شرح دالة zip() في بايثون مع أمثلة عملية واضحة
مقدمة إلى دالة zip() في بايثون
عند كتابة البرامج بلغة Python، ستواجه كثيراً حالات تحتاج فيها إلى المرور على أكثر من كائن قابل للتكرار في الوقت نفسه، مثل القوائم والسلاسل النصية والصفوف. هنا تظهر أهمية دالة zip() التي توفّر طريقة أنيقة وفعالة لتنفيذ التكرار المتوازي دون تعقيد غير ضروري.
في هذا الدليل، سنتعرف على آلية عمل zip()، ولماذا تكون أفضل من بعض الحلول التقليدية في مواقف كثيرة، وما الذي يحدث عند اختلاف أطوال القوائم، وكيف يمكن الاستفادة من zip_longest() عند الحاجة إلى الاحتفاظ بجميع العناصر.

كيف نستخدم العامل in للتنقل داخل العناصر القابلة للتكرار؟
قبل فهم دالة zip()، من المفيد أن نسترجع الطريقة الأساسية للتكرار داخل كائن قابل للتكرار باستخدام حلقة for مع العامل in. الصيغة العامة تكون كالتالي:
for item in list_1:
# do something on itemالفكرة هنا بسيطة: يمر المفسّر على كل عنصر داخل list_1، ثم ينفّذ العملية المطلوبة على كل item.
لكن عند وجود أكثر من قائمة، مثل list_1 وlist_2، فإن استخدام حلقتين متداخلتين لا يحقق التكرار المتوازي الذي نريده:
# Example - 2 lists, list_1 and list_2
for i1 in list_1:
for i2 in list_2:
# do something on i1 and i2هذا الأسلوب يجعل البرنامج يمر على جميع عناصر list_2 لكل عنصر واحد من list_1، أي أنه ينتج تركيبات متعددة، وليس اقتراناً بين العناصر المتناظرة في الموضع نفسه. لذلك فهو لا يناسب الحالات التي نحتاج فيها إلى الوصول إلى العنصر ذي الفهرس نفسه من أكثر من قائمة.
لماذا لا يكون استخدام range() هو الخيار الأفضل دائماً؟
قد يخطر ببالك استخدام range() مع len() للوصول إلى العناصر عبر الفهارس، خاصة إذا كانت القوائم متساوية في الطول. مثال ذلك:
for i in range(len(list_1)):
# do something on list_1[i],list_2[i],list_3[i],...,list_N[i]هذا الأسلوب قد يعمل جيداً عندما تكون جميع القوائم متطابقة في عدد العناصر، لكنه ليس الأكثر أماناً أو مرونة دائماً.
متى تظهر المشكلة؟
- إذا حُذف عنصر من إحدى القوائم، فقد تحاول الوصول إلى فهرس لم يعد موجوداً، مما يؤدي إلى خطأ
IndexError. - إذا أُضيفت عناصر جديدة إلى إحدى القوائم، فقد لا تتم معالجتها لأن المجال الذي أنشأته عبر
range()لا يشملها. - الاعتماد على الفهارس يجعل الكود أقل وضوحاً مقارنة بالحلول المباشرة التي تتعامل مع العناصر نفسها.
لهذا السبب، تكون دالة zip() في كثير من الحالات أكثر أناقة وأسهل قراءة وصيانة.
ما هي دالة zip() في بايثون؟
دالة zip() تستقبل كائناً قابلاً للتكرار واحداً أو أكثر، ثم تُنشئ مُكرّراً iterator يعيد عناصر مجمّعة على شكل صفوف tuples. يحتوي كل صف على العناصر المتناظرة من المدخلات وفقاً للفهرس نفسه.
الصيغة العامة للدالة هي:
zip(*iterables)
بمعنى آخر، إذا مررت قائمتين إلى zip()، فإنها تربط العنصر الأول من الأولى مع العنصر الأول من الثانية، ثم الثاني مع الثاني، وهكذا.
كيف تنشئ zip() مُكرّراً من الصفوف؟
عند تطبيق zip() على قائمتين مثل L1 وL2، فإن الناتج يكون سلسلة من الصفوف، بحيث يحتوي كل صف على عنصر من كل قائمة في الموضع نفسه.
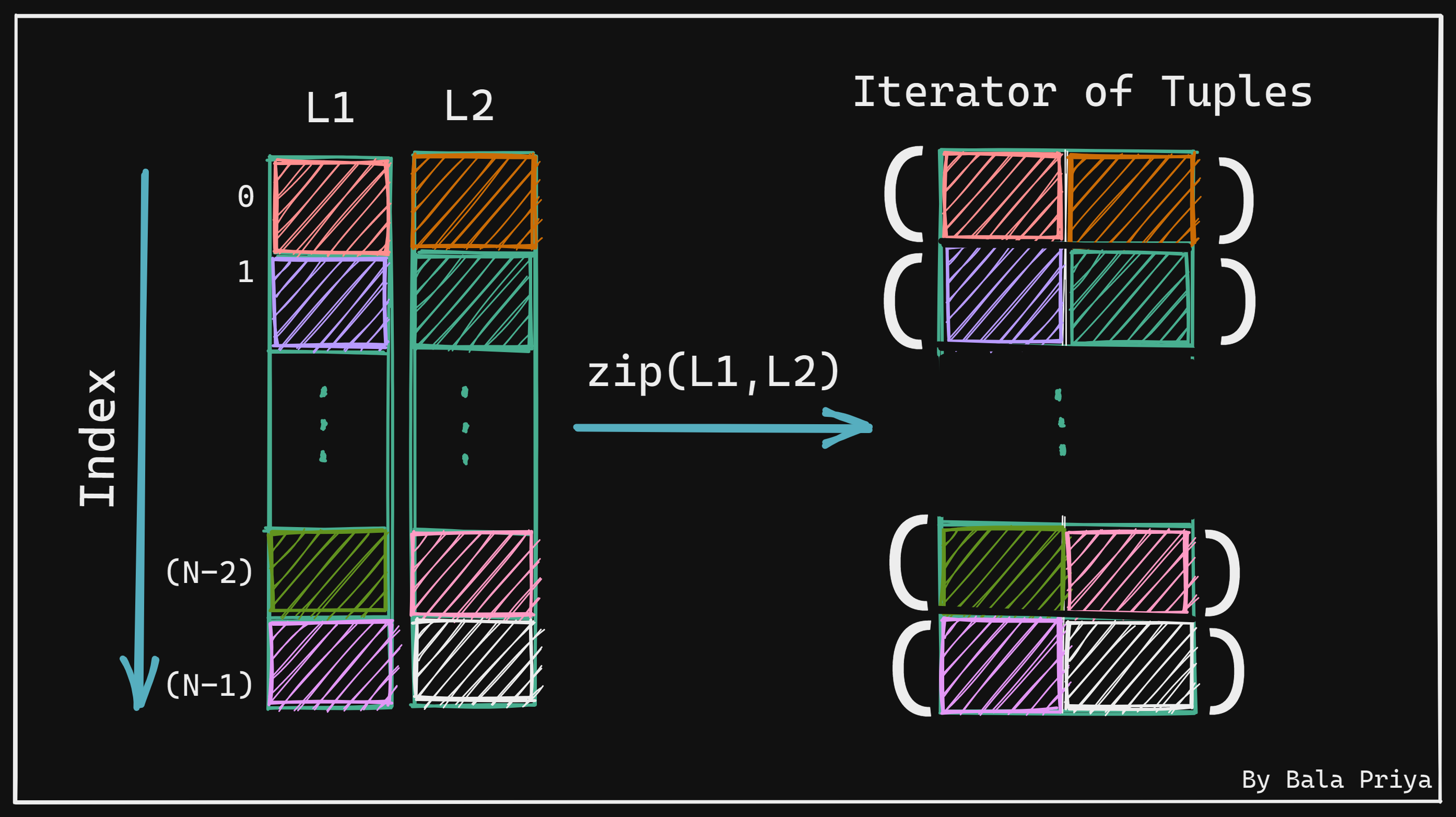
فمثلاً:
- الصف الأول يحتوي على العنصر عند الفهرس
0منL1والعنصر عند الفهرس0منL2. - الصف الثاني يحتوي على العنصرين عند الفهرس
1. - وتتكرر العملية بالطريقة نفسها لبقية العناصر.
استخدام دالة zip() مع مثال عملي
لنأخذ مثالاً بسيطاً على قائمتين متساويتين في الطول:
L1 = [1, 2, 3, 4, 5]
L2 = ['a', 'b', 'c', 'd', 'e']
zip_L1L2 = zip(L1, L2)
print(zip_L1L2)
# Sample Output
# <zip object at 0x7f92f44d5550>ستلاحظ أن الناتج ليس قائمة مباشرة، بل كائن من نوع zip object، لأنه مُكرّر يمكن المرور عليه لاحقاً.
ولعرض القيم بوضوح، يمكن تحويله إلى قائمة باستخدام list():
print(list(zip_L1L2))
# Output
# [(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd'), (5, 'e')]هذا الإخراج يوضّح كيف تم دمج العناصر المتناظرة من القائمتين في صفوف مرتبة.
ماذا يحدث إذا اختلفت أطوال العناصر القابلة للتكرار؟
واحدة من أهم خصائص zip() أنها تتوقف عندما ينتهي أقصر كائن قابل للتكرار. وهذا يعني أنها لا ترمي خطأً عند اختلاف الأطوال، بل تكتفي بعدد العناصر المتاحة في أقصر مدخل.
لنعدّل المثال السابق بحذف العنصر 'e' من L2:
L1 = [1, 2, 3, 4, 5]
L2 = ['a', 'b', 'c', 'd']
zip_L1L2 = zip(L1, L2)
print(list(zip_L1L2))
# Output
# [(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd')]كما ترى، تجاهلت الدالة العنصر 5 في L1 لأن القائمة الثانية انتهت قبله. هذه الميزة مفيدة عندما تريد تفادي الأخطاء، لكنها تتطلب الانتباه إذا كان فقدان العناصر غير المرغوب فيه يمثل مشكلة منطقية في التطبيق.
ماذا لو مررت عنصراً قابلاً للتكرار واحداً فقط أو لم تمرر شيئاً؟
عند تمرير كائن واحد فقط
إذا مررت قائمة واحدة فقط إلى zip()، فستحصل على صفوف أحادية العنصر:
L1 = [1, 2, 3, 4, 5]
zip_L1 = zip(L1)
print(list(zip_L1))
# Output
# [(1,), (2,), (3,), (4,), (5,)]لاحظ أن كل عنصر وُضع داخل صف tuple يحتوي على قيمة واحدة.
عند عدم تمرير أي وسيطات
إذا استدعيت zip() بدون أي مدخلات، فستحصل على مُكرّر فارغ:
zip_None = zip()
print(list(zip_None))
# Output
# []مثال عملي مفيد: دمج البيانات وحساب الإجمالي
من الاستخدامات الواقعية الممتازة لـ zip() دمج بيانات مرتبطة ببعضها، مثل أسماء المنتجات والأسعار والكميات. المثال التالي يوضح ذلك:
fruits = ["apples", "oranges", "bananas", "melons"]
prices = [20, 10, 5, 15]
quantities = [5, 7, 3, 4]
for fruit, price, quantity in zip(fruits, prices, quantities):
print(f"You bought {quantity} {fruit} for $ {price * quantity}")
# Output
# You bought 5 apples for $ 100
# You bought 7 oranges for $ 70
# You bought 3 bananas for $ 15
# You bought 4 melons for $ 60هذا المثال يبيّن قوة zip() في جعل الكود أقرب إلى اللغة الطبيعية: كل دورة من الحلقة تستخرج اسم الفاكهة وسعرها وكميتها معاً، ثم تنفّذ العملية المطلوبة مباشرة.
متى نستخدم zip_longest() بدلاً من zip()؟
إذا كنت تحتاج إلى الاحتفاظ بجميع العناصر حتى عند اختلاف الأطوال، فإن دالة zip() لن تكون كافية، لأنها تتوقف عند أقصر مدخل. هنا يأتي دور zip_longest() من الوحدة itertools.
أولاً، قم باستيرادها:
from itertools import zip_longestوالآن لنستخدم المثال نفسه الذي تكون فيه L2 أقصر من L1 بعنصر واحد:
L1 = [1, 2, 3, 4, 5]
L2 = ['a', 'b', 'c', 'd']
zipL_L1L2 = zip_longest(L1, L2)
print(list(zipL_L1L2))
# Output
# [(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd'), (5, None)]لاحظ أن العنصر 5 بقي موجوداً في الناتج، لكن لأنه لا يوجد عنصر مقابل له في L2، فقد استخدمت الدالة القيمة None كبديل افتراضي.
تخصيص القيمة البديلة عبر fillvalue
يمكنك استبدال None بقيمة أوضح وفقاً لاحتياجك، باستخدام الوسيط الاختياري fillvalue. هذا يفيد عند التعامل مع تقارير أو بيانات تحتاج إلى إخراج أكثر وصفاً.
from itertools import zip_longest
L1 = [1, 2, 3, 4, 5]
L2 = ['a', 'b', 'c', 'd']
result = list(zip_longest(L1, L2, fillvalue='Empty'))
print(result)
# Output
# [(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd'), (5, 'Empty')]مقارنة سريعة بين zip() وzip_longest()
| الدالة | السلوك عند اختلاف الأطوال | أفضل استخدام |
|---|---|---|
zip() |
تتوقف عند أقصر كائن قابل للتكرار | عندما تكون البيانات متوازية ويكفيك الجزء المشترك |
zip_longest() |
تحتفظ بجميع العناصر وتملأ الناقص بقيمة افتراضية | عندما تريد عدم فقدان أي عنصر من المدخلات |
أفضل الممارسات عند استخدام zip()
- استخدم
zip()عندما تكون العناصر في أكثر من قائمة مرتبطة منطقياً ببعضها. - تأكد من فهم سلوكها عند اختلاف الأطوال حتى لا تفقد بيانات دون ملاحظة.
- استخدم
zip_longest()إذا كان الاحتفاظ بجميع العناصر شرطاً أساسياً. - فضّل هذا الأسلوب على الاعتماد المفرط على الفهارس، لأن الكود يكون أوضح وأسهل في القراءة.
- عند كتابة شروحات أو أكواد تعليمية، احرص على تحويل الناتج إلى
list()إذا أردت عرض المحتوى بشكل مباشر وواضح.
الخلاصة التقنية
تُعد دالة zip() من الأدوات الأساسية التي تمنح كود Python بساطة وأناقة عند التعامل مع التكرار المتوازي. هي حل مثالي لدمج البيانات المرتبطة والتنقل بين عدة قوائم في وقت واحد دون التعرض لمشكلات الفهارس المعقدة. أما إذا كانت أطوال البيانات غير متساوية وتحتاج إلى عدم فقدان أي عنصر، فإن zip_longest() توفّر بديلاً عملياً ومرناً. من الناحية التقنية، الاختيار بين الدالتين يجب أن يعتمد على طبيعة البيانات وما إذا كان التوقف عند أقصر قائمة سلوكاً مقبولاً أم لا.