الدليل الشامل لمكتبة Pandas في Python لعلوم البيانات

مقدمة إلى مكتبة Pandas
تُعد مكتبة Pandas، التي اشتق اسمها من اختصار لـ "panel data" (بيانات اللوحة)، حجر الزاوية في عالم تحليل البيانات باستخدام لغة Python. تتميز هذه المكتبة ببنية بيانات فائقة الكفاءة تُعرف باسم DataFrame، والتي تُسهل على مطوري Python التعامل مع البيانات الجدولية، تمامًا مثل جداول البيانات في برامج مثل Excel، ضمن نصوص Python البرمجية. سيوفر لك هذا الدليل الشامل فهمًا عميقًا لأساسيات Pandas التي ستمكنك من بناء تطبيقات تعتمد على البيانات اليوم.
تم بناء Pandas على أساس مكتبة NumPy وتُستخدم على نطاق واسع. يعود الفضل في إنشائها إلى Wes McKinney، الذي طورها لتسهيل العمل مع مجموعات البيانات في Python ضمن مجال عمله في التمويل. وفقًا لموقع المكتبة الرسمي، تُعد Pandas "أداة تحليل ومعالجة بيانات مفتوحة المصدر سريعة، قوية، مرنة، وسهلة الاستخدام، مبنية على لغة برمجة Python". كونها مكتبة مفتوحة المصدر يعني أن أي شخص يمكنه الاطلاع على شفرتها المصدرية والمساهمة في تطويرها عبر طلبات السحب (pull requests).
الفائدة الرئيسية لمكتبة Pandas
صُممت Pandas خصيصًا للتعامل مع البيانات ثنائية الأبعاد، والتي تشبه إلى حد كبير جداول بيانات Excel. وعلى غرار مكتبة NumPy التي تحتوي على بنية بيانات مدمجة تُسمى array مع سمات وطرق خاصة، فإن مكتبة Pandas تقدم بنية بيانات ثنائية الأبعاد مدمجة تُسمى DataFrame، والتي تُعد أكثر قوة ومرونة.
خلال الأقسام التالية، سنتعمق في استكشاف المكونات والعمليات الأساسية لمكتبة Pandas:
Pandas SeriesPandas DataFrames- كيفية التعامل مع البيانات المفقودة في
Pandas - دمج وربط
DataFramesفيPandas - العمليات الشائعة في
Pandas - إدخال وإخراج البيانات المحلية والبعيدة في
Pandas
فهم Pandas Series
في هذا القسم، سنتناول مفهوم Pandas Series، وهو مكون أساسي في مكتبة Pandas لبرمجة Python.
ما هي Pandas Series؟
Series هي نوع خاص من هياكل البيانات المتاحة في مكتبة Pandas. تُشبه Pandas Series مصفوفات NumPy أحادية البعد، ولكنها تتميز بقدرتها على استخدام فهرس مسمى أو فهرس زمني (datetime index) بدلاً من الفهرس الرقمي فقط.
الاستيرادات المطلوبة للعمل مع Pandas Series
للعمل مع Pandas Series، ستحتاج إلى استيراد كل من NumPy و Pandas، كما يلي:
import numpy as np
import pandas as pd
سنفترض أن هذه الاستيرادات قد تم تنفيذها قبل تشغيل أي كتل برمجية لاحقة.
كيفية إنشاء Pandas Series
هناك عدة طرق لإنشاء Pandas Series. سنستكشفها جميعًا في هذا القسم. لنبدأ بإنشاء بعض المتغيرات الأولية: قائمتين، مصفوفة NumPy، وقاموس.
labels = ['a', 'b', 'c']
my_list = [10, 20, 30]
arr = np.array([10, 20, 30])
d = {'a': 10, 'b': 20, 'c': 30}
أسهل طريقة لإنشاء Pandas Series هي تمرير قائمة Python عادية إلى الدالة pd.Series(). نفعل ذلك باستخدام المتغير my_list كما هو موضح أدناه:
pd.Series(my_list)
إذا قمت بتشغيل هذا في دفتر ملاحظات Jupyter الخاص بك، ستلاحظ أن المخرجات تختلف تمامًا عن قائمة Python العادية:
0 10
1 20
2 30
dtype: int64
المخرجات الموضحة أعلاه مصممة بوضوح لتقديم عمودين. العمود الثاني هو البيانات من my_list. فما هو العمود الأول؟ إحدى المزايا الرئيسية لاستخدام Pandas Series على مصفوفات NumPy هي أنها تسمح بالتسمية (labeling). وكما قد تكون خمنت، فإن العمود الأول هو عمود من التسميات. يمكننا إضافة تسميات إلى Pandas Series باستخدام الوسيط index كما يلي:
pd.Series(my_list, index=labels) # تذكر - لقد أنشأنا قائمة 'labels' سابقًا في هذا القسم
مخرجات هذا الكود هي:
a 10
b 20
c 30
dtype: int64
لماذا قد ترغب في استخدام التسميات في Pandas Series؟ الميزة الرئيسية هي أنها تسمح لك بالوصول إلى عنصر في Series باستخدام تسميته بدلاً من فهرسه الرقمي. لتوضيح الأمر، بمجرد تطبيق التسميات على Pandas Series، يمكنك استخدام إما فهرسها الرقمي أو تسميتها. مثال على ذلك أدناه:
Series = pd.Series(my_list, index=labels)
Series[0] # تُرجع 10
Series['a'] # تُرجع 10 أيضًا
ربما لاحظت أن القدرة على الرجوع إلى عنصر في Series باستخدام تسميته تشبه كيفية الرجوع إلى value من زوج key-value في القاموس. وبسبب هذا التشابه في طريقة عملهما، يمكنك أيضًا تمرير قاموس لإنشاء Pandas Series. سنستخدم القاموس d={'a': 10, 'b': 20, 'c': 30} الذي أنشأناه سابقًا كمثال:
pd.Series(d)
مخرجات هذا الكود هي:
a 10
b 20
c 30
dtype: int64
الميزة الرئيسية لـ Pandas Series على مصفوفات NumPy
بينما لم نلاحظ ذلك في حينه، فإن مصفوفات NumPy محدودة للغاية بخاصية واحدة: يجب أن يكون كل عنصر في مصفوفة NumPy من نفس نوع هيكل البيانات. بعبارة أخرى، يجب أن تكون عناصر مصفوفة NumPy كلها سلاسل نصية، أو كلها أعداد صحيحة، أو كلها قيم منطقية – وهكذا. لا تعاني Pandas Series من هذا القيد. في الواقع، Pandas Series مرنة للغاية. على سبيل المثال، يمكنك تمرير ثلاث من دوال Python المدمجة إلى Pandas Series دون الحصول على خطأ:
pd.Series([sum, print, len])
إليك مخرجات هذا الكود:
0 <built-in function sum>
1 <built-in function print>
2 <built-in function len>
dtype: object
لتوضيح الأمر، المثال أعلاه غير عملي إلى حد كبير وليس شيئًا سنقوم بتنفيذه في الممارسة. ومع ذلك، فهو مثال ممتاز على مرونة بنية بيانات Pandas Series.
الغوص في Pandas DataFrames
تسمح NumPy للمطورين بالعمل مع مصفوفات NumPy أحادية البعد (تُسمى أحيانًا متجهات) ومصفوفات NumPy ثنائية الأبعاد (تُسمى أحيانًا مصفوفات). لقد استكشفنا Pandas Series في القسم الأخير، والتي تُشبه مصفوفات NumPy أحادية البعد. في هذا القسم، سنتعمق في Pandas DataFrames، والتي تُشبه مصفوفات NumPy ثنائية الأبعاد – ولكن مع وظائف أكثر بكثير. تُعد DataFrames أهم بنية بيانات في مكتبة Pandas، لذا انتبه جيدًا طوال هذا القسم.
ما هو Pandas DataFrame؟
Pandas DataFrame هو بنية بيانات ثنائية الأبعاد تحتوي على تسميات لكل من صفوفها وأعمدتها. بالنسبة للمستخدمين المعتادين على Microsoft Excel، أو Google Sheets، أو برامج جداول البيانات الأخرى، فإن DataFrames متشابهة جدًا. إليك مثال على Pandas DataFrame يتم عرضه داخل دفتر ملاحظات Jupyter.
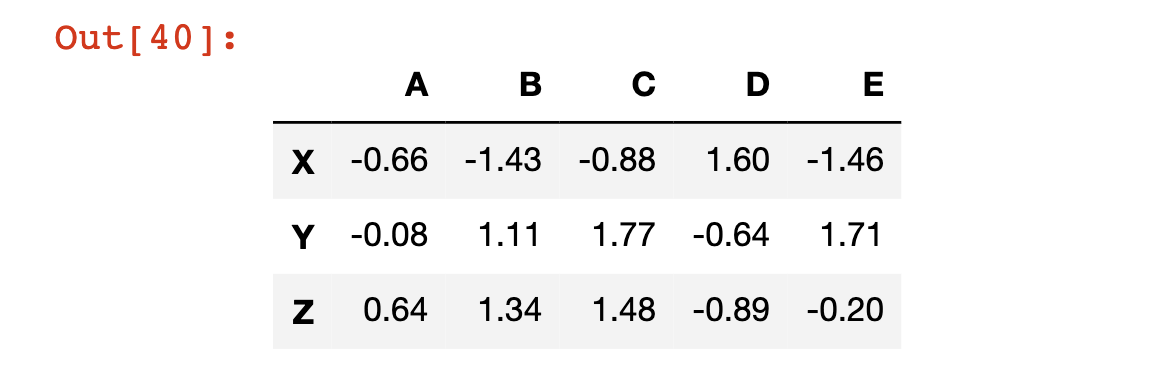
سنمر الآن بعملية إعادة إنشاء هذا DataFrame خطوة بخطوة. أولاً، ستحتاج إلى استيراد كل من مكتبتي NumPy و Pandas. لقد قمنا بذلك من قبل، ولكن في حال كنت غير متأكد، إليك مثال آخر على كيفية القيام بذلك:
import numpy as np
import pandas as pd
سنحتاج أيضًا إلى إنشاء قوائم لأسماء الصفوف والأعمدة. يمكننا القيام بذلك باستخدام قوائم Python العادية:
rows = ['X', 'Y', 'Z']
cols = ['A', 'B', 'C', 'D', 'E']
بعد ذلك، سنحتاج إلى إنشاء مصفوفة NumPy تحتوي على البيانات الموجودة داخل خلايا DataFrame. لقد استخدمت الدالة np.random.randn من NumPy لهذا الغرض. كما قمت بتضمين هذه الدالة داخل الدالة np.round (مع وسيط ثانٍ بقيمة 2)، والذي يقرب كل نقطة بيانات إلى منزلتين عشريتين ويجعل بنية البيانات أسهل بكثير في القراءة. إليك الدالة النهائية التي ولدت البيانات.
data = np.round(np.random.randn(3, 5), 2)
بمجرد الانتهاء من ذلك، يمكنك تضمين جميع المتغيرات المكونة في الدالة pd.DataFrame لإنشاء أول DataFrame لك!
pd.DataFrame(data, rows, cols)
هناك الكثير مما يمكن استكشافه هنا، لذا دعنا نناقش هذا المثال بمزيد من التفصيل. أولاً، ليس من الضروري إنشاء كل متغير خارج DataFrame نفسه. كان بإمكانك إنشاء هذا DataFrame في سطر واحد هكذا:
pd.DataFrame(np.round(np.random.randn(3, 5), 2), ['X', 'Y', 'Z'], ['A', 'B', 'C', 'D', 'E'])
ومع ذلك، فإن الإعلان عن كل متغير على حدة يجعل الكود أسهل بكثير في القراءة. ثانيًا، قد تتساءل عما إذا كان من الضروري وضع الصفوف في دالة DataFrame قبل الأعمدة. إنه ضروري بالفعل. إذا حاولت تشغيل pd.DataFrame(data, cols, rows)، فسيقوم دفتر ملاحظات Jupyter الخاص بك بإنشاء رسالة الخطأ التالية:
ValueError: Shape of passed values is (3, 5), indices imply (5, 3)
بعد ذلك، سنستكشف العلاقة بين Pandas Series و Pandas DataFrames.
العلاقة بين Pandas Series و Pandas DataFrame
دعنا نلقي نظرة أخرى على Pandas DataFrame الذي أنشأناه للتو:
إذا طُلب منك وصف Pandas Series شفهيًا، فقد يكون أحد الطرق هو "مجموعة من الأعمدة المسماة التي تحتوي على بيانات حيث تشترك كل عمود في نفس مجموعة فهرس الصفوف." ومن المثير للاهتمام أن كل من هذه الأعمدة هو في الواقع Pandas Series! لذا يمكننا تعديل تعريفنا لـ Pandas DataFrame ليتناسب مع تعريفه الرسمي: "مجموعة من Pandas Series التي تشترك في نفس الفهرس."
الفهرسة والتعيين في Pandas DataFrames
يمكننا بالفعل استدعاء Series محددة من Pandas DataFrame باستخدام الأقواس المربعة، تمامًا كما نستدعي عنصرًا من قائمة. إليك بعض الأمثلة:
df = pd.DataFrame(data, rows, cols)
df['A']
"""
Returns:
X -0.66
Y -0.08
Z 0.64
Name: A, dtype: float64
"""
df['E']
"""
Returns:
X -1.46
Y 1.71
Z -0.20
Name: E, dtype: float64
"""
ماذا لو أردت تحديد عدة أعمدة من Pandas DataFrame؟ يمكنك تمرير قائمة من الأعمدة، إما مباشرة داخل الأقواس المربعة – مثل df[['A', 'E']] – أو عن طريق الإعلان عن المتغير خارج الأقواس المربعة هكذا:
columnsIWant = ['A', 'E']
df[columnsIWant] # تُرجع DataFrame، ولكن فقط مع الأعمدة A و E
يمكنك أيضًا تحديد عنصر معين من صف معين باستخدام أقواس مربعة متسلسلة. على سبيل المثال، إذا أردت العنصر الموجود في الصف A عند الفهرس X (وهو العنصر في الخلية العلوية اليسرى من DataFrame) يمكنك الوصول إليه باستخدام df['A']['X']. إليك بعض الأمثلة الأخرى أدناه.
df['B']['Z'] # تُرجع 1.34
df['D']['Y'] # تُرجع -0.64
كيفية إنشاء وإزالة الأعمدة في Pandas DataFrame
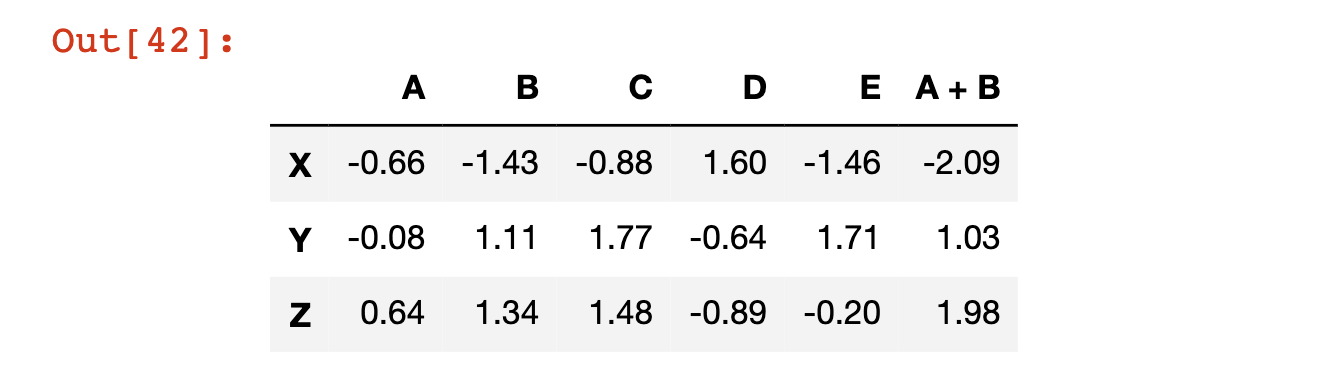
يمكنك إنشاء عمود جديد في Pandas DataFrame عن طريق تحديد العمود كما لو كان موجودًا بالفعل، ثم تعيين Pandas Series جديدة له. على سبيل المثال، في كتلة الكود التالية، ننشئ عمودًا جديدًا يُسمى 'A + B' وهو مجموع العمودين A و B:
df['A + B'] = df['A'] + df['B']
df # السطر الأخير يطبع DataFrame الجديد
إليك مخرجات كتلة الكود هذه:
لإزالة هذا العمود من Pandas DataFrame، نحتاج إلى استخدام الدالة pd.DataFrame.drop. لاحظ أن هذه الدالة افتراضيًا تُسقط الصفوف، وليس الأعمدة. لتبديل إعدادات الدالة للعمل على الأعمدة، يجب أن نمرر لها الوسيط axis=1.
df.drop('A + B', axis=1)
من المهم جدًا ملاحظة أن دالة drop (والعديد من دوال DataFrame الأخرى!) لا تُعدل DataFrame نفسه افتراضيًا. لإثبات ذلك، اطبع المتغير df مرة أخرى، ولاحظ كيف لا يزال يحتوي على العمود A + B:
df
السبب في أن drop (والعديد من دوال DataFrame الأخرى!) لا تُعدل بنية البيانات افتراضيًا هو لمنعك من حذف البيانات عن طريق الخطأ. هناك طريقتان لجعل pandas تُعيد الكتابة تلقائيًا على DataFrame الحالي. الأولى هي تمرير الوسيط inplace=True، هكذا:
df.drop('A + B', axis=1, inplace=True)
والثانية هي استخدام عامل التعيين (assignment operator) الذي يُعيد الكتابة يدويًا على المتغير الموجود، هكذا:
df = df.drop('A + B', axis=1)
كلا الخيارين صالحان، لكنني أجد نفسي أستخدم الخيار الثاني بشكل متكرر لأنه أسهل في التذكر. يمكن استخدام دالة drop أيضًا لإسقاط الصفوف. على سبيل المثال، يمكننا إزالة الصف Z كما يلي:
df.drop('Z')
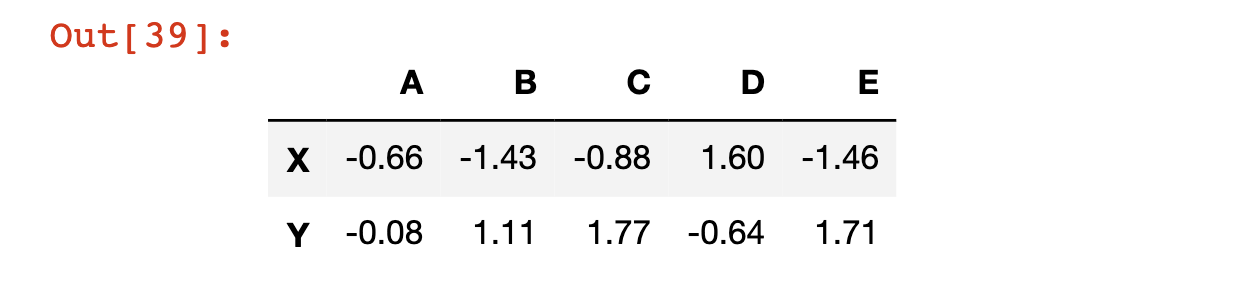
كيفية تحديد صف من Pandas DataFrame
لقد رأينا بالفعل أنه يمكننا الوصول إلى عمود معين من Pandas DataFrame باستخدام الأقواس المربعة. سنرى الآن كيفية الوصول إلى صف معين من Pandas DataFrame، بهدف مشابه لتوليد Pandas Series من بنية البيانات الأكبر. يمكن الوصول إلى صفوف DataFrame بواسطة تسمية الصف الخاصة بها باستخدام السمة loc جنبًا إلى جنب مع الأقواس المربعة. مثال أدناه:
df.loc['X']
إليك مخرجات هذا الكود:
A -0.66
B -1.43
C -0.88
D 1.60
E -1.46
Name: X, dtype: float64
يمكن الوصول إلى صفوف DataFrame بواسطة فهرسها الرقمي باستخدام السمة iloc جنبًا إلى جنب مع الأقواس المربعة. مثال أدناه:
df.iloc[0]
كما تتوقع، لهذا الكود نفس مخرجات مثالنا الأخير:
A -0.66
B -1.43
C -0.88
D 1.60
E -1.46
Name: X, dtype: float64
كيفية تحديد عدد الصفوف والأعمدة في Pandas DataFrame
هناك العديد من الحالات التي سترغب فيها في معرفة شكل Pandas DataFrame. بالشكل، أعني عدد الأعمدة والصفوف في بنية البيانات. تحتوي Pandas على سمة مدمجة تُسمى shape تسمح لنا بالوصول إلى هذا بسهولة:
df.shape # تُرجع (3, 5)
تقطيع (Slicing) Pandas DataFrames
لقد رأينا بالفعل كيفية تحديد الصفوف والأعمدة والعناصر من Pandas DataFrame. في هذا القسم، سنستكشف كيفية تحديد مجموعة فرعية من DataFrame. على وجه التحديد، دعنا نحدد العناصر من العمودين A و B والصفوف X و Y. يمكننا بالفعل التعامل مع هذا بطريقة خطوة بخطوة. أولاً، دعنا نحدد العمودين A و B:
df[['A', 'B']]
ثم، دعنا نحدد الصفوف X و Y:
df[['A', 'B']].loc[['X', 'Y']]
وهكذا نكون قد انتهينا!
التحديد الشرطي باستخدام Pandas DataFrame
إذا تذكرت من مناقشتنا لمصفوفات NumPy، فقد تمكنا من تحديد عناصر معينة من المصفوفة باستخدام عوامل شرطية. على سبيل المثال، إذا كان لدينا مصفوفة NumPy تُسمى arr وأردنا فقط قيم المصفوفة الأكبر من 4، يمكننا استخدام الأمر arr[arr > 4]. تتبع Pandas DataFrames بناءً مشابهًا. على سبيل المثال، إذا أردنا معرفة أين يحتوي DataFrame الخاص بنا على قيم أكبر من 0.5، يمكننا كتابة df > 0.5 للحصول على المخرجات التالية:

يمكننا أيضًا إنشاء Pandas DataFrame جديد يحتوي على القيم العادية حيث تكون العبارة True، وقيم NaN – التي تعني "ليست رقمًا" (Not a Number) – حيث تكون العبارة خاطئة. نفعل ذلك عن طريق تمرير العبارة إلى DataFrame باستخدام الأقواس المربعة، هكذا:
df[df > 0.5]
إليك مخرجات هذا الكود:
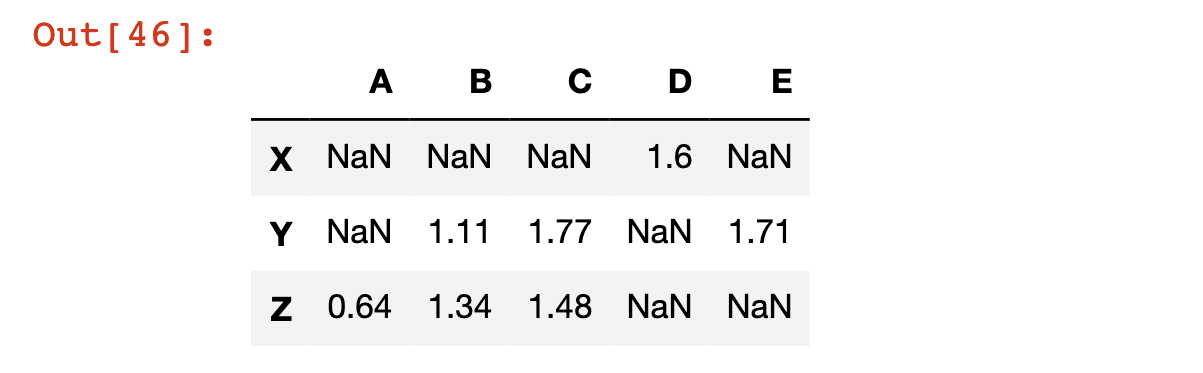
يمكنك أيضًا استخدام التحديد الشرطي لإرجاع مجموعة فرعية من DataFrame حيث يتم استيفاء شرط معين في عمود محدد. لتكون أكثر تحديدًا، لنفترض أنك أردت المجموعة الفرعية من DataFrame حيث كانت القيمة في العمود C أقل من 1. هذا صحيح فقط للصف X. يمكنك الحصول على مصفوفة من القيم المنطقية المرتبطة بهذه العبارة هكذا:
df['C'] < 1
إليك المخرجات:
X True
Y False
Z False
Name: C, dtype: bool
يمكنك أيضًا الحصول على القيم الفعلية لـ DataFrame بالنسبة لأمر التحديد الشرطي هذا عن طريق كتابة df[df['C'] < 1]، والذي يُخرج فقط الصف الأول من DataFrame (نظرًا لأنه الصف الوحيد الذي تكون فيه العبارة صحيحة للعمود C):
![DataFrame يظهر الصفوف التي تحقق الشرط df['C'] < 1](https://nickmccullum.com/images/advanced-python/pandas-dataframe/pandas-dataframe-conditional-selection-dataframe.png)
يمكنك أيضًا ربط عدة شروط معًا أثناء استخدام التحديد الشرطي. نفعل ذلك باستخدام عامل & الخاص بـ pandas. لا يمكنك استخدام عامل and العادي في Python، لأنه في هذه الحالة لا نقارن قيمتين منطقيتين. بدلاً من ذلك، نقارن Pandas Series التي تحتوي على قيم منطقية، ولهذا السبب يتم استخدام الحرف & بدلاً من ذلك. كمثال على التحديد الشرطي المتعدد، يمكنك إرجاع المجموعة الفرعية من DataFrame التي تحقق df['C'] > 0 و df['A'] > 0 باستخدام الكود التالي:
df[(df['C'] > 0) & (df['A'] > 0)]
![DataFrame يظهر الصفوف التي تحقق شروطًا متعددة: df['C'] > 0 و df['A'] > 0](https://nickmccullum.com/images/advanced-python/pandas-dataframe/pandas-dataframe-multiple-conditional-selection.png)
كيفية تعديل فهرس Pandas DataFrame
هناك عدة طرق يمكنك من خلالها تعديل فهرس Pandas DataFrame. أبسطها هو إعادة تعيين الفهرس إلى قيمه الرقمية الافتراضية. نفعل ذلك باستخدام الدالة reset_index:
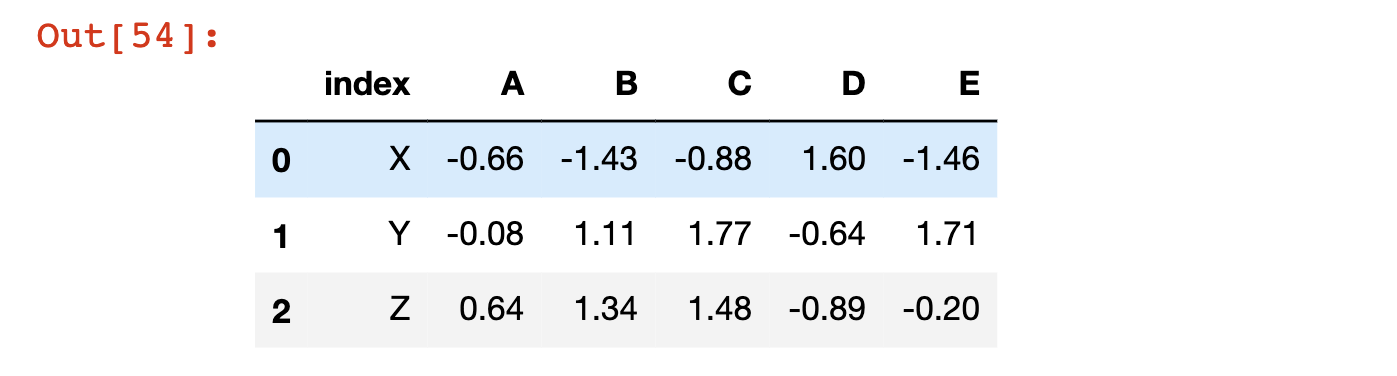
df.reset_index()
لاحظ أن هذا ينشئ عمودًا جديدًا في DataFrame يُسمى index يحتوي على تسميات الفهرس السابقة:
لاحظ أنه مثل عمليات DataFrame الأخرى التي استكشفناها، لا تُعدل reset_index DataFrame الأصلي ما لم (1) تجبرها على ذلك باستخدام عامل التعيين = أو (2) تحدد inplace=True. يمكنك أيضًا تعيين عمود موجود كفهرس لـ DataFrame باستخدام الدالة set_index. يمكننا تعيين العمود A كفهرس لـ DataFrame باستخدام الكود التالي:
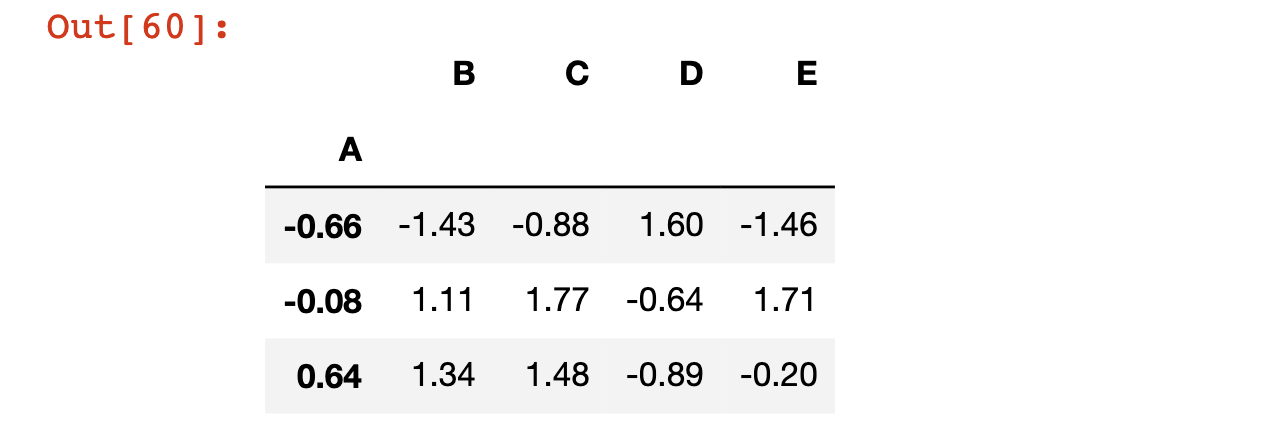
df.set_index('A')
قيم A موجودة الآن في فهرس DataFrame:
هناك ثلاث نقاط تستحق الملاحظة هنا:
set_indexلا تُعدلDataFrameالأصلي ما لم (1) تجبرها على ذلك باستخدام عامل التعيين=أو (2) تحددinplace=True.- ما لم تقم بتشغيل
reset_indexأولاً، فإن تنفيذ عمليةset_indexمعinplace=Trueأو عامل التعيين=سيؤدي إلى الكتابة فوق قيم الفهرس الحالية بشكل دائم. - إذا أردت إعادة تسمية الفهرس الخاص بك بتسميات غير موجودة حاليًا في عمود، يمكنك القيام بذلك عن طريق (1) إنشاء مصفوفة
NumPyبهذه القيم، (2) إضافة هذه القيم كصف جديد لـPandas DataFrame، و (3) تشغيل عمليةset_index.
كيفية إعادة تسمية الأعمدة في Pandas DataFrame
آخر عملية DataFrame سنناقشها هي كيفية إعادة تسمية أعمدتها. الأعمدة هي سمة من سمات Pandas DataFrame، مما يعني أنه يمكننا استدعائها وتعديلها باستخدام عامل النقطة البسيط. على سبيل المثال:
df.columns # تُرجع Index(['A', 'B', 'C', 'D', 'E'], dtype='object')
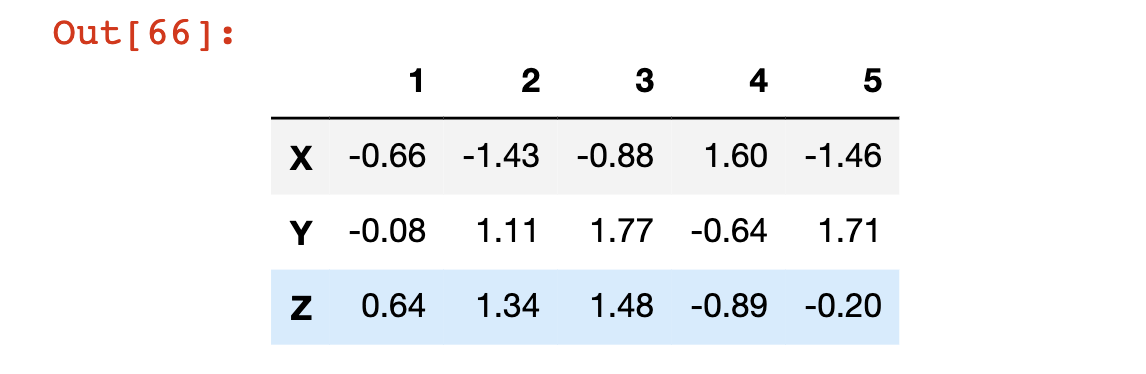
عامل التعيين هو أفضل طريقة لتعديل هذه السمة:
df.columns = [1, 2, 3, 4, 5]
df
التعامل مع البيانات المفقودة في Pandas DataFrames
في عالم مثالي، سنعمل دائمًا مع مجموعات بيانات مثالية. ومع ذلك، هذا ليس هو الحال أبدًا في الممارسة العملية. هناك العديد من الحالات عند العمل مع البيانات الكمية التي ستحتاج فيها إلى إسقاط أو تعديل البيانات المفقودة. سنستكشف استراتيجيات للتعامل مع البيانات المفقودة في Pandas طوال هذا القسم.
DataFrame الذي سنستخدمه في هذا القسم
سنستخدم السمة np.nan لتوليد قيم NaN طوال هذا القسم.
np.nan # تُرجع nan
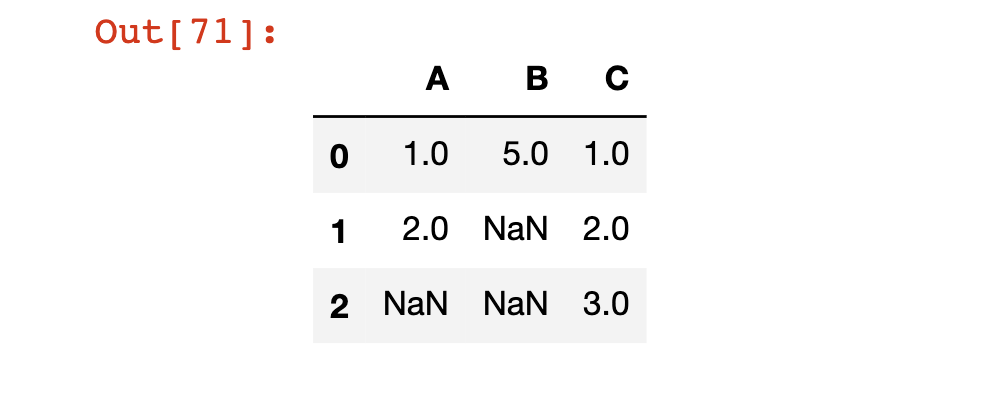
في هذا القسم، سنستخدم DataFrame التالي:
df = pd.DataFrame(np.array([[1, 5, 1],[2, np.nan, 2],[np.nan, np.nan, 3]]))
df.columns = ['A', 'B', 'C']
df
دالة Pandas dropna()
تحتوي Pandas على دالة مدمجة تُسمى dropna. عند تطبيقها على DataFrame، ستقوم دالة dropna بإزالة أي صفوف تحتوي على قيمة NaN. دعنا نطبق دالة dropna على DataFrame الخاص بنا df كمثال:
df.dropna()
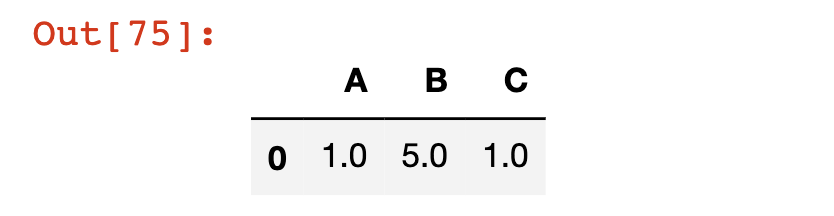
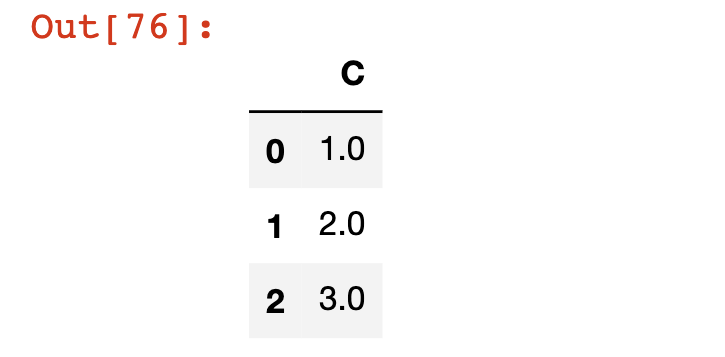
لاحظ أنه مثل عمليات DataFrame الأخرى التي استكشفناها، لا تُعدل dropna DataFrame الأصلي ما لم (1) تجبرها على ذلك باستخدام عامل التعيين = أو (2) تحدد inplace=True. يمكننا أيضًا إسقاط أي أعمدة تحتوي على قيم مفقودة عن طريق تمرير الوسيط axis=1 إلى دالة dropna، هكذا:
df.dropna(axis=1)
دالة Pandas fillna()
في كثير من الحالات، سترغب في استبدال القيم المفقودة في Pandas DataFrame بدلاً من إسقاطها بالكامل. صُممت دالة fillna لهذا الغرض. على سبيل المثال، دعنا نملأ كل قيمة مفقودة في DataFrame الخاص بنا بـ '?':
df.fillna('?')

من الواضح أنه لا يوجد موقف تقريبًا نرغب فيه في استبدال البيانات المفقودة برمز تعبيري. كان هذا مجرد مثال مضحك. بدلاً من ذلك، سنقوم بشكل أكثر شيوعًا باستبدال قيمة مفقودة بأحد الخيارين التاليين:
- متوسط قيمة
DataFrameبأكمله. - متوسط قيمة ذلك الصف من
DataFrame.
سنوضح كلاهما أدناه. لملء القيم المفقودة بمتوسط القيمة عبر DataFrame بأكمله، استخدم الكود التالي:
df.fillna(df.mean())
لملء القيم المفقودة داخل عمود معين بمتوسط القيمة من ذلك العمود، استخدم الكود التالي (هذا للعمود A):
df['A'].fillna(df['A'].mean())
دالة Pandas groupby()
في هذا القسم، سنناقش كيفية استخدام ميزة groupby في pandas.
ما هي ميزة Pandas groupby()؟
تأتي Pandas مع ميزة groupby مدمجة تسمح لك بتجميع الصفوف بناءً على عمود معين وتنفيذ دالة تجميعية عليها. على سبيل المثال، يمكنك حساب مجموع جميع الصفوف التي تحتوي على قيمة 1 في العمود ID. لأي شخص مطلع على لغة SQL للاستعلام عن قواعد البيانات، فإن دالة groupby في pandas تشبه إلى حد كبير عبارة groupby في SQL. من الأسهل فهم دالة groupby في pandas باستخدام مثال. سنستخدم DataFrame التالي:
df = pd.DataFrame([
['Google', 'Sam', 200],
['Google', 'Charlie', 120],
['Salesforce', 'Ralph', 125],
['Salesforce', 'Emily', 250],
['Adobe', 'Rosalynn', 150],
['Adobe', 'Chelsea', 500]
])
df.columns = ['Organization', 'Salesperson Name', 'Sales']
df
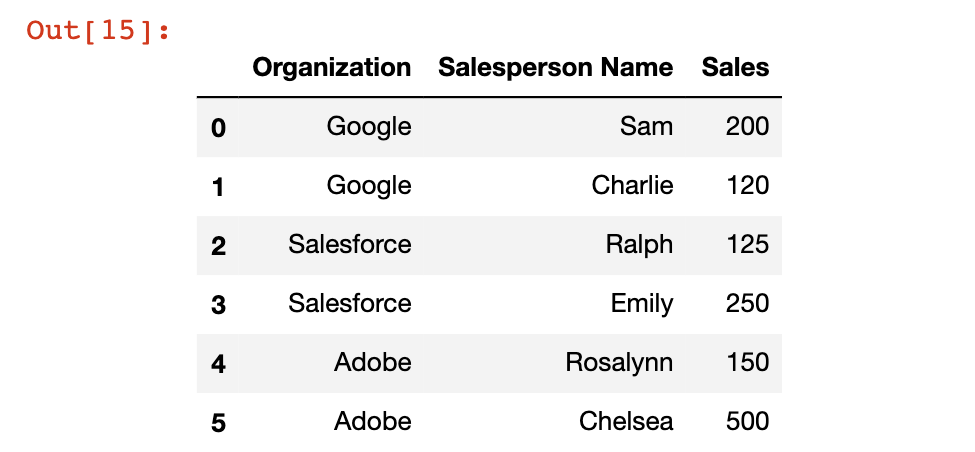
يحتوي هذا DataFrame على معلومات مبيعات لثلاث منظمات منفصلة: Google، Salesforce، و Adobe. سنستخدم دالة groupby للحصول على بيانات مبيعات موجزة لكل منظمة محددة. للبدء، سنحتاج إلى إنشاء كائن groupby. هذا هو بنية بيانات تُخبر Python بالعمود الذي ترغب في تجميع DataFrame بواسطته. في حالتنا، هو العمود Organization، لذا ننشئ كائن groupby هكذا:
df.groupby('Organization')
إذا رأيت مخرجات تبدو هكذا، ستعرف أنك أنشأت الكائن بنجاح:
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x113f4ecd0>
بمجرد إنشاء كائن groupby، يمكنك استدعاء العمليات على هذا الكائن لإنشاء DataFrame بمعلومات موجزة عن مجموعات Organization. إليك بعض الأمثلة:
df.groupby('Organization').mean() # المتوسط (أو المعدل) لعمود المبيعات
df.groupby('Organization').sum() # مجموع عمود المبيعات
df.groupby('Organization').std() # الانحراف المعياري لعمود المبيعات
لاحظ أنه نظرًا لأن جميع العمليات المذكورة أعلاه رقمية، فإنها ستتجاهل تلقائيًا عمود Salesperson Name، لأنه يحتوي فقط على سلاسل نصية. إليك بعض الدوال التجميعية الأخرى التي تعمل جيدًا مع دالة groupby في pandas:
df.groupby('Organization').count() # يحسب عدد الملاحظات
df.groupby('Organization').max() # يُرجع القيمة القصوى
df.groupby('Organization').min() # يُرجع القيمة الدنيا
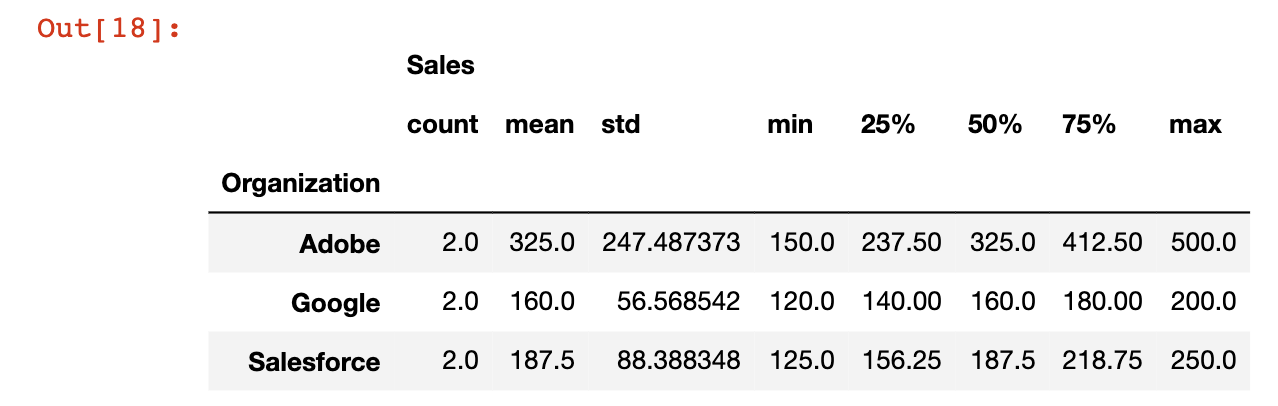
استخدام groupby() مع دالة describe()
إحدى الأدوات المفيدة جدًا عند العمل مع Pandas DataFrames هي دالة describe، والتي تُرجع معلومات مفيدة لكل فئة تعمل عليها دالة groupby. من الأفضل تعلم هذا من خلال مثال. لقد جمعت دالتي groupby و describe أدناه:
df.groupby('Organization').describe()
إليك كيف تبدو المخرجات:
دالة Pandas concat()
في هذا القسم، سنتعلم كيفية ربط Pandas DataFrames. سيكون هذا قسمًا موجزًا، لكنه مفهوم مهم مع ذلك. دعنا نبدأ!
DataFrames التي سنستخدمها في هذا القسم
لتوضيح كيفية دمج Pandas DataFrames، سأستخدم 3 أمثلة لـ DataFrames:
df1 = pd.DataFrame({
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
}, index=[0, 1, 2, 3])
df2 = pd.DataFrame({
'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']
}, index=[4, 5, 6, 7])
df3 = pd.DataFrame({
'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']
}, index=[8, 9, 10, 11])
كيفية ربط Pandas DataFrames
أي شخص أخذ دورة "مقدمة إلى Python" سيتذكر أن ربط السلاسل النصية (string concatenation) يعني إضافة سلسلة نصية إلى نهاية سلسلة نصية أخرى. مثال على ربط السلاسل النصية أدناه:
str1 = "Hello "
str2 = "World!"
str1 + str2 # تُرجع 'Hello World!'
ربط DataFrame مشابه جدًا. إنه يعني إضافة DataFrame إلى نهاية DataFrame آخر. لكي نتمكن من إجراء ربط DataFrame، يجب أن يكون لدينا اثنان من DataFrames بنفس الأعمدة. مثال أدناه:
pd.concat([df1, df2, df3])

افتراضيًا، ستقوم pandas بالربط على طول axis=0، مما يعني أنها تضيف صفوفًا، وليس أعمدة. إذا أردت إضافة صفوف، فما عليك سوى تمرير axis=0 كمتغير جديد إلى دالة concat.
pd.concat([df1,df2,df3],axis=1)
في حالتنا، هذا ينشئ DataFrame قبيحًا جدًا مع العديد من القيم المفقودة:
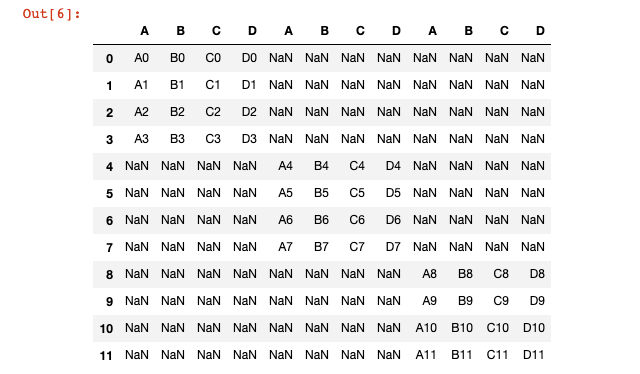
دالة Pandas merge()
في هذا القسم، سنتعلم كيفية دمج Pandas DataFrames.
DataFrames التي سنستخدمها في هذا القسم
في هذا القسم، سنستخدم Pandas DataFrames التاليين:
import pandas as pd
leftDataFrame = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']
})
rightDataFrame = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
})
تحتوي الأعمدة A و B و C و D على بيانات حقيقية، بينما يحتوي العمود key على مفتاح مشترك بين كلا DataFrames. دمج DataFrames يعني ربطهما على طول عمود واحد مشترك بينهما.
كيفية دمج Pandas DataFrames
يمكنك دمج Pandas DataFrames على طول عمود مشترك باستخدام دالة merge. لأي شخص مطلع على لغة برمجة SQL، هذا مشابه جدًا لتنفيذ inner join في SQL. لا تقلق إذا كنت غير مطلع على SQL، لأن بناء جملة merge بسيط جدًا في الواقع. يبدو هكذا:
pd.merge(leftDataFrame, rightDataFrame, how='inner', on='key')
دعنا نفصل الوسائط الأربعة التي مررناها إلى دالة merge:
leftDataFrame: هذا هوDataFrameالذي نود دمجه على اليسار.rightDataFrame: هذا هوDataFrameالذي نود دمجه على اليمين.how='inner': هذا هو نوع الدمج الذي تقوم به العملية. هناك أنواع متعددة من الدمج، لكننا سنغطي الدمج الداخلي (inner merges) فقط في هذه الدورة.on='key': هذا هو العمود الذي ترغب في إجراء الدمج عليه. نظرًا لأنkeyكان العمود الوحيد المشترك بينDataFrames، فقد كان الخيار الوحيد الذي يمكننا استخدامه لإجراء الدمج.
دالة Pandas join()
في هذا القسم، ستتعلم كيفية ربط Pandas DataFrames.
DataFrames التي سنستخدمها في هذا القسم
سنستخدم DataFrames التاليين في هذا القسم:
leftDataFrame = pd.DataFrame({
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']
}, index=['K0', 'K1', 'K2', 'K3'])
rightDataFrame = pd.DataFrame({
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
}, index=['K0', 'K1', 'K2', 'K3'])
إذا بدت هذه مألوفة، فذلك لأنها كذلك! هذه هي نفس DataFrames تقريبًا التي استخدمناها عند تعلم كيفية دمج Pandas DataFrames. الفرق الرئيسي هو أنه بدلاً من أن يكون عمود key عمودًا خاصًا به، فإنه الآن فهرس DataFrame. يمكنك التفكير في هذه DataFrames على أنها تلك من القسم الأخير بعد تنفيذ .set_index(key).
كيفية ربط Pandas DataFrames
ربط Pandas DataFrames مشابه جدًا لدمج Pandas DataFrames باستثناء أن المفاتيح التي ترغب في دمجها موجودة في الفهرس بدلاً من احتوائها داخل عمود. لربط هذين DataFrames، يمكننا استخدام الكود التالي:
leftDataFrame.join(rightDataFrame)
عمليات شائعة أخرى في Pandas
سيستكشف هذا القسم العمليات الشائعة في مكتبة Pandas Python. الغرض من هذا القسم هو استكشاف عمليات pandas المهمة التي لم تتناسب مع أي من الأقسام التي ناقشناها حتى الآن.
DataFrame الذي سنستخدمه في هذا القسم
سأستخدم DataFrame التالي في هذا القسم:
df = pd.DataFrame({
'col1':['A', 'B', 'C', 'D'],
'col2':[2, 7, 3, 7],
'col3':['fgh', 'rty', 'asd', 'qwe']
})
كيفية العثور على قيم فريدة في Pandas Series
تحتوي Pandas على دالة ممتازة تُسمى unique يمكن استخدامها للعثور على قيم فريدة داخل Pandas Series. لاحظ أن هذه الدالة تعمل فقط على Series وليس على DataFrames. إذا حاولت تطبيق هذه الدالة على DataFrame، فستواجه خطأ:
df.unique() # تُرجع AttributeError: 'DataFrame' object has no attribute 'unique'
ومع ذلك، نظرًا لأن أعمدة Pandas DataFrame هي كل منها Series، يمكننا تطبيق دالة unique على عمود معين، هكذا:
df['col2'].unique() # تُرجع array([2, 7, 3])
تحتوي Pandas أيضًا على دالة منفصلة تُسمى nunique تحسب عدد القيم الفريدة في Series وتُرجع تلك القيمة كعدد صحيح. على سبيل المثال:
df['col2'].nunique() # تُرجع 3
من المثير للاهتمام أن دالة nunique هي نفسها تمامًا len(unique()) ولكنها عملية شائعة بما يكفي لدرجة أن مجتمع pandas قرر إنشاء دالة محددة لحالة الاستخدام هذه.
كيفية حساب تكرار كل قيمة في Pandas Series
تحتوي Pandas على دالة تُسمى value_counts تسمح لك بسهولة حساب عدد مرات ظهور كل ملاحظة. مثال أدناه:
df['col2'].value_counts()
"""
Returns:
7 2
2 1
3 1
Name: col2, dtype: int64
"""
كيفية استخدام دالة Pandas apply()
تُعد دالة apply واحدة من أقوى الدوال المتاحة في مكتبة pandas. إنها تسمح لك بتطبيق دالة مخصصة على كل عنصر من عناصر Pandas Series. على سبيل المثال، تخيل أن لدينا الدالة exponentify التالية التي تأخذ عددًا صحيحًا وترفعه إلى قوة نفسه:
def exponentify(x):
return x**x
تسمح لك دالة apply بتطبيق دالة exponentify بسهولة على كل عنصر من عناصر Series:
df['col2'].apply(exponentify)
"""
Returns:
0 4
1 823543
2 27
3 823543
Name: col2, dtype: int64
"""
يمكن استخدام دالة apply أيضًا مع الدوال المدمجة مثل len (على الرغم من أنها بالتأكيد أكثر قوة عند استخدامها مع الدوال المخصصة). مثال على استخدام دالة len بالاقتران مع apply أدناه:
df['col3'].apply(len)
"""
Returns
0 3
1 3
2 3
3 3
Name: col3, dtype: int64
"""
كيفية فرز Pandas DataFrame
يمكنك تصفية Pandas DataFrame حسب قيم عمود معين باستخدام دالة sort_values. على سبيل المثال، إذا أردت الفرز حسب col2 في DataFrame الخاص بنا df، فستقوم بتشغيل الأمر التالي:
df.sort_values('col2')
مخرجات هذا الأمر أدناه:
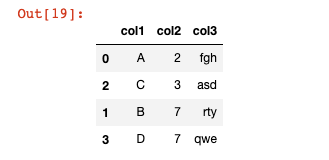
هناك شيئان يجب ملاحظتهما من هذه المخرجات:
- كما ترى، يحتفظ كل صف بفهره، مما يعني أن الفهرس أصبح الآن غير مرتب.
- كما هو الحال مع دوال
DataFrameالأخرى، لا تُعدل هذه الدالةDataFrameالأصلي فعليًا ما لم تجبرها على ذلك باستخدام عامل التعيين=أو عن طريق تمريرinplace = True.
إدخال وإخراج البيانات المحلية (I/O) في Pandas
في هذا القسم، سنبدأ في استكشاف إدخال وإخراج البيانات باستخدام مكتبة Pandas Python.
سنعمل مع ملفات مختلفة تحتوي على أسعار الأسهم لشركات مثل Facebook (FB)، Amazon (AMZN)، Google (GOOG)، و Microsoft (MSFT). يمكنك العثور على هذه الملفات في مجلد stock_prices ضمن مستودع GitHub الخاص بالدورة. يُفضل حفظ هذه الملفات في نفس الدليل الذي تستخدمه لدفتر ملاحظات Jupyter الخاص بك.
كيفية استيراد ملفات .csv باستخدام Pandas
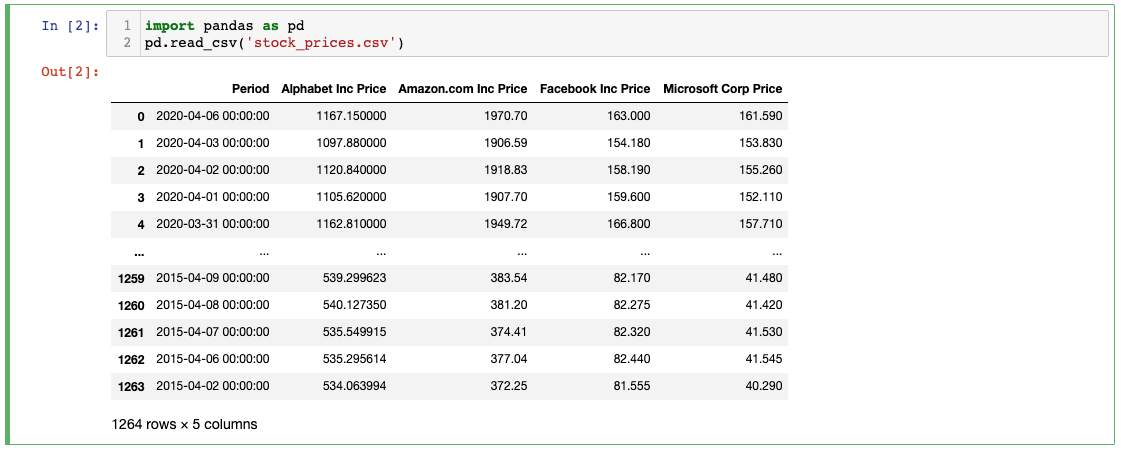
يمكننا استيراد ملفات .csv إلى Pandas DataFrame باستخدام دالة read_csv، هكذا:
import pandas as pd
pd.read_csv('stock_prices.csv')
كما سترى، هذا ينشئ (ويعرض) Pandas DataFrame جديدًا يحتوي على البيانات من ملف .csv.
يمكنك أيضًا تعيين هذا DataFrame الجديد لمتغير ليتم الرجوع إليه لاحقًا باستخدام عامل التعيين = العادي:
new_data_frame = pd.read_csv('stock_prices.csv')
هناك عدد من دوال read المضمنة في مكتبة برمجة pandas. إذا كنت تحاول استيراد بيانات من مستند خارجي، فمن المحتمل أن pandas لديها دالة مدمجة لهذا الغرض. إليك بعض الأمثلة على دوال read المختلفة:
pd.read_json()
pd.read_html()
pd.read_excel()
إذا أردنا استيراد ملف .csv لم يكن موجودًا مباشرة في دليل العمل الخاص بنا، نحتاج إلى تعديل بناء جملة دالة read_csv قليلاً. إذا كان الملف موجودًا في مجلد أعمق مما تعمل فيه الآن، فأنت بحاجة إلى تحديد المسار الكامل للملف في وسيط دالة read_csv. على سبيل المثال، إذا كان ملف stock_prices.csv موجودًا في مجلد يُسمى new_folder، فيمكننا استيراده هكذا:
new_data_frame = pd.read_csv('./new_folder/stock_prices.csv')
بالنسبة لأولئك غير المطلعين على العمل مع تدوين الدليل، فإن . في بداية مسار الملف يشير إلى الدليل الحالي. وبالمثل، يشير .. إلى دليل واحد فوق الدليل الحالي، ويشير ... إلى دليلين فوق الدليل الحالي. هذا البناء (باستخدام النقاط) هو بالضبط كيف نشير إلى (ونستورد) الملفات الموجودة فوق دليل العمل الحالي.
كيفية تصدير ملفات .csv باستخدام Pandas
لتوضيح كيفية حفظ ملف .csv جديد، دعنا أولاً ننشئ DataFrame جديدًا. على وجه التحديد، دعنا نملأ DataFrame بثلاثة أعمدة و 50 صفًا ببيانات عشوائية باستخدام دالة np.random.randn:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(50, 3))
الآن بعد أن أصبح لدينا DataFrame، يمكننا حفظه باستخدام دالة to_csv. تأخذ هذه الدالة اسم الملف الجديد كوسيط لها.
df.to_csv('my_new_csv.csv')
ستلاحظ أنه إذا قمت بتشغيل الكود أعلاه، سيبدأ ملف .csv الجديد بعمود غير مسمى يحتوي على فهرس DataFrame. مثال أدناه (بعد فتح ملف .csv في Microsoft Excel):
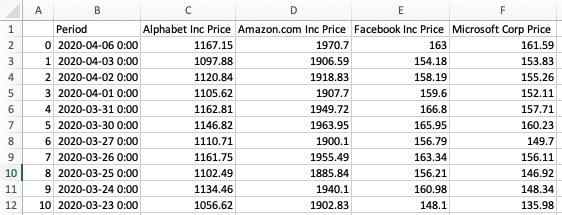
في كثير من الحالات، هذا غير مرغوب فيه. لإزالة عمود الفهرس الفارغ، مرر index=False كوسيط ثانٍ لدالة to_csv، هكذا:
new_data_frame.to_csv('my_new_csv.csv', index=False)
ملف .csv الجديد لا يحتوي على عمود الفهرس غير المسمى:
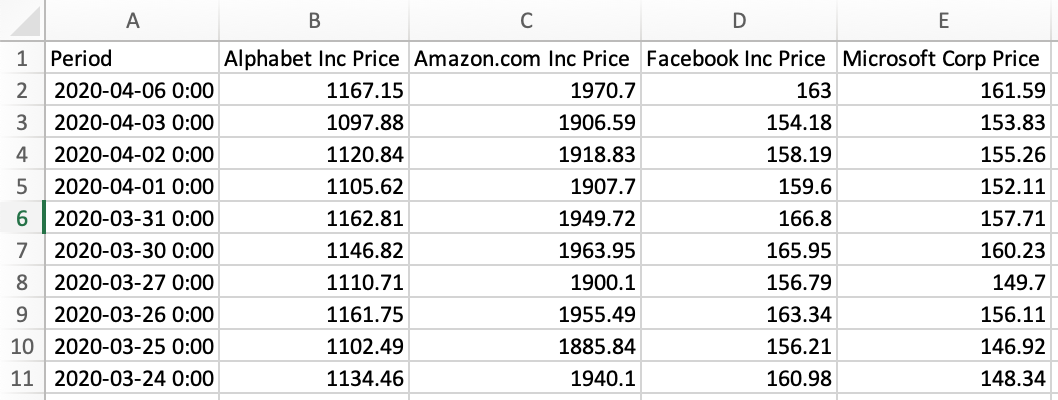
تُسهل دالتا read_csv و to_csv استيراد وتصدير البيانات من ملفات .csv باستخدام pandas. سنرى لاحقًا في هذا القسم أنه لكل دالة read تسمح لنا باستيراد البيانات، توجد عادةً دالة to مقابلة تسمح لنا بحفظ تلك البيانات!
كيفية استيراد ملفات .json باستخدام Pandas
إذا لم تكن لديك خبرة في العمل مع مجموعات البيانات الكبيرة، فقد لا تكون مطلعًا على نوع ملف JSON. يرمز JSON إلى JavaScript Object Notation. تشبه ملفات JSON قواميس Python إلى حد كبير. تُعد ملفات JSON أحد أكثر أنواع البيانات شيوعًا بين مطوري البرمجيات لأنه يمكن معالجتها باستخدام كل لغة برمجة تقريبًا. تحتوي Pandas على دالة تُسمى read_json تُسهل جدًا استيراد ملفات JSON كـ Pandas DataFrame. مثال أدناه:
json_data_frame = pd.read_json('stock_prices.json')
سنتعلم كيفية تصدير ملفات JSON لاحقًا.
كيفية تصدير ملفات .json باستخدام Pandas
كما ذكرت سابقًا، توجد عادةً دالة to لكل دالة read. هذا يعني أنه يمكننا حفظ DataFrame في ملف JSON باستخدام دالة to_json. على سبيل المثال، دعنا نأخذ DataFrame df الذي تم إنشاؤه عشوائيًا من وقت سابق في هذا القسم ونحفظه كملف JSON في دليلنا المحلي:
df.to_json('my_new_json.json')
سنتعلم كيفية العمل مع ملفات Excel - التي تحتوي على امتداد الملف .xlsx - بعد ذلك.
كيفية استيراد ملفات .xlsx باستخدام Pandas
تُسهل دالة read_excel في Pandas جدًا استيراد البيانات من مستند Excel إلى Pandas DataFrame:
new_data_frame = pd.read_excel('stock_prices.xlsx')
على عكس دالتي read_csv و read_json التي استكشفناها سابقًا في هذا القسم، يمكن لدالة read_excel قبول وسيط ثانٍ. السبب في أن read_excel تقبل وسائط متعددة هو أن جداول بيانات Excel يمكن أن تحتوي على أوراق متعددة. يحدد الوسيط الثاني الورقة التي تحاول استيرادها ويُسمى sheet_name. على سبيل المثال، إذا كان stock_prices الخاص بنا يحتوي على ورقة ثانية تُسمى Sheet2، فستقوم باستيراد تلك الورقة إلى Pandas DataFrame هكذا:
new_data_frame.to_excel('stock_prices.xlsx', sheet_name='Sheet2')
إذا لم تحدد أي قيمة لـ sheet_name، فستقوم read_excel باستيراد الورقة الأولى من جدول بيانات Excel افتراضيًا. أثناء استيراد مستندات Excel، من المهم جدًا ملاحظة أن pandas تستورد البيانات فقط. لا يمكنها استيراد قدرات Excel الأخرى مثل التنسيق أو الصيغ أو وحدات الماكرو. قد يؤدي محاولة استيراد البيانات من مستند Excel الذي يحتوي على هذه الميزات إلى تعطل pandas.
كيفية تصدير ملفات .xlsx باستخدام Pandas
يُشبه تصدير ملفات Excel إلى حد كبير استيراد ملفات Excel، باستثناء أننا نستخدم to_excel بدلاً من read_excel. مثال أدناه باستخدام DataFrame df الذي تم إنشاؤه عشوائيًا:
df.to_excel('my_new_excel_file.xlsx')
مثل read_excel، تقبل to_excel وسيطًا ثانيًا يُسمى sheet_name يسمح لك بتحديد اسم الورقة التي تحفظها. على سبيل المثال، كان بإمكاننا تسمية ورقة ملف .xlsx الجديد My New Sheet! عن طريق تمريرها إلى دالة to_excel هكذا:
df.to_excel('my_new_excel_file.xlsx', sheet_name='My New Sheet!')
إذا لم تحدد قيمة لـ sheet_name، فسيتم تسمية الورقة Sheet1 افتراضيًا (تمامًا كما عند إنشاء مستند Excel جديد باستخدام التطبيق الفعلي).
إدخال وإخراج البيانات عن بعد (Remote I/O) في Pandas
في القسم الأخير من هذه الدورة، تعلمنا كيفية استيراد البيانات من ملفات .csv و .json و .xlsx التي تم حفظها على جهاز الكمبيوتر المحلي الخاص بنا. سنتابع ذلك من خلال توضيح كيفية استيراد الملفات دون حفظها فعليًا على جهازك المحلي أولاً. يُسمى هذا remote importing (الاستيراد عن بعد).
ما هو الاستيراد عن بعد ولماذا هو مفيد؟
الاستيراد عن بعد يعني جلب ملف إلى نص Python البرمجي الخاص بك دون حفظ هذا الملف على جهاز الكمبيوتر الخاص بك. قد لا يبدو واضحًا للوهلة الأولى لماذا قد نرغب في الانخراط في الاستيراد عن بعد. ومع ذلك، يمكن أن يكون مفيدًا جدًا. السبب في أن الاستيراد عن بعد مفيد هو أنه، بحكم تعريفه، يعني أن نص Python البرمجي سيستمر في العمل حتى لو لم يتم حفظ الملف الذي يتم استيراده على جهاز الكمبيوتر الخاص بك. هذا يعني أنه يمكنني إرسال الكود الخاص بي إلى الزملاء أو الأصدقاء وسيظل يعمل بشكل صحيح.
طوال بقية هذا القسم، سأوضح كيفية إجراء عمليات الاستيراد عن بعد في pandas لملفات .csv و .json و .xlsx.
كيفية استيراد ملفات .csv عن بعد
أولاً، انتقل إلى مستودع GitHub الخاص بالدورة. افتح مجلد stock_prices. انقر على ملف stock_prices.csv ثم انقر على زر Raw file، كما هو موضح أدناه.
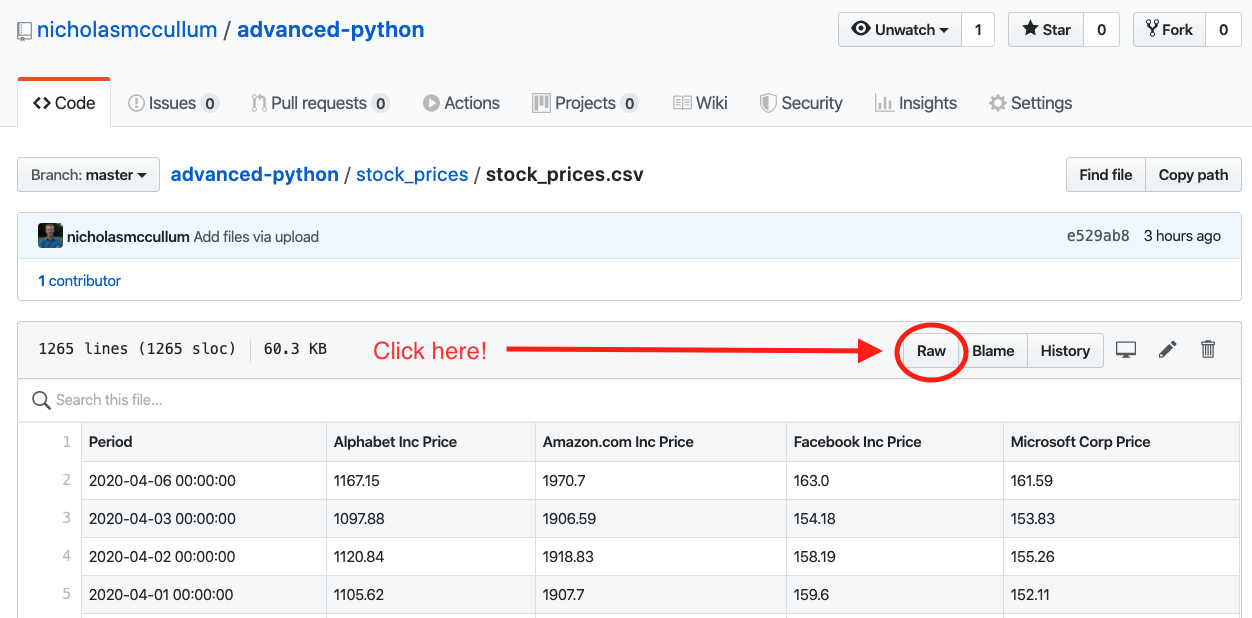
سيأخذك هذا إلى صفحة جديدة تحتوي على البيانات من ملف .csv الموجود داخل stock_prices.csv. لاستيراد هذا الملف عن بعد إلى نص Python البرمجي الخاص بك، يجب عليك أولاً نسخ عنوان URL الخاص به إلى الحافظة. يمكنك القيام بذلك إما عن طريق (1) تمييز عنوان URL بالكامل، والنقر بزر الماوس الأيمن على النص المحدد، والنقر على copy، أو (2) تمييز عنوان URL بالكامل وكتابة CTRL+C على لوحة المفاتيح. سيبدو عنوان URL هكذا:
https://raw.githubusercontent.com/nicholasmccullum/advanced-python/master/stock_prices/stock_prices.csv
يمكنك تمرير عنوان URL هذا إلى دالة read_csv لاستيراد مجموعة البيانات إلى Pandas DataFrame دون حفظ مجموعة البيانات على جهاز الكمبيوتر الخاص بك أولاً:
pd.read_csv('https://raw.githubusercontent.com/nicholasmccullum/advanced-python/master/stock_prices/stock_prices.csv')
كيفية استيراد ملفات .json عن بعد
يمكننا استيراد ملفات .json عن بعد بطريقة مشابهة لملفات .csv. أولاً، احصل على عنوان URL الخام من GitHub. سيبدو هكذا:
https://raw.githubusercontent.com/nicholasmccullum/advanced-python/master/stock_prices/stock_prices.json
بعد ذلك، مرر عنوان URL هذا إلى دالة read_json هكذا:
pd.read_json('https://raw.githubusercontent.com/nicholasmccullum/advanced-python/master/stock_prices/stock_prices.json')
كيفية استيراد ملفات .xlsx عن بعد
يمكننا استيراد ملفات .xlsx عن بعد بطريقة مشابهة لملفات .csv و .json. لاحظ أنك ستحتاج إلى النقر في مكان مختلف قليلاً على واجهة GitHub. على وجه التحديد، ستحتاج إلى النقر بزر الماوس الأيمن على ‘View Raw’ وتحديد ‘Copy Link Address’، كما هو موضح أدناه.
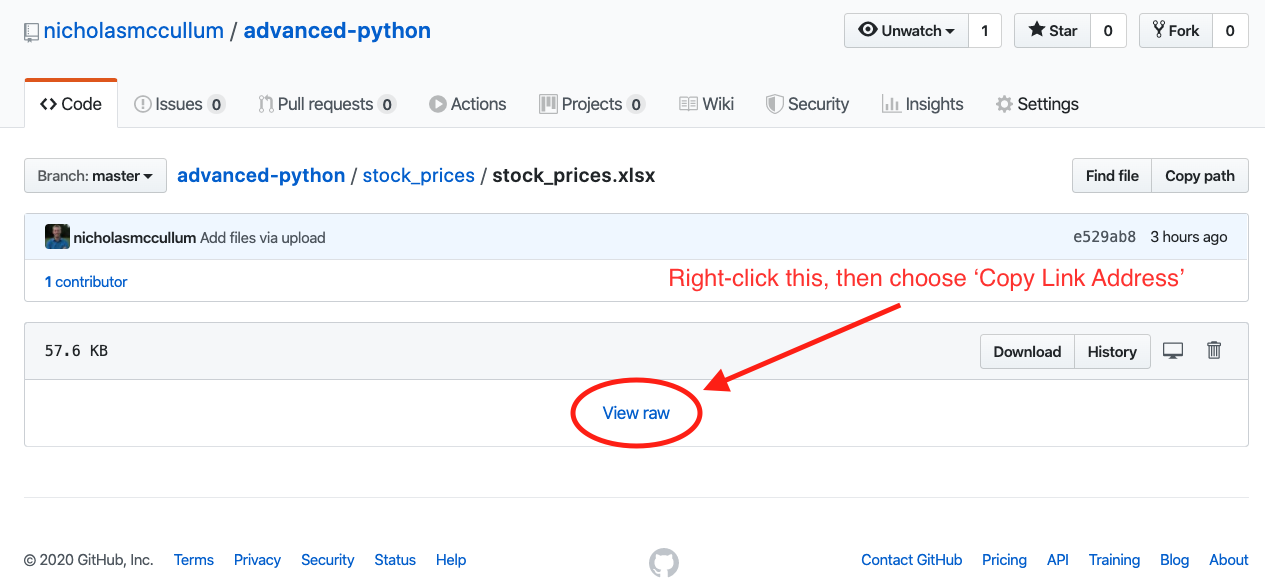
سيبدو عنوان URL الخام هكذا:
https://github.com/nicholasmccullum/advanced-python/blob/master/stock_prices/stock_prices.xlsx?raw=true
ثم، مرر عنوان URL هذا إلى دالة read_excel، هكذا:
pd.read_excel('https://github.com/nicholasmccullum/advanced-python/blob/master/stock_prices/stock_prices.xlsx?raw=true')
سلبيات الاستيراد عن بعد
الاستيراد عن بعد يعني أنك لست بحاجة إلى حفظ الملف الذي يتم استيراده على جهاز الكمبيوتر المحلي الخاص بك أولاً، وهي ميزة لا جدال فيها. ومع ذلك، فإن الاستيراد عن بعد له أيضًا عيبان:
- يجب أن يكون لديك اتصال بالإنترنت لإجراء عمليات الاستيراد عن بعد.
- الوصول إلى عنوان
URLلاسترداد مجموعة البيانات يستغرق وقتًا طويلاً نسبيًا، مما يعني أن إجراء عمليات الاستيراد عن بعد سيؤدي إلى إبطاء سرعة كودPythonالخاص بك.
الخلاصة التقنية
تُعد مكتبة Pandas بلا شك واحدة من أهم الأدوات في ترسانة أي متخصص في علوم البيانات أو مطور Python يعمل مع البيانات. لقد استعرض هذا الدليل الشامل قدراتها الأساسية، بدءًا من هياكل البيانات المحورية مثل Series و DataFrame، ووصولاً إلى التعامل مع البيانات المفقودة، ودمج مجموعات البيانات، وتنفيذ العمليات التجميعية المعقدة باستخدام groupby. إن مرونة Pandas وكفاءتها في التعامل مع البيانات الجدولية تجعلها لا غنى عنها في مراحل تنظيف البيانات، استكشافها، وتحويلها. القدرة على استيراد وتصدير البيانات من مصادر متنوعة، سواء كانت محلية أو بعيدة، تزيد من قيمتها كأداة شاملة لإدارة تدفقات عمل البيانات. إتقان Pandas يفتح الأبواب أمام تحليل بيانات أعمق وأكثر فعالية، مما يُمكن المطورين من بناء حلول قوية وقابلة للتطوير في مجالات مثل التمويل، التعلم الآلي، والتحليلات الإحصائية.