كيفية استخدام بايثون وPandas لتحليل بيانات الأعاصير والعواصف الاستوائية بصرياً
مقدمة: هل أصبحت العواصف الكبرى أكثر تكراراً؟
تتكرر كثيراً عبارات من قبيل: الطقس لم يعد كما كان، والكوارث الطبيعية صارت أشد من السابق. لكن بدلاً من الاكتفاء بالانطباعات العامة، يمكننا العودة إلى البيانات التاريخية واستخدام أدوات تحليل البيانات لفهم الصورة بدقة أكبر. في هذا المقال سنستعرض طريقة عملية لتحليل بيانات الأعاصير والعواصف الاستوائية في الولايات المتحدة باستخدام Python ومكتبة Pandas، مع التركيز على تنظيف البيانات وتمثيلها بصرياً للوصول إلى استنتاجات أكثر موضوعية.

ما المقصود بالعاصفة الكبرى؟
عندما نتحدث عن الأعاصير، فنحن نشير غالباً إلى ما يُعرف علمياً باسم tropical cyclones. وتوصف بأنها tropical لأنها تتشكل فوق المحيطات ضمن المناطق المدارية القريبة من خط الاستواء، بينما يشير مصطلح cyclone إلى الطبيعة الدورانية لحركة الرياح داخل العاصفة.
بصورة عامة:
- العاصفة ذات الرياح المستمرة بين
34و63عقدة تُصنّف كعاصفة استوائية. - إذا تجاوزت سرعة الرياح
64عقدة، فإنها تُصنّف كإعصارhurricane، أوtyphoonفي بعض المناطق الأخرى. - الأعاصير تُقسم إلى فئات من
1إلى5وفق مقياس الشدة، وتُعد الفئة الخامسة الأخطر والأكثر تدميراً.
من أين تأتي بيانات الأعاصير التاريخية؟
تتوفر في الولايات المتحدة سجلات تاريخية موثوقة نسبياً تمتد لأكثر من قرن ونصف. لكن فهم هذه البيانات يتطلب معرفة كيف جُمعت عبر الزمن، لأن جودة الرصد تطورت بشكل كبير.
تطور وسائل الرصد الجوي
- قبل أربعينيات القرن الماضي، كانت أغلب الملاحظات تأتي من السفن العابرة للمحيطات.
- ظهور الاستطلاع الجوي في الأربعينيات ساعد على اكتشاف عواصف لم يكن من السهل رصدها سابقاً.
- بدء استخدام الأقمار الصناعية منذ الستينيات جعل تتبع النشاط المداري أكثر شمولاً ودقة.
هذا يعني أن ارتفاع عدد العواصف المسجلة في بعض الفترات لا يدل دائماً على زيادة فعلية في النشاط الجوي، بل قد يكون نتيجة تحسن أدوات الرصد.
ماذا تقول السجلات التاريخية فعلاً؟
بحسب بيانات NOAA، لا يوجد دليل واضح على أن الأعاصير الأطلسية طويلة المدة ازدادت عدداً بشكل ملحوظ. أما العواصف قصيرة المدة فقد ارتفعت في السجلات الحديثة، لكن التفسير الأقرب هو تحسن المراقبة وليس تغيراً حقيقياً في عددها فقط.
لذلك، من المهم عند تحليل البيانات الخام أن ندرك أن السجل التاريخي ليس مثالياً، وأن الاستنتاجات يجب أن تُقرأ في سياق تطور تقنيات الرصد.
تحليل بيانات أعاصير الولايات المتحدة بين 1851 و2019
مصدر البيانات هنا هو سجلات تأثيرات ووصول الأعاصير إلى اليابسة في الولايات المتحدة من NOAA. بعد نسخ الجدول وحفظه في ملف .csv، يمكننا البدء في تنظيفه داخل بيئة Jupyter.
تهيئة بيئة العمل
import pandas as pd
import matplotlib as plt
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv('all-us-hurricanes-noaa.csv')فحص أنواع البيانات
قبل أي معالجة، من المفيد التحقق من أنواع الأعمدة عبر df.dtypes، لأن بعض القيم الرقمية قد تكون مخزنة ككائنات object، ما يعطل التحليل الإحصائي والرسوم البيانية.
df.dtypesتنظيف الصفوف غير المفيدة
تتضمن البيانات الأصلية صفوفاً تمثل عناوين العقود مثل 1850s، وصفوفاً لسنوات لم تُسجل فيها أحداث وتحمل القيمة None. كما توجد قيم مفقودة في سرعة الرياح ممثلة بالرمز -----.
df = df[(df.Year.str.contains("s")) == False]
df = df[(df.Month.str.contains("None")) == False]
df = df.replace('Sp-Oc', 'Sep')
df = df.replace('Jl-Au', 'Jul')تحويل الأشهر إلى قيم رقمية
لتحويل اختصارات الأشهر مثل Jan وSep إلى أرقام، نستخدم الدالة pd.to_datetime() مع التنسيق %b.
df.Month = pd.to_datetime(df.Month, format='%b').dt.monthإعادة تسمية الأعمدة
تبسيط أسماء الأعمدة يجعل الكتابة أوضح وأسهل أثناء التحليل.
df.columns = ['Year', 'Month', 'States', 'Category', 'Pressure', 'Max Wind', 'Name']تحويل القيم إلى صيغ مناسبة
بعد ذلك نُحوّل عمود السنة إلى أعداد صحيحة، والقيم المفقودة في Max Wind إلى NaN، ثم نحوّل العمود نفسه إلى float.
df = df.astype({'Year': 'int'})
df = df.replace('-----', np.NaN)
df = df.astype({'Max Wind': 'float'})يمكن التحقق من النتيجة مجدداً عبر:
df.dtypesعرض بيانات الأعاصير بصرياً
لدراسة البيانات بشكل أوضح، من الأفضل فصل المقاييس الرئيسية الثلاثة:
- فئة الإعصار
Category - الضغط الجوي
Pressure - أقصى سرعة رياح
Max Wind
ولمعرفة توزيع الفئات أولاً، يمكن استخدام value_counts():
df['Category'].value_counts()غالباً سنلاحظ أن الأعاصير من الفئتين 1 و2 أكثر عدداً من الفئات الأعلى شدة.
رسم مدرج تكراري لجميع الأعاصير
df.hist(column='Year', bins=25)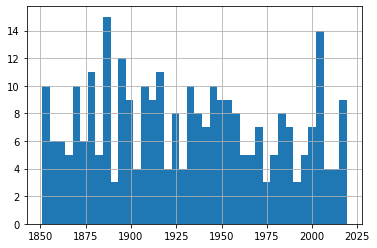
يمنحنا هذا الرسم نظرة عامة على توزع الأحداث عبر الزمن، لكنه لا يكشف الفروق بين الفئات المختلفة.
تقسيم البيانات حسب فئة الإعصار
df_category = df[['Year', 'Category']]
df_wind = df[['Year', 'Max Wind']]
df_pressure = df[['Year', 'Pressure']]ثم نستخدم حلقة for لرسم مدرج تكراري مستقل لكل فئة:
for x in range(1, 6):
cat_num = x
converted_num = str(cat_num)
dfcat = df_category['Category'] == (x)
df1 = df_category[dfcat]
df1.hist(column='Year', bins=20)
plt.title("Total Category " + (converted_num) + " Events")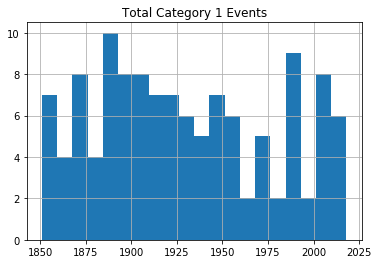
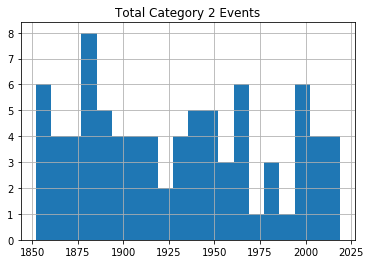
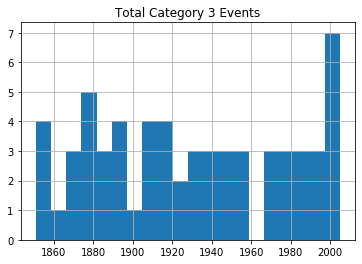
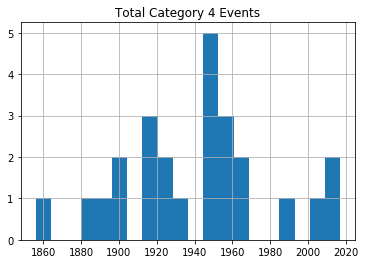
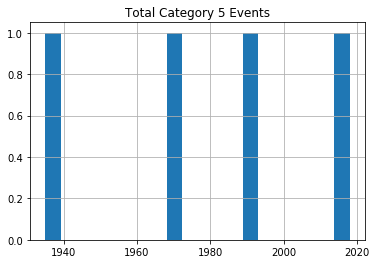
عند مراجعة الرسوم، لا يظهر اتجاه واضح يدل على زيادة كبيرة ومستمرة في تكرار الأعاصير القوية مع مرور الوقت، على الأقل ضمن هذه البيانات الخام غير المعدلة.
تحليل بيانات العواصف الاستوائية في الولايات المتحدة
الأعاصير ليست وحدها المهمة، فالعواصف الاستوائية المدمرة تستحق التحليل أيضاً. توفر NOAA مجموعة بيانات مشابهة لهذه الفئة، ويمكن حفظها بالطريقة نفسها في ملف .csv.
يجدر الانتباه إلى أن البيانات لا تحتوي على سجلات للفترة بين 1966 و1982، وهو فراغ زمني يجب أخذه بالحسبان أثناء تفسير الرسوم.
بدء التحليل
import pandas as pd
import matplotlib as plt
import numpy as np
df = pd.read_csv('all-us-tropical-storms-noaa.csv')إزالة الصفوف التي لا تحتوي على أحداث
df = df[(df.Date.str.contains("None")) == False]تنظيف عمود التاريخ من الرموز الإضافية
يتضمن عمود Date بعض الرموز التي تشير إلى حواشٍ مثل $ و* و# و% و&. يجب حذفها قبل تحويل التاريخ.
df['Date'] = df.Date.str.replace('\$', '')
df['Date'] = df.Date.str.replace('\*', '')
df['Date'] = df.Date.str.replace('\#', '')
df['Date'] = df.Date.str.replace('\%', '')
df['Date'] = df.Date.str.replace('\&', '')إعادة تسمية الأعمدة وتحويل التاريخ
df.columns = ['Storm#', 'Date', 'Time', 'Lat', 'Lon', 'MaxWinds', 'LandfallState', 'StormName']
df.Date = pd.to_datetime(df.Date)تمثيل بيانات العواصف الاستوائية
في هذه المجموعة، يُعد عمود MaxWinds الأكثر أهمية لأنه يعكس شدة العاصفة مباشرة.
df1 = df[['Date', 'MaxWinds']]مدرج تكراري لجميع العواصف الاستوائية
df1['Date'].hist()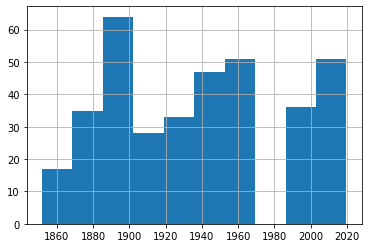
يُظهر الرسم فجوة زمنية واضحة في فترة السبعينيات تقريباً بسبب غياب البيانات، ولا يقدّم دليلاً بصرياً مباشراً على تصاعد حاد في عدد العواصف.
معرفة حجم البيانات
print(df1.shape)تشير النتيجة إلى وجود 362 حدثاً في هذه العينة.
تقسيم العواصف حسب سرعة الرياح
بما أن القيم تأتي غالباً بمضاعفات 5 عقدات، يمكن تقسيم البيانات إلى أربع مجموعات تقريبية:
- من
30إلى39عقدة - من
40إلى49عقدة - من
50إلى59عقدة - من
60إلى79عقدة
df_30 = df1[df1['MaxWinds'].between(30, 39)]
df_40 = df1[df1['MaxWinds'].between(40, 49)]
df_50 = df1[df1['MaxWinds'].between(50, 59)]
df_60 = df1[df1['MaxWinds'].between(60, 79)]التحقق من عدد الأحداث في كل مجموعة
st1 = len(df_30.index)
print('The number of storms between 30 and 39: ', st1)
st2 = len(df_40.index)
print('The number of storms between 40 and 49: ', st2)
st3 = len(df_50.index)
print('The number of storms between 50 and 59: ', st3)
st4 = len(df_60.index)
print('The number of storms between 60 and 79: ', st4)هذا الفحص يساعد على التأكد من منطقية التقسيم قبل رسم البيانات.
تحليل التكرارات داخل مجموعة محددة
df_40['MaxWinds'].value_counts()مثلاً يمكن ملاحظة عدد أحداث 40 عقدة مقابل 45 عقدة داخل الشريحة نفسها.
رسم خطي للمجموعات الأربع
import matplotlib.pyplot as plt
fig = plt.figure()
ax = plt.subplot(111)
df_30['MaxWinds'].plot(ax=ax, label='df_30')
df_40['MaxWinds'].plot(ax=ax, label='df_40')
df_50['MaxWinds'].plot(ax=ax, label='df_50')
df_60['MaxWinds'].plot(ax=ax, label='df_60')
ax.set_ylabel('Wind Speed In Knots')
ax.set_xlabel('Time Between 1851 and 2019')
plt.title('Tropical Storms by Maximum Wind Speeds (knots)')
ax.legend()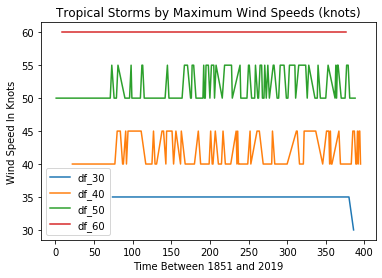
هذا الرسم مفيد لمراجعة سلامة البيانات، لكنه ليس الأفضل لقياس تغير التكرار بمرور الزمن.
رسم مدرجات تكرارية لكل شريحة سرعة
df_30['Date'].hist(bins=20)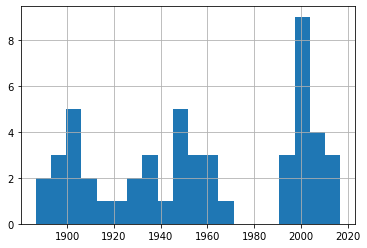
df_40['Date'].hist(bins=20)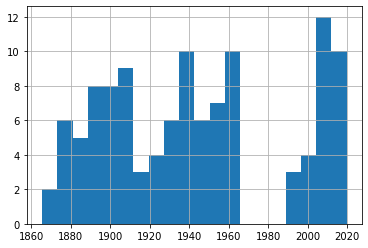
df_50['Date'].hist(bins=20)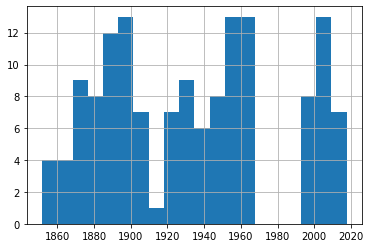
df_60['Date'].hist(bins=20)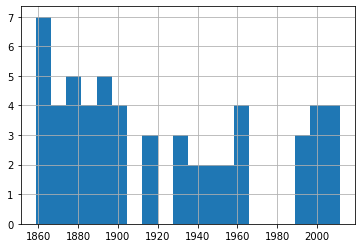
من خلال هذه الرسوم، يبدو أن تكرار العواصف ضمن الشرائح المختلفة ظل متقارباً نسبياً عبر المدى الزمني المتاح، مع ضرورة تذكر أن اختلاف جودة الرصد بين الماضي والحاضر قد يؤثر في قراءة النتائج.
أفضل ممارسات عند تحليل بيانات الطقس باستخدام Python
- افحص أنواع البيانات دائماً باستخدام
dtypesقبل البدء بالتحليل. - نظّف القيم النصية غير القياسية مثل
Noneو-----قبل الرسم أو الحساب. - استخدم
value_counts()وshapeللتحقق من منطقية النتائج. - جرّب أكثر من قيمة في
binsعند إنشاء المدرجات التكرارية حتى لا تخفي الاتجاهات المهمة. - لا تفسّر الرسوم البيانية بمعزل عن سياق جمع البيانات وتطور أدوات الرصد.
الخلاصة التقنية
تحليل بيانات الأعاصير والعواصف الاستوائية باستخدام Python وPandas يكشف قيمة كبيرة للبيانات التاريخية، لكنه يذكرنا أيضاً بأن الأرقام وحدها لا تكفي من دون فهم سياقها. من الناحية التقنية، يمكن القول إن تنظيف البيانات وتحويلها إلى صيغ صحيحة هو الخطوة الأهم قبل أي استنتاج. أما من ناحية النتائج، فالبيانات الخام المعروضة هنا لا تقدم دليلاً بسيطاً ومباشراً على تصاعد منتظم في تكرار العواصف الكبرى، ما يجعل التحليل المتزن القائم على البيانات أفضل بكثير من الاعتماد على الانطباعات العامة.