خوارزمية آلة المتجهات الداعمة (SVM): دليل شامل لتعلم الآلة مع أمثلة برمجية

في عالم اليوم الذي يتسارع فيه الابتكار التقني، أصبحت مهام تعلم الآلة جزءًا لا يتجزأ من حياتنا اليومية. من تصنيف الصور وترجمة اللغات إلى معالجة كميات هائلة من البيانات من أجهزة الاستشعار والتنبؤ بالقيم المستقبلية بناءً على البيانات الحالية، تتعدد تطبيقات تعلم الآلة وتتنوع. لحسن الحظ، هناك خوارزميات مصممة للتعامل مع مختلف أنواع البيانات والمشكلات التي قد تواجهها.
من بين هذه الخوارزميات، تبرز آلة المتجهات الداعمة (SVM) كأداة قوية ومتعددة الاستخدامات. لكن قبل الغوص في تفاصيلها، دعنا نراجع مفهومين أساسيين في تعلم الآلة: التعلم الخاضع للإشراف والتعلم غير الخاضع للإشراف.
التعلم الخاضع للإشراف مقابل التعلم غير الخاضع للإشراف
يُعد التعلم الخاضع للإشراف (Supervised Learning) والتعلم غير الخاضع للإشراف (Unsupervised Learning) من أكثر استراتيجيات تعلم الآلة شيوعًا واستخدامًا.
ما هو التعلم الخاضع للإشراف؟
يحدث التعلم الخاضع للإشراف عندما تقوم بتدريب نموذج تعلم آلة باستخدام بيانات مُصنفة (labelled data). هذا يعني أن لديك بيانات تحتوي بالفعل على التصنيف الصحيح المرتبط بها. أحد الاستخدامات الشائعة للتعلم الخاضع للإشراف هو التنبؤ بالقيم للبيانات الجديدة. مع هذا النوع من التعلم، ستحتاج إلى إعادة بناء نماذجك كلما حصلت على بيانات جديدة لضمان دقة التنبؤات. على سبيل المثال، يمكن استخدام التعلم الخاضع للإشراف لتصنيف صور الأطعمة؛ حيث يمكن أن يكون لديك مجموعة بيانات مخصصة لصور البيتزا فقط لتعليم النموذج ما هي البيتزا.
ما هو التعلم غير الخاضع للإشراف؟
على النقيض، يتم التعلم غير الخاضع للإشراف عندما تقوم بتدريب نموذج ببيانات غير مُصنفة (unlabeled data). هذا يعني أن النموذج سيتعين عليه إيجاد ميزاته الخاصة به وتقديم تنبؤات بناءً على كيفية تصنيف البيانات. مثال على ذلك هو تزويد النموذج بصور لأنواع متعددة من الأطعمة بدون تسميات. قد تحتوي مجموعة البيانات على صور للبيتزا والبطاطس المقلية وأطعمة أخرى، ويمكنك استخدام خوارزميات مختلفة لجعل النموذج يحدد صور البيتزا فقط دون أي تسميات مسبقة.
ما هي الخوارزمية؟
عندما تسمع الناس يتحدثون عن خوارزميات تعلم الآلة، تذكر أنهم يشيرون إلى معادلات رياضية مختلفة. الخوارزمية هي ببساطة دالة رياضية قابلة للتخصيص. لهذا السبب تحتوي معظم الخوارزميات على عناصر مثل دوال التكلفة (cost functions)، وقيم الأوزان (weight values)، ودوال المعلمات (parameter functions) التي يمكنك تبديلها بناءً على البيانات التي تعمل بها. في جوهرها، تعلم الآلة هو مجرد مجموعة من المعادلات الرياضية التي تحتاج إلى حلها بسرعة فائقة. لهذا السبب توجد العديد من الخوارزميات المختلفة للتعامل مع أنواع مختلفة من البيانات. إحدى هذه الخوارزميات هي آلة المتجهات الداعمة (Support Vector Machine)، وهذا ما سيتناوله هذا المقال بالتفصيل.
ما هي آلة المتجهات الداعمة (SVM)؟
آلات المتجهات الداعمة (SVMs) هي مجموعة من طرق التعلم الخاضع للإشراف (supervised learning methods) المستخدمة للتصنيف (classification)، والانحدار (regression)، واكتشاف القيم الشاذة (outliers detection). هذه كلها مهام شائعة في تعلم الآلة. يمكنك استخدامها لاكتشاف الخلايا السرطانية بناءً على ملايين الصور، أو يمكنك استخدامها للتنبؤ بمسارات القيادة المستقبلية باستخدام نموذج انحدار مُعد بشكل جيد. توجد أنواع محددة من SVMs يمكنك استخدامها لمشكلات تعلم آلة معينة، مثل انحدار المتجهات الداعمة (Support Vector Regression - SVR) الذي يعد امتدادًا لتصنيف المتجهات الداعمة (Support Vector Classification - SVC).
الشيء الرئيسي الذي يجب تذكره هنا هو أن هذه مجرد معادلات رياضية مُعدلة لتعطيك الإجابة الأكثر دقة ممكنة بأسرع وقت ممكن. تختلف SVMs عن خوارزميات التصنيف الأخرى بسبب الطريقة التي تختار بها حد القرار (decision boundary) الذي يزيد المسافة إلى أقصى حد من أقرب نقاط البيانات لجميع الفئات. يُطلق على حد القرار الذي تنشئه SVMs اسم مصنف الهامش الأقصى (maximum margin classifier) أو مستوى الهامش الأقصى الفائق (maximum margin hyperplane).
كيف تعمل خوارزمية SVM؟
يعمل مصنف SVM الخطي البسيط عن طريق إنشاء خط مستقيم بين فئتين. هذا يعني أن جميع نقاط البيانات على جانب واحد من الخط ستمثل فئة، ونقاط البيانات على الجانب الآخر من الخط ستوضع في فئة مختلفة. هذا يعني أنه يمكن أن يكون هناك عدد لا نهائي من الخطوط للاختيار من بينها. ما يجعل خوارزمية SVM الخطية أفضل من بعض الخوارزميات الأخرى، مثل أقرب الجيران (k-nearest neighbors)، هو أنها تختار أفضل خط لتصنيف نقاط البيانات الخاصة بك. إنها تختار الخط الذي يفصل البيانات ويكون أبعد ما يمكن عن أقرب نقاط البيانات.
يساعد مثال ثنائي الأبعاد (2-D) على فهم المصطلحات المعقدة لتعلم الآلة. بشكل أساسي، لديك بعض نقاط البيانات على شبكة. أنت تحاول فصل هذه النقاط حسب الفئة التي يجب أن تنتمي إليها، ولكنك لا تريد أن تكون هناك أي بيانات في الفئة الخاطئة. هذا يعني أنك تحاول إيجاد الخط الفاصل بين أقرب نقطتين يحافظ على فصل نقاط البيانات الأخرى. وبالتالي، فإن أقرب نقطتين للبيانات تمنحك المتجهات الداعمة (support vectors) التي ستستخدمها لإيجاد هذا الخط. يُطلق على هذا الخط اسم حد القرار (decision boundary).
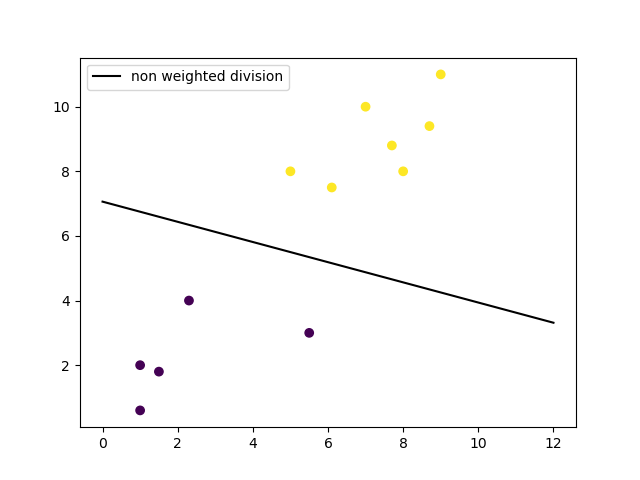
لا يجب أن يكون حد القرار خطًا مستقيمًا بالضرورة. يُشار إليه أيضًا باسم المستوى الفائق (hyperplane) لأنه يمكنك العثور على حد القرار باستخدام أي عدد من الميزات (features)، وليس فقط اثنتين، مما يجعله أكثر مرونة للبيانات المعقدة.
أنواع آلات المتجهات الداعمة (SVMs)
هناك نوعان مختلفان من SVMs، يُستخدم كل منهما لأغراض مختلفة:
Simple SVM(آلة المتجهات الداعمة البسيطة): تُستخدم عادةً لمشكلات الانحدار الخطي (linear regression) والتصنيف الخطي (linear classification).Kernel SVM(آلة المتجهات الداعمة ذات النواة): تتمتع بمرونة أكبر للبيانات غير الخطية (non-linear data) لأنه يمكنك إضافة المزيد من الميزات لتناسب مستوى فائقًا (hyperplane) بدلاً من مساحة ثنائية الأبعاد (two-dimensional space).
لماذا تُستخدم SVMs في تعلم الآلة؟
تُستخدم SVMs في تطبيقات متعددة مثل التعرف على خط اليد، واكتشاف التسلل، واكتشاف الوجوه، وتصنيف رسائل البريد الإلكتروني، وتصنيف الجينات، وفي صفحات الويب. هذا أحد الأسباب الرئيسية لاستخدام SVMs في تعلم الآلة؛ فهي تستطيع التعامل مع كل من التصنيف والانحدار على البيانات الخطية وغير الخطية.
سبب آخر لاستخدام SVMs هو قدرتها على إيجاد علاقات معقدة بين بياناتك دون الحاجة إلى إجراء الكثير من التحويلات بنفسك. إنها خيار ممتاز عندما تعمل مع مجموعات بيانات أصغر تحتوي على عشرات إلى مئات الآلاف من الميزات. عادةً ما تحقق SVMs نتائج أكثر دقة مقارنة بالخوارزميات الأخرى نظرًا لقدرتها على التعامل مع مجموعات البيانات الصغيرة والمعقدة.
إيجابيات وسلبيات استخدام SVMs
فيما يلي بعض الإيجابيات والسلبيات لاستخدام SVMs:
- الإيجابيات:
- فعالة على مجموعات البيانات ذات الميزات المتعددة، مثل البيانات المالية أو الطبية.
- فعالة في الحالات التي يكون فيها عدد الميزات أكبر من عدد نقاط البيانات.
- تستخدم مجموعة فرعية من نقاط التدريب في دالة القرار تسمى المتجهات الداعمة (
support vectors)، مما يجعلها فعالة من حيث استهلاك الذاكرة. - يمكن تحديد دوال نواة مختلفة لدالة القرار. يمكنك استخدام النوى الشائعة، ولكن من الممكن أيضًا تحديد نوى مخصصة.
- السلبيات:
- إذا كان عدد الميزات أكبر بكثير من عدد نقاط البيانات، فإن تجنب الإفراط في التخصيص (
over-fitting) عند اختيار دوال النواة ومصطلح التنظيم (regularization term) أمر بالغ الأهمية. - لا توفر
SVMsتقديرات احتمالية مباشرة. تُحسب هذه التقديرات باستخدام عملية تحقق متقاطع خماسية الطيات (five-fold cross-validation) مكلفة. - تعمل بشكل أفضل على مجموعات العينات الصغيرة بسبب وقت تدريبها الطويل.
- إذا كان عدد الميزات أكبر بكثير من عدد نقاط البيانات، فإن تجنب الإفراط في التخصيص (
دوال النواة (Kernel Functions)
نظرًا لأن SVMs يمكنها استخدام أي عدد من النوى، فمن المهم أن تعرف عن بعضها.
النواة الخطية (Linear Kernel)
يُوصى بها عادةً لتصنيف النصوص لأن معظم مشكلات التصنيف من هذا النوع قابلة للفصل خطيًا (linearly separable). تعمل النواة الخطية (linear kernel) بشكل جيد جدًا عندما يكون هناك الكثير من الميزات، ومشكلات تصنيف النصوص تحتوي على الكثير من الميزات. دوال النواة الخطية أسرع من معظم النوى الأخرى ولديك عدد أقل من المعلمات لتحسينها.
إليك الدالة التي تحدد النواة الخطية:
f(X) = w^T * X + bفي هذه المعادلة، w هو متجه الوزن (weight vector) الذي تريد تقليله، X هي البيانات التي تحاول تصنيفها، و b هو المعامل الخطي (linear coefficient) المقدر من بيانات التدريب. تحدد هذه المعادلة حد القرار (decision boundary) الذي تُرجعه SVM.
النواة متعددة الحدود (Polynomial Kernel)
لا تُستخدم النواة متعددة الحدود (polynomial kernel) في الممارسة كثيرًا لأنها ليست فعالة حسابيًا مثل النوى الأخرى وتنبؤاتها ليست دقيقة بنفس القدر.
إليك الدالة للنواة متعددة الحدود:
f(X1, X2) = (a + X1^T * X2) ^ bهذه إحدى أبسط معادلات النواة متعددة الحدود التي يمكنك استخدامها. يمثل f(X1, X2) حد القرار متعدد الحدود الذي سيفصل بياناتك. يمثل X1 و X2 بياناتك.
دالة الأساس الشعاعي الغاوسية (Gaussian Radial Basis Function – RBF)
تُعد دالة الأساس الشعاعي الغاوسية (RBF) واحدة من أقوى النوى وأكثرها شيوعًا في SVMs. عادةً ما تكون الخيار المفضل للبيانات غير الخطية (non-linear data).
إليك معادلة نواة RBF:
f(X1, X2) = exp(-gamma * ||X1 - X2||^ 2 )في هذه المعادلة، تحدد gamma مدى تأثير نقطة تدريب واحدة على نقاط البيانات الأخرى من حولها. ||X1 - X2|| هو حاصل الضرب النقطي (dot product) بين ميزاتك.
النواة السينيّة (Sigmoid Kernel)
تُعد النواة السينيّة (sigmoid kernel) أكثر فائدة في الشبكات العصبية (neural networks) منها في آلات المتجهات الداعمة، ولكن هناك حالات استخدام محددة عرضية.
إليك الدالة للنواة السينيّة:
f(X, y) = tanh(alpha * X^T * y + C)في هذه الدالة، alpha هو متجه وزن (weight vector) و C هي قيمة إزاحة (offset value) لمراعاة بعض الأخطاء في تصنيف البيانات التي قد تحدث.
نوى أخرى
هناك الكثير من النوى الأخرى التي يمكنك استخدامها لمشروعك. قد يكون هذا قرارًا يتعين عليك اتخاذه عندما تحتاج إلى تلبية قيود معينة على الأخطاء، أو ترغب في محاولة تسريع وقت التدريب، أو تريد ضبط المعلمات بدقة فائقة. تشمل بعض النوى الأخرى: دالة الأساس الشعاعي ANOVA، الظل الزائدي (hyperbolic tangent)، و Laplace RBF.
الآن بعد أن عرفت القليل عن كيفية عمل النوى داخليًا، دعنا ننتقل إلى بعض الأمثلة العملية.
أمثلة عملية مع مجموعات البيانات
لإظهار كيفية عمل SVMs عمليًا، سنتناول عملية تدريب نموذج باستخدام مكتبة Scikit-learn في بايثون. تُستخدم هذه المكتبة بشكل شائع في جميع أنواع مشكلات تعلم الآلة وتعمل بشكل جيد مع مكتبات بايثون الأخرى.
فيما يلي الخطوات التي تُتبع عادةً في مشاريع تعلم الآلة:
- استيراد مجموعة البيانات.
- استكشاف البيانات لمعرفة شكلها.
- معالجة البيانات الأولية (
Pre-process the data). - تقسيم البيانات إلى سمات (
attributes) وتصنيفات (labels). - تقسيم البيانات إلى مجموعات تدريب (
training sets) واختبار (testing sets). - تدريب خوارزمية
SVM. - إجراء بعض التنبؤات.
- تقييم نتائج الخوارزمية.
يمكن دمج بعض هذه الخطوات اعتمادًا على كيفية معالجتك لبياناتك. سنقدم مثالًا باستخدام SVM خطي وآخر باستخدام SVM غير خطي.
مثال على SVM الخطي (Linear SVM)
سنبدأ باستيراد بعض المكتبات التي ستسهل العمل مع معظم مشاريع تعلم الآلة.
import matplotlib.pyplot as plt
import numpy as np
from sklearn import svmللحصول على مثال خطي بسيط، سنقوم بإنشاء بعض البيانات الوهمية (dummy data) التي ستحل محل استيراد مجموعة بيانات حقيقية.
# linear data
X = np.array([1, 5, 1.5, 8, 1, 9, 7, 8.7, 2.3, 5.5, 7.7, 6.1])
y = np.array([2, 8, 1.8, 8, 0.6, 11, 10, 9.4, 4, 3, 8.8, 7.5])السبب في أننا نعمل مع مصفوفات numpy هو تسريع عمليات المصفوفات لأنها تستخدم ذاكرة أقل من قوائم بايثون (Python lists). يمكنك أيضًا الاستفادة من تحديد أنواع محتويات المصفوفات.
الآن دعنا نلقي نظرة على شكل البيانات في رسم بياني:
# show unclassified data
plt.scatter(X, y)
plt.show()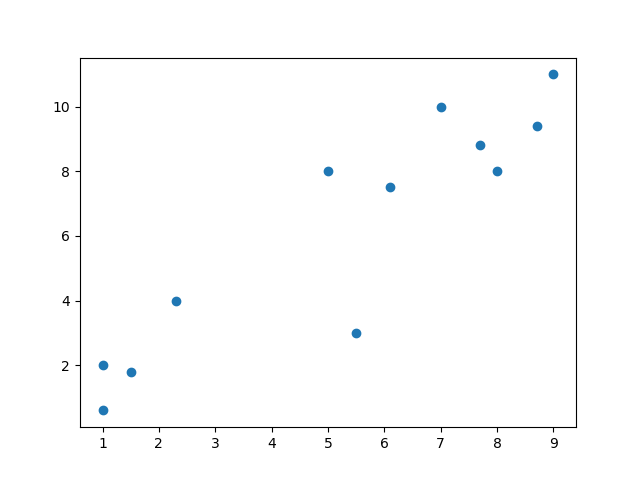
بمجرد أن ترى كيف تبدو البيانات، يمكنك تخمين أفضل للخوارزمية التي ستعمل بشكل أفضل لك. تذكر أن هذه مجموعة بيانات بسيطة جدًا، لذلك في معظم الأحيان ستحتاج إلى بعض العمل على بياناتك لجعلها في حالة قابلة للاستخدام.
سنقوم ببعض المعالجة الأولية على الكود المنظم بالفعل. سيضع هذا البيانات الخام في تنسيق يمكننا استخدامه لتدريب نموذج SVM.
# shaping data for training the model
training_X = np.vstack((X, y)).T
training_y = [0, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1]الآن يمكننا إنشاء نموذج SVM باستخدام نواة خطية (linear kernel).
# define the model
clf = svm.SVC(kernel='linear', C=1.0)هذا السطر الواحد من الكود أنشأ نموذج تعلم آلة كاملاً. الآن علينا فقط تدريبه باستخدام البيانات التي قمنا بمعالجتها مسبقًا.
# train the model
clf.fit(training_X, training_y)هذه هي الطريقة التي يمكنك بها بناء نموذج لأي مشروع تعلم آلة. قد تكون مجموعة البيانات التي لدينا صغيرة، ولكن إذا واجهت مجموعة بيانات واقعية يمكن تصنيفها بحد خطي، فإن هذا النموذج لا يزال يعمل. مع تدريب نموذجك، يمكنك إجراء تنبؤات حول كيفية تصنيف نقطة بيانات جديدة، ويمكنك رسم حد القرار (decision boundary).
دعنا نرسم حد القرار:
# get the weight values for the linear equation from the trained SVM model
w = clf.coef_[0]
# get the y-offset for the linear equation
a = -w[0] / w[1]
# make the x-axis space for the data points
XX = np.linspace(0, 13)
# get the y-values to plot the decision boundary
yy = a * XX - clf.intercept_[0] / w[1]
# plot the decision boundary
plt.plot(XX, yy, 'k-')
# show the plot visually
plt.scatter(training_X[:, 0], training_X[:, 1], c=training_y)
plt.legend()
plt.show()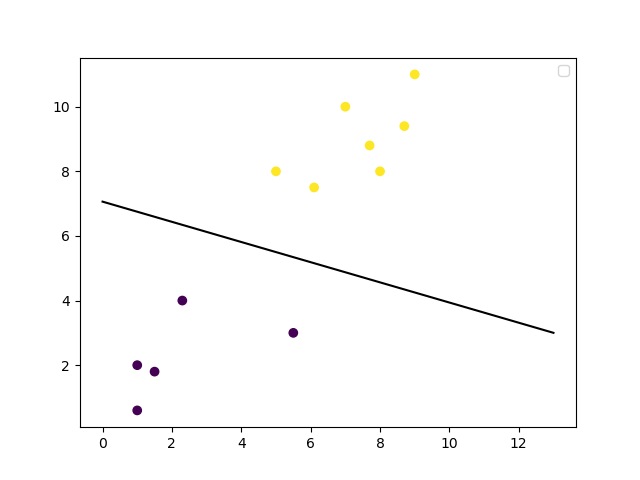
مثال على SVM غير الخطي (Non-Linear SVM)
لهذا المثال، سنستخدم مجموعة بيانات أكثر تعقيدًا قليلاً لإظهار أحد المجالات التي تتألق فيها SVMs. دعنا نستورد بعض الحزم.
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
from sklearn import svmهذه المجموعة من الاستيرادات مشابهة لتلك الموجودة في المثال الخطي، باستثناء أنها تستورد شيئًا إضافيًا واحدًا. الآن يمكننا استخدام مجموعة بيانات مباشرة من مكتبة Scikit-learn.
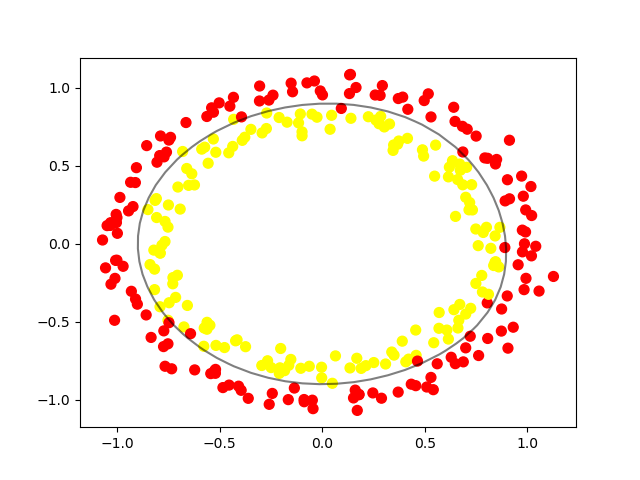
# non-linear data
circle_X, circle_y = datasets.make_circles(n_samples=300, noise=0.05)الخطوة التالية هي إلقاء نظرة على شكل هذه البيانات الخام باستخدام رسم بياني.
# show raw non-linear data
plt.scatter(circle_X[:, 0], circle_X[:, 1], c=circle_y, marker='.')
plt.show()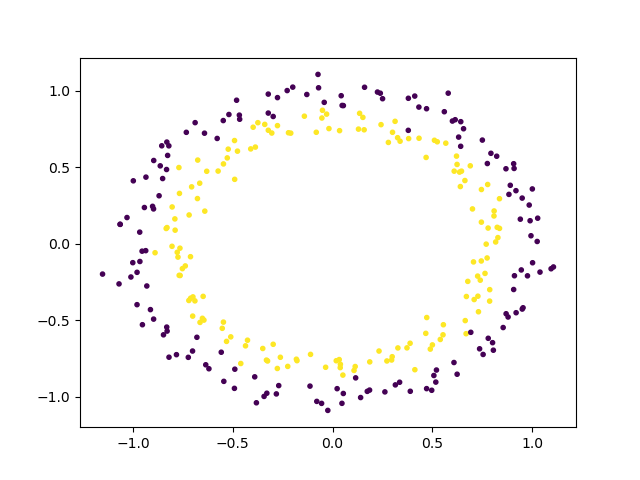
الآن بعد أن رأيت كيف يتم فصل البيانات، يمكننا اختيار SVM غير خطي للبدء به. لا تحتاج مجموعة البيانات هذه إلى أي معالجة أولية قبل استخدامها لتدريب النموذج، لذلك يمكننا تخطي هذه الخطوة. إليك كيف سيبدو نموذج SVM لهذا الغرض:
# make non-linear algorithm for model
nonlinear_clf = svm.SVC(kernel='rbf', C=1.0)في هذه الحالة، سنختار نواة RBF (دالة الأساس الشعاعي الغاوسية) لتصنيف هذه البيانات. يمكنك أيضًا تجربة النواة متعددة الحدود (polynomial kernel) لترى الفرق بين النتائج التي تحصل عليها.
الآن حان وقت تدريب النموذج.
# training non-linear model
nonlinear_clf.fit(circle_X, circle_y)يمكنك البدء في تصنيف البيانات الجديدة في الفئة الصحيحة بناءً على هذا النموذج. لرؤية كيف يبدو حد القرار، سيتعين علينا إنشاء دالة مخصصة لرسمه.
# Plot the decision boundary for a non-linear SVM problem
def plot_decision_boundary(model, ax=None):
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# create grid to evaluate model
x = np.linspace(xlim[0], xlim[1], 30)
y = np.linspace(ylim[0], ylim[1], 30)
Y, X = np.meshgrid(y, x)
# shape data
xy = np.vstack([X.ravel(), Y.ravel()]).T
# get the decision boundary based on the model
P = model.decision_function(xy).reshape(X.shape)
# plot decision boundary
ax.contour(X, Y, P, levels=[0], alpha=0.5, linestyles=['-'])لديك كل ما تحتاجه لرسم حد القرار لهذه البيانات غير الخطية. يمكننا القيام بذلك ببضعة أسطر من الكود التي تستخدم مكتبة Matplotlib، تمامًا مثل الرسوم البيانية الأخرى.
# plot data and decision boundary
plt.scatter(circle_X[:, 0], circle_X[:, 1], c=circle_y, s=50)
plot_decision_boundary(nonlinear_clf)
plt.scatter(nonlinear_clf.support_vectors_[:, 0], nonlinear_clf.support_vectors_[:, 1], s=50, lw=1, facecolors='none')
plt.show()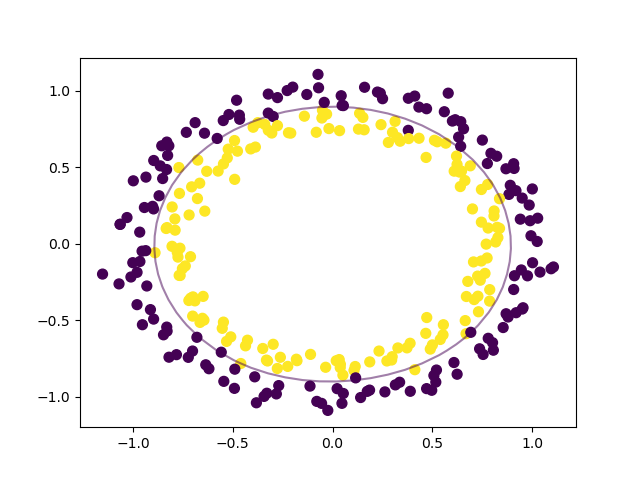
عندما تكون لديك بياناتك وتعرف المشكلة التي تحاول حلها، يمكن أن يكون الأمر بهذه البساطة حقًا. يمكنك تغيير نموذج التدريب الخاص بك بالكامل، واختيار خوارزميات وميزات مختلفة للعمل بها، وضبط نتائجك بدقة بناءً على معلمات متعددة. توجد مكتبات وحزم لكل هذا الآن، لذلك لا يوجد الكثير من الرياضيات التي يجب عليك التعامل معها.
نصائح لمشكلات العالم الحقيقي مع SVM
تواجه مجموعات البيانات الواقعية بعض المشكلات الشائعة بسبب حجمها الكبير، وأنواع البيانات المتغيرة التي تحتويها، ومقدار قوة الحوسبة التي قد تحتاجها لتدريب نموذج. هناك بعض الأشياء التي يجب الانتباه إليها بشكل خاص مع SVMs:
- تأكد من أن بياناتك في شكل رقمي بدلاً من شكل فئوي (
categorical form). تتوقعSVMsأرقامًا بدلاً من أنواع أخرى من التصنيفات. - تجنب نسخ البيانات قدر الإمكان. ستقوم بعض مكتبات بايثون بإنشاء نسخ مكررة من بياناتك إذا لم تكن بتنسيق معين. سيؤدي نسخ البيانات أيضًا إلى إبطاء وقت التدريب الخاص بك وتحريف الطريقة التي يخصص بها نموذجك الأوزان لميزة معينة.
- راقب حجم ذاكرة التخزين المؤقت للنواة (
kernel cache size) لأنها تستخدم ذاكرة الوصول العشوائي (RAM) الخاصة بك. إذا كان لديك مجموعة بيانات كبيرة جدًا، فقد يتسبب ذلك في حدوث مشكلات لنظامك. - قم بتحجيم بياناتك (
Scale your data) لأن خوارزمياتSVMليست ثابتة المقياس (scale invariant). هذا يعني أنه يمكنك تحويل جميع بياناتك لتكون ضمن النطاقات[0, 1]أو[-1, 1].
تأملات إضافية حول تعلم الآلة و SVM
قد تتساءل لماذا لم أتعمق في التفاصيل الرياضية هنا. السبب الرئيسي هو أنني لا أريد أن أخيف الناس من تعلم المزيد عن تعلم الآلة. من الممتع التعرف على تلك المعادلات الرياضية الطويلة والمعقدة واشتقاقاتها، ولكن نادرًا ما ستكتب خوارزمياتك الخاصة وتكتب براهين في المشاريع الحقيقية.
الأمر يشبه استخدام معظم الأشياء الأخرى التي تفعلها كل يوم، مثل هاتفك أو جهاز الكمبيوتر الخاص بك. يمكنك القيام بكل ما تحتاج إليه دون معرفة كيفية بناء المعالجات. تعلم الآلة يشبه أي تطبيق هندسة برمجيات آخر. هناك الكثير من الحزم التي تسهل عليك الحصول على النتائج التي تحتاجها دون خلفية عميقة في الإحصاء.
بمجرد أن تكتسب بعض الممارسة مع الحزم والمكتبات المختلفة المتاحة، ستكتشف أن أصعب جزء في تعلم الآلة هو الحصول على بياناتك وتصنيفها.
الخلاصة التقنية
تُعد خوارزمية آلة المتجهات الداعمة (SVM) حجر زاوية في مجال تعلم الآلة، بفضل قدرتها الفريدة على تحديد حدود قرار مثلى تفصل بين الفئات بأكبر هامش ممكن. هذه الميزة، بالإضافة إلى مرونتها في التعامل مع البيانات الخطية وغير الخطية عبر دوال النواة المتنوعة مثل Linear و RBF، تجعلها أداة لا غنى عنها في العديد من التطبيقات المعقدة، من التعرف على الأنماط إلى التصنيف الطبي. على الرغم من أن فهم التفاصيل الرياضية العميقة قد يكون تحديًا، إلا أن توفر مكتبات مثل Scikit-learn قد بسّط بشكل كبير عملية تطبيق SVMs، مما يتيح للمطورين التركيز على جودة البيانات وتصميم النموذج بدلاً من التعقيدات الحسابية. ومع ذلك، يظل التعامل مع مجموعات البيانات الكبيرة وتحسين المعلمات تحديًا يتطلب خبرة ومعرفة عملية لضمان الحصول على أفضل النتائج وتجنب الإفراط في التخصيص.