استخراج بيانات الويب باستخدام PHP: كيفية الزحف إلى صفحات المواقع بأدوات مفتوحة المصدر
مقدمة إلى استخراج بيانات الويب باستخدام PHP
يُعد استخراج بيانات الويب من الأساليب العملية التي تتيح جمع المعلومات من صفحات الإنترنت بشكل آلي، ويُعرف أيضاً باسم Web Scraping أو Web Crawling. وتبرز لغة PHP بوصفها واحدة من أكثر لغات البرمجة استخداماً في تطوير تطبيقات الويب الخلفية، ما يجعلها خياراً مناسباً لبناء أدوات قادرة على قراءة الصفحات واستخلاص البيانات منها.
يمكن تنفيذ هذه المهمة عبر كتابة شيفرة PHP من الصفر، لكن الاستفادة من المكتبات مفتوحة المصدر توفّر وقتاً كبيراً وتمنحك أدوات جاهزة للتعامل مع الطلبات، وتحليل المستندات، والتنقّل داخل عناصر الصفحة بكفاءة أعلى. في هذا الدليل، سنستعرض أبرز الأدوات التي يمكن استخدامها مع PHP لاستخراج البيانات من صفحات الويب، مثل Guzzle وGoutte وSimple HTML DOM وSymfony Panther.
ملاحظة مهمة: قبل البدء في استخراج البيانات من أي موقع، احرص على مراجعة شروط الاستخدام الخاصة به. فحتى إن كانت البيانات متاحة للعامة، فإن إرسال عدد كبير من الطلبات قد يضغط على خوادم الموقع. وفي بعض الحالات، قد يكون من الأفضل التواصل مع الجهة المالكة للموقع للحصول على API رسمي بدلاً من الاعتماد على الزحف.

كيفية إعداد المشروع قبل البدء
إذا كنت ترغب في تطبيق الأمثلة عملياً، فستحتاج إلى تهيئة بيئة التطوير بشكل صحيح. هذه الخطوة مهمة لتجنّب المشكلات المرتبطة بالإصدارات أو الاعتماديات.
المتطلبات الأساسية
- تثبيت أحدث إصدار مناسب من
PHP. - تثبيت أداة
Composerلإدارة الحزم والاعتماديات. - استخدام محرر شيفرة برمجية مناسب مثل
VS Codeأو أي محرر آخر تفضله.
إنشاء مجلد المشروع
بعد تجهيز البيئة، أنشئ مجلد المشروع ثم انتقل إليه من خلال الطرفية:
mkdir php_scraper
cd php_scraperتهيئة ملف composer.json
نفّذ الأمرين التاليين لإنشاء ملف الإعدادات الأساسي وتحديث الحزم:
composer init --require="php >= 7.4" --no-interaction
composer updateبعد اكتمال هذه الخطوات، تصبح جاهزاً للبدء في بناء أداة استخراج بيانات باستخدام PHP.
استخدام Guzzle وXML وXPath في استخراج البيانات
تُعد مكتبة Guzzle عميلاً قوياً للتعامل مع بروتوكول HTTP في PHP، إذ تتيح إرسال الطلبات واستقبال الاستجابات بأسلوب بسيط ومرن. وعند دمجها مع XPath، يمكن تحليل بنية الصفحة والوصول إلى العناصر المطلوبة بدقة.
أما XML فهو تنسيق بنيوي يُستخدم لتمثيل البيانات بطريقة قابلة للقراءة آلياً وبشرياً، بينما يُستخدم XPath كلغة استعلام تساعد على تحديد العقد والعناصر داخل المستند.
تثبيت مكتبة Guzzle
ابدأ بتثبيت المكتبة عبر Composer باستخدام الأمر التالي:
composer require guzzlehttp/guzzleبعد التثبيت، أنشئ ملفاً جديداً باسم guzzle_requests.php لتجربة الشيفرة.
الموقع التجريبي المستخدم
في هذا المثال، سنعتمد على موقع Books to Scrape لأنه مناسب للتعلم والتجارب. والهدف هو استخراج عناوين الكتب المعروضة في الصفحة وطباعتها داخل الطرفية.
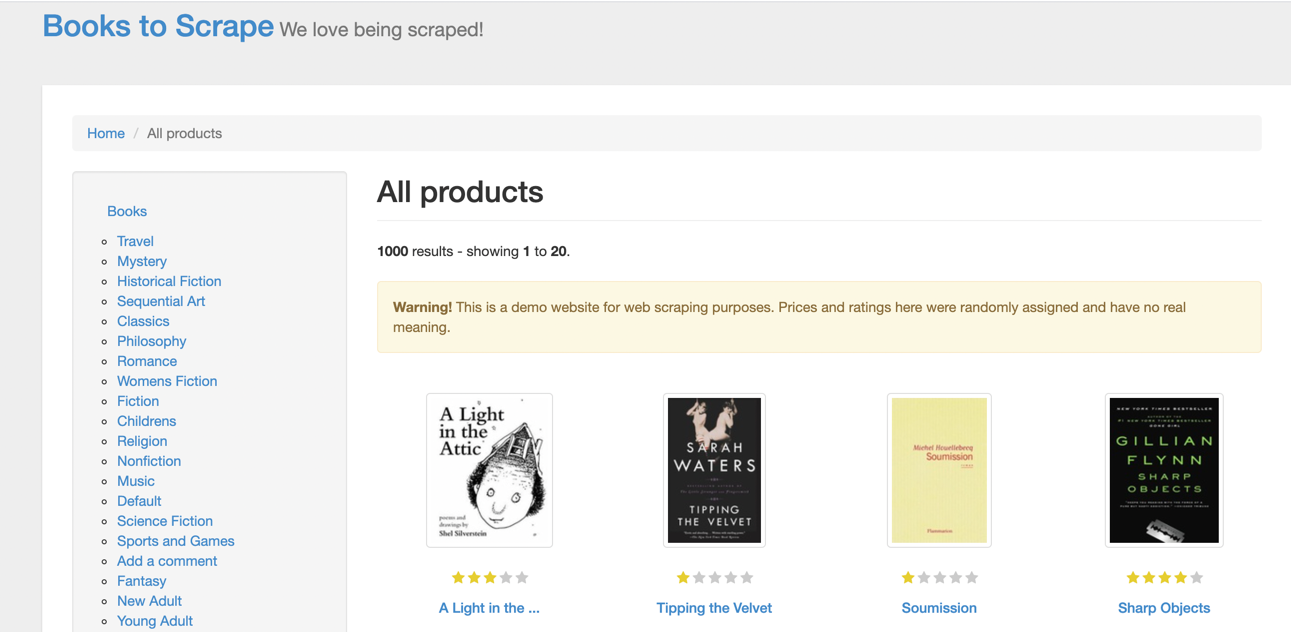
فهم بنية الصفحة قبل الزحف
الخطوة الأولى في أي عملية Web Scraping ناجحة هي فهم بنية HTML الخاصة بالصفحة. ويمكنك القيام بذلك عبر فتح أدوات المطور في المتصفح باستخدام خيار Inspect بعد النقر بزر الفأرة الأيمن على العنصر المطلوب.
عند فحص صفحة الكتب، ستلاحظ أن عنوان كل كتاب يوجد داخل عنصر رابط <a>، والذي يكون غالباً متضمناً داخل عناصر هيكلية أخرى مثل <article> أو <h3> وفقاً لبنية الصفحة.

فكرة العمل باستخدام XPath
بعد معرفة موقع البيانات داخل الصفحة، يمكنك استخدام تعبيرات XPath لاختيار العناصر المستهدفة، مثل روابط الكتب أو النصوص المخزنة داخل خاصية title. هذه الطريقة تمنحك دقة أعلى مقارنة بالبحث العشوائي داخل الشيفرة المصدرية.
عادةً تمر العملية بالمراحل التالية:
- إرسال طلب
HTTP GETإلى الصفحة. - استقبال محتوى الصفحة بصيغة
HTML. - تحميل المستند داخل محلّل مناسب.
- استخدام
XPathلتحديد العناصر المطلوبة. - استخراج النص أو السمات اللازمة مثل
titleأوhref.
مثال توضيحي على الفكرة العامة
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
$client = new Client();
$response = $client->request('GET', 'http://books.toscrape.com/');
$html = (string) $response->getBody();
$dom = new DOMDocument();
libxml_use_internal_errors(true);
$dom->loadHTML($html);
libxml_clear_errors();
$xpath = new DOMXPath($dom);
$nodes = $xpath->query('//article//h3/a');
foreach ($nodes as $node) {
echo $node->getAttribute('title') . PHP_EOL;
}تُظهر هذه الشيفرة التدفق الأساسي للعمل: تحميل الصفحة، تحليلها، ثم استخراج عناوين الكتب عبر محدد XPath مناسب.
لماذا تُعد الأدوات مفتوحة المصدر خياراً ذكياً؟
الاعتماد على مكتبات مفتوحة المصدر في مشاريع استخراج البيانات يوفر كثيراً من المرونة، خاصة عندما تحتاج إلى التوسع لاحقاً أو التعامل مع صفحات أكثر تعقيداً. كما أن هذه الأدوات غالباً ما تكون مدعومة من مجتمعات نشطة، ما يسهل العثور على حلول للمشكلات الشائعة.
| الأداة | الاستخدام الأساسي | متى تُناسبك؟ |
|---|---|---|
Guzzle |
إرسال طلبات HTTP |
عند الحاجة إلى جلب محتوى الصفحات بسرعة ومرونة |
XPath |
التنقل داخل بنية المستند | عند الرغبة في استخراج عناصر دقيقة من HTML أو XML |
Goutte |
الزحف وتحليل الصفحات بسهولة | للمهام السريعة والمتوسطة دون تعقيد كبير |
Simple HTML DOM |
التعامل المباشر مع عناصر HTML |
عندما تفضّل واجهة سهلة وبسيطة |
Symfony Panther |
محاكاة متصفح فعلي بدون واجهة | عند التعامل مع مواقع تعتمد على JavaScript |
أفضل ممارسات تحسين الأداء والالتزام بسياسات المواقع
نجاح مشروع استخراج البيانات لا يعتمد فقط على كتابة الشيفرة، بل يرتبط أيضاً بأخلاقيات التنفيذ واحترام البنية التشغيلية للمواقع المستهدفة.
نصائح مهمة قبل تنفيذ أي زاحف
- راجع ملف
robots.txtإن وُجد لمعرفة الصفحات المسموح الوصول إليها. - تجنب إرسال عدد كبير من الطلبات خلال فترة قصيرة.
- استخدم فترات انتظار بين الطلبات لتخفيف الضغط على الخادم.
- غيّر أسلوبك إلى
APIرسمي متى كان ذلك متاحاً. - اختبر الشيفرة على صفحات بسيطة قبل نقلها إلى مواقع أكبر وأكثر تعقيداً.
متى تحتاج إلى متصفح بدون واجهة؟
بعض المواقع لا تعرض محتواها الكامل داخل HTML الأولي، بل تولّده لاحقاً عبر JavaScript. في هذه الحالة، قد لا يكون Guzzle وحده كافياً، وهنا تظهر أهمية أدوات مثل Symfony Panther التي يمكنها تشغيل الصفحة كما يفعل المتصفح ثم استخراج المحتوى بعد اكتمال التحميل.
نصائح تحريرية لصناعة محتوى تقني مقبول في Google AdSense
إذا كنت تنشر مقالات تقنية حول البرمجة أو استخراج البيانات، فمن المهم أن يكون المحتوى مفيداً، واضحاً، ومبنياً على تجربة حقيقية. لا يكفي مجرد ترجمة الأفكار، بل يجب إعادة صياغتها بأسلوب يضيف فهماً أعمق للقارئ العربي.
- اشرح المفاهيم الأساسية قبل عرض الشيفرة.
- استخدم أمثلة قابلة للتطبيق وليست نظرية فقط.
- احرص على تقسيم المحتوى بعناوين واضحة ومنظمة.
- تجنب النسخ الحرفي أو الحشو الذي يضعف جودة الصفحة.
- قدّم خلاصة أو رأياً تقنياً في نهاية المقال لإبراز القيمة المضافة.
الخلاصة التقنية
يُعد استخدام PHP في استخراج بيانات الويب خياراً عملياً وفعالاً، خصوصاً عند دمجه مع أدوات مثل Guzzle وXPath. وإذا كانت الصفحة بسيطة وثابتة، فغالباً ستكفيك هذه الأدوات لإنجاز المهمة بكفاءة. أما في المواقع الديناميكية التي تعتمد على JavaScript، فستحتاج إلى حلول أكثر تقدماً مثل Symfony Panther. الأهم من ذلك كلّه هو أن يكون الزحف منظماً، قانونياً، ويهدف إلى تقديم فائدة حقيقية دون الإضرار بالمواقع المستهدفة.