كيفية استخدام المقاييس لمراقبة بنية الخدمات المصغّرة بفعالية
مقدمة: لماذا تُعد المقاييس أساسية في مراقبة الخدمات المصغّرة؟
في البيئات الحديثة التي تعتمد على Microservices، لا يكفي تشغيل الخدمة ثم انتظار ظهور الأعطال. تحتاج الأنظمة الموزعة إلى رؤية مستمرة لحالتها التشغيلية، وهنا تبرز أهمية Metrics بوصفها وسيلة رقمية دقيقة تساعد على قياس سلوك النظام، واكتشاف التغيرات، وبناء تنبيهات استباقية قبل أن تتفاقم المشكلات.
في مقال سابق، كان التركيز على السجلات Logs وأهمية التمييز بين السجل المنظم وغير المنظم. أما هنا، فسننتقل إلى المقاييس، وهي تمثيل رقمي للبيانات يُستخدم عادة للعدّ أو القياس خلال فترة زمنية محددة. ومن خلال هذه الأرقام يمكن فهم الحالة الحالية للنظام، وقراءة سلوكه التاريخي، بل وإجراء تحليلات إحصائية تساعد على توقع مشكلاته المحتملة مستقبلاً.

الميزة الكبرى في المقاييس أنها لا تكتفي بوصف ما يحدث، بل تتيح أيضاً إنشاء لوحات متابعة Dashboards وتنبيهات Alerts تساعد الفرق التقنية على الاستجابة بسرعة لأي سلوك غير طبيعي.
السجلات مقابل المقاييس: ما الفرق الجوهري؟
كيف يتم تمثيل السجلات؟
السجلات Logs تُكتب عادة على شكل نصوص. قد تكون سطوراً نصية بسيطة، أو بيانات بصيغة JSON، أو أزواجاً من نوع مفتاح/قيمة. والهدف منها توثيق حدث محدد وقع داخل النظام مع أكبر قدر ممكن من التفاصيل.
مثال على سجل نموذجي:
[ 2020-09-27T18:54:41,500+0530 ]-[ERROR]-[InventoryValidator]-[13] Exception in fetching product information - Product Not Availableهذا النوع من البيانات مفيد جداً عند التحقيق في الأعطال، لأنه يوضح الرسالة والسياق والزمن والمكوّن الذي أصدر الخطأ.
كيف يتم تمثيل المقاييس؟
على النقيض، المقاييس Metrics هي قيم رقمية تعبّر عن شيء يمكن قياسه، مثل استهلاك المعالج، وعدد الأخطاء، وزمن الاستجابة. وغالباً ما تُخزّن مع وسوم Tags أو Labels تساعد على تصنيفها وتحليلها لاحقاً.
مثال مبسط على مقياس:
{ class=InventoryValidator, exception=Product Not Available, timestamp=1609306200 }ورغم أن هذا المثال يتضمن معلومات وصفية، فإن جوهر المقياس يظل رقمياً وقابلاً للتجميع والتحليل الزمني.
دقة البيانات: ماذا تخبرك السجلات وماذا تخبرك المقاييس؟
السجلات تمنحك صورة تفصيلية عالية الدقة
السجلات توفر بيانات غنية جداً عن الحدث، بما في ذلك تسلسل التنفيذ، ورسائل الأخطاء، وأحياناً الأثر الكامل للاستثناء Stack Trace. لهذا السبب تُعد السجلات خياراً ممتازاً عند محاولة فهم ما حدث فعلياً داخل النظام ولماذا حدث.
باختصار، السجلات تجيب عن سؤال: ماذا حدث بالتحديد؟
المقاييس تمنحك رؤية إجمالية منخفضة الدقة ولكن شديدة الفاعلية
المقاييس لا تهدف إلى شرح كل حدث على حدة، بل إلى إعطائك مؤشرات عامة مثل عدد الطلبات، ومعدل الأخطاء، واستهلاك الذاكرة، وضغط النظام. هذه الرؤية المجمعة تجعلها مثالية للمتابعة المستمرة والتنبيه المبكر.
باختصار، المقاييس تجيب عن سؤال: كم مرة حدث شيء ما، ومتى بدأ يتغير؟
التكلفة التشغيلية: أيهما أخف على البنية التحتية؟
من الناحية العملية، تخزين السجلات مكلف نسبياً، لأن حجمها يزداد بزيادة حركة المرور وعدد الأحداث التي تنتجها الخدمات. وكلما توسع النظام، ارتفع عبء التخزين والفهرسة والاسترجاع.
أما المقاييس، فغالباً ما تكون أقل كلفة من حيث التخزين، لأن البيانات الرقمية المجمعة لا تنمو بنفس سرعة السجلات النصية التفصيلية. لكن هذا لا يعني أنها مجانية بالكامل؛ إذ تعتمد التكلفة على عدد الأبعاد أو الوسوم المرفقة بكل مقياس.
بكلمات أخرى: السجلات تمنحك عمقاً أكبر، بينما توفر المقاييس كفاءة أفضل في المتابعة الواسعة والمستمرة.
مفهوم Cardinality في المقاييس ولماذا يجب الانتباه إليه؟
كل مقياس يُعرَّف عادة من خلال عنصرين رئيسيين:
- اسم المقياس
Metric Name - مجموعة من الأزواج المفتاحية والقيمية مثل
TagsأوLabels
عدد التركيبات الممكنة لهذه القيم يُعرف باسم Cardinality. وهو عامل حاسم لأن زيادته المفرطة ترفع تكلفة التخزين والاستعلام بشكل كبير.
لنفترض أنك تقيس استهلاك المعالج عبر ثلاثة مضيفين:
(name=pod.cpu.utilization, host=A)
(name=pod.cpu.utilization, host=B)
(name=pod.cpu.utilization, host=C)في هذه الحالة، قيمة Cardinality تساوي 3.
إذا أضفت وسم المنطقة السحابية AWS Region مثل us-west-1 وus-west-2، فسيتضاعف عدد التركيبات، وقد تصل القيمة إلى 6 أو أكثر بحسب عدد المضيفين والمناطق.
لهذا السبب، ينبغي اختيار الحد الأدنى من الوسوم الذي يحقق فائدة تحليلية حقيقية دون تضخيم غير ضروري في حجم البيانات.
أنواع المقاييس المهمة في مراقبة الخدمات المصغّرة
أولاً: الإشارات الذهبية Golden Signals
تُعد الإشارات الذهبية من أكثر الأطر استخداماً لمراقبة الحالة العامة للأنظمة الموزعة. وهي تساعد على تحديد الاختناقات والانحرافات بسرعة.
- التوافر
Availability: يقيس مدى قدرة النظام على خدمة العملاء، مثل نسبة الطلبات الناجحة مقابل الفاشلة. - السلامة التشغيلية
Health: تُقاس عادة عبر اختبارات دورية مثلHealth ChecksأوPings. - معدل الطلبات
Request Rate: عدد الطلبات الواردة إلى النظام خلال فترة زمنية معينة. - التشبع
Saturation: مدى امتلاء الموارد أو الضغط الواقع على النظام، مثل عمق الطوابير أو انخفاض الذاكرة المتاحة. - الاستغلال
Utilization: مدى انشغال النظام بالعمل، مثل نسبة حمل المعالج أو استهلاك الذاكرة. - معدل الأخطاء
Error Rate: عدد أو نسبة الأخطاء التي ينتجها النظام. - زمن الاستجابة
Latency: الوقت الذي يستغرقه النظام للرد، وغالباً ما يُراقب عند النسب المئوية مثلP95وP99.
ثانياً: مقاييس الموارد Resource Metrics
هذا النوع يأتي غالباً بشكل افتراضي من مزود البنية التحتية أو منصة التشغيل مثل AWS CloudWatch أو مقاييس Kubernetes. وهو مهم لفهم صحة البيئة التي تعمل عليها الخدمات.
- استهلاك المعالج والذاكرة
CPU/Memory Utilization: يوضح الضغط على الموارد الأساسية. - عدد المضيفين أو الحاويات
Host Count: مفيد لاكتشاف الانخفاضات الناتجة عن تعطلPodsأو الخوادم. - عدد الخيوط الحية
Live Threads: يساعد على كشف مشكلات التزامن وتضخم التنفيذ المتوازي. - استخدام الذاكرة المكدسة
Heap Usage: مهم لرصد تسرب الذاكرة وتحليل مشاكل الأداء الطويلة الأمد.
ثالثاً: مقاييس الأعمال Business Metrics
هذا النوع لا يكتفي بقياس التقنية، بل يربط المراقبة بالقيمة الفعلية التي يقدمها المنتج. وهو بالغ الأهمية عند إدارة خدمات تمس الإيرادات أو تجربة المستخدم مباشرة.
- معدل الطلبات على الواجهات البرمجية
API Request Rate: يوضح حجم التفاعل مع الوظائف الأساسية. - معدل أخطاء الواجهات
API Error Rate: يكشف الأعطال المؤثرة على المستخدمين أو الأنظمة المستهلكة للخدمة. - زمن معالجة الطلبات
API Latency: يساعد على تقييم جودة التجربة وسرعة الخدمة.
لوحات المتابعة والتنبيهات: أين تظهر قوة المقاييس فعلياً؟
بما أن المقاييس تُخزن عادة في قواعد بيانات زمنية Time-Series Databases، فإن الاستعلام عنها يكون أكثر موثوقية وكفاءة عند تحليل حالة النظام عبر الزمن. ومن هنا يمكن بناء لوحات متابعة مرئية توضح الاتجاهات التاريخية والحالة اللحظية.
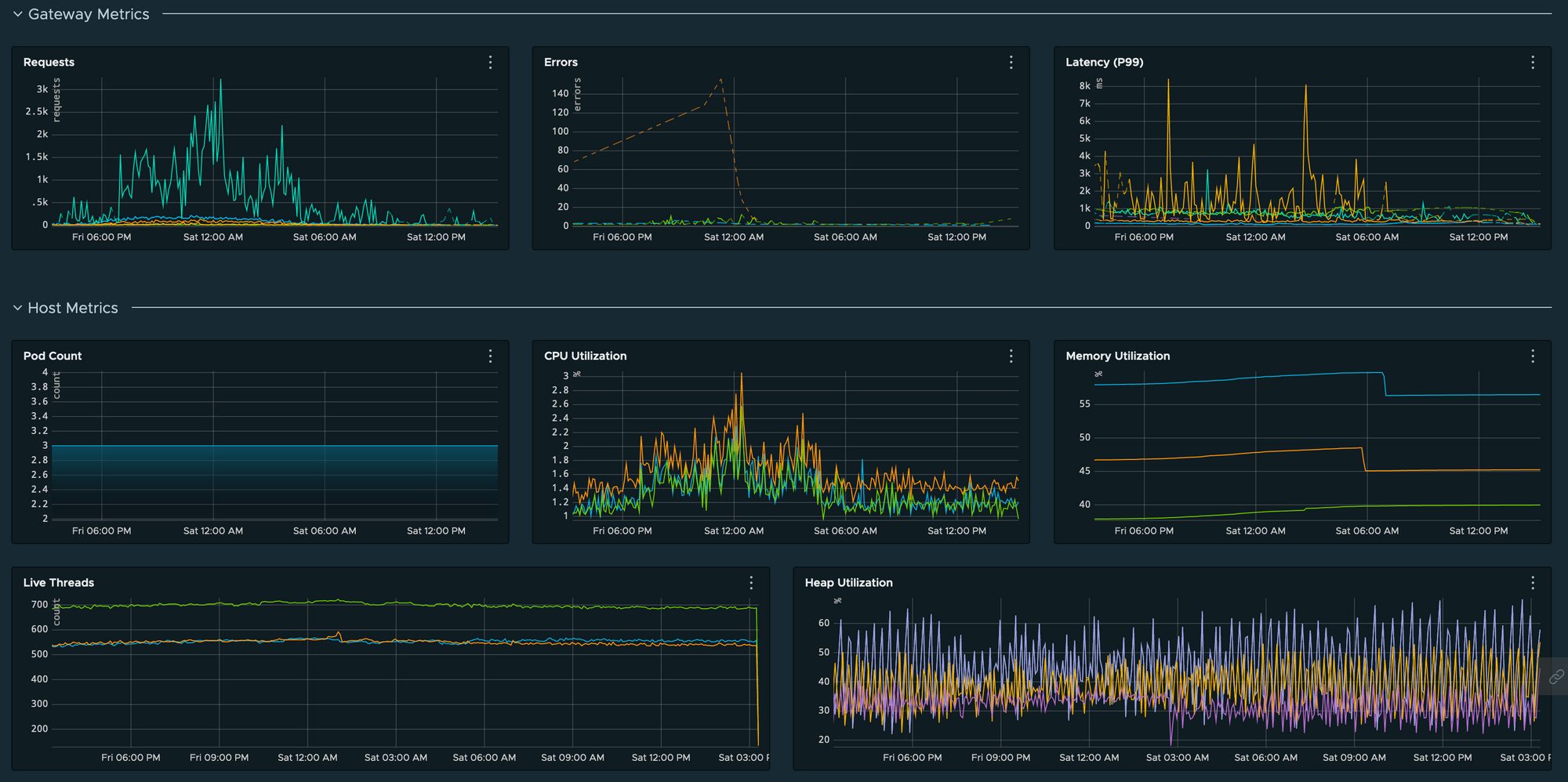
يمكن استخدام هذه المقاييس في أدوات مثل Wavefront وGrafana لبناء لوحات تعرض:
- تغيرات معدل الطلبات عبر الزمن
- الارتفاعات المفاجئة في الأخطاء
- نسب استهلاك الموارد
- زمن الاستجابة حسب الخدمة أو البيئة
كما يمكن تحويلها إلى تنبيهات ذكية عند تحقق شروط محددة، مثل:
- ارتفاع معدل الأخطاء فوق نسبة معينة
- زيادة استهلاك المعالج بشكل حاد
- انخفاض عدد النسخ العاملة من الخدمة
- تجاوز زمن الاستجابة الحد المقبول
الطبيعة الرقمية للمقاييس تجعل من السهل إنشاء استعلامات رياضية مركبة، مثل حساب نسبة أخطاء قدرها X% خلال آخر Y دقائق، وهو ما يصعب تنفيذه بكفاءة عند الاعتماد على السجلات وحدها.
التحدي الحقيقي: لا تُفرط في إصدار المقاييس
أكبر خطأ يقع فيه كثير من الفرق الهندسية هو الاعتقاد بأن جمع كل شيء أفضل من جمع ما يلزم فقط. في الواقع، إصدار عدد كبير جداً من المقاييس، أو إضافة عدد مفرط من الأبعاد لكل مقياس، قد يؤدي إلى:
- ارتفاع كبير في تكاليف التخزين والمعالجة
- بطء في الاستعلامات ولوحات المتابعة
- صعوبة في تفسير البيانات المهمة وسط الضوضاء
- إرباك الفرق التقنية عند الاستجابة للحوادث
الممارسة الأفضل هي تصميم مقاييس تعطي صورة عالية المستوى عن صحة النظام، ثم استخدام السجلات للتفاصيل الدقيقة عند الحاجة.
كيف تستخدم السجلات والمقاييس معاً في بيئة إنتاجية؟
السجلات والمقاييس ليسا بديلين عن بعضهما، بل يكمل كل منهما الآخر. في أي نظام إنتاجي حقيقي، تحتاج إلى الاثنين معاً للوصول إلى مراقبة فعالة وتشخيص دقيق.
غالباً ما تكون المقاييس هي خط الرؤية الأول. فهي تكشف أن هناك مشكلة ما، لكنها لا تشرح سببها بالكامل. بعد ذلك تأتي السجلات لتوفير التفاصيل اللازمة لتحليل الجذر الحقيقي للعطل.
مثال عملي من متجر إلكتروني
تخيل تطبيق تجارة إلكترونية يشبه Amazon. من أهم المقاييس هنا:
- إجمالي عدد الطلبات الناجحة
- إجمالي عدد الطلبات الفاشلة
في الوضع الطبيعي، يبقى عدد الطلبات الفاشلة قريباً من الصفر أو ضمن هامش ضئيل. لكن إذا حدث خلل مفاجئ في نظام الدفع أو إدارة المخزون، فسيبدأ هذا الرقم بالارتفاع.
في هذه الحالة يمكن إنشاء تنبيه يعتمد على مقياسين معاً:
- إجمالي الطلبات
- عدد الطلبات الفاشلة
ثم حساب نسبة الفشل، وإذا تجاوزت مثلاً 5% يتم إرسال إشعار فوري إلى الفريق المسؤول.
بعد وصول التنبيه، يبدأ دور السجلات. إذ يمكن الرجوع إلى Logs لمعرفة رسائل الخطأ، وتسلسل الأحداث، وStack Trace الذي يوضح السبب الجذري، سواء كان في خدمة داخلية أو نظاماً تابعاً لجهة خارجية.
أفضل الممارسات لبناء استراتيجية مراقبة ناجحة
- ابدأ بمقاييس أساسية تشمل
LatencyوError RateوRequest Rate. - أضف مقاييس موارد واضحة لفهم استقرار البنية التحتية.
- اربط المراقبة بمؤشرات أعمال حقيقية، مثل الطلبات المكتملة أو المدفوعات الفاشلة.
- قلّل
Cardinalityقدر الإمكان دون الإضرار بالقيمة التحليلية. - استخدم المقاييس للتنبيه السريع، والسجلات للتحقيق المتعمق.
- أنشئ لوحات متابعة بسيطة وواضحة بدلاً من لوحات مزدحمة تصعب قراءتها.
الخلاصة التقنية
المقاييس ليست مجرد أرقام تُعرض على لوحة متابعة، بل هي طبقة أساسية لفهم صحة الخدمات المصغّرة واتجاه سلوكها بمرور الوقت. قوتها الحقيقية تظهر في الرصد المستمر، واكتشاف الانحرافات مبكراً، وبناء تنبيهات قابلة للتنفيذ. ومع ذلك، لا يمكنها وحدها تفسير كل مشكلة؛ فالسجلات تظل المصدر الأهم للتفاصيل الدقيقة والتحليل الجنائي للأعطال. لذلك، فإن أفضل نهج تقني هو الجمع الذكي بين Metrics وLogs ضمن استراتيجية مراقبة متوازنة، منخفضة التكلفة، وعالية الفاعلية.