الدليل الشامل للشبكات العصبية المتكررة (RNN) في بايثون

تُعد الشبكات العصبية المتكررة (Recurrent Neural Networks أو RNNs) نماذج تعلم عميق متخصصة في معالجة مشكلات السلاسل الزمنية. تجد هذه الشبكات تطبيقات حيوية في مجالات متقدمة مثل السيارات ذاتية القيادة، وخوارزميات التداول عالي التردد، بالإضافة إلى العديد من التطبيقات الواقعية الأخرى التي تتطلب فهمًا للبيانات المتسلسلة.
يهدف هذا الدليل الشامل إلى تعريفك بالأسس الجوهرية للشبكات العصبية المتكررة. لن تكتفي بالتعرف على المفاهيم النظرية فحسب، بل ستتعلم أيضًا كيفية بناء وتدريب شبكة عصبية متكررة خاصة بك، قادرة على التنبؤ بسعر سهم شركة Facebook (FB) ليوم الغد، مما يمنحك فهمًا عمليًا عميقًا لهذه التقنية القوية.
فهم الشبكات العصبية المتكررة: نظرة معمقة
تُعد الشبكات العصبية المتكررة مثالاً بارزًا ضمن المجال الأوسع للشبكات العصبية. توجد أنواع أخرى من الشبكات العصبية التي تخدم أغراضًا مختلفة، منها:
- الشبكات العصبية الاصطناعية (
Artificial Neural Networks - ANNs) - الشبكات العصبية التلافيفية (
Convolutional Neural Networks - CNNs)
في هذا الدليل، سنركز بشكل خاص على الشبكات العصبية المتكررة. سنبدأ مناقشتنا باستكشاف المفهوم الأساسي والحدس وراء عمل هذه الشبكات.
أنواع المشكلات التي تحلها الشبكات العصبية المتكررة
على الرغم من أننا لم نتناول ذلك بشكل صريح بعد، إلا أن كل نوع من الشبكات العصبية مصمم لحل فئات واسعة من المشكلات:
- الشبكات العصبية الاصطناعية (
ANNs): تُستخدم عادةً لمشكلات التصنيف (classification) والانحدار (regression). - الشبكات العصبية التلافيفية (
CNNs): تُستخدم بشكل أساسي في مشكلات الرؤية الحاسوبية (computer vision).
أما الشبكات العصبية المتكررة (RNNs)، فتُستخدم عادةً لحل مشكلات تحليل السلاسل الزمنية (time series analysis). تجدر الإشارة إلى أن جميع هذه الأنواع الثلاثة من الشبكات العصبية (الاصطناعية، التلافيفية، والمتكررة) تُستخدم لحل مشكلات التعلم الآلي الخاضع للإشراف (supervised machine learning).
ربط الشبكات العصبية بأجزاء الدماغ البشري
كما تعلمون، صُممت الشبكات العصبية لتحاكي الدماغ البشري. ينطبق هذا على كل من بنيتها (كلاهما يتكون من خلايا عصبية) ووظيفتها (كلاهما يُستخدم لاتخاذ القرارات والتنبؤات). الأجزاء الرئيسية الثلاثة للدماغ هي:
- المخ (
Cerebrum) - جذع الدماغ (
Brainstem) - المخيخ (
Cerebellum)
يمكن القول إن أهم جزء في الدماغ هو المخ، الذي يحتوي على أربعة فصوص رئيسية:
- الفص الجبهي (
Frontal Lobe) - الفص الجداري (
Parietal Lobe) - الفص الصدغي (
Temporal Lobe) - الفص القذالي (
Occipital Lobe)
الابتكار الرئيسي الذي تحتويه الشبكات العصبية هو فكرة “الأوزان” (weights). بعبارة أخرى، أهم خاصية للدماغ التي حاكتها الشبكات العصبية هي القدرة على التعلم من الخلايا العصبية الأخرى. إن قدرة الشبكة العصبية على تغيير أوزانها خلال كل حقبة (epoch) من مرحلة تدريبها تشبه الذاكرة طويلة المدى التي نراها في البشر (والحيوانات الأخرى).
يُعد الفص الصدغي هو جزء الدماغ المرتبط بالذاكرة طويلة المدى. وبشكل منفصل، كانت الشبكة العصبية الاصطناعية (ANN) هي أول نوع من الشبكات العصبية يمتلك خاصية الذاكرة طويلة المدى هذه. وبهذا المعنى، قارن العديد من الباحثين الشبكات العصبية الاصطناعية بالفص الصدغي للدماغ البشري.
وبالمثل، يُعد الفص القذالي هو المكون الدماغي الذي يمد رؤيتنا بالطاقة. وبما أن الشبكات العصبية التلافيفية (CNNs) تُستخدم عادةً لحل مشكلات الرؤية الحاسوبية، فيمكن القول إنها تعادل الفص القذالي في الدماغ.
وكما ذكرنا، تُستخدم الشبكات العصبية المتكررة (RNNs) لحل مشكلات السلاسل الزمنية. يمكنها التعلم من الأحداث التي وقعت في التكرارات السابقة القريبة من مرحلة تدريبها. وبهذه الطريقة، غالبًا ما تُقارن بالفص الجبهي للدماغ – الذي يمد ذاكرتنا قصيرة المدى بالطاقة.
لتلخيص ذلك، غالبًا ما يربط الباحثون كل شبكة من الشبكات العصبية الثلاث بالأجزاء التالية من الدماغ:
- الشبكات العصبية الاصطناعية (
ANNs): الفص الصدغي - الشبكات العصبية التلافيفية (
CNNs): الفص القذالي - الشبكات العصبية المتكررة (
RNNs): الفص الجبهي
بنية الشبكة العصبية المتكررة
دعنا الآن نناقش بنية الشبكة العصبية المتكررة. أولاً، تذكر أن بنية الشبكة العصبية الأساسية تبدو كما يلي:
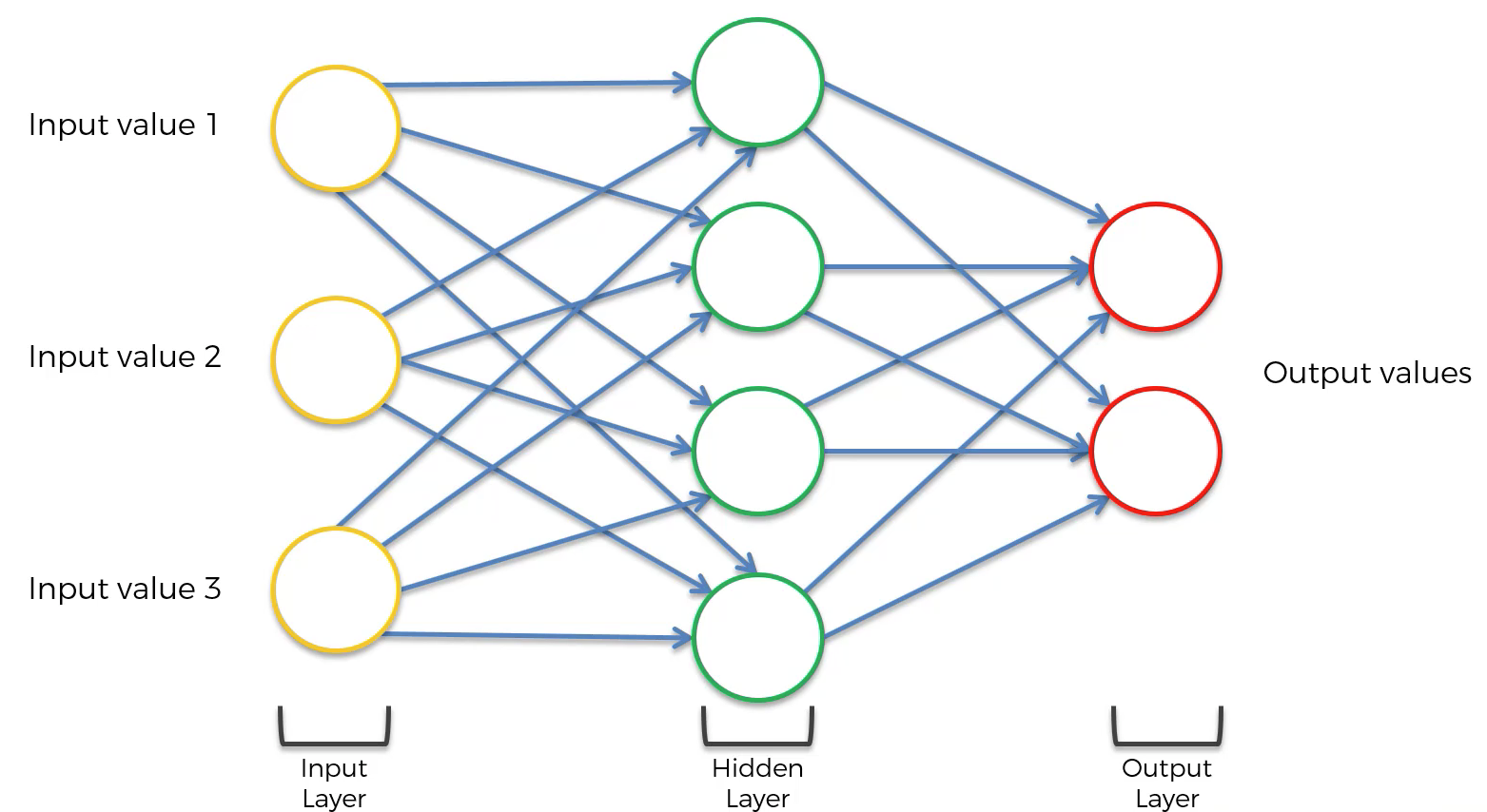
التعديل الأول الذي يجب إجراؤه على هذه الشبكة العصبية هو دمج كل طبقة من طبقات الشبكة معًا، بهذا الشكل:
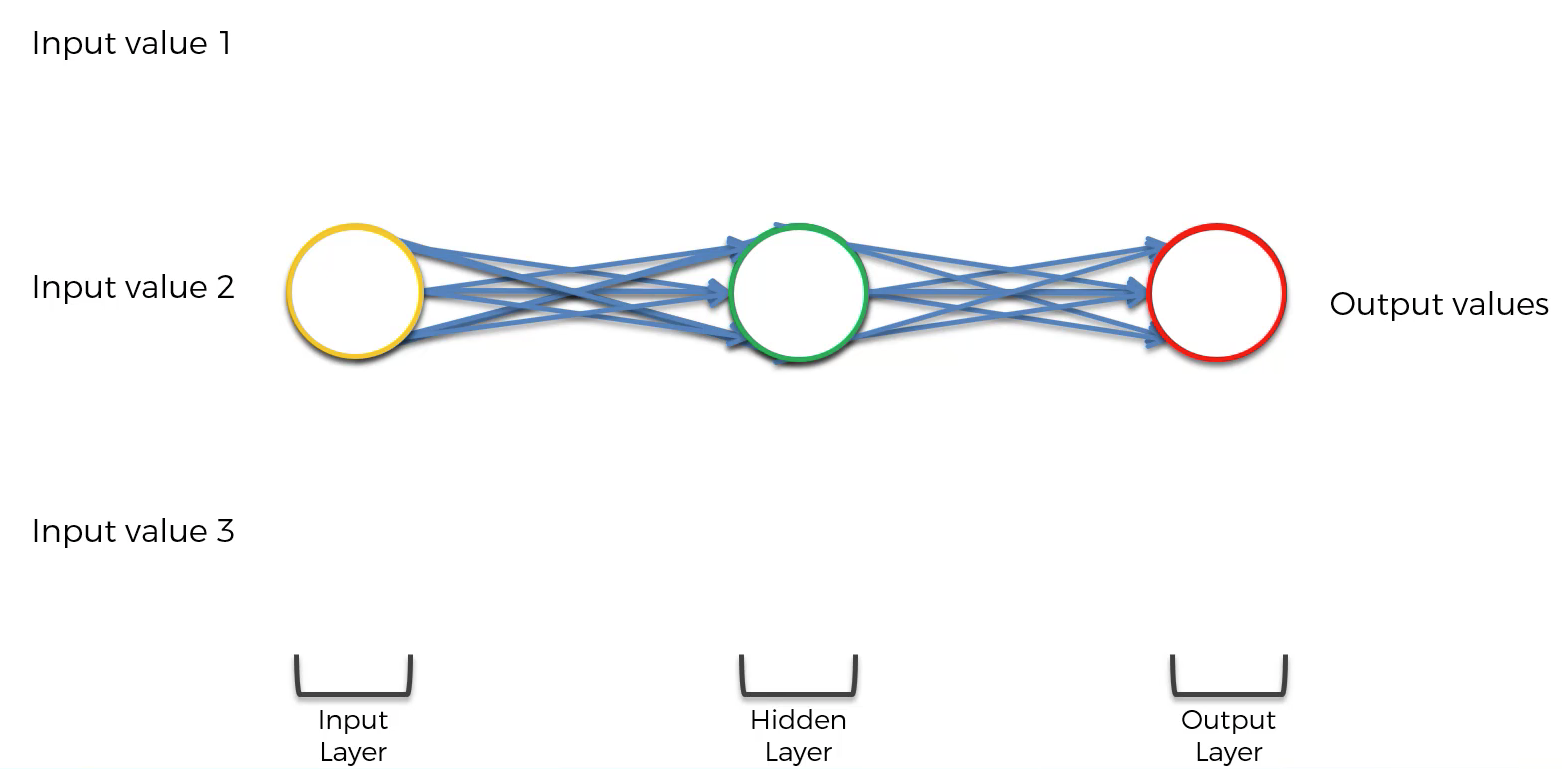
بعد ذلك، يجب إجراء ثلاثة تعديلات أخرى:
- يجب تبسيط وصلات الخلايا العصبية في الشبكة العصبية إلى خط واحد.
- يجب تدوير الشبكة العصبية بأكملها 90 درجة.
- يجب إنشاء حلقة حول الطبقة المخفية للشبكة العصبية.
ستظهر الشبكة العصبية الآن بالشكل التالي:
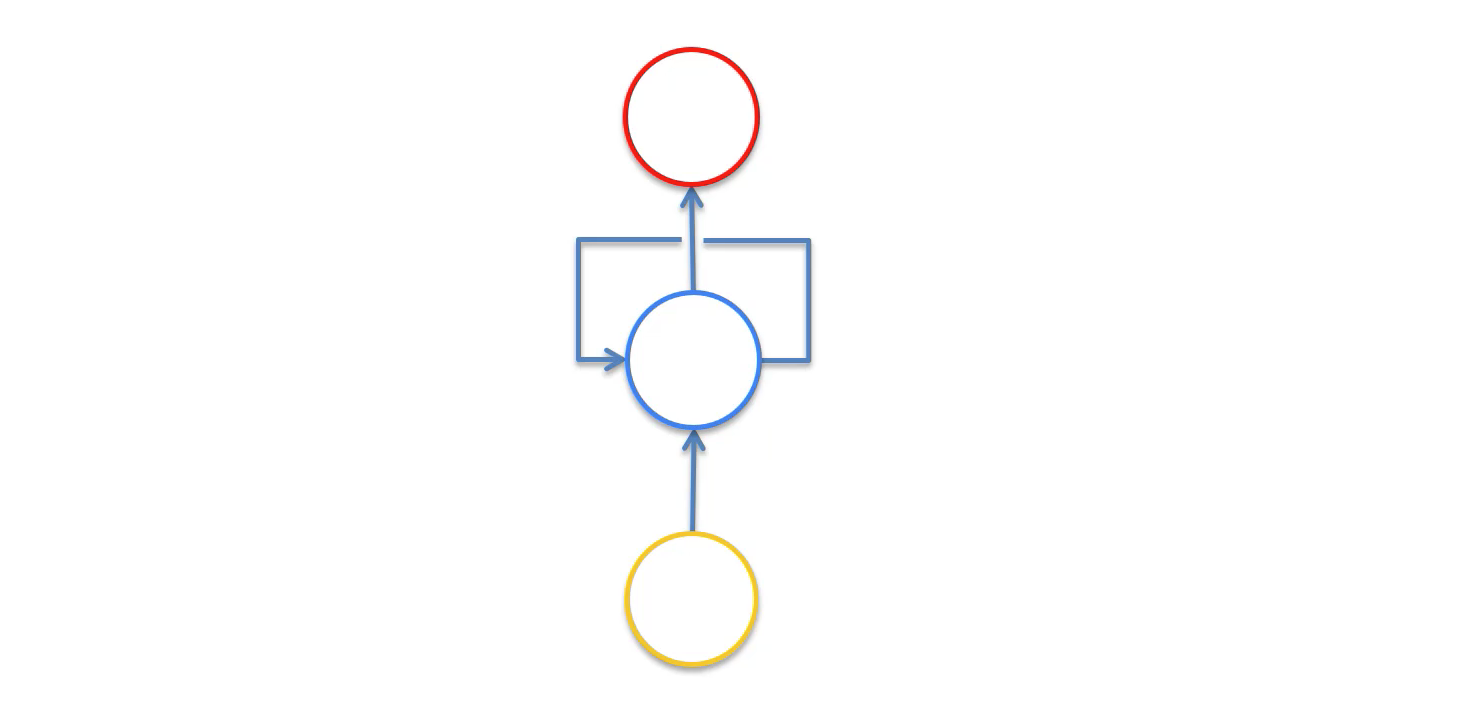
يُطلق على الخط الذي يحيط بالطبقة المخفية للشبكة العصبية المتكررة اسم “الحلقة الزمنية” (temporal loop). يُستخدم هذا للإشارة إلى أن الطبقة المخفية لا تولد مخرجًا فحسب، بل يتم تغذية هذا المخرج مرة أخرى كمدخل إلى نفس الطبقة.
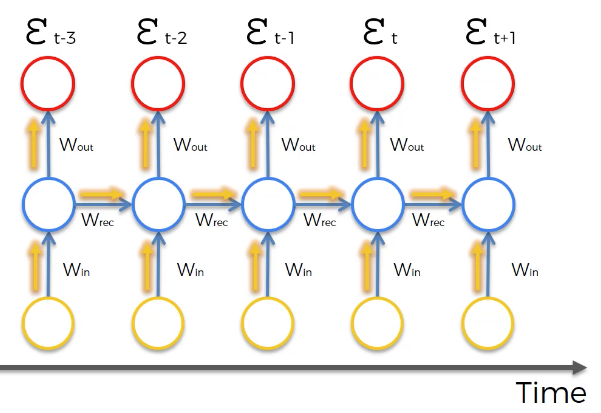
يُعد التصور مفيدًا في فهم هذا المفهوم. كما ترون في الصورة التالية، لا تُستخدم الطبقة المخفية المطبقة على ملاحظة محددة من مجموعة البيانات لتوليد مخرج لتلك الملاحظة فحسب، بل تُستخدم أيضًا لتدريب الطبقة المخفية للملاحظة التالية.
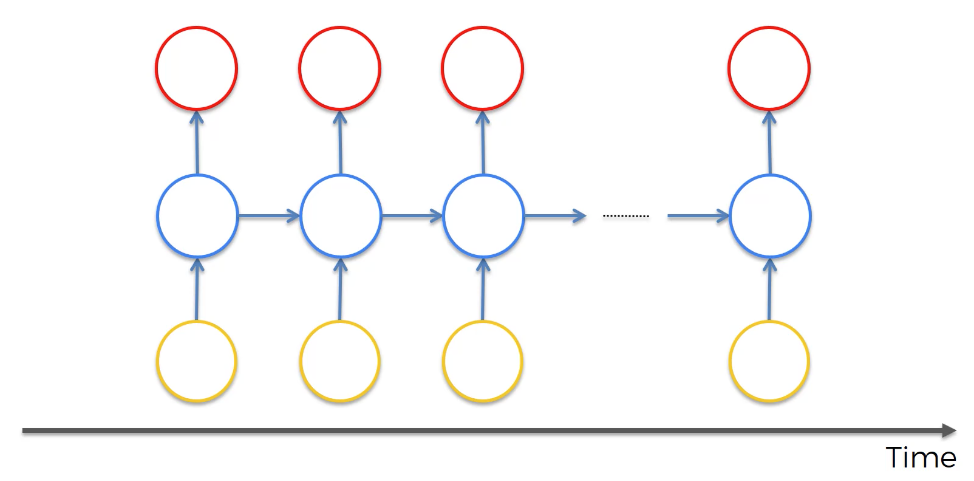
هذه الخاصية، التي تجعل ملاحظة واحدة تساعد في تدريب الملاحظة التالية، هي السبب في أن الشبكات العصبية المتكررة مفيدة جدًا في حل مشكلات تحليل السلاسل الزمنية.
مشكلة التدرج المتلاشي في الشبكات العصبية المتكررة
تاريخيًا، كانت مشكلة التدرج المتلاشي (vanishing gradient problem) واحدة من أكبر العقبات أمام نجاح الشبكات العصبية المتكررة. لهذا السبب، يُعد فهم هذه المشكلة أمرًا بالغ الأهمية قبل بناء أول شبكة RNN خاصة بك. سيشرح هذا القسم مشكلة التدرج المتلاشي بلغة واضحة، بما في ذلك مناقشة الحلول الأكثر فائدة لهذه المشكلة المثيرة للاهتمام.
ما هي مشكلة التدرج المتلاشي؟
قبل أن نتعمق في تفاصيل مشكلة التدرج المتلاشي، من المفيد أن يكون لدينا بعض الفهم لكيفية اكتشاف المشكلة في البداية. اكتشف مشكلة التدرج المتلاشي العالم الألماني في علوم الحاسوب Sepp Hochreiter، الذي كان له دور مؤثر في تطوير الشبكات العصبية المتكررة في التعلم العميق.
الآن دعنا نستكشف مشكلة التدرج المتلاشي بالتفصيل. كما يوحي اسمها، ترتبط مشكلة التدرج المتلاشي بخوارزميات انحدار التدرج (gradient descent algorithms) في التعلم العميق. تذكر أن خوارزمية انحدار التدرج تبدو كالتالي:
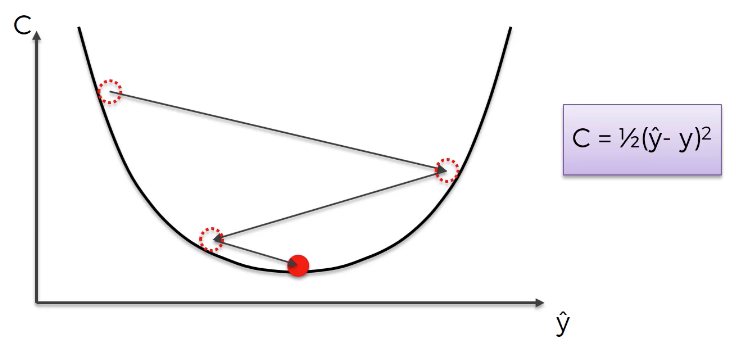
ثم تُدمج خوارزمية انحدار التدرج هذه مع خوارزمية الانتشار العكسي (backpropagation algorithm) لتحديث أوزان الوصلات العصبية في جميع أنحاء الشبكة العصبية. تتصرف الشبكات العصبية المتكررة بشكل مختلف قليلاً لأن الطبقة المخفية لملاحظة واحدة تُستخدم لتدريب الطبقة المخفية للملاحظة التالية.
هذا يعني أن دالة التكلفة (cost function) للشبكة العصبية تُحسب لكل ملاحظة في مجموعة البيانات. تُصوّر قيم دالة التكلفة هذه في الجزء العلوي من الصورة التالية:
تحدث مشكلة التدرج المتلاشي عندما تتحرك خوارزمية الانتشار العكسي إلى الخلف عبر جميع الخلايا العصبية في الشبكة العصبية لتحديث أوزانها. تعني طبيعة الشبكات العصبية المتكررة أن دالة التكلفة المحسوبة في طبقة عميقة من الشبكة العصبية ستُستخدم لتغيير أوزان الخلايا العصبية في الطبقات الأقل عمقًا.
العملية الحسابية التي تحسب هذا التغيير هي عملية ضربية (multiplicative)، مما يعني أن التدرج المحسوب في خطوة عميقة داخل الشبكة العصبية سيُضرب مرة أخرى عبر الأوزان في وقت مبكر من الشبكة. بعبارة أخرى، يتم “تخفيف” التدرج المحسوب في عمق الشبكة مع تحركه إلى الخلف عبر الشبكة، مما قد يتسبب في تلاشي التدرج – ومن هنا جاء اسم مشكلة التدرج المتلاشي!
يُشار إلى العامل الفعلي الذي يُضرب عبر الشبكة العصبية المتكررة في خوارزمية الانتشار العكسي بالمتغير الرياضي Wrec. يطرح هذا مشكلتين:
- عندما يكون
Wrecصغيرًا، تواجه مشكلة التدرج المتلاشي (vanishing gradient problem). - عندما يكون
Wrecكبيرًا، تواجه مشكلة التدرج المتفجر (exploding gradient problem).
لاحظ أن كلتا هاتين المشكلتين يُشار إليهما عمومًا بالاسم الأبسط “مشكلة التدرج المتلاشي”.
لتلخيص ذلك، تنتج مشكلة التدرج المتلاشي عن الطبيعة الضربيه لخوارزمية الانتشار العكسي. وهذا يعني أن التدرجات المحسوبة في مرحلة عميقة من الشبكة العصبية المتكررة يكون لها إما تأثير صغير جدًا (في مشكلة التدرج المتلاشي) أو تأثير كبير جدًا (في مشكلة التدرج المتفجر) على أوزان الخلايا العصبية الموجودة في طبقات أقل عمقًا في الشبكة العصبية.
كيفية حل مشكلة التدرج المتلاشي
هناك عدد من الاستراتيجيات التي يمكن استخدامها لحل مشكلة التدرج المتلاشي. سنستكشف استراتيجيات لكل من مشكلتي التدرج المتلاشي والتدرج المتفجر بشكل منفصل. دعنا نبدأ بالأخيرة.
حل مشكلة التدرج المتفجر
بالنسبة للتدرجات المتفجرة، من الممكن استخدام نسخة معدلة من خوارزمية الانتشار العكسي تسمى truncated backpropagation. تحد خوارزمية الانتشار العكسي المقطوعة من عدد الخطوات الزمنية التي سيتم فيها إجراء الانتشار العكسي، مما يوقف الخوارزمية قبل حدوث مشكلة التدرج المتفجر. يمكنك أيضًا إدخال “عقوبات” (penalties)، وهي تقنيات مبرمجة لتقليل تأثير الانتشار العكسي مع تحركه عبر الطبقات الأقل عمقًا في الشبكة العصبية. أخيرًا، يمكنك إدخال “قص التدرج” (gradient clipping)، والذي يضع سقفًا اصطناعيًا يحد من مدى كبر التدرج في خوارزمية الانتشار العكسي.
حل مشكلة التدرج المتلاشي
تُعد تهيئة الأوزان (weight initialization) إحدى التقنيات التي يمكن استخدامها لحل مشكلة التدرج المتلاشي. تتضمن هذه التقنية إنشاء قيمة أولية اصطناعية للأوزان في الشبكة العصبية لمنع خوارزمية الانتشار العكسي من تعيين أوزان صغيرة بشكل غير واقعي. يمكنك أيضًا استخدام شبكات حالة الصدى (echo state networks)، وهي نوع محدد من الشبكات العصبية مصمم لتجنب مشكلة التدرج المتلاشي. شبكات حالة الصدى خارج نطاق هذا الدليل؛ يكفي معرفة وجودها في الوقت الحالي.
الحل الأهم لمشكلة التدرج المتلاشي هو نوع محدد من الشبكات العصبية يسمى شبكات الذاكرة طويلة المدى (Long Short-Term Memory Networks أو LSTMs)، والتي كان رائداها Sepp Hochreiter و Jürgen Schmidhuber. تذكر أن السيد هوخرايتر هو العالم الذي اكتشف مشكلة التدرج المتلاشي في الأصل.
تُستخدم شبكات LSTMs في المشكلات المتعلقة بشكل أساسي بالتعرف على الكلام، ومن أبرز الأمثلة على ذلك استخدام Google لشبكة LSTM للتعرف على الكلام في عام 2015، مما أدى إلى انخفاض بنسبة 49% في أخطاء النسخ. تُعتبر شبكات LSTMs الشبكة العصبية المفضلة للعلماء المهتمين بتطبيق الشبكات العصبية المتكررة. سنركز بشكل كبير على شبكات LSTMs خلال ما تبقى من هذا الدليل.
شبكات الذاكرة طويلة المدى (LSTMs)
شبكات الذاكرة طويلة المدى (Long Short-Term Memory networks أو LSTMs) هي نوع من الشبكات العصبية المتكررة (RNNs) تُستخدم لحل مشكلة التدرج المتلاشي. تختلف هذه الشبكات عن الشبكات العصبية المتكررة “العادية” بطرق مهمة. سيعرفك هذا الدليل على شبكات LSTMs. لاحقًا في هذا الدليل، سنقوم ببناء وتدريب شبكة LSTM من الصفر.
يمكنك الانتقال إلى قسم محدد من هذا الدرس التطبيقي حول LSTM باستخدام جدول المحتويات أدناه:
- تاريخ شبكات الـ
LSTMs - كيف تحل شبكات الـ
LSTMsمشكلة التدرج المتلاشي - آلية عمل شبكات الـ
LSTMs - تنوعات بنية شبكات الـ
LSTM - تنوع “فتحة النظر” (
Peephole Variation) - تنوع “البوابة المزدوجة” (
Coupled Gate Variation) - تنوعات أخرى لشبكات الـ
LSTM
تاريخ شبكات الـ LSTM
كما ألمحنا في القسم الأخير، فإن أهم شخصيتين في مجال شبكات LSTMs هما Sepp Hochreiter و Jürgen Schmidhuber. كان الأخير مشرف دكتوراه للأول في الجامعة التقنية في ميونيخ بألمانيا. قدمت أطروحة دكتوراه هوخرايتر شبكات LSTMs للعالم لأول مرة.
كيف تحل شبكات الـ LSTM مشكلة التدرج المتلاشي؟
في الدرس التطبيقي الأخير، تعلمنا كيف يمكن أن يؤدي مصطلح Wrec في خوارزمية الانتشار العكسي (backpropagation algorithm) إلى مشكلة التدرج المتلاشي أو مشكلة التدرج المتفجر. استكشفنا حلولاً مختلفة محتملة لهذه المشكلة، بما في ذلك العقوبات (penalties)، وقص التدرج (gradient clipping)، وحتى شبكات حالة الصدى (echo state networks). ومع ذلك، تُعد شبكات LSTMs هي الحل الأفضل.
إذًا، كيف تعمل شبكات LSTMs؟ إنها ببساطة تغير قيمة Wrec. في شرحنا لمشكلة التدرج المتلاشي، تعلمت أن:
- عندما يكون
Wrecصغيرًا، تواجه مشكلة التدرج المتلاشي. - عندما يكون
Wrecكبيرًا، تواجه مشكلة التدرج المتفجر.
يمكننا أن نكون أكثر تحديدًا:
- عندما يكون
Wrec < 1، تواجه مشكلة التدرج المتلاشي. - عندما يكون
Wrec > 1، تواجه مشكلة التدرج المتفجر.
هذا منطقي إذا فكرت في الطبيعة الضربيه لخوارزمية الانتشار العكسي. إذا كان لديك رقم أصغر من 1 وضربته في نفسه مرارًا وتكرارًا، فستنتهي برقم يتلاشى. وبالمثل، فإن ضرب رقم أكبر من 1 في نفسه عدة مرات يؤدي إلى رقم كبير جدًا.
لحل هذه المشكلة، تضبط شبكات LSTMs قيمة Wrec = 1. بالتأكيد هناك ما هو أكثر في شبكات LSTMs من مجرد ضبط Wrec = 1، ولكن هذا هو بالتأكيد التغيير الأهم الذي يجريه هذا النوع من الشبكات العصبية المتكررة.
آلية عمل شبكات الـ LSTM
سيشرح هذا القسم كيفية عمل شبكات LSTMs. قبل المتابعة، تجدر الإشارة إلى أنني سأستخدم صورًا من تدوينة Christopher Olah بعنوان “فهم شبكات الـ LSTMs” (Understanding LSTMs)، والتي نُشرت في أغسطس 2015 وتحتوي على بعض من أفضل تصورات LSTM التي رأيتها على الإطلاق.
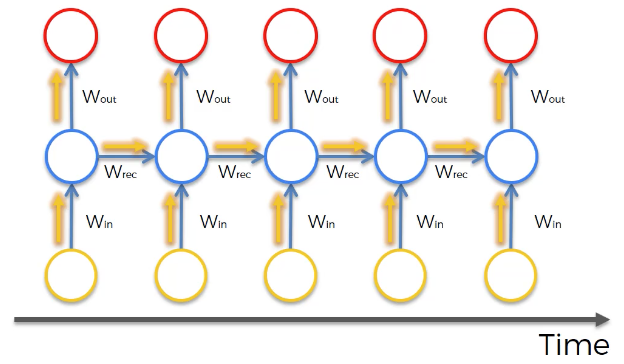
للبدء، دعنا نلقي نظرة على النسخة الأساسية من الشبكة العصبية المتكررة:
تحتوي هذه الشبكة العصبية على خلايا عصبية ووصلات عصبية تنقل المجاميع الموزونة للمخرجات من طبقة كمدخلات للطبقة التالية. ستتحرك خوارزمية الانتشار العكسي إلى الخلف عبر هذه الخوارزمية وتحدث أوزان كل خلية عصبية استجابةً لدالة التكلفة المحسوبة في كل حقبة من مرحلة تدريبها. على النقيض، إليك كيف تبدو شبكة LSTM:
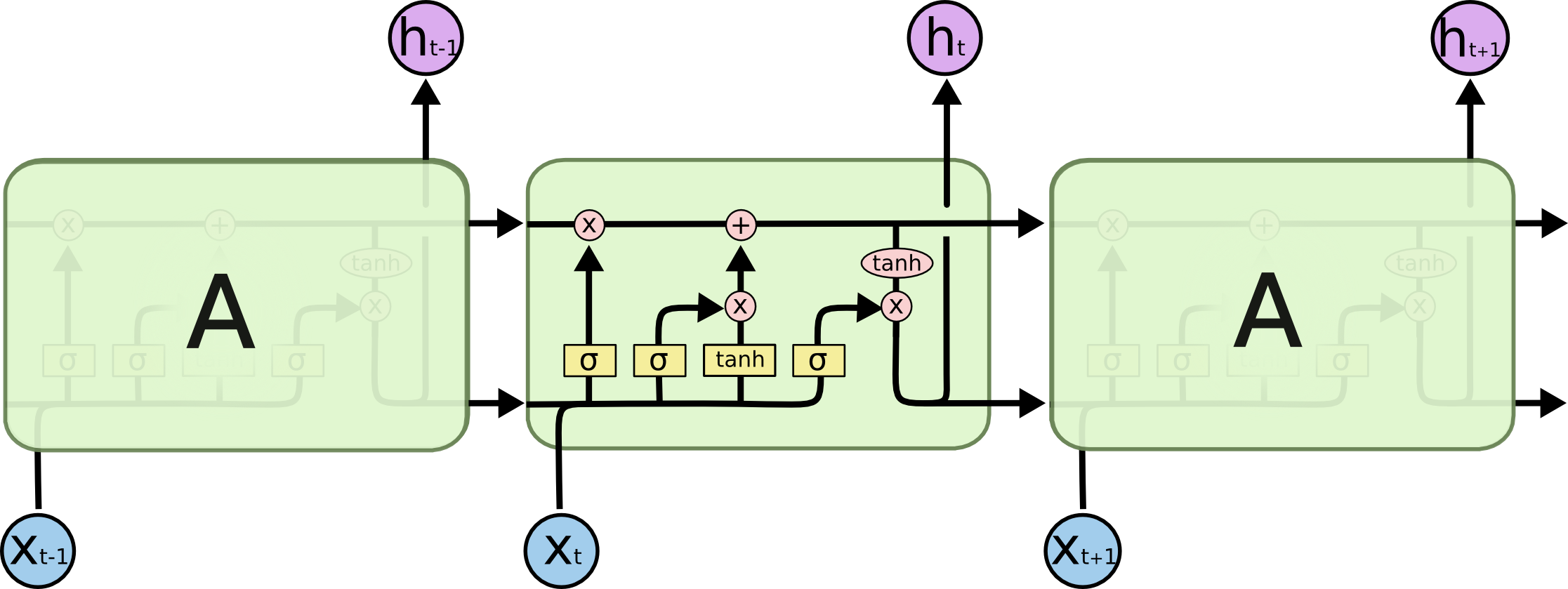
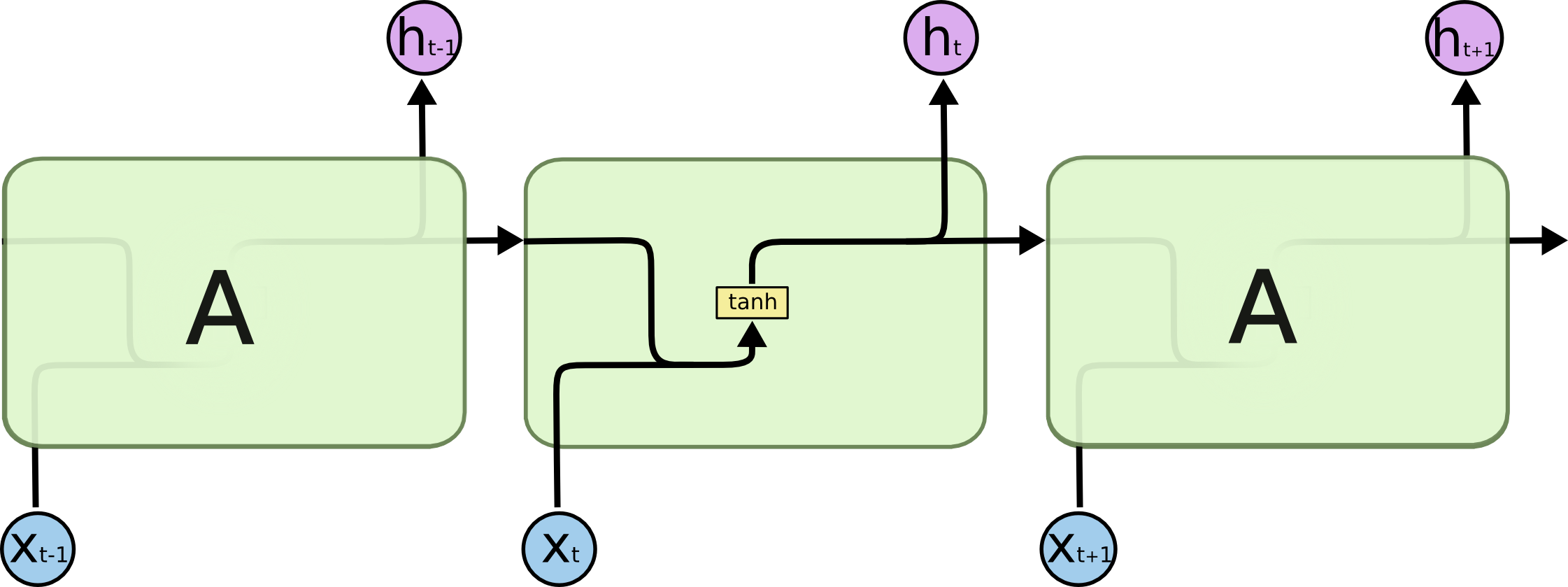
كما ترون، تحتوي شبكة LSTM على تعقيد متأصل أكبر بكثير من الشبكة العصبية المتكررة العادية. هدفي هو أن تتمكن من فهم هذه الصورة بالكامل بحلول الوقت الذي تنهي فيه هذا الدرس التطبيقي.
أولاً، دعنا نتعرف على الرموز المستخدمة في الصورة أعلاه:

الآن بعد أن أصبح لديك فكرة عن الرموز التي سنستخدمها في هذا الدرس التطبيقي حول LSTM، يمكننا البدء في فحص وظائف الطبقة داخل شبكة LSTM العصبية. كل طبقة لها المظهر التالي:
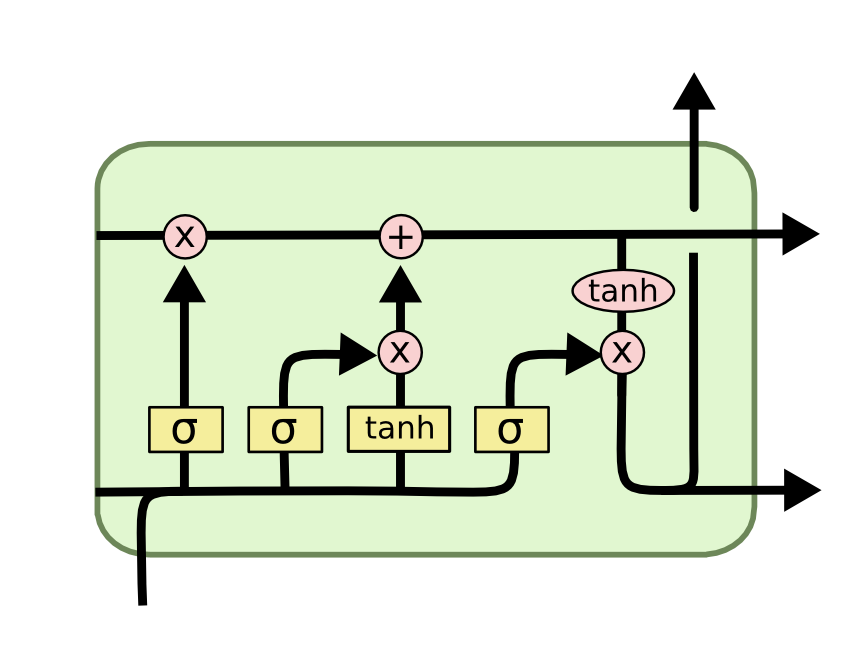
قبل أن نتعمق في وظائف العقد داخل شبكة LSTM العصبية، تجدر الإشارة إلى أن كل مدخل ومخرج لهذه النماذج التعلم العميق هو متجه (vector). في بايثون، يُعبر عن ذلك عمومًا بواسطة مصفوفة NumPy أو بنية بيانات أخرى أحادية البعد.
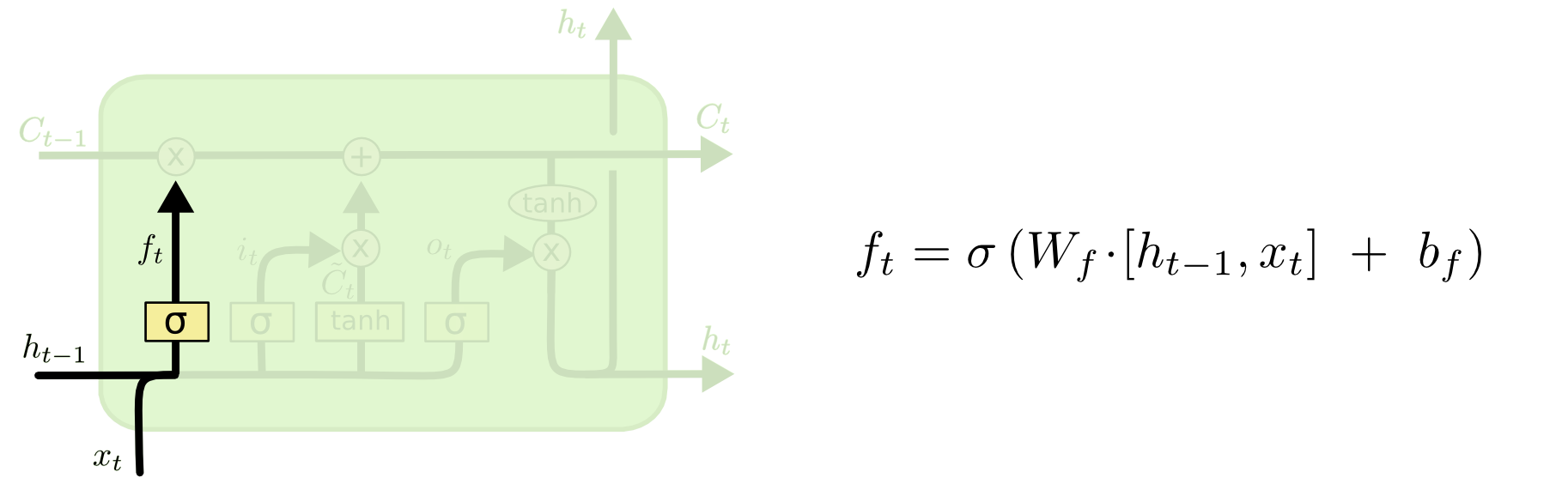
أول ما يحدث داخل شبكة LSTM هو دالة التنشيط (activation function) لطبقة “بوابة النسيان” (forget gate layer). تنظر هذه الطبقة إلى مدخلات الطبقة (المُشار إليها بـ xt للملاحظة و ht لمخرج الطبقة السابقة من الشبكة العصبية) وتخرج إما 1 أو 0 لكل رقم في حالة الخلية (cell state) من الطبقة السابقة (المُشار إليها بـ Ct-1). إليك تصور لتنشيط طبقة بوابة النسيان:
لم نناقش حالة الخلية بعد، لذا دعنا نفعل ذلك الآن. تُمثل حالة الخلية في مخططنا بالخط الأفقي الطويل الذي يمر عبر الجزء العلوي من المخطط. على سبيل المثال، إليك حالة الخلية في تصوراتنا:
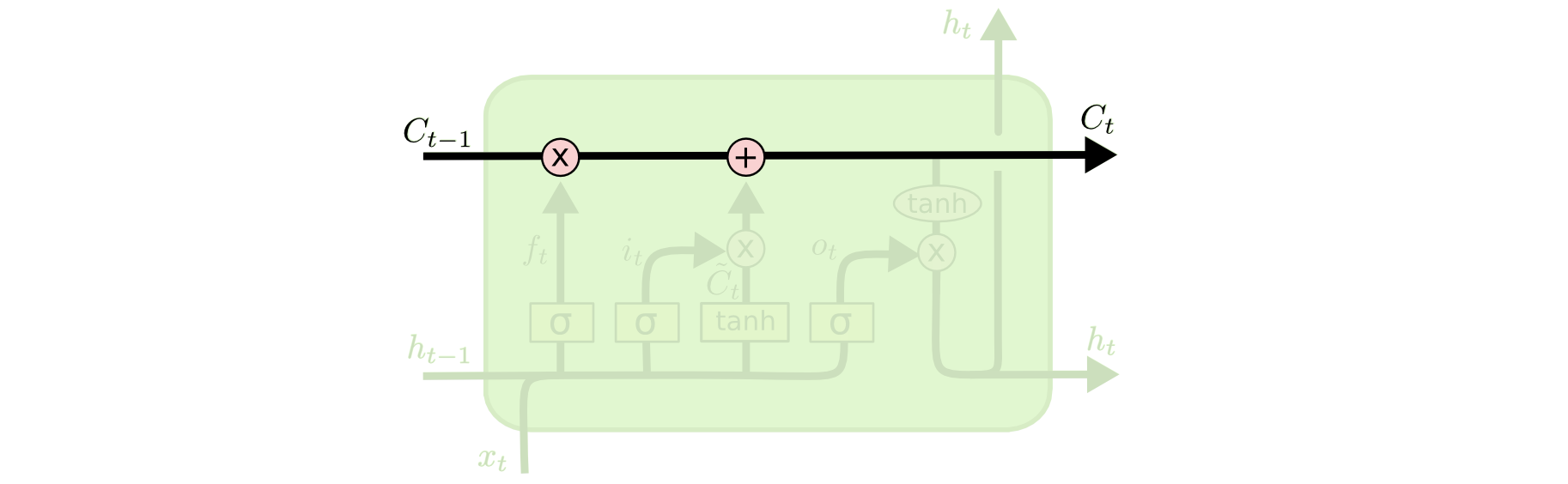
الغرض من حالة الخلية هو تحديد المعلومات التي يجب نقلها من الملاحظات المختلفة التي تُدرب عليها الشبكة العصبية المتكررة. يتخذ قرار نقل المعلومات من عدمه بواسطة “البوابات” (gates) – التي تُعد بوابة النسيان مثالاً رئيسيًا عليها. ستبدو كل بوابة داخل شبكة LSTM بالشكل التالي:
يشير الرمز σ داخل هذه البوابات إلى دالة السيجمويد (Sigmoid function)، والتي ربما رأيتها تُستخدم في نماذج التعلم الآلي للانحدار اللوجستي (logistic regression). تُستخدم دالة السيجمويد كنوع من دالة التنشيط في شبكات LSTMs التي تحدد المعلومات التي تمر عبر البوابة للتأثير على حالة الخلية في الشبكة. بحكم تعريفها، يمكن لدالة السيجمويد أن تُخرج أرقامًا بين 0 و 1 فقط. غالبًا ما تُستخدم لحساب الاحتمالات لهذا السبب. في حالة نماذج LSTM، تحدد نسبة كل مخرج يجب السماح له بالتأثير على حالة الخلية.
الخطوتان التاليتان في نموذج LSTM مترابطتان بشكل وثيق: “طبقة بوابة الإدخال” (input gate layer) و “طبقة tanh” (tanh layer). تعمل هذه الطبقات معًا لتحديد كيفية تحديث حالة الخلية. في الوقت نفسه، تُكمل الخطوة الأخيرة، والتي تسمح للخلية بتحديد ما يجب نسيانه بشأن الملاحظة الأخيرة في مجموعة البيانات. إليك تصور لهذه العملية:
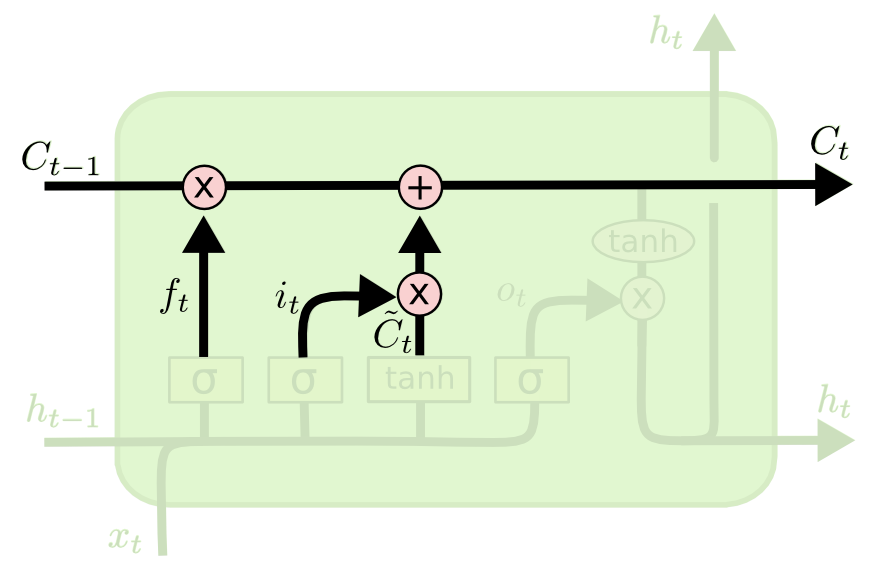
تحدد الخطوة الأخيرة من شبكة LSTM المخرج لهذه الملاحظة (المُشار إليه بـ ht). تمر هذه الخطوة عبر دالة سيجمويد ودالة الظل الزائدي (hyperbolic tangent function). يمكن تصورها كالتالي:
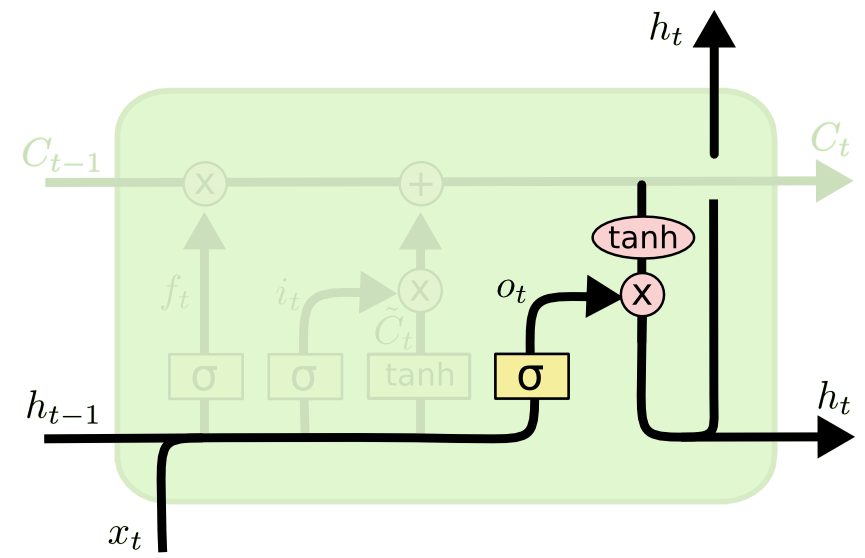
هذا يختتم عملية تدريب طبقة واحدة من نموذج LSTM. كما قد تتخيل، هناك الكثير من الرياضيات الكامنة تحت السطح التي تجاوزناها. الهدف من هذا القسم هو شرح كيفية عمل شبكات LSTMs بشكل عام، وليس فهم كل عملية في التفاصيل.
تنوعات بنية شبكات الـ LSTM
أردت أن أختتم هذا الدرس التطبيقي بمناقشة بعض التنوعات المختلفة لبنية LSTM التي تختلف قليلاً عن شبكة LSTM الأساسية التي ناقشناها حتى الآن. كتذكير سريع، إليك كيف تبدو عقدة معممة لشبكة LSTM:
تنوع “فتحة النظر” (Peephole Variation)
ربما يكون أهم تنوع في بنية LSTM هو “تنوع فتحة النظر” (peephole variant)، والذي يسمح لطبقات البوابة بقراءة البيانات من حالة الخلية. إليك تصور لما قد يبدو عليه تنوع فتحة النظر:
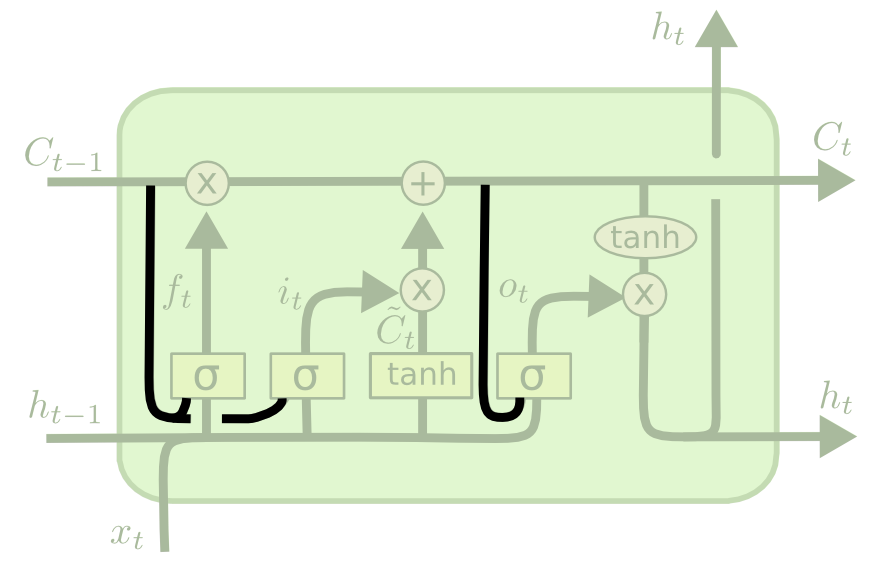
لاحظ أنه بينما يضيف هذا المخطط فتحة نظر إلى كل بوابة في الشبكة العصبية المتكررة، يمكنك أيضًا إضافة فتحات نظر إلى بعض البوابات وليس كلها.
تنوع “البوابة المزدوجة” (Coupled Gate Variation)
هناك تنوع آخر لبنية LSTM حيث يتخذ النموذج قرار ما يجب نسيانه وما يجب إضافة معلومات جديدة إليه معًا. في نموذج LSTM الأصلي، كانت هذه القرارات تُتخذ بشكل منفصل. إليك تصور لما تبدو عليه هذه البنية:
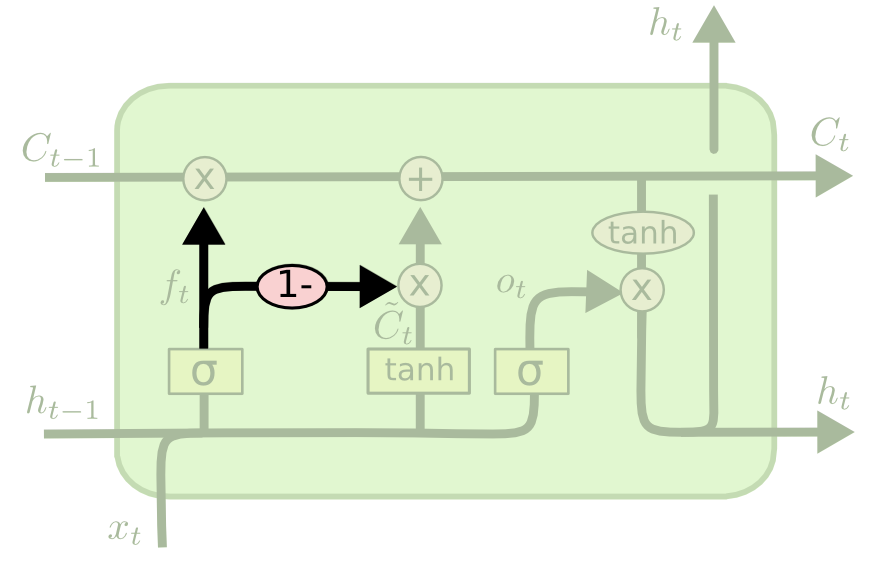
تنوعات أخرى لشبكات الـ LSTM
هذه مجرد مثالين على تنوعات بنية LSTM. هناك العديد غيرها. فيما يلي بعض الأمثلة:
- الوحدات المتكررة ذات البوابات (
Gated Recurrent UnitsأوGRUs) - شبكات
RNNsذات البوابات العميقة (Depth Gated RNNs) - شبكات
RNNsذات الساعة (Clockwork RNNs)
بناء وتدريب شبكة عصبية متكررة
حتى الآن في مناقشتنا للشبكات العصبية المتكررة، تعلمت ما يلي:
- المفهوم الأساسي وراء الشبكات العصبية المتكررة.
- مشكلة التدرج المتلاشي التي أعاقت تقدم الشبكات العصبية المتكررة تاريخيًا.
- كيف تساعد شبكات الذاكرة طويلة المدى (
LSTMs) في حل مشكلة التدرج المتلاشي.
لقد حان الوقت الآن لبناء أول شبكة عصبية متكررة خاصة بك! وبشكل أكثر تحديدًا، سيعلمك هذا الدرس التطبيقي كيفية بناء وتدريب شبكة LSTM للتنبؤ بسعر سهم Facebook (FB).
يمكنك الانتقال إلى قسم محدد من هذا الدرس التطبيقي حول الشبكات العصبية المتكررة في بايثون باستخدام جدول المحتويات أدناه:
- تنزيل مجموعة البيانات لهذا الدرس التطبيقي
- استيراد المكتبات اللازمة لهذا الدرس التطبيقي
- استيراد مجموعة بيانات التدريب إلى سكربت بايثون
- تطبيق تحجيم الميزات على مجموعة البيانات
- تحديد عدد الخطوات الزمنية للشبكة العصبية المتكررة
- الانتهاء من مجموعات البيانات بتحويلها إلى مصفوفات
NumPy - استيراد مكتبات
TensorFlow - بناء الشبكة العصبية المتكررة
- إضافة طبقة
LSTMالأولى - إضافة بعض تنظيم الانقطاع (
Dropout Regularization) - إضافة ثلاث طبقات
LSTMإضافية مع تنظيم الانقطاع - إضافة طبقة الإخراج للشبكة العصبية المتكررة
- تجميع الشبكة العصبية المتكررة
- تدريب الشبكة العصبية المتكررة على مجموعة التدريب
- إجراء التنبؤات باستخدام الشبكة العصبية المتكررة
- استيراد بيانات الاختبار
- بناء مجموعة بيانات الاختبار اللازمة للتنبؤات
- تحجيم بيانات الاختبار
- تجميع بيانات الاختبار
- إجراء التنبؤات فعليًا
- الكود الكامل لهذا الدرس التطبيقي
تنزيل مجموعة البيانات لهذا الدرس التطبيقي
للمتابعة في هذا الدرس التطبيقي، ستحتاج إلى تنزيل مجموعتي بيانات:
- مجموعة بيانات تدريب تحتوي على معلومات حول سعر سهم
Facebookمن بداية عام 2015 إلى نهاية عام 2019. - مجموعة بيانات اختبار تحتوي على معلومات حول سعر سهم
Facebookخلال الشهر الأول من عام 2020.
سيتم تدريب شبكتنا العصبية المتكررة على بيانات 2015-2019 وستُستخدم للتنبؤ ببيانات يناير 2020. يمكنك تنزيل بيانات التدريب وبيانات الاختبار باستخدام الروابط أدناه:
كل من مجموعتي البيانات هاتين هما ببساطة صادرات من Yahoo! Finance. تبدوان بهذا الشكل (عند فتحهما في Microsoft Excel):

بمجرد تنزيل الملفات، انقلها إلى الدليل الذي ترغب في العمل فيه وافتح Jupyter Notebook.
استيراد المكتبات اللازمة لهذا الدرس التطبيقي
سيعتمد هذا الدرس التطبيقي على عدد من مكتبات بايثون مفتوحة المصدر، بما في ذلك NumPy و pandas و matplotlib. دعنا نبدأ سكربت بايثون الخاص بنا باستيراد بعض هذه المكتبات:
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltاستيراد مجموعة بيانات التدريب إلى سكربت بايثون
المهمة التالية التي يجب إكمالها هي استيراد مجموعة البيانات الخاصة بنا إلى سكربت بايثون. سنقوم في البداية باستيراد مجموعة البيانات كـ pandas DataFrame باستخدام طريقة read_csv. ومع ذلك، نظرًا لأن وحدة keras من TensorFlow تقبل فقط مصفوفات NumPy كمعلمات، ستحتاج بنية البيانات إلى التحويل بعد الاستيراد. دعنا نبدأ باستيراد ملف .csv بالكامل كـ DataFrame:
training_data = pd.read_csv('FB_training_data.csv')ستلاحظ عند النظر إلى DataFrame أنه يحتوي على العديد من الطرق المختلفة لقياس سعر سهم Facebook، بما في ذلك سعر الافتتاح (opening price)، وسعر الإغلاق (closing price)، والأسعار المرتفعة والمنخفضة (high and low prices)، ومعلومات الحجم (volume information):
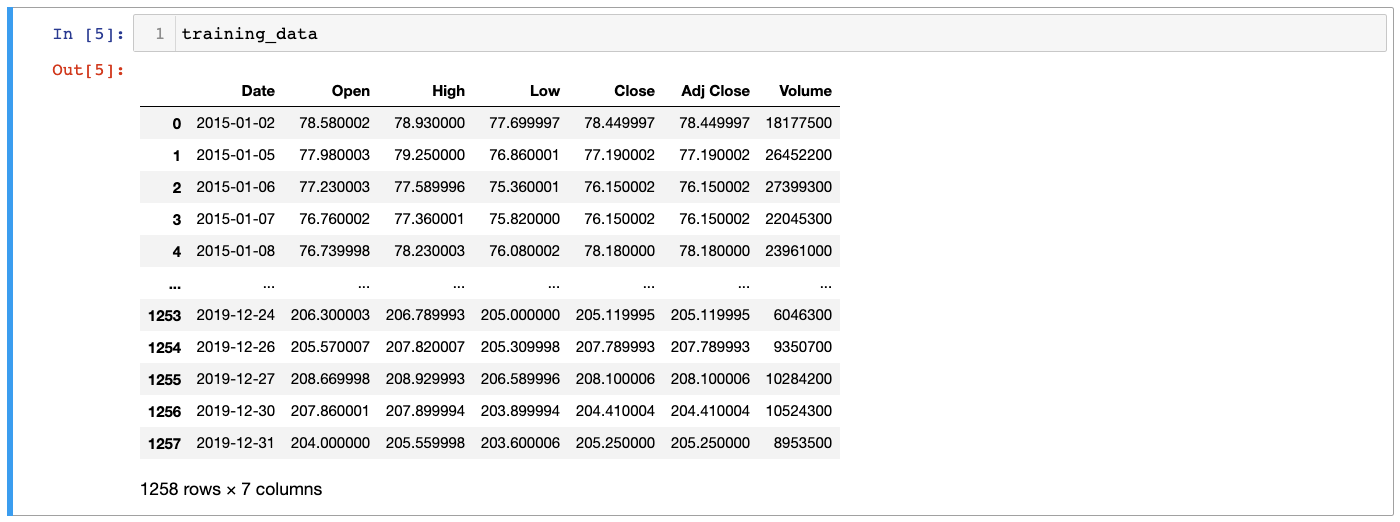
سنحتاج إلى تحديد نوع محدد من سعر السهم قبل المتابعة. دعنا نستخدم Close، الذي يشير إلى سعر الإغلاق غير المعدل لسهم Facebook. الآن نحتاج إلى تحديد هذا العمود من DataFrame وتخزينه في مصفوفة NumPy. إليك الأمر للقيام بذلك:
training_data = training_data.iloc[:, 1].valuesلاحظ أن هذا الأمر يحل محل المتغير training_data الحالي الذي أنشأناه سابقًا. يمكنك الآن التحقق من أن متغير training_data الخاص بنا هو بالفعل مصفوفة NumPy عن طريق تشغيل type(training_data)، والذي يجب أن يُرجع:
numpy.ndarrayتطبيق تحجيم الميزات على مجموعة البيانات
دعنا الآن نخصص بعض الوقت لتطبيق بعض تحجيم الميزات (feature scaling) على مجموعة البيانات الخاصة بنا. كتذكير سريع، هناك طريقتان رئيسيتان يمكنك من خلالهما تطبيق تحجيم الميزات على مجموعة البيانات الخاصة بك:
- توحيد القياس (
Standardization) - التطبيع (
Normalization)
سنستخدم التطبيع لبناء شبكتنا العصبية المتكررة، والذي يتضمن طرح القيمة الدنيا لمجموعة البيانات ثم القسمة على نطاق مجموعة البيانات. إليك دالة التطبيع المعرفة رياضيًا:
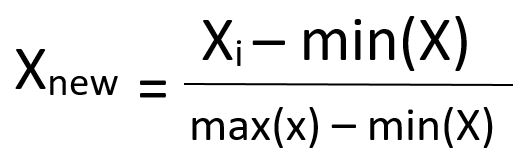
لحسن الحظ، تجعل مكتبة scikit-learn من السهل جدًا تطبيق التطبيع على مجموعة البيانات باستخدام فئتها MinMaxScaler. دعنا نبدأ باستيراد هذه الفئة إلى سكربت بايثون الخاص بنا. تعيش فئة MinMaxScaler داخل وحدة preprocessing من scikit-learn، لذا فإن الأمر لاستيراد الفئة هو:
from sklearn.preprocessing import MinMaxScalerبعد ذلك، نحتاج إلى إنشاء مثيل لهذه الفئة. سنقوم بتعيين الكائن الذي تم إنشاؤه حديثًا إلى متغير يسمى scaler. سنستخدم المعلمات الافتراضية لهذه الفئة، لذلك لا نحتاج إلى تمرير أي شيء:
scaler = MinMaxScaler()نظرًا لأننا لم نحدد أي معلمات غير افتراضية، فإن هذا سيقوم بتحجيم مجموعة البيانات الخاصة بنا بحيث تكون كل ملاحظة بين 0 و 1. لقد أنشأنا كائن scaler الخاص بنا ولكن مجموعة بيانات training_data لم يتم تحجيمها بعد. نحتاج إلى استخدام طريقة fit_transform لتعديل مجموعة البيانات الأصلية. إليك العبارة للقيام بذلك:
training_data = scaler.fit_transform(training_data.reshape(-1, 1))تحديد عدد الخطوات الزمنية للشبكة العصبية المتكررة
الشيء التالي الذي نحتاج إلى القيام به هو تحديد عدد “الخطوات الزمنية” (timesteps) لدينا. تحدد الخطوات الزمنية عدد الملاحظات السابقة التي يجب مراعاتها عندما تقوم الشبكة العصبية المتكررة بإجراء تنبؤ حول الملاحظة الحالية. سنستخدم 40 خطوة زمنية في هذا الدرس التطبيقي. هذا يعني أنه لكل يوم تتنبأ به الشبكة العصبية، ستأخذ في الاعتبار أسعار الأسهم للأربعين يومًا السابقة لتحديد مخرجها. لاحظ أنه نظرًا لوجود حوالي 20 يوم تداول فقط في شهر معين، فإن استخدام 40 خطوة زمنية يعني أننا نعتمد على بيانات سعر السهم من الشهرين السابقين.
إذًا، كيف نحدد عدد الخطوات الزمنية فعليًا داخل سكربت بايثون الخاص بنا؟ يتم ذلك من خلال إنشاء هيكلين خاصين للبيانات:
- هيكل بيانات سنسميه
x_training_dataيحتوي على آخر 40 ملاحظة لسعر السهم في مجموعة البيانات. هذه هي البيانات التي ستستخدمها الشبكة العصبية المتكررة لإجراء التنبؤات. - هيكل بيانات سنسميه
y_training_dataيحتوي على سعر السهم لليوم التالي. هذه هي نقطة البيانات التي تحاول الشبكة العصبية المتكررة التنبؤ بها.
للبدء، دعنا نهيئ كل من هياكل البيانات هذه كقائمة بايثون فارغة:
x_training_data = []
y_training_data =[]الآن سنستخدم حلقة for لملء البيانات الفعلية في كل من قوائم بايثون هذه. إليك الكود (مع مزيد من الشرح للكود بعد كتلة الكود):
for i in range(40, len(training_data)):
x_training_data.append(training_data[i -40 :i, 0])
y_training_data.append(training_data[i, 0])دعنا نفكك مكونات كتلة الكود هذه:
- تتسبب الدالة
range(40, len(training_data))في تكرار حلقةforمن40إلى الفهرس الأخير لبيانات التدريب. - يتسبب السطر
x_training_data.append(training_data[i-40:i, 0])في قيام الحلقة بإلحاق أسعار الأسهم الأربعين السابقة بـx_training_dataمع كل تكرار للحلقة. - وبالمثل، يتسبب السطر
y_training_data.append(training_data[i, 0])في قيام الحلقة بإلحاق سعر سهم اليوم التالي بـy_training_dataمع كل تكرار للحلقة.
تحويل مجموعات البيانات إلى مصفوفات NumPy
تم تصميم TensorFlow للعمل بشكل أساسي مع مصفوفات NumPy. لهذا السبب، آخر شيء نحتاج إلى القيام به هو تحويل قائمتي بايثون اللتين أنشأناهما للتو إلى مصفوفات NumPy. لحسن الحظ، هذا بسيط. ما عليك سوى تغليف قوائم بايثون في دالة np.array. إليك الكود:
x_training_data = np.array(x_training_data)
y_training_data = np.array(y_training_data)إحدى الطرق المهمة التي يمكنك من خلالها التأكد من أن سكربت الخاص بك يعمل كما هو متوقع هي التحقق من شكل (shape) كلتا مصفوفتي NumPy. يجب أن تكون مصفوفة x_training_data مصفوفة NumPy ثنائية الأبعاد، حيث يكون أحد الأبعاد 40 (عدد الخطوات الزمنية) والبعد الثاني هو len(training_data) - 40، والذي يُقيّم إلى 1218 في حالتنا. وبالمثل، يجب أن يكون كائن y_training_data مصفوفة NumPy أحادية الأبعاد بطول 1218 (وهو، مرة أخرى، len(training_data) - 40). يمكنك التحقق من شكل المصفوفات عن طريق طباعة خاصية shape الخاصة بها، هكذا:
print(x_training_data.shape)
print(y_training_data.shape)هذا يطبع:
(1218, 40)
(1218,)تتمتع كلتا المصفوفتين بالأبعاد التي تتوقعها. ومع ذلك، نحتاج إلى إعادة تشكيل كائن x_training_data مرة أخرى قبل الشروع في بناء شبكتنا العصبية المتكررة. والسبب في ذلك هو أن طبقة الشبكة العصبية المتكررة المتاحة في TensorFlow تقبل البيانات بتنسيق محدد جدًا. يمكنك قراءة وثائق TensorFlow حول هذا الموضوع هنا. لإعادة تشكيل كائن x_training_data، سأستخدم طريقة np.reshape. إليك الكود للقيام بذلك:
x_training_data = np.reshape(x_training_data, (x_training_data.shape[0], x_training_data.shape[1], 1))الآن دعنا نطبع شكل x_training_data مرة أخرى:
print(x_training_data.shape)هذا يخرج:
(1218, 40, 1)تتمتع مصفوفاتنا بالشكل المطلوب، لذا يمكننا المتابعة لبناء شبكتنا العصبية المتكررة.
استيراد مكتبات TensorFlow
قبل أن نتمكن من البدء في بناء شبكتنا العصبية المتكررة، سنحتاج إلى استيراد عدد من الفئات من TensorFlow. إليك العبارات التي يجب تشغيلها قبل المتابعة:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
from tensorflow.keras.layers import Dropoutبناء الشبكة العصبية المتكررة
لقد حان الوقت الآن لبناء شبكتنا العصبية المتكررة. أول شيء يجب القيام به هو تهيئة كائن من فئة Sequential في TensorFlow. كما يوحي اسمها، تم تصميم فئة Sequential لبناء الشبكات العصبية عن طريق إضافة تسلسلات من الطبقات بمرور الوقت. إليك الكود لتهيئة شبكتنا العصبية المتكررة:
rnn = Sequential()كما هو الحال مع شبكاتنا العصبية الاصطناعية (artificial neural networks) والشبكات العصبية التلافيفية (convolutional neural networks)، يمكننا إضافة المزيد من الطبقات إلى هذه الشبكة العصبية المتكررة باستخدام طريقة add.
إضافة طبقة LSTM الأولى
الطبقة الأولى التي سنضيفها هي طبقة LSTM. للقيام بذلك، قم بتمرير استدعاء لفئة LSTM (التي استوردناها للتو) إلى طريقة add. تقبل فئة LSTM عدة معلمات. وبشكل أكثر دقة، سنحدد ثلاث وسائط:
- عدد خلايا
LSTMالعصبية التي ترغب في تضمينها في هذه الطبقة. زيادة عدد الخلايا العصبية هي إحدى طرق زيادة أبعاد شبكتك العصبية المتكررة. في حالتنا، سنحددunits = 45. return_sequences = True– يجب تحديد هذا دائمًا إذا كنت تخطط لتضمين طبقةLSTMأخرى بعد الطبقة التي تضيفها. يجب عليك تحديدreturn_sequences = Falseلآخر طبقةLSTMفي شبكتك العصبية المتكررة.input_shape: عدد الخطوات الزمنية وعدد المتنبئات في بيانات التدريب لدينا. في حالتنا، نستخدم40خطوة زمنية و1متنبئ فقط (سعر السهم)، لذلك سنضيف.
إليك طريقة add الكاملة:
rnn.add(LSTM(units = 45, return_sequences = True, input_shape = (x_training_data.shape[1], 1)))لاحظ أنني استخدمت x_training_data.shape[1] بدلاً من القيمة المكتوبة يدويًا في حال قررنا تدريب الشبكة العصبية المتكررة على نموذج أكبر في وقت لاحق.
إضافة بعض تنظيم الانقطاع (Dropout Regularization)
تنظيم الانقطاع (Dropout regularization) هو تقنية تُستخدم لتجنب فرط التخصيص (overfitting) عند تدريب الشبكات العصبية. يتضمن ذلك استبعاد – أو “إسقاط” – مخرجات طبقات معينة بشكل عشوائي خلال مرحلة التدريب. يسهل TensorFlow تنفيذ تنظيم الانقطاع باستخدام فئة Dropout التي استوردناها سابقًا في سكربت بايثون الخاص بنا. تقبل فئة Dropout معلمة واحدة: معدل الانقطاع (dropout rate). يشير معدل الانقطاع إلى عدد الخلايا العصبية التي يجب إسقاطها في طبقة معينة من الشبكة العصبية. من الشائع استخدام معدل انقطاع بنسبة 20%. سنتبع هذا التقليد في شبكتنا العصبية المتكررة. إليك كيفية توجيه TensorFlow لإسقاط 20% من الخلايا العصبية في طبقة LSTM خلال كل تكرار من مرحلة التدريب:
rnn.add(Dropout(0.2))إضافة ثلاث طبقات LSTM إضافية مع تنظيم الانقطاع
سنضيف الآن ثلاث طبقات LSTM إضافية (مع تنظيم الانقطاع) إلى شبكتنا العصبية المتكررة. سترى أنه بعد تحديد طبقة LSTM الأولى، فإن إضافة المزيد أمر بسيط. لإضافة المزيد من الطبقات، كل ما يجب القيام به هو نسخ طريقتي add الأوليين مع تغيير صغير واحد. وهو أننا يجب أن نزيل وسيط input_shape من فئة LSTM. سنبقي عدد الخلايا العصبية (أو units) ومعدل الانقطاع كما هو في كل استدعاءات فئة LSTM. نظرًا لأن طبقة LSTM الثالثة التي نضيفها في هذا القسم ستكون آخر طبقة LSTM لدينا، يمكننا إزالة معلمة return_sequences = True كما ذكرنا سابقًا. إزالة المعلمة يضبط return_sequences إلى قيمتها الافتراضية False. إليك الكود الكامل لإضافة طبقات LSTM الثلاث التالية:
rnn.add(LSTM(units = 45, return_sequences = True))
rnn.add(Dropout(0.2))
rnn.add(LSTM(units = 45, return_sequences = True))
rnn.add(Dropout(0.2))
rnn.add(LSTM(units = 45))
rnn.add(Dropout(0.2))هذا الكود متكرر جدًا وينتهك مبدأ DRY (Don't Repeat Yourself) لتطوير البرمجيات. دعنا نضعه في حلقة بدلاً من ذلك:
for i in [True, True, False]:
rnn.add(LSTM(units = 45, return_sequences = i))
rnn.add(Dropout(0.2))إضافة طبقة الإخراج للشبكة العصبية المتكررة
دعنا ننهي تصميم شبكتنا العصبية المتكررة بإضافة طبقة الإخراج. ستكون طبقة الإخراج مثيلًا لفئة Dense، وهي نفس الفئة التي استخدمناها لإنشاء طبقة الاتصال الكاملة لشبكتنا العصبية التلافيفية في وقت سابق من هذا الدليل. المعلمة الوحيدة التي نحتاج إلى تحديدها هي units، وهو العدد المطلوب من الأبعاد التي يجب أن تولدها طبقة الإخراج. نظرًا لأننا نريد إخراج سعر سهم اليوم التالي (قيمة واحدة)، فسنحدد units = 1. إليك الكود لإنشاء طبقة الإخراج الخاصة بنا:
rnn.add(Dense(units = 1))تجميع الشبكة العصبية المتكررة
كما تتذكر من الدروس التطبيقية حول الشبكات العصبية الاصطناعية والشبكات العصبية التلافيفية، فإن خطوة التجميع (compilation step) لبناء شبكة عصبية هي حيث نحدد محسن الشبكة العصبية (optimizer) ودالة الخسارة (loss function) الخاصة بها. يسمح لنا TensorFlow بتجميع شبكة عصبية باستخدام طريقة compile التي تحمل اسمًا مناسبًا. تقبل وسيطين: optimizer و loss. دعنا نبدأ بإنشاء دالة compile فارغة:
rnn.compile(optimizer = '', loss = '')نحتاج الآن إلى تحديد معلمات optimizer و loss. دعنا نبدأ بمناقشة معلمة optimizer. تستخدم الشبكات العصبية المتكررة عادةً محسن RMSProp في مرحلة التجميع. ومع ذلك، سنستخدم محسن Adam (كما كان من قبل). محسن Adam هو محسن قوي ومفيد في مجموعة واسعة من بنيات الشبكات العصبية.
معلمة loss بسيطة إلى حد ما. نظرًا لأننا نتنبأ بمتغير مستمر، يمكننا استخدام متوسط الخطأ التربيعي (mean squared error) – تمامًا كما تفعل عند قياس أداء نموذج التعلم الآلي للانحدار الخطي (linear regression). هذا يعني أنه يمكننا تحديد loss = mean_squared_error. إليك طريقة compile النهائية:
rnn.compile(optimizer = 'adam', loss = 'mean_squared_error')تدريب الشبكة العصبية المتكررة على مجموعة التدريب
لقد حان الوقت الآن لتدريب شبكتنا المتكررة على بيانات التدريب الخاصة بنا. للقيام بذلك، نستخدم طريقة fit. تقبل طريقة fit أربعة وسائط في هذه الحالة:
- بيانات التدريب: في حالتنا، ستكون
x_training_dataوy_training_data. - الحقب (
Epochs): عدد التكرارات التي ترغب في تدريب الشبكة العصبية المتكررة عليها. سنحددepochs = 100في هذه الحالة. - حجم الدفعة (
The batch size): حجم الدفعات التي سيتم تدريب الشبكة بها خلال كل حقبة.
إليك الكود لتدريب هذه الشبكة العصبية المتكررة وفقًا لمواصفاتنا:
rnn.fit(x_training_data, y_training_data, epochs = 100, batch_size = 32)سيقوم Jupyter Notebook الآن بإنشاء عدد من المخرجات المطبوعة لكل حقبة في خوارزمية التدريب. تبدو كالتالي:
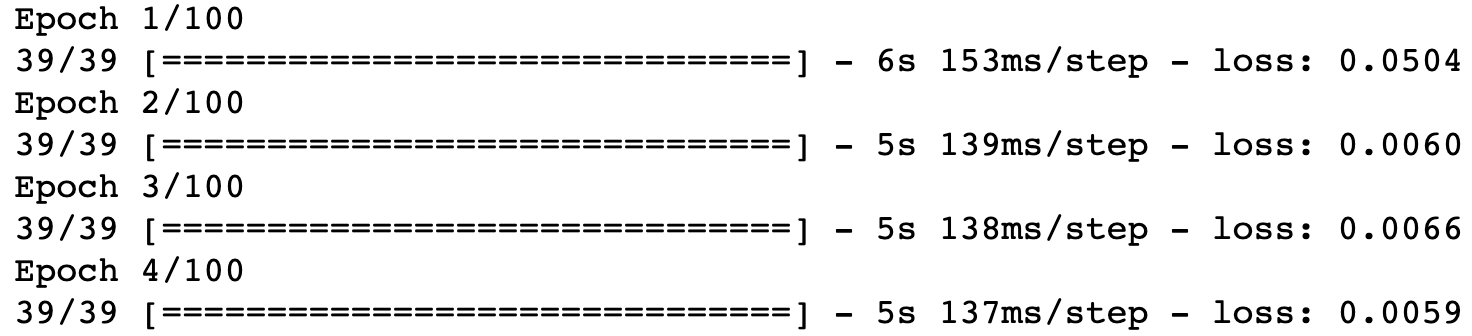
كما ترون، يوضح كل مخرج المدة التي استغرقتها الحقبة للحساب بالإضافة إلى دالة الخسارة المحسوبة في تلك الحقبة. يجب أن تروا قيمة دالة الخسارة تنخفض ببطء مع تدريب الشبكة العصبية المتكررة على بيانات التدريب بمرور الوقت. في حالتي، انخفضت قيمة دالة الخسارة من 0.0504 في التكرار الأول إلى 0.0017 في التكرار الأخير.
إجراء التنبؤات باستخدام الشبكة العصبية المتكررة
لقد قمنا ببناء شبكتنا العصبية المتكررة وتدريبها على بيانات سعر سهم Facebook على مدار السنوات الخمس الماضية. لقد حان الوقت الآن لإجراء بعض التنبؤات!
استيراد بيانات الاختبار
للبدء، دعنا نستورد بيانات سعر السهم الفعلية للشهر الأول من عام 2020. سيعطينا هذا شيئًا لمقارنة قيمنا المتوقعة به. إليك الكود للقيام بذلك. لاحظ أنه مشابه جدًا للكود الذي استخدمناه لاستيراد بيانات التدريب الخاصة بنا في بداية سكربت بايثون الخاص بنا:
test_data = pd.read_csv('FB_test_data.csv')
test_data = test_data.iloc[:, 1].valuesإذا قمت بتشغيل العبارة print(test_data.shape)، فستُرجع (21,). يوضح هذا أن بيانات الاختبار لدينا هي مصفوفة NumPy أحادية الأبعاد تحتوي على 21 إدخالًا – مما يعني أنه كان هناك 21 يوم تداول في سوق الأسهم في يناير 2020. يمكنك أيضًا إنشاء رسم بياني سريع للبيانات باستخدام plt.plot(test_data). يجب أن يولد هذا التصور التالي في بايثون:
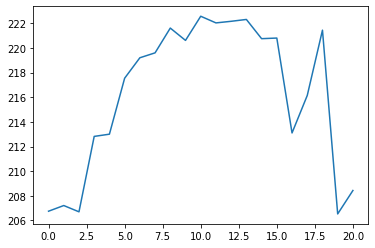
مع بعض الحظ، يجب أن تتبع قيمنا المتوقعة نفس التوزيع.
بناء مجموعة بيانات الاختبار اللازمة للتنبؤات
قبل أن نتمكن فعليًا من إجراء تنبؤات لسعر سهم Facebook في يناير 2020، نحتاج أولاً إلى إجراء بعض التغييرات على مجموعة البيانات الخاصة بنا. والسبب في ذلك هو أنه للتنبؤ بكل من الـ 21 ملاحظة في يناير، سنحتاج إلى الـ 40 يوم تداول السابقة. ستأتي بعض أيام التداول هذه من مجموعة الاختبار بينما سيأتي الباقي من مجموعة التدريب. لهذا السبب، يلزم بعض الدمج (concatenation).
لسوء الحظ، لا يمكنك ببساطة دمج مصفوفات NumPy على الفور. هذا لأننا طبقنا بالفعل تحجيم الميزات على بيانات التدريب ولكننا لم نطبق أي تحجيم للميزات على بيانات الاختبار. لإصلاح ذلك، نحتاج إلى إعادة استيراد كائن x_training_data الأصلي تحت اسم متغير جديد يسمى unscaled_x_training_data. من أجل الاتساق، سنقوم أيضًا بإعادة استيراد بيانات الاختبار كـ DataFrame تسمى unscaled_test_data:
unscaled_training_data = pd.read_csv('FB_training_data.csv')
unscaled_test_data = pd.read_csv('FB_test_data.csv')الآن يمكننا دمج عمود Open من كل DataFrame مع العبارة التالية:
all_data = pd.concat((unscaled_training_data['Open'], unscaled_test_data['Open']), axis = 0)كائن all_data هذا هو سلسلة pandas Series بطول 1279. الآن نحتاج إلى إنشاء مصفوفة لجميع أسعار الأسهم من يناير 2020 والأربعين يوم تداول التي سبقت يناير. سنسمي هذا الكائن x_test_data لأنه يحتوي على قيم x التي سنستخدمها لإجراء تنبؤات سعر السهم لشهر يناير 2020.
أول شيء تحتاج إلى القيام به هو العثور على فهرس أول يوم تداول في يناير داخل كائن all_data الخاص بنا. تحدد العبارة len(all_data) - len(test_data) هذا الفهرس لنا. يمثل هذا الحد الأعلى للعنصر الأول في المصفوفة. للحصول على الحد الأدنى، ما عليك سوى طرح 40 من هذا الرقم. بعبارة أخرى، الحد الأدنى هو len(all_data) - len(test_data) - 40. سيكون الحد الأعلى لمصفوفة x_test_data بأكملها هو العنصر الأخير في مجموعة البيانات. وبناءً عليه، يمكننا إنشاء مصفوفة NumPy هذه بالعبارة التالية:
x_test_data = all_data[len(all_data) - len(test_data) - 40:].valuesيمكنك التحقق مما إذا كان هذا الكائن قد تم إنشاؤه كما هو مطلوب عن طريق طباعة len(x_test_data)، والذي تبلغ قيمته 61. هذا منطقي – يجب أن يحتوي على 21 قيمة لشهر يناير 2020 بالإضافة إلى 40 قيمة سابقة. الخطوة الأخيرة في هذا القسم هي إعادة تشكيل مصفوفة NumPy الخاصة بنا بسرعة لجعلها مناسبة لطريقة predict:
x_test_data = np.reshape(x_test_data, (-1, 1))لاحظ أنه إذا أهملت هذه الخطوة، فسيقوم TensorFlow بطباعة رسالة مفيدة تشرح بالضبط كيفية تحويل بياناتك.
تحجيم بيانات الاختبار
تم تدريب شبكتنا العصبية المتكررة على بيانات محجمة. لهذا السبب، نحتاج إلى تحجيم متغير x_test_data الخاص بنا قبل أن نتمكن من استخدام النموذج لإجراء التنبؤات.
x_test_data = scaler.transform(x_test_data)لاحظ أننا استخدمنا طريقة transform هنا بدلاً من طريقة fit_transform (كما كان من قبل). هذا لأننا نريد تحويل بيانات الاختبار وفقًا للملاءمة الناتجة عن مجموعة بيانات التدريب بأكملها. هذا يعني أن التحويل الذي يُطبق على بيانات الاختبار سيكون هو نفسه الذي يُطبق على بيانات التدريب – وهو أمر ضروري لشبكتنا العصبية المتكررة لإجراء تنبؤات دقيقة.
تجميع بيانات الاختبار
آخر شيء نحتاج إلى القيام به هو تجميع بيانات الاختبار الخاصة بنا في 21 مصفوفة بحجم 40. بعبارة أخرى، سنقوم الآن بإنشاء مصفوفة حيث يتوافق كل إدخال مع تاريخ في يناير ويحتوي على أسعار الأسهم للأربعين يوم تداول السابقة. الكود للقيام بذلك مشابه لشيء استخدمناه سابقًا:
final_x_test_data = []
for i in range(40, len(x_test_data)):
final_x_test_data.append(x_test_data[i -40 :i, 0])
final_x_test_data = np.array(final_x_test_data)أخيرًا، نحتاج إلى إعادة تشكيل متغير final_x_test_data لتلبية معايير TensorFlow. رأينا هذا سابقًا، لذا يجب ألا يحتاج الكود إلى شرح:
final_x_test_data = np.reshape(final_x_test_data, (final_x_test_data.shape[0], final_x_test_data.shape[1], 1))إجراء التنبؤات فعليًا
بعد قدر هائل من إعادة معالجة البيانات، أصبحنا الآن جاهزين لإجراء التنبؤات باستخدام بيانات الاختبار الخاصة بنا! هذه الخطوة بسيطة. ما عليك سوى تمرير كائن final_x_test_data الخاص بنا إلى طريقة predict التي تُستدعى على كائن rnn. على سبيل المثال، إليك كيفية إنشاء هذه التنبؤات وتخزينها في متغير يحمل اسمًا مناسبًا يسمى predictions:
predictions = rnn.predict(final_x_test_data)دعنا نرسم هذه التنبؤات عن طريق تشغيل plt.plot(predictions) (لاحظ أنك ستحتاج إلى تشغيل plt.clf() لمسح لوحتك أولاً):
كما ترون، فإن القيم المتوقعة في هذا الرسم البياني كلها بين 0 و 1. هذا لأن مجموعة البيانات لدينا لا تزال محجمة! نحتاج إلى إلغاء تحجيمها حتى تكون للتنبؤات أي معنى عملي. تأتي فئة MinMaxScaler التي استخدمناها لتحجيم مجموعة البيانات الأصلية بطريقة inverse_transform مفيدة لإلغاء تحجيم البيانات. إليك كيفية إلغاء تحجيم البيانات وإنشاء رسم بياني جديد:
unscaled_predictions = scaler.inverse_transform(predictions)
plt.clf() #This clears the first prediction plot from our canvas
plt.plot(unscaled_predictions) 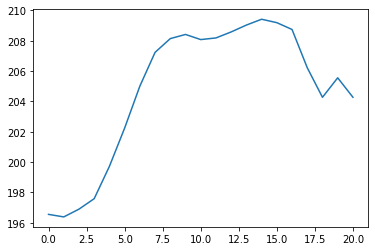
هذا يبدو أفضل بكثير! أي شخص تابع سعر سهم Facebook لأي فترة من الزمن يمكنه أن يرى أن هذا يبدو قريبًا جدًا مما تم تداوله فعليًا. دعنا ننشئ رسمًا بيانيًا يقارن أسعار الأسهم المتوقعة بأسعار سهم Facebook الفعلية:
plt.plot(unscaled_predictions, color = '#135485', label = "Predictions")
plt.plot(test_data, color = 'black', label = "Real Data")
plt.title('Facebook Stock Price Predictions')الكود الكامل للدرس التطبيقي
يمكنك عرض الكود الكامل لهذا الدرس التطبيقي في مستودع GitHub هذا. كما تم لصقه أدناه للرجوع إليه:
#Import the necessary data science libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#Import the data set as a pandas DataFrame
training_data = pd.read_csv('FB_training_data.csv')
#Transform the data set into a NumPy array
training_data = training_data.iloc[:, 1].values
#Apply feature scaling to the data set
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
training_data = scaler.fit_transform(training_data.reshape(-1, 1))
#Initialize our x_training_data and y_training_data variables
#as empty Python lists
x_training_data = []
y_training_data =[]
#Populate the Python lists using 40 timesteps
for i in range(40, len(training_data)):
x_training_data.append(training_data[i -40 :i, 0])
y_training_data.append(training_data[i, 0])
#Transforming our lists into NumPy arrays
x_training_data = np.array(x_training_data)
y_training_data = np.array(y_training_data)
#Verifying the shape of the NumPy arrays
print(x_training_data.shape)
print(y_training_data.shape)
#Reshaping the NumPy array to meet TensorFlow standards
x_training_data = np.reshape(x_training_data, (x_training_data.shape[0], x_training_data.shape[1], 1))
#Printing the new shape of x_training_data
print(x_training_data.shape)
#Importing our TensorFlow libraries
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
from tensorflow.keras.layers import Dropout
#Initializing our recurrent neural network
rnn = Sequential()
#Adding our first LSTM layer
rnn.add(LSTM(units = 45, return_sequences = True, input_shape = (x_training_data.shape[1], 1)))
#Perform some dropout regularization
rnn.add(Dropout(0.2))
#Adding three more LSTM layers with dropout regularization
for i in [True, True, False]:
rnn.add(LSTM(units = 45, return_sequences = i))
rnn.add(Dropout(0.2))
#Adding our output layer
rnn.add(Dense(units = 1))
#Compiling the recurrent neural network
rnn.compile(optimizer = 'adam', loss = 'mean_squared_error')
#Training the recurrent neural network
rnn.fit(x_training_data, y_training_data, epochs = 100, batch_size = 32)
#Import the test data set and transform it into a NumPy array
test_data = pd.read_csv('FB_test_data.csv')
test_data = test_data.iloc[:, 1].values
#Make sure the test data's shape makes sense
print(test_data.shape)
#Plot the test data
plt.plot(test_data)
#Create unscaled training data and test data objects
unscaled_training_data = pd.read_csv('FB_training_data.csv')
unscaled_test_data = pd.read_csv('FB_test_data.csv')
#Concatenate the unscaled data
all_data = pd.concat((unscaled_training_data['Open'], unscaled_test_data['Open']), axis = 0)
#Create our x_test_data object, which has each January day + the 40 prior days
x_test_data = all_data[len(all_data) - len(test_data) - 40:].values
x_test_data = np.reshape(x_test_data, (-1, 1))
#Scale the test data
x_test_data = scaler.transform(x_test_data)
#Grouping our test data
final_x_test_data = []
for i in range(40, len(x_test_data)):
final_x_test_data.append(x_test_data[i -40 :i, 0])
final_x_test_data = np.array(final_x_test_data)
#Reshaping the NumPy array to meet TensorFlow standards
final_x_test_data = np.reshape(final_x_test_data, (final_x_test_data.shape[0], final_x_test_data.shape[1], 1))
#Generating our predicted values
predictions = rnn.predict(final_x_test_data)
#Plotting our predicted values
plt.clf() #This clears the old plot from our canvas
plt.plot(predictions)
#Unscaling the predicted values and re-plotting the data
unscaled_predictions = scaler.inverse_transform(predictions)
plt.clf() #This clears the first prediction plot from our canvas
plt.plot(unscaled_predictions)
#Plotting the predicted values against Facebook's actual stock price
plt.plot(unscaled_predictions, color = '#135485', label = "Predictions")
plt.plot(test_data, color = 'black', label = "Real Data")
plt.title('Facebook Stock Price Predictions')الخلاصة التقنية
في هذا الدليل الشامل، استكشفنا عالم الشبكات العصبية المتكررة (RNNs) وتعمقنا في فهم شبكات الذاكرة طويلة المدى (LSTMs) كحل فعال لمشكلة التدرج المتلاشي. لقد رأينا كيف تُعد RNNs أدوات قوية لتحليل السلاسل الزمنية، وكيف يمكن لـ LSTMs، بفضل بنيتها المعقدة التي تتضمن البوابات، أن تحتفظ بالمعلومات ذات الصلة لفترات طويلة، مما يجعلها مثالية للمهام التي تتطلب ذاكرة طويلة المدى مثل التنبؤ بأسعار الأسهم أو التعرف على الكلام.
لقد قمنا بتطبيق هذه المفاهيم عمليًا من خلال بناء وتدريب شبكة LSTM في بايثون باستخدام مكتبة TensorFlow/Keras، وتوقعنا سعر سهم Facebook. أظهرت التجربة أهمية كل خطوة، بدءًا من إعداد البيانات وتحجيم الميزات، مرورًا بتحديد عدد الخطوات الزمنية، ووصولاً إلى بناء الطبقات المتتالية وتجميع النموذج وتدريبه. كما أبرزنا ضرورة إعادة تحجيم التنبؤات النهائية لتكون قابلة للتفسير البشري.
إن القدرة على معالجة البيانات المتسلسلة بدقة تفتح آفاقًا واسعة للابتكار في مجالات متعددة، من التمويل إلى الرعاية الصحية. وتُعد LSTMs حجر الزاوية في هذا التقدم، مما يوفر للمطورين والباحثين أداة قوية لمواجهة تحديات التعلم العميق المعقدة.