كيفية إعداد البحث الجغرافي في تطبيقك باستخدام Elasticsearch
أصبحت الميزات المعتمدة على الموقع جزءاً أساسياً في كثير من التطبيقات الحديثة، سواء في خدمات التوصيل أو الخرائط أو اقتراح الأماكن القريبة من المستخدم. ورغم أن تنفيذ البحث الجغرافي قد يبدو معقداً في البداية، فإن Elasticsearch يوفّر أدوات جاهزة تجعل هذه المهمة مباشرة ومرنة.
في هذا الدليل سنبني مثالاً عملياً للبحث عن المدن اعتماداً على الإحداثيات الجغرافية، ثم ننتقل إلى تحسين النتائج بحيث لا تقتصر على التصفية فقط، بل تُرتَّب أيضاً بحسب الأقرب إلى المستخدم.

ما هو Elasticsearch ولماذا يناسب البحث الجغرافي؟
يُعد Elasticsearch قاعدة بيانات من نوع NoSQL تعتمد على المستندات documents، ويُستخدم على نطاق واسع كمحرّك بحث قوي وقابل للتوسع. ومن أبرز مزاياه أنه يدعم نوع البيانات الجغرافية geo_point، ما يسمح لك بتخزين خطوط الطول والعرض والاستعلام عنها بكفاءة عالية.
هذا يعني أنك لست مضطراً إلى بناء منطق حساب المسافات من الصفر، لأن Elasticsearch يتكفّل بجزء كبير من العمل، سواء عند البحث داخل نطاق معين أو عند ترتيب النتائج وفق القرب.
تثبيت Elasticsearch وتشغيله
يمكنك اتباع دليل التثبيت الرسمي من موقع Elasticsearch. في هذا الشرح نعتمد على إصدار 7.4.2، ومن المهم الانتباه إلى أن بعض السلوكيات قد تختلف بين الإصدارات، خصوصاً بعد إزالة mapping types في الإصدارات الأحدث.
بعد اكتمال التثبيت، شغّل الخدمة محلياً. في بيئات Linux يكون التشغيل عادة عبر الأمر التالي:
./bin/elasticsearchوللتأكد من أن الخدمة تعمل بشكل صحيح، أرسل طلب GET إلى المنفذ 9200 على جهازك المحلي:
GET http://localhost:9200إذا عاد لك رد من الخادم، فهذا يعني أن Elasticsearch جاهز لاستقبال الفهارس والبيانات.
إنشاء فهرس للمدن في Elasticsearch
الفهرس index في Elasticsearch يشبه الجدول في قواعد البيانات التقليدية. سننشئ فهرساً باسم cities لتخزين بيانات المدن، وسنعتمد بنية بسيطة وواضحة:
id: معرّف من النوعkeyword.name: اسم المدينة من النوعtext.coordinate: إحداثيات المدينة من النوعgeo_point.
إنشاء الفهرس يتم عبر طلب PUT كما يلي:
PUT http://localhost:9200/cities
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text"
},
"coordinate": {
"type": "geo_point"
}
}
}
}إذا تم إنشاء الفهرس بنجاح، فسيكون الرد مشابهاً للتالي:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "cities"
}هذه الخطوة مهمة لأنها تحدد شكل البيانات منذ البداية وتضمن أن الحقل coordinate سيُفهم على أنه حقل جغرافي فعلي، وليس مجرد كائن عادي.
ملخص أنواع الحقول المستخدمة
| الحقل | النوع | الوظيفة |
|---|---|---|
id |
keyword |
تخزين المعرّف كما هو دون تحليل نصي |
name |
text |
تخزين اسم المدينة وإتاحة البحث النصي عليه |
coordinate |
geo_point |
تخزين خطوط العرض والطول لاستخدامها في الاستعلامات الجغرافية |
إدخال بيانات المدن باستخدام Bulk API
بعد إنشاء الفهرس، نحتاج إلى إدخال البيانات. في Elasticsearch يُطلق على السجل اسم document، وهو قريب في المفهوم من الصف في قواعد بيانات SQL.
وبما أننا سنضيف عدة مدن دفعة واحدة، فمن الأفضل استخدام واجهة Bulk API لأنها أسرع وأكثر عملية من إرسال طلب مستقل لكل سجل.
POST http://localhost:9200/cities/_bulk
{ "index": { "_index": "cities" } }
{ "id": 1, "name": "Jakarta", "coordinate": { "lat": -6.2008, "lon": 106.8456 } }
{ "index": { "_index": "cities" } }
{ "id": 2, "name": "Tokyo", "coordinate": { "lat": 35.6762, "lon": 139.6503 } }
{ "index": { "_index": "cities" } }
{ "id": 3, "name": "Hong Kong", "coordinate": { "lat": 22.3193, "lon": 114.1694 } }
{ "index": { "_index": "cities" } }
{ "id": 4, "name": "New York", "coordinate": { "lat": 40.7128, "lon": -74.0060 } }
{ "index": { "_index": "cities" } }
{ "id": 5, "name": "Paris", "coordinate": { "lat": 48.8566, "lon": 2.3522 } }
{ "index": { "_index": "cities" } }
{ "id": 6, "name": "Bali", "coordinate": { "lat": -8.3405, "lon": 115.0920 } }
{ "index": { "_index": "cities" } }
{ "id": 7, "name": "Berlin", "coordinate": { "lat": 52.5200, "lon": 13.4050 } }
{ "index": { "_index": "cities" } }
{ "id": 8, "name": "San Francisco", "coordinate": { "lat": 37.7749, "lon": -122.4194 } }
{ "index": { "_index": "cities" } }
{ "id": 9, "name": "Beijing", "coordinate": { "lat": 39.9042, "lon": 116.4074 } }قد يبدو هذا التنسيق غريباً لأنه ليس JSON تقليدياً بالكامل، لكن هذا طبيعي في Bulk API. فهو يعتمد على أسطر متتابعة تمثل أوامر الإدخال متبوعة بالبيانات نفسها.
الاستجابة الناجحة تكون مشابهة لما يلي:
{
"took": 72,
"errors": false,
"items": [
...
]
}القيمة false داخل errors تعني أن عملية الإدخال تمت بنجاح دون أخطاء على مستوى السجلات.
تنفيذ بحث جغرافي حسب المسافة

الآن نصل إلى الجزء الأهم: الاستعلام عن المدن المخزنة بالاعتماد على الموقع. يوفّر Elasticsearch استعلاماً جاهزاً باسم geo_distance يتيح لك البحث عن السجلات الموجودة داخل دائرة نصف قطرها محدد حول نقطة معينة.
إذا أردنا مثلاً البحث عن المدن ضمن مسافة 10km من إحداثيات قريبة من مدينة San Francisco، فسيكون الاستعلام على النحو التالي:
POST http://localhost:9200/cities/_search
{
"query": {
"bool": {
"filter": {
"geo_distance": {
"distance": "10km",
"coordinate": {
"lat": 37.76,
"lon": -122.42
}
}
}
}
}
}النتيجة المتوقعة هنا هي مدينة San Francisco فقط، لأن إحداثياتها تقع داخل هذا النطاق الصغير.
{
"took": 7,
"timed_out": false,
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.0,
"hits": [
{
"_index": "cities",
"_score": 0.0,
"_source": {
"id": 8,
"name": "San Francisco",
"coordinate": {
"lat": 37.7749,
"lon": -122.4194
}
}
}
]
}
}هذا النوع من الاستعلامات مثالي عندما تريد فقط معرفة ما إذا كانت المدينة أو الفرع أو المستخدم يقع ضمن نطاق جغرافي محدد.
توسيع نطاق البحث للحصول على نتائج أكثر
إذا قمنا بتوسيع المسافة إلى 4500km، فسنحصل على عدد أكبر من النتائج:
{
"query": {
"bool": {
"filter": {
"geo_distance": {
"distance": "4500km",
"coordinate": {
"lat": 37.76,
"lon": -122.42
}
}
}
}
}
}في هذه الحالة قد تظهر مدينتان مثل San Francisco وNew York. وهذا منطقي من ناحية التصفية، لأن كلتيهما تقعان داخل المدى المحدد.
لكن توجد ملاحظة مهمة: هذا الاستعلام يقوم بعملية filter فقط، أي إنه يقرر من يدخل ضمن النتائج ومن يُستبعد، من دون أن يهتم بترتيب الأقرب فالأبعد بشكل ذكي. لذلك قد لا تظهر النتائج بالترتيب الذي يتوقعه المستخدم.
ترتيب النتائج حسب القرب باستخدام function_score
إذا كان هدفك هو عرض أقرب الأماكن أولاً، فالتصفية وحدها لا تكفي. هنا يظهر دور استعلام function_score، والذي يسمح بتعديل درجة السجل score اعتماداً على قواعد إضافية، مثل المسافة عن نقطة معينة.
ومن بين الدوال المتاحة لهذا الغرض توجد دوال الانحدار decay functions مثل:
explineargauss
كل دالة تمنح تناقصاً مختلفاً في درجة النتائج كلما ابتعدت عن نقطة الأصل. ولتبسيط الفكرة سنستخدم هنا الدالة linear.
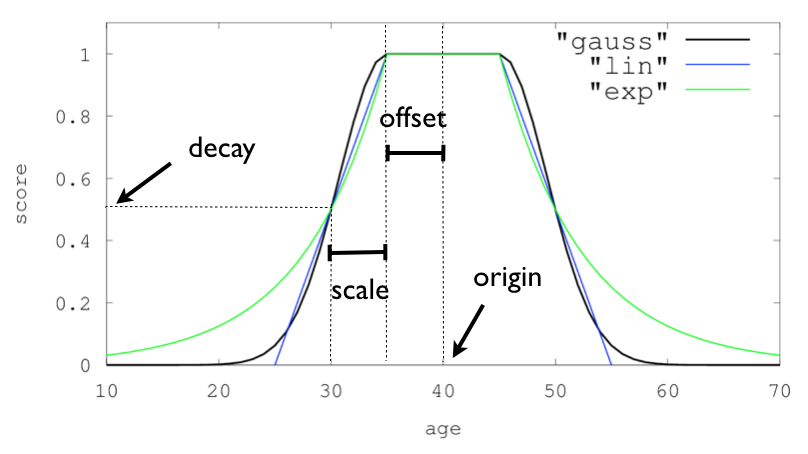
مثال عملي على ترتيب المدن الأقرب
POST http://localhost:9200/cities/_search
{
"query": {
"function_score": {
"functions": [
{
"linear": {
"coordinate": {
"origin": "37, -122",
"offset": "100km",
"scale": "2500km"
}
}
}
],
"min_score": 0.1
}
}
}في هذا الاستعلام:
originتمثل النقطة المرجعية التي نقيس منها القرب.offsetتحدد مسافة آمنة لا ينخفض داخلها التقييم بشكل كبير.scaleتحدد المعدل الذي تتراجع به الدرجة مع الابتعاد.min_scoreتمنع ظهور نتائج ضعيفة الصلة.
النتيجة هنا ستكون مرتبة بحسب أعلى score، أي إن المدينة الأقرب إلى الإحداثيات المرجعية ستظهر أولاً.
{
"took": 32,
"timed_out": false,
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "cities",
"_score": 1.0,
"_source": {
"id": 8,
"name": "San Francisco",
"coordinate": {
"lat": 37.7749,
"lon": -122.4194
}
}
},
{
"_index": "cities",
"_score": 0.19508117,
"_source": {
"id": 4,
"name": "New York",
"coordinate": {
"lat": 40.7128,
"lon": -74.0060
}
}
}
]
}
}بهذا الشكل تظهر San Francisco أولاً لأنها الأقرب فعلياً إلى نقطة الأصل، بينما تأتي New York بعدها بدرجة أقل.
متى تستخدم التصفية فقط ومتى تستخدم الترتيب الذكي؟
| الحالة | الاستعلام الأنسب | السبب |
|---|---|---|
| إظهار الفروع داخل نطاق محدد | geo_distance |
يكفي لاستبعاد النتائج البعيدة بسرعة |
| اقتراح أقرب المدن أو المتاجر | function_score |
يساعد على ترتيب النتائج حسب القرب والأولوية |
| البحث المحلي مع صلة نصية وجغرافية معاً | bool مع function_score |
يجمع بين المطابقة النصية والمسافة |
نصائح عملية لتحسين البحث الجغرافي في التطبيقات
- استخدم الحقل
geo_pointمنذ البداية ولا تخزن الإحداثيات كنص عادي. - افصل بين منطق التصفية ومنطق الترتيب حتى تتمكن من ضبط تجربة المستخدم بدقة.
- اختبر القيم الخاصة بـ
offsetوscaleوفق طبيعة تطبيقك، لأن القيم المثالية تختلف بين تطبيق محلي صغير وتطبيق يغطي قارات متعددة. - إذا كنت تجمع بين البحث النصي والموقع، فاحرص على موازنة
scoreحتى لا تطغى المسافة على جودة المطابقة النصية أو العكس. - راجع إصدار
Elasticsearchالمستخدم لديك، لأن بعض الأمثلة القديمة قد تحتاج إلى تعديلات بسيطة لتتوافق مع الإصدارات الحديثة.
الخلاصة التقنية
يوفّر Elasticsearch نقطة انطلاق ممتازة لبناء بحث جغرافي سريع وقابل للتوسع داخل التطبيقات. تبدأ العملية بتعريف حقل geo_point بشكل صحيح، ثم استخدام geo_distance للتصفية، وأخيراً تحسين الترتيب عبر function_score عندما تكون أولوية القرب مهمة للمستخدم. من الناحية العملية، القوة الحقيقية لا تكمن في مجرد إظهار النتائج القريبة، بل في تقديمها بترتيب منطقي يخدم تجربة الاستخدام ويزيد من دقة التوصيات داخل التطبيق.