دليل شامل لاستخدام مكتبة Texthero في إعداد البيانات النصية لمشاريع معالجة اللغة الطبيعية (NLP)

تمهيد: أهمية معالجة اللغة الطبيعية وتحديات البيانات النصية
معالجة اللغة الطبيعية (NLP) هي أحد أهم مجالات الدراسة والبحث في عالمنا اليوم. تمتلك العديد من التطبيقات في القطاع التجاري مثل روبوتات الدردشة (chatbots)، تحليل المشاعر (sentiment analysis)، وتصنيف المستندات (document classification).
يُعدّ التحضير المسبق للبيانات النصية (Preprocessing) وتمثيلها من أصعب الأجزاء وأكثرها تعقيدًا عند العمل على مشروع NLP. يمكن أن تكون مجموعات البيانات النصية شائكة وصعبة المعالجة بشكل لا يصدق. ولكن لحسن الحظ، يمكن لحزمة بايثون الحديثة المسماة Texthero أن تساعدك في حل هذه التحديات.
ما هي مكتبة Texthero؟
Texthero هي مجموعة أدوات بايثون بسيطة تساعدك على التعامل مع مجموعات البيانات النصية. توفر وظائف سريعة وسهلة تتيح لك معالجة البيانات النصية مسبقًا، تمثيلها، تحويلها إلى متجهات (vectors)، وتصويرها في بضعة أسطر من التعليمات البرمجية فقط.
![]()
صُممت Texthero لتُستخدم فوق مكتبة Pandas، مما يسهل معالجة وتحليل سلاسل Pandas Series أو إطارات البيانات DataFrames النصية. إذا كنت تعمل على مشروع NLP، يمكن لـ Texthero أن تساعدك على إنجاز المهام بشكل أسرع من ذي قبل وتمنحك المزيد من الوقت للتركيز على المهام الهامة.
ملاحظة هامة: لا تزال مكتبة Texthero في نسختها التجريبية (beta version). قد تواجه بعض الأخطاء وقد تتغير بعض المسارات البرمجية (pipelines). سيتم إصدار نسخة أسرع وأفضل وستجلب معها تغييرات كبيرة.
نظرة عامة على وحدات Texthero الرئيسية
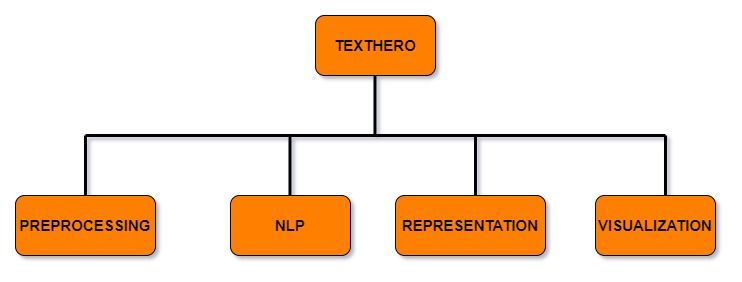
تحتوي Texthero على أربع وحدات مفيدة تتعامل مع وظائف مختلفة يمكنك تطبيقها على مجموعات البيانات النصية الخاصة بك:
1. وحدة المعالجة المسبقة (Preprocessing)
تتيح هذه الوحدة المعالجة المسبقة الفعالة لسلاسل Pandas Series أو إطارات البيانات DataFrames النصية. تحتوي على طرق مختلفة لتنظيف مجموعة البيانات النصية الخاصة بك مثل lowercase()، remove_html_tags()، و remove_urls().
2. وحدة معالجة اللغة الطبيعية (NLP)
تحتوي هذه الوحدة على بعض مهام NLP مثل named_entities (الكيانات المسماة)، noun_chunks (تكتلات الأسماء)، وما إلى ذلك.
3. وحدة التمثيل (Representation)
تحتوي هذه الوحدة على خوارزميات مختلفة لتحويل الكلمات إلى متجهات (vectors) مثل TF-IDF، GloVe، تحليل المكونات الرئيسية (Principal Component Analysis - PCA)، و term_frequency.
4. وحدة التصور (Visualization)
تحتوي الوحدة الأخيرة على ثلاث طرق مختلفة لتصور الرؤى والإحصائيات الخاصة بإطار بيانات Pandas DataFrame النصي. يمكنها رسم مخطط مبعثر (scatter plot) وسحابة كلمات (word cloud).
تثبيت مكتبة Texthero
مكتبة Texthero مجانية، مفتوحة المصدر، وموثقة جيدًا. لتثبيتها، افتح الطرفية (terminal) ونفذ الأمر التالي:
pip install textheroتستخدم الحزمة العديد من المكتبات الأخرى في الخلفية مثل Gensim، SpaCy، scikit-learn، و NLTK. لا تحتاج إلى تثبيتها جميعًا بشكل منفصل، سيتولى pip ذلك.
كيفية استخدام Texthero في مشروعك
في هذا المقال، سأستخدم مجموعة بيانات إخبارية لأوضح لك كيفية استخدام الطرق المختلفة التي توفرها وحدات Texthero في مشروع NLP الخاص بك. سنبدأ باستيراد حزم بايثون الهامة التي سنستخدمها.
#import important packages
import texthero as hero
import pandas as pdثم سنقوم بتحميل مجموعة بيانات من دليل البيانات. تركز مجموعة البيانات لهذا المقال على الأخبار باللغة السواحلية.
#load dataset
data = pd.read_csv(
"data/swahili_news_dataset.csv"
)دعنا نلقي نظرة على أول 5 صفوف من مجموعة البيانات:
# show top 5 rows
data.head()
كما ترى، في مجموعة البيانات الخاصة بنا لدينا ثلاثة أعمدة (id، content، و category). لهذا المقال، سنركز على ميزة content.
# select news content only and show top 5 rows
news_content = data[[ "content" ]]
news_content.head()لقد أنشأنا إطار بيانات جديدًا يركز على المحتوى فقط، ثم سنعرض أول 5 صفوف منه.

المعالجة المسبقة للبيانات باستخدام Texthero
يمكننا استخدام الطريقة clean() لإجراء المعالجة المسبقة لسلسلة Pandas Series النصية.
# clean the news content by using clean method from hero package
news_content[ 'clean_content' ] = hero.clean(news_content[ 'content' ])تقوم طريقة clean() بتشغيل سبع وظائف عند تمرير سلسلة Pandas إليها. هذه الوظائف السبع هي:
lowercase(s): تحول جميع النصوص إلى أحرف صغيرة.remove_diacritics(): تزيل جميع علامات التشكيل من السلاسل النصية.remove_stopwords(): تزيل جميع الكلمات الوقفية (stopwords).remove_digits(): تزيل جميع الكتل الرقمية.remove_punctuation(): تزيل جميع علامات الترقيم (!"#$%&'()*+,-./:;<=>?@[]^ `{|}~).fillna(s): تستبدل القيم غير المعينة بمسافات فارغة.remove_whitespace(): تزيل جميع المسافات البيضاء الزائدة بين الكلمات.
الآن يمكننا رؤية المحتوى الإخباري بعد تنظيفه.
#show unclean and clean news content
news_content.head()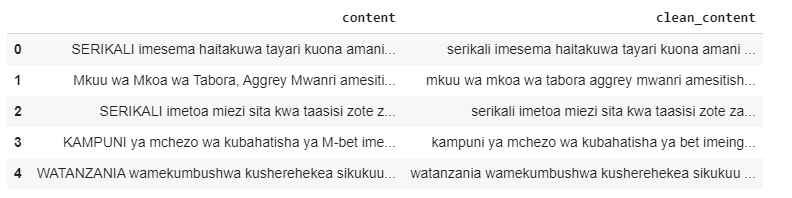
التنظيف المخصص (Custom Cleaning)
إذا لم يتناسب المسار الافتراضي (default pipeline) من طريقة clean() مع احتياجاتك، يمكنك إنشاء مسار مخصص (custom pipeline) بقائمة الوظائف التي ترغب في تطبيقها على مجموعة البيانات الخاصة بك. كمثال، قمت بإنشاء مسار مخصص بخمس وظائف فقط لتنظيف مجموعة البيانات الخاصة بي.
#create custom pipeline
from texthero import preprocessing
custom_pipeline = [
preprocessing.fillna,
preprocessing.lowercase,
preprocessing.remove_whitespace,
preprocessing.remove_punctuation,
preprocessing.remove_urls,
]الآن يمكنني استخدام custom_pipeline لتنظيف مجموعة البيانات الخاصة بي.
#altearnative for custom pipeline
news_content[ 'clean_custom_content' ] = news_content[ 'content' ].pipe(hero.clean, custom_pipeline)يمكنك رؤية مجموعة البيانات النظيفة التي أنشأناها باستخدام المسار المخصص.
# show output of custome pipeline
news_content.clean_custom_content.head()
وظائف المعالجة المسبقة المفيدة الأخرى
فيما يلي بعض الوظائف المفيدة الأخرى من وحدات المعالجة المسبقة التي يمكنك تجربتها لتنظيف مجموعة البيانات النصية الخاصة بك.
إزالة الأرقام (Remove Digits)
يمكنك استخدام الدالة remove_digits() لإزالة الأرقام من مجموعات البيانات النصية الخاصة بك.
text = pd.Series( "Hi my phone number is +255 711 111 111 call me at 09:00 am" )
clean_text = hero.preprocessing.remove_digits(text)
print(clean_text)
output: Hi my phone number is + call me at : am
dtype: objectإزالة الكلمات الوقفية (Remove Stopwords)
يمكنك استخدام الدالة remove_stopwords() لإزالة الكلمات الوقفية من مجموعات البيانات النصية الخاصة بك.
text = pd.Series( "you need to know NLP to develop the chatbot that you desire" )
clean_text = hero.remove_stopwords(text)
print(clean_text)
output: need know NLP develop chatbot desire
dtype: objectإزالة الروابط (Remove URLs)
يمكنك استخدام الدالة remove_urls() لإزالة الروابط من مجموعات البيانات النصية الخاصة بك.
text = pd.Series( "Go to https://www.freecodecamp.org/news/ to read more articles you like" )
clean_text = hero.remove_urls(text)
print(clean_text)
output: Go to to read more articles you like
dtype: objectتقسيم الكلمات (Tokenize)
تقوم طريقة tokenize() بتقسيم كل صف في سلسلة Pandas Series المعطاة إلى رموز (tokens) وتعيد سلسلة Pandas Series حيث يحتوي كل صف على قائمة من الرموز.
text = pd.Series([ "You can think of Texthero as a tool to help you understand and work with text-based dataset. " ])
clean_text = hero.tokenize(text)
print(clean_text)
output: [You, can, think, of, Texthero, as, a, tool, to, help, you, understand, and, work, with, text, based, dataset]
dtype: objectإزالة وسوم HTML (Remove HTML Tags)
يمكنك إزالة وسوم HTML من سلسلة Pandas Series المعطاة باستخدام طريقة remove_html_tags().
text = pd.Series( "<html><body><h2>hello world</h2></body></html>" )
clean_text = hero.remove_html_tags(text)
print(clean_text)
output: hello world
dtype: objectوظائف التصور المفيدة
تحتوي Texthero على طرق مختلفة لتصور الرؤى والإحصائيات الخاصة بإطار بيانات Pandas DataFrame النصي.
الكلمات الأكثر شيوعًا (Top Words)
إذا كنت ترغب في معرفة الكلمات الأكثر شيوعًا في مجموعة البيانات النصية الخاصة بك، يمكنك استخدام طريقة top_words() من وحدة التصور (visualization module). هذه الطريقة مفيدة إذا كنت ترغب في رؤية كلمات إضافية يمكنك إضافتها إلى قوائم الكلمات الوقفية (stop words). لا تعيد هذه الطريقة مخططًا شريطيًا، لذلك سأستخدم matplotlib لتصور الكلمات الأكثر شيوعًا في مخطط شريطي.
import matplotlib.pyplot as plt
NUM_TOP_WORDS = 20
top_20 = hero.visualization.top_words(news_content[ 'clean_content' ]).head(NUM_TOP_WORDS)
# Draw the bar chart
top_20.plot.bar(rot= 90 , title= "Top 20 words" );
plt.show(block= True );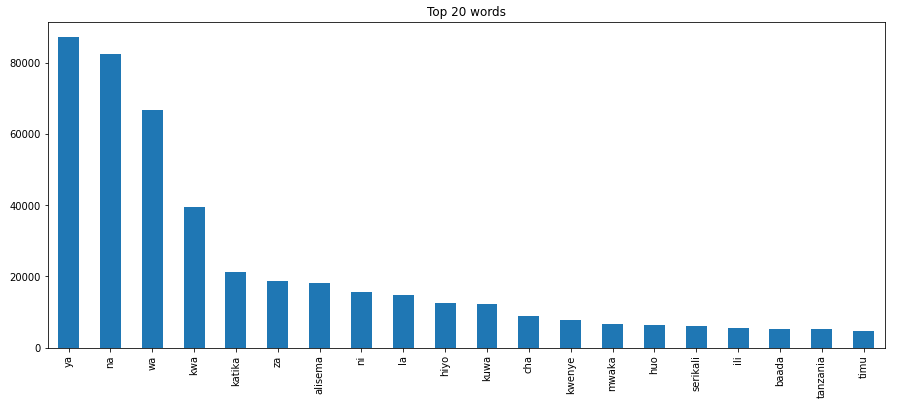
في الرسم البياني أعلاه، يمكننا تصور الكلمات العشرين الأكثر شيوعًا من مجموعة البيانات الإخبارية الخاصة بنا.
سحابات الكلمات (Wordclouds)
تقوم طريقة wordcloud() من وحدة التصور برسم صورة باستخدام WordCloud من حزمة word_cloud.
#Plot wordcloud image using WordCloud method
hero.wordcloud(news_content.clean_content, max_words= 100 ,)لقد قمنا بتمرير سلسلة إطار البيانات (dataframe series) وعدد الكلمات القصوى (لهذا المثال، 100 كلمة) إلى طريقة wordcloud().

وظائف التمثيل المفيدة
تحتوي Texthero على طرق مختلفة من وحدة التمثيل (representation module) تساعدك على تحويل الكلمات إلى متجهات (vectors) باستخدام خوارزميات مختلفة مثل TF-IDF، word2vec أو GloVe. في هذا القسم سأوضح لك كيفية استخدام هذه الطرق.
TF-IDF
يمكنك تمثيل سلسلة Pandas Series النصية باستخدام TF-IDF. لقد أنشأت سلسلة Pandas جديدة تحتوي على قطعتين من المحتوى الإخباري وقمت بتمثيلها في ميزات TF-IDF باستخدام طريقة tfidf().
# Create a new text-based Pandas Series.
news = pd.Series([ "mkuu wa mkoa wa tabora aggrey mwanri amesitisha likizo za viongozi wote mkoani humo kutekeleza maazimio ya jukwaa la fursa za biashara la mkoa huo" , "serikali imetoa miezi sita kwa taasisi zote za umma ambazo hazitumii mfumo wa gepg katika ukusanyaji wa fedha kufanya hivyo na baada ya hapo itafanya ukaguzi na kuwawajibisha" ])
#convert into tfidf features
hero.tfidf(news)
output: [0.187132760851739, 0.0, 0.187132760851739, 0....
[0.0, 0.18557550845969953, 0.0, 0.185575508459...
dtype: objectملاحظة: TF-IDF تعني “تكرار المصطلح – معكوس تكرار المستند” (term frequency-inverse document frequency).
تكرار المصطلح (Term Frequency)
يمكنك تمثيل سلسلة Pandas Series النصية باستخدام طريقة term_frequency(). يُستخدم تكرار المصطلح (TF) لإظهار مدى تكرار تعبير (مصطلح أو كلمة) في مستند أو محتوى نصي.
news = pd.Series([ "mkuu wa mkoa wa tabora aggrey mwanri amesitisha likizo za viongozi wote mkoani humo kutekeleza maazimio ya jukwaa la fursa za biashara la mkoa huo" , "serikali imetoa miezi sita kwa taasisi zote za umma ambazo hazitumii mfumo wa gepg katika ukusanyaji wa fedha kufanya hivyo na baada ya hapo itafanya ukaguzi na kuwawajibisha" ])
# Represent a text-based Pandas Series using term_frequency.
hero.term_frequency(news)
output: [1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, ...
[0, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, ...
dtype: objectتجميع البيانات باستخدام K-means
يمكن لـ Texthero تنفيذ خوارزمية تجميع K-means باستخدام طريقة kmeans(). إذا كان لديك مجموعة بيانات نصية غير مصنفة (unlabeled)، يمكنك استخدام هذه الطريقة لتجميع المحتوى وفقًا لأوجه التشابه بينها. في هذا المثال، سأقوم بإنشاء إطار بيانات Pandas جديد يسمى news بالأعمدة التالية: content، tfidf، و kmeans_labels.
column_names = [ "content" , "tfidf" , "kmeans_labels" ]
news = pd.DataFrame(columns = column_names)سنستخدم فقط أول 30 قطعة من المحتوى النظيف من إطار بيانات news_content الخاص بنا وسنقوم بتجميعها في مجموعات باستخدام طريقة kmeans().
# collect 30 clean content.
news[ "content" ] = news_content.clean_content[: 30 ]
# convert them into tf-idf features.
news[ 'tfidf' ] = (
news[ 'content' ]
.pipe(hero.tfidf)
)
# perform clustering algorithm by using kmeans()
news[ 'kmeans_labels' ] = (
news[ 'tfidf' ]
.pipe(hero.kmeans, n_clusters= 5 )
.astype(str)
)في الكود المصدري أعلاه، في مسار طريقة k-means، قمنا بتمرير عدد المجموعات وهو 5. هذا يعني أننا سنقوم بتجميع هذه المحتويات في 5 مجموعات. الآن تم تصنيف المحتوى الإخباري المحدد إلى خمس مجموعات.
# show content and their labels
news[[ "content" , "kmeans_labels" ]].head()
تحليل المكونات الرئيسية (PCA)
يمكنك أيضًا استخدام طريقة pca() لإجراء تحليل المكونات الرئيسية (Principal Component Analysis) على سلسلة Pandas Series المعطاة. تحليل المكونات الرئيسية (PCA) هو تقنية لتقليل أبعاد مجموعات البيانات الخاصة بك. هذا يزيد من قابلية التفسير ولكنه في نفس الوقت يقلل من فقدان المعلومات. في هذا المثال، سنستخدم ميزات tfidf من إطار بيانات news ونمثلها في مكونين باستخدام طريقة pca(). أخيرًا، سنعرض مخططًا مبعثرًا (scatterplot) باستخدام طريقة scatterplot().
#perform pca
news[ 'pca' ] = news[ 'tfidf' ].pipe(hero.pca)
#show scatterplot
hero.scatterplot(news, 'pca' , color= 'kmeans_labels' , title= "news" )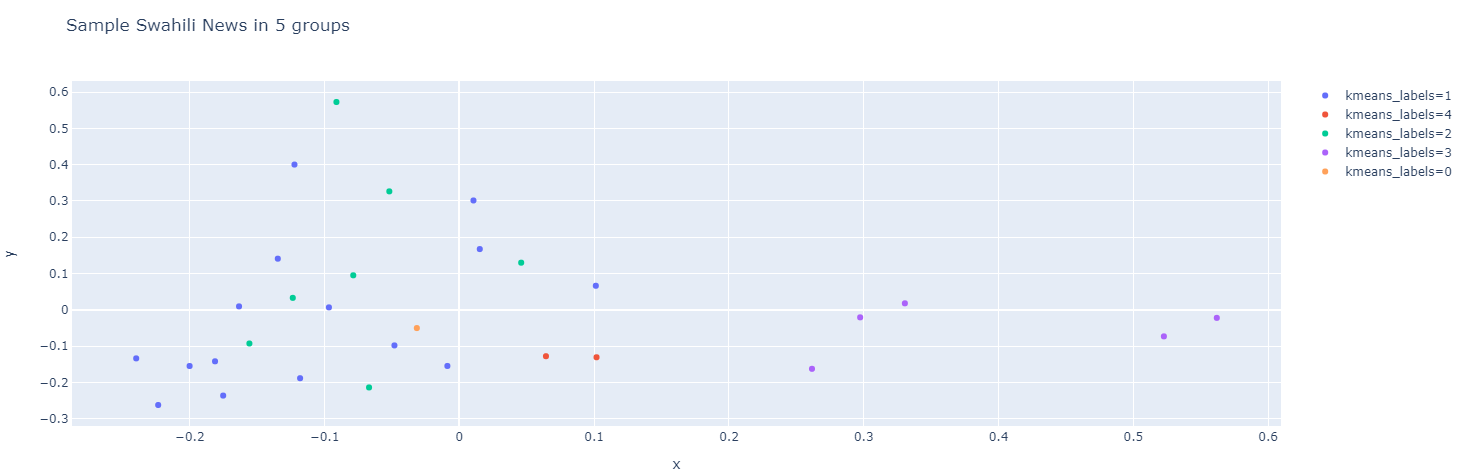
خاتمة
في هذا المقال، تعلمت أساسيات كيفية استخدام حزمة أدوات بايثون Texthero في مشروع NLP الخاص بك. يمكنك معرفة المزيد عن الطرق المتاحة في الوثائق الرسمية. يمكنك تنزيل مجموعة البيانات والدفتر (notebook) المستخدمين في هذا المقال من هنا: مستودع GitHub.
إذا تعلمت شيئًا جديدًا أو استمتعت بقراءة هذا المقال، فيرجى مشاركته حتى يتمكن الآخرون من رؤيته. إلى ذلك الحين، نلقاك في المنشور التالي!
الخلاصة التقنية
تُعد مكتبة Texthero إضافة قيمة للغاية لمطوري وباحثي NLP، حيث تُبسّط بشكل كبير المهام المعقدة لتنظيف وتحضير البيانات النصية. قدرتها على التكامل السلس مع Pandas، وتقديم مسارات عمل جاهزة للتنظيف (مثل clean())، بالإضافة إلى دعمها للتمثيل المتقدم (TF-IDF، GloVe) والتصور (wordclouds، top_words)، يجعلها أداة فعالة لتقليل الوقت والجهد المبذول في مرحلة المعالجة المسبقة. على الرغم من كونها لا تزال في مرحلة البيتا، إلا أن مرونتها في إنشاء مسارات تنظيف مخصصة ودعمها لخوارزميات التجميع والحد من الأبعاد (مثل K-means و PCA) يضعها كخيار ممتاز للتعامل مع تحديات البيانات النصية في مشاريع NLP المتنوعة.