أبرز ميزات Scikit-Learn 0.24 في بايثون التي يجب أن يعرفها مختصو تعلم الآلة
مقدمة إلى مكتبة Scikit-Learn في بايثون
تُعد مكتبة scikit-learn واحدة من أشهر المكتبات مفتوحة المصدر والمجانية في مجال تعلم الآلة باستخدام Python. وتوفر هذه المكتبة مجموعة كبيرة من الأدوات الفعالة لبناء نماذج التصنيف والانحدار والتجميع وخفض الأبعاد، إلى جانب أدوات مهمة لتقييم النماذج وتحسين أدائها.
يعتمد كثير من علماء البيانات ومهندسي تعلم الآلة والباحثين على scikit-learn بسبب سهولة استخدامها، ووضوح توثيقها، وتنوع الأمثلة العملية المتاحة لها. وفي الإصدار 0.24 تحديداً، حصلت المكتبة على مجموعة من التحسينات والميزات الجديدة التي تستحق الاهتمام، خاصة لمن يعمل على مشاريع تحليل البيانات والنمذجة التنبؤية بشكل احترافي.

تثبيت أحدث إصدار من مكتبة Scikit-Learn
قبل تجربة الميزات الجديدة، تأكد أولاً من تثبيت أحدث إصدار من المكتبة. إذا كنت تستخدم pip، يمكنك تنفيذ الأمر التالي:
pip install --upgrade scikit-learnأما إذا كنت تعمل بمدير الحزم conda، فاستخدم الأمر التالي:
conda install -c conda-forge scikit-learnيدعم هذا الإصدار إصدارات Python من 3.6 حتى 3.9، وهو ما يجعله مناسباً لكثير من بيئات العمل الشائعة.
مقياس MAPE الجديد لتقييم نماذج الانحدار
ما هو Mean Absolute Percentage Error؟
أضاف الإصدار الجديد مقياساً مهماً لتقييم نماذج الانحدار يُعرف باسم Mean Absolute Percentage Error أو MAPE. هذا المقياس يساعدك على فهم مقدار الخطأ النسبي بين القيم الحقيقية والقيم المتوقعة، وهو مفيد عندما تريد قراءة الخطأ بصورة أكثر قرباً من الواقع العملي.
في السابق، كان من الشائع حساب هذا المقياس يدوياً باستخدام كود مشابه لما يلي:
np.mean(np.abs((y_test - preds) / y_test))لكن في scikit-learn 0.24 أصبح بإمكانك استخدام الدالة الجاهزة mean_absolute_percentage_error() من الوحدة sklearn.metrics.
مثال عملي على استخدام mean_absolute_percentage_error()
from sklearn.metrics import mean_absolute_percentage_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
print(mean_absolute_percentage_error(y_true, y_pred))
0.3273809523809524من المهم الانتباه إلى أن ناتج هذه الدالة لا يُعرض كنسبة مئوية مباشرة بين 0 و100. بدلاً من ذلك، يتم تمثيله ضمن نطاق يبدأ من 0، وأفضل قيمة ممكنة هي 0.0 لأنها تعني عدم وجود خطأ.
دعم القيم المفقودة في OneHotEncoder
ما الذي تغيّر في هذا الإصدار؟
أصبح OneHotEncoder قادراً على التعامل مع القيم المفقودة مباشرة عند ظهورها داخل البيانات. وبدلاً من تجاهل هذه القيم أو التسبب في خطأ، يتعامل معها على أنها فئة مستقلة بحد ذاتها.
هذه الميزة مفيدة جداً عند تجهيز البيانات الفئوية، لأنها تقلل الحاجة إلى معالجة مسبقة إضافية، وتمنحك مرونة أكبر في بناء خطوط معالجة البيانات.
استيراد الحزم الأساسية
import pandas as pd
import numpy as np
from sklearn.preprocessing import OneHotEncoderإنشاء إطار بيانات يحتوي على قيم مفقودة
# intialise data of lists.
data = {
'education_level': ['primary', 'secondary', 'bachelor', np.nan, 'masters', np.nan]
}
# Create DataFrame
df = pd.DataFrame(data)
# Print the output.
print(df)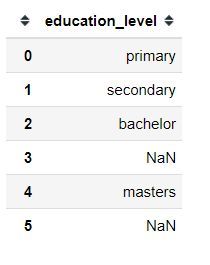
كما يظهر في المثال، يحتوي العمود education_level على قيمتين مفقودتين.
إنشاء كائن OneHotEncoder وتحويل البيانات
enc = OneHotEncoder()enc.fit_transform(df).toarray()
تم تحويل العمود إلى تمثيل رقمي، كما عوملت القيم المفقودة بوصفها فئة جديدة مستقلة، وهو ما يمكن ملاحظته في العمود الأخير من المصفوفة الناتجة.
طريقة جديدة لاختيار السمات باستخدام SequentialFeatureSelector
يوفر الإصدار 0.24 أسلوباً جديداً لاختيار السمات أو الخصائص المهمة في البيانات عبر الأداة SequentialFeatureSelector. ويمكن استخدام هذه الأداة بطريقتين:
- الاختيار الأمامي
Forward Selection - الاختيار الخلفي
Backward Selection
الاختيار الأمامي Forward Selection
في هذا الأسلوب، يبدأ النموذج من دون أي سمات، ثم يضيف في كل خطوة السمة التي تحسن أداء التحقق المتقاطع cross-validation بأفضل شكل ممكن. وتتكرر العملية حتى الوصول إلى العدد المطلوب من السمات.
الاختيار الخلفي Backward Selection
أما هذا الأسلوب فيبدأ بكل السمات المتاحة، ثم يحذف تدريجياً السمات الأقل فائدة حتى يصل إلى العدد المستهدف. وهو مناسب عندما تكون لديك مجموعة سمات كبيرة وتريد تقليصها بذكاء.
مثال عملي
from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_irisX, y = load_iris(return_X_y=True, as_frame=True)
feature_names = X.columnsknn = KNeighborsClassifier(n_neighbors=3)sfs = SequentialFeatureSelector(
knn,
n_features_to_select=2,
direction='backward'
)sfs.fit(X, y)print(
"Features selected by backward sequential selection: "
f"{feature_names[sfs.get_support()].tolist()}"
)في هذا المثال، تم استخدام أسلوب الاختيار الخلفي لاختيار أفضل سمتين من بيانات iris. وغالباً ما تُظهر النتائج أن السمات المرتبطة بطول البتلة وعرضها من أكثر السمات تأثيراً.
ورغم أن هذه الطريقة فعالة، فإنها قد تكون أبطأ من أساليب أخرى مثل SelectFromModel وRFE، لأنها تعتمد على التقييم عبر cross-validation في كل خطوة.
أساليب جديدة لضبط المعاملات الفائقة
عند الحديث عن ضبط المعاملات الفائقة Hyper-Parameter Tuning، اعتاد كثير من الممارسين على استخدام GridSearchCV وRandomizedSearchCV. لكن الإصدار الجديد أضاف فئتين جديدتين هما:
HalvingGridSearchCVHalvingRandomSearchCV
تعتمد هاتان الأداتان على أسلوب يُعرف باسم successive halving، وهو نهج ذكي يسرّع عملية البحث عن أفضل مجموعة معاملات دون اختبار جميع الاحتمالات بنفس الكلفة.
كيف تعمل آلية successive halving؟
يمكن تشبيهها ببطولة تنافسية بين مجموعات المعاملات المختلفة:
- في البداية، يتم تدريب عدد كبير من التركيبات على جزء صغير من البيانات.
- ثم تُستبعد التركيبات الأضعف أداءً.
- في كل جولة لاحقة، تحصل التركيبات الأفضل على موارد أكبر وعدد ملاحظات أكثر.
- تتكرر العملية حتى تبقى أفضل مجموعة معاملات في النهاية.
هذا النهج يوفر الوقت والموارد، خاصة عندما تكون مساحة البحث كبيرة.
مع ذلك، يجدر التنبيه إلى أن هذه الفئات كانت عند طرحها لا تزال ضمن الميزات التجريبية experimental.
مثال عملي على HalvingRandomSearchCV
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from sklearn.experimental import enable_halving_search_cv
from sklearn.model_selection import HalvingRandomSearchCV
from scipy.stats import randintبما أن هذه الميزة كانت تجريبية، يجب استيراد enable_halving_search_cv بشكل صريح قبل استخدامها.
X, y = make_classification(n_samples=1000)clf = RandomForestClassifier(n_estimators=20)param_dist = {
"max_depth": [3, None],
"max_features": randint(1, 11),
"min_samples_split": randint(2, 11),
"bootstrap": [True, False],
"criterion": ["gini", "entropy"]
}rsh = HalvingRandomSearchCV(
estimator=clf,
param_distributions=param_dist,
cv=5,
factor=2,
min_resources=20
)هناك معاملان مهمان ينبغي فهمهما هنا:
factor: يحدد نسبة التركيبات التي ستنتقل إلى الجولة التالية. فعندما تكون قيمته3مثلاً، ينتقل فقط ثلث المرشحين تقريباً.min_resources: يحدد مقدار الموارد الأولية، مثل عدد العينات المستخدمة في أول جولة لكل تركيبة معاملات.
rsh.fit(X, y)بعد انتهاء التدريب، يمكنك استعراض عدة مؤشرات مفيدة:
print(rsh.n_iterations_)وتمثل عدد الجولات، وقد تكون مثلاً 6.
print(rsh.n_candidates_)وتمثل عدد التركيبات التي جرى تقييمها في كل جولة، مثل:
[50, 25, 13, 7, 4, 2]print(rsh.n_resources_)وتمثل عدد الموارد المستخدمة في كل جولة، مثل:
[20, 40, 80, 160, 320, 640]print(rsh.best_params_){
'bootstrap': False,
'criterion': 'entropy',
'max_depth': None,
'max_features': 5,
'min_samples_split': 2
}تُعد هذه الإضافات مهمة جداً لمن يريد الوصول إلى أفضل أداء بأقل وقت ممكن، خاصة في المشاريع التي تحتوي على بيانات كبيرة أو نماذج مكلفة تدريبياً.
مُقدِّر جديد للتعلّم شبه الخاضع للإشراف عبر SelfTrainingClassifier
قدّم scikit-learn 0.24 أداة جديدة للتعلم شبه الخاضع للإشراف Semi-Supervised Learning باسم SelfTrainingClassifier. وتسمح هذه الأداة بتحويل أي مصنف خاضع للإشراف تقريباً إلى مصنف قادر على الاستفادة من البيانات غير المعلّمة، بشرط أن يتمكن من إرجاع احتمالات الفئات عبر predict_proba.
تكمن أهمية هذه الفكرة في أن كثيراً من مجموعات البيانات الواقعية تحتوي على عدد محدود من السجلات المعلّمة، مقابل كمية كبيرة من السجلات غير المعلّمة. وهنا يساعد هذا الأسلوب في تحسين الاستفادة من البيانات المتاحة.
ملاحظة مهمة: يجب أن تحمل القيم غير المعلّمة في المتغير الهدف قيمة -1.
مثال عملي
import numpy as np
from sklearn import datasets
from sklearn.semi_supervised import SelfTrainingClassifier
from sklearn.svm import SVCفي هذا المثال، سنستخدم بيانات iris وخوارزمية Support Vector Machine بوصفها مصنفاً أساسياً:
rng = np.random.RandomState(42)
iris = datasets.load_iris()
random_unlabeled_points = rng.rand(iris.target.shape[0]) < 0.3
iris.target[random_unlabeled_points] = -1في السطر الأخير، جرى تعيين بعض القيم في الهدف إلى -1 كي تُعامل بوصفها غير معلّمة.
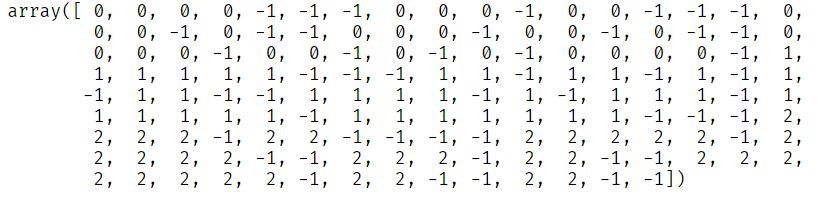
svc = SVC(probability=True, gamma="auto")self_training_model = SelfTrainingClassifier(base_estimator=svc)self_training_model.fit(iris.data, iris.target)بهذه الطريقة، يستطيع النموذج أن يبدأ بالتعلم من الجزء المعلّم، ثم يضيف تدريجياً بعض التوقعات عالية الثقة من البيانات غير المعلّمة إلى عملية التدريب.
لماذا يُعد هذا الإصدار مهماً لممارسي تعلم الآلة؟
يجمع الإصدار 0.24 بين تحسينات عملية ومباشرة في عدة مراحل أساسية من دورة بناء النماذج، ومنها:
- تقييم النماذج عبر مقياس
MAPE. - معالجة البيانات الفئوية التي تحتوي على قيم مفقودة.
- اختيار السمات بطريقة تسلسلية ومنهجية.
- تسريع ضبط المعاملات الفائقة بأساليب أكثر كفاءة.
- إتاحة التعلم شبه الخاضع للإشراف باستخدام نماذج مألوفة.
هذه الميزات لا تضيف وظائف جديدة فحسب، بل تعزز أيضاً مرونة المكتبة وسهولة استخدامها في البيئات الإنتاجية والمشاريع البحثية على حد سواء.
الخلاصة التقنية
إذا كنت تعتمد على scikit-learn في مشاريعك، فإن الإصدار 0.24 يمثل خطوة مهمة نحو مكتبة أكثر نضجاً وذكاءً. أكثر ما يميّز هذا الإصدار هو تركيزه على تسهيل المهام المتكررة التي يواجهها المتخصص يومياً، مثل اختيار السمات، والتعامل مع البيانات الناقصة، وضبط المعاملات بكفاءة أعلى. ومن الناحية العملية، فإن تبنّي هذه الميزات يمكن أن يقلل زمن التطوير ويرفع جودة النماذج، خصوصاً في مشاريع تعلم الآلة التي تتطلب سرعة في التجريب ووضوحاً في التقييم.