التعامل مع إطارات البيانات وملفات CSV في R: دليل شامل مع أمثلة عملية

في هذا المقال، ستتعلمون:
- ما هي ملفات
CSVوما هي استخداماتها. - كيفية إنشاء ملفات
CSVباستخدام جداول بيانات جوجل (Google Sheets). - كيفية قراءة ملفات
CSVفي لغةR. - ما هي إطارات البيانات (
Data Frames) وما هي استخداماتها. - كيفية الوصول إلى عناصر إطار البيانات.
- كيفية تعديل إطار البيانات.
- كيفية إضافة وحذف الصفوف والأعمدة.
سنستخدم بيئة التطوير المتكاملة مفتوحة المصدر RStudio لتشغيل الأمثلة. لنبدأ رحلتنا! ✨
مقدمة إلى ملفات CSV
تُعد ملفات CSV (القيم المفصولة بفواصل) من اللبنات الأساسية في تحليل البيانات، حيث تُستخدم لتخزين البيانات الممثلة على شكل جدول. في هذا النوع من الملفات، تُفصل القيم بواسطة فواصل لتمثيل الأعمدة المختلفة في الجدول، كما يوضح المثال التالي:
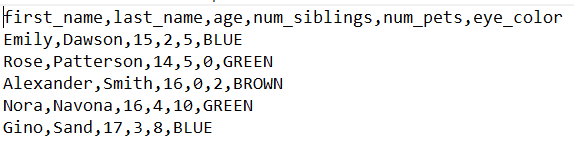
ملف CSV النموذجي
سنقوم بإنشاء هذا الملف باستخدام جداول بيانات جوجل (Google Sheets).
كيفية إنشاء ملف CSV باستخدام جداول بيانات جوجل (Google Sheets)
لنقم بإنشاء أول ملف CSV خاص بكم باستخدام جداول بيانات جوجل.
الخطوة 1: الوصول إلى جداول بيانات جوجل
اذهبوا إلى موقع جداول بيانات جوجل وانقروا على زر “Go to Google Sheets”:
يمكنكم أيضاً الوصول إلى جداول بيانات جوجل بالنقر على الزر الموجود في الزاوية العلوية اليمنى من الصفحة الرئيسية لجوجل:
بالتكبير، نرى زر “Sheets”:
ملاحظة: لاستخدام جداول بيانات جوجل، تحتاجون إلى حساب Gmail. بدلاً من ذلك، يمكنكم إنشاء ملف CSV باستخدام برنامج MS Excel أو أي محرر جداول بيانات آخر.
سترون هذه اللوحة:
الخطوة 2: إنشاء جدول بيانات فارغ
أنشئوا جدول بيانات فارغاً بالنقر على زر “+”:
الآن لديكم جدول بيانات فارغ جديد:
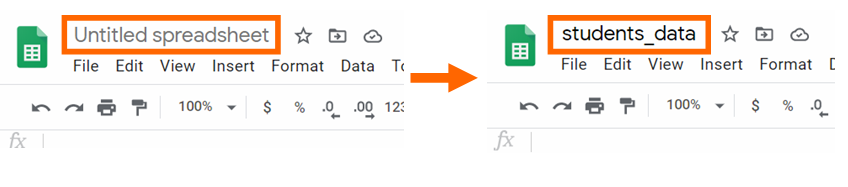
الخطوة 3: تسمية جدول البيانات
غيروا اسم جدول البيانات إلى students_data. سنحتاج إلى استخدام اسم الملف للتعامل مع إطارات البيانات. اكتبوا الاسم الجديد وانقروا على enter لتأكيد التغيير.
الخطوة 4: تحديد عناوين الأعمدة
في الصف الأول من جدول البيانات، اكتبوا عناوين الأعمدة:
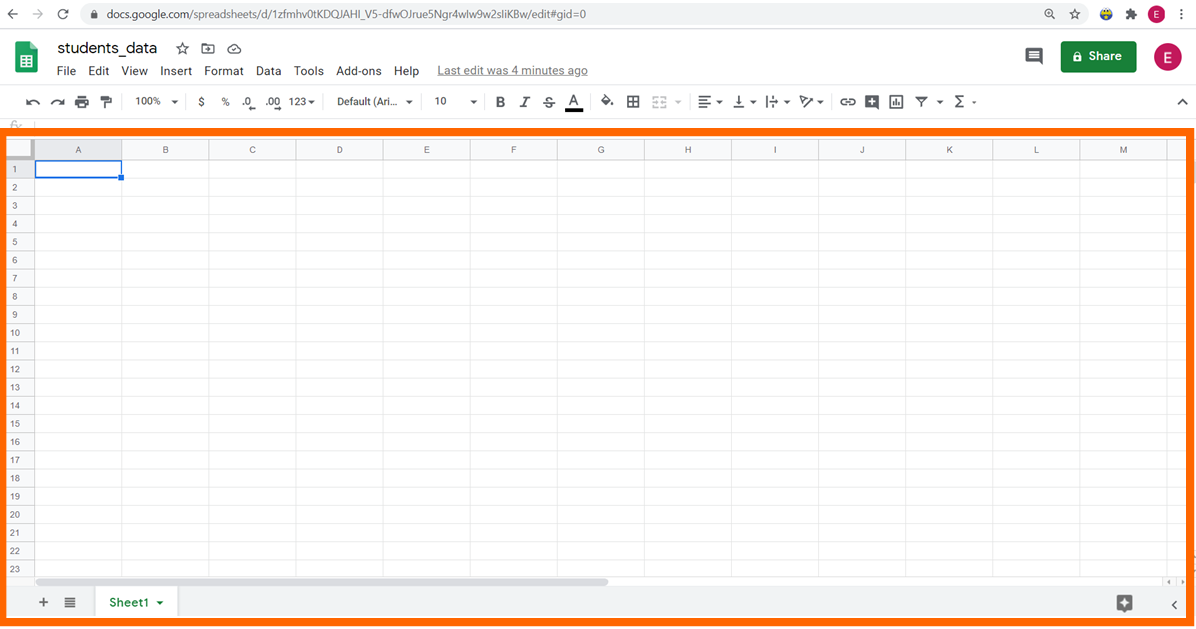
عند استيراد ملف CSV في لغة R، تُسمى عناوين الأعمدة “متغيرات” (variables). سنعرف ستة متغيرات: first_name، last_name، age، num_siblings، num_pets، و eye_color، كما ترون أدناه:

نصيحة: لاحظوا أن الأسماء مكتوبة بأحرف صغيرة والكلمات مفصولة بشرطة سفلية (_). هذا ليس إلزامياً، ولكن نظراً لأنكم ستحتاجون إلى الوصول إلى هذه الأسماء في R، فمن الشائع جداً استخدام هذا التنسيق.
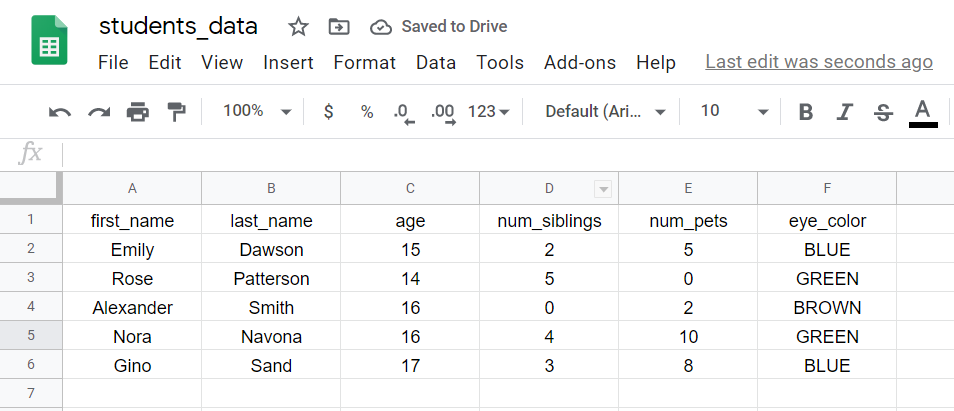
الخطوة 5: إدخال البيانات
أدخلوا البيانات لكل عمود. عند قراءة الملف في R، يُسمى كل صف “ملاحظة” (observation)، ويتوافق مع بيانات مأخوذة من فرد أو حيوان أو كائن أو كيان جمعنا منه البيانات. في هذه الحالة، يتوافق كل صف مع بيانات طالب:
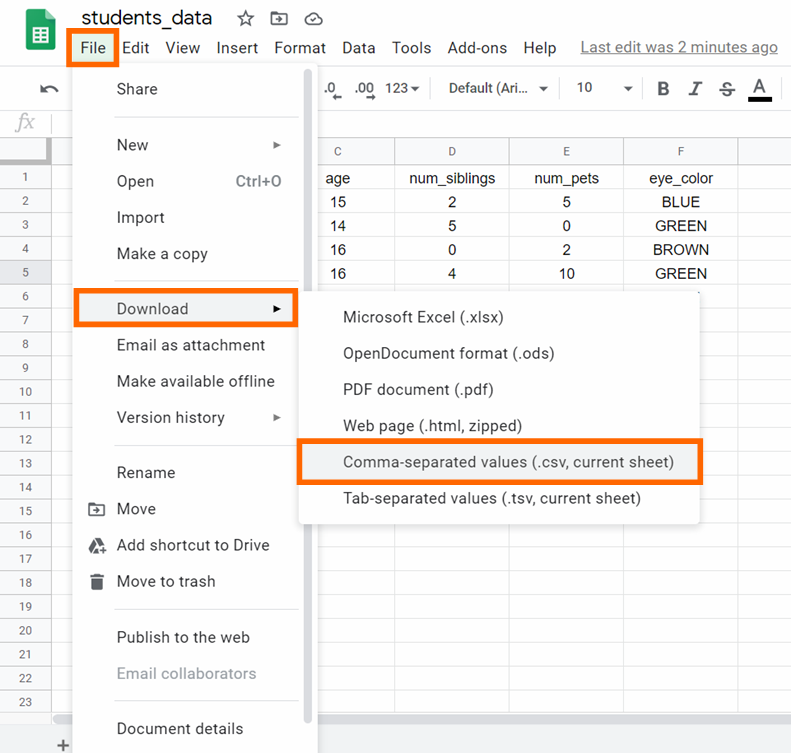
الخطوة 6: تنزيل ملف CSV
قوموا بتنزيل ملف CSV بالنقر على File -> Download -> Comma-separated values، كما ترون أدناه:
الخطوة 7: إعادة تسمية ملف CSV
أعيدوا تسمية ملف CSV. ستحتاجون إلى إزالة “Sheet1” من الاسم الافتراضي لأن جداول بيانات جوجل ستضيف هذا تلقائياً إلى اسم الملف.

عمل رائع! الآن لديكم ملف CSV الخاص بكم وحان الوقت للبدء في العمل به في لغة R.
كيفية قراءة ملف CSV في R
في بيئة RStudio، الخطوة الأولى قبل قراءة ملف CSV هي التأكد من أن دليل العمل الحالي (current working directory) هو الدليل الذي يوجد فيه ملف CSV. إذا لم يكن الأمر كذلك، فستحتاجون إلى استخدام المسار الكامل للملف.
تغيير دليل العمل الحالي
يمكنكم تغيير دليل العمل الحالي في هذه اللوحة:
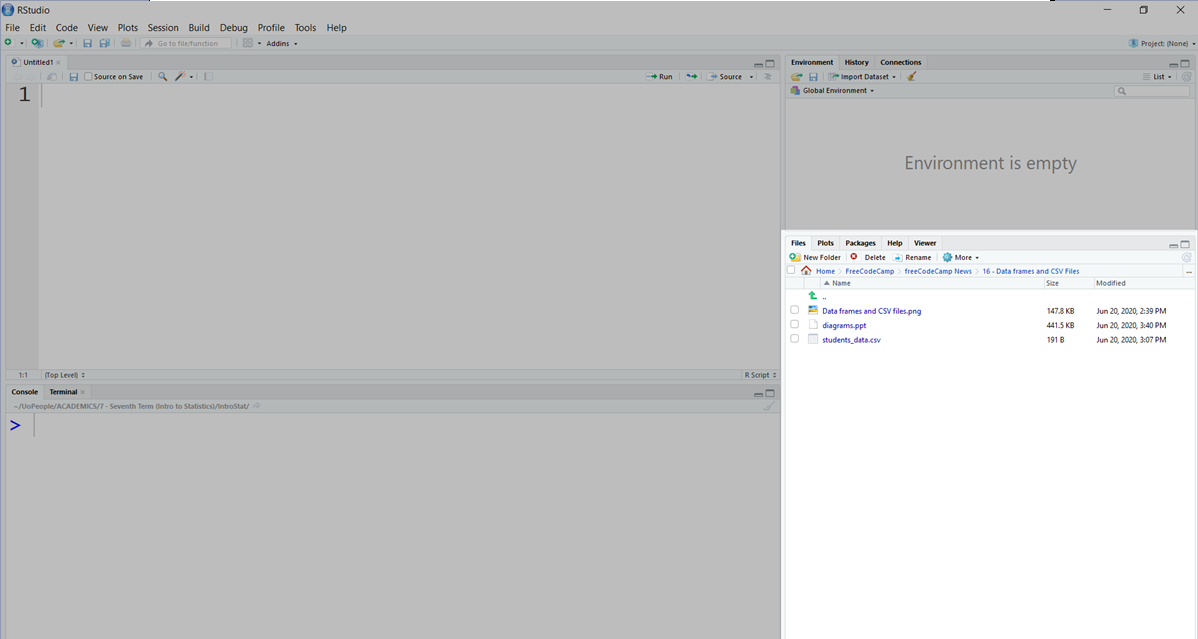
بالتكبير، يمكنكم رؤية المسار الحالي (1) واختيار المسار الجديد بالنقر على زر القطع الناقص (...) إلى اليمين (2):
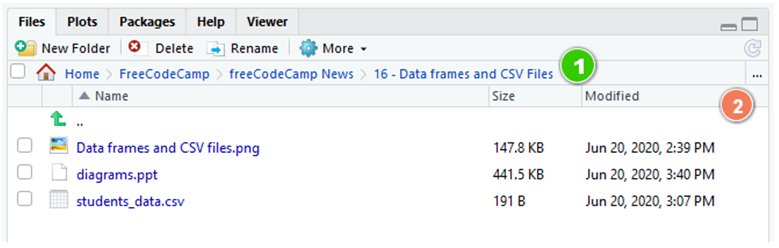
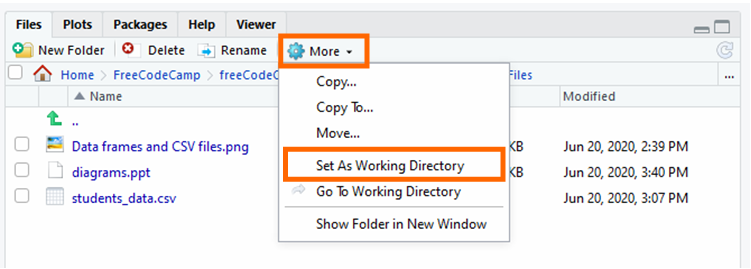
يمكنكم أيضاً التحقق من دليل العمل الحالي باستخدام الدالة getwd() في وحدة التحكم التفاعلية. ثم، انقروا على “More” و “Set As Working Directory”.
قراءة ملف CSV
بمجرد تعيين دليل العمل الحالي، يمكنكم قراءة ملف CSV باستخدام هذا الأمر:

في كود R، لدينا هذا:
> students_data <- read.csv( "students_data.csv" )نصيحة: نقوم بتعيين الملف للمتغير students_data للوصول إلى بيانات ملف CSV من خلال هذا المتغير. في R، يمكننا فصل الكلمات باستخدام النقاط (.)، والشرطات السفلية (_)، أو باستخدام تنسيق UpperCamelCase أو lowerCamelCase.
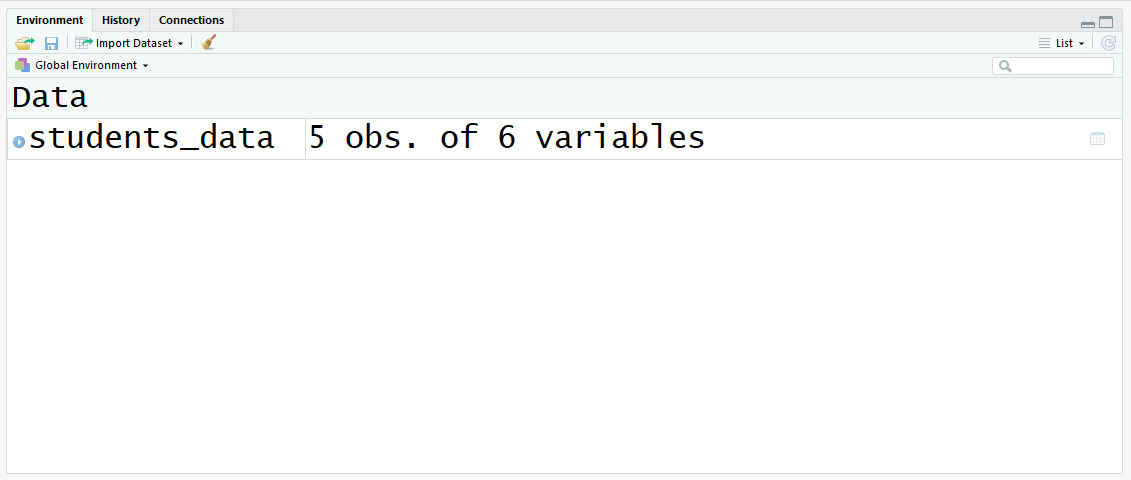
بعد تشغيل هذا الأمر، سترون هذا في اللوحة العلوية اليمنى:
الآن لديكم متغير معرف في البيئة! دعونا نرى ما هي إطارات البيانات وكيف ترتبط ارتباطاً وثيقاً بملفات CSV.
مقدمة إلى إطارات البيانات (Data Frames)
إطارات البيانات هي التنسيق الرقمي القياسي المستخدم لتخزين البيانات الإحصائية على شكل جدول. عند قراءة ملف CSV في R، يتم إنشاء إطار بيانات تلقائياً. يمكننا تأكيد ذلك عن طريق التحقق من نوع المتغير باستخدام الدالة class:
> class(students_data)
[1] "data.frame"هذا منطقي، أليس كذلك؟ تحتوي ملفات CSV على بيانات ممثلة على شكل جدول، وإطارات البيانات تمثل تلك البيانات الجدولية في الكود الخاص بكم، لذا فهي مرتبطة بعمق. إذا أدخلتم هذا المتغير في وحدة التحكم التفاعلية، فسترون محتوى ملف CSV:
> students_data
first_name last_name age num_siblings num_pets eye_color
1 Emily Dawson 15 2 5 BLUE
2 Rose Patterson 14 5 0 GREEN
3 Alexander Smith 16 0 2 BROWN
4 Nora Navona 16 4 10 GREEN
5 Gino Sand 17 3 8 BLUEمزيد من المعلومات حول إطار البيانات
لديكم عدة بدائل مختلفة لرؤية عدد المتغيرات (الأعمدة) والملاحظات (الصفوف) في إطار البيانات:
خياركم الأول هو النظر إلى اللوحة العلوية اليمنى التي تعرض المتغيرات المعرفة حالياً في البيئة. يحتوي إطار البيانات هذا على 5 ملاحظات (صفوف) و 6 متغيرات (أعمدة):

بديل آخر هو استخدام الدالتين nrow و ncol في وحدة التحكم التفاعلية أو في برنامجكم، مع تمرير إطار البيانات كمعامل. نحصل على نفس النتائج: 5 صفوف و 6 أعمدة.
> nrow(students_data)
[1] 5
> ncol(students_data)
[1] 6يمكنكم أيضاً رؤية مزيد من المعلومات حول إطار البيانات باستخدام الدالة str:
> str(students_data)
'data.frame': 5 obs. of 6 variables:
$ first_name : Factor w/ 5 levels "Alexander","Emily",..: 2 5 1 4 3
$ last_name : Factor w/ 5 levels "Dawson","Navona",..: 1 3 5 2 4
$ age : int 15 14 16 16 17
$ num_siblings: int 2 5 0 4 3
$ num_pets : int 5 0 2 10 8
$ eye_color : Factor w/ 3 levels "BLUE","BROWN",..: 1 3 2 3 1تخبركم هذه الدالة (المطبقة على إطار بيانات) بما يلي:
- عدد الملاحظات (الصفوف).
- عدد المتغيرات (الأعمدة).
- أسماء المتغيرات.
- أنواع بيانات المتغيرات.
- مزيد من المعلومات حول المتغيرات.
يمكنكم رؤية أن هذه الدالة رائعة حقاً عندما تريدون معرفة المزيد عن البيانات التي تعملون بها.
نصيحة: في R، “العامل” (Factor) هو متغير نوعي، وهو متغير تمثل قيمه فئات. على سبيل المثال، المتغير eye_color لديه القيم "BLUE"، "BROWN"، "GREEN" وهي فئات، لذا كما ترون في مخرجات الدالة str أعلاه، يتم تعريف هذا المتغير تلقائياً كـ “عامل” (factor) عند قراءة ملف CSV في R.
إطارات البيانات: العمليات والدوال الرئيسية
الآن تعرفون كيفية رؤية مزيد من المعلومات حول إطار البيانات. لكن سحر إطارات البيانات يكمن في القدرات والوظائف المذهلة التي تقدمها، لذا دعونا نرى هذا بمزيد من التفصيل.
كيفية الوصول إلى قيمة في إطار البيانات
إطارات البيانات تشبه المصفوفات، لذا يمكنكم الوصول إلى القيم الفردية باستخدام مؤشرين محاطين بأقواس مربعة ومفصولين بفاصلة للإشارة إلى الصفوف والأعمدة التي ترغبون في تضمينها في النتيجة، كالتالي:

على سبيل المثال، إذا أردنا الوصول إلى قيمة eye_color (العمود 6) للطالب الرابع في البيانات (الصف 4):
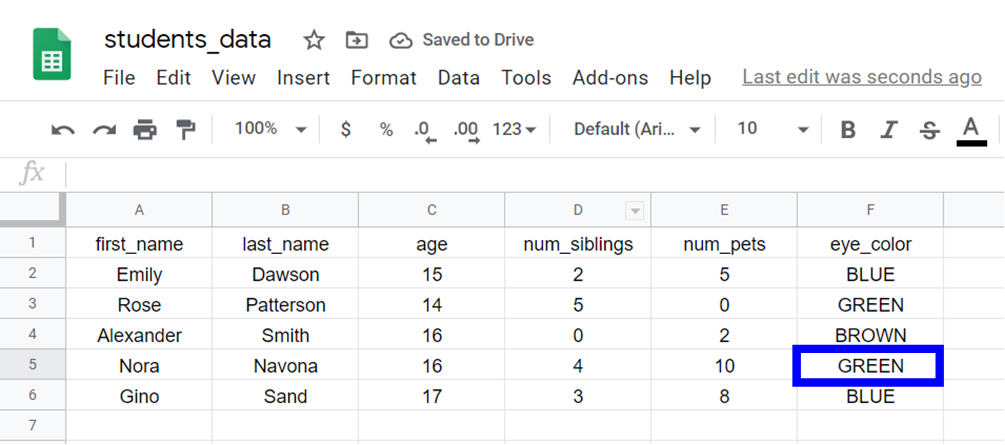
نحتاج إلى استخدام هذا الأمر:
> students_data[4, 6]نصيحة: في R، تبدأ المؤشرات من 1 ولا يتم احتساب الصف الأول الذي يحتوي على أسماء المتغيرات.
هذا هو الناتج:
[1] GREEN
Levels: BLUE BROWN GREENيمكنكم رؤية أن القيمة هي "GREEN". المتغيرات من نوع “عامل” (factor) لها “مستويات” (levels) تمثل الفئات أو القيم المختلفة التي يمكن أن تأخذها. يخبرنا هذا الناتج بمستويات المتغير eye_color.
كيفية الوصول إلى صفوف وأعمدة إطار البيانات
يمكننا أيضاً استخدام هذا النحو للوصول إلى نطاق من الصفوف والأعمدة للحصول على جزء من المصفوفة الأصلية، كالتالي:

على سبيل المثال، إذا أردنا الحصول على العمر وعدد الأشقاء للطلاب الثالث والرابع والخامس في القائمة، فسنستخدم:
> students_data[3:5, 3:4]
age num_siblings
3 16 0
4 16 4
5 17 3نصيحة: النحو الأساسي لتعريف فترة في R هو <start>:<end>. لاحظ أن هذه المؤشرات شاملة، لذا يتم تضمين العنصرين الثالث والخامس في المثال أعلاه عندما نكتب 3:5.
إذا أردنا الحصول على جميع الصفوف أو الأعمدة، فإننا ببساطة نحذف الفترة ونضمن الفاصلة، كالتالي:
> students_data[3:5,]
first_name last_name age num_siblings num_pets eye_color
3 Alexander Smith 16 0 2 BROWN
4 Nora Navona 16 4 10 GREEN
5 Gino Sand 17 3 8 BLUEلم نقم بتضمين فترة للأعمدة بعد الفاصلة في students_data[3:5,]، لذا نحصل على جميع أعمدة إطار البيانات للصفوف الثلاثة التي حددناها.
وبالمثل، يمكننا الحصول على جميع الصفوف لنطاق معين من الأعمدة إذا حذفنا الصفوف:
> students_data[, 1:3]
first_name last_name age
1 Emily Dawson 15
2 Rose Patterson 14
3 Alexander Smith 16
4 Nora Navona 16
5 Gino Sand 17نصيحة: لاحظ أنكم لا تزالون بحاجة إلى تضمين الفاصلة في كلتا الحالتين.
كيفية الوصول إلى عمود كامل
هناك ثلاث طرق للوصول إلى عمود بأكمله:
الخيار الأول: الحصول على عمود كإطار بيانات
للوصول إلى عمود وإعادته كإطار بيانات، يمكنكم استخدام هذا النحو:

على سبيل المثال:
> students_data["first_name"]
first_name
1 Emily
2 Rose
3 Alexander
4 Nora
5 Ginoالخيار الثاني: الحصول على عمود كمتجه (vector)
للحصول على عمود كمتجه (تسلسل)، يمكنكم استخدام هذا النحو:

نصيحة: لاحظوا استخدام الرمز $.
على سبيل المثال:
> students_data$first_name
[1] Emily Rose Alexander Nora Gino
Levels: Alexander Emily Gino Nora Roseالخيار الثالث: طريقة بديلة للحصول على عمود كمتجه
يمكنكم أيضاً استخدام هذا النحو للحصول على العمود كمتجه (انظر أدناه). هذا يعادل النحو السابق:
> students_data[["first_name"]]
[1] Emily Rose Alexander Nora Gino
Levels: Alexander Emily Gino Nora Roseكيفية تصفية صفوف إطار البيانات
يمكنكم تصفية صفوف إطار البيانات للحصول على جزء من المصفوفة يلبي شروطاً معينة. لهذا، نستخدم هذا النحو، مع تمرير الشرط كعنصر أول داخل أقواس مربعة، ثم فاصلة، وأخيراً ترك العنصر الثاني فارغاً.

على سبيل المثال، للحصول على جميع الصفوف التي يكون فيها students_data$age > 16، سنستخدم:
> students_data[students_data$age > 16,]
first_name last_name age num_siblings num_pets eye_color
5 Gino Sand 17 3 8 BLUEنحصل على إطار بيانات يحتوي على الصفوف التي تلبي هذا الشرط.
تصفية الصفوف واختيار الأعمدة
يمكنكم دمج هذا الشرط مع نطاق من الأعمدة:
> students_data[students_data$age > 16, 3:6]
age num_siblings num_pets eye_color
5 17 3 8 BLUEنحصل على الصفوف التي تلبي الشرط والأعمدة في النطاق 3:6.
كيفية تعديل إطارات البيانات
يمكنكم تعديل القيم الفردية لإطار البيانات، إضافة أعمدة، إضافة صفوف، وإزالتها. دعونا نرى كيف يمكنكم القيام بذلك!
كيفية تغيير قيمة
لتغيير قيمة فردية في إطار البيانات، تحتاجون إلى استخدام هذا النحو:

على سبيل المثال، إذا أردنا تغيير القيمة الموجودة حالياً في الصف 4 والعمود 6، والمشار إليها باللون الأزرق هنا:
نحتاج إلى استخدام سطر الكود هذا:
students_data[4, 6] <- "BROWN"نصيحة: يمكنكم أيضاً استخدام = كعامل تعيين.
هذا هو الناتج. تم تغيير القيمة بنجاح.

ملاحظة: تذكروا أن الصف الأول من ملف CSV لا يُحسب كصف أول لأنه يحتوي على أسماء المتغيرات.
كيفية إضافة صفوف إلى إطار البيانات
لإضافة صف إلى إطار بيانات، تحتاجون إلى استخدام الدالة rbind:

تأخذ هذه الدالة وسيطتين:
- إطار البيانات الذي تريدون تعديله.
- قائمة تحتوي على بيانات الصف الجديد.
لإنشاء القائمة، يمكنكم استخدام الدالة list() مع كل قيمة مفصولة بفاصلة. هذا مثال:
> rbind(students_data, list("William", "Smith", 14, 7, 3, "BROWN"))الناتج هو:
first_name last_name age num_siblings num_pets eye_color
1 Emily Dawson 15 2 5 BLUE
2 Rose Patterson 14 5 0 GREEN
3 Alexander Smith 16 0 2 BROWN
4 Nora Navona 16 4 10 BROWN
5 Gino Sand 17 3 8 BLUE
6 <NA> Smith 14 7 3 BROWNولكن انتظروا! تم عرض رسالة تحذير:
Warning message:
In `[<-.factor`(`*tmp*`, ri, value = "William") :
invalid factor level, NA generatedولاحظوا القيمة الأولى للصف السادس، إنها <NA>:
6 <NA> Smith 14 7 3 BROWNحدث هذا لأن المتغير first_name تم تعريفه تلقائياً كـ “عامل” (factor) عندما قرأنا ملف CSV، والعوامل لها “فئات” (مستويات) ثابتة. لا يمكنكم إضافة مستوى جديد (قيمة – "William") إلى هذا المتغير ما لم تقرأوا ملف CSV بالقيمة FALSE للمعامل stringsAsFactors، كما هو موضح أدناه:
> students_data <- read.csv("students_data.csv", stringsAsFactors = FALSE)
الآن، إذا حاولنا إضافة هذا الصف، يتم تعديل إطار البيانات بنجاح.
> students_data <- rbind(students_data, list("William", "Smith", 14, 7, 3, "BROWN"))
> students_data
first_name last_name age num_siblings num_pets eye_color
1 Emily Dawson 15 2 5 BLUE
2 Rose Patterson 14 5 0 GREEN
3 Alexander Smith 16 0 2 BROWN
4 Nora Navona 16 4 10 GREEN
5 Gino Sand 17 3 8 BLUE
6 William Smith 14 7 3 BROWNنصيحة: لاحظ أنه إذا قرأتم ملف CSV مرة أخرى وقمتم بتعيينه لنفس المتغير، فسيتم إزالة جميع التغييرات التي تم إجراؤها مسبقاً وسترون إطار البيانات الأصلي. تحتاجون إلى إضافة هذا المعامل إلى السطر الأول من الكود الذي يقرأ ملف CSV ثم إجراء التغييرات عليه.
كيفية إضافة أعمدة إلى إطار البيانات
إضافة الأعمدة إلى إطار البيانات أبسط بكثير. تحتاجون إلى استخدام هذا النحو:

على سبيل المثال:
> students_data$GPA <- c(4.0, 3.5, 3.2, 3.15, 2.9, 3.0)نصيحة: يجب أن يكون عدد العناصر مساوياً لعدد صفوف إطار البيانات.
يعرض الناتج إطار البيانات مع عمود GPA الجديد:
> students_data
first_name last_name age num_siblings num_pets eye_color GPA
1 Emily Dawson 15 2 5 BLUE 4.00
2 Rose Patterson 14 5 0 GREEN 3.50
3 Alexander Smith 16 0 2 BROWN 3.20
4 Nora Navona 16 4 10 GREEN 3.15
5 Gino Sand 17 3 8 BLUE 2.90
6 William Smith 14 7 3 BROWN 3.00كيفية إزالة الأعمدة
لإزالة الأعمدة من إطار البيانات، تحتاجون إلى استخدام هذا النحو:

عندما تقومون بتعيين القيمة NULL لعمود، يتم إزالة هذا العمود من إطار البيانات تلقائياً. على سبيل المثال، لإزالة عمود age، نستخدم:
> students_data$age <- NULLالناتج هو:
> students_data
first_name last_name num_siblings num_pets eye_color GPA
1 Emily Dawson 2 5 BLUE 4.00
2 Rose Patterson 5 0 GREEN 3.50
3 Alexander Smith 0 2 BROWN 3.20
4 Nora Navona 4 10 GREEN 3.15
5 Gino Sand 3 8 BLUE 2.90
6 William Smith 7 3 BROWN 3.00كيفية إزالة الصفوف
لإزالة الصفوف من إطار البيانات، يمكنكم استخدام المؤشرات والنطاقات. على سبيل المثال، لإزالة الصف الأول من إطار بيانات:

يأخذ [-1,] جزءاً من إطار البيانات لا يتضمن الصف الأول. ثم يتم تعيين هذا الجزء لنفس المتغير. إذا كان لدينا إطار البيانات هذا وأردنا حذف الصف الأول:

الناتج هو إطار بيانات لا يتضمن الصف الأول:
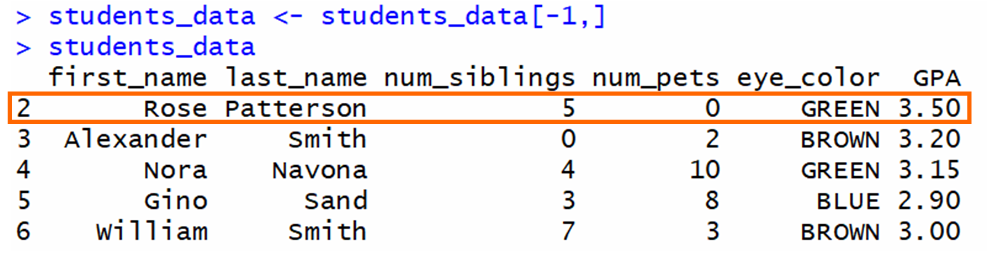
بشكل عام، لإزالة صف معين، تحتاجون إلى استخدام هذا النحو حيث <row_num> هو الصف الذي تريدون إزالته:

نصيحة: لاحظوا علامة - قبل رقم الصف.
على سبيل المثال، إذا أردنا إزالة الصف 4 من إطار البيانات هذا:

الناتج هو:
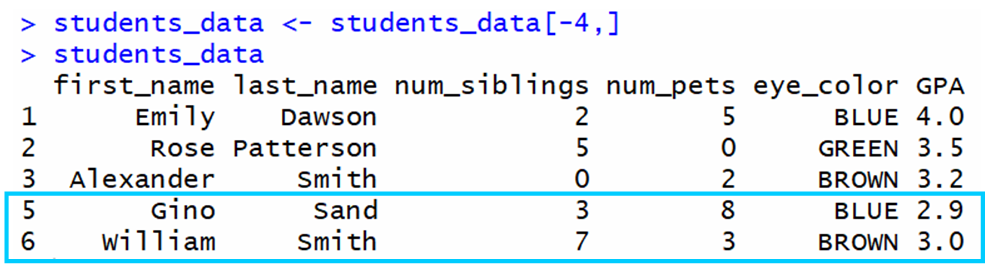
كما ترون، تم إزالة الصف 4 بنجاح.
الخلاصة التقنية
في هذا المقال، استكشفنا بعمق كيفية التعامل مع ملفات CSV وإطارات البيانات (Data Frames) في لغة البرمجة الإحصائية R. لقد رأينا أن ملفات CSV، بساطتها وفعاليتها في تخزين البيانات الجدولية، تشكل حجر الزاوية للعديد من عمليات تحليل البيانات. وعند قراءتها في R، تتحول تلقائياً إلى إطارات بيانات، وهي البنية الأساسية في R للتعامل مع البيانات المنظمة.
تُقدم إطارات البيانات مرونة وقوة لا مثيل لها في معالجة البيانات، بدءاً من الوصول إلى القيم الفردية، ومروراً بتصفية الصفوف والأعمدة بناءً على شروط محددة، وصولاً إلى تعديل البيانات بإضافة أو حذف صفوف وأعمدة. إن فهم هذه العمليات الأساسية ليس مجرد مهارة تقنية، بل هو مفتاح لفتح آفاق أوسع في تحليل البيانات واستخلاص الرؤى منها. من خلال إتقان هذه المفاهيم، يصبح بإمكان المحللين والعلماء التعامل بكفاءة مع مجموعات البيانات المعقدة، مما يمهد الطريق لاتخاذ قرارات مستنيرة وبناء نماذج إحصائية متقدمة. نأمل أن يكون هذا الدليل قد أضاف قيمة حقيقية لمسيرتكم في عالم علم البيانات.