مبادئ البرمجة الوظيفية: دليل شامل للمطورين

مرحباً بكم في منصة قيد! بصفتي خبيراً في تحسين محركات البحث ومحرر محتوى تقني، يسعدني أن أقدم لكم هذا الدليل الشامل حول مبادئ البرمجة الوظيفية (Functional Programming - FP). في هذا المقال، سنستعرض المبادئ الأساسية للبرمجة الوظيفية، ثم ننتقل لاستكشاف مفاهيم أكثر تقدماً. سنبدأ بالحديث عن أهمية البرمجة الوظيفية ومتى تكون مفيدة ومتى لا تكون كذلك.
سنغطي الكثير من المعلومات هنا، لذا يرجى أخذ وقتكم الكافي في القراءة. لا تترددوا في أخذ فترات راحة بين جلسات القراءة وممارسة التمارين المقترحة. بالطبع، يمكنكم تخطي الأقسام أو العودة إليها حسب احتياجاتكم.
يستهدف هذا المقال عدة أنواع من القراء:
- أولئك الذين لا يعرفون شيئاً تقريباً عن البرمجة الوظيفية (
FP) ولكنهم على دراية جيدة بلغةJavaScript. - أصحاب المعرفة المتوسطة بالبرمجة الوظيفية (
FP) وبعض الألفة مع هذا النمط البرمجي، ولكنهم يرغبون في الحصول على صورة أوضح للموضوع واستكشاف المفاهيم المتقدمة. - أولئك الذين لديهم معرفة واسعة بالبرمجة الوظيفية (
FP) ويرغبون في ورقة غش سريعة لمراجعة بعض المفاهيم عند الحاجة.
أدعوكم للتفكير ملياً في كل جملة بدلاً من التسرع في المحتوى كما اعتدنا جميعاً. آمل أن يكون هذا المقال علامة فارقة في رحلتكم إلى عالم البرمجة الوظيفية، ومصدراً للمعلومات يمكن الرجوع إليه عند الحاجة. فقط تذكروا، هذا المقال لا يشكل مصدراً وحيداً للحقيقة، بل هو دعوة للتعمق أكثر بعد قراءته. بعبارة أخرى، إنه مصمم للمراجعة والتوسع بموارد وممارسات إضافية. آمل أن أوضح لكم المشهد الوظيفي في أذهانكم، وأثير اهتمامكم بما لم تكونوا تعرفونه، والأهم من ذلك، أن أقدم لكم أدوات مفيدة لمشاريعكم اليومية. دون مزيد من اللغط، دعونا نبدأ!
لماذا البرمجة الوظيفية؟
في رأيي، هناك 3 فوائد رئيسية للبرمجة الوظيفية (FP) و 3 عيوب (صغيرة):
المزايا:
- قابلية قراءة أعلى، وبالتالي قابلية صيانة أفضل: الكود يكون أسهل في الفهم والتعديل.
- أخطاء أقل، خاصة في سياقات التزامن: تقلل من المشاكل المتعلقة بتغيير الحالة المشتركة.
- طريقة جديدة للتفكير في حل المشكلات: تفتح آفاقاً جديدة للمنطق البرمجي.
- (ميزة شخصية إضافية) رائعة للتعلم بحد ذاتها!
العيوب:
- قد تواجه مشكلات في الأداء: بسبب طبيعة عدم التغيير ونسخ البيانات.
- أقل بديهية عند التعامل مع الحالة (
state) وعمليات الإدخال/الإخراج (I/O): تتطلب فهماً مختلفاً لكيفية إدارة التفاعلات الخارجية. - غير مألوفة لمعظم الناس + مصطلحات رياضية تبطئ عملية التعلم: منحنى تعلم أولي قد يكون صعباً.
الآن سأشرح لماذا أعتقد ذلك.
زيادة قابلية القراءة
أولاً، غالباً ما تكون البرمجة الوظيفية (Functional Programming) أكثر قابلية للقراءة بسبب طبيعتها التصريحية (declarative). بعبارة أخرى، يركز الكود على وصف نتيجة العمليات، وليس العمليات نفسها. يصف كايل سيمبسون (Kyle Simpson) الأمر على النحو التالي:
الكود التصريحي (
Declarative code) هو الكود الذي يركز بشكل أكبر على وصف “ما” هي النتيجة. الكود الأمرّي (Imperative code) (العكس) يركز على توجيه الكمبيوتر بدقة “كيف” يفعل شيئاً ما.
نظراً لأننا نقضي الغالبية العظمى من وقتنا في قراءة الكود (حوالي 80% من الوقت، على ما أعتقد) وليس كتابته، فإن قابلية القراءة هي أول شيء يجب أن نعززه لزيادة كفاءتنا عند البرمجة. من المحتمل جداً أيضاً أن تعود إلى مشروع بعد عدة أسابيع من عدم لمسه، لذا فإن كل السياق المحمّل في ذاكرتك قصيرة المدى سيكون قد اختفى. وبالتالي، لن يكون فهم الكود الأمرّي (imperative code) الخاص بك سهلاً كما كان. وينطبق الشيء نفسه على الزملاء المحتملين الذين يعملون معك في المشروع. لذا فإن قابلية القراءة ميزة ضخمة لغرض أكثر أهمية: قابلية الصيانة. يمكنني التوقف عن الجدال هنا. يجب أن تمنحك زيادة قابلية القراءة دافعاً كبيراً لتعلم البرمجة الوظيفية. لحسن الحظ، هذه ميزة ستختبرها أكثر فأكثر كلما أصبحت على دراية بالنمط البرمجي. لا حاجة لأن تكون خبيراً. في اللحظة التي تكتب فيها سطراً من الكود التصريحي (declarative code)، ستختبر ذلك. الآن، الحجة الثانية.
كود أقل عرضة للأخطاء
البرامج الوظيفية (Functional programs) أقل عرضة للأخطاء، خاصة في سياقات التزامن (concurrent contexts). نظراً لأن النمط الوظيفي يسعى جاهداً لتجنب التغييرات (mutations)، فإن الموارد المشتركة لن تحتوي على محتويات غير متوقعة. على سبيل المثال، تخيل أن خيطين (threads) يصلان إلى نفس المتغير. إذا كان هذا المتغير قابلاً للتغيير (mutable)، فمع نمو البرامج، من المحتمل ألا تحصل على ما تريده عند إعادة الوصول إليه. بالإضافة إلى ذلك، فإن ظهور أنظمة المعالجات المتعددة (multiprocessor systems) يسمح بخيوط متعددة بالتنفيذ بالتوازي. لذا يوجد الآن أيضاً خطر التداخل (قد يحاول خيط الكتابة بينما يحاول الآخر القراءة). إنه لأمر مخز نوعاً ما عدم الاستفادة من الأجهزة لأننا غير قادرين على جعل البرمجيات تعمل. ومع ذلك، فإن JavaScript أحادية الخيط (single-threaded) وتجربتي الشخصية لا تتوسع كثيراً خارجها. وبالتالي، أنا أقل ثقة في هذه الحجة، لكن المبرمجين الأكثر خبرة يبدو أنهم يتفقون على هذه الحقيقة (مما سمعت/قرأت).
حل المشكلات
أخيراً، الميزة الأخيرة – والأكثر أهمية مما قد تتخيل – هي أن البرمجة الوظيفية (Functional Programming) تمنحك طريقة جديدة للتفكير في حل المشكلات. قد تكون معتاداً جداً على حل المشكلات باستخدام الفئات (classes) والكائنات (objects) (البرمجة الشيئية التوجه – Object-Oriented Programming) لدرجة أنك لا تفكر حتى في أنه قد تكون هناك طريقة أفضل للقيام بذلك. أنا لا أقول إن البرمجة الوظيفية أفضل دائماً. أنا أقول إنها ستكون أفضل في حالات معينة وأن امتلاك هذه المعرفة سيفتح عقلك (أو يعيد فتحه) ويجعلك مبرمجاً أفضل. لأنه سيكون لديك الآن المزيد من الأدوات وقدرة متزايدة على اختيار الأداة المناسبة للمشكلة المطروحة. أعتقد حتى أن بعض المبادئ الأساسية في البرمجة الوظيفية (FP) يمكن أن تُترجم إلى حل المشكلات خارج مجال أجهزة الكمبيوتر. دعونا نرى العيوب الآن.
مشكلات الأداء
العيب الأول هو أنه من خلال تطبيق تقنيات البرمجة الوظيفية (FP)، قد ينتهي بك الأمر باستخدام الكثير من الوقت و/أو الذاكرة. نظراً لأنك لا تريد تغيير الأشياء، فإن العملية هي أساساً نسخ البيانات، ثم تغيير تلك النسخة واستخدامها كحالة حالية. هذا يعني أن البيانات الأصلية تُترك دون تغيير ولكنك تخصص الكثير من الوقت والذاكرة لإنشاء النسخة الجديدة. لذا عندما تقوم بإنشاء الكثير من النسخ (كائنات متداخلة كبيرة جداً) أو تستخدم تقنيات مثل العودية (recursion) (تراكم الطبقات في مكدس الاستدعاء – callstack)، قد تظهر مشكلات في الأداء. ومع ذلك، توجد العديد من الحلول (مثل المشاركة الهيكلية – structural sharing، وتحسين استدعاء الذيل – tail-call optimization) التي تجعل الأداء الضعيف نادراً جداً.
أقل بديهية
العيب الثاني هو عندما تحتاج إلى حالة (state) أو عمليات إدخال/إخراج (I/O operations). حسناً، ستقول: أجهزة الكمبيوتر هي آلات ذات حالة (stateful machines)! وفي النهاية سأحتاج إلى استدعاء قاعدة بياناتي، أو عرض شيء على الشاشة، أو كتابة ملف. أنا أتفق تماماً. المهم هو أن نتذكر أن البرمجة الوظيفية (Functional Programming) هي أسلوب مناسب للبشر، لكن الآلات تقوم بعمليات أمرّية (imperative operations) (أي تغييرات – mutations) طوال الوقت. هذه هي طريقة عملها على أدنى مستوى. يكون الكمبيوتر في حالة معينة في لحظة معينة ويتغير طوال الوقت. الهدف من البرمجة الوظيفية (FP) هو تسهيل منطقنا حول الكود مما يزيد من فرص أن تعمل الأشياء المعقدة التي تنتج عنه بالفعل. وتساعدنا البرمجة الوظيفية التفاعلية (Functional Reactive Programming) في التعامل مع الحالة (state) (إذا كنت ترغب في معرفة المزيد، توجد روابط في نهاية المقال).
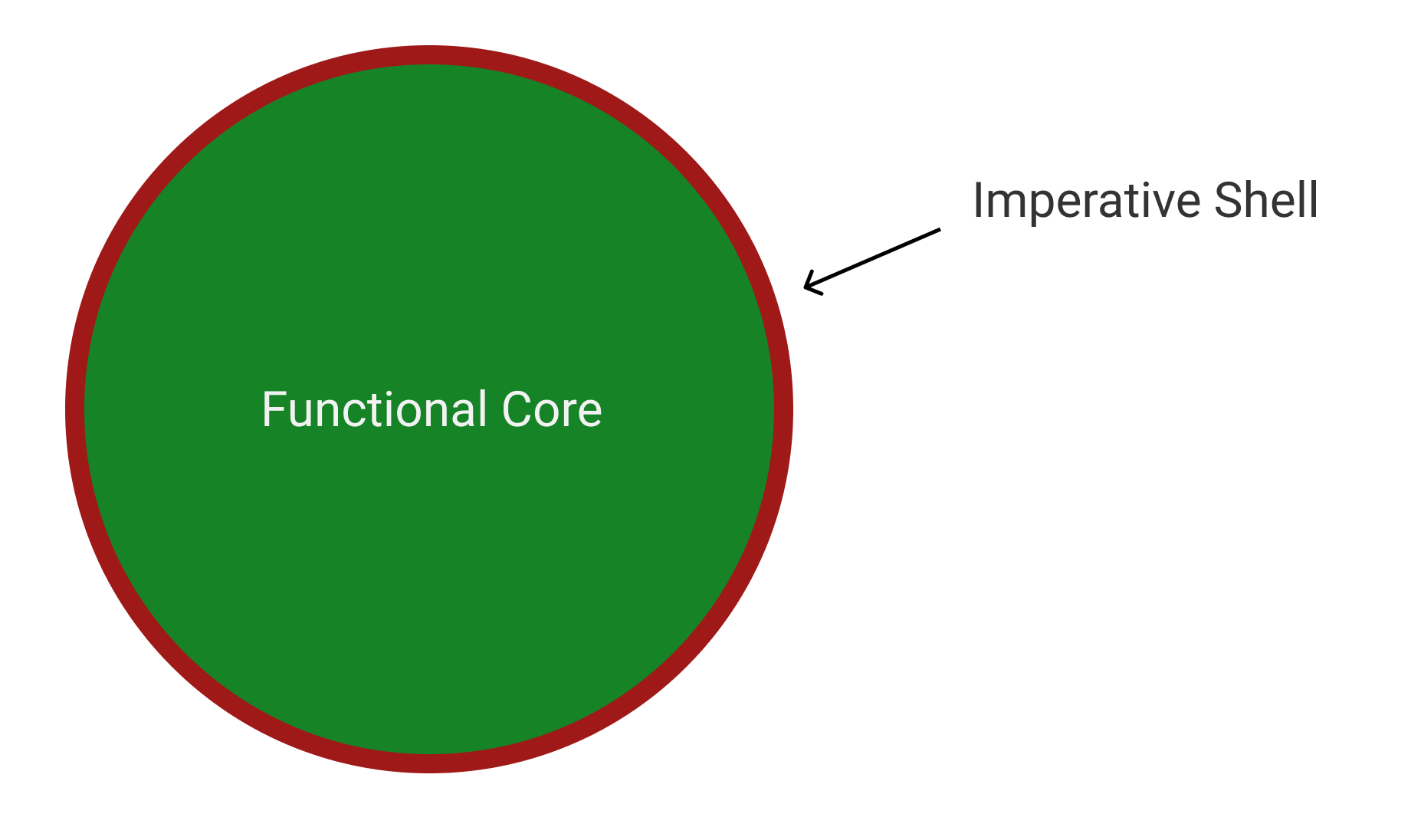
حتى لو بدا الكود الأمرّي (imperative code) أسهل/أكثر بديهية للوهلة الأولى، فسوف تفقد المسار في النهاية. أنا واثق تماماً أنه إذا بذلت الجهود الأولية لتعلم البرمجة الوظيفية (FP)، فسوف تؤتي ثمارها. بالنسبة لعمليات الإدخال/الإخراج (I/O) – اختصار لـ Input/Output، أي الكود الذي ينقل البيانات إلى أو من جهاز كمبيوتر وإلى أو من جهاز طرفي – لا يمكننا الحصول على دوال نقية ومعزولة بعد الآن. للتعامل مع ذلك، يمكننا اتباع نهج “اللب الوظيفي والقشرة الأمرّية” (Functional Core Imperative Shell). بعبارة أخرى، نريد أن نفعل أكبر قدر ممكن بطريقة وظيفية وندفع عمليات الإدخال/الإخراج (I/O operations) إلى الطبقة الخارجية للبرنامج:
منحنى تعلم أكثر حدة
أخيراً، العيب الأخير هو أن البرمجة الوظيفية (Functional Programming) مليئة بالمصطلحات الرياضية. وهذا غالباً ما يخلق احتكاكاً غير ضروري عندما يحاول المطورون تعلمها. من المحتمل أن يكون ذلك لأن هذا النمط من البرمجة ظهر لأول مرة في العالم الأكاديمي وبقي هناك لفترة طويلة قبل أن يظهر ويصبح أكثر شعبية. ومع ذلك، لا ينبغي لهذه المصطلحات التقنية/غير المألوفة أن تجعلك تهمل المبادئ الرياضية القوية جداً التي تكمن وراءها.
بشكل عام، أعتقد أن نقاط قوة البرمجة الوظيفية (FP) تفوق نقاط ضعفها. وتعتبر البرمجة الوظيفية منطقية جداً لغالبية برمجة JavaScript للأغراض العامة. فقط تذكر أن هناك عدداً قليلاً من البرامج ذات المتطلبات الخاصة التي لا تتناسب معها البرمجة الوظيفية (FP). ولكن إذا لم تكن هذه هي حالتك، فلا يوجد سبب لعدم الاستفادة من هذا النمط البرمجي.
الآن، إذا كنت مبتدئاً تماماً، فقد تشعر ببعض الضياع. لا بأس – تابع معي. ستوضح الأقسام التالية المفاهيم التي أشرت إليها هنا. الآن دعونا نتعمق في جوهر البرمجة الوظيفية.
البيانات، العمليات الحسابية، والإجراءات
في البرمجة الوظيفية (FP)، يمكنك تقسيم برنامجك إلى 3 أجزاء: البيانات (data)، العمليات الحسابية (calculations)، والإجراءات (actions).
البيانات (Data)
البيانات هي، حسناً، البيانات. في لغاتنا، تتخذ أشكالاً وأنواعاً مختلفة. في JavaScript لديك الأرقام (numbers)، السلاسل النصية (strings)، المصفوفات (arrays)، الكائنات (objects)، وما إلى ذلك. ولكن في النهاية، هي مجرد بتات (bits). البيانات هي اللبنات الأساسية للبرنامج. عدم وجودها يشبه عدم وجود ماء في حديقة مائية. ثم يمكننا فعل أشياء بالبيانات: عمليات حسابية أو إجراءات.
العمليات الحسابية (Calculations)
العمليات الحسابية هي تحويلات للبيانات شبيهة بالرياضيات. الدوال (Functions) هي طريقة لإنشائها. أنت تزودها بمجموعة من المدخلات (inputs) وهي تُرجع لك مجموعة من المخرجات (outputs). هذا كل شيء. لا تفعل شيئاً خارج الدالة، تماماً كما في الرياضيات. العالم المحيط بالدالة لا يتأثر. بالإضافة إلى ذلك، إذا قمت بتغذية الدالة بنفس المدخلات عدة مرات، فيجب أن تعطيك دائماً نفس المخرجات. المصطلح الشائع لهذا النوع من الدوال هو “دالة نقية” (pure function). بسبب خصائصها، يكون سلوكها بالكامل معروفاً مسبقاً. في الواقع، نظراً لأنها تُرجع قيمة فقط، يمكننا التعامل معها على أنها تلك القيمة، كبيانات. بعبارة أخرى، يمكننا استبدال استدعاء الدالة بالقيمة التي تُرجعها ولن يغير ذلك حالة البرنامج. وهذا ما يسمى “الشفافية المرجعية” (referential transparency). وبالتالي، من السهل جداً فهمها، ويمكنك استخدامها كمدخل أو مخرج لدالة وتعيينها للمتغيرات. هذه الأنواع من الدوال تسمى “دوال من الدرجة الأولى” (first-class functions). في JavaScript، جميع الدوال هي دوال من الدرجة الأولى. من الآمن استخدام الدوال النقية (pure functions) لأنها، مرة أخرى، مثل القيم. بالنسبة للدوال التي تفعل أكثر من إرجاع قيمة، فإنك تعتمد على الذاكرة البشرية. وهذه استراتيجية سيئة، خاصة للبرامج الكبيرة التي يعمل عليها عدة أشخاص. لذا يمكنك استخدام الدوال النقية (pure functions) كبديل للعمليات الحسابية (calculations). إنهما متطابقان. الآن دعنا نتحدث عن الإجراءات.
الإجراءات (Actions)
بالطبع، نحتاج أيضاً إلى دوال تؤثر على العالم الخارجي، وتفعل شيئاً بالفعل. وإلا، فإن برنامجك سيكون آلة حاسبة بدون شاشة. عندما تؤثر دالة على أشياء خارج نطاقها، نقول إن لها “آثاراً جانبية” (side-effects). على عكس الدوال النقية (pure functions)، يقال إنها “غير نقية” (impure). الآثار الجانبية الشائعة هي تعيين/تغيير المتغيرات خارج الدالة، التسجيل في وحدة التحكم (logging to the console)، إجراء استدعاء واجهة برمجة تطبيقات (API call)، وما إلى ذلك. لذا، أساساً، الإجراءات (actions) والدوال غير النقية (impure functions) هما الشيء نفسه. إليك مثال بسيط لتوضيح هذه المفاهيم:
// ↓ variable
// ↓ data
let a = 3;
// Calculation / Pure function
const double = (x) => x * 2;
double(a); // 6
// Action / Impure function
const IncThenPrint = () => {
// assignment of a variable outside the scope of the function
a = a + 1;
// do something (here printing) outside the function
console.log(a);
};
IncThenPrint(); // console: 4
في البرمجة الوظيفية (FP)، الهدف هو فصل البيانات (data) والعمليات الحسابية (calculations) والإجراءات (actions) مع السعي للقيام بمعظم العمليات باستخدام العمليات الحسابية. لماذا؟ لأن الإجراءات (actions) تعتمد على العالم الخارجي. ليس لدينا سيطرة كاملة عليه. وبالتالي، قد نحصل على نتائج/سلوكيات غير متوقعة منها. لذا إذا كانت غالبية برنامجك تتكون من إجراءات (actions)، فإنه سرعان ما يصبح فوضى. بأخذ المثال السابق، ماذا لو قرر شخص ما في مكان آخر في البرنامج تعيين كائن للمتغير a؟ حسناً، سنحصل على نتيجة غير متوقعة عند تشغيل IncThenPrint() لأنه لا معنى لإضافة 1 إلى كائن:
let a = 3;
// ...
a = { key: "value" };
// ...
// Action / Impure function
const IncThenPrint = () => {
// assignment of a variable outside the scope of the function
a = a + 1;
// do something (here printing) outside the function
console.log(a); // prints: 4
};
IncThenPrint(); // prints: [object Object]1
// (Because JavaScript is a dynamically-typed language, it converts both operands of the + operator
// to strings so it can perform the operation, thus explaining the result.
// But obviously, that not what was intended.)
القدرة على التمييز بين البيانات (data) والعمليات الحسابية (calculations) والإجراءات (actions) في برنامجك هي مهارة أساسية يجب تطويرها.
الربط (Mapping)
الربط (Mapping) هو مفهوم بسيط ولكنه مهم جداً في عالم البرمجة الوظيفية. “الربط من A إلى B” يعني الانتقال من A إلى B عبر بعض الارتباط. بعبارة أخرى، يشير A إلى B بواسطة رابط بينهما. على سبيل المثال، تربط دالة نقية (pure function) مدخلاً بمخرج. يمكننا كتابة ذلك على النحو التالي: input --> output؛ حيث يشير السهم إلى دالة. مثال آخر هو الكائنات (objects) في JavaScript. إنها تربط المفاتيح (keys) بالقيم (values). في لغات أخرى، غالباً ما يسمى هذا الهيكل البياناتي “خريطة” (map) أو “خريطة تجزئة” (hash-map)، وهو أكثر وضوحاً. كما يوحي المصطلح الأخير، فإن ما يحدث خلف الكواليس هو أن كل مفتاح مرتبط بقيمته عبر دالة تجزئة (hash function). يتم تمرير المفتاح إلى دالة التجزئة التي تُرجع فهرس القيمة المقابلة في المصفوفة التي تخزنها جميعاً. دون الخوض في مزيد من التفاصيل، أردت تقديم هذا المصطلح لأنني سأستخدمه في جميع أنحاء هذا المقال.
مزيد من التفاصيل حول الآثار الجانبية (Side-Effects)
قبل أن ننتقل، أرغب في التعمق أكثر في الآثار الجانبية (side-effects) في JavaScript وعرض مشكلة خفية قد لا تكون على دراية بها. للتذكير، القول بأن الدالة لها آثار جانبية هو نفسه القول: “عندما تعمل هذه الدالة، سيتغير شيء خارج نطاقها”. كما قلت، يمكن أن يكون ذلك تسجيل في وحدة التحكم (logging to the console)، أو إجراء استدعاء واجهة برمجة تطبيقات (API call)، أو تغيير متغير خارجي، وما إلى ذلك. دعنا نرى مثالاً على الأخير:
let y;
const f = (x) => {
y = x * x;
};
f(5);
y; // 25
هذا سهل الفهم جداً. عندما تعمل الدالة f()، فإنها تعين قيمة جديدة للمتغير الخارجي y، وهو أثر جانبي. نسخة نقية من هذا المثال ستكون:
const f = (x) => x * x;
const y = f(5); // 25
ولكن هناك طريقة أخرى لتغيير متغير خارجي تكون أكثر دقة:
let myArr = [1, 2, 3, { key: "value" }, "a string", 4];
const g = (arr) => {
let total = 0;
for (let i = 0; i < arr.length; i++) {
if (Number.isNaN(Number(arr[i]))) {
arr[i] = 0;
}
total += arr[i];
}
return total;
};
g(myArr); // 10
myArr; // [1, 2, 3, 0, 0, 4]
// Oops, all elements that were not numbers have been changed to 0 !
لماذا حدث هذا؟ في JavaScript، عند تعيين قيمة لمتغير أو تمريرها إلى دالة، يتم نسخها تلقائياً. ولكن هناك فرق يجب إجراؤه هنا. القيم البدائية (Primitive values) (null، undefined، السلاسل النصية strings، الأرقام numbers، القيم المنطقية booleans، والرموز symbols) يتم تعيينها/تمريرها دائماً "بواسطة نسخة القيمة" (by value-copy). على النقيض من ذلك، فإن القيم المركبة (compound values) مثل الكائنات objects، المصفوفات arrays، والدوال functions (بالمناسبة، المصفوفات والدوال هي كائنات في JavaScript، لكنني لا أشير إليها على أنها كائنات للوضوح) تنشئ "نسخة بواسطة المرجع" (copy by reference) عند التعيين أو التمرير. لذا في المثال السابق، القيمة التي تم تمريرها إلى g() هي قيمة مركبة، وهي المصفوفة myArr. ما يحدث هو أن g() تخزن عنوان الذاكرة الخاص بـ myArr في arr، وهو اسم المعامل المستخدم في جسم الدالة. بعبارة أخرى، لا توجد نسخة قيمة لكل عنصر في myArr كما تتوقع. وبالتالي، عندما تقوم بمعالجة أو تغيير arr، فإنها تذهب بالفعل إلى موقع ذاكرة myArr وتنفذ أي عملية حسابية تحددها. لذا نعم، كن على دراية بهذه الخاصية الغريبة.
تمارين (المجموعة 1)
في المقتطف أدناه، ابحث عن الدوال النقية (pure functions) والدوال غير النقية (impure ones):
// a
const capitalizeFirst = (str) => str.charAt(0).toUpperCase() + str.slice(1);
// b
const greeting = (persons) => {
persons.forEach((person) => {
const fullname = `${capitalizeFirst(person.firstname)} ${capitalizeFirst(
person.lastname
)}`;
console.log(`Hello ${fullname}!`);
});
};
// c
const getLabels = async (endpoint) => {
const res = await fetch("https://my-database-api/" + endpoint);
const data = await res.json();
return data.labels;
};
// d
const counter = (start, end) => {
return start === end ? "End" :
// e
() => counter(start + 1, end);
};
قم بتحويل هذا المقتطف إلى دالة نقية (pure one) (يمكنك إنشاء أكثر من دالة واحدة إذا شعرت بالحاجة إلى ذلك):
const people = [
{ firstname: "Bill", lastname: "Harold", age: 54 },
{ firstname: "Ana", lastname: "Atkins", age: 42 },
{ firstname: "John", lastname: "Doe", age: 57 },
{ firstname: "Davy", lastname: "Johnson", age: 34 },
];
const parsePeople = (people) => {
const parsedPeople = [];
for (let i = 0; i < people.length; i++) {
people[i].firstname = people[i].firstname.toUpperCase();
people[i].lastname = people[i].lastname.toUpperCase();
}
const compareAges = (person1, person2) => person1.age - person2.age;
return people.sort(compareAges);
};
parsePeople(people);
// [
// {firstname: "DAVY", lastname: "JOHNSON", age: 34},
// {firstname: "ANA", lastname: "ATKINS", age: 42},
// {firstname: "BILL", lastname: "HAROLD", age: 54},
// {firstname: "JOHN", lastname: "DOE", age: 57},
// ]
عدم القابلية للتغيير (Immutability)
كما رأينا سابقاً، أحد الآثار الجانبية الشائعة هو تغيير متغير. لا تريد أن تفعل ذلك في البرمجة الوظيفية. لذا فإن إحدى الخصائص المهمة للبرنامج الوظيفي هي عدم قابلية البيانات للتغيير (immutability of data). في اللغات الوظيفية مثل Clojure و Haskell، هذه الميزة مدمجة – ليس لديك طريقة لتغيير البيانات ما لم تسمح اللغة بذلك. في أي حال، يجب أن تختار بوعي القيام بذلك. ولكن في JavaScript، هذا ليس هو الحال. لذا فالأمر يتعلق أكثر بامتلاك عقلية "عدم القابلية للتغيير" (immutability) بدلاً من تطبيق قوي حقيقي لهذه الميزة.
ما يعنيه هذا هو أنك ستقوم أساساً بعمل نسخ من البيانات التي تريد العمل عليها. في القسم الأول، رأينا أن دوال JavaScript تقوم تلقائياً بعمل نسخ من الوسائط التي يتم تمريرها. بينما يتم نسخ القيم البدائية (primitive values) بالقيمة (by value)، يتم نسخ القيم المركبة (compound values) بالمرجع فقط (by reference)، لذلك لا يزال من الممكن تغييرها. وبالتالي، عند العمل مع كائن (object) أو مصفوفة (array) في دالة، يجب عليك إنشاء نسخة ثم العمل عليها. بالمناسبة، لاحظ أن بعض الدوال المدمجة (built-in functions) لا تغير القيمة التي يتم استدعاؤها عليها، بينما البعض الآخر يفعل. على سبيل المثال، دوال Array.prototype.map()، Array.prototype.filter()، أو Array.prototype.reduce() لا تغير المصفوفة الأصلية. من ناحية أخرى، دوال Array.prototype.reverse() و Array.prototype.push() تغير المصفوفة الأصلية. يمكنك معرفة ما إذا كانت دالة مدمجة تغير القيمة التي يتم استدعاؤها عليها أم لا في الوثائق، لذا تحقق منها إذا لم تكن متأكداً. هذا مزعج، وفي النهاية ليس آمناً تماماً.
النسخ السطحية مقابل النسخ العميقة (Shallow vs. Deep Copies)
منذ إصدار ES6، أصبح من السهل عمل نسخ من الكائنات (objects) و المصفوفات (arrays) من خلال تدوين الانتشار (spread notation)، ودالة Array.from()، ودالة Object.assign(). على سبيل المثال:
// arrays
const fruits = ["apple", "strawberry", "banana"];
const fruitsCopy = [...fruits];
fruitsCopy[0] = "mutation";
// fruitsCopy: ['mutation', 'strawberry', 'banana']
// fruits (not mutated): ['apple', 'strawberry', 'banana']
// objects
const obj = { a: 1, b: 2, c: 3 };
const objCopy = { ...obj };
objCopy.a = "mutation";
// objCopy: {a: "mutation", b: 2, c: 3}
// obj (not mutated): {a: 1, b: 2, c: 3}
console.log(obj);
console.log(objCopy);
هذا رائع ولكن هناك مشكلة. مصفوفات/كائنات الانتشار (Spread arrays/objects) يتم نسخ مستواها الأول فقط بالقيمة (by value)، وهو ما يُعرف أيضاً بالنسخ السطحية (shallow copy). لذا فإن جميع المستويات اللاحقة لا تزال قابلة للتغيير (mutable):
// But with nested objects/arrays, that doesn't work
const nestedObj = { a: { b: "canBeMutated" } };
const nestedObjCopy = { ...nestedObj };
nestedObjCopy.a.b = "hasBeenMutated!";
console.log(nestedObj);
console.log(nestedObjCopy);
// nestedObjCopy: {a: {b: "hasBeenMutated!"}}}
// nestedObj (mutated): {a: {b: "hasBeenMutated!"}}
لحل هذه المشكلة، نحتاج إلى دالة مخصصة لعمل نسخ عميقة (deep copies). يناقش هذا المقال حلولاً متعددة. إليك نسخة مختصرة من الدالة المخصصة المقترحة فيه:
// works for arrays and objects
const deepCopy = (obj) => {
if (typeof obj !== "object" || obj === null) {
return obj; // Return the value if obj is not an object
}
// Create an array or object to hold the values
let newObj = Array.isArray(obj) ? [] : {};
for (let key in obj) {
// Recursively (deep) copy for nested objects, including arrays
newObj[key] = deepCopy(obj[key]);
}
return newObj;
};
const nestedObj = {
lvl1: { lvl2: { lvl3: { lvl4: "tryToMutateMe" } } },
b: ["tryToMutateMe"],
};
const nestedObjCopy = deepCopy(nestedObj);
nestedObjCopy.lvl1.lvl2.lvl3.lvl4 = "mutated";
nestedObjCopy.b[0] = "mutated";
console.log(nestedObj); // { lvl1: { lvl2: { lvl3: { lvl4: "tryToMutateMe" } } }, b: ["tryToMutateMe"]}
console.log(nestedObjCopy); // { lvl1: { lvl2: { lvl3: { lvl4: "mutated" } } }, b: ["mutated"]}
إذا كنت تستخدم بالفعل مكتبة توفر أدوات وظيفية مساعدة (functional utilities)، فمن المحتمل أن تحتوي على دالة لعمل نسخ عميقة. أنا شخصياً أحب Ramda. انظر إلى دالة clone الخاصة بها. إذا كان الفرق بين النسخ السطحية والعميقة لا يزال غير واضح، تحقق من هذا. الآن دعنا نتحدث عن الأداء. من الواضح أن عمل النسخ لا يخلو من التكلفة. بالنسبة للأجزاء الحساسة للأداء في البرنامج، أو في الحالات التي تحدث فيها التغييرات بشكل متكرر، فإن إنشاء مصفوفة أو كائن جديد (خاصة إذا كان يحتوي على الكثير من البيانات) غير مرغوب فيه لأسباب تتعلق بالمعالجة والذاكرة. في هذه الحالات، ربما يكون استخدام هياكل البيانات غير القابلة للتغيير (immutable data structures) من مكتبة مثل Immutable.js فكرة أفضل. إنها تستخدم تقنية تسمى المشاركة الهيكلية (structural sharing) التي أشرت إليها عند الحديث عن عيوب البرمجة الوظيفية (FP) في وقت سابق من هذا المقال. تحقق من هذا الحديث الرائع لمعرفة المزيد. وبالتالي، فإن التعامل مع البيانات غير القابلة للتغيير (immutable data) هو، في رأيي، المهارة الثانية التي يجب أن تمتلكها في مجموعة أدوات المبرمج الوظيفي الخاص بك.
التركيب (Composition) والتقليص (Currying)
التركيب (Composition)
ليس من المستغرب أن تكون اللبنات الأساسية للبرنامج الوظيفي هي الدوال (functions). نظراً لأن دوالك خالية من الآثار الجانبية (side-effects) وتعتبر من الدرجة الأولى (first-class)، يمكننا تركيبها. كما قلت، "من الدرجة الأولى" (first-class) تعني أنها تُعامل كهياكل بيانات عادية، ويمكن تعيينها للمتغيرات، أو تمريرها كوسائط، أو إرجاعها من دوال أخرى. التركيب (Composition) فكرة قوية. من دوال صغيرة جداً، يمكنك إضافة وظائفها لتشكيل دالة أكثر تعقيداً، ولكن دون عناء تحديدها مسبقاً. بالإضافة إلى ذلك، تحصل على مرونة أكبر لأنه يمكنك بسهولة إعادة ترتيب تركيباتك. نظراً لأنها مدعومة بقوانين رياضية، فإننا نعلم أن كل شيء سيعمل إذا اتبعناها. دعنا نقدم بعض الكود لجعل الأمور ملموسة:
const map = (fn, arr) => arr.map(fn);
const first = (xs) => xs[0];
const formatInitial = (x) => x.toUpperCase() + ".";
const intercalate = (sep, arr) => arr.join(sep);
const employees = ["Yann", "Brigitte", "John", "William"];
const initials = intercalate("\n", map(formatInitial, map(first, employees)));
// Y.
// B.
// J.
// W.
أوه – يوجد بعض التداخل هنا. خذ بعض الوقت لفهم ما يحدث. كما ترى، هناك استدعاءات دوال يتم تمريرها كوسائط لدوال خارجية. بقوة دالة map()، قمنا أساساً بتركيب وظائف first() و formatInitial() و join() لتطبيقها في النهاية على مصفوفة employees. رائع جداً! ولكن كما ترى، التداخل مزعج. يجعل الأمور أصعب في القراءة.
التقليص (Currying)
لتسطيح هذا التداخل وجعل التركيب سهلاً، يجب أن نتحدث عن التقليص (currying). قد يخيفك هذا المصطلح، ولكن لا تقلق، إنه مجرد مصطلح فني لفكرة بسيطة: تغذية دالة بوسيط واحد في كل مرة. عادةً، عندما نقوم باستدعاء دالة، فإننا نوفر جميع الوسائط دفعة واحدة ونحصل على النتيجة:
const add = (x, y) => x + y;
add(3, 7); // 10
ولكن ماذا لو كان بإمكاننا تمرير وسيط واحد فقط وتوفير الثاني لاحقاً؟ حسناً، يمكننا فعل ذلك عن طريق تقليص (currying) دالة add() على النحو التالي:
const add = (x) => (y) => x + y;
const addTo3 = add(3); // (y) => 3 + y
// ...later
addTo3(7); // 10
يمكن أن يكون هذا مفيداً إذا لم يكن لدينا جميع الوسائط بعد. قد لا تفهم لماذا لا نملك جميع الوسائط مسبقاً، لكنك سترى لاحقاً. بفضل الإغلاقات (closures)، نقوم بتحميل الدالة مسبقاً بوسائطها خطوة بخطوة حتى نقوم بتشغيلها في النهاية. إذا واجهت صعوبة في فهم مفهوم الإغلاق (closure)، تحقق من هذا، ثم هذا للتعمق أكثر. باختصار، يسمح الإغلاق (closure) لدالة داخلية بالوصول إلى متغيرات نطاق دالة خارجية. لهذا السبب يمكننا الوصول إلى x في نطاق addTo3() الذي يأتي من النطاق الخارجي، add(). غالباً لا ترغب في عناء كتابة دوالك بهذا الشكل الخاص. بالإضافة إلى ذلك، لا يمكنك دائماً كتابتها بهذه الطريقة، على سبيل المثال، عندما تستخدم دوال مكتبات خارجية وأي شيء تقريباً لا تكتبه ولكن تستخدمه على أي حال. لهذا السبب، هناك مساعد شائع لتقليص (curry) دالة (من كتاب كايل سيمبسون YDKJS):
const curry = (fn, arity = fn.length) => {
return (function nextCurried(prevArgs) {
return function curried(...nextArgs) {
const args = [...prevArgs, ...nextArgs];
return args.length < arity ? nextCurried(args) : fn(...args);
};
})([]);
};
تأخذ دالة curry() دالة وعدداً يسمى "الدرجة" (arity) (اختياري). درجة الدالة هي عدد الوسائط التي تأخذها. في حالة دالة add()، هي 2. نحتاج إلى هذه المعلومات لمعرفة متى تكون جميع الوسائط موجودة، وبالتالي اتخاذ قرار بتشغيل الدالة أو إرجاع دالة مقلصة أخرى ستأخذ الوسائط المتبقية. لذا دعنا نعيد هيكلة مثالنا باستخدام دالة add():
const add = curry((x, y) => x + y);
const addTo3 = add(3);
addTo3(7); // 10
أو لا يزال بإمكاننا استدعاء دالة add() بجميع وسائطها مباشرة:
const add = curry((x, y) => x + y);
add(3, 7); // 10
التطبيق الجزئي (Partial Application)
في الواقع، "مقلص" (curried) يعني بدقة "يأخذ وسيطاً واحداً في كل مرة"، لا أكثر ولا أقل. عندما يمكننا توفير عدد الوسائط التي نريدها، فإننا نتحدث في الواقع عن "التطبيق الجزئي" (partial application). وبالتالي، فإن التقليص (currying) هو شكل مقيد من التطبيق الجزئي. دعنا نرى مثالاً أكثر وضوحاً للتطبيق الجزئي مقارنة بالتقليص:
const listOf4 = curry((a, b, c, d) => `1. ${a} \n2. ${b} \n3. ${c} \n4. ${d}`);
// strict currying
const a = listOf4("First")("Second")("Third")("Fourth");
// or
const b = listOf4("First");
// later
const c = b("Second")("Third");
// later
const d = c("Fourth");
// partial application
const e = listOf4("First", "Second", "Third", "Fourth");
// or
const b = listOf4("First");
// later
const c = b("Second", "Third");
// later
const d = c("Fourth");
هل ترى الفرق؟ مع التقليص (currying)، يجب عليك توفير وسيط واحد في كل مرة. إذا كنت ترغب في تغذية أكثر من وسيط واحد، فأنت بحاجة إلى إجراء استدعاء دالة جديد، ومن هنا جاء زوج الأقواس حول كل وسيط. بصراحة، هذا مجرد مسألة أسلوب. يبدو الأمر غريباً بعض الشيء عندما لا تكون معتاداً عليه، ولكن من ناحية أخرى، يجد بعض الناس أن أسلوب التطبيق الجزئي (partial application) فوضوي. المساعد curry() الذي قدمته يسمح لك بالقيام بالأمرين معاً. إنه يوسع التعريف الحقيقي للتقليص (currying)، لكنني أفضل الحصول على كلتا الوظيفتين ولا أحب اسم looseCurry الذي استخدمه كايل سيمبسون في كتابه. لذا، لقد غششت قليلاً. فقط تذكر الاختلافات وكن على دراية بأن مساعدات curry() التي تجدها في المكتبات ربما تتبع التعريف الصارم.
البيانات تأتي أخيراً (Data comes last)
النقطة الأخيرة التي أرغب في ذكرها هي أننا عادة ما نضع البيانات (data) كوسيط أخير. مع الدوال السابقة التي استخدمتها، لم يكن ذلك واضحاً لأن جميع الوسائط هي بيانات. ولكن ألق نظرة على هذا:
const replace = curry((regex, replacement, str) => str.replace(regex, replacement));
يمكنك أن ترى أن البيانات (str) في الموضع الأخير لأنها من المحتمل أن تكون آخر شيء سنرغب في تمريره. سترى أن هذا هو الحال عند تركيب الدوال.
الجمع بين كل ذلك (Bring it all together)
الآن للاستفادة من التقليص (currying) وتسطيح تداخلنا السابق، نحتاج أيضاً إلى مساعد للتركيب (composition). لقد خمنت ذلك، إنه يسمى compose():
const compose = (...fns) => fns.reverse().reduce((fn1, fn2) => (...args) => fn2(fn1(...args)));
تأخذ دالة compose() الدوال كوسائط وتُرجع دالة أخرى تأخذ الوسيط (الوسائط) لتمريرها عبر خط الأنابيب بأكمله (whole pipeline). يتم تطبيق الدوال من اليمين إلى اليسار بسبب fns.reverse(). نظراً لأن دالة compose() تُرجع دالة تأخذ الوسيط (الوسائط) المستقبلية، يمكننا ربط دوالنا بحرية دون استدعائها، مما يسمح لنا بإنشاء دوال وسيطة. لذا مع مثالنا الأولي:
const map = (fn, arr) => arr.map(fn);
const first = (xs) => xs[0];
const formatInitial = (x) => x.toUpperCase() + ".";
const intercalate = (sep, arr) => arr.join(sep);
const getInitials = compose(formatInitial, first);
const employees = ["Yann", "Brigitte", "John", "William"];
const initials = intercalate("\n", map(getInitials, employees));
// Y.
// B.
// J.
// W.
تأخذ دالتا first() و formatInitial() وسيطاً واحداً بالفعل. لكن دالتي map() و intercalate() تأخذان وسيطين، لذا لا يمكننا تضمينهما كما هما في مساعد compose() الخاص بنا لأنه سيتم تمرير وسيط واحد فقط. في هذه الحالة، إنها مصفوفة تأخذها كلتا الدالتين كوسيط نهائي (تذكر، البيانات هي آخر شيء يتم تمريره). سيكون من الجيد إعطاء دالتي map() و intercalate() وسيطهما الأول مقدماً. انتظر دقيقة – يمكننا تقليصهما (curry)!:
// ...
const map = curry((fn, arr) => arr.map(fn));
const intercalate = curry((sep, arr) => arr.join(sep));
const formatInitials = compose(
intercalate("\n"),
map(formatInitial),
map(first)
);
const employees = ["Yann", "Brigitte", "John", "William"];
const initials = formatInitials(employees);
// Y.
// B.
// J.
// W.
نظيف جداً! كما قلت، دالة compose() تنشئ خط أنابيب (pipeline) بالدوال التي نقدمها لها، وتستدعيها من اليمين إلى اليسار. لذا دعنا نتخيل ما يحدث عندما يتم تحليل formatInitials(employees):
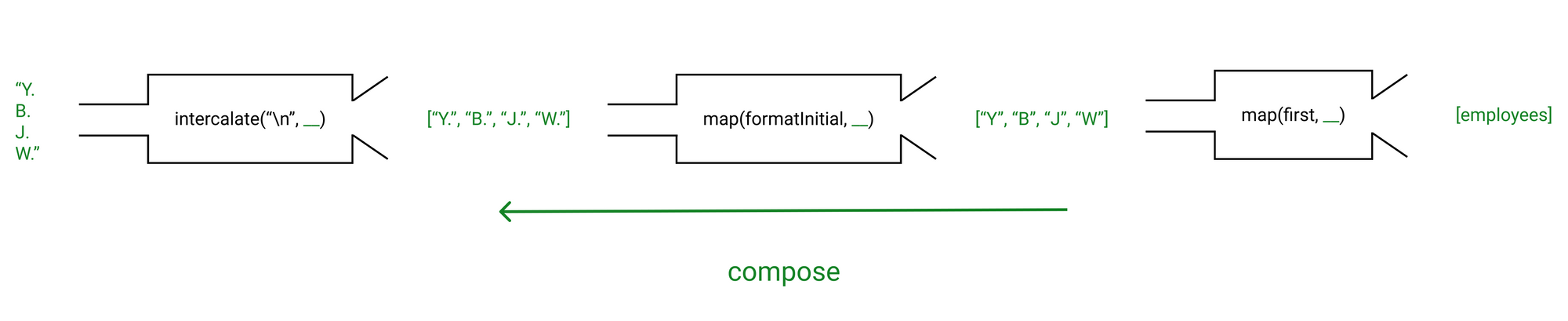
شخصياً، أفضل عندما يكون التدفق من اليسار إلى اليمين، لأنه عند كتابة الدالة، أحب التفكير في التحويل الذي يجب تطبيقه أولاً، ثم كتابته، ثم التكرار حتى نهاية خط الأنابيب. بينما مع دالة compose()، يجب أن أعود خطوة إلى الوراء لكتابة التحويل التالي. هذا فقط يقطع تدفق تفكيري. لحسن الحظ، ليس من الصعب تعديلها لتنتقل من اليسار إلى اليمين. علينا فقط التخلص من جزء .reverse(). دعنا نسمي مساعدنا الجديد pipe():
const pipe = (...fns) => fns.reduce((fn1, fn2) => (...args) => fn2(fn1(...args)));
لذا إذا أعدنا هيكلة المقتطف السابق، نحصل على:
const formatInitials = pipe(map(first), map(formatInitial), intercalate("\n"));
بالنسبة للتصور، نفس الشيء مثل compose() ولكن بترتيب عكسي:
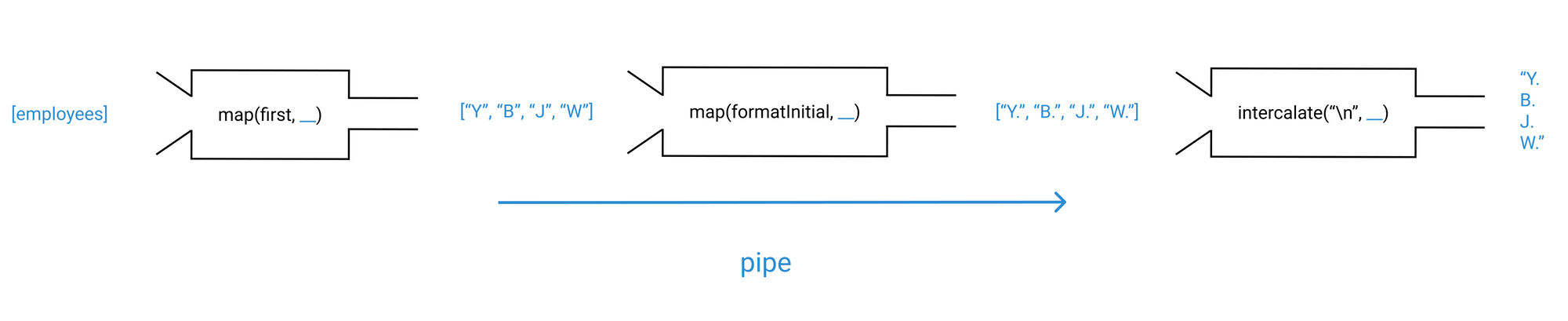
توقيعات أنواع هيندلي-ميلنر (Hindley-Milner Type Signatures)
كما تعلمون، ينتهي البرنامج الكامل بعدد لا بأس به من الدوال. عندما تعود إلى مشروع بعد عدة أسابيع، لا يكون لديك السياق الكافي لفهم ما تفعله كل دالة بسهولة. لمواجهة ذلك، تعيد قراءة الأجزاء التي تحتاجها فقط. ولكن هذا يمكن أن يكون مملاً للغاية. سيكون من الجيد أن يكون لديك طريقة سريعة وقوية لتوثيق دوالك وشرح ما تفعله في لمحة. هنا يأتي دور توقيعات الأنواع (type signatures). إنها طريقة لتوثيق كيفية عمل الدالة ومدخلاتها ومخرجاتها. على سبيل المثال:
// ↓ function name
// ↓ input
// ↓ output
// formatInitial :: String -> String
const formatInitial = (x) => x.toUpperCase() + ".";
هنا نرى أن دالة formatInitial() تأخذ سلسلة نصية (String) وتُرجع سلسلة نصية (String). لا نهتم بالتنفيذ. دعنا نلقي نظرة على مثال آخر:
// first :: [a] -> a
const first = (xs) => xs[0];
يمكن التعبير عن الأنواع بمتغيرات (عادةً a، b، إلخ) وتشير الأقواس المربعة إلى "مصفوفة من" أي شيء بداخلها. لذا يمكننا قراءة هذا التوقيع حرفياً على النحو التالي: first() تأخذ مصفوفة من a وتُرجع a، حيث يمكن أن يكون a من أي نوع. ولكن نظراً لأن النوع الذي يتم أخذه كمدخل هو نفسه الذي يتم إرجاعه كمخرج، فإننا نستخدم نفس المتغير. إذا كان للمخرج نوع آخر، لكنا استخدمنا b:
// imaginaryFunction :: a -> b
تحذير! هذا لا يضمن أن a و b هما نوعان مختلفان. لا يزال من الممكن أن يكونا متماثلين. أخيراً، دعنا نرى حالة دالة intercalate() وهي أكثر تعقيداً بعض الشيء:
// intercalate :: String -> [a] -> String
const intercalate = curry((sep, arr) => arr.join(sep));
حسناً، هنا يوجد سهمان، يمكن استبدالهما بـ "تُرجع...". إنهما يشيران إلى الدوال. لذا تأخذ دالة intercalate() سلسلة نصية (String) ثم تُرجع دالة تأخذ مصفوفة من a، والتي تُرجع سلسلة نصية (String). واو، هذا صعب التتبع. كان بإمكاننا كتابة التوقيع على النحو التالي:
// intercalate :: String -> ([a] -> String)
الآن أصبح أكثر وضوحاً أنها تُرجع دالة أولاً، والتي توجد بين قوسين هنا. ثم ستأخذ تلك الدالة [a] كمدخل وتُرجع String. ولكننا عادة لا نستخدمها من أجل الوضوح. أساساً، إذا صادفت توقيعاً بالشكل:
// imaginaryFunction :: a -> b -> c -> d -> e
// or
// imaginaryFunction :: a -> (b -> (c -> (d -> e)))
// ...you see how parens nesting affects readability
النوع e، الموجود على الجانب الأيمن، هو المخرج. وكل شيء قبله هو مدخلات تُعطى واحدة تلو الأخرى، مما يشير إلى أن الدالة مقلصة (curried).
في الوقت الحاضر، لدينا عادة أنظمة أنواع مثل TypeScript أو Flow، ويمكن للمحرر (IDE) أن يمنحنا توقيع النوع لدالة عندما نحوم فوق اسمها. وبالتالي، قد يكون من غير الضروري كتابتها كتعليقات في الكود الخاص بك. ولكن هذا يظل أداة رائعة لامتلاكها في مجموعة أدواتك لأن الكثير من المكتبات الوظيفية الموجودة تستخدم توقيعات الأنواع هذه في وثائقها. وتستخدمها اللغات الوظيفية الاصطلاحية (مثل Haskell) بكثافة. لذا إذا جربتها، فمن المأمول ألا تضيع تماماً.
اهنئ نفسك على القراءة حتى الآن. يجب أن تكون لديك الآن القدرة على العمل مع الدوال عالية الترتيب (higher-order functions). الدوال عالية الترتيب هي ببساطة دوال تأخذ دوال كمدخلات و/أو تُرجعها. في الواقع، هذا بالضبط ما فعلناه. على سبيل المثال، curry() هي دالة عالية الترتيب لأنها تأخذ دالة كمدخل وتُرجع دالة كمخرج. دوال compose() و pipe() و map() و reduce() كلها دوال عالية الترتيب لأنها تأخذ دالة واحدة على الأقل كمدخل. إنها رائعة جداً لأنها تسمح بإنشاء تجريدات قوية جداً. يكفي الثرثرة. دعنا نتدرب قليلاً.
تمارين (المجموعة 2)
بالنظر إلى سلسلة نصية بالشكل:
const input = "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.";
...وهذه المساعدات:
// filter :: (a -> Boolean) -> [a] -> [a]
const filter = curry((fn, arr) => arr.filter(fn));
// removeDuplicates :: [a] -> [a]
const removeDuplicates = (arr) => Array.from(new Set(arr));
// getChars :: String -> [Character]
const getChars = (str) => str.split("");
// lowercase :: String -> String
const lowercase = (str) => str.toLowerCase();
// sort :: [a] -> [a]
const sort = (arr) => [...arr].sort();
أنشئ دالة getLetters() تُرجع جميع الحروف في سلسلة نصية بدون تكرارات، بترتيب أبجدي، وبأحرف صغيرة. الهدف هو استخدام compose() و/أو pipe():
// getLetters :: String -> [Character]
const getLetters = ...
ملاحظة: قد تحتاج إلى إنشاء دوال وسيطة قبل الدالة النهائية.
تخيل أن لديك كائناً بأسماء المجموعات كمفاتيح ومصفوفات من الكائنات تمثل الأشخاص كقيم:
{
"groupName": [
{ firstname: "John", lastname: "Doe", age: 35, sex: "M" },
{ firstname: "Maria", lastname: "Talinski", age: 28, sex: "F" },
// ...
],
// ...
}
أنشئ دالة تُرجع كائناً بالشكل:
{
"groupName": {
"medianAgeM": 34,
"medianAgeF": 38,
},
// ...
}
حيث medianAgeM هو العمر الوسيط للرجال في المجموعة و medianAgeF هو العمر الوسيط للنساء. إليك بعض المساعدات:
// map :: (a -> b) -> [a] -> [b]
const map = curry((fn, arr) => arr.map(fn));
// getEntries :: Object -> [[Key, Val]]
const getEntries = (o) => Object.entries(o);
// fromEntries:: [[Key, Val]] -> Object
const fromEntries = (entries) => Object.fromEntries(entries);
// mean :: Number -> Number -> Number
const mean = curry((x, y) => Math.round((x + y) / 2));
// reduceOverVal :: (b -> a -> b) -> b -> [Key, [a]] -> [Key, b]
const reduceOverVal = curry(
(fn, initVal, entry) => [
entry[0],
entry[1].reduce(fn, initVal),
]
);
قد تحتاج إلى إنشاء دوال وسيطة قبل الدالة النهائية، وكما كان من قبل، حاول استخدام compose() و pipe():
// groupsMedianAges :: Object -> Object
const groupsMedianAges = ...
ابحث عن توقيع النوع (type signature) لدالة reduce():
const reduce = curry((fn, initVal, arr) => arr.reduce(fn, initVal));
ابحث عن توقيع النوع (type signature) لدالة curry():
const curry = (fn, arity = fn.length) => {
return (function nextCurried(prevArgs) {
return function curried(...nextArgs) {
const args = [...prevArgs, ...nextArgs];
return args.length < arity ? nextCurried(args) : fn(...args);
};
})([]);
};
العمل مع الصناديق: من الفانكتورات (Functors) إلى المونادات (Monads)
قد تكون بالفعل متوتراً من عنوان هذا القسم. قد تفكر، "ما هي بحق الجحيم 'الفانكتورات' (Functors) و'المونادات' (Monads)؟" أو ربما سمعت عن المونادات (monads) لأنها "صعبة" الفهم بشكل مشهور. لسوء الحظ، لا يمكنني التنبؤ بأنك ستفهم هذه المفاهيم بالتأكيد، أو ستطبقها بفعالية في أي عمل تقوم به. في الواقع، إذا تحدثت عنها في نهاية هذا الدليل، فذلك لأنني أعتقد أنها أدوات قوية جداً لا نحتاجها في كثير من الأحيان. إليك الجزء المطمئن: مثل أي شيء في العالم، إنها ليست سحراً. إنها تتبع نفس قواعد الفيزياء (وبشكل أكثر تحديداً علوم الكمبيوتر والرياضيات) مثل أي شيء آخر. لذا في النهاية، يمكن فهمها. إنها تتطلب فقط القدر المناسب من الوقت والطاقة. بالإضافة إلى ذلك، إنها تبني أساساً على ما تحدثنا عنه سابقاً: الأنواع (types)، الربط (mapping)، والتركيب (composition). الآن، ابحث عن أنبوب المثابرة هذا في مجموعة أدواتك ودعنا نبدأ.
لماذا نستخدم الصناديق؟
نريد بناء برنامجنا باستخدام دوال نقية (pure functions). ثم نستخدم التركيب (composition) لتحديد الترتيب الذي تعمل به هذه الدوال على البيانات. ومع ذلك، كيف نتعامل مع قيم null أو undefined؟ كيف نتعامل مع الاستثناءات؟ أيضاً، كيف ندير الآثار الجانبية (side-effects) دون فقدان السيطرة، لأنه في يوم من الأيام سنحتاج إلى تنفيذها؟
الحالتان الأوليان تتضمنان التفرع (branching). إما أن تكون القيمة null ونفعل هذا، أو نفعل ذاك. إما أن يكون هناك خطأ ونفعل هذا، أو نجاح ونفعل ذاك. الطريقة المعتادة للتعامل مع التفرع هي التحكم في التدفق (control flow). ومع ذلك، فإن التحكم في التدفق أمرّي (imperative). إنه يصف "كيف" يعمل الكود. لذا توصل المبرمجون الوظيفيون إلى فكرة استخدام "صندوق" (box) يحتوي على إحدى قيمتين محتملتين. نستخدم هذا الصندوق كمدخل/مخرج للدوال بغض النظر عما بداخله. ولكن نظراً لأن هذه الصناديق لها أيضاً سلوكيات محددة تجرد تطبيق الدالة، يمكننا تطبيق دالة على صندوق وسوف يقرر كيفية تنفيذها بالفعل اعتماداً على قيمتها الداخلية. وبالتالي، لا يتعين علينا تكييف دوالنا مع البيانات. لا يتعين علينا إفسادها بمنطق لا ينتمي إليها. أشياء مثل:
const myFunc = (x) => {
// ...
if (x !== null) {
// ...
} else {
// ...
}
};
بهذا، يمكننا تنفيذ التفرع (وأشياء أخرى) مع استخدام الدوال فقط والحفاظ على التركيب (composition). الصناديق التي سنراها، والتي تسمى "أنواع البيانات الجبرية" (Algebraic Data Types - ADT)، تمكننا من فعل المزيد مع إبقاء البيانات والدوال منفصلة. الفانكتورات (Functors) والمونادات (monads) هي بالفعل أنواع بيانات جبرية.
الفانكتورات (Functors)
الفانكتورات (Functors) هي حاويات/هياكل بيانات/أنواع تحمل بيانات جنباً إلى جنب مع طريقة map(). تسمح لنا طريقة map() هذه بتطبيق دالة على القيمة (القيم) الموجودة داخل الفانكتور. ما يتم إرجاعه هو نفس الفانكتور ولكن يحتوي على نتيجة استدعاء الدالة. دعنا نقدم Identity، أبسط فانكتور:
يمكننا تنفيذها بفئة (class)، لكنني سأستخدم دوال عادية هنا:
const Identity = (x) => ({
inspect: () => `Identity(${x})`,
map: (fn) => Identity(fn(x)),
value: x,
});
// add5 :: Number -> Number
const add5 = (x) => x + 5;
const myFirstFunctor = Identity(1);
myFirstFunctor.map(add5); // Identity(6)
هل ترى؟ ليس معقداً! Identity هو مكافئ لدالة identity() ولكن في عالم الفانكتورات. identity() هي دالة معروفة في البرمجة الوظيفية (FP) قد تبدو عديمة الفائدة للوهلة الأولى:
// identity :: a -> a
const identity = (x) => x;
إنها لا تفعل شيئاً على البيانات، فقط تُرجعها كما هي. ولكن يمكن أن تكون مفيدة عند القيام بأشياء مثل التركيب (composition) لأنه في بعض الأحيان، لا تريد أن تفعل أي شيء بالبيانات، فقط تمررها. ونظراً لأن التركيب (composition) يعمل مع الدوال وليس القيم الخام، فأنت بحاجة إلى لفها في دالة identity(). تخدم Identity نفس الغرض ولكن عند تركيب الفانكتورات. المزيد عن ذلك لاحقاً. بالعودة إلى المقتطف السابق، كان بإمكاننا القيام بـ map(add5, 1) وكان سيعطينا نفس النتيجة بصرف النظر عن حقيقة أنه لن تكون هناك حاوية حولها. لذا لا توجد ميزة إضافية هنا. الآن دعنا نرى فانكتوراً آخر يسمى Maybe:
const Nothing = () => ({
inspect: () => `Nothing()`,
map: Nothing,
});
const Maybe = { Just, Nothing };
// Just is equivalent to Identity
Maybe هو مزيج من فانكتورين، Just و Nothing. يحتوي Nothing، حسناً، على لا شيء. لكنه لا يزال فانكتوراً لذا يمكننا استخدامه أينما احتجنا إلى فانكتورات. Maybe، كما يوحي اسمه، قد يحتوي على قيمة (Just) أو لا (Nothing). الآن كيف نستخدمه؟ في معظم الأحيان، يتم استخدامه في الدوال التي يمكن أن تُرجع null أو undefined:
// isNothing :: a -> Boolean
const isNothing = (x) => x === null || x === undefined;
// safeProp :: String -> Object -> Maybe a
const safeProp = curry(
(prop, obj) => isNothing(obj[prop]) ? Maybe.Nothing() : Maybe.Just(obj[prop])
);
const o = { a: 1 };
const a = safeProp("a", o); // Just(1)
const b = safeProp("b", o); // Nothing
a.map(add5); // Just(6)
b.map(add5); // Nothing
هل ترى أين تكمن قوة Maybe؟ يمكنك تطبيق دالة بأمان على القيمة الداخلية داخل أي فانكتور تُرجعه safeProp()، ولن تحصل على نتيجة NaN غير متوقعة لأنك أضفت رقماً مع null أو undefined. بفضل فانكتور Nothing، لن يتم استدعاء الدالة المربوطة على الإطلاق. ومع ذلك، غالباً ما تغش تطبيقات Maybe قليلاً عن طريق إجراء فحص isNothing() داخل الموناد، بينما لا ينبغي لموناد نقي تماماً أن يفعل ذلك:
const Maybe = (x) => ({
map: (fn) => (x === null || x === undefined ? Maybe(x) : Maybe(fn(x))),
inspect: () => `Maybe(${x})`,
value: x,
});
// safeProp :: String -> Object -> Maybe a
const safeProp = curry((prop, obj) => Maybe(obj[prop]));
const o = { a: 1 };
const c = safeProp("a", o); // Maybe(1)
const d = safeProp("b", o); // Maybe(undefined)
c.map(add5); // Maybe(6)
d.map(add5); // Maybe(undefined)
ميزة وجود هذه الفانكتورات هي أنه لكي تُسمى "فانكتورات"، يجب أن تنفذ واجهة محددة، وفي هذه الحالة هي map(). وبالتالي، لكل نوع من الفانكتورات ميزات فريدة مع امتلاك قدرات مشتركة بين جميع الفانكتورات، مما يجعلها قابلة للتنبؤ. عند استخدام Maybe في حالات حقيقية، نحتاج في النهاية إلى فعل شيء بالبيانات لتحرير القيمة. بالإضافة إلى ذلك، إذا اتخذت العمليات الفرع غير المرغوب فيه وفشلت، فسنحصل على Nothing. دعنا نتخيل أننا نريد طباعة القيمة المسترجعة من o في مثالنا السابق. قد نرغب في طباعة شيء أكثر فائدة للمستخدم من "Nothing" إذا فشلت العملية. لذا لتحرير القيمة وتوفير احتياطي إذا حصلنا على Nothing، لدينا مساعد صغير يسمى maybe():
// maybe :: c -> (a -> b) -> Maybe a -> b | c
const maybe = curry(
(fallbackVal, fn, maybeFunctor) =>
maybeFunctor.val === undefined ? fallbackVal : fn(maybeFunctor.val)
);
// ...
const o = { a: 1 };
const printVal1 = pipe(
safeProp("a"),
maybe("Failure to retrieve the value.", add5),
console.log
);
const printVal2 = pipe(
safeProp("b"),
maybe("Failure to retrieve the value.", add5),
console.log
);
printVal1(o); // console: 6
printVal2(o); // console: "Failure to retrieve the value."
رائع! إذا كانت هذه هي المرة الأولى التي تتعرض فيها لهذا المفهوم، فقد يبدو غير واضح وغير مألوف. ولكن في الواقع، إنه شيء أنت على دراية به بالفعل. إذا كنت على دراية بلغة JavaScript، فمن المحتمل أنك استخدمت دالة map() المدمجة:
[1, 2, 3].map((x) => x * 2); // [2, 4, 6]
حسناً، تذكر تعريف الفانكتور. إنه هيكل بيانات يحتوي على طريقة map(). الآن انظر إلى المقتطف السابق: ما هو هيكل البيانات الذي يحتوي على طريقة map() هنا؟ المصفوفة (Array)! النوع الأصلي Array في JavaScript هو فانكتور! تخصصه هو أنه يمكن أن يحتوي على قيم متعددة. لكن جوهر map() يظل كما هو: يأخذ قيمة كمدخل ويُرجعها/يربطها بمخرج. لذا في هذه الحالة، تعمل دالة الربط (mapper function) لكل قيمة. رائع! الآن بعد أن عرفنا ما هو الفانكتور، دعنا ننتقل لتوسيع واجهته.
المؤشر (Pointed)
الفانكتور المؤشر (pointed functor) هو الذي يحتوي على طريقة of() (تسمى أيضاً pure، unit). لذا مع Maybe يعطينا ذلك:
const Maybe = {Just, Nothing, of: Just};
تهدف طريقة of() إلى وضع قيمة معينة في السياق الأدنى الافتراضي للفانكتور. قد تسأل: لماذا Just وليس Nothing؟ عند استخدام of()، نتوقع أن نكون قادرين على الربط (map) على الفور. إذا استخدمنا Nothing، فسيتجاهل كل ما نربطه. تتوقع of() منك إدخال قيمة "ناجحة". وبالتالي، لا يزال بإمكانك الوقوع في الخطأ عن طريق إدخال undefined، على سبيل المثال، ثم ربط دالة لا تتوقع هذه القيمة:
Maybe.of(undefined).map((x) => x + 1); // Just(NaN)
دعنا نقدم فانكتوراً آخر لفهم متى يكون مفيداً بشكل أفضل:
const IO = (dangerousFn) => ({
inspect: () => `IO(?)`,
map: (fn) => IO(() => fn(dangerousFn())),
});
IO.of = (x) => IO(() => x);
على عكس Just، لا تحصل IO على قيمة كما هي ولكنها تحتاج إلى لفها في دالة. لماذا هذا؟ I/O تعني Input/Output (إدخال/إخراج). يستخدم المصطلح لوصف أي برنامج أو عملية أو جهاز ينقل البيانات إلى أو من جهاز كمبيوتر وإلى أو من جهاز طرفي. لذا فهو مخصص للاستخدام في عمليات الإدخال/الإخراج، والتي تعد آثاراً جانبية (side-effects) لأنها تعتمد على/تؤثر على العالم الخارجي. الاستعلام عن نموذج الكائن للمستند (DOM) هو مثال:
// getEl :: String -> DOM
const getEl = (sel) => document.querySelector(sel);
هذه الدالة غير نقية (impure) لأنه عند إعطائها نفس المدخل، يمكن أن تُرجع مخرجات مختلفة:
getEl("#root"); // <div id="root"></div>
// or
getEl("#root"); // <div id="root">There's text now !</div>
// or
getEl("#root"); // null
بينما عن طريق إدخال دالة وسيطة، تُرجع getEl() دائماً نفس المخرج:
// getEl :: String -> _ -> DOM
const getEl = (sel) => () => document.querySelector(sel);
getEl("#root"); // function...
مهما كانت الوسيطة التي يتم تمريرها، ستُرجع getEl() دائماً دالة، مما يسمح لها بأن تكون نقية (pure). ومع ذلك، نحن لا نمحو التأثير بطريقة سحرية لأنه الآن، الدالة المرتجعة هي التي تكون غير نقية (impure). نحصل على النقاء من الكسل (laziness). الدالة الخارجية تعمل فقط كصندوق حماية يمكننا تمريره بأمان. عندما نكون مستعدين لإطلاق التأثير، نستدعي دالة الدالة المرتجعة. ونظراً لأننا نريد أن نكون حذرين عند القيام بذلك، فإننا نسمي الدالة unsafePerformIO() لتذكير المبرمج بأنها خطيرة. حتى ذلك الحين، يمكننا القيام بعمليات الربط (mapping) والتركيب (composition) بسلام. لذا هذه هي الآلية التي تستخدمها IO. إذا مررت قيمة إليها مباشرة، فيجب أن تكون دالة بنفس توقيع الدالة التي تُرجعها getEl():
const a = IO(() => document.querySelector("#root"));
// and not:
const invalid = IO(document.querySelector("#root"));
ولكن كما يمكنك أن تتخيل، يصبح من الممل بسرعة أن نلف قيمتنا دائماً في دالة قبل تمريرها إلى IO. هنا تبرز قوة of() – ستفعل ذلك من أجلنا:
const betterNow = IO.of(document.querySelector("#root"));
هذا ما قصدته بـ "السياق الأدنى الافتراضي" (default minimum context). في حالة IO، فإنه يلف القيمة الخام في دالة. ولكن يمكن أن يكون شيئاً آخر، يعتمد على الفانكتور المعني.
تمارين (المجموعة 3)
اكتب دالة uppercaseF() تقوم بتحويل سلسلة نصية داخل فانكتور إلى أحرف كبيرة:
// uppercaseF :: Functor F => F String -> F String
const uppercaseF = ...
استخدم دالة uppercaseF() التي أنشأتها مسبقاً، ودالتي maybe() و safeProp() لإنشاء دالة تسترجع اسم المستخدم وتطبعه بنسخة بأحرف كبيرة. كائن المستخدم له هذا الشكل:
{
name: "Yann Salmon",
age: 18,
interests: ["Programming", "Sport", "Reading", "Math"],
// ...
}
// safeProp :: String -> Object -> Maybe a
// maybe :: c -> (a -> b) -> Maybe a -> b | c
// printUsername :: User -> _
const printUsername = ...
التطبيقات (Applicatives)
إذا كنت تعمل مع الفانكتورات (functors)، فسوف تصادف مواقف لديك فيها فانكتورات متعددة تحتوي على قيم ترغب في تطبيق دالة عليها:
// concatStr :: String -> String -> String
const concatStr = curry((str1, str2) => str1 + str2);
const a = Identity("Hello");
const b = Identity(" world !");
لسوء الحظ، لا يمكننا تمرير الفانكتورات (functors) كوسائط إلى concatStr() لأنها تتوقع سلاسل نصية. تحل واجهة Applicative هذه المشكلة. الفانكتور الذي ينفذها هو الذي ينفذ طريقة ap(). تأخذ ap() فانكتوراً كوسيط وتُرجع فانكتوراً من نفس النوع. داخل الفانكتور المرتجع، ستكون هناك نتيجة ربط (mapping) قيمة الفانكتور الذي تم استدعاء ap() عليه، على قيمة الفانكتور الذي تم أخذه كوسيط سابقاً. أعلم أن هذا كثير للهضم. خذ بعض الوقت ودع ذلك يستقر. دعنا نواصل مقتطفنا السابق لنرى ذلك عملياً:
// concatStr :: String -> String -> String
const concatStr = curry((str1, str2) => str1 + str2);
const a = Identity("Hello");
const b = Identity(" world !");
const c = a.map(concatStr); // Identity(concatStr("Hello", _))
const result = c.ap(b); // Identity("Hello world !")
أولاً، نقوم بربط (map) دالة concatStr() على a. ما يحدث هو أن concatStr("Hello") يتم استدعاؤها وتصبح القيمة الداخلية لـ c، ولا يزال فانكتور Identity. وتذكر، ماذا تُرجع concatStr("Hello")؟ دالة أخرى تنتظر الوسائط المتبقية! بالفعل، concatStr() مقلصة (curried). لاحظ أن التقليص (currying) ضروري لاستخدام هذه التقنية. ثم، كما قلت، تقوم ap() بربط (map) قيمة الفانكتور الذي تم استدعاؤها عليه (في هذه الحالة c، لذا فهي تربط concatStr("Hello")) على قيمة الفانكتور الذي تم أخذه كوسيط (هنا هو b الذي يحتوي على " world !"). لذا ينتهي المطاف بـ result ليكون فانكتور Identity (من نفس نوع b) يحتوي على نتيجة concatStr("Hello")(" world !")، أي "Hello world !"! إليك التنفيذ:
const Identity = (x) => ({
inspect: () => `Identity(${x})`,
// Functor interface
map: (fn) => Identity(fn(x)),
// Applicative interface
ap: (functor) => functor.map(x),
value: x,
});
// Pointed interface
Identity.of = (x) => Identity(x);
كما ترى، يجب أن يحتوي الفانكتور الذي يتم استدعاء ap() عليه على دالة. وإلا فلن يعمل. في مثالنا السابق، كانت تلك هي خطوة c. إذا قمنا بدمج كل شيء، نحصل على:
// concatStr :: String -> String -> String
const concatStr = curry((str1, str2) => str1 + str2);
const result = Identity("Hello").map(concatStr).ap(Identity(" world !")); // Identity("Hello world !")
هناك خاصية رياضية مثيرة للاهتمام حول ap():
F(x).map(fn) === F(fn).ap(F(x));
الجانب الأيسر من المساواة يتوافق مع ما فعلناه سابقاً. لذا باتباع الجانب الأيمن، يمكن أيضاً كتابة result على النحو التالي:
const result = Identity(concatStr)
.ap(Identity("Hello"))
.ap(Identity(" world !"));
خذ وقتك لإعادة القراءة إذا شعرت بالارتباك. النسخة الأخيرة تشبه استدعاء دالة عادية أكثر من السابقة. نحن نغذي concatStr() بوسائطها بطريقة من اليسار إلى اليمين:

وكل ذلك يحدث داخل حاويتنا الواقية. أخيراً، يمكننا زيادة تبسيط هذه العملية باستخدام التحديد البارامتري (parametrization). دالة تسمى liftA2() تفعل ذلك:
// liftA2 :: Apply functor F => (a -> b -> c) -> F a -> F b -> F c
const liftA2 = curry((fn, F1, F2) => F1.map(fn).ap(F2));
// ...
const result = liftA2(concatStr, Identity("Hello"), Identity(" world !"));
أنا متأكد من أننا يمكن أن نتفق على أن هذا الاسم غريب حقاً. أعتقد أنه كان منطقياً لرواد البرمجة الوظيفية، الذين كانوا على الأرجح من "الرياضيين". ولكن على أي حال، يمكنك التفكير فيه على أنه "رفع" دالة ووسائطها، ثم وضعها في فانكتور من أجل تطبيق ap() على كل منها. ومع ذلك، فإن هذا الاستعارة صحيحة جزئياً فقط لأن الوسائط تُعطى بالفعل داخل حاويتها. الجزء المثير للاهتمام هو جسم الدالة. يمكنك ملاحظة أنها تستخدم الجانب الأيسر من الخاصية الرياضية التي رأيناها سابقاً. إذا قمنا بتنفيذها باستخدام الجانب الأيمن، نحتاج إلى معرفة نوع الفانكتور الذي تنتمي إليه F1 و F2 لأننا نحتاج إلى لف الدالة بنفس النوع:
const liftA2 = curry((fn, F1, F2) => F(fn).ap(F1).ap(F2));
// ↑ what's F ?
نحتاج إلى منشئ (constructor) دقيق. لذا باستخدام النسخة اليسرى، نجرد نوع الفانكتور مجاناً. الآن قد تفكر، "حسناً، ولكن ماذا لو كانت الدالة تتطلب 3، 4، أو أكثر من الوسائط؟" إذا كان هذا هو الحال، يمكنك بناء متغيرات فقط عن طريق توسيع دالة liftA2() السابقة:
// liftA3 :: Apply functor F => (a -> b -> c -> d) -> F a -> F b -> F c -> F d
const liftA3 = curry((fn, F1, F2, F3) => F1.map(fn).ap(F2).ap(F3));
// liftA4 :: Apply functor F => (a -> b -> c -> d -> e) -> F a -> F b -> F c -> F d -> F e
const liftA4 = curry((fn, F1, F2, F3, F4) => F1.map(fn).ap(F2).ap(F3).ap(F4));
// take3Args :: String -> String -> Number -> String
const take3Args = curry(
(firstname, lastname, age) => `My name is ${firstname} ${lastname} and I'm ${age}.`
);
// take4Args :: a -> b -> c -> d -> [a, b, c, d]
const take4Args = curry((a, b, c, d) => [a, b, c, d]);
liftA3(take3Args, Identity("Yann"), Identity("Salmon"), Identity(18));
// Identity("My name is Yann Salmon and I'm 18.")
liftA4(take4Args, Identity(1), Identity(2), Identity(3), Identity(4));
// Identity([1, 2, 3, 4])
كما تلاحظ، يشير A* إلى عدد الوسائط. واو! لقد غطينا الكثير من الأشياء. مرة أخرى، أرغب في تهنئتكم على الوقت والاهتمام الذي قدمتموه حتى الآن. لدينا الآن تقريباً مجموعة أدوات كاملة لحل مشاكل العالم الحقيقي بطريقة وظيفية. نحتاج الآن إلى استكشاف واجهة Monad.
تمارين (المجموعة 4)
اعتبر كائن المستخدم هذا للتمارين التالية:
const user = {
id: "012345",
name: "John Doe",
hobbies: ["Cycling", "Drawing"],
friends: [
{ name: "Mickael Bolp", ...},
// ...
],
partner: { name: "Theresa Doe", ...},
// ...
}
أنشئ دالة تُرجع عبارة تصف الزوجين إذا كان المستخدم لديه شريك باستخدام المساعدات المعطاة ودالة ap():
// safeProp :: String -> Object -> Maybe a
const safeProp = curry(
(prop, obj) =>
obj[prop] === undefined || obj[prop] === null ? Maybe.Nothing() : Maybe.Just(obj[prop])
);
// getCouplePresentation :: User -> User -> String
const getCouplePresentation = curry(
(name1, name2) => `${name1} and ${name2} are partners.`
);
// getName :: User -> String
const getName = (user) => user.name;
// I could have written: const getName = safeProp("name")
// but I didn't and that's intentional.
// We assume that a user always has a name.
const couple = ...
أعد هيكلة الإجابة السابقة باستخدام liftA2() (تحقق من إجابة السؤال السابق أولاً):
// liftA2 :: Apply functor F => (a -> b -> c) -> F a -> F b -> F c
const liftA2 = curry((fn, F1, F2) => F1.map(fn).ap(F2));
const couple = ...
المونادات (Monads)
في التمارين السابقة، أعطيت المساعد getName() بينما كان بإمكاننا اشتقاقه من safeProp(). السبب في قيامي بذلك هو أن safeProp() تُرجع فانكتور Maybe. وبالتالي، بمحاولة الحصول على اسم شريك المستخدم، ينتهي بنا المطاف بفانكتورين Maybe متداخلين:
const getPartnerName = pipe(safeProp("partner"), map(safeProp("name")));
// Maybe(Maybe("Theresa Doe"))
دعنا نرى مثالاً آخر حيث تتفاقم هذه المشكلة:
// getUser :: Object -> IO User
const getUser = ({ email, password }) => IO.of(db.getUser(email, password));
// getLastPurchases :: User -> IO [Purchase]
const getLastPurchases = (user) => IO.of(db.purchases(user));
// display :: [Purchase] -> IO _
const display = "some implementation";
// displayUserPurchases :: Object -> IO _
const displayUserPurchases = pipe(
getUser,
map(getLastPurchases),
map(map(display))
);
displayUserPurchases({ email: "johndoe@whatever.com", password: "1234" }); // IO(IO(IO _))
كيف نتخلص من هذه الطبقات المتداخلة من الحاويات التي تجبرنا على القيام بـ map() متداخلة تضعف قابلية القراءة؟ المونادات (Monads) لإنقاذنا! المونادات هي فانكتورات يمكنها التسطيح. مرة أخرى، مثل الفانكتورات العادية، من المحتمل أنك لن تستخدمها كثيراً. ومع ذلك، فهي تجريدات قوية تجمع مجموعة محددة من السلوكيات مع قيمة. إنها هياكل بيانات مدعومة بقوانين رياضية تجعلها قابلة للتنبؤ وموثوقة للغاية. بالإضافة إلى ذلك، تخبرنا قوانين مثل التركيب (composition) أو الترابط (associativity) أنه يمكننا فعل الشيء نفسه مع إجراء العمليات بطريقة مختلفة. تذكر ما رأيناه مع التطبيقات (Applicatives) ودالة ap():
F(x).map(fn) === F(fn).ap(F(x));
يمكن أن تكون هذه مفيدة لأن بعض المتغيرات قد تكون أكثر كفاءة حسابياً. الأمر هو أن الطريقة التي نفضل بها كتابة البرامج قد تختلف عن الطريقة التي يجب أن تكتب بها إذا أردنا أن تكون فعالة قدر الإمكان. لذا نظراً لأن هذه القوانين تضمن لنا أن جميع المتغيرات تفعل الشيء نفسه، يمكننا الكتابة بالطريقة التي نحبها ونطلب من المترجم استخدام المتغير الأكثر كفاءة لاحقاً. لهذا السبب لم أزعجكم بهذه القوانين كثيراً. ولكن كونوا على دراية بفائدتها (التي تتجاوز ذلك بالتأكيد).
بالعودة إلى موناداتنا، يتم تنفيذ سلوك التسطيح عادةً باستخدام طريقة chain() (تسمى أيضاً flatMap، bind، >>=):
const Identity = (x) => ({
inspect: () => `Identity(${x})`,
// Functor interface
map: (fn) => Identity(fn(x)),
// Applicative interface
ap: (functor) => functor.map(x),
// Monad interface
chain: (fn) => fn(x),
value: x,
});
// Pointed interface
Identity.of = (x) => Identity(x);
// chain :: Monad M => (a -> M b) -> M a -> M b
const chain = curry((fn, monad) => monad.chain(fn));
const getPartnerName = pipe(safeProp("partner"), chain(safeProp("name")));
في حالة Identity، دالة chain() تشبه دالة map() ولكن بدون فانكتور Identity جديد يحيط بها. قد تفكر، "هذا يهزم الغرض، سنحصل على قيمة غير معبأة!" ولكن، لن نفعل ذلك لأن fn تهدف إلى إرجاع فانكتور. انظر إلى توقيع النوع (type signature) لمساعد chain() هذا:
// chain :: Monad M => (a -> M b) -> M a -> M b
const chain = curry((fn, monad) => monad.chain(fn));
في الواقع، كان بإمكاننا فعل الشيء نفسه عن طريق تطبيق الدالة التي تُرجع فانكتور أولاً، مما يعطينا فانكتوراً متداخلاً، ثم إزالة الداخلي أو الخارجي. على سبيل المثال:
const Identity = (x) => ({
// ...
chain: (fn) => Identity(x).map(fn).value,
value: x,
});
يمكنك أن ترى أننا نلف x أولاً، ثم نربط (map)، ثم نلتقط القيمة الداخلية. نظراً لأن لف x في Identity جديد وفي النهاية التقاط قيمته الداخلية هما عمليتان متعاكستان، فمن الأفضل عدم القيام بأي منهما كما في النسخة الأولى. الآن دعنا نعيد هيكلة المقتطف الأول من هذا القسم (مع الفانكتورات المتداخلة) باستخدام مساعد chain():
// BEFORE
// ...
// displayUserPurchases :: Object -> IO _
const displayUserPurchases = pipe(
getUser,
map(getLastPurchases),
map(map(display))
);
displayUserPurchases({ email: "johndoe@whatever.com", password: "1234" }); // IO(IO(IO _))
// AFTER
// ...
const displayUserPurchases = pipe(
getUser,
chain(getLastPurchases),
chain(display)
);
displayUserPurchases({ email: "johndoe@whatever.com", password: "1234" }); // IO _
أولاً، تُرجع getUser() كائن IO(User). ثم نقوم بربط (chain) دالة getLastPurchases() بدلاً من ربطها (mapping). بعبارة أخرى، نحتفظ بنتيجة getLastPurchases(User) (وهي IO(?))، ونتخلص من IO الأصلي الذي أحاط بـ User. لهذا السبب غالباً ما تُقارن المونادات بالبصل – تسطيحها/ربطها (flattening/chaining) يشبه إزالة طبقة من البصل. عندما تفعل ذلك، فإنك تطلق نتائج غير مرغوب فيها محتملة قد تجعلك تبكي 😭. في المثال الأخير، إذا كانت العملية الحسابية الأولى getUser() قد أعادت Nothing، فإن استدعاء chain() عليها كان سيعيد Nothing أيضاً. هذا الفانكتور لا يقوم بأي عملية. ومع ذلك، نحتاج إلى توسيع النسخة البسيطة التي رأيناها سابقاً في هذا المقال من أجل إعطائها واجهتي Applicative و Monad. وإلا، فلن نتمكن من استخدامها على هذا النحو:
const Nothing = () => ({
inspect: () => `Nothing()`,
map: Nothing,
ap: Nothing,
chain: Nothing,
});
Nothing.of = () => Nothing();
طالما أنك تحافظ على طبقة واحدة على الأقل (أي فانكتور واحد) حتى تكون مستعداً لإطلاق التأثير، فلا بأس بذلك. ولكن إذا قمت بتسطيح الموناد للحصول على القيمة الخام المحتواة فيه في كل مكان لأنك غير قادر على معرفة كيفية تركيبها، فإن ذلك يهزم الغرض.
ملخص
- الفانكتورات (
Functors): تطبق دالة على قيمة ملفوفة (map()). - الفانكتورات المؤشرة (
Pointed functors): لديها طريقة لوضع قيمة في السياق الأدنى الافتراضي للفانكتور (of()). - التطبيقات (
Applicatives): تطبق دالة ملفوفة على قيمة ملفوفة (ap()+of()). - المونادات (
Monads): تطبق دالة تُرجع قيمة ملفوفة على قيمة ملفوفة (chain()+of()).
تمارين (المجموعة 5)
اعتبر هذا الكائن:
const restaurant = {
name: "The Creamery",
address: {
city: "Los Angeles",
street: {
name: "Melrose Avenue",
},
},
rating: 8,
};
أنشئ دالة getStreetName()، كما يوحي اسمها، تُرجع اسم الشارع للمطعم. استخدم safeProp() (ودالة chain()، بالإضافة إلى أي مساعدات وظيفية أخرى تحتاجها) للقيام بذلك بطريقة نقية.
// safeProp :: String -> Object -> Maybe a
const safeProp = curry(
(prop, obj) =>
obj[prop] === undefined || obj[prop] === null ? Maybe.Nothing() : Maybe.Just(obj[prop])
);
// getStreetName :: Object -> Maybe String
const getStreetName = ...
إجابات التمارين
الإجابات التي أقترحها ليست الوحيدة. قد تتوصل إلى حلولك الخاصة، أو حتى أفضل. طالما أن حلك يعمل، فهذا رائع.
المجموعة 1
العودة إلى التمارين.
-
الدوال النقية (
Pure functions):a،d،e/ الدوال غير النقية (Impure functions):b،cبالنسبة لـ
e، قد لا تكون الإجابة سهلة الفهم. كانت هذه الدالة:const counter = (start, end) => { // ... // e () => counter(start + 1, end); };لذا فهي دالة داخل أخرى. قلنا إن الدالة النقية (
pure function) لا ينبغي أن تعتمد على الخارج، ولكن هنا تصل إلى متغيرات خارج نطاقها، تلك التي لديها إغلاق (closure) عليها (counter،start، وend). في لغة وظيفية نقية، على عكسJavaScript، ستكونcounterوstartوendغير قابلة للتغيير (immutable) لذا ستكونeنقية لأنه، لنفس المدخل (في هذه الحالة لا شيء)، سنحصل دائماً على نفس المخرج. ومع ذلك، فإن القيم فيJavaScriptقابلة للتغيير (mutable) افتراضياً. لذا إذا كانstartكائناً لأي سبب، فقد يتم تغييره خارجcounterأو داخلeنفسها. في هذه الحالة، ستعتبرeغير نقية (impure). ولكن نظراً لأن هذا ليس هو الحال هنا، فقد صنفتها كدالة نقية. انظر إلى هذا الموضوع لمزيد من التفاصيل. -
const people = [ { firstname: "Bill", lastname: "Harold", age: 54 }, { firstname: "Ana", lastname: "Atkins", age: 42 }, { firstname: "John", lastname: "Doe", age: 57 }, { firstname: "Davy", lastname: "Johnson", age: 34 }, ]; const uppercaseNames = (person) => ({ firstname: person.firstname.toUpperCase(), lastname: person.lastname.toUpperCase(), age: person.age, }); // "sort" mutates the original array it's applied on. // So I make a copy before ([...people]) to not mutate the original argument. const sortByAge = (people) => [...people].sort((person1, person2) => person1.age - person2.age); const parsePeople = (people) => sortByAge(people.map(uppercaseNames)); // NOT SURE TO INCLUDE // If you have already read the section on Composition (after this one), you may come up with // a more readable version for "parsePeople": // const parsePeople = pipe(map(uppercaseNames), sortByAge); // or // const parsePeople = compose(sortByAge, map(uppercaseNames)); parsePeople(people); // [ // {firstname: "DAVY", lastname: "JOHNSON", age: 34}, // {firstname: "ANA", lastname: "ATKINS", age: 42}, // {firstname: "BILL", lastname: "HAROLD", age: 54}, // {firstname: "JOHN", lastname: "DOE", age: 57}, // ]هذه هي النسخة التي توصلت إليها، ولكن أي اختلاف يعمل طالما أنه لا يحتوي على آثار جانبية (
side-effects). الدالة في التمرين تغير بالفعل الكائن الذي تم تمريره كوسيط. ولكن يمكنك التحقق من أن مصفوفةpeopleالأصلية لم تتغير في هذا التصحيح.
المجموعة 2
العودة إلى التمارين.
-
const input = "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum."; // ... // keepLetters :: [Character] -> [Character] | [] const keepLetters = filter((char) => "abcdefghijklmnopqrstuvwxyz".includes(char) ); // getLetters :: String -> [Character] const getLetters = pipe( lowercase, getChars, keepLetters, removeDuplicates, sort ); // or // const getLetters = compose( // sort, // removeDuplicates, // keepLetters, // getChars, // lowercase // ); getLetters(input); // ["a", "b", "c", "d", "e", "f", "g", "h", "i", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "x"] -
// getMedianAges :: [Key, [Person]] -> [Key, Object] const getMedianAges = reduceOverVal((acc, person) => { const key = `medianAge${person.sex}`; return !acc[key] ? { ...acc, [key]: person.age } : { ...acc, [key]: mean(acc[key], person.age) }; }, {}); // groupsMedianAges :: Object -> Object const groupsMedianAges = pipe(getEntries, map(getMedianAges), fromEntries); // or // const groupsMedianAges = compose(fromEntries, map(getMedianAges), getEntries); -
// reduce :: (b -> a -> b) -> b -> [a] -> b -
// curry :: ((a, b, ...) -> c) -> a -> b -> ... -> c
المجموعة 3
العودة إلى التمارين.
-
const uppercaseF = map((str) => str.toUpperCase()); // Example: // const myFunctor = Just("string") // uppercaseF(myFunctor) // Just("STRING") -
// printUsername :: User -> _ const printUsername = pipe( safeProp("name"), uppercaseF, maybe("Username not found !", console.log) ); // Example: // printUsername({ name: "Yann Salmon", age: 18, interests: ["Programming", "Sport", "Reading", "Math"], // ... }); // console: YANN SALMON
المجموعة 4
العودة إلى التمارين.
-
// getPartnerName :: User -> Maybe String const getPartnerName = pipe(safeProp("partner"), map(getName)); // userName :: Maybe String const userName = Maybe.of(getName(user)); // partnerName :: Maybe String const partnerName = getPartnerName(user); // couple :: Maybe String const couple = Maybe.of(getCouplePresentation).ap(userName).ap(partnerName); // Just("John Doe and Theresa Doe are partners.") -
// ... const couple = liftA2(getCouplePresentation, userName, partnerName);
المجموعة 5
العودة إلى التمارين.
-
// ... // getStreetName :: Object -> Maybe String const getStreetName = pipe( safeProp("address"), chain(safeProp("street")), chain(safeProp("name")) ); getStreetName(restaurant); // Just("Melrose Avenue")
للمضي قدماً
هذا المقال مستوحى بشكل أساسي مما تعلمته من هذه الموارد الثلاثة الرائعة (حسب مستوى الصعوبة):
- قائمة تشغيل
Fun Fun Function(فيديو) - كتاب
Functional-Light JavaScript - كتاب
Mostly adequate guide for Functional Programming
مثلي، ستجدون بالتأكيد بعض المفاهيم صعبة الفهم في البداية. ولكن يرجى الاستمرار. لا تترددوا في إعادة مشاهدة مقاطع الفيديو وإعادة قراءة الفقرات بعد ليلة نوم جيدة. أؤكد لكم أن ذلك سيؤتي ثماره.
يوجد أيضاً مستودع Github رائع يجمع الموارد حول البرمجة الوظيفية في JavaScript. ستجدون، من بين أمور أخرى، مكتبات رائعة توفر مساعدات وظيفية. مفضلتي في الوقت الحالي هي Ramda JS. ويوفر آخرون أيضاً مونادات مثل Sanctuary.
بالتأكيد لا أعرف كل شيء عن البرمجة الوظيفية، لذا هناك مواضيع لم أغطها. تلك التي أعرفها هي:
- تقنية تسمى "التحويل" (
transducing). باختصار، إنها طريقة لتركيب عملياتmap()وfilter()وreduce()معاً. تحقق من هذا و ذاك لمعرفة المزيد. - أنواع أخرى شائعة من المونادات:
Either،Map،List. - هياكل جبرية أخرى مثل "شبه المجموعات" (
semi-groups) و"المونيدات" (monoids). - البرمجة الوظيفية التفاعلية (
Functional Reactive Programming).
الخلاصة التقنية
لقد استعرضنا في هذا الدليل الشامل مبادئ البرمجة الوظيفية (FP) بدءاً من الأساسيات وصولاً إلى المفاهيم المتقدمة كالفانكتورات (Functors) والمونادات (Monads). يتبين لنا أن FP تقدم منهجية قوية لبناء برامج أكثر قابلية للقراءة والصيانة وأقل عرضة للأخطاء، خاصة في البيئات المتزامنة. على الرغم من أن منحنى التعلم قد يكون حاداً في البداية بسبب المصطلحات الجديدة، إلا أن الفوائد المتمثلة في التفكير التصريحي (declarative thinking) والتعامل الممنهج مع الآثار الجانبية (side-effects) تفوق بكثير التحديات. إن فهم مفاهيم مثل الدوال النقية (pure functions)، وعدم القابلية للتغيير (immutability)، والتركيب (composition)، والتقليص (currying)، يزود المطورين بأدوات قوية لكتابة كود نظيف وفعال، مما يعزز جودة البرمجيات ويفتح آفاقاً جديدة في حل المشكلات المعقدة.
هذا كل شيء! قبل أن ننهي، أود أن أحذركم من الأخطاء المحتملة. أنا لست خبيراً في البرمجة الوظيفية، لذا يرجى أن تكونوا نقديين تجاه هذا المقال كلما تعلمتم المزيد عنه. أنا دائماً منفتح للمناقشات والتحسينات. في أي حال، آمل أن أكون قد وضعت ما أعتبره الأساسيات الضرورية لكم لتكونوا أكثر إنتاجية في عملكم اليومي، بالإضافة إلى تزويدكم بالأدوات والاهتمام للمضي قدماً. ومع ذلك، استمروا في البرمجة! 👨💻