مصنف الغابات العشوائية (Random Forest Classifier): دليل شامل لاستخدام خوارزميات الشجرة في تعلم الآلة

تُعد خوارزميات الشجرة (Tree-based algorithms) من الأساليب الشائعة في تعلم الآلة، وتُستخدم بفعالية لحل مشاكل التعلم الخاضع للإشراف (supervised learning). تتميز هذه الخوارزميات بمرونتها وقدرتها على معالجة أنواع مختلفة من المشكلات، سواء كانت تصنيفية (classification) أو انحدارية (regression). عند إجراء التنبؤات على عينات التدريب في المناطق التي تنتمي إليها، تميل خوارزميات الشجرة إلى استخدام المتوسط (mean) للميزات المستمرة أو المنوال (mode) للميزات الفئوية. كما أنها تُقدم تنبؤات عالية الدقة، وتتميز بالاستقرار وسهولة التفسير، مما يجعلها أداة قيمة في ترسانة أي عالم بيانات.
أمثلة على خوارزميات الشجرة
تتنوع خوارزميات الشجرة التي يمكنك الاستفادة منها في مشاريع تعلم الآلة، ومن أبرزها:
- أشجار القرار (
Decision Trees) - الغابات العشوائية (
Random Forest) - تعزيز التدرج (
Gradient Boosting) - التجميع بالتمهيد (
Bagging - Bootstrap Aggregation)
لذا، ينبغي على كل عالم بيانات إتقان هذه الخوارزميات وتطبيقها في مشاريعه. في هذا المقال، سنتعمق في فهم خوارزمية الغابات العشوائية (Random Forest). بعد إتمام قراءتك، ستكون قادرًا على استخدام هذه الخوارزمية بكفاءة لبناء نماذج تنبؤية وحل مشاكل التصنيف باستخدام مكتبة scikit-learn.
ما هي الغابات العشوائية (Random Forest)؟
تُعد الغابات العشوائية (Random Forest) إحدى أشهر خوارزميات التعلم الخاضع للإشراف القائمة على الأشجار، والأكثر مرونة وسهولة في الاستخدام. يمكن تطبيق هذه الخوارزمية لحل كل من مشاكل التصنيف والانحدار. تعتمد الغابات العشوائية على دمج مئات من أشجار القرار، حيث يتم تدريب كل شجرة قرار على عينة مختلفة من الملاحظات. تُجرى التنبؤات النهائية للغابة العشوائية عن طريق حساب متوسط تنبؤات كل شجرة على حدة.
مزايا استخدام الغابات العشوائية
تتعدد فوائد استخدام الغابات العشوائية بشكل كبير. فبينما تميل أشجار القرار الفردية إلى فرط الملاءمة (overfitting) لبيانات التدريب، تستطيع الغابات العشوائية التخفيف من هذه المشكلة عن طريق حساب متوسط نتائج التنبؤ من الأشجار المختلفة. يمنح هذا النهج الغابات العشوائية دقة تنبؤية أعلى مقارنة بشجرة قرار واحدة.
تُساعد خوارزمية الغابات العشوائية أيضًا في تحديد الميزات الهامة في مجموعة البيانات الخاصة بك. إنها تشكل الأساس لخوارزمية Boruta، التي تُستخدم لاختيار الميزات الأساسية في مجموعة البيانات. لقد تم استخدام الغابات العشوائية في مجموعة واسعة من التطبيقات، مثل تقديم توصيات لمنتجات مختلفة للعملاء في التجارة الإلكترونية. في الطب، يمكن استخدام خوارزمية الغابات العشوائية لتحديد مرض المريض من خلال تحليل سجله الطبي. وفي القطاع المصرفي، يمكن استخدامها بسهولة لتحديد ما إذا كان العميل محتالاً أم شرعيًا.
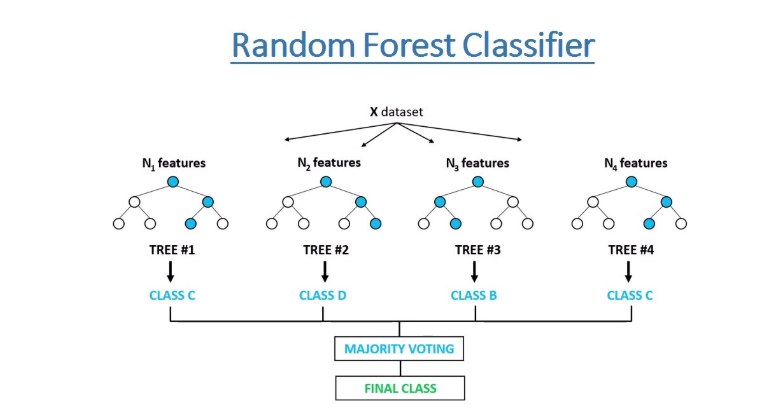
كيف تعمل خوارزمية الغابات العشوائية؟
تعمل خوارزمية الغابات العشوائية باتباع الخطوات التالية:
- الخطوة 1: تختار الخوارزمية عينات عشوائية من مجموعة البيانات المُقدمة.
- الخطوة 2: تُنشئ الخوارزمية شجرة قرار لكل عينة مختارة. ثم تحصل على نتيجة تنبؤ من كل شجرة قرار تم إنشاؤها.
- الخطوة 3: يتم بعد ذلك إجراء تصويت (
Voting) لكل نتيجة تنبؤ. بالنسبة لمشكلة التصنيف، تستخدم الخوارزمية المنوال (mode)، وبالنسبة لمشكلة الانحدار، تستخدم المتوسط (mean). - الخطوة 4: وأخيرًا، تختار الخوارزمية نتيجة التنبؤ التي حصلت على أكبر عدد من الأصوات كنتيجة تنبؤ نهائية.
تطبيق عملي للغابات العشوائية
الآن بعد أن أصبحت على دراية بآلية عمل خوارزمية الغابات العشوائية، دعنا نبني مصنف غابات عشوائية (Random Forest Classifier). سنقوم ببناء هذا المصنف باستخدام مجموعة بيانات مرض السكري لدى هنود بيما (Pima Indians Diabetes dataset). تتضمن هذه المجموعة التنبؤ بحدوث مرض السكري في غضون 5 سنوات بناءً على التفاصيل الطبية المُقدمة. هذه مشكلة تصنيف ثنائي (binary classification problem).
مهمتنا هي تحليل وإنشاء نموذج على مجموعة بيانات مرض السكري لدى هنود بيما للتنبؤ بما إذا كان مريض معين معرضًا لخطر الإصابة بالسكري، بالنظر إلى عوامل مستقلة أخرى.
1. استيراد المكتبات الأساسية
سنبدأ باستيراد الحزم الهامة التي سنستخدمها لتحميل مجموعة البيانات وإنشاء مصنف الغابات العشوائية. سنستخدم مكتبة scikit-learn لتحميل خوارزمية الغابات العشوائية واستخدامها.
# import important packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import pandas_profiling
from matplotlib import rcParams
import warnings
warnings.filterwarnings("ignore")
# figure size in inches
rcParams["figure.figsize"] = 10, 6
np.random.seed(42)2. تحميل مجموعة البيانات
الآن سنقوم بتحميل مجموعة البيانات من الدليل المحدد:
# Load dataset
data = pd.read_csv("../data/pima_indians_diabetes.csv")يمكننا الآن ملاحظة عينة من مجموعة البيانات.
# show sample of the dataset
data.sample(5)
كما ترون، تحتوي مجموعة البيانات لدينا على ميزات مختلفة ذات قيم رقمية. دعونا نفهم قائمة الميزات المتوفرة في هذه المجموعة.
# show columns
data.columns
في مجموعة البيانات هذه، توجد 8 ميزات إدخال (input features) وميزة إخراج/هدف واحدة (output / target feature). يُعتقد أن القيم المفقودة مُشفرة بقيم صفرية. فيما يلي معنى أسماء المتغيرات (من الميزة الأولى إلى الأخيرة):
Number of times pregnant: عدد مرات الحمل.Plasma glucose concentration a 2 hours in an oral glucose tolerance test: تركيز جلوكوز البلازما بعد ساعتين في اختبار تحمل الجلوكوز الفموي.Diastolic blood pressure (mm Hg): ضغط الدم الانبساطي (مم زئبق).Triceps skinfold thickness (mm): سُمك طية الجلد ثلاثية الرؤوس (مم).2-hour serum insulin (mu U/ml): الأنسولين في مصل الدم بعد ساعتين (وحدة دولية/مل).Body mass index (weight in kg/(height in m)^2): مؤشر كتلة الجسم (الوزن بالكيلوجرام / (الطول بالمتر)^2).Diabetes pedigree function: دالة نسب السكري.Age (years): العمر (بالسنوات).Class variable (0 or 1): متغير الفئة (0 أو 1)، حيث 1 يعني الإصابة بالسكري و 0 يعني عدم الإصابة.
ثم نقوم بتقسيم مجموعة البيانات إلى ميزات مستقلة (independent features) وميزة هدف (target feature). ميزة الهدف لدينا لهذه المجموعة تسمى class.
# split data into input and target variable(s)
X = data.drop("class", axis=1)
y = data["class"]3. المعالجة المسبقة لمجموعة البيانات
قبل إنشاء النموذج، نحتاج إلى توحيد (standardize) ميزاتنا المستقلة باستخدام طريقة StandardScaler من مكتبة scikit-learn.
# standardize the dataset
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)يمكنك معرفة المزيد عن كيفية ولماذا يتم توحيد بياناتك من خلال مقالات متخصصة في هذا المجال.
4. تقسيم مجموعة البيانات إلى بيانات تدريب واختبار
الآن نقوم بتقسيم مجموعة البيانات المعالجة لدينا إلى بيانات تدريب واختبار. ستشكل بيانات الاختبار 10% من إجمالي مجموعة البيانات المعالجة.
# split into train and test set
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, stratify=y, test_size=0.10, random_state=42
)5. بناء مصنف الغابات العشوائية
حان الوقت الآن لإنشاء مصنف الغابات العشوائية الخاص بنا ثم تدريبه على مجموعة التدريب. سنقوم أيضًا بتمرير عدد الأشجار (100) في الغابة التي نريد استخدامها عبر المعلمة المسماة n_estimators.
# create the classifier
classifier = RandomForestClassifier(n_estimators=100)
# Train the model using the training sets
classifier.fit(X_train, y_train)
يُظهر الإخراج أعلاه قيم المعلمات المختلفة لمصنف الغابات العشوائية المستخدمة أثناء عملية التدريب على بيانات التدريب. بعد التدريب، يمكننا إجراء التنبؤ على بيانات الاختبار.
# prediction on the test set
y_pred = classifier.predict(X_test)ثم نتحقق من الدقة باستخدام القيم الفعلية والمتوقعة من بيانات الاختبار.
# Calculate Model Accuracy
print("Accuracy:", accuracy_score(y_test, y_pred))Accuracy: 0.8051948051948052تبلغ دقة نموذجنا حوالي 80.5%، وهو أمر جيد. ولكن يمكننا دائمًا تحسينها.
6. تحديد الميزات الهامة
كما ذكرت سابقًا، يمكننا أيضًا التحقق من الميزات الهامة باستخدام متغير feature_importances_ من خوارزمية الغابات العشوائية في scikit-learn.
# check Important features
feature_importances_df = pd.DataFrame(
{"feature": list(X.columns), "importance": classifier.feature_importances_}
).sort_values("importance", ascending=False)
# Display feature_importances_df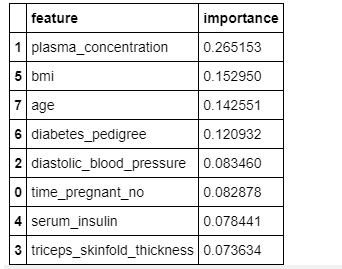
يُظهر الشكل أعلاه الأهمية النسبية للميزات ومساهمتها في النموذج. يمكننا أيضًا تصور هذه الميزات ودرجاتها باستخدام مكتبتي seaborn و matplotlib.
# visualize important features
# Creating a bar plot
sns.barplot(x=feature_importances_df.feature, y=feature_importances_df.importance)
# Add labels to your plot
plt.xlabel("Feature Importance Score")
plt.ylabel("Features")
plt.title("Visualizing Important Features")
plt.xticks(rotation=45, horizontalalignment="right", fontweight="light", fontsize="x-large")
plt.show()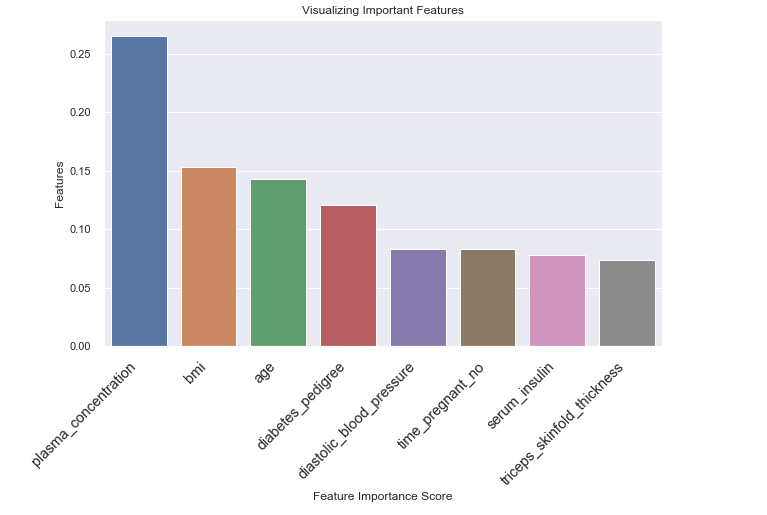
من الشكل أعلاه، يمكنك أن ترى أن ميزة triceps_skinfold_thickness ذات أهمية منخفضة ولا تساهم كثيرًا في التنبؤ. هذا يعني أنه يمكننا إزالة هذه الميزة وتدريب مصنف الغابات العشوائية الخاص بنا مرة أخرى، ثم معرفة ما إذا كان يمكنه تحسين أدائه على بيانات الاختبار.
# load data with selected features
X = data.drop(["class", "triceps_skinfold_thickness"], axis=1)
y = data["class"]
# standardize the dataset
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# split into train and test set
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, stratify=y, test_size=0.10, random_state=42
)سنقوم بتدريب خوارزمية الغابات العشوائية باستخدام الميزات المعالجة المختارة من مجموعة البيانات الخاصة بنا، وإجراء التنبؤات، ثم إيجاد دقة النموذج.
# Create a Random Classifier
clf = RandomForestClassifier(n_estimators=100)
# Train the model using the training sets
clf.fit(X_train, y_train)
# prediction on test set
y_pred = clf.predict(X_test)
# Calculate Model Accuracy
print("Accuracy:", accuracy_score(y_test, y_pred))Accuracy: 0.8181818181818182الآن، زادت دقة النموذج من 80.5% إلى 81.8% بعد أن أزلنا الميزة الأقل أهمية المسماة triceps_skinfold_thickness. يشير هذا إلى أنه من المهم جدًا التحقق من الميزات الهامة ومعرفة ما إذا كان يمكنك إزالة الميزات الأقل أهمية لزيادة أداء نموذجك.
الخلاصة التقنية
تُعد خوارزميات الشجرة، وبخاصة الغابات العشوائية (Random Forest)، أدوات لا غنى عنها في مجال تعلم الآلة، حيث توفر توازنًا ممتازًا بين الدقة، الاستقرار، وسهولة التفسير. لقد أظهر هذا الدليل العملي كيف يمكن لهذه الخوارزمية معالجة مشكلة تصنيف معقدة مثل التنبؤ بالسكري، مع تسليط الضوء على قدرتها الفائقة في التعامل مع فرط الملاءمة (overfitting) وتحديد أهمية الميزات. إن القدرة على تحليل أهمية الميزات وتعديل مجموعة البيانات بناءً على هذا التحليل، كما رأينا في تحسين الدقة بعد إزالة ميزة triceps_skinfold_thickness، تُبرهن على القيمة العملية لهذه الخوارزمية في بناء نماذج تنبؤية أكثر كفاءة وقابلية للتفسير. يُنصح دائمًا باستكشاف خوارزميات شجرية أخرى مثل Extra-trees algorithm لتعميق الفهم وتوسيع نطاق التطبيق.