كيفية استخدام Object Storage في موازاة البيانات وتجارب تحليل البيانات
مقدمة: لماذا تحتاج المؤسسات إلى موازاة البيانات؟
أصبحت البيانات اليوم من أهم الأصول الرقمية داخل الشركات، إذ تتيح فهماً أدق لأداء الأعمال من خلال تحليل المبيعات، ومعدلات فقدان العملاء، وسلوك المستخدمين، وغيرها من المؤشرات التي يمكن متابعتها شبه لحظياً مع تدفق البيانات. لكن القيمة الحقيقية لا تظهر فقط في التحليلات التقليدية، بل في القدرة على اختبار علاقات جديدة بين مجموعات بيانات مختلفة قد تبدو غير مترابطة ظاهرياً، ثم استخراج أنماط وفرص ذات أثر مباشر على القرارات.
هنا يظهر مفهوم Data Parallelization أو موازاة البيانات، وهو أسلوب يتيح معالجة مجموعة البيانات نفسها بطرق متعددة ومتزامنة لإنشاء نماذج وتجارب مختلفة، مع الحفاظ الكامل على سلامة البيانات الأصلية. ولتحقيق ذلك بكفاءة، تحتاج المؤسسات إلى بنية تخزين مرنة وقابلة للتوسع، وهنا يتفوق Object Storage بوصفه خياراً عملياً وحديثاً.

الفرق بين Block Storage وObject Storage
قبل الحديث عن تجارب البيانات وإدارة الإصدارات، من المهم فهم الفارق بين نمطي التخزين الأكثر شيوعاً: Block Storage وObject Storage. هذا الفهم يساعدك على اختيار البنية المناسبة لمشاريع التحليل الضخمة وتطبيقات Machine Learning.
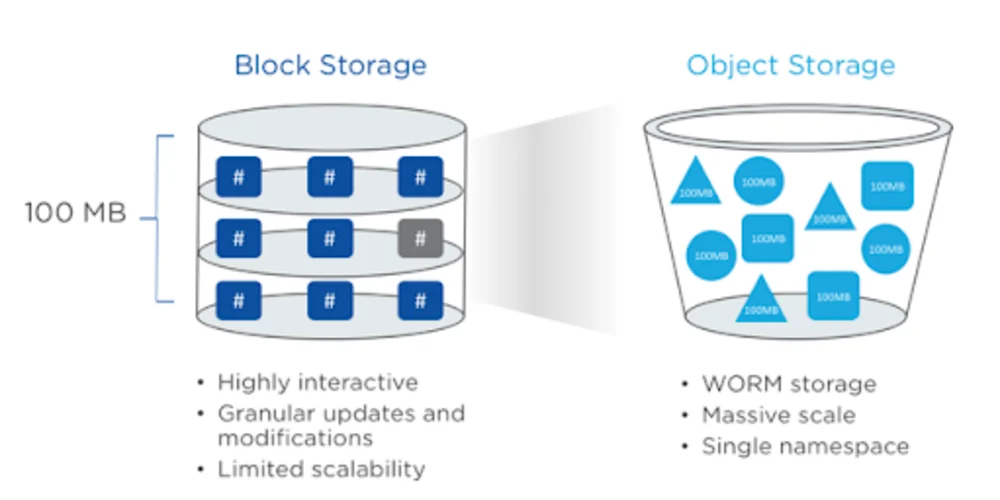
ما هو Block Storage؟
يشير Block Storage، المعروف أيضاً في بعض البيئات باسم SAN، إلى تخزين البيانات على شكل كتل منفصلة داخل الأقراص. وهو النموذج التقليدي المستخدم في أنظمة الملفات على الحواسيب الشخصية، كما يُعتمد عليه في البيئات المؤسسية عبر شبكات من الأقراص المتصلة ببنية عتادية متخصصة.
ورغم فعاليته في حالات كثيرة، فإنه يواجه عدداً من القيود المهمة:
- إذا تعرض جزء أو كتلة للتلف، فقد يؤدي ذلك إلى الإضرار بالملفات المرتبطة بها.
- التوسع فيه مكلف نسبياً، لأنه يعتمد على بنية تحتية عتادية معقدة.
- الوصول إلى البيانات قد يتطلب تحديد موقعها أولاً داخل بنية التخزين قبل استرجاعها.
ما هو Object Storage؟
في Object Storage تُخزَّن البيانات على هيئة كائنات مستقلة. يحتوي كل كائن عادةً على ثلاثة عناصر رئيسية:
- Blob: وهو المحتوى الفعلي للبيانات.
- UUID: معرّف فريد يميز كل كائن.
- Metadata: بيانات وصفية مثل الطابع الزمني، والإصدار، والمالك أو المؤلف.
يمتاز هذا النموذج بسهولة التوسع وانخفاض كلفته مقارنة بالأنظمة التقليدية، كما يسهّل الوصول إلى البيانات لأن كل كائن يمكن استدعاؤه مباشرة عبر معرّفه الفريد. لذلك يُعد خياراً مثالياً للبيئات التي تتعامل مع أحجام ضخمة ومتنوعة من البيانات.
ومن خصائصه المهمة أن البيانات غالباً ما تُكتب مرة واحدة ولا تُحدَّث بالطريقة التقليدية نفسها. ورغم أن هذا قد يبدو قيداً في البداية، فإنه يتحول إلى ميزة قوية عند التعامل مع الإصدارات والتجارب، لأن الأصل يبقى محفوظاً دون عبث.
لماذا يحل Object Storage مشكلات حقيقية في تحليل البيانات؟
القوة الحقيقية لـ Object Storage لا تكمن فقط في السرعة أو القابلية للتوسع، بل في ملاءمته العميقة لسير العمل القائم على التحليل، والتجريب، وبناء النماذج.
حماية البيانات الأصلية من التلف أو الكتابة فوقها
بما أن الكائنات لا تُستبدل بسهولة بعد تخزينها، يصبح من الأصعب على الأخطاء البشرية أو العمليات غير المصرح بها أن تتسبب في فقدان البيانات أو تشويهها. وهذه ميزة بالغة الأهمية في مشاريع معالجة البيانات واسعة النطاق.
دعم البيانات غير المهيكلة
لا تقتصر البيانات الحديثة على الجداول وقواعد البيانات فقط، بل تشمل ملفات PDF، والصور، والفيديوهات، والتسجيلات، والوثائق النصية. هذا النوع من البيانات غير المهيكلة يصعب استيعابه في أنظمة تقليدية، بينما يسمح Object Storage بتخزينه وتحليله والاستفادة منه لاحقاً في تطوير نماذج Machine Learning.
إدارة الإصدارات بطريقة تشبه Git
عند تخزين أكثر من نسخة للبيانات نفسها مع Metadata مختلفة، يصبح من الممكن تتبع تطور البيانات عبر الزمن. هذه الفكرة تشبه كثيراً إدارة إصدارات الشيفرة البرمجية باستخدام Git، لكنها موجهة هنا إلى البيانات والنماذج والنتائج.
ما هي Data Lakes ولماذا أصبحت ضرورية؟
تُعد Data Lakes مستودعات مركزية تسمح بتخزين البيانات بصرف النظر عن نوعها أو صيغتها. بدلاً من إبقاء المعلومات موزعة بين الأقسام والأنظمة المختلفة، يمكن جمعها في بيئة واحدة موحدة، سواء كانت قادمة من قواعد بيانات، أو ملفات فيديو، أو سجلات تشغيل، أو مستندات.
تكمن أهمية Data Lakes في النقاط التالية:
- إزالة العزلة بين أقسام المؤسسة المختلفة.
- السماح بتخزين البيانات دون الحاجة إلى تهيئتها مسبقاً.
- تسريع عمليات التحليل والوصول إلى البيانات.
- تمكين فرق متعددة من الاستفادة من المصدر نفسه للبيانات.
وبفضل هذه المرونة، تصبح المؤسسة أكثر قدرة على بناء رؤى تحليلية دقيقة، وتسريع التجارب، واتخاذ القرارات بناءً على بيانات أكثر شمولاً.
كيف تعمل تجارب البيانات وموازاتها مع Object Storage؟
تماماً كما يحتاج تطوير البرمجيات إلى أدوات تنظّم الإصدارات وسير العمل، فإن العمل على البيانات يحتاج إلى منصة تدعم التجريب، والتفرعات، وتتبع التغييرات. وهنا يظهر LakeFS كأداة مفتوحة المصدر مصممة لتقديم قدرات مشابهة لـ Git ولكن على مستوى البيانات.
يتيح LakeFS إنشاء Branches مستقلة، وتجربة تعديلات على البيانات أو النماذج بعيداً عن النسخة الأساسية، ثم دمج النتائج لاحقاً عند التأكد من جودتها. هذا النموذج يسهّل تنفيذ Data Parallelization دون المساس بسلامة البيانات الأصلية.
لماذا تُعد ميزة Git-like مهمة في إدارة البيانات؟
وجود نهج يشبه Git عند التعامل مع البيانات يمنح الفرق التقنية مزايا عملية واضحة:
- إجراء التجارب في بيئات معزولة وآمنة.
- الحفاظ على سلامة الفرع الرئيسي إلى حين اعتماد التغييرات.
- تتبع الإصدارات والتعديلات بدقة.
- العمل التعاوني بين فرق التحليل والهندسة وعلوم البيانات.
دور ACID في موثوقية البيانات
عند بناء Data Lake موثوق، من المهم أن تكون العمليات متوافقة مع مبادئ ACID. هذا يعني أن التغييرات يمكن أن تتم بمعزل داخل الفروع، دون الإضرار بالنسخة الأساسية. وبهذا، يمكن إجراء التجارب بثقة ثم دمجها بعد التحقق من النتائج.
أهمية CI/CD للبيانات
من المزايا اللافتة في LakeFS دعمه لفكرة Continuous Integration وCI/CD في سياق البيانات. فالمؤسسات تحتاج إلى استيعاب تدفقات جديدة من البيانات بسرعة ومن دون تعطيل الأنظمة أو العمليات التحليلية الجارية. لذلك، فإن دمج التحديثات بشكل منظم وآلي يمثل قيمة كبيرة في البيئات الإنتاجية.
كيفية تثبيت LakeFS محلياً
للبدء في استخدام LakeFS محلياً، يمكنك تشغيل الأمر المخصص عبر الطرفية، مع افتراض أن Docker وDocker-Compose مثبتان مسبقاً على جهازك.
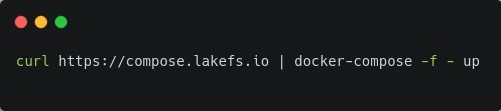
# قم بتشغيل أمر التثبيت الموضح في المرجع الرسمي لـ LakeFS باستخدام Docker Composeبعد اكتمال التثبيت، افتح الرابط التالي في المتصفح للتحقق من نجاح العملية:
http://127.0.0.1:8000/setupإذا لم يكن Docker أو Docker-Compose متوفراً لديك، يمكنك استخدام طرق تثبيت بديلة من الوثائق الرسمية.
كيفية إنشاء Repository في LakeFS
بعد التأكد من نجاح التثبيت، أنشئ أولاً مستخدم admin داخل الواجهة.
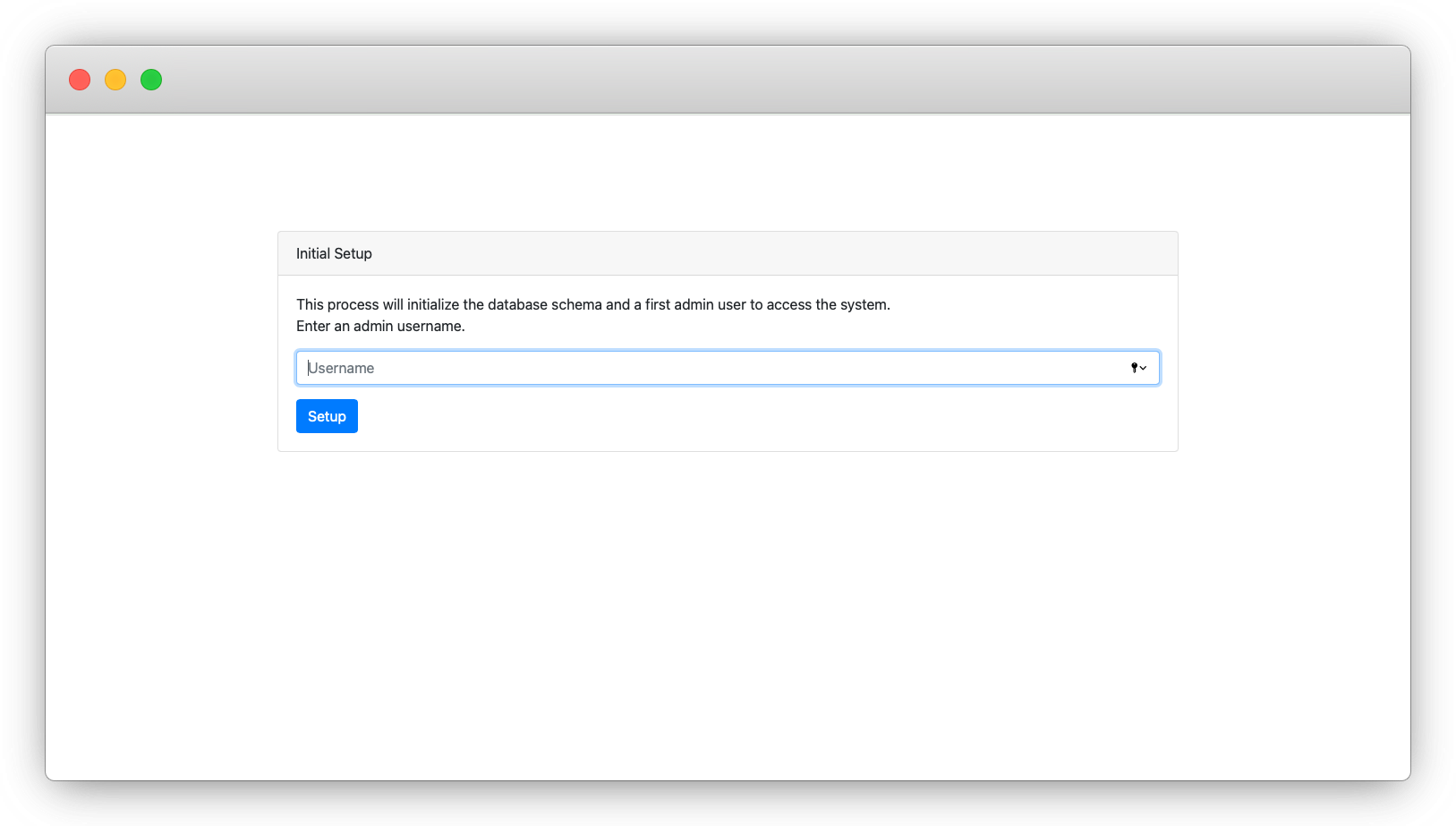
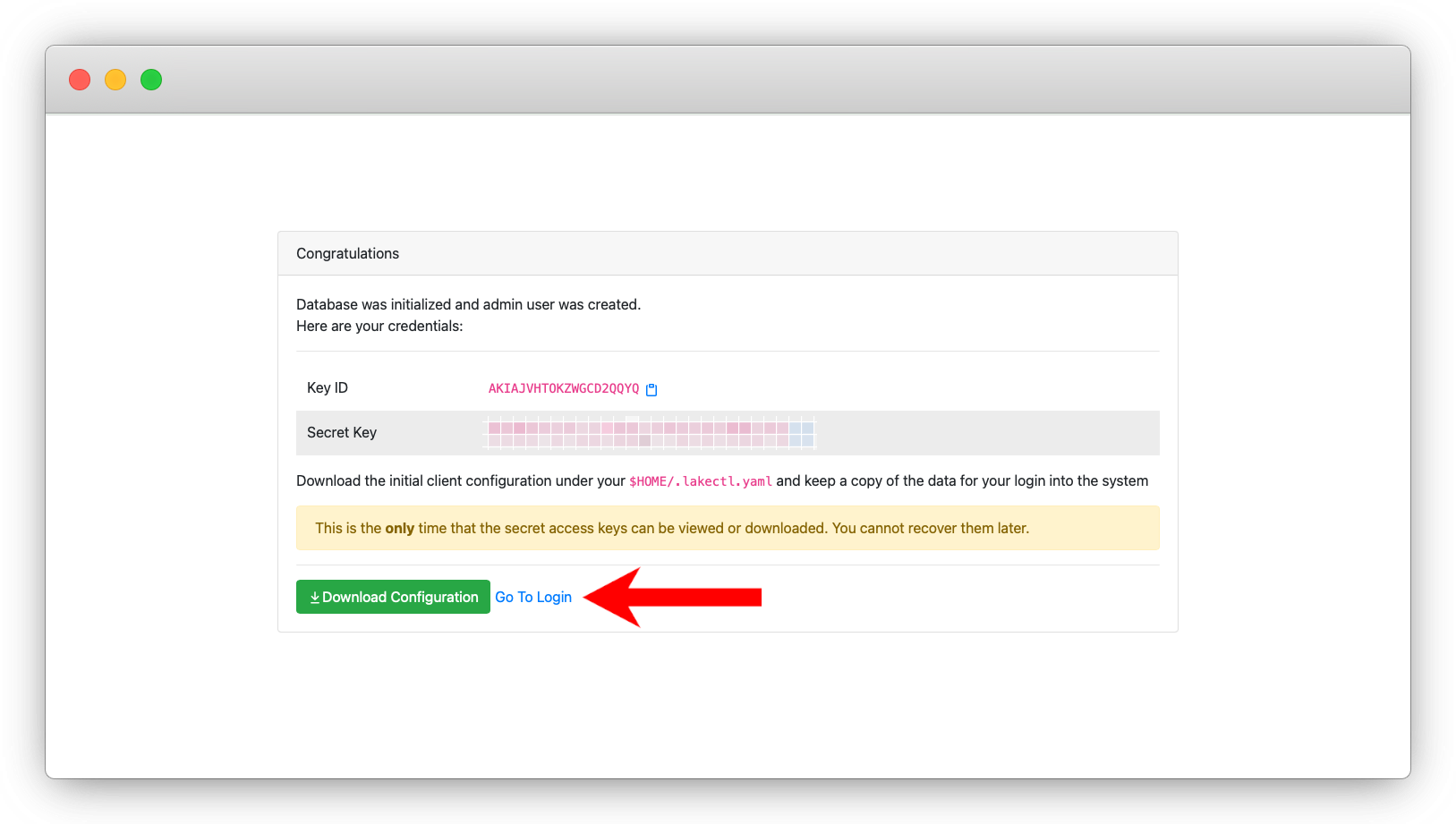
بعد تسجيل الدخول، انتقل إلى الصفحة الرئيسية ثم اضغط على خيار Create Repository. ستظهر لك نافذة منبثقة لإعداد المستودع الجديد.
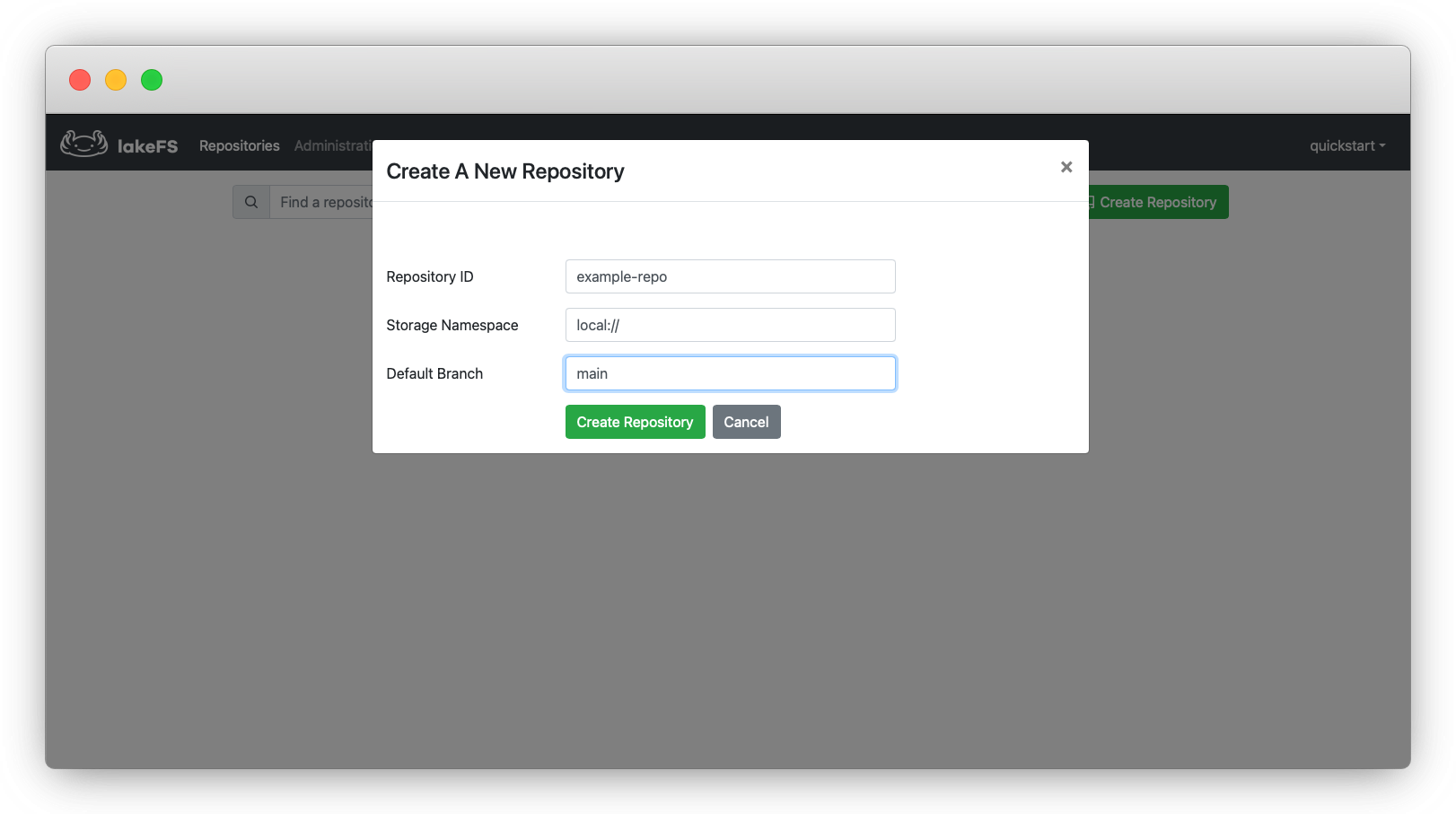
بهذه الخطوة تكون قد أنشأت أول Repository، وهو الحاوية الأساسية التي ستخزن فيها بياناتك وتبني عليها فروع التجارب لاحقاً.
كيفية إضافة البيانات إلى LakeFS Repository
لرفع البيانات إلى LakeFS، ستحتاج إلى تثبيت AWS CLI ثم إعداد ملف اتصال جديد باستخدام بيانات الاعتماد التي أنشأتها عند إعداد المستخدم الإداري.
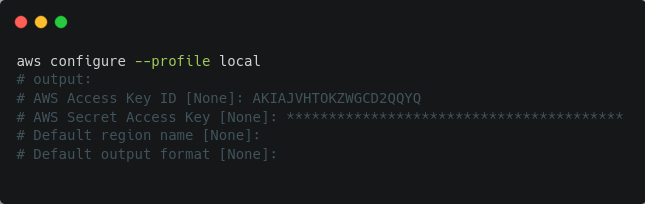
# إعداد profile جديد في AWS CLI باستخدام بيانات اعتماد LakeFSبعد ذلك يمكنك التحقق من نجاح الاتصال عبر تنفيذ أمر اختبار:
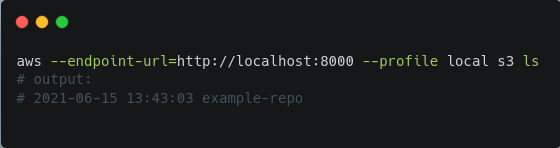
# تشغيل أمر اختبار الاتصال بالمستودعولنسخ الملفات إلى الفرع الرئيسي main، استخدم الأمر المناسب مع مراعاة كتابة اسم الفرع ضمن المسار:

# نسخ الملفات إلى المسار المرتبط بالفرع main داخل Repositoryبعد رفع الملفات، ستتمكن من رؤيتها داخل واجهة المستخدم الرسومية.
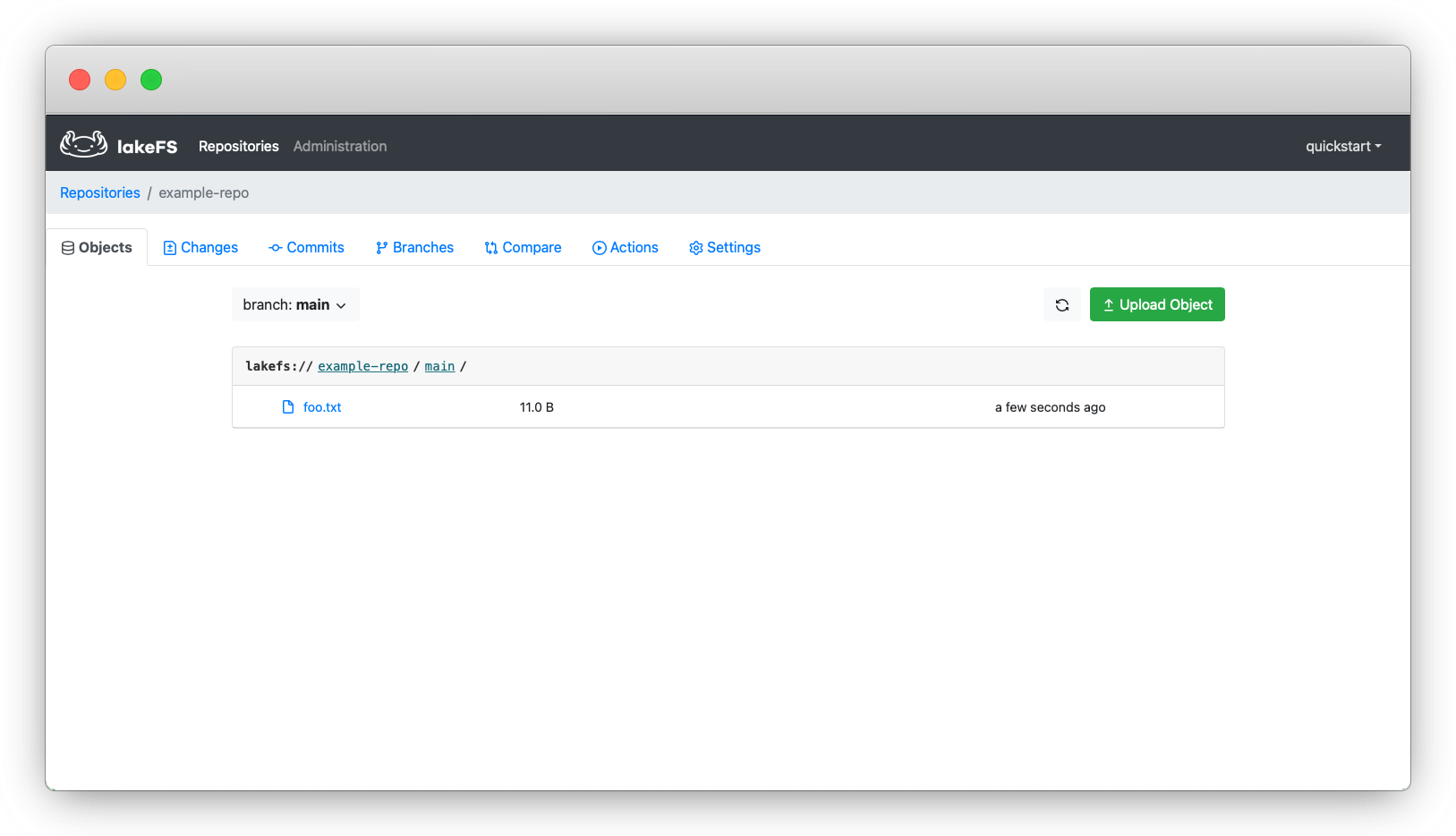
كيفية تثبيت LakeFS CLI
للتحكم بالمستودعات، وإنشاء الفروع، وتنفيذ أوامر الإدارة المتقدمة، ستحتاج إلى تثبيت LakeFS CLI. الخطوة الأولى هي تنزيل الملف التنفيذي binary من المصدر الرسمي، ثم استخدام بيانات اعتماد المسؤول للاتصال.
# إعداد LakeFS CLI باستخدام endpoint وaccess key وsecret keyبعد الإعداد، يمكنك تجربة بعض الأوامر الأساسية للتعامل مع المستودعات والفروع.

# أمثلة على أوامر LakeFS CLI مثل list وbranch وcommitيمكنك لاحقاً التوسع باستخدام أوامر إضافية مثل إنشاء Branches، وتنفيذ Commits، ودمج التعديلات بين الفروع، وهي وظائف تجعل إدارة البيانات أقرب كثيراً إلى تجربة تطوير البرمجيات الحديثة.
أفضل الممارسات عند استخدام Object Storage للتجريب وموازاة البيانات
- حافظ دائماً على نسخة رئيسية مستقرة من البيانات في فرع موثوق.
- أنشئ فروعاً منفصلة لكل تجربة أو نموذج تحليلي جديد.
- استخدم Metadata بذكاء لوصف مصدر البيانات والإصدار والغرض منها.
- تجنب التعديل المباشر على البيانات الإنتاجية قبل التحقق من النتائج.
- ادمج سير عمل البيانات مع أدوات الأتمتة وCI/CD قدر الإمكان.
متى يكون Object Storage الخيار الأنسب؟
يكون Object Storage مناسباً جداً إذا كنت تعمل في واحدة أو أكثر من الحالات التالية:
- لديك أحجام كبيرة من البيانات تنمو باستمرار.
- تتعامل مع بيانات مهيكلة وغير مهيكلة في الوقت نفسه.
- تحتاج إلى بيئة آمنة لتجربة النماذج دون المساس بالأصل.
- تريد تتبع إصدارات البيانات كما تتبع إصدارات الشيفرة.
- تبحث عن حل مرن وقابل للتوسع بتكلفة معقولة.
الخلاصة التقنية
إذا كان هدفك بناء بيئة حديثة لتحليل البيانات وتطوير النماذج بشكل آمن ومرن، فإن Object Storage يقدم أساساً تقنياً قوياً يتفوق في التوسع، وحماية البيانات، ودعم البيانات غير المهيكلة. وعند دمجه مع أدوات مثل LakeFS، تصبح إدارة الإصدارات، وإنشاء الفروع، وتنفيذ تجارب Data Parallelization أكثر تنظيماً وموثوقية. من منظور تقني، هذا النهج لا يحسن فقط كفاءة العمل، بل يرفع أيضاً جودة القرارات المستندة إلى البيانات داخل المؤسسة.