، وسنستخدم أدوات من عالم Data Science لتحويل البيانات الخام إلى نموذج قابل للتشغيل. هذا النوع من المشاريع مهم جداً لأنه يجمع بين التحليل، والهندسة، والنشر، وهي المراحل الأساسية لأي منتج ذكي يعتمد على البيانات.
نظرة عامة على المشروع التقني
يتكوّن المشروع من أربع مراحل رئيسية:
- إجراء تحليل استكشافي للبيانات أو
EDA. - تنظيف البيانات ومعالجة القيم المفقودة.
- تدريب نموذج تعلم آلة للتنبؤ بالأسعار.
- إنشاء واجهة
APIلاستخدام النموذج في التنبؤ الفعلي.
هذا التسلسل مهم لأنه يمنع القفز مباشرة إلى التدريب قبل فهم طبيعة البيانات، وهو خطأ شائع يؤدي غالباً إلى نماذج ضعيفة أو نتائج مضللة.
محتويات المستودع والملفات الأساسية
عند تنزيل المشروع ستجد عدداً من الملفات، ولكل ملف دور واضح في خط العمل:
requirements.txt: الحزم المطلوبة للتثبيت عبرpip.raw_data.csv: البيانات الخام المستخدمة في المشروع.Exploratory-Data-Analysis-House-Prices.ipynb: دفترJupyter Notebookالخاص بالتحليل الاستكشافي.data_cleaning.py: سكربت تنظيف البيانات.train_model.py: سكربت تدريب نموذج تعلم الآلة.predict.py: ملف يحتوي على الفئةHousePriceModelلتحميل النموذج وإجراء التنبؤ.api.py: ملف الواجهة البرمجية المبنية باستخدامFastAPI.test_api.py: سكربت اختبار الواجهة البرمجية.
إعداد البيئة وتثبيت الحزم
من الأفضل دائماً إنشاء بيئة افتراضية لعزل المشروع عن بقية مشاريع Python:
python3 -m venv venvثم فعّل البيئة الافتراضية:
source ./venv/bin/activateبعد ذلك ثبّت الحزم المطلوبة من الملف requirements.txt:
pip install -r requirements.txtعند اكتمال التثبيت بنجاح ستظهر لك رسالة تنتهي عادة بعبارة مشابهة:
Successfully installed Babel-2.9.0 Jinja2-2.11.3 MarkupSafe-1.1.1 Pygments-2.8.0 Send2Trash-1.5.0 anyio-2.1.0 argon2-cffi-20.1.0 async-generator-1.10 attrs-20.3.0 backcall-0.2.0 bleach-3.3.0 certifi-2020.12.5 cffi-1.14.5 chardet-4.0.0 click-7.1.2 decorator-4.4.2 defusedxml-0.6.0 entrypoints-0.3 fastapi-0.63.0 h11-0.12.0 idna-2.10 ipykernel-5.4.3 ipython-7.20.0 ipython-genutils-0.2.0 jedi-0.18.0 joblib-1.0.1 json5-0.9.5 jsonschema-3.2.0 jupyter-client-6.1.11 jupyter-core-4.7.1 jupyter-server-1.3.0 jupyterlab-3.0.7 jupyterlab-pygments-0.1.2 jupyterlab-server-2.2.0 mistune-0.8.4 nbclassic-0.2.6 nbclient-0.5.2 nbconvert-6.0.7 nbformat-5.1.2 nest-asyncio-1.5.1 notebook-6.2.0 numpy-1.20.1 packaging-20.9 pandas-1.2.2 pandocfilters-1.4.3 parso-0.8.1 pexpect-4.8.0 pickleshare-0.7.5 prometheus-client-0.9.0 prompt-toolkit-3.0.16 ptyprocess-0.7.0 pycparser-2.20 pydantic-1.7.3 pyparsing-2.4.7 pyrsistent-0.17.3 python-dateutil-2.8.1 pytz-2021.1 pyzmq-22.0.3 requests-2.25.1 scikit-learn-0.24.1 scipy-1.6.0 six-1.15.0 sniffio-1.2.0 starlette-0.13.6 terminado-0.9.2 testpath-0.4.4 threadpoolctl-2.1.0 tornado-6.1 traitlets-5.0.5 urllib3-1.26.3 uvicorn-0.13.3 wcwidth-0.2.5 webencodings-0.5.1تشغيل التحليل الاستكشافي للبيانات EDA
لفتح دفتر التحليل الاستكشافي استخدم الأمر التالي:
jupyter-notebook Exploratory-Data-Analysis-House-Prices.ipynbبعد فتح الدفتر، شغّل جميع الخلايا من خلال Cell > Run All. هذه المرحلة تساعدك على فهم شكل البيانات، وأنواع الأعمدة، والقيم المفقودة، والعلاقات المحتملة مع متغير الهدف SalePrice.
فهم مشكلة التنبؤ بأسعار المنازل
الفكرة الأساسية في هذه المسألة هي التنبؤ بالسعر النهائي للمنزل اعتماداً على عشرات الخصائص، مثل المساحة، وجود القبو، جودة التشطيبات، نوع المرآب، والموقع. لذلك فالمسألة ليست مبنية على عامل واحد فقط، بل على مجموعة كبيرة من المؤثرات المتداخلة.
في مثل هذه البيانات، قد تبدو بعض الخصائص غير مهمة للوهلة الأولى، لكن التحليل يكشف أن أثرها قد يكون واضحاً عند دمجها مع خصائص أخرى. لهذا السبب يبدأ أي مشروع جيد بفهم البيانات قبل بناء النموذج.
استيراد المكتبات الأساسية
في بداية التحليل تم استخدام عدد من المكتبات الشائعة في تحليل البيانات والتصور:
import math
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inlineتُستخدم مكتبة numpy في العمليات العددية، بينما توفّر pandas أدوات قوية للتعامل مع الجداول. أما matplotlib وseaborn فهما مناسبتان جداً لبناء الرسوم التحليلية التي تسهّل قراءة الأنماط.
تحميل البيانات وإلقاء نظرة أولية
بما أن البيانات مخزنة بصيغة CSV، فيمكن تحميلها باستخدام الدالة read_csv():
train = pd.read_csv('raw_data.csv')
train.shape(1168, 81)هذا يعني أن لدينا 1168 سجلاً و81 عموداً. من المهم هنا التمييز بين الأعمدة الوصفية والأعمدة المستخدمة فعلاً في النمذجة، لأن بعض الأعمدة مثل Id لا تضيف قيمة تنبؤية حقيقية.
ويمكن معاينة أول الصفوف باستخدام head() مع التحويل عبر .T لتسهيل قراءة الأعمدة:
train.head(3).Tفحص بنية البيانات وأنواع الأعمدة
الدالة info() مفيدة جداً لأنها تعرض عدد القيم غير الفارغة ونوع كل عمود:
train.info()من خلال هذه الخطوة يتضح أن بعض الأعمدة تحتوي على عدد كبير من القيم المفقودة مثل Alley وPoolQC وFence. كما نلاحظ وجود أعمدة رقمية وأخرى نصية من النوع object.
أما الدالة describe() فتعرض إحصاءات وصفية أولية مثل المتوسط والانحراف المعياري والحدين الأدنى والأقصى والربيعات:
train.describe().Tهذه القراءة السريعة تساعد على اكتشاف القيم الشاذة وفهم نطاقات المتغيرات المهمة مثل LotArea وGrLivArea وSalePrice.
تنظيف البيانات: القرارات الأهم
حذف الأعمدة غير المفيدة مباشرة
العمود Id مجرد معرف ولا يحمل إشارة تنبؤية حقيقية مرتبطة بالسعر، لذلك تمت إزالته:
train.drop(columns=['Id'], inplace=True)تحديد الأعمدة ذات القيم المفقودة
يمكن حساب الأعمدة التي تحتوي على قيم مفقودة بهذه الطريقة:
columns_with_miss = train.isna().sum()
columns_with_miss = columns_with_miss[columns_with_miss != 0]
print('Columns with missing values:', len(columns_with_miss))
columns_with_miss.sort_values(ascending=False)Columns with missing values: 19بعض الأعمدة تحتوي على حجم مفقود كبير جداً، مثل:
PoolQCMiscFeatureAlleyFence
وبسبب النسبة العالية من القيم المفقودة فيها، تم حذفها في هذه المرحلة لتقليل التشويش وتعقيد المعالجة.
train.drop(columns=['PoolQC', 'MiscFeature', 'Alley', 'Fence'], inplace=True)الاحتفاظ ببعض الأعمدة رغم القيم المفقودة
ليست كل قيمة مفقودة عديمة الفائدة. على سبيل المثال، غياب قيمة في العمود FireplaceQu قد يعني ببساطة أن المنزل لا يحتوي على موقد. وهذا بحد ذاته معلومة مفيدة. لذلك تم تحويل القيم المفقودة إلى 0 ثم ترميز القيم الترتيبية رقمياً:
train['FireplaceQu'].fillna(0, inplace=True)
train['FireplaceQu'].replace({'Po': 1, 'Fa': 2, 'TA': 3, 'Gd': 4, 'Ex': 5}, inplace=True)
يوضح الرسم أن جودة الموقد ترتبط بارتفاع السعر، لذلك كان من المنطقي الإبقاء على هذا المتغير.
حذف بعض الأعمدة الرقمية ذات القيم المفقودة
بعد مراجعة الارتباطات، تقرر حذف الأعمدة التالية لتبسيط النموذج الأولي:
LotFrontageGarageYrBltMasVnrArea
cols_to_be_removed = ['LotFrontage', 'GarageYrBlt', 'MasVnrArea']
train.drop(columns=cols_to_be_removed, inplace=True)هذا لا يعني أن هذه الأعمدة عديمة الفائدة نهائياً، بل يعني أنها أُبعدت في النسخة الأولى من المشروع لتقليل التعقيد وتسريع الوصول إلى نموذج صالح للعمل.
معالجة المتغيرات الفئوية
تعبئة القيم الناقصة في الأعمدة الاسمية
بعض الأعمدة الفئوية يمكن تعويض القيم المفقودة فيها بقيم وصفية مثل NA أو None حسب معنى العمود:
for c in ['GarageType', 'GarageFinish', 'BsmtFinType2', 'BsmtExposure', 'BsmtFinType1']:
train[c].fillna('NA', inplace=True)
train['MasVnrType'].fillna('None', inplace=True)أما العمود Electrical فتم تعويض القيمة المفقودة فيه بأكثر قيمة تكراراً وهي SBrkr:
train['Electrical'].fillna('SBrkr', inplace=True)ترميز الأعمدة الترتيبية
هناك أعمدة فئوية ذات ترتيب منطقي واضح، مثل الجودة أو الحالة، ولذلك يفضّل تحويلها إلى قيم رقمية مرتبة. تم ذلك مع الأعمدة التالية:
ExterQualExterCondBsmtQualBsmtCondHeatingQCKitchenQualGarageQualGarageCond
ord_cols = ['ExterQual', 'ExterCond', 'BsmtQual', 'BsmtCond', 'HeatingQC', 'KitchenQual', 'GarageQual', 'GarageCond']
for col in ord_cols:
train[col].fillna(0, inplace=True)
train[col].replace({'Po': 1, 'Fa': 2, 'TA': 3, 'Gd': 4, 'Ex': 5}, inplace=True)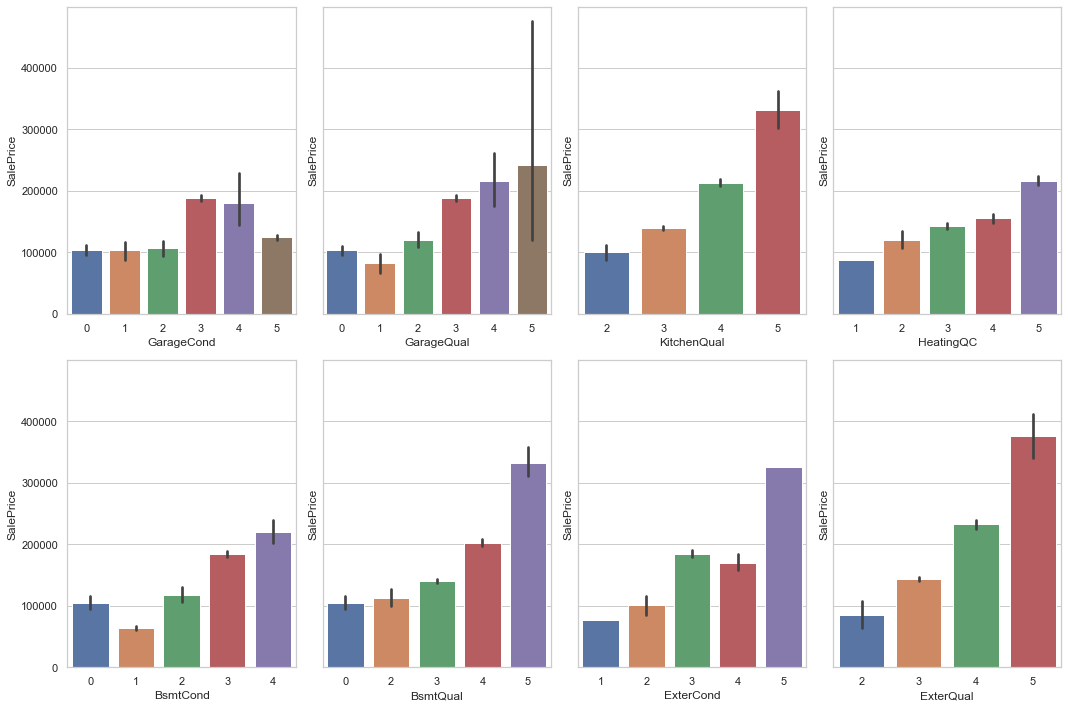
هذا النوع من الترميز يحافظ على المعنى الترتيبي للمتغير، وهو أفضل من معاملته كفئة عشوائية في مثل هذه الحالات.
تحليل المتغيرات الاسمية غير المرتبة
بعض الأعمدة الفئوية لا تحتوي على ترتيب منطقي، مثل Neighborhood أو RoofStyle. لمعرفة عدد القيم المميزة فيها يمكن استخدام الشيفرة التالية:
cols = train.columns
num_cols = train._get_numeric_data().columns
nom_cols = list(set(cols) - set(num_cols))
print(f'Nominal columns: {len(nom_cols)}')
value_counts = {}
for c in nom_cols:
value_counts[c] = len(train[c].value_counts())
sorted_value_counts = {k: v for k, v in sorted(value_counts.items(), key=lambda item: item[1])}
sorted_value_countsNominal columns: 31ولتبسيط التحليل البصري، تم التركيز على الأعمدة التي تمتلك أقل من 7 قيم مختلفة:
nom_cols_less_than_6 = []
for c in nom_cols:
n_values = len(train[c].value_counts())
if n_values < 7:
nom_cols_less_than_6.append(c)
print(f'Nominal columns with less than 6 values: {len(nom_cols_less_than_6)}')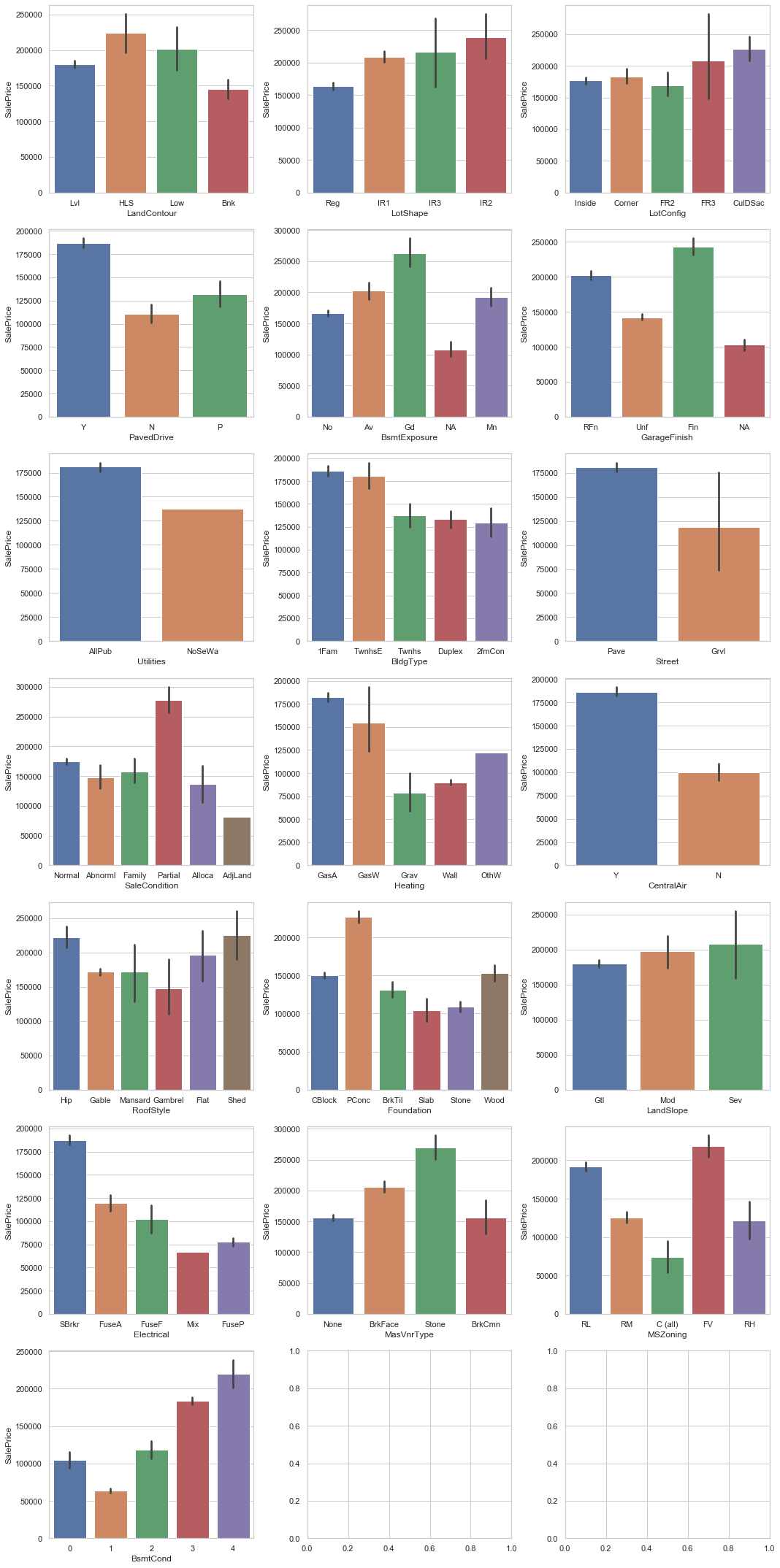
يتضح من الرسوم أن بعض هذه المتغيرات له أثر جيد على السعر، ولذلك تم الإبقاء عليها بدلاً من حذفها بشكل متسرع.
فحص القيم الصفرية والقيم الشاذة
عند مراجعة البيانات قد نجد عدداً كبيراً من القيم الصفرية في أعمدة معينة:
train.isin([0]).sum().sort_values(ascending=False).head(25)لكن وجود القيمة 0 لا يعني بالضرورة أن البيانات سيئة. على سبيل المثال، إذا كان PoolArea يساوي 0 فهذا يعني ببساطة عدم وجود مسبح، وهي معلومة ذات قيمة تنبؤية.
كما تم فحص القيم الشاذة باستخدام مخططات boxplot:
numerical_columns = list(train.dtypes[train.dtypes == 'int64'].index)
len(numerical_columns)rows = 7
columns = 6
fig, axes = plt.subplots(rows, columns, figsize=(30, 30))
x, y = 0, 0
for i, column in enumerate(numerical_columns):
sns.boxplot(x=train[column], ax=axes[x, y])
if y < columns - 1:
y += 1
elif y == columns - 1:
x += 1
y = 0
else:
y += 1
رغم وجود عدد من القيم الشاذة، فقد تقرر الإبقاء عليها لأن بعضها يمثّل حالات حقيقية نادرة، وليس أخطاء إدخال. في مشاريع تعلم الآلة، حذف القيم الشاذة دون فهم سببها قد يؤدي إلى خسارة معلومات مهمة.
حفظ البيانات بعد التنظيف
بعد انتهاء جميع خطوات التنظيف أصبح عدد الأعمدة 73 بدلاً من 81، ولم تعد هناك قيم مفقودة:
columns_with_miss = train.isna().sum()
columns_with_miss = columns_with_miss[columns_with_miss != 0]
print(f'Columns with missing values: {len(columns_with_miss)}')
columns_with_miss.sort_values(ascending=False)Columns with missing values: 0
Series([], dtype: int64)train.shape(1168, 73)ثم يتم حفظ الملف المنظّف:
train.to_csv('train-cleaned.csv')سكربت تنظيف البيانات data_cleaning.py
بعد اتخاذ قرارات التنظيف في التحليل الاستكشافي، من الأفضل تحويلها إلى سكربت ثابت يمكن إعادة تشغيله تلقائياً:
python data_cleaning.pyالناتج المتوقع:
Original Data: (1168, 81)
After Cleaning: (1168, 73)وهذا هو السكربت الكامل:
import os
import pandas as pd
# writes the output on 'cleaned_data.csv' by default
def clean_data(df, output_file='cleaned_data.csv'):
# Removes columns with missing values issues
cols_to_be_removed = ['Id', 'PoolQC', 'MiscFeature', 'Alley', 'Fence', 'LotFrontage', 'GarageYrBlt', 'MasVnrArea']
df.drop(columns=cols_to_be_removed, inplace=True)
# Transforms ordinal columns to numerical
ordinal_cols = ['FireplaceQu', 'ExterQual', 'ExterCond', 'BsmtQual', 'BsmtCond', 'HeatingQC', 'KitchenQual', 'GarageQual', 'GarageCond']
for col in ordinal_cols:
df[col].fillna(0, inplace=True)
df[col].replace({'Po': 1, 'Fa': 2, 'TA': 3, 'Gd': 4, 'Ex': 5}, inplace=True)
# Replace the NaN with NA
for c in ['GarageType', 'GarageFinish', 'BsmtFinType2', 'BsmtExposure', 'BsmtFinType1']:
df[c].fillna('NA', inplace=True)
# Replace the NaN with None
df['MasVnrType'].fillna('None', inplace=True)
# Imputes with most frequent value
df['Electrical'].fillna('SBrkr', inplace=True)
# Saves a copy
cleaned_data = os.path.join(output_file)
df.to_csv(cleaned_data)
return df
if __name__ == "__main__":
# Reads the file train.csv
train_file = os.path.join('train.csv')
if os.path.exists(train_file):
df = pd.read_csv(train_file)
print(f'Original Data: {df.shape}')
cleaned_df = clean_data(df)
print(f'After Cleaning: {cleaned_df.shape}')
else:
print(f'File not found {train_file}')بناء نموذج تعلم الآلة
بعد تجهيز البيانات في الملف cleaned_data.csv، يمكن الانتقال إلى تدريب النموذج. يتم ذلك عبر الملف train_model.py:
python train_model.pyالناتج المتوقع سيكون قريباً من التالي:
Train data for modeling: (934, 73)
Test data for predictions: (234, 73)
Training the model ...
Testing the model ...
Average Price Test: 175652.0128205128
RMSE : 11098.009355519898
Model saved at model.pklفي هذه المرحلة يتم تقسيم البيانات إلى مجموعة تدريب ومجموعة اختبار، ثم تدريب النموذج وقياس أدائه باستخدام مقياس RMSE. هذا المقياس مهم لأنه يعبّر عن متوسط مقدار الخطأ بوحدة السعر نفسها، ما يجعله سهل التفسير عملياً.
لماذا يُعد RMSE مهماً؟
إذا كان متوسط أسعار الاختبار قريباً من 175,000 وكان الخطأ الجذري المتوسط نحو 10,000 أو 11,000، فهذا يعني أن النموذج يخطئ في المتوسط بمقدار معقول نسبياً مقارنة بقيمة الأصل نفسها. وهو أداء جيد كنقطة انطلاق لمشروع أولي.
سكريبت تدريب النموذج train_model.py
import numpy as np
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
import pickle
def create_train_test_data(dataset):
# load and split the data
data_train = dataset.sample(frac=0.8, random_state=30).reset_index(drop=True)
data_test = dataset.drop(data_train.index).reset_index(drop=True)
# save the data
data_train.to_csv('train.csv', index=False)
data_test.to_csv('test.csv', index=False)
print(f"Train data for modeling: {data_train.shape}")
print(f"Test data for predictions: {data_test.shape}")
def train_model(x_train, y_train):
print("Training the model ...")
model = Pipeline(steps=[
("label encoding", OneHotEncoder(handle_unknown='ignore')),
("tree model", LinearRegression())
])
model.fit(x_train, y_train)
return model
def accuracy(model, x_test, y_test):
print("Testing the model ...")
predictions = model.predict(x_test)
tree_mse = mean_squared_error(y_test, predictions)
tree_rmse = np.sqrt(tree_mse)
return tree_rmse
def export_model(model):
# Save the model
pkl_path = 'model.pkl'
with open(pkl_path, 'wb') as file:
pickle.dump(model, file)
print(f"Model saved at {pkl_path}")
def main():
# Load the whole data
data = pd.read_csv('cleaned_data.csv', keep_default_na=False, index_col=0)
# Split train/test
# Creates train.csv and test.csv
create_train_test_data(data)
# Loads the data for the model training
train = pd.read_csv('train.csv', keep_default_na=False)
x_train = train.drop(columns=['SalePrice'])
y_train = train['SalePrice']
# Loads the data for the model testing
test = pd.read_csv('test.csv', keep_default_na=False)
x_test = test.drop(columns=['SalePrice'])
y_test = test['SalePrice']
# Train and Test
model = train_model(x_train, y_train)
rmse_test = accuracy(model, x_test, y_test)
print(f"Average Price Test: {y_test.mean()}")
print(f"RMSE: {rmse_test}")
# Save the model
export_model(model)
if __name__ == '__main__':
main()فئة التنبؤ وتحميل النموذج
بعد حفظ النموذج داخل الملف model.pkl، نحتاج إلى طبقة بسيطة لتحميله واستخدامه. هذا هو دور الملف predict.py الذي يحتوي على الفئة HousePriceModel:
# the pickle lib is used to load the machine learning model
import pickle
import pandas as pd
class HousePriceModel():
def __init__(self):
self.model = self.load_model()
self.preds = None
def load_model(self):
# uses the file model.pkl
pkl_filename = 'model.pkl'
try:
with open(pkl_filename, 'rb') as file:
pickle_model = pickle.load(file)
except:
print(f'Error loading the model at {pkl_filename}')
return None
return pickle_model
def predict(self, data):
if not isinstance(data, pd.DataFrame):
data = pd.DataFrame(data, index=[0])
# makes the predictions using the loaded model
self.preds = self.model.predict(data)
return self.predsهذه الطبقة مفيدة لأنها تفصل منطق التنبؤ عن منطق الواجهة البرمجية، ما يجعل المشروع أسهل في الصيانة والتطوير لاحقاً.
إنشاء واجهة API باستخدام FastAPI
لنشر النموذج وجعله قابلاً للاستهلاك من أي تطبيق خارجي، يمكن بناء واجهة برمجية بسيطة باستخدام FastAPI. لتشغيلها استخدم:
uvicorn api:appوسيكون الناتج مشابهاً لما يلي:
INFO: Started server process [56652]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)هذا هو الكود الخاص بالواجهة:
from fastapi import FastAPI
from datetime import datetime
from predict import HousePriceModel
app = FastAPI()
@app.get("/")
def root():
return {"status": "online"}
@app.post("/predict")
def predict(inputs: dict):
model = HousePriceModel()
start = datetime.today()
pred = model.predict(inputs)[0]
dur = (datetime.today() - start).total_seconds()
return predالنقطة النهائية /predict تستقبل بيانات المنزل على هيئة JSON ثم تعيد السعر المتوقع.
اختبار الواجهة البرمجية
بعد تشغيل الخادم في نافذة طرفية، افتح نافذة أخرى وفعّل البيئة الافتراضية مجدداً:
source ./venv/bin/activateثم شغّل سكربت الاختبار:
python test_api.pyالناتج المتوقع:
The actual Sale Price: 109000
The predicted Sale Price: 109000.01144237864وهذا هو كود الاختبار:
# import requests library to make API calls
import requests
from predict import HousePriceModel
# a sample input with all the features we
# used to train the model
sample_input = {
'MSSubClass': 20,
'MSZoning': 'RL',
'LotArea': 7922,
'Street': 'Pave',
'LotShape': 'Reg',
'LandContour': 'Lvl',
'Utilities': 'AllPub',
'LotConfig': 'Inside',
'LandSlope': 'Gtl',
'Neighborhood': 'NAmes',
'Condition1': 'Norm',
'Condition2': 'Norm',
'BldgType': '1Fam',
'HouseStyle': '1Story',
'OverallQual': 5,
'OverallCond': 7,
'YearBuilt': 1953,
'YearRemodAdd': 2007,
'RoofStyle': 'Gable',
'RoofMatl': 'CompShg',
'Exterior1st': 'VinylSd',
'Exterior2nd': 'VinylSd',
'MasVnrType': 'None',
'ExterQual': 3,
'ExterCond': 4,
'Foundation': 'CBlock',
'BsmtQual': 3,
'BsmtCond': 3,
'BsmtExposure': 'No',
'BsmtFinType1': 'GLQ',
'BsmtFinSF1': 731,
'BsmtFinType2': 'Unf',
'BsmtFinSF2': 0,
'BsmtUnfSF': 326,
'TotalBsmtSF': 1057,
'Heating': 'GasA',
'HeatingQC': 3,
'CentralAir': 'Y',
'Electrical': 'SBrkr',
'1stFlrSF': 1057,
'2ndFlrSF': 0,
'LowQualFinSF': 0,
'GrLivArea': 1057,
'BsmtFullBath': 1,
'BsmtHalfBath': 0,
'FullBath': 1,
'HalfBath': 0,
'BedroomAbvGr': 3,
'KitchenAbvGr': 1,
'KitchenQual': 4,
'TotRmsAbvGrd': 5,
'Functional': 'Typ',
'Fireplaces': 0,
'FireplaceQu': 0,
'GarageType': 'Detchd',
'GarageFinish': 'Unf',
'GarageCars': 1,
'GarageArea': 246,
'GarageQual': 3,
'GarageCond': 3,
'PavedDrive': 'Y',
'WoodDeckSF': 0,
'OpenPorchSF': 52,
'EnclosedPorch': 0,
'3SsnPorch': 0,
'ScreenPorch': 0,
'PoolArea': 0,
'MiscVal': 0,
'MoSold': 1,
'YrSold': 2010,
'SaleType': 'WD',
'SaleCondition': 'Abnorml'
}
def run_prediction_from_sample():
url = "http://127.0.0.1:8000/predict"
headers = {
"Content-Type": "application/json",
"Accept": "text/plain"
}
response = requests.post(url, headers=headers, json=sample_input)
print("The actual Sale Price: 109000")
print(f"The predicted Sale Price: {response.text}")
if __name__ == "__main__":
run_prediction_from_sample()لماذا هذا المشروع مهم عملياً؟
يمثل هذا المشروع نموذجاً ممتازاً لأي شخص يريد الانتقال من مرحلة التعلم النظري إلى تنفيذ حل متكامل. فهو لا يكتفي بتحليل البيانات أو تدريب نموذج فقط، بل يربط ذلك بمفهوم النشر والخدمة البرمجية، وهي النقطة التي يحتاجها السوق فعلياً.
كما أن طريقة العمل هنا تبرز حقيقة مهمة: بناء نماذج Machine Learning ليس مساراً خطياً. قد تبدأ بقرارات تنظيف بسيطة، ثم تعود لاحقاً لإعادة تقييم بعض الأعمدة أو تجربة أساليب ترميز مختلفة أو نماذج أقوى.
أفضل تحسينات مستقبلية على المشروع
- تجربة نماذج أكثر تقدماً مثل
Random ForestأوXGBoost. - استخدام تقسيم أكثر صرامة مع
cross-validation. - إضافة طبقة تحقق من صحة المدخلات داخل
API. - تسجيل النموذج وإصدار نسخه لتسهيل التتبع.
- مراقبة الأداء بعد النشر إذا تم استخدامه في بيئة حقيقية.
هذه الخطوات قد ترفع جودة التنبؤات وتجعل المشروع أقرب إلى منتج احترافي قابل للتوسع.
الخلاصة التقنية
هذا المشروع يوضح بوضوح أن نجاح نموذج التنبؤ لا يعتمد على الخوارزمية فقط، بل يبدأ من فهم البيانات واتخاذ قرارات تنظيف منطقية ومدروسة. استخدام EDA قبل التدريب، ثم تنظيم العمل في سكربتات مستقلة، وأخيراً نشر النموذج عبر FastAPI هو مسار تقني صحيح وعملي. ومن منظور هندسي، فإن القيمة الحقيقية للمشروع تكمن في ترابط المراحل كلها ضمن خط عمل واحد يمكن تطويره وتحسينه لاحقاً بسهولة.