استخراج بيانات متجر إلكتروني باستخدام بايثون عبر Beautiful Soup وPandas
مقدمة: ما هو استخراج البيانات من الويب باستخدام Python؟
يُعد استخراج البيانات من الويب أو Web Scraping من أهم المهارات العملية التي تساعد المطورين والمحللين على جمع المعلومات من المواقع بشكل آلي ومنظم. في هذا الدليل سنبني مشروعاً عملياً لاستخراج بيانات منتجات من متجر إلكتروني باستخدام لغة Python مع مكتبتي Beautiful Soup وPandas.
الفكرة هنا لا تقتصر على قراءة الصفحة الرئيسية فقط، بل تمتد إلى الدخول إلى صفحة كل منتج على حدة لاستخراج تفاصيل أعمق مثل اسم المنتج والسعر والتقييم والوصف. وهذه الطريقة مفيدة جداً عندما لا تكون كل البيانات متاحة في صفحة القوائم الرئيسية.

قبل البدء: الاعتبارات الأخلاقية واحترام robots.txt
قبل تنفيذ أي عملية Scraping على أي موقع، يجب مراجعة ملف robots.txt الخاص به. هذا الملف يوضح للمطورين وبرامج الزحف ما الصفحات المسموح الوصول إليها وما القيود المفروضة.
- لا ترسل عدداً كبيراً من الطلبات في وقت قصير.
- تجنب الضغط على خوادم الموقع دون داعٍ.
- استخدم المشروع لأغراض تعليمية أو تحليلية مشروعة.
- تحقق دائماً من شروط الاستخدام الخاصة بالموقع.
في المثال التطبيقي، سنعتمد على متجر إلكتروني متخصص في بيع الويسكي، وسنجمع البيانات بشكل منظم ومسؤول.

فهم المشكلة: لماذا نحتاج إلى زيارة صفحة كل منتج؟
في كثير من المتاجر الإلكترونية، لا تعرض صفحة التصنيفات جميع التفاصيل المهمة. قد تجد اسم المنتج والسعر فقط، بينما يكون التقييم أو الوصف داخل الصفحة الداخلية الخاصة بالمنتج.
لهذا سنعمل على مرحلتين:
- جمع روابط جميع المنتجات من صفحات التصنيف.
- زيارة كل رابط على حدة لاستخراج البيانات التفصيلية.
هذه المنهجية تمنحك مرونة أعلى وتساعدك على بناء قاعدة بيانات أدق وأكثر فائدة.

إعداد مشروع استخراج البيانات في Python
إنشاء المجلد وتثبيت المكتبات
إعداد المشروع بسيط للغاية. يكفي إنشاء مجلد جديد ثم تثبيت المكتبات المطلوبة: beautifulsoup4 وrequests وpandas. يفترض هذا الشرح أنك تستخدم إصدار Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
pip install pandasإنشاء ملف المشروع واستيراد المكتبات
بعد ذلك، أنشئ ملفاً داخل المجلد وليكن مثلاً باسم scraper.py، ثم أضف الاستيرادات التالية:
import requests
from bs4 import BeautifulSoup
import pandas as pdتهيئة المتغيرات الأساسية وإرسال User-Agent
سنحتاج إلى تعريف الرابط الأساسي للموقع في متغير baseurl، وذلك لأن روابط المنتجات قد تأتي بصيغة نسبية ونحتاج إلى تحويلها إلى روابط كاملة.
كذلك من الأفضل إرسال قيمة User-Agent مخصصة مع كل طلب HTTP، لأن بعض المواقع قد تمنع الطلبات الافتراضية القادمة من مكتبة requests.
baseurl = "https://www.thewhiskyexchange.com"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}تحليل بنية الصفحة واكتشاف روابط المنتجات
الخطوة التالية هي فحص الصفحة باستخدام أدوات المطور في المتصفح مثل Inspect داخل Chrome DevTools. الهدف هنا هو معرفة الوسوم والعناصر التي تحتوي على بطاقات المنتجات وروابطها.

بعد الفحص سنجد أن كل منتج موجود داخل عنصر li يحمل فئة product-grid__item. لذا يمكننا استخراج جميع هذه العناصر كما يلي:
k = requests.get('https://www.thewhiskyexchange.com/c/35/japanese-whisky').text
soup = BeautifulSoup(k, 'html.parser')
productlist = soup.find_all("li", {"class": "product-grid__item"})
print(productlist)طباعة القائمة هنا تساعدنا على التأكد من أننا نستهدف العناصر الصحيحة بالفعل.
استخراج روابط صفحات المنتجات
بعد الحصول على العناصر التي تمثل المنتجات، نحتاج الآن إلى استخراج الرابط الداخلي لكل منتج من داخل الوسم a الذي يحمل الفئة product-card.
productlinks = []
for product in productlist:
link = product.find("a", {"class": "product-card"}).get('href')
productlinks.append(baseurl + link)في هذا الجزء:
- أنشأنا قائمة فارغة باسم
productlinks. - استخدمنا حلقة
forللمرور على كل منتج. - استخرجنا قيمة الخاصية
hrefعبر الدالةget(). - أضفنا
baseurlلتكوين رابط كامل وصحيح.

جمع الروابط من جميع صفحات التصنيف
لأن المنتجات موزعة على عدة صفحات، نحتاج إلى تكرار العملية على جميع الصفحات بدلاً من صفحة واحدة فقط. في المثال الحالي هناك خمس صفحات، لذلك سنستخدم حلقة تمر من 1 إلى 5.
productlinks = []
for x in range(1, 6):
k = requests.get(
'https://www.thewhiskyexchange.com/c/35/japanese-whisky?pg={}&psize=24&sort=pasc'.format(x)
).text
soup = BeautifulSoup(k, 'html.parser')
productlist = soup.find_all("li", {"class": "product-grid__item"})
for product in productlist:
link = product.find("a", {"class": "product-card"}).get('href')
productlinks.append(baseurl + link)بعد تشغيل هذا الجزء، يمكنك التأكد من عدد الروابط عبر طباعة طول القائمة productlinks. في المثال الأصلي من المفترض أن نحصل على 97 رابطاً.
تحليل صفحة المنتج واستخراج البيانات المطلوبة
الآن تبدأ المرحلة الأهم: زيارة كل صفحة منتج واستخراج المعلومات التي نحتاجها. بعد فحص صفحة المنتج، سنجد أن البيانات موزعة تقريباً كما يلي:
- الاسم داخل الوسم
h1. - السعر داخل الوسم
p. - التقييم داخل عنصر مراجعات مخصص.
- الوصف داخل عنصر
div.

يمكننا تنفيذ ذلك عبر الشيفرة التالية:
data = []
for link in productlinks:
f = requests.get(link, headers=headers).text
hun = BeautifulSoup(f, 'html.parser')
try:
price = hun.find("p", {"class": "product-action__price"}).text.replace('\n', "")
except:
price = None
try:
about = hun.find("div", {"class": "product-main__description"}).text.replace('\n', "")
except:
about = None
try:
rating = hun.find("div", {"class": "review-overview"}).text.replace('\n', "")
except:
rating = None
try:
name = hun.find("h1", {"class": "product-main__name"}).text.replace('\n', "")
except:
name = None
whisky = {
"name": name,
"price": price,
"rating": rating,
"about": about
}
data.append(whisky)لماذا استخدمنا try وexcept؟
ليست كل صفحات المنتجات متطابقة تماماً. بعض المنتجات قد لا تحتوي على تقييم، وبعضها قد يفتقد جزءاً من الوصف. لذلك يساعدنا استخدام try وexcept على منع توقف البرنامج عند غياب أي عنصر.
تنظيف النصوص باستخدام replace()
عند استخراج النصوص من HTML، غالباً ما تظهر أسطر جديدة أو فراغات غير مرغوبة. لهذا استُخدمت الدالة replace() لإزالة محارف \n وتحسين شكل البيانات قبل تخزينها.
تنظيم البيانات في Pandas DataFrame
بعد الانتهاء من جمع البيانات، تأتي مرحلة تنظيمها في بنية أكثر وضوحاً. وهنا تبرز فائدة مكتبة Pandas التي تسهّل عرض البيانات وتحليلها أو حفظها لاحقاً في ملف CSV أو Excel.
df = pd.DataFrame(data)
print(df)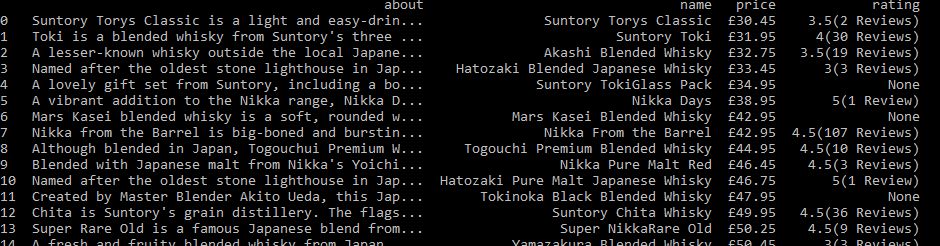
الكود الكامل لمشروع Web Scraping
فيما يلي النسخة الكاملة من السكربت بعد جمع جميع الخطوات السابقة في ملف واحد:
import requests
from bs4 import BeautifulSoup
import pandas as pd
baseurl = "https://www.thewhiskyexchange.com"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
productlinks = []
t = {}
data = []
c = 0
for x in range(1, 6):
k = requests.get(
'https://www.thewhiskyexchange.com/c/35/japanese-whisky?pg={}&psize=24&sort=pasc'.format(x)
).text
soup = BeautifulSoup(k, 'html.parser')
productlist = soup.find_all("li", {"class": "product-grid__item"})
for product in productlist:
link = product.find("a", {"class": "product-card"}).get('href')
productlinks.append(baseurl + link)
for link in productlinks:
f = requests.get(link, headers=headers).text
hun = BeautifulSoup(f, 'html.parser')
try:
price = hun.find("p", {"class": "product-action__price"}).text.replace('\n', "")
except:
price = None
try:
about = hun.find("div", {"class": "product-main__description"}).text.replace('\n', "")
except:
about = None
try:
rating = hun.find("div", {"class": "review-overview"}).text.replace('\n', "")
except:
rating = None
try:
name = hun.find("h1", {"class": "product-main__name"}).text.replace('\n', "")
except:
name = None
whisky = {
"name": name,
"price": price,
"rating": rating,
"about": about
}
data.append(whisky)
c = c + 1
print("completed", c)
df = pd.DataFrame(data)
print(df)نصائح مهمة لتحسين جودة مشروع الاستخراج
1) أضف مهلة زمنية بين الطلبات
من الأفضل استخدام تأخير بسيط بين الطلبات عبر مكتبة مثل time باستخدام sleep() لتجنب إرسال عدد كبير من الطلبات بسرعة.
2) تحقق من الاستجابات
بدلاً من الاعتماد على .text مباشرة في كل مرة، يمكنك التحقق من رمز الحالة Status Code للتأكد من أن الطلب نجح.
3) خزّن النتائج في ملف
بعد بناء DataFrame يمكنك حفظ النتائج بسهولة باستخدام df.to_csv() أو df.to_excel().
4) تعامل مع تغيّر بنية الموقع
مواقع الويب تتغير باستمرار، لذلك قد تحتاج إلى تعديل أسماء الفئات class أو محددات العناصر إذا تغيرت بنية HTML.
متى تكون Beautiful Soup وPandas خياراً ممتازاً؟
هذا المزيج مناسب جداً عندما تريد:
- استخراج بيانات منظمة من صفحات ثابتة نسبياً.
- تحويل النتائج إلى جداول قابلة للتحليل.
- إنجاز مهام جمع البيانات بسرعة ووضوح.
- بناء نماذج أولية لمشاريع تحليل السوق أو متابعة الأسعار.
أما إذا كانت الصفحة تعتمد بشدة على JavaScript لتحميل المحتوى، فقد تحتاج إلى أدوات إضافية مثل Selenium أو حلول تعتمد على المتصفح.
الخلاصة التقنية
يعرض هذا المثال طريقة عملية وفعالة لبناء سكربت استخراج بيانات من متجر إلكتروني باستخدام Python وBeautiful Soup وPandas. القوة الحقيقية في هذا الأسلوب تكمن في تقسيم العمل إلى مراحل واضحة: جمع الروابط أولاً، ثم زيارة الصفحات الداخلية، ثم تنظيف النتائج وتنظيمها في جدول تحليلي. تقنياً، هذا النمط مناسب جداً لمهام تتبع الأسعار وتحليل المنتجات وبناء قواعد بيانات خفيفة، بشرط الالتزام بأخلاقيات الزحف واحترام موارد المواقع المستهدفة.