محارف يونيكود: ما الذي يجب على كل مطور معرفته عن الترميز؟
مقدمة: لماذا يُعد الترميز أساسياً في تطوير البرمجيات؟
إذا كنت تطور تطبيقاً يدعم أكثر من لغة، أو تعمل على موقع يستهدف جمهوراً دولياً، فلا بد أن تفهم مفهوم Encoding. وحتى إن لم تكن مطوراً متعدد اللغات، فإن كل نص يظهر أمامك على الشاشة يمر في الأصل عبر طبقة من التحويل والترميز قبل أن يصبح قابلاً للقراءة.
الترميز ليس مجرد تفصيل تقني صغير، بل هو أساس نقل النصوص وتخزينها وعرضها بصورة صحيحة. ومن دون معيار موحد، قد تظهر الكلمات على شكل رموز مشوهة أو غير مفهومة، وهي مشكلة عانى منها الويب في مراحله الأولى.

في هذا المقال ستتعرف على تاريخ الترميز، ومشكلة ASCII، وكيف جاء Unicode ليقدم حلاً عملياً، ثم نفهم دور UTF-8 ولماذا أصبح الخيار المفضل على الويب الحديث.
ما هو الترميز؟
الحاسوب لا يفهم سوى النظام الثنائي، أي سلسة من 0 و1. وهذه هي اللغة الأساسية التي تُخزن بها البيانات وتُنقل وتُعالج.
- الرقم الثنائي الواحد يسمى
bit. - كل
8 bitsتشكلbyteواحداً. - كل ما تتعامل معه في الحاسوب، من النصوص إلى الصور إلى الأوامر، يتحول في النهاية إلى تمثيل ثنائي.
لكن السؤال الأهم هو: كيف ننتقل من أرقام ثنائية إلى حروف وكلمات مفهومة؟ هنا يأتي دور الترميز، إذ يحدد القواعد التي تربط بين القيم الثنائية والمحارف التي نقرأها.
نبذة تاريخية: كيف بدأ ترميز النصوص؟
معيار ASCII وبداياته
في بدايات الحوسبة والإنترنت، كان التركيز موجهاً أساساً إلى اللغة الإنجليزية. لذلك ظهر معيار ASCII، وهو اختصار لـ American Standard Code for Information Interchange.
كانت فكرته بسيطة: تعيين قيمة رقمية لكل حرف أو رقم أو رمز معين، بحيث يستطيع الحاسوب تحويل البيانات الثنائية إلى نص مقروء.
على سبيل المثال، يمكن تمثيل العبارة Hello world على شكل بيانات ثنائية، ثم يُفسرها معيار ASCII كحروف إنجليزية:
01001000 01100101 01101100 01101100 01101111 00100000 01110111 01101111 01110010 01101100 01100100عند فك هذا التسلسل وفق معيار ASCII، نحصل على النص Hello world.
لماذا كان ASCII مناسباً في البداية؟
اعتمد ASCII على مجموعة محدودة من المحارف تكفي لتمثيل:
- الحروف الإنجليزية الكبيرة والصغيرة.
- الأرقام من
0إلى9. - بعض الرموز الشائعة.
- محارف تحكم غير مطبوعة مثل الجرس أو مسح السطر.
وبما أن byte واحداً يمكنه تمثيل عدد كبير من القيم، فقد بدا هذا المعيار كافياً لمرحلة مبكرة كانت فيها اللغة الإنجليزية هي المسيطرة على الأنظمة الرقمية.
مشكلة ASCII: ماذا حدث عندما توسع العالم الرقمي؟
رغم نجاح ASCII في البيئات الإنجليزية، فقد ظهرت مشكلته الحقيقية عند الحاجة إلى دعم لغات أخرى مثل العربية واليونانية والصينية والروسية وغيرها.
كان معيار ASCII يغطي فقط جزءاً محدوداً من المحارف، وترك عدداً من القيم غير المستخدمة. هنا بدأت الشركات والأنظمة المختلفة في استغلال هذه المساحة الفارغة بطرق متباينة، فأنشأت كل جهة تقريباً نسختها الخاصة من الامتدادات.
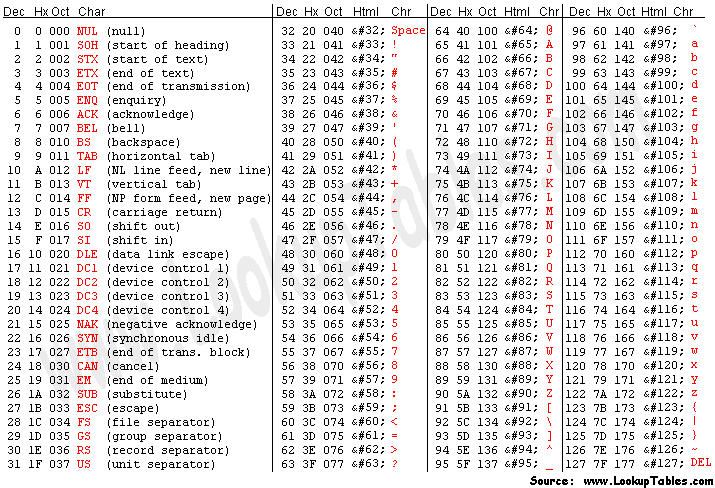
كانت النتيجة أن الملف الذي يُكتب على جهاز ما قد لا يُقرأ بشكل صحيح على جهاز آخر، حتى لو كانا يتعاملان مع اللغة نفسها.
ما هي صفحات الشيفرة Code Pages؟
عندما بدأت الأنظمة تضيف محارف خارج نطاق ASCII القياسي، ظهرت ما يسمى Code Pages. وهي ببساطة جداول محلية أو خاصة تحدد معنى القيم الإضافية في النطاق الممتد.
المشكلة أن هذه الصفحات لم تكن موحدة عالمياً. فقد تجد أكثر من صفحة شيفرة للغة واحدة، بل وأكثر من طريقة لتمثيل الحرف نفسه. وهذا جعل تبادل البيانات بين الأنظمة أمراً غير موثوق.

بالنسبة للغات ذات العدد الضخم من المحارف مثل الصينية، كانت المشكلة أعقد بكثير، لأن عدد المحارف يتجاوز بكثير المساحة المحدودة المتاحة في الأنظمة القديمة.
ظاهرة النص المشوه Mojibake
عندما يُفك ترميز النص باستخدام معيار مختلف عن ذلك الذي استُخدم عند ترميزه، تظهر النتيجة على شكل رموز غريبة أو حروف مشوهة. تعرف هذه الحالة باسم Mojibake.
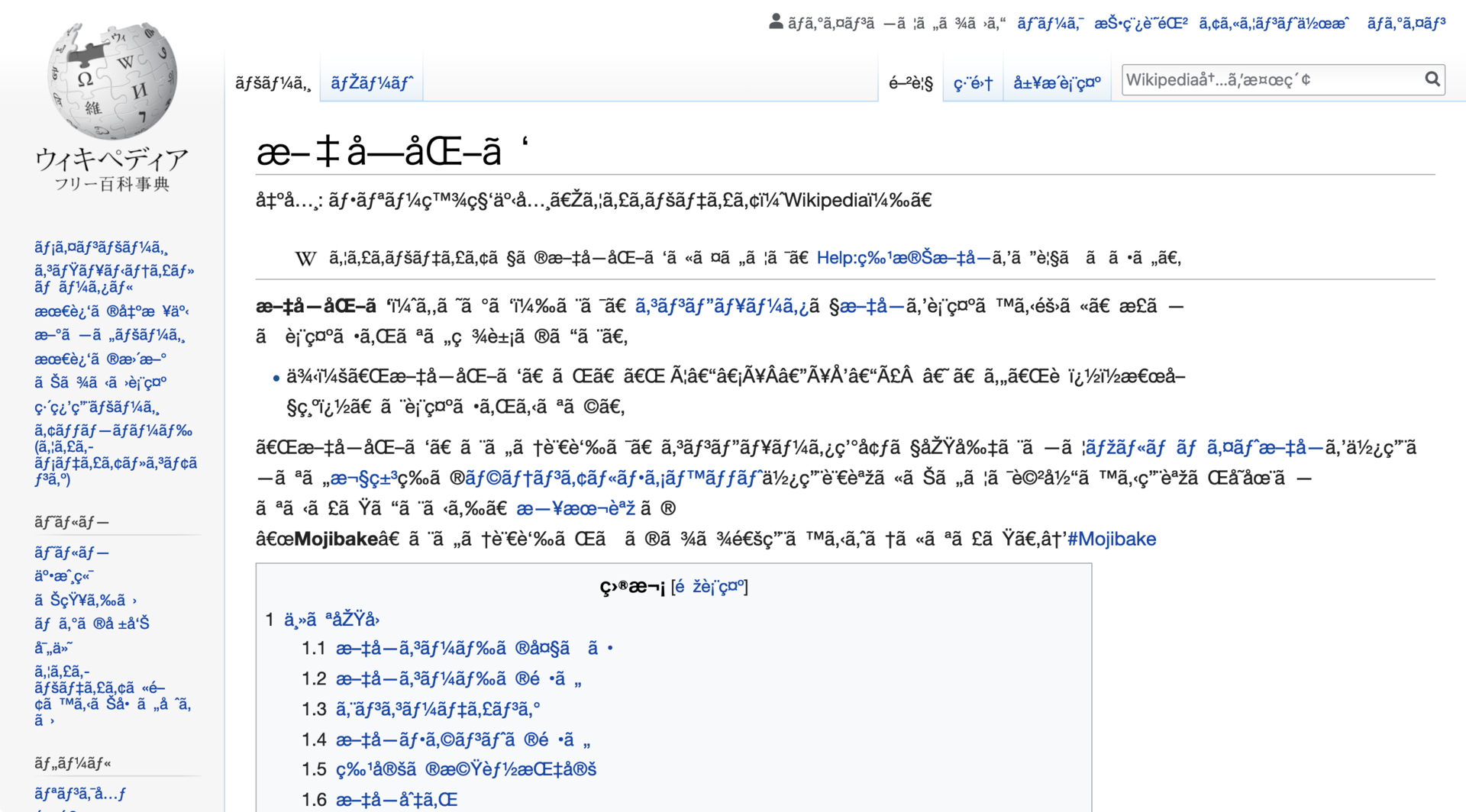
هذه المشكلة لم تكن مجرد خلل بصري، بل كانت تعيق التواصل الرقمي نفسه. فإذا لم يتفق المرسل والمستقبل على الترميز، تصبح البيانات النصية عديمة الفائدة تقريباً.
ظهور Unicode: الحل العالمي لتوحيد المحارف
جاء Unicode ليعالج الفوضى الناتجة عن تعدد صفحات الشيفرة. ويمكن اعتباره نظاماً عالمياً يمنح كل محرف معروف تقريباً قيمة فريدة تسمى Code Point.
بدلاً من أن تعتمد كل منصة أو لغة على جدولها الخاص، أصبح بالإمكان الرجوع إلى مرجع موحد يشمل محارف اللغات المختلفة والرموز الرياضية والرموز التقنية وحتى الرموز التعبيرية.
يشمل Unicode عدداً هائلاً من المحارف، بدءاً من الحروف اللاتينية والعربية، وصولاً إلى الهيروغليفية المصرية والرموز القديمة جداً.
كيف تبدو نقاط الشيفرة في Unicode؟
كل محرف في Unicode يملك معرّفاً فريداً. فعلى سبيل المثال، يمكن تمثيل عبارة Hello World بالنقاط التالية:
U+0048 : LATIN CAPITAL LETTER H
U+0065 : LATIN SMALL LETTER E
U+006C : LATIN SMALL LETTER L
U+006C : LATIN SMALL LETTER L
U+006F : LATIN SMALL LETTER O
U+0020 : SPACE
U+0057 : LATIN CAPITAL LETTER W
U+006F : LATIN SMALL LETTER O
U+0072 : LATIN SMALL LETTER R
U+006C : LATIN SMALL LETTER L
U+0064 : LATIN SMALL LETTER Dالبادئة U+ تعني أننا نتحدث عن نقطة شيفرة ضمن معيار Unicode. وغالباً ما تُعرض هذه القيم بالنظام الست عشري Hexadecimal لأنه أسهل في القراءة من التمثيل الثنائي المباشر.
من المهم هنا فهم نقطة أساسية: Unicode ليس طريقة التخزين نفسها، بل هو قاموس موحد للمحارف ونقاطها المرجعية.
ما الفرق بين Unicode وUTF؟
هذا التفريق مهم جداً. فـ Unicode يحدد المحارف ونقاط الشيفرة الخاصة بها، أما UTF فهو الطريقة الفعلية لترميز هذه النقاط داخل الذاكرة أو الملفات.
كلمة UTF هي اختصار لـ Unicode Transformation Format، وهي تحدد كيف تتحول نقاط الشيفرة إلى بايتات يمكن للحاسوب تخزينها أو إرسالها.
أشهر صيغ UTF
UTF-8: يستخدم طولاً متغيراً ويعد الأكثر شيوعاً على الويب.UTF-16: يعتمد غالباً على وحدات بطول2 bytes.UTF-32: يستخدم4 bytesلكل نقطة شيفرة، وهو أبسط منطقياً لكنه أقل كفاءة من حيث الحجم.
هذه الصيغ كلها يمكنها تمثيل محارف Unicode، لكنها تختلف في طريقة التخزين وحجم البيانات الناتج.
لماذا أصبح UTF-8 هو الخيار الأفضل للويب؟
يُعد UTF-8 الترميز الأكثر استخداماً على الإنترنت اليوم، كما أنه الترميز المفضل في مواصفات HTML5 للمستندات الجديدة.
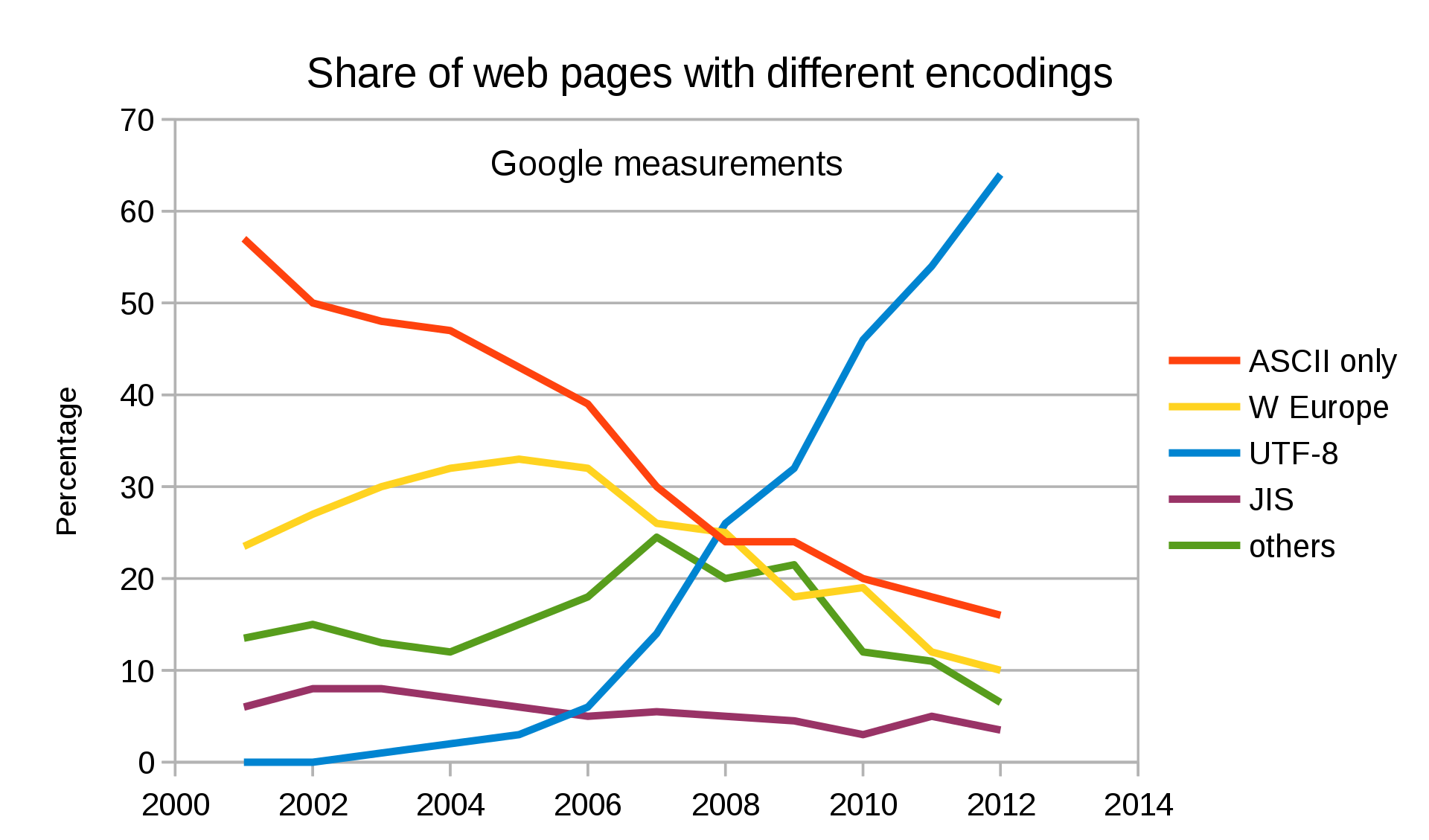

أبرز مزايا UTF-8
- متوافق عكسياً مع
ASCIIفي النطاق0-127. - يدعم جميع محارف
Unicode. - فعال جداً في تخزين النصوص الإنجليزية.
- مناسب للويب وقواعد البيانات وواجهات البرمجة الحديثة.
التوافق العكسي مع ASCII كان عاملاً حاسماً في انتشاره، لأن الأنظمة القديمة لم تكن تحتاج إلى تغيير جذري حتى تبدأ باستخدامه.
كيف يعمل UTF-8؟
يستخدم UTF-8 ترميزاً متغير الطول، أي إن عدد bytes المستخدمة لتمثيل المحرف يعتمد على نوعه:
- المحارف الإنجليزية الأساسية غالباً ما تحتاج إلى
1 byte. - بعض اللغات الأوروبية والعربية والعبرية قد تحتاج إلى
2 bytesأو أكثر بحسب نقطة الشيفرة. - محارف آسيوية كثيرة تحتاج إلى
3 bytes. - بعض الرموز الخاصة والرموز التعبيرية قد تستخدم
4 bytes.
هذا ما يجعل UTF-8 مرناً وعملياً. فهو لا يهدر المساحة مع النصوص البسيطة، وفي الوقت نفسه يدعم اللغات العالمية دون مشاكل هيكلية.
وعندما يمتد المحرف إلى أكثر من byte، يستخدم الترميز نمطاً خاصاً يحدد أن البايت التالي جزء من المحرف نفسه، وليس محرفاً جديداً.
دور BOM في تحديد الترميز
أحياناً تحتاج الأنظمة إلى وسيلة تساعدها في معرفة نوع الترميز المستخدم داخل الملف. هنا يظهر مفهوم Byte Order Mark أو BOM.
وهو علامة توضع في بداية الملف لتشير إلى الترميز المستخدم. وقد يسمى أحياناً Encoding Signature. ورغم فائدته في بعض السياقات، فإن استخدامه مع UTF-8 ليس دائماً ضرورياً، لكنه يظل مفهوماً مهماً عند التعامل مع الملفات القادمة من بيئات مختلفة.
كيف تُعرض النصوص على الشاشة فعلياً؟
بصورة مبسطة، تمر العملية بالمراحل التالية:
- قراءة الترميز المستخدم في الملف أو الرسالة.
- فك البايتات وتحويلها إلى نقاط شيفرة في
Unicode. - مطابقة هذه النقاط مع المحارف المناسبة.
- عرض المحارف على الشاشة باستخدام الخطوط والمحرك الرسومي.
أي خلل في هذه السلسلة قد يؤدي إلى عرض خاطئ للنص، حتى لو كانت البيانات الأصلية سليمة.
كيفية تحديد الترميز في صفحات الويب
عند إنشاء صفحة ويب، يجب تحديد الترميز بوضوح داخل القسم <head> حتى يستطيع المتصفح تفسير المحتوى بشكل صحيح منذ اللحظة الأولى.
<html lang="en">
<head>
<meta charset="utf-8">
</head>من الأفضل وضع الوسم <meta charset="utf-8"> في بداية القسم <head>، لأن المتصفح قد يضطر إلى إعادة تحليل الصفحة إذا بدأ بترميز خاطئ.
كذلك يمكن تحديد الترميز عبر ترويسة Content-Type ضمن طلبات واستجابات HTTP.
ماذا يحدث إذا لم يُحدد الترميز؟
عندما لا يجد المتصفح تعريفاً واضحاً للترميز، قد يحاول التخمين عبر وسائل مختلفة، مثل فحص BOM أو الاعتماد على آليات استدلال داخلية. لكن هذا التخمين ليس مضموناً دائماً، وقد يقود إلى ظهور محتوى مشوه.
أمثلة واقعية على أهمية الترميز الصحيح
أهمية الترميز لا تقتصر على الجانب الأكاديمي. فهي تؤثر مباشرة في:
- عرض المحتوى العربي واللغات متعددة الاتجاه بشكل صحيح.
- سلامة البيانات في قواعد البيانات والاستيراد والتصدير.
- فهم واجهات
APIللمدخلات والمخرجات النصية. - تجربة المستخدم في المواقع والتطبيقات.
- الأرشفة والفهرسة الصحيحة في محركات البحث.
أي خطأ في الترميز قد يعني صفحات غير قابلة للقراءة، أو رسائل بريد مشوهة، أو ملفات CSV تظهر بحروف غير مفهومة، أو مشاكل في نتائج البحث.

هل اكتمل معيار Unicode؟
الإجابة المختصرة: لا. معيار Unicode يتطور باستمرار، وتُضاف إليه محارف واقتراحات جديدة بانتظام. وهذا طبيعي لأن اللغات والرموز والاحتياجات الرقمية في تطور دائم.
لذلك لا ينبغي النظر إلى Unicode على أنه مشروع منتهٍ، بل على أنه معيار حي يتوسع باستمرار ليغطي استخدامات أوسع وأكثر دقة.
أفضل الممارسات للمطورين عند التعامل مع الترميز
- اعتمد
UTF-8كخيار افتراضي في المشاريع الجديدة. - حدد الترميز صراحة في ملفات
HTMLوترويساتHTTP. - تأكد من أن قاعدة البيانات والاتصال بينها وبين التطبيق يستخدمان الترميز نفسه.
- اختبر ملفات الاستيراد والتصدير، خاصة
CSVوJSONوXML. - انتبه إلى النصوص القادمة من أنظمة قديمة أو برامج مكتبية تستخدم صفحات شيفرة مختلفة.
- راجع الأدوات والمحررات البرمجية للتأكد من حفظ الملفات باستخدام
UTF-8.
الخلاصة التقنية
فهم الترميز ليس رفاهية للمطور، بل مهارة أساسية تؤثر في جودة المنتج واستقراره وقدرته على دعم اللغات العالمية. لقد فشل ASCII في تلبية احتياجات الإنترنت متعدد اللغات، وجاء Unicode ليقدم قاموساً عالمياً موحداً، بينما وفر UTF-8 آلية عملية وفعالة لتخزين هذا التنوع الهائل من المحارف. من الناحية التقنية، يمكن القول إن اختيار ترميز صحيح وتوحيده عبر كامل المنظومة من الواجهة إلى قاعدة البيانات هو أحد القرارات الصغيرة التي تمنع مشكلات كبيرة ومكلفة لاحقاً.